
パラメータ数・データセット・計算の配分最適化
固定された計算予算の中で、パラメータ数とデータセットサイズをどう配分するかは、LLM の学習設計でかなり重要な論点です。見た目にはどちらも「増やせば良さそう」に見えますが、実際には片方だけを増やしても、もう片方が足りなければ期待した改善にはつながりにくいです。
この記事では、A1 で学んだスケール則の考え方を前提に、配分最適化をどう捉えるかを整理します。U カーブの見方、実験の組み方、μTransfer(μP)による探索コスト削減までを、実務で判断しやすい順番で見ていきます。
1. パラメータ配分最適化とは何か?
固定された計算予算の中で、パラメータ数 N とデータセットサイズ D をどう分けるか。B-3 は、その配分を誤ると学習効率が下がる、という話を扱います。
LLM の学習では、モデルを大きくするだけでは十分ではありません。データが足りなければ学習が追いつかず、逆にデータを増やしすぎても、モデル側の容量が足りなければ性能は伸び切りません。だからこそ、N と D を別々に大きくするのではなく、固定計算予算の下で最適な組み合わせを探す必要があります。
この章では、U カーブの見方と、μTransfer(μP)を使って探索コストを下げる考え方を整理します。
2. 固定計算予算の下で何を決めるのか?
スケーリング則の文脈では、学習に使える総計算量 C が決まっているとき、パラメータ数 N と学習データ量 D の配分を考えます。ざっくりした関係は次の通りです。
$$ C \approx 6ND $$
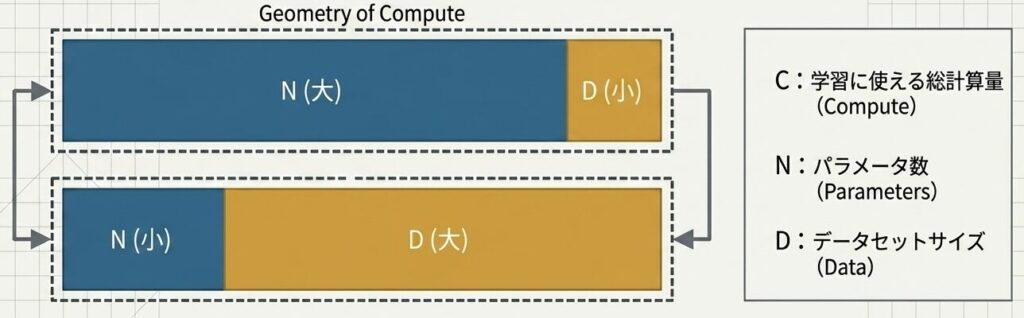
この式が意味しているのは、N を増やせば D を減らす方向に、D を増やせば N を減らす方向に、どちらかを調整しなければならないということです。つまり、固定予算では「どちらをどれだけ増やすか」を決めない限り、最適化は進みません。
実務でよくある失敗は、モデルサイズだけを追ってデータ側の制約を見落とすことです。たとえば、同じ計算量で 100M パラメータのモデルと 500M パラメータのモデルを比べると、後者は一見強そうに見えます。しかし、学習トークン数が十分でなければ、単に大きいだけのモデルになりやすいです。逆に、データだけを増やしても、モデル容量が足りなければ吸収しきれません。
実装としては、まず固定計算予算から候補の組み合わせを作り、そのあとで実測 loss を並べる形にすると扱いやすいです。以下は、計算予算から D を逆算して候補を並べる最小例です。
from dataclasses import dataclass
from typing import Iterable
@dataclass
class AllocationCandidate:
num_params: int
num_tokens: int
d_over_n: float
def build_allocation_candidates(total_flops: float, param_candidates: Iterable[int]) -> list[AllocationCandidate]:
"""固定計算予算から候補の配分を作る"""
candidates: list[AllocationCandidate] = []
for num_params in param_candidates:
num_tokens = int(total_flops / (6 * num_params))
candidates.append(
AllocationCandidate(
num_params=num_params,
num_tokens=num_tokens,
d_over_n=num_tokens / num_params,
)
)
return candidates
def print_candidates(candidates: list[AllocationCandidate], measured_losses: list[float]) -> None:
"""候補と実測 loss を並べて比較する"""
for candidate, loss in zip(candidates, measured_losses):
print(
f"N={candidate.num_params/1e6:.0f}M, "
f"D={candidate.num_tokens/1e9:.1f}B, "
f"D/N={candidate.d_over_n:.1f}, "
f"loss={loss:.4f}"
)
def select_best_candidate(candidates: list[AllocationCandidate], measured_losses: list[float]) -> tuple[AllocationCandidate, float]:
"""最小 loss の配分を選ぶ"""
best_index = min(range(len(measured_losses)), key=measured_losses.__getitem__)
return candidates[best_index], measured_losses[best_index]
total_flops = 1e21
param_candidates = [10e6, 50e6, 100e6, 500e6, 1e9]
candidates = build_allocation_candidates(total_flops, param_candidates)
# ここに実際の学習結果を入れて比較する
measured_losses = [3.15, 2.48, 2.12, 1.58, 1.67]
print_candidates(candidates, measured_losses)
best_candidate, best_loss = select_best_candidate(candidates, measured_losses)
print(
f"best: N={best_candidate.num_params/1e6:.0f}M, "
f"D={best_candidate.num_tokens/1e9:.1f}B, "
f"loss={best_loss:.4f}"
)計算量(C)を固定した瞬間、パラメータ(N)とデータ(D)は「トレードオフ」の関係になる。どちらかを調整しなければ最適化は進まない。
3. U カーブはなぜ生まれるのか?
N と D のバランスを動かしていくと、性能は一直線に良くなるわけではありません。ある点を超えると、むしろ悪化します。この形が U カーブとして見える理由です。
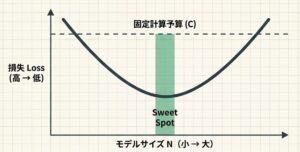
ここで大事なのは、両端で別の問題が起きていることです。
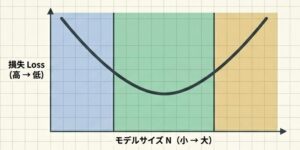
| 状況 | 起きやすいこと | 読み取り方 |
|---|---|---|
| モデルが小さすぎる | 表現力が足りず、学習しても頭打ちになる | 容量不足を疑う |
| ちょうどよい配分 | 損失が最も下がりやすい | まずここを基準にする |
| モデルが大きすぎるのにデータが足りない | 学習が追いつかず、改善が鈍る | データ不足を疑う |
たとえば、同じ計算予算で「小さめのモデルに多めのトークンを与える」ケースと、「大きめのモデルに少ないトークンしか与えない」ケースを比べると、後者のほうが必ずしも良いとは限りません。見た目は大きいのに、学習が足りないからです。
この章のポイントは、U カーブを「理論上の飾り」として見るのではなく、「どこから先は逆効果になりやすいか」を確かめる実験指標として使うことです。
NとDのバランスを動かすと、性能は一直線には伸びない。 バランスが崩れると Lossは悪化し、U字型の軌跡を描く。
4. 実験はどう組むのか?
最適配分を探すときは、まず計算予算 C を固定します。そのうえで、候補となる N をいくつか決め、各 N に対して D を式から逆算します。こうすると、比較の基準がそろいます。
実験の考え方はシンプルです。
| 手順 | やること | 目的 |
|---|---|---|
| 1 | 総計算量を固定する | 比較条件をそろえる |
| 2 | N の候補を複数用意する | どの規模がよいかを見る |
| 3 | D を C から逆算する | 片方だけを増やしてしまうのを防ぐ |
| 4 | 同じ評価条件で loss を比べる | 最適点を見つける |
ここで気をつけたいのは、N と D 以外の条件まで同時に変えないことです。学習率、バッチサイズ、最適化手法まで一気に変えてしまうと、何が効いたのか分からなくなります。探索の失敗は、たいていこの「一度に変えすぎる」ところから始まります。
実験ログを見るときは、最終 loss だけでなく、学習の安定性や収束の速さも合わせて見ると判断しやすくなります。最終値が同じでも、途中で大きく揺れている設定は、再現性の面で不安が残るからです。
厳格なルール:「NとD以外の条件(学習率、バッチサイズ、最適化手法など)は絶対に同時に変えないこと」。一度に変えすぎると原因の切り分けが不可能になる。
5. μTransfer(μP)は何を効率化するのか?
μTransfer(μP)は、小規模モデルで見つけた最適な学習設定を、大規模モデルに転移させやすくする考え方です。ここで特に効くのは学習率の探索です。
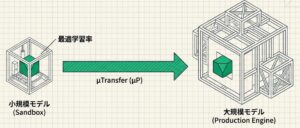
通常は、大きいモデルごとに学習率を何度も試し、どの値が安定しているかを確認します。ところが μP を使うと、小さなモデルで学習率の当たりをつけ、その設定を大きいモデルに持ち込む流れを作りやすくなります。
この資料の例では、全グリッド探索を回すより、探索試行数を大きく減らせる想定でした。たとえば、学習率候補 5 個 × モデル規模 5 通りで 25 回、廻す代わりに、小規模探索 1 回と大規模本番 1 回に分けると、試行回数をかなり抑えられます。実際の削減率は構成に依存しますが、少なくとも「全部の組み合わせを試す」よりは明らかに軽くなります。
| 方式 | 探索のしかた | ねらい |
|---|---|---|
| 従来の全探索 | 大小さまざまなモデルで学習率を総当たりする | まわり道だが分かりやすい |
| μP を使う方法 | 小規模モデルで見つけた値を大規模モデルへ転移する | 探索コストを抑える |
ただし、μP は魔法ではありません。アーキテクチャや正規化、初期化の前提が変われば、転移の効き方も変わります。だからこそ、理論の名前だけで安心せず、最終的には自分の設定で確認する必要があります。
小規模モデルで広範に探索して発見した「最適な学習設定(学習率など)」を、大規模モデルへ直接「転移」させる技術。大規模での試行錯誤をスキップし、探索コストを劇的に下げる。
6. どこで失敗しやすいのか?
このテーマでありがちな失敗は、結果が悪かったときに原因を取り違えることです。
たとえば、500M パラメータの設定で loss が悪化したとします。ここで「大きいモデルはダメだった」と結論づけるのは早すぎます。実際には、データ量が足りなかっただけかもしれませんし、学習率が合っていなかっただけかもしれません。
よくあるつまずきは次の通りです。
| 失敗例 | 何が問題か | どう直すか |
|---|---|---|
| N と D と学習率を同時に変える | 原因が切り分けられない | 変更点を一つずつに絞る |
| 1 回の結果だけで判断する | ばらつきを見落とす | 複数 seed で確認する |
| 最適比率を全タスクにそのまま当てる | 前提が違うのに一般化してしまう | モデルとデータごとに再確認する |
| 学習 loss だけを見る | 汎化や安定性を見逃す | 検証指標も並べて見る |
このあたりは、実験を急いだときほど起こりやすいです。配分最適化は、当てずっぽうで速く進めるより、比較条件をそろえて遅く確かめたほうが、結果的に近道になります。
Takeaway:最初から完璧な配分を狙うと失敗する。段階的に進めることで「何を増やしたから良くなったのか」が追える。
7. どの順序で試すべきなのか?
最初から完璧な配分を狙う必要はありません。むしろ、現実的には段階的に進めたほうが失敗しにくいです。
- まずは計算予算を固定する
- N の候補を少数に絞る
- D を式から逆算して、同条件で比較する
- loss と安定性を見て、候補を一つ減らす
- 探索コストが重いなら μP を検討する
この順序にしておくと、「何を増やしたから良くなったのか」が追いやすくなります。反対に、最初から全部を最適化しようとすると、何が効いて何が効かなかったのか分からなくなります。
実務では、まず理論値に近い配分を置いてみて、そこから少しずつずらすのが扱いやすいです。理論は出発点として有効ですが、最終判断は必ず自分のデータとモデルで下す必要があります。
8. まとめ
計算予算とモデル選定のプロセス
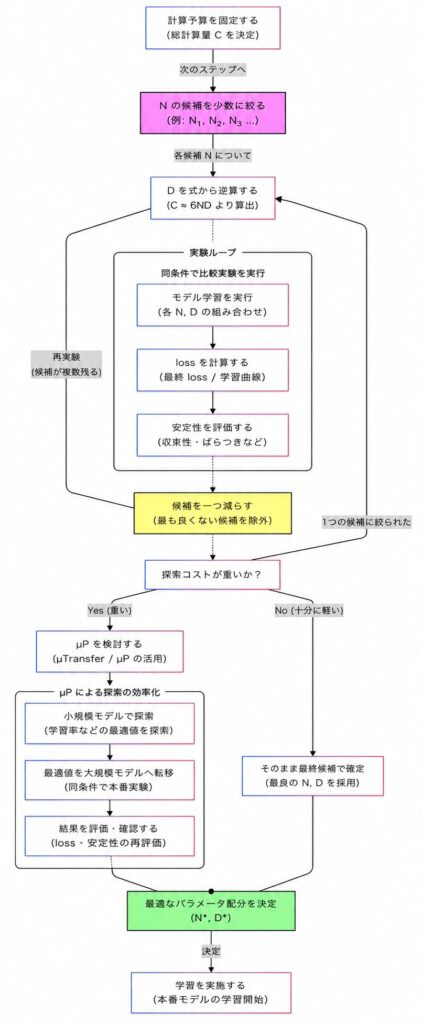
B-3 の要点は、固定計算予算の下では N か D のどちらかだけを追っても最適化にならない、ということです。U カーブは、そのバランスを外したときに性能が落ちることを示す見取り図として使えます。
さらに、μTransfer(μP)を使えば、小規模モデルでの探索結果を大規模モデルに持ち込みやすくなり、試行回数を抑えられます。ただし、それは前提がそろっている場合に限ります。条件が違えば、必ず自分の設定で検証し直す必要があります。
結局のところ、この章で覚えたいのは「大きくすればよい」でも「データを増やせばよい」でもありません。限られた計算資源の中で、どの配分が最も学習効率を高めるかを見極めることです。
9. 今回のブログの考察
パラメータ配分の最適化は、見た目以上に「何を増やせばよいか」を決める作業ではなく、「何を増やすと逆に無駄が増えるか」を見極める作業だと言えます。今回の記事で見たように、N を大きくすれば安心でも、D を増やせば必ず伸びるわけでもありません。固定計算予算の下では、どちらか一方だけを押し上げても、もう一方が足りなければ期待した改善にはつながりにくいからです。実務でこの判断を誤ると、計算資源を使ったわりに手応えが薄い、という結果になりやすいでしょう。
大事なのは、U カーブや μTransfer(μP)を「最適解の暗記」として使うことではありません。むしろ、いま詰まっているのが容量不足なのか、データ不足なのか、探索コストなのかを切り分けるための道具として使うことに意味があります。そう考えると、この章の本質は配分そのものではなく、配分を通じてボトルネックを特定することにあります。どこを動かせば効くのかが見えれば、実験の優先順位も自然に決まりますし、逆にそこが見えないうちは、どれだけ大きなモデルを作っても判断は曖昧なままです。
つまり、配分最適化で本当に問われているのは「どれだけ大きくできるか」ではなく、「限られた計算資源をどの方向に使えば、次の一歩が最も意味のあるものになるか」だと考えられます。そこを押さえておくと、理論の話が単なる知識ではなく、実験設計の具体的な判断基準として見えてきます。
参考文献
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.
- Yang, G., et al. (2022). “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.” Microsoft Research.
このシリーズの案内
- B-2: スケール則の測定と検証
- B-4: 計算効率の測定と最適化
- A-4: Chinchilla則とは何か – D≈20N の理論的根拠
- C-1: 最適配分の理論基盤


コメント