前回までの記事では、スケール則をどう測るか、どう配分するか、どう計算効率を上げるかを見てきました。ここまで読むと、モデルは「学習をどう設計するか」で性能が決まるように見えますが、実務ではそれだけではありません。
この記事では、学習済みモデルに対して「推論時にどれだけ計算を使うか」という視点から、Chain-of-Thought、Beam Search、Speculative Decoding などの手法を整理します。再学習なしでどこまで改善できるのか、そしてどこでコストやレイテンシとの折り合いをつけるべきなのかを、実務で判断しやすい順番で見ていきます。
1. なぜ推論時スケーリングが重要なのか?
訓練時スケーリングは、モデルサイズやデータ量を増やして性能を上げる考え方です。代表例として、Chinchilla 則の $D \approx 20N$ がよく引用されます。
一方で推論時スケーリングは、学習済みモデルに対して「1 回の回答にどれだけ計算を使うか」を増やして、出力品質を改善する考え方です。
現場の意思決定で見ると、この違いは大きいです。
- 訓練時スケーリング: 精度は上がりやすいが、再学習コストが重い
- 推論時スケーリング: 追加学習なしで改善できるが、1 リクエストあたりの計算コストが増える
要するに、「モデルを作り直す」か「使い方を賢くする」かの違いです。
学習済みモデルに対して「1回の回答にどれだけ計算を使うか」を動的に調整することで、再学習ゼロで出力品質を飛躍的に高めるパラダイムシフト。
2. 推論時スケーリングとは何か?
推論時スケーリングは、主に次の 3 つの軸で実施されます。
| 軸 | 何を増やすか | 期待できる効果 | 主なトレードオフ |
|---|---|---|---|
| 思考ステップ(CoT) | 推論の中間ステップ | 推論の一貫性向上 | レイテンシ増加 |
| 候補探索(Beam Search) | 候補系列の本数 | 良い候補を拾う確率向上 | 計算量・メモリ増加 |
| 推論経路の最適化(Speculative Decoding) | ドラフト+検証の二段構成 | 速度向上 | 採択率に性能が依存 |
ここで重要なのは、すべてのタスクで同じように効くわけではない点です。推論問題、生成問題、対話問題で効き方は変わります。
3. CoT はどのように効くのか?
CoT(Chain-of-Thought)は、モデルに段階的な推論を促す方法です。算術、論理、手順選択のような「途中式が必要な問題」で効果が出やすいと報告されています。
次のコードは、ステップ数を増やしたときの改善をシミュレーションする最小例です。
import numpy as np
def cot_scaling_law(n_steps: np.ndarray, alpha_infer: float = -0.031):
"""簡易モデル: ステップ増加で精度が漸増する挙動を表現"""
baseline_accuracy = 0.75
accuracy = baseline_accuracy + 0.20 * np.power(n_steps, -alpha_infer)
return accuracy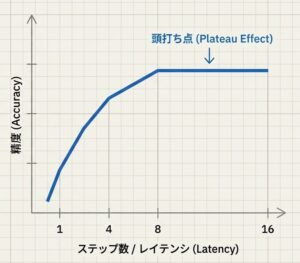
実務での失敗例として多いのは、CoT を「常に長くすれば良い」と考えることです。実際には、ステップを増やすほど改善幅は鈍化し、応答時間だけが増える局面が出ます。したがって、4 ステップ、8 ステップ、16 ステップのように段階的に検証して、改善の頭打ち点を見つける運用が現実的です。
4. Beam Search はどこまで使うべきなのか?
Beam Search は、複数の候補系列を並行探索して、最終的により良い系列を選ぶ方法です。特に翻訳や要約など、候補の質に差が出やすいタスクで有効です。
import numpy as np
def beam_search_scaling(beam_size: int, model_size: str = "medium"):
coefficients = {
"small": {"baseline": 0.68, "alpha": 0.15},
"medium": {"baseline": 0.76, "alpha": 0.18},
"large": {"baseline": 0.82, "alpha": 0.20},
}
coeff = coefficients[model_size]
return coeff["baseline"] + coeff["alpha"] * np.log2(beam_size)ただし、Beam サイズは大きいほど良いとは限りません。理由は 2 つあります。
- 候補が増えるほどレイテンシとメモリ負荷が上がる
- タスクによっては、候補多様性よりデコーディング戦略の調整のほうが効く
実務では、beam=1, 2, 4, 8 のような小さなグリッド探索で十分に傾向を掴めることが多いです。
5. Speculative Decoding はなぜ速度改善につながるのか?
Speculative Decoding は、小さなドラフトモデルで候補トークンを先に出し、大きなターゲットモデルで検証する二段構成です。狙いは「品質を維持しながら待ち時間を減らすこと」です。
class SpeculativeDecoding:
def __init__(self, draft_model_size: int, target_model_size: int):
self.draft_params = draft_model_size
self.target_params = target_model_size
def compute_speedup(self, acceptance_rate: float = 0.85):
draft_time = 1.0 * (self.draft_params / self.target_params)
verify_time = 1.0
avg_time_per_iteration = draft_time + acceptance_rate * verify_time
baseline_time = verify_time + verify_time
speedup = baseline_time / avg_time_per_iteration
return speedup注意点は、速度改善が採択率に強く依存することです。採択率が想定より低い場合、理論値ほど高速化しないケースがあります。ここは必ず本番相当のログで確認してください。
6. どの手法を選ぶべきなのか?
以下は、実務での意思決定に使える目安です。数値はタスクやモデルで変わるため、厳密な保証値ではなく運用上のガイドとして扱ってください。
| 状況 | 推奨テクニック | 計算投資の目安 | 期待効果の目安 |
|---|---|---|---|
| 高精度必須(例: 医療系の下書き支援) | CoT(16+ ステップ) | 16x 前後 | 精度向上が見込みやすい |
| バランス重視(例: 業務チャット) | CoT(4)+ Beam(4) | 4x 前後 | 精度と速度の折衷 |
| 低レイテンシ重視(例: エッジ推論) | Speculative Decoding | 1-2x | 体感速度の改善 |
| リソース制約が厳しい | Single-step + 前処理最適化 | 1x | ベースライン維持 |
各手法は独立しているだけでなく、用途に応じて組み合わせることで最大の効果を発揮する。
7. 導入時に失敗しやすいポイントは何か?
推論時スケーリングは有効ですが、次の失敗が起きやすいです。
- 精度だけを見てレイテンシ SLO を破る
- 開発環境の改善値を本番にそのまま適用する
- CoT や Beam の設定を固定し、タスク別に調整しない
回避策はシンプルです。
- 品質指標と同時にレイテンシ、コストを必ず記録する
- 最低 3 段階の設定(小・中・大)を比較する
- 本番相当データで再評価してから固定値を決める
8. まとめ
推論時スケーリングの価値は、「再学習なしでも性能改善の余地を作れること」です。特に、短期間で品質を上げたい局面では強力な選択肢になります。
ただし、改善は無料ではありません。精度、速度、コストの 3 軸を同時に見ながら、タスク別に最適点を探る運用が必要です。
商用 LLM で推論最適化が競争力になっているのは、この 3 軸の設計と検証を継続しているからだと考えられます。

LLMの性能は、モデルのサイズ(固定値)だけで決まるわけではない。 同じモデルであっても、用途に応じて動的に「推論時の計算量」をチューニングすることで、1つのモデルから全く異なるパフォーマンスを引き出すことができる。 「高性能なモデルを作る」ことと、「モデルを賢く使う」ことは両輪である。
9. 今回のブログの考察
推論時スケーリングの面白さは、モデルを「もっと賢く作る」だけではなく、「賢さをどう使うか」を設計し直せる点にあります。今回の記事で見た CoT、Beam Search、Speculative Decoding は、いずれも学習済みモデルに追加の計算や手順を与えることで、出力を安定させたり、速度を改善したりする方法でした。ここから分かるのは、LLM の性能はモデル本体だけで決まるのではなく、推論時の設計でもかなり変わるということです。
実務では、つい「高性能なモデルを使えば解決する」と考えがちです。しかし、実際には用途ごとに求められるものが違います。正確さを優先したい場面もあれば、応答速度が重要な場面もあり、コスト制約が最優先になることもあります。推論時スケーリングは、そのトレードオフを見える形にしてくれる考え方だと言えます。だからこそ、単に手法名を覚えるのではなく、自分のタスクでは何を増やし、何を抑えるべきかを考える視点が重要です。
結局のところ、推論時スケーリングは「同じモデルでも、使い方次第でまだ伸びる余地がある」ことを示しています。再学習に進む前に、まず推論の設計を見直す。この順番を持てるかどうかが、実務での無駄なコストを減らし、性能改善の打ち手を広げるうえで大きな差になるはずです。
参考文献
- Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.”
- Leviathan, Y., et al. (2023). “Fast Inference from Transformers via Speculative Decoding.”
コメント