
Chinchilla則とは何か:N と D の最適配分
2022 年まで、LLM の開発では「パラメータ数を増やすことが最優先」という空気が強くありました。もちろん、モデルを大きくすることには意味があります。ですが、DeepMind の Chinchilla 研究は、そこにだけ注目していると最適な学習配分を外す可能性があることを示しました。
Chinchilla 則の本質は、モデルサイズの話だけではありません。限られた計算予算の中で、パラメータ数 $N$ と学習データ量 $D$ をどう配分すればよいかを、経験則としてかなり具体的に示した点にあります。
この記事で学べること
- Chinchilla 則がどの問題を解いたのか?
- N と D の最適比率がなぜ重要なのか?
- Gopher と Chinchilla の比較で何が変わったのか?
- 実務ではどう考えるべきか?
1. Chinchilla 則は何を変えたのか?
GPT-3 は 1750 億パラメータを持つ巨大なモデルでした。この規模感は当時のLLM開発を強く印象づけましたが、DeepMind は、モデルを大きくする方向だけに寄せても、同じ計算予算の中で最良の結果にはならないことを示しました。
Chinchilla 研究が示したのは、訓練効率を考えるなら「大きさ」ではなく「配分」を見るべきだということです。言い換えると、同じ計算資源を使うなら、パラメータ数とデータ量のバランスを整えたほうが、より高い性能につながる場合がある、ということです。
見落とされていた視点 「計算予算に対するデータ量の重要性」が欠落していた。巨大化への偏重は、予算が限られている場合、「最適な学習配分」を外す原因となる。
2. Chinchilla 則の核心は何なのか?
DeepMind の研究では、計算量 $C$ を固定した場合に、パラメータ数 $N$ とデータセットサイズ $D$ をどう配分すれば最も良い性能を得られるかが調べられました。
その結果として示されたのが、次の関係です。

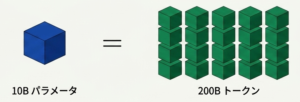
つまり、最適な学習トークン数は、最適なパラメータ数の約 20 倍が目安になるということです。
この式の意味は単純ですが、実務への影響は大きいです。モデルの規模だけを見て「大きいから強い」と判断するのではなく、学習データがそれに見合っているかを同時に見なければならないからです。
例えば、10B(100億)パラメータのモデルを最適に訓練するには、200B(2000億)トークンのデータが必要になる。器(パラメータ)に見合った学習データを与えなければならない。
3. Gopher と Chinchilla を比べると何が見えるのか?
この原則がどれほど重要かは、Gopher と Chinchilla の比較を見ると分かりやすいです。

Gopher(従来型、2021年発表)
- パラメータ数: 280B(2800億)
- 学習トークン数: 300B(3000億)
- D/N比: $\frac{300B}{280B} \approx 1.1$
Gopher の時代は、「まずモデルを大きくする」という考え方が強く、D/N 比は約 1.1 と、かなりパラメータ重視の配分でした。
Chinchilla(最適型、2022年発表)
- パラメータ数: 70B(700億)
- 学習トークン数: 1.4T(1.4兆)
- D/N比: $\frac{1.4T}{70B} = 20.0$
Chinchilla は、Gopher の 1/4 のパラメータサイズでありながら、代わりに 4.6 倍のデータ量を使うことで、Gopher を上回る性能を達成しました。
ここで重要なのは、単に「小さいモデルのほうが良い」と言っているわけではないことです。そうではなく、同じ計算予算の中で、データを十分に与えたほうが結果が良くなる領域がある、という点が本質です。
4. 同じ計算量で比べると何が起きるのか?
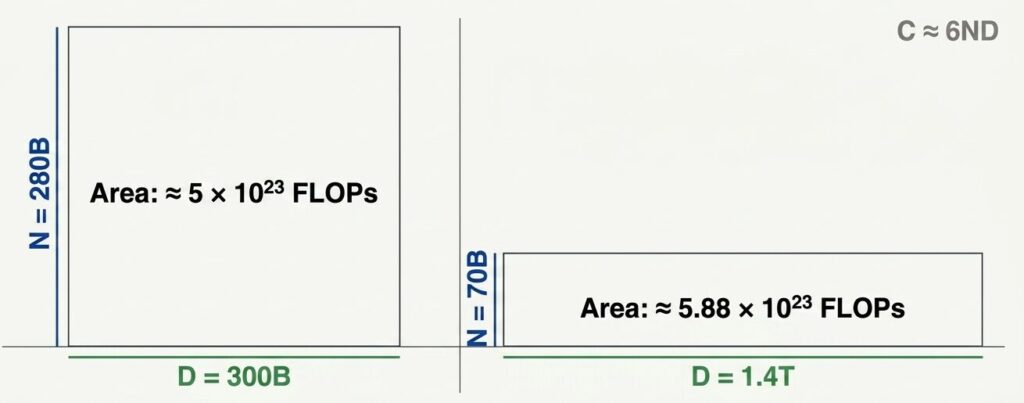
重要なのは、この比較が同じ計算量 $C$ の制約下で行われていることです。
計算量の公式 $C \approx 6ND$ を使うと:
| モデル | 計算式 | 計算量 |
|---|---|---|
| Gopher | $6 \times 280B \times 300B$ | $\approx 5 \times 10^{23}$ FLOPs |
| Chinchilla | $6 \times 70B \times 1.4T$ | $\approx 5.88 \times 10^{23}$ FLOPs |
つまり、ほぼ同じ計算予算で、パラメータを 1/4 に減らし、データを 4.6 倍増やすことで、より高い性能を得られたのです。
この結果が示すのは、計算資源が限られている現場では、「どれだけ大きいモデルを作れるか」よりも、「その予算をどう配るか」のほうが重要になる場面がある、ということです。
重要なのは、同じ計算量(C)の制約下で行われていること。 予算の「使い方」の次元を変えるだけで、性能が逆転する。
5. スケール則と Chinchilla 則はどう違うのか?
スケール則と Chinchilla 則は別の概念ですが、密接につながっています。
| 概念 | 定義 | 役割 |
|---|---|---|
| スケール則 | N, D, C が性能に線形(両対数グラフで)に影響する | 性能予測の基礎 |
| Chinchilla則 | 計算量を固定した場合、N と D をどう配分すべきか | 最適配分のガイドライン |
つまり、Chinchilla 則は、スケール則を実際の学習設計に落とし込むための、かなり実践的な指針だと言えます。
6. Chinchilla 則は実務に何を示しているのか?
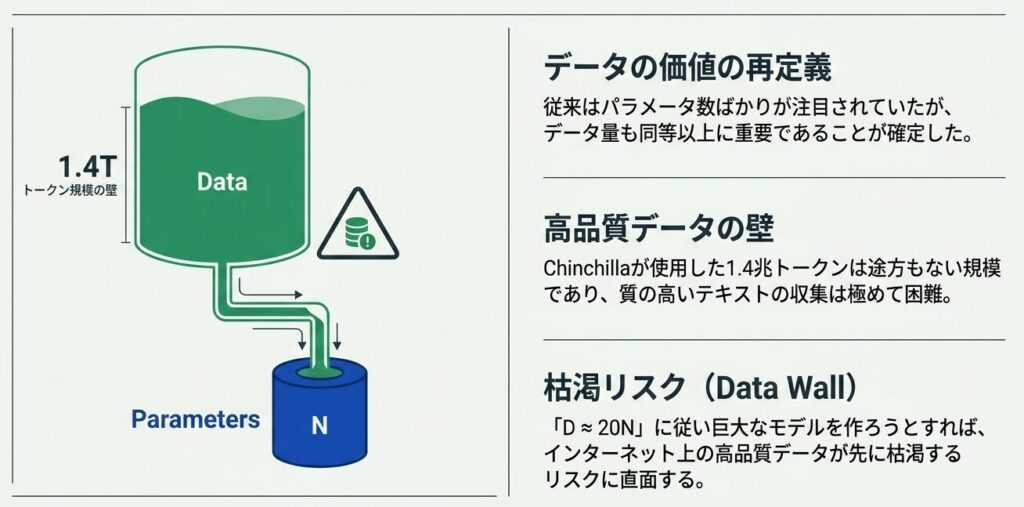
1. データは想像以上に重要だった
従来の LLM 開発では、パラメータ数ばかりが注目され、学習トークン数は相対的に見えにくい存在でした。Chinchilla 則は、実際にはデータ量もパラメータ数と同じくらい重要だと示しました。
2. 投資判断の精度を上げやすい
「1000 PF-days の計算予算がある」という制約の下で、最適なパラメータサイズとデータ量を決めやすくなります。
計算例:
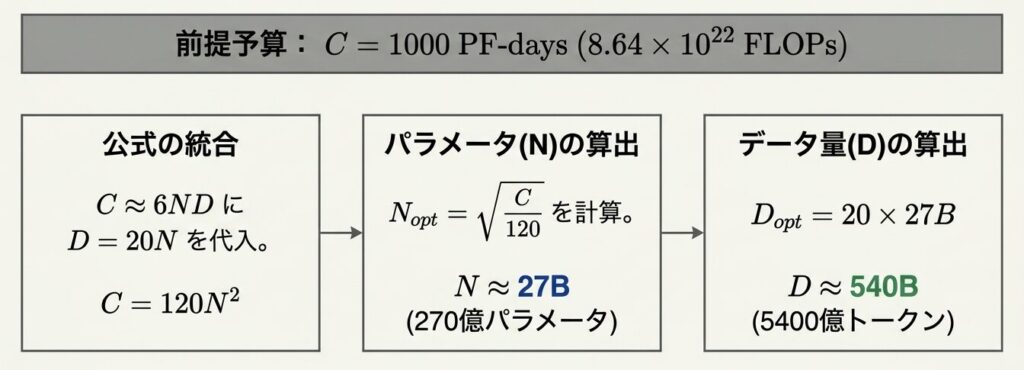
投資額(計算量)が決まれば、目指すべきアーキテクチャの絶対的な基準値が自動的に導き出される。
3. 推論コストは別問題として残る
Chinchilla 則は、あくまで訓練効率を最適化する考え方です。実際の運用では、推論コストやレスポンス速度も別途考える必要があります。
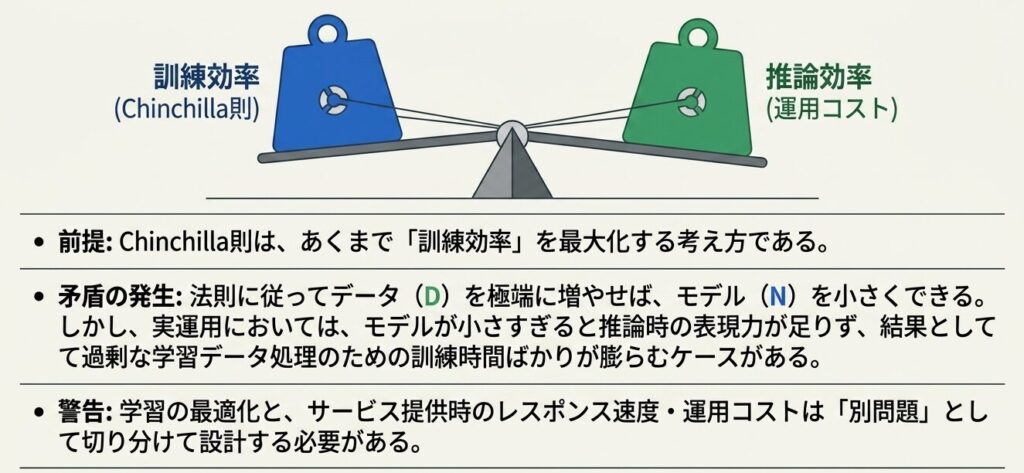
💡 Chinchilla Trap: Chinchilla 則に従って学習を最適化しても、推論時の運用コストが高くなる場合がある
7. よくある誤解は何か?
1. ただ大きくすればいいわけではないのか?
いいえ。Chinchilla 則が示したのは、計算資源を固定したときに、パラメータ数だけを増やしても最適にはならない場合がある、ということです。
2. データを増やせば必ず勝てるのか?
これも違います。データを増やすことは重要ですが、モデルサイズとのバランスが悪ければ、やはり効率は落ちます。
3. これは理論ではなく経験則なのか?
はい。Chinchilla 則は、現実の学習結果から導かれた実践的な指針です。だからこそ強い一方で、条件が変われば見え方も変わります。
8. 今回のブログの考察
Chinchilla 則が教えてくれるのは、LLM 開発では「どれだけ大きいモデルを作るか」よりも、「限られた予算をどう配るか」のほうが本質的な場合がある、ということです。今回の記事で見たように、同じ計算量でも、パラメータ数とデータ量の配分を変えるだけで結果が大きく変わります。これは、モデルの性能が単純な規模競争だけで決まらないことを、かなり具体的に示しています。
実務で大切なのは、この考え方を「大きいモデルは不要だ」と読み違えないことです。Chinchilla 則は小さいモデルを勧めているのではなく、与えた計算予算を最も効率よく使う配分を考えよう、と言っているにすぎません。だから、モデルサイズだけを見て判断するのではなく、データ量が足りているのか、推論コストまで含めて現実的か、という視点を持つ必要があります。
つまり、Chinchilla 則の価値は、単なる理論の発見ではなく、開発の判断基準を一段具体化したことにあります。経験則としてのスケール則を、そのまま現場の設計に落とし込むときに、N と D のバランスを考える習慣があるかどうかで、同じ予算でも結果はかなり変わります。
参考資料
- Hoffmann, J. et al. (2022). “Training Compute-Optimal Large Language Models.” arXiv:2203.15556
- Rae, J. et al. (2021). “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.” arXiv:2112.11446
このシリーズの案内
次の記事: A-5: スケール則の応用と実務的影響
前の記事: A-3: スケール則の証拠と信頼性

コメント