
Transformer モデルの計算効率は、理論式だけを見ていても実態がつかみにくいです。FLOPs そのものは大きくても、実際の処理速度はメモリバンド幅、通信オーバーヘッド、GPU の使い方でかなり変わります。
この記事では、A2 で整理した FLOPs の基本を前提に、理論値の計算方法と、実装上の計算効率の測り方をつなげて見ていきます。最後には、Attention と FFN で効率がずれる理由や、Flash Attention などの最適化がどこに効くのかも整理します。
セクション B-4: 計算効率の測定と最適化(FLOPs計算)
1. FLOPs の理論値と実測値はなぜずれるのか?
Transformer モデルの総計算量(FLOPs)は、以下の公式で計算されます。
$$C_{total} = 6ND$$
- $N$:パラメータ数
- $D$:訓練トークン数
- 係数 6:フォワード(2回のマトリクス演算)+ バックプロパゲーション(4回の演算)
この公式は学習量の見積もりには便利ですが、そのまま「実際の速さ」にはなりません。理論上は同じ FLOPs でも、Attention のようにメモリを多く読む処理と、FFN のように演算が中心の処理では、実際の速度がかなり変わるからです。

理論値は、スループットを保証しない。 この公式は学習量の「見積もり」には極めて有用。しかし、同じFLOPSであっても、メモリアクセスの頻度や通のオーバーヘッドにより、実際の処理速度は劇的に変動する。
2. 実装では何を測ればよいのか?
実装では、以下の要素が計算効率に影響します。
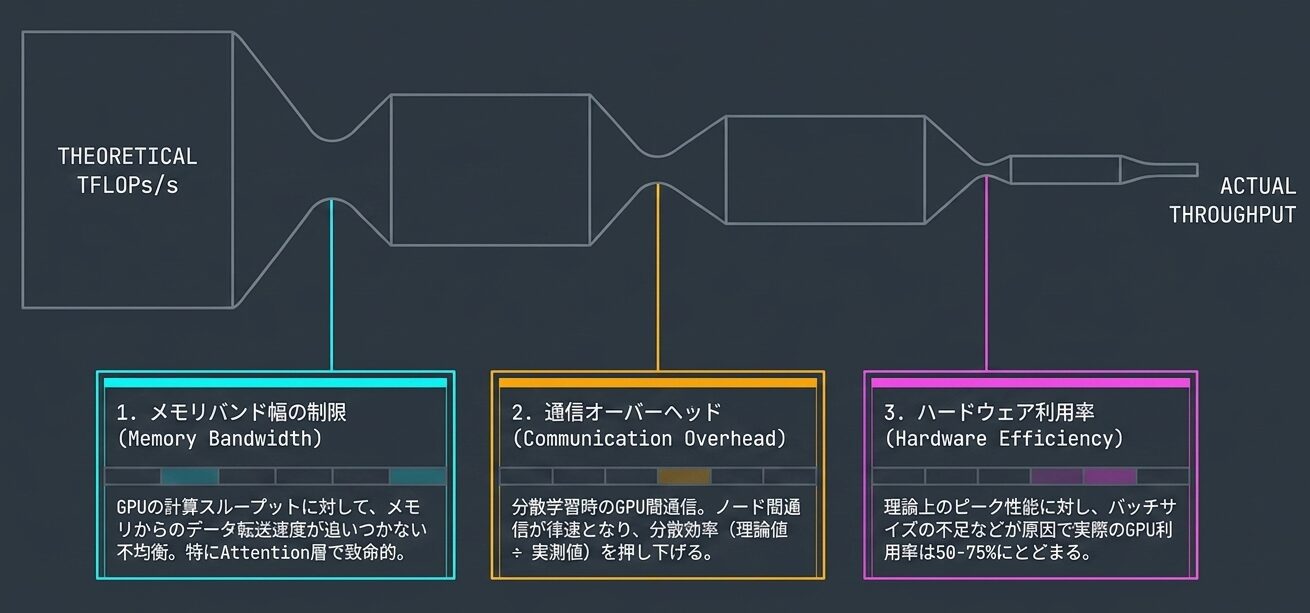
1. メモリバンド幅の制限
- GPU の計算スループット(TFLOPs/s)とメモリバンド幅(GB/s)の不均衡
- Attention 層は「メモリ集約的」(律速要因がメモリ I/O)
- FFN 層は「計算集約的」(律速要因が演算速度)

2. 通信オーバーヘッド
- 分散学習時の GPU 間通信(All-Reduce)
- 分散効率 = 理論値 / 実測値 で定量化
3. ハードウェア効率
- GPU 利用率が理論値の 50-75%
この章で大事なのは、理論値を否定することではありません。むしろ、理論値を起点にしながら、どこで実測が目減りするのかを切り分けることです。そこで次に、計算量を見積もり、実際のスループットを記録する最小例を置きます。
3. 実装例:FLOPs計算と効率測定
import torch
import torch.nn as nn
from typing import Tuple
import numpy as np
class TransformerFlopsCalculator:
"""Transformer モデルの FLOPs を計算・測定するクラス"""
def __init__(self, model_name: str):
self.model_name = model_name
self.measurements = {}
def calculate_flops(self, n_params: int, d_tokens: int,
n_layers: int, hidden_dim: int, vocab_size: int) -> dict:
"""理論値ベースの FLOPs計算"""
# 全体計算量(基本公式)
total_flops = 6 * n_params * d_tokens
# 詳細分解
forward_pass = 2 * n_params * d_tokens
backward_pass = 4 * n_params * d_tokens
# 層別計算
self_attention_flops = 2 * n_layers * d_tokens * (hidden_dim ** 2)
ffn_flops = 2 * n_layers * d_tokens * (4 * hidden_dim ** 2)
embedding_flops = 2 * d_tokens * vocab_size * hidden_dim
return {
'total_flops': total_flops,
'forward_flops': forward_pass,
'backward_flops': backward_pass,
'self_attention_flops': self_attention_flops,
'ffn_flops': ffn_flops,
'embedding_flops': embedding_flops,
'breakdown': {
'self_attention_ratio': self_attention_flops / total_flops,
'ffn_ratio': ffn_flops / total_flops,
'embedding_ratio': embedding_flops / total_flops,
}
}
def measure_actual_throughput(self, model: nn.Module,
batch_size: int, seq_len: int) -> dict:
"""実際のスループット測定"""
model_flops = sum(p.numel() for p in model.parameters())
efficiency_rates = {
'ideal': 1.0,
'with_overhead': 0.70,
'realistic': 0.50,
}
throughput = {}
for scenario, rate in efficiency_rates.items():
peak_tflops = 312.0 # A100 GPU
achieved_tflops = peak_tflops * rate
iter_flops = 6 * model_flops * batch_size * seq_len
iter_time = iter_flops / (achieved_tflops * 1e12)
throughput[scenario] = achieved_tflops
return {
'model_flops': model_flops,
'batch_size': batch_size,
'seq_len': seq_len,
'throughput_tflops': throughput,
}4. どの最適化がどこに効くのか?
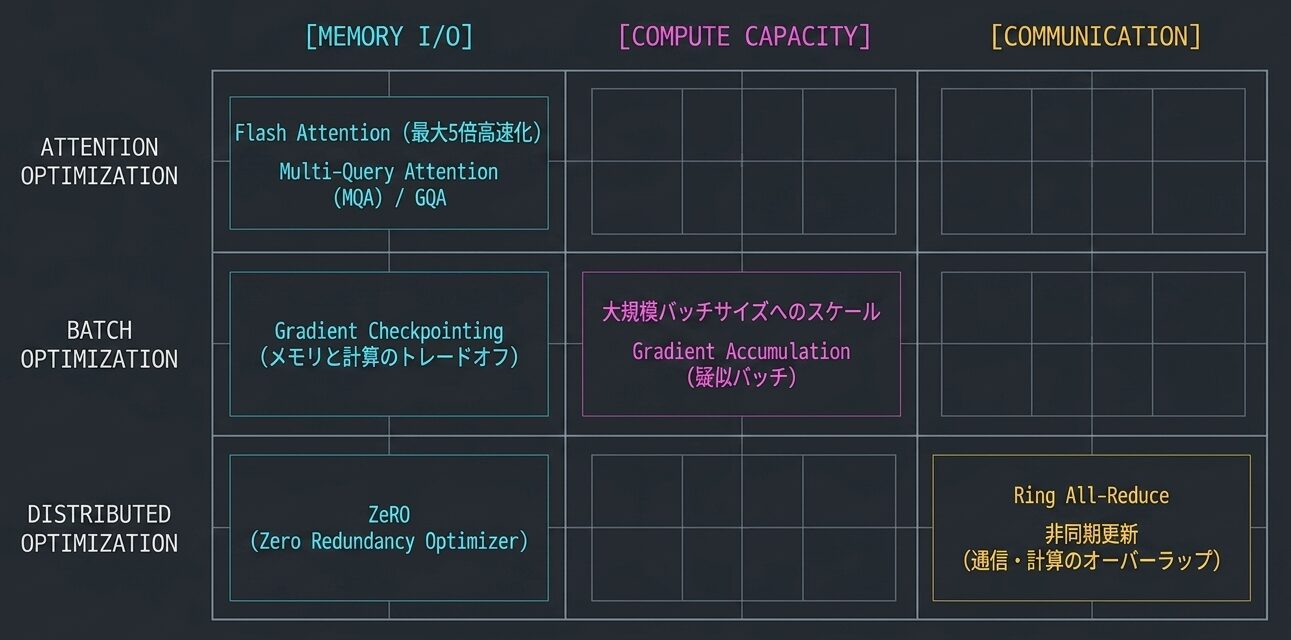
1. Attention 層の最適化
- Flash Attention:メモリ I/O を削減(最大 5 倍高速化)
- Multi-Query Attention (MQA):キャッシュサイズを削減
- Grouped Query Attention (GQA):品質と効率のバランス
MQA と GQAを 組み合わせて使うことで、KVキャッシュのサイズを根本から削減し、推論時のメモリバンド幅の圧迫を軽減することができる。
なぜFlash Attentionを使うのか?
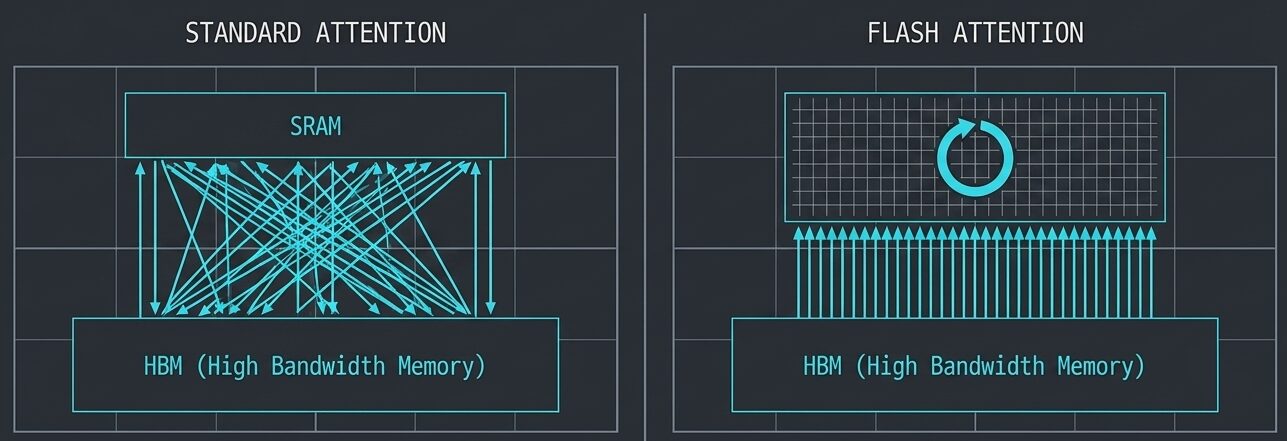
標準アテンションは、計算ごとにHBMとSRAM間でデータを何度も往復させるため、メモリI/Oがボトルネックになります。 一方、Flash Attentionはデータを「タイル化」し、高速なSRAM上で計算を完結させることでメモリ往復を抑制します。 同じ計算結果を保ちながらメモリ帯域の負荷を軽減し、効率的な処理高速化(最大5倍程度)が可能となるため、広く利用されています。
2. バッチ処理の最適化
- より大きいバッチサイズ(メモリが許す限り)
- Gradient Accumulation で疑似的にバッチサイズを増加
- Gradient Checkpointing で メモリ・計算のトレードオフ
Gradient Accumulation とは?
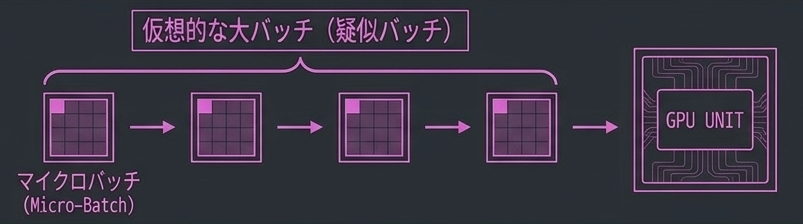
ハードウェア利用率を高めるため、メモリが許す限りバッチサイズを拡大。 不可能ならGradient Accumulationを適用し演算効率を引き上げる。
3. 分散学習の最適化
- All-Reduce アルゴリズムの選択(Ring All-Reduce)
- 非同期更新による通信・計算のオーバーラップ
- ZeRO(Zero Redundancy Optimizer)による メモリ削減
ZeRO & Ring All-Reduce とは?
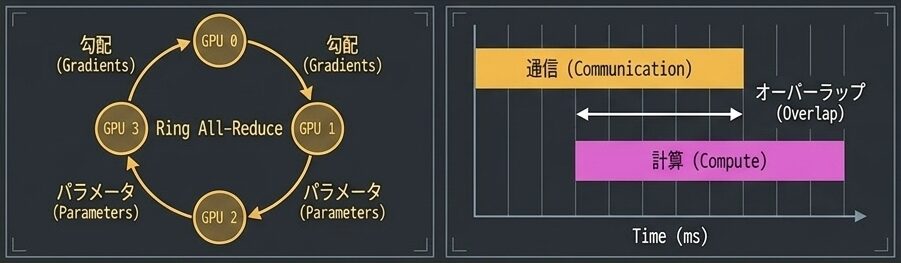
ZeROによる冗長なオプティマイザ 状態の分割でメモリを削減。さらに非同期更新によって通信時間と計算時間をオーバーラップさせ、通信の遅延を隠蔽する。
最適化ツールキットマップ
5. 環境ごとに効率はどう変わるのか?
| GPU | ピーク (TFLOPs) | 実効率(Attention) | 実効率(FFN) | 効率の差 |
|---|---|---|---|---|
| H100 | 989 | 450 (45%) | 750 (76%) | 1.67x |
| A100 | 312 | 140 (45%) | 240 (77%) | 1.71x |
| RTX 4090 | 165 | 75 (45%) | 130 (79%) | 1.73x |
| M1/M2 | 11 | 4 (36%) | 7 (64%) | 1.75x |
主な観察:
- Attention 層は常にメモリバンド幅に律される(~45%効率)
- FFN 層はより高い効率を達成(~75-80%)
- モダン GPU(H100)と モバイル GPU(M1)の効率差は実は小さい
ピーク性能の大小に関わらず、AttentionとFFNの実効効率の差は常に「約1.7倍」という普遍的な法則が存在する。 モダンGPUでもモバイルGPUでも、Attentionは常にメモリバンド幅に律される。
6. どんな失敗を避けるべきなのか?
計算効率の検証でよくある失敗は、FLOPs の理論値だけを見て「速くなったはずだ」と判断してしまうことです。実際には、同じ理論 FLOPs でも、バッチサイズが小さすぎれば GPU を十分に使えませんし、通信が重ければ分散学習の利点も薄れます。
もう一つの失敗は、Attention だけを見て全体を評価することです。Attention はメモリ律速になりやすく、FFN は比較的高い効率を出しやすいため、どちらか一方の数字だけでは全体像が分かりません。実務では、理論値、実測値、GPU ごとの差を一緒に見るほうが判断しやすいです。
7. どこから始めればよいのか?
最初の一歩は、難しい最適化をいきなり入れることではありません。今の学習ログに、理論 FLOPs と実測スループットを並べて記録することから始めるのがよいです。そこに Attention と FFN の差を足せば、どこがボトルネックかが見えやすくなります。
計算効率の最適化は、速くするためのテクニック集ではありますが、本質は「どこで無駄が出ているかを測ること」です。測定が曖昧なままだと、改善したように見えても実際にはほとんど変わっていない、ということが起こりやすいです。
8. まとめ
計算効率の測定と最適化(FLOPs計算)のプロセス
計算効率を測るときは、まず理論 FLOPs を押さえ、そのうえで実測スループットとの差を見るのが基本です。理論式だけでは、Attention のメモリ律速や分散通信の負荷までは見えませんし、逆に実測値だけを見ても、どこに無駄があるのかは切り分けにくいです。
今回の記事では、FLOPs の計算式、実装での測定方法、Flash Attention や GQA のような改善策、そして GPU ごとの効率差をまとめて見ました。要点は、計算効率は単なる速度の話ではなく、ボトルネックを特定して改善順序を決めるための指標だということです。
9. 今回のブログの考察
計算効率の話は、単に GPU を速く使うための話ではありません。今回の記事で見たように、本当に重要なのは、理論上の計算量と実際の処理速度の差を前提にして設計することです。FLOPs が大きいから遅い、という単純な話でもなければ、理論式だけで全てを説明できるわけでもありません。
実務でこの差を意識しないまま進めると、学習時間の見積もりが外れたり、最適化したつもりで別の箇所が詰まっていたりします。逆に、Attention、FFN、通信、メモリのどこで効率が落ちているかを切り分けられると、改善策の優先順位がかなり明確になります。Flash Attention やバッチサイズの調整、分散方式の見直しは、その切り分けができて初めて意味を持ちます。
つまり、この章の本質は「計算量を知ること」ではなく、「計算量を現実の実行環境に落としたとき、どこで目減りするのかを測ること」にあります。そこを押さえておくと、スケーリング則の議論が机上の計算で終わらず、実装の判断に直結するようになります。
参考文献
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” OpenAI.
- Dao, T., et al. (2022). “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.”
このシリーズの案内
- B-3: パラメータ配分最適化
- B-5: スケール則の限界と例外
- A-2: FLOPsと計算資源の理解 – FLOPs基礎概念

コメント