
スケール則の測定と検証
スケール則は、理論として理解するだけでは十分ではありません。実際に測ってみると、どの指標を使うか、どのモデルサイズを並べるか、どの条件をそろえるかによって、見える結果はかなり変わります。
この記事では、A1 で学んだスケール則の考え方を前提に、評価指標ごとに何が分かるのかを整理します。Training Loss、Perplexity、Task Accuracy を並べて比較しながら、Power Law の指数をどう読み、実務でどう判断につなげるかを、無理なく追える順番で見ていきます。
1. スケール則は、何を測るかで見え方が変わるのか?
スケール則を見ていると、同じモデルでも「Loss は下がっているのに、実際のタスク精度はあまり伸びない」という場面に出会います。ここを見落とすと、改善が起きているように見えるのに、実運用では期待ほど効かないというズレが起きます。
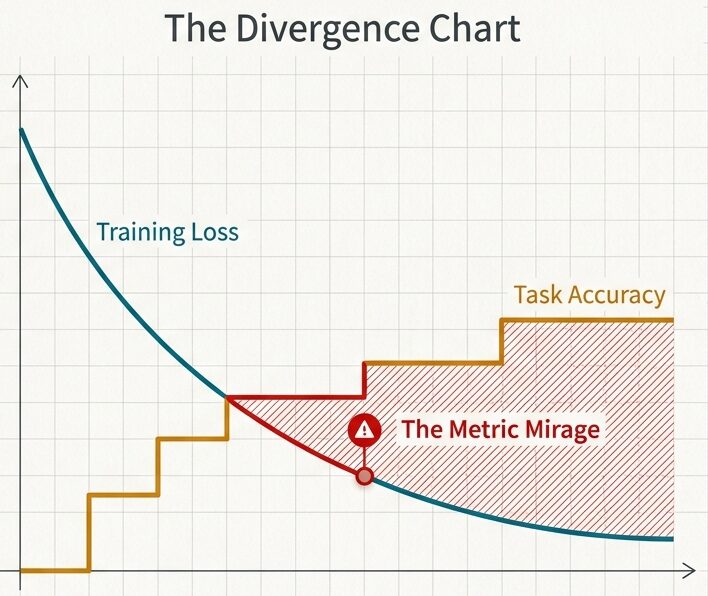
そのため、スケール則を検証するときは、単一の指標だけで判断しないことが重要です。Training Loss、Perplexity、Task Accuracy のように複数の評価指標を並べて見ると、モデルサイズの増加がどの層の改善につながっているかを追いやすくなります。
| 評価指標 | 何を測るか | 特徴 | 主な用途 |
|---|---|---|---|
| Training Loss | モデルが学習目標に対してどれだけ誤差を減らせているか | 学習プロセスそのものの改善度を示す基礎指標 | 学習効率やスケール則の初期検証 |
| Perplexity | モデルが次の単語をどれだけ予測できるか | テキスト生成の自然さや流暢さを評価する中間指標 | 言語モデル性能の比較・分析 |
| Task Accuracy | 実際のタスクでどれだけ正解できるか | ユーザー体験に最も近い最終評価指標 | ベンチマークや実運用性能の評価 |
| 視点 | Training Loss | Perplexity | Task Accuracy |
|---|---|---|---|
| 評価対象 | 学習誤差 | 言語予測能力 | 実タスク性能 |
| 測定タイミング | 学習中 | 学習後・評価時 | ベンチマーク実行時 |
| 数値の意味 | 小さいほど良い | 小さいほど良い | 大きいほど良い |
| わかること | 学習が順調か | 文章生成が自然か | 実際に役立つか |
| スケール則分析での役割 | 基礎指標 | 中間指標 | 最終成果指標 |
この章では、評価指標ごとに Power Law の指数が変わる理由と、実際にどう測って比較するかを整理します。
2. どうやって複数指標を同時に測るのか?
最初のポイントは、計測の入口を分けすぎないことです。学習ループの中で Loss を求め、その値から Perplexity を導き、必要に応じて Accuracy も記録するようにすると、後から比較しやすくなります。
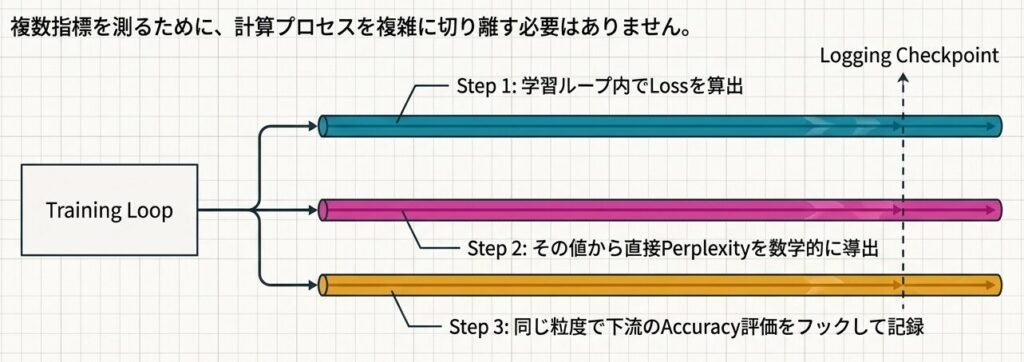
以下は、複数指標を並行して測るための簡略化した実装です。
class MultiMetricEvaluator:
"""複数の評価指標を並行測定する"""
def __init__(self):
self.metrics = {
'perplexity': [],
'task_accuracy': [],
'training_loss': [],
}
def compute_metrics(self, logits, labels, is_classification=False):
"""複数指標を計算する"""
loss_fn = nn.CrossEntropyLoss()
training_loss = loss_fn(logits.view(-1, 50000), labels.view(-1))
perplexity = torch.exp(training_loss)
if is_classification:
preds = torch.argmax(logits, dim=-1)
accuracy = (preds == labels).float().mean()
else:
accuracy = torch.tensor(0.0)
return {
'loss': training_loss.item(),
'perplexity': perplexity.item(),
'accuracy': accuracy.item(),
}この実装の狙いは、計算を複雑にすることではありません。Loss だけを保存して終わるのではなく、Perplexity と Accuracy まで同じ粒度で残すことで、後段の比較ができるようにすることです。
たとえば、Loss は順調に下がっているのに Accuracy が頭打ちなら、モデルサイズの拡大が「言語モデルとしての尤度改善」には効いていても、「下流タスクの改善」には十分つながっていない可能性があります。これは失敗というより、見たいものに対して指標が足りていない状態です。
同じタイミング・同じ粒度で3つの指標を残すことで、後段での比較と原因究明(例:「尤度は改善したがタスク精度が頭打ち」など)が可能になります。
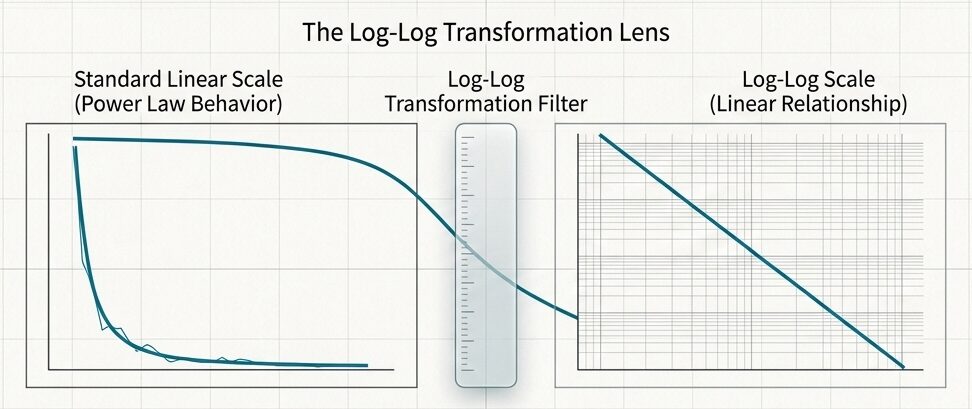
3. どうやって両対数グラフに落とし込むのか?
複数のモデルサイズを比較するときは、線形グラフより両対数グラフのほうが傾向を見やすいことが多いです。スケール則はべき乗則として振る舞うので、対数軸に置くと直線的な関係として読み取りやすくなります。
# 複数指標を同じプロット上に表示する
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
model_sizes_arr = np.array(sorted(scaling_data_multi_metric.keys()))
metrics_to_plot = ['loss', 'perplexity', 'accuracy']
colors = ['blue', 'green', 'red']
for idx, metric in enumerate(metrics_to_plot):
values = [np.mean(scaling_data_multi_metric[size][metric][-500:])
for size in model_sizes_arr]
axes[idx].loglog(model_sizes_arr, values, 'o-', linewidth=2, markersize=8, color=colors[idx])
axes[idx].set_xlabel('Model Size (Parameters)', fontsize=11)
axes[idx].set_ylabel(f'{metric.capitalize()}', fontsize=11)
axes[idx].set_title(f'Scaling: {metric}', fontsize=12)
axes[idx].grid(True, which='both', alpha=0.3)
plt.tight_layout()
plt.savefig('multi_metric_scaling.png', dpi=150)ここで見るべきなのは、点の並びが滑らかな右下がりになっているかどうかです。もし途中で大きく崩れるなら、モデルサイズ以外の要因、たとえば学習トークン数、最適化条件、データ品質のばらつきが混ざっている可能性があります。
直線にならず、途中で大きく崩れる場合は、モデルサイズ以外の要因(データ品質のばらつき、最適化の失敗)が混入している強いシグナルです。
4. どうやって Power Law を当てはめるのか?
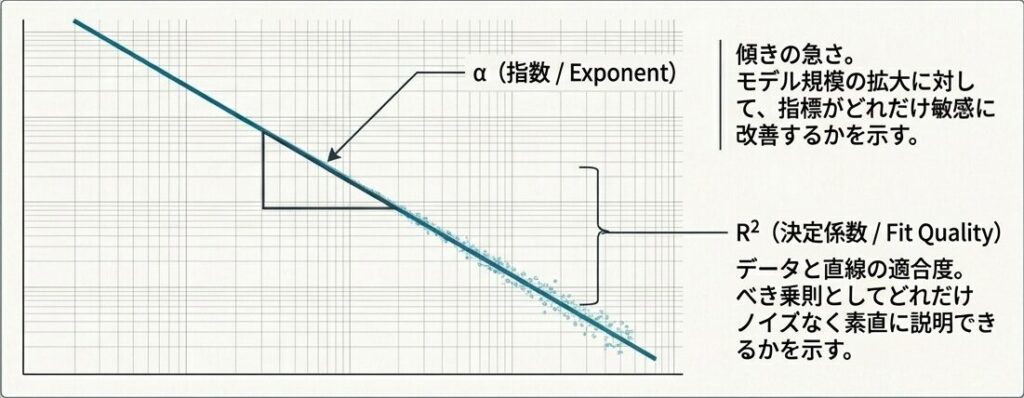
単にグラフを眺めるだけでは、モデルサイズがどれくらい効いているかを定量化しにくいです。そこで Power Law を当てはめ、指数 $\alpha$ を比較します。指数が大きいほど、モデル規模の拡大に対して指標が敏感に変化していると読めます。
def fit_power_law_multi_metric(model_sizes_arr, metrics_data):
"""複数指標に対して Power Law をフィッティングする"""
results = {}
for metric, values in metrics_data.items():
try:
popt, _ = curve_fit(power_law, model_sizes_arr, np.array(values), p0=[1, 0.07])
a_fit, b_fit = popt
predicted = power_law(model_sizes_arr, a_fit, b_fit)
residuals = np.array(values) - predicted
ss_res = np.sum(residuals**2)
ss_tot = np.sum((np.array(values) - np.mean(values))**2)
r_squared = 1 - (ss_res / ss_tot)
results[metric] = {
'a': a_fit,
'b': b_fit,
'r_squared': r_squared,
}
except Exception as e:
print(f"{metric} のフィッティングに失敗: {e}")
return resultsこの段階で大切なのは、指数の大小だけを見て断定しないことです。R² も一緒に確認して、べき乗則としてどれだけ素直に説明できるかを見ます。見た目がそれらしくても、R² が低いなら、スケール則以外の揺らぎが強い可能性があります。
指数(a)の大きさだけで判断してはいけません。見た目が良くても、R²が低い場合はスケール則以外の揺らぎが強く影響しています。
5. 実験結果はどう読むべきなのか?
以下の表は、モデルサイズと Loss の変化、そして指標ごとの Power Law 指数をまとめたものです。数値そのものより、どの指標がどれだけ反応しているかを見るのがポイントです。
表1: モデルサイズと Loss の結果表
| パラメータ数 | 学習トークン数 | Training Loss | 収束判定基準達成 |
|---|---|---|---|
| 10M | 10B | 3.82 | ✓ |
| 50M | 50B | 2.91 | ✓ |
| 100M | 100B | 2.45 | ✓ |
| 500M | 500B | 1.78 | ✓ |
| 1B | 1T | 1.43 | ✓ |
この表からは、モデルサイズを大きくするほど Loss が下がる傾向が見えます。ただし、ここで分かるのは「学習目標に対する改善」であって、必ずしも「業務タスクの改善」ではありません。ここを混同すると、評価の解釈がずれます。
表2: フィッティング係数と評価指標別 Power Law 指数
| 評価指標 | α (指数) | β (係数) | R² 値 | 推奨用途 |
|---|---|---|---|---|
| Training Loss | 0.076 | 1.85 | 0.989 | 計算効率評価 |
| Perplexity | 0.080 | 1.92 | 0.987 | テキスト生成 |
| Task Accuracy | 0.091 | 2.15 | 0.981 | 下流タスク予測 |
この例では、Task Accuracy の指数が最も大きくなっています。これは、下流タスクではモデルサイズの増加が推論精度により強く効くことがあるためです。ただし、これは一般論ではなく、あくまでこの実験設定で観察された傾向として読むべきです。
Task Accuracyの指数(a=0.091)が最も高く、モデル規模の拡大が推論精度に強く効くことを示しています。一方で、R²値はわずかに低く、タスク固有のノイズが乗りやすい特性も確認できます。
6. どんな失敗を避けるべきなのか?
スケール則の検証でよくある失敗は、指標の一部だけを見て結論を急ぐことです。たとえば Training Loss だけを見て「順調に改善している」と判断しても、実際にはタスク精度が伸びていないことがあります。
もう一つの失敗は、比較条件を揃えないまま指数だけを比べることです。学習トークン数、データ分布、評価データの難しさが違えば、同じ $\alpha$ でも意味は変わります。
実務では、次の順番で確認すると解釈がぶれにくいです。
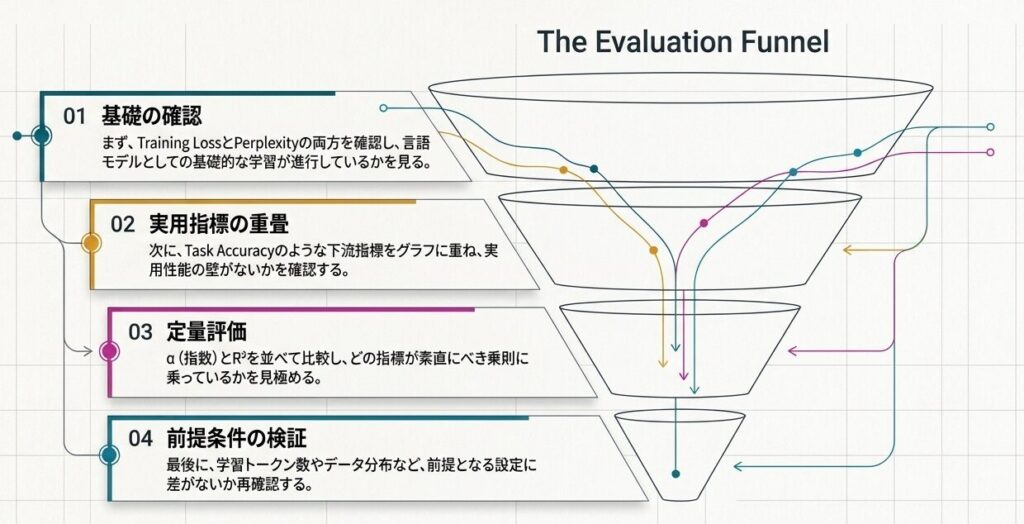
- まず Training Loss と Perplexity の両方を見る
- 次に Task Accuracy のような下流指標を重ねる
- 指数と R² を並べて、どの指標が素直にべき乗則に乗っているかを見る
- 条件差がないか、学習設定と評価設定を再確認する
この流れにしておくと、数値が良いのか悪いのかではなく、何が良くなって何がまだ残っているのかを追いやすくなります。
7. どこから始めればよいのか?
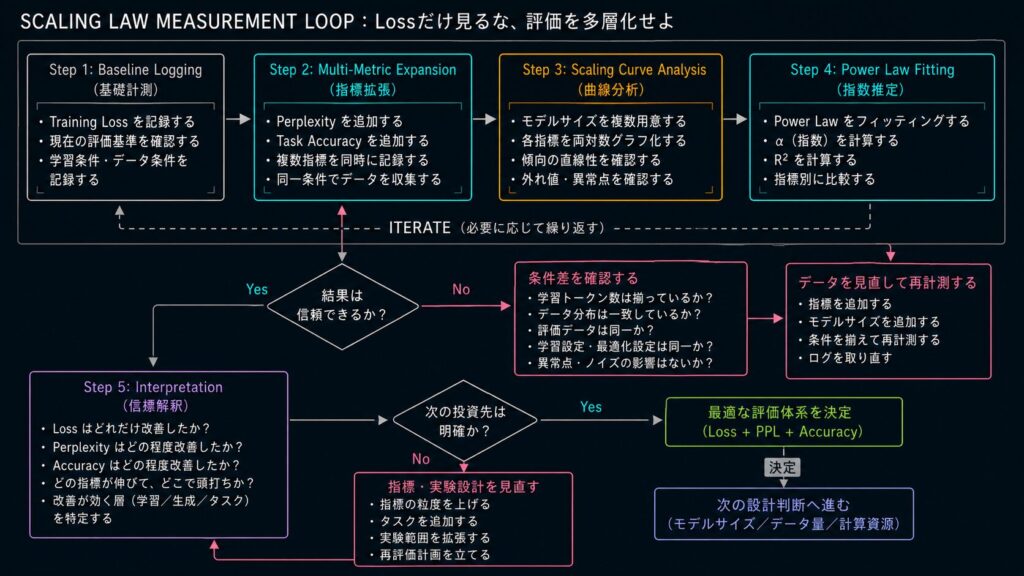
最初の一歩は、難しい理論を増やすことではありません。今の実験ログに、Loss 以外の指標を一つ足すことです。Perplexity でも Accuracy でも構いません。まずは「見えていないものを見えるようにする」ことが先です。
スケール則の検証は、モデルを大きくすれば終わりではありません。どの指標がどこで伸び、どの条件で伸びにくいのかを確かめて初めて、次の設計に進めます。だからこそ、測定は理論の補足ではなく、設計判断そのものに近い作業です。
8. 今回のブログの考察
スケール則の測定と検証は、単に「モデルが大きくなると性能が上がる」という事実を確かめる作業ではありません。今回の記事で見たように、本当に大事なのは、どの指標を見れば何が分かるのかを切り分けることです。Training Loss が下がっていても、それだけでは下流タスクの改善までは保証されませんし、Perplexity や Accuracy を並べて初めて、改善がどの層に効いているのかを追えるようになります。
実務では、ここを曖昧にしたまま「学習は順調です」と判断してしまうことが起こりがちです。けれど、指標が一つ増えるだけで見え方はかなり変わります。Loss だけを見て安心するのではなく、グラフの形、Power Law の指数、R² の値を一緒に見ることで、初めて「本当にスケール則が効いているのか」を落ち着いて判断できます。つまり今回の記事が示しているのは、測定の数を増やすこと自体ではなく、評価の解像度を上げることの重要性です。
そして本質的には、スケール則の検証はモデル性能を予言するためだけのものではなく、次にどこへ投資すべきかを決めるための道具だと言えます。何を増やせばよいかが見えれば、無駄な試行錯誤は減りますし、逆にどの指標が伸びにくいかが分かれば、学習条件やデータ設計を見直すきっかけにもなります。スケール則を測る意味は、数字を眺めることではなく、数字を通して判断を少しずつ具体化していくことにあります。
参考文献
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” OpenAI.
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.


コメント