
スケール則を実装する – 基本フロー
スケール則は、理論として理解するだけでは十分ではありません。実際に手を動かしてみると、どのサイズで試すか、何を記録するか、どの指標で比較するかによって、見える結果がかなり変わります。
この記事では、A1 で学んだスケール則の考え方を、実装の現場でどう扱うのかに絞って整理します。小規模実験の設計から、複数モデルサイズでの比較、両対数グラフへの可視化、直線フィッティング、外挿予測までを、無理なく追える順番で見ていきます。
1. この記事で学べること
- スケール則を実装するときの基本フロー
- 小規模実験をどう設計すべきか
- 複数モデルサイズをどう比較するか
- 両対数グラフと直線フィッティングをどう読むか
- 外挿予測をどこまで信じてよいか
2. なぜ、実装フローを先に決めるのか?
スケール則の検証でよくある失敗は、いきなり大きなモデルを走らせてしまうことです。これは一見まっすぐなやり方に見えますが、実際にはかなり危険です。学習が終わるまで時間がかかるうえ、比較の基準が曖昧だと、結果が出ても何を学べたのか分かりにくくなるからです。
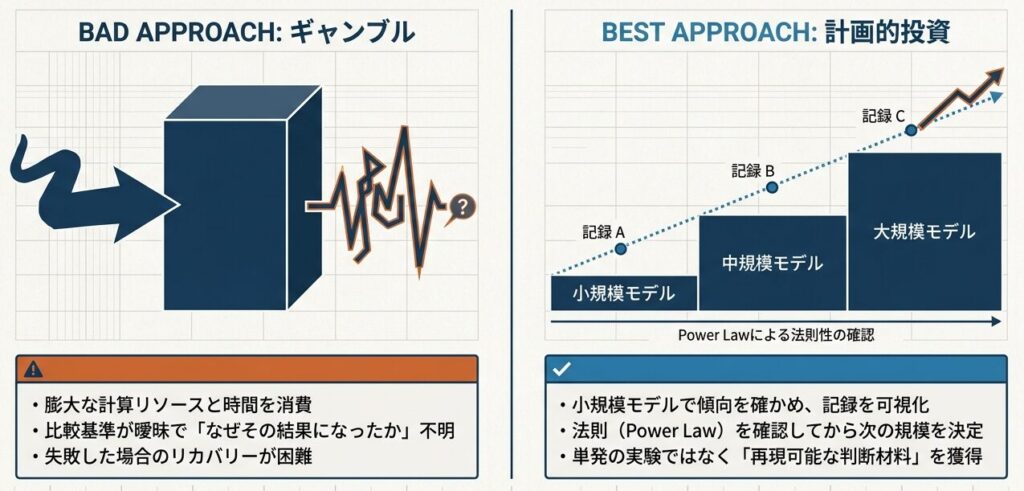
そこで必要になるのが、先に実装フローを決めることです。小さく試し、記録し、可視化し、傾向を見てから次の規模を決める。この順番にするだけで、実験はかなり整理されます。
実務的には、次のような考え方が分かりやすいです。
- まず小規模モデルで傾向が見えるか確かめる
- 次に複数サイズで同じ条件のまま比較する
- 最後に両対数グラフで Power Law の形を確認する
この流れがあると、単発の実験結果ではなく、再現可能な判断材料として扱いやすくなります。
3. まず何を設計するべきか?
最初に決めるべきなのは、モデルの大きさではなく、比較の条件です。ここが曖昧だと、後でどれだけ高価な実験をしても、解釈がぶれてしまいます。
特に大事なのは次の 3 つです。
- どのモデルサイズを試すか
- どの学習設定を固定するか
- どの指標を記録するか
たとえば、10M、50M、100M、500M のように段階をそろえておけば、サイズの違いによる変化を比較しやすくなります。逆に、モデルサイズだけ変えてバッチサイズや学習率まで変えてしまうと、どの要素が効いたのか分からなくなります。
ここでのポイントは、華やかな実験をすることではありません。あとから説明できる実験にすることです。
4. 複数モデルサイズで何を見ればよいのか?
スケール則の検証では、複数サイズのモデルを同じ条件に近い形で学習させ、Loss の変化を記録します。大事なのは、1 回の最終スコアだけを見るのではなく、学習の過程を追うことです。
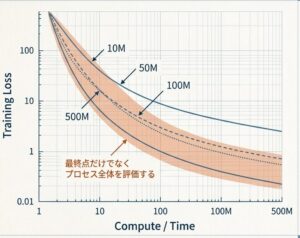
実際には、次のような観点で記録すると分かりやすいです。
- 学習がどれくらい安定して進んだか
- 小さいモデルと大きいモデルで Loss の落ち方が違うか
- 同じ学習時間でどのサイズが最も効率よく改善したか
ここで注意したいのは、Validation Loss だけで判断しないことです。スケール則の傾向を見るときは、まず Training Loss の変化がどのような形になるかを確認したほうが、法則性を追いやすいです。
よくある失敗
小さいモデルだけで「良さそう」と判断してしまうと、後で大きなモデルにしたときに傾向が崩れることがあります。逆に、最初から大きすぎるモデルを選ぶと、学習が重すぎて比較の材料が足りなくなります。
だからこそ、複数サイズを並べる意味があります。1 つの成功例ではなく、サイズが変わったときの変化を見ることが、スケール則実装の中心です。
5. 両対数グラフで何が見えるのか?
スケール則が実装上で分かりやすくなる瞬間は、両対数グラフにプロットしたときです。通常のグラフでは曲線に見えていたものが、両対数にすると直線に近づくことがあります。
これは、性能改善が単なる偶然ではなく、べき乗則に従っている可能性を示します。A1 で見た「規模を上げると損失が予測可能に下がる」という話が、ここで目に見える形になります。
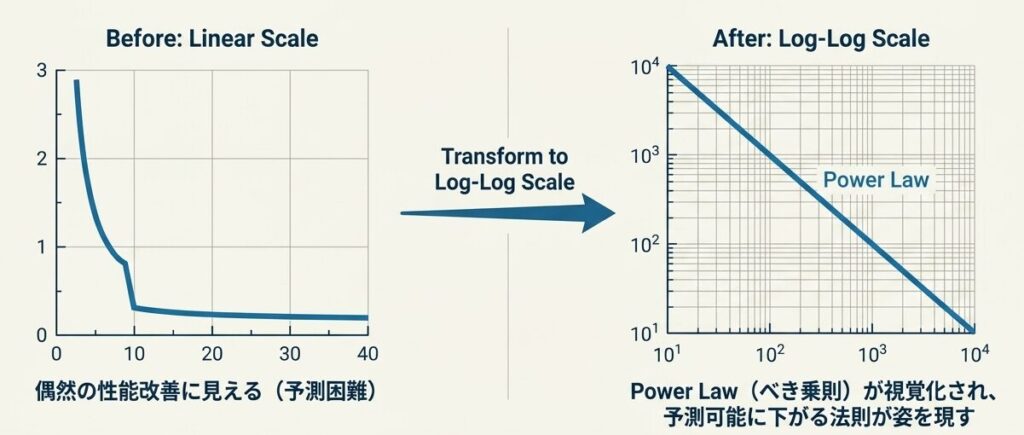
読み方のコツ
- 直線に近いほど、Power Law の説明がしやすい
- 傾きが急なら、サイズ増加の効果が大きい可能性がある
- 点が大きく乱れるなら、データや学習条件を見直したほうがよい
ただし、きれいな直線が出たからといって、すぐに未来の大規模モデルまで完全に予測できるわけではありません。ここは A3 の内容ともつながりますが、あくまで「傾向を見積もりやすい」というのが正確な言い方です。
直線の傾きが急なほど、サイズ増加による改善効果が大きいことを意味する。
6. 直線フィッティングは何のために行うのか?
両対数グラフで傾向が見えたら、次は直線フィッティングを行います。これは、見た目の印象を数値化する作業です。
Power Law の形に当てはめると、モデルサイズと Loss の関係を次のような式で表せます。
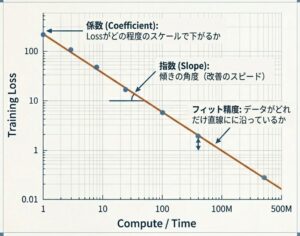
- Loss がどの程度の係数で下がるか
- 指数がどのくらいの傾きになるか
- フィットの精度がどれくらい高いか
この段階で大事なのは、指数そのものを暗記することではありません。実務では、指数の値よりも、その傾向が十分に安定しているかを確認するほうが重要です。
ありがちな読み違い
フィットがうまくいったからといって、どんなサイズにも同じ規則がそのまま続くとは限りません。学習データの質やアーキテクチャが変われば、傾きも変わる可能性があります。
つまり、直線フィッティングは「答えを出す」ためというより、「どこまで説明できるかを見極める」ための手順です。
7. 外挿予測はどこまで使えるのか?
最後のステップは、フィッティングした結果を使って、まだ試していないサイズの性能を予測することです。これが外挿予測です。
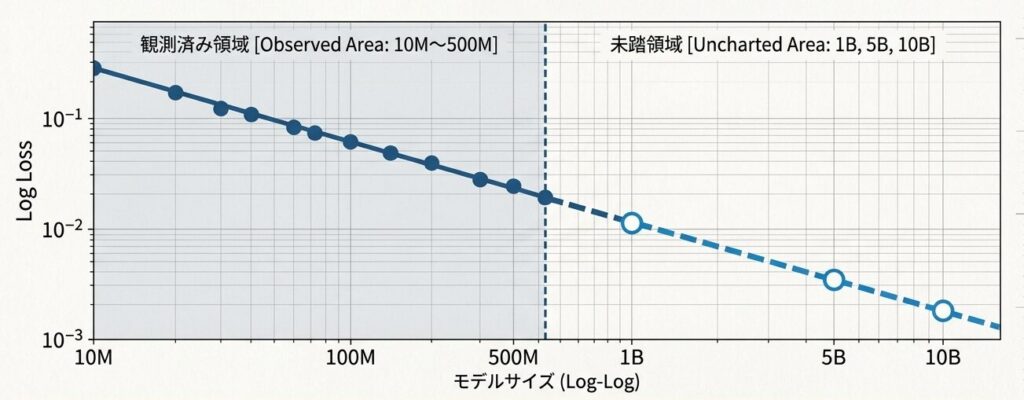
たとえば、500M パラメータまでしか試していなくても、その先の 1B、5B、10B 規模での Loss をある程度見積もれます。ここで役立つのは、学習を始める前に「どこまで伸びそうか」を把握できることです。
ただし、注意が必要です
外挿予測は便利ですが、未来を保証するものではありません。予測がうまくいくのは、これまでと同じ条件が大きくは変わらないときです。つまり、前提条件が同じまま維持されて初めて、外挿予測は成立するということです。
次のような条件が変わると、予測はずれやすくなります。
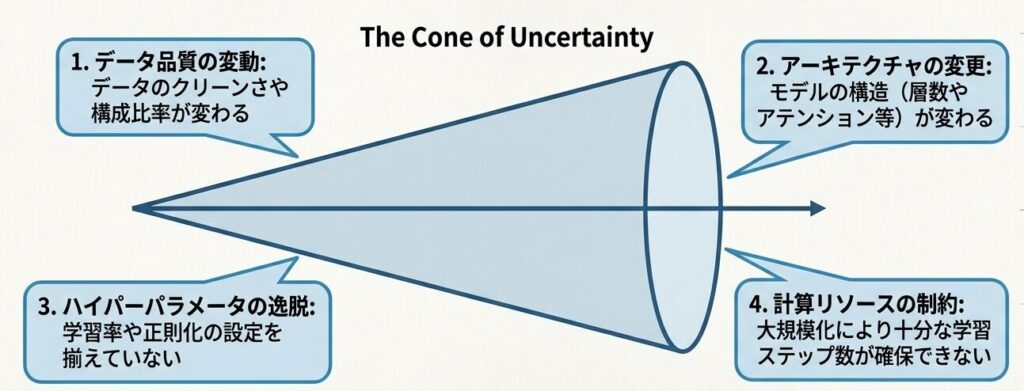
- データ品質が変わる
- モデルアーキテクチャが変わる
- 学習率や正則化の設定が大きく変わる
- 計算制約が厳しくなり、十分な学習ができない
外挿予測は「未来の絶対的な答え」ではない。次に多大な計算資源を投じて大きなサイズを試す価値があるかどうかを判断するための「強力な投資材料」である。
8. 実装では何を確認すべきなのか?
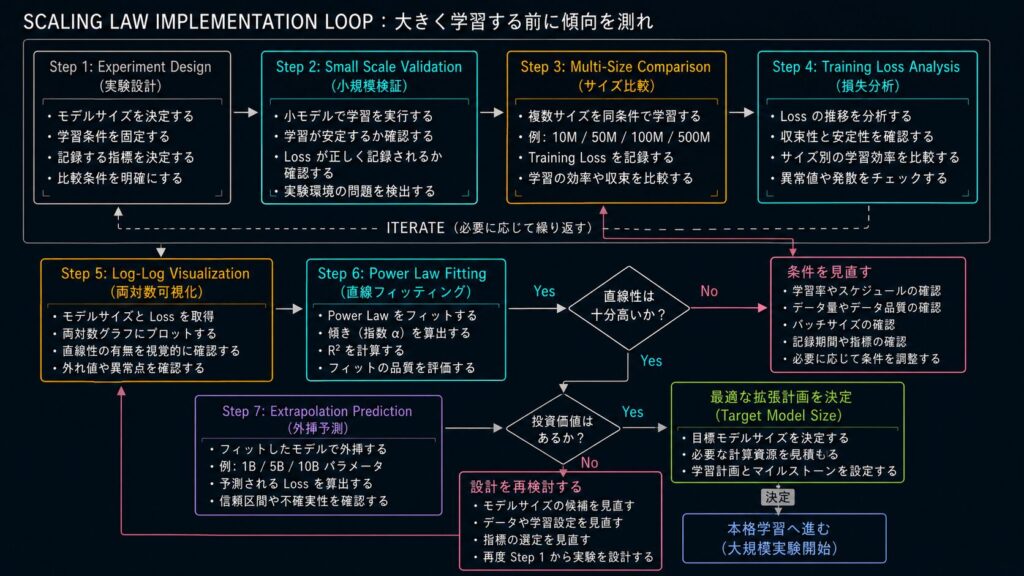
実装段階での確認は、派手なテクニックよりも地味なチェックの積み重ねです。ここを省くと、結果の解釈が一気に不安定になります。
最低限、次の点は確認しておきたいです。
- GPU メモリが足りているか
- 学習が途中で発散していないか
- Loss が十分な期間にわたって記録されているか
- 同じ条件で複数サイズを比較しているか
- Validation の変化と Training Loss の変化を混同していないか
特に、スケール則の初期検証では「比較条件をそろえること」が最優先です。条件がばらつくと、どんなに丁寧に実験しても、見えてくるのはノイズだけになりやすいです。
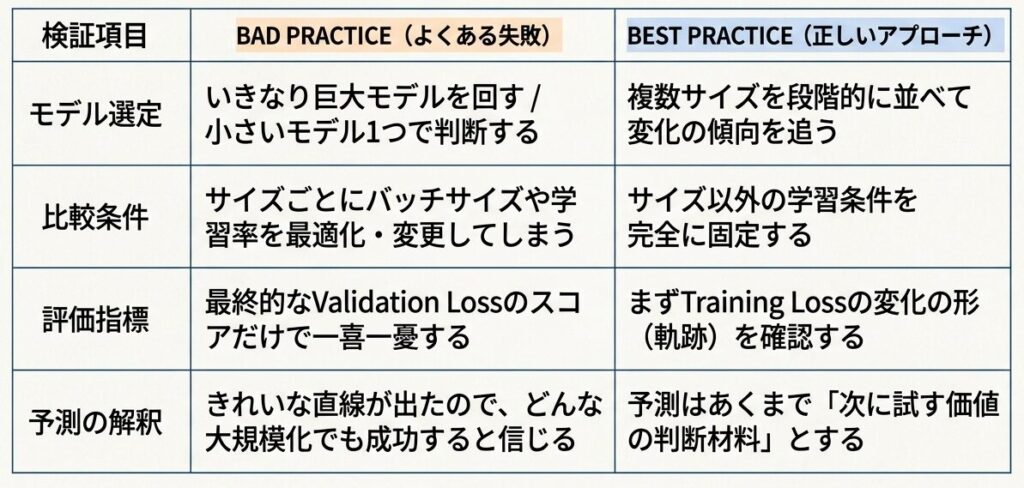
実装における「よくある失敗」と「正しいアプローチ」
9. 今回のブログの考察
スケール則を実装する意味は、理論をコードに落とし込むことそのものより、判断の筋道を作ることにあります。小規模実験から始め、複数サイズで比較し、両対数グラフで傾向を確認し、必要なら外挿する。この流れを持つだけで、モデル開発はかなり再現性のある仕事になります。
実務では、最初から大規模実験に飛びつきたくなることがあります。けれど、実際に効くのは、その前段階でどれだけ見通しを作れるかです。どのサイズで何を測るかを明確にしておくと、学習後に「何が分かったのか」を説明しやすくなります。
つまり、B1 の本質は、スケール則を実装するための手順書であると同時に、試行錯誤を意味のある比較に変えるための考え方にあります。見た目は単純な流れでも、比較条件をそろえ、記録を残し、傾向を読むという基本を丁寧に積み上げることが、結局いちばん強いです。
参考文献
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” OpenAI.
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.
- PyTorch Documentation: https://pytorch.org/docs/
このシリーズの案内
次の記事: B-2: スケール則の測定と検証
前の記事: A-6: 用語集と基礎知識


コメント