前回までは、スケーリング則をどう実装し、推論や位置エンコーディングまで含めてどう運用するかを見てきました。ここからのブログ C では、もう一段実務寄りに進みます。テーマは「限られた計算予算を、モデルサイズとデータ量へどう配分するか」です。
LLM 開発では、予算が増えるとつい「より大きなモデルを作る」方向へ進みたくなります。大きなモデルは分かりやすく強そうに見えますし、社内説明もしやすいからです。けれど、同じ計算量を使うなら、モデルを大きくするより、データ量を増やしたほうが良い局面があります。
この考え方を強く印象づけたのが Chinchilla 則です。この記事では、Gopher と Chinchilla の比較を入口に、固定計算予算下でなぜ U カーブが生まれるのか、D ≈ 20N をどう解釈すべきか、実務でどこまで信じてよいのかを整理します。
1. なぜ最適配分を考える必要があるのか?
LLM の性能改善では、モデルサイズ、データ量、計算量の 3 つがよく登場します。このうち計算量は、現実にはほぼ予算です。GPU 時間、電力、開発期間、再実験の余力まで含めると、使える計算量には必ず上限があります。
問題は、その限られた計算量をどこに使うかです。
たとえば、同じ計算予算で次の 2 つの選択肢があるとします。
- 大きなモデルを、相対的に少ないトークンで学習する
- 小さめのモデルを、より多くのトークンで学習する
直感だけで考えると、前者を選びたくなります。パラメータ数が大きいほうが、能力の上限も高そうに見えるからです。しかし、学習データが足りないと、その大きな容量を十分に使えません。逆に、データが大量にあってもモデルが小さすぎると、データに含まれるパターンを吸収しきれません。
つまり最適配分とは、「モデルを大きくするか、データを増やすか」のバランス問題です。ここを間違えると、同じ計算量を使っているのに、得られる性能が大きく変わります。
2. Gopher と Chinchilla は何を示したのか?
Chinchilla 則を理解するうえで重要なのが、DeepMind の Gopher と Chinchilla の比較です。
Gopher は 2021 年に発表された 280B パラメータ規模の大規模言語モデルです。当時として非常に大きなモデルであり、多くのタスクで強い性能を示しました。一方で、Chinchilla の研究では「既存の大規模モデルは、計算量の割に学習トークンが少なく、十分に訓練されていないのではないか」という問題意識が示されました。
そこで DeepMind は、Gopher とほぼ同等の学習計算量で、より小さい 70B パラメータの Chinchilla を、より多い約 1.4T トークンで学習しました。結果として、Chinchilla は多くの評価で Gopher を上回りました。特に MMLU では、Gopher より 7 ポイント以上高い平均精度が報告されています。
ここで重要なのは、「Chinchilla は単に小さいモデルだった」のではなく、「同じ計算予算の使い方を変えた」という点です。
| 観点 | Gopher | Chinchilla |
|---|---|---|
| 発表 | 2021 年 | 2022 年 |
| パラメータ数 | 280B | 70B |
| 学習トークン数 | 約 300B | 約 1.4T |
| 学習計算量 | ほぼ同等 | ほぼ同等 |
| 解釈 | モデルサイズ寄り | データ量とのバランス重視 |
この比較から得られる教訓は明確です。同じ計算予算でも、モデルサイズに寄せすぎると、データ不足で性能を取り切れない場合があります。
3. Chinchilla 則とは何か?
Chinchilla 則の中心にあるのは、固定された学習計算量のもとでは、モデルサイズ N と学習トークン数 D をバランスよく増やすべきだという考え方です。
論文では、損失をおおまかに次のように分けて考えます。
$$ L(N, D) = L_\infty + \frac{A}{N^\alpha} + \frac{B}{D^\beta} $$
ここで、N はパラメータ数、D は学習トークン数です。第 2 項はモデルが小さいことによる限界、第 3 項はデータが少ないことによる限界を表します。
また、Transformer の学習計算量は、ざっくり次のように近似されます。
$$ C \approx 6ND $$
つまり、計算予算 C が固定されているとき、N を増やすと D を減らさざるを得ません。逆に、D を増やすと N を小さくする必要があります。
Chinchilla 則の実務的な目安としてよく引用されるのが、次の関係です。
$$ D \approx 20N $$
これは、「パラメータ 1 個につき、およそ 20 トークンで学習する」という意味です。たとえば 1B パラメータなら、20B トークン程度が一つの目安になります。
ただし、これは絶対法則ではありません。学習計算量だけを最適化する場合の目安であり、推論コスト、データ品質、ドメイン特化、再利用回数を含めると、最適点は変わります。
4. U カーブはなぜ生まれるのか?
固定計算予算のもとで N と D の比率を変えると、損失は U 字に近い形を取ります。
左側では、モデルが小さすぎます。データは十分あっても、モデル容量が足りないため、複雑なパターンを学びきれません。
右側では、モデルが大きすぎます。パラメータは多いのに、学習トークンが足りないため、せっかくの容量を活かしきれません。
中央に、モデルサイズとデータ量のバランスが良い点があります。これが compute-optimal な点です。
| 領域 | 状態 | 起きやすい問題 |
|---|---|---|
| モデル不足 | N が小さく、D が多い |
データを吸収しきれない |
| 最適付近 | N と D が釣り合う |
計算予算あたりの損失が低い |
| データ不足 | N が大きく、D が少ない |
容量を使い切れない |
実務での失敗は、右側に寄ることが多いです。大きなモデルを作ったものの、データが足りず、評価では期待ほど伸びない。さらに推論コストも重い。この状態になると、学習費用だけでなく運用費用まで重くなります。
5. D ≈ 20N はどう使えばよいのか?
D ≈ 20N は、最初の見積もりとして非常に便利です。モデルサイズを決める前に、必要なトークン数を概算できるからです。
| パラメータ数 | Chinchilla 目安のトークン数 |
|---|---|
| 100M | 2B |
| 1B | 20B |
| 7B | 140B |
| 70B | 1.4T |
ただし、この表をそのまま学習計画にしてはいけません。理由は 3 つあります。
- データ品質が違えば、同じトークン数でも価値が違う
- 推論コストを含めると、小さめのモデルをより長く学習するほうが有利な場合がある
- ドメイン特化モデルでは、一般 Web テキストよりも対象ドメインの濃さが重要になる
たとえば、社内文書検索向けのモデルを作る場合、一般的な Web テキストを 20B トークン増やすより、実際の業務文書、FAQ、問い合わせ履歴を丁寧に整備するほうが効くかもしれません。ここは断定できませんが、業務特化では「量」だけでなく「目的に近いデータか」がかなり重要になります。
6. 計算予算から最適配分をどう概算するのか?
理論を実務に落とすには、まず計算予算から N と D の目安を出せるようにしておくと便利です。
C ≈ 6ND と D ≈ 20N を組み合わせると、次のように概算できます。
$$ C \approx 120N^2 $$
つまり、N は C の平方根に比例します。簡単なコードにすると、次のようになります。
from dataclasses import dataclass
@dataclass
class AllocationPlan:
params_b: float
tokens_b: float
train_flops: float
def estimate_chinchilla_allocation(train_flops: float) -> AllocationPlan:
n_params = (train_flops / 120) ** 0.5
n_tokens = 20 * n_params
return AllocationPlan(
params_b=n_params / 1e9,
tokens_b=n_tokens / 1e9,
train_flops=train_flops,
)
plan = estimate_chinchilla_allocation(train_flops=1.0e22)
print(plan)このコードは、あくまで初期見積もりです。実際には、GPU の実効効率、データローダー、再学習回数、チェックポイント保存、評価コストが入ります。したがって、ここで出した値をそのまま確定計画にするのではなく、検討の出発点として使うのが安全です。
7. 実務ではどこで判断を間違えやすいのか?
最適配分の議論でよくある失敗は、D ≈ 20N を「正解の比率」として固定してしまうことです。これは便利な目安ですが、万能ではありません。
よくある失敗は次の通りです。
- モデルサイズを先に決めてから、あとでデータ量を合わせようとする
- データの品質を見ずに、トークン数だけで判断する
- 学習計算量だけを見て、推論コストを無視する
- 小規模実験の傾向を確認せず、本番規模へ進む
特に注意したいのは、推論コストです。Chinchilla 則は、主に学習計算量の最適化を扱います。しかし、実サービスでは学習より推論のほうが長く続きます。多くのリクエストを処理するなら、少し小さなモデルを多めのトークンで学習し、推論単価を下げるほうが合理的な場合があります。
これは B8 で触れた「推論コスト込みの最適点」と同じ話です。学習時の compute-optimal と、事業全体での cost-optimal は必ずしも一致しません。
8. Gopher 型と Chinchilla 型をどう使い分けるべきなのか?
ここでは、かなり単純化して考えます。
Gopher 型は、モデルサイズを大きくする方向です。能力の上限を引き上げたいときには魅力がありますが、データが足りない場合は効率が悪くなります。また、推論コストも重くなりがちです。
Chinchilla 型は、同じ計算量の中でモデルサイズとデータ量をバランスさせる方向です。学習計算量あたりの性能を重視するなら、まずこちらを基準に考えるのが自然です。
| 判断軸 | Gopher 型に寄りやすい場合 | Chinchilla 型に寄りやすい場合 |
|---|---|---|
| 目的 | 最大能力の探索 | 計算効率の改善 |
| データ | 十分な高品質データがないと危険 | データ整備の効果が出やすい |
| 推論 | 重くなりやすい | 相対的に軽くしやすい |
| 実務適性 | 研究探索向き | 製品開発・予算管理向き |
ただし、現在の公開モデル開発では、Chinchilla 最適よりさらに多くのトークンで学習する over-training 的な設計も見られます。これは、学習計算量だけでなく、推論コストやモデル配布後の利用回数まで考えると合理的な場合があるためです。
したがって、実務での順番はこうです。まず Chinchilla 則で基準線を引く。そのうえで、推論コスト、データ品質、用途、配布形態に応じて、より小さく長く学習するか、より大きく能力上限を狙うかを判断します。
9. 本番計画に入る前に何を確認すべきなのか?
最適配分は、表計算だけで決めるものではありません。本番学習へ進む前に、少なくとも次を確認したほうがよいです。
- 目標は事前学習損失か、下流タスク性能か?
- 必要なデータ量だけでなく、データ品質を確認したか?
- モデルサイズを先に固定しすぎていないか?
- 推論コストを見積もったか?
- 小規模実験で
NとDの傾向を確認したか? - 評価セットが実運用に近いか?
- 再実験用の計算予算を残しているか?
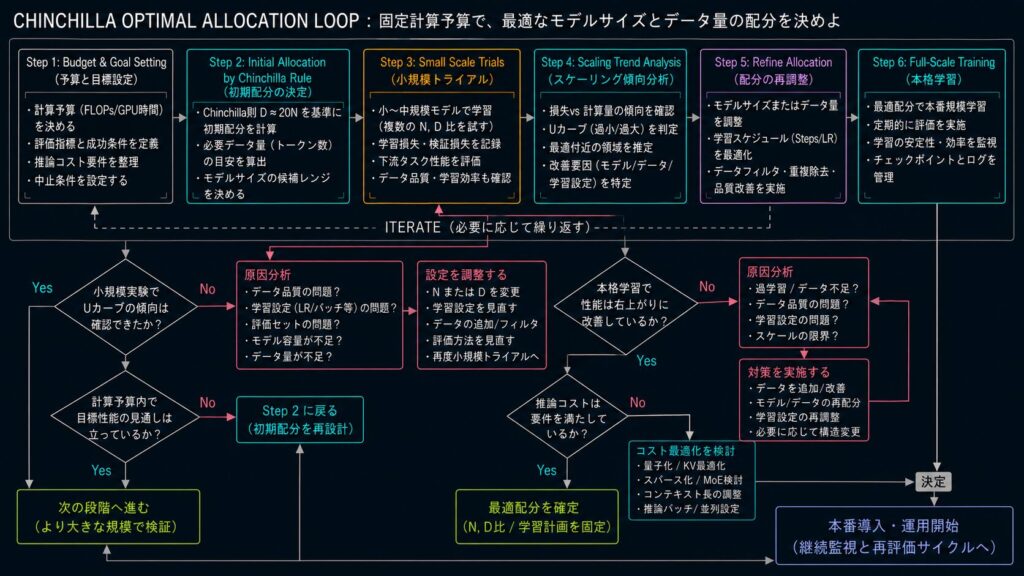
ここで大切なのは、最適配分を一度で当てようとしないことです。小規模実験で傾向を見て、データ品質を直し、評価セットを調整し、もう一度見積もる。この反復がないと、理論上はきれいでも実務では外れやすくなります。
10. まとめ
Chinchilla 則が示した重要な教訓は、「大きなモデルを作ればよい」という単純な発想から抜け出すことです。同じ計算予算でも、モデルサイズとデータ量の配分によって性能は大きく変わります。
今回の要点は次の通りです。
- Gopher は大きなモデルに寄せた設計で、Chinchilla は同等計算量でより小さく多くのデータを使った
- 固定計算予算では、モデル不足とデータ不足の間に最適点がある
D ≈ 20Nは学習計算量に基づく便利な目安だが、絶対法則ではない- データ品質、推論コスト、用途によって実務上の最適点は変わる
- 本番計画では、小規模実験と評価セット設計を挟むべきである
最適配分とは、数式で一発で答えを出す作業ではありません。理論で基準線を引き、実験で補正し、運用制約で現実に合わせる作業です。
11. 今回のブログの考察
Chinchilla 則の面白さは、単に「データを増やせ」と言っているところではありません。大規模モデル開発の意思決定を、パラメータ数の競争から、計算予算の使い方の問題へ引き戻した点にあります。
実務では、モデルサイズは分かりやすい指標です。7B より 70B、70B より 700B のほうが強そうに見えます。しかし、実際にはデータ量、データ品質、推論コスト、評価方法がそろって初めて、そのモデルサイズに意味が出ます。
だからこそ、最適配分の理論は「大きくするな」という話ではありません。大きくする前に、同じ計算量で他にもっと効く配分がないかを考えるための道具です。この視点を持てると、LLM 開発は派手なスケール競争ではなく、根拠を積み上げる投資判断として扱いやすくなります。
参考文献
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.”
- Rae, J., et al. (2021). “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.”
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.”
- Sardana, N., et al. (2024). “Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws.”

コメント