
前回は、スケーリング戦略を「どこまで大きくし、いつ止めるか」という運用判断として整理しました。今回は、もう少しモデル内部に近い話に戻ります。テーマは RoPE と位置エンコーディングです。
長いコンテキストを扱う LLM では、単にメモリを増やせば長文が読めるわけではありません。モデルは、トークンが何番目にあるのか、どのトークン同士がどれくらい離れているのかを理解する必要があります。この位置情報の扱いが崩れると、コンテキスト長を伸ばしても、途中から参照が不安定になったり、長文の後半で急に回答品質が落ちたりします。
RoPE(Rotary Positional Embedding)は、Llama 系列や Mistral 系列など多くの Transformer 系 LLM で使われている位置表現です。この記事では、RoPE の基本、rope_theta の意味、長文コンテキスト拡張で何が起きるのか、実装時にどこで失敗しやすいのかを、実務で判断しやすい順番で整理します。
1. なぜ位置エンコーディングが重要なのか?
Transformer は、入力トークン列をそのまま見るだけでは、単語の順番を自然には理解できません。注意機構はトークン同士の関係を見るのが得意ですが、「この単語は文頭にある」「この説明は 8,000 トークン前に出てきた」といった位置情報は、何らかの形で与える必要があります。
短い入力だけを扱うなら、この問題は目立ちにくいです。しかし、コンテキスト長を 4K、8K、32K、128K と伸ばしていくと、位置表現の設計が急に効いてきます。
たとえば、長い仕様書をモデルに渡して質問するとします。冒頭に重要な制約があり、後半に具体例がある場合、モデルはその距離をまたいで情報を結びつける必要があります。位置表現が弱いと、後半だけを見て答えたり、冒頭の制約を忘れたような回答になったりします。
ここで重要なのは、長文対応は「最大トークン数を設定ファイルで増やすだけ」の話ではないという点です。位置エンコーディング、Attention 実装、KV キャッシュ、学習データの長さ分布、評価セットがすべて関係します。
2. RoPE とは何か?
RoPE は、位置情報をベクトルの回転として埋め込む方法です。絶対位置を単純に足し込むのではなく、Query と Key に対して位置に応じた回転をかけることで、注意スコアの中に相対的な距離情報が現れるようにします。
直感的には、同じ単語ベクトルでも、1 番目にあるときと 100 番目にあるときでは、少し違う角度で表現されると考えると分かりやすいです。この回転角度が位置によって変わるため、モデルはトークン間の距離を扱えるようになります。
RoPE の基本形は、2 次元ペアごとに次のような回転をかけるものです。
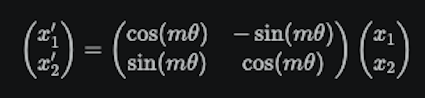
ここで、$m$ は位置インデックス、$\theta$ は次元ごとに異なる周波数です。RoPE の論文では、この回転によって絶対位置を扱いながら、注意スコア上では相対位置に関する性質を持てることが説明されています。
最小限のイメージを Python で書くと、次のようになります。
import numpy as np
def rotate_pair(x1: float, x2: float, position: int, theta: float) -> tuple[float, float]:
angle = position * theta
cos, sin = np.cos(angle), np.sin(angle)
return x1 * cos - x2 * sin, x1 * sin + x2 * cos
print(rotate_pair(1.0, 0.0, position=0, theta=0.01))
print(rotate_pair(1.0, 0.0, position=100, theta=0.01))実際の LLM では、これを Query と Key の各次元ペアに対して行います。上のコードは数学的な雰囲気を掴むための単純化であり、そのまま実装に使うものではありません。
3. rope_theta は何を決めているのか?
rope_theta は、RoPE で使う周波数の分布を決める重要な設定です。多くの実装では、次元ごとの周波数はおおむね次のような形で作られます。
$$ \theta_i = \mathrm{base}^{-2i/d} $$
この base に相当する値が、実装上の rope_theta として扱われることが多いです。典型的な古い設定では 10000.0 が使われます。一方で、Llama 3 の設定では 500000.0 が使われていることが知られています。
ただし、ここで誤解しやすい点があります。rope_theta は、RMSNorm の安定化パラメータではありません。また、モデルサイズを大きくすれば自動的に上げるべき値でもありません。主に、位置表現の周波数スケール、最大コンテキスト長、事前学習時の設定と整合させて扱う値です。
実務で見るべきなのは、次の関係です。
| 観点 | 確認すること |
|---|---|
| 事前学習時の設定 | モデルがどの rope_theta で学習されたか |
| 最大コンテキスト長 | 学習時と推論時でどこまで伸ばすか |
| RoPE 拡張方式 | 位置補間、NTK-aware、YaRN などを使うか |
| 評価方法 | 長文検索、要約、複数箇所参照で品質を測るか |
rope_theta は「大きければよい」という単純なものではありません。学習時の設定と推論時の設定がずれると、短文では問題が見えなくても、長文で性能が崩れることがあります。
4. RoPE スケーリングとは何か?
RoPE スケーリングとは、元の学習コンテキスト長より長い入力を扱うために、RoPE の位置表現を調整することです。
ここで起きている問題はシンプルです。モデルが 4K や 8K 程度の長さを中心に学習されている場合、32K や 128K の位置は、学習時に十分見ていない領域になります。そのまま位置番号だけを伸ばすと、回転角度の分布が学習時と大きく変わり、外挿が難しくなります。
代表的な方向性は次の通りです。
| 方法 | 考え方 | 注意点 |
|---|---|---|
| 何もしない | 設定だけ最大長を増やす | 長文で品質劣化しやすい |
| 位置補間 | 長い位置を学習済み範囲へ圧縮する | 短文性能や局所距離の扱いに影響する場合がある |
| NTK-aware 系 | 周波数スケールを調整して外挿を緩和する | 実装差があり、評価なしの流用は危険 |
| YaRN / LongRoPE 系 | 周波数帯ごとに調整し、長文性能を狙う | 設定項目が増え、検証が必須になる |
つまり RoPE スケーリングは、長文対応のための便利なつまみではありますが、万能ではありません。とくに、元モデルの事前学習設定、追加学習の有無、推論時の実装が合っていないと、期待したほど伸びないことがあります。
5. 長文コンテキスト拡張で何が壊れやすいのか?
実務で多い失敗は、「最大コンテキスト長を増やしたので長文対応できた」と考えてしまうことです。設定上は 32K 入るようになっても、モデルが 32K の情報を安定して使えるとは限りません。
壊れやすいのは、次のような場面です。
- 長文の冒頭にある条件を後半の質問で使う
- 複数箇所に散らばった情報を統合する
- 似た形式の項目が長文中に何度も出てくる
- 後半にある情報を優先しすぎて、前半の制約を忘れる
たとえば契約書レビューで、冒頭に「本契約は日本法に準拠する」とあり、後半に英米法を前提にした条項例が出てくる場合を考えます。長文対応が弱いモデルは、後半の近い文脈に引っ張られて、冒頭の制約を落とすことがあります。これは単なる記憶容量の問題ではなく、位置と注意の使い方の問題でもあります。
したがって、長文評価では平均スコアだけを見るのは危険です。短い QA では問題がなくても、長文検索、複数証拠統合、長文要約では別の失敗が出ます。
6. 実装では何を固定し、何を検証すべきなのか?
まず固定すべきなのは、モデルが事前学習されたときの位置設定です。既存モデルを使う場合、rope_theta や rope_scaling を理由なく変更するのは避けるべきです。
とくに危険なのは、次のような変更です。
- 学習済みチェックポイントに対して
rope_thetaだけを変える max_position_embeddingsだけを増やして長文対応とみなす- 短文ベンチマークだけで長文性能を判断する
- 実装ごとの
rope_scalingの意味を確認せずに設定を移植する
設定ファイルを確認するための最小例は、次のように書けます。
def summarize_rope_config(config: dict) -> dict:
return {
"rope_theta": config.get("rope_theta"),
"rope_scaling": config.get("rope_scaling"),
"max_position_embeddings": config.get("max_position_embeddings"),
"original_max_position_embeddings": config.get("original_max_position_embeddings"),
}
llama3_like_config = {
"rope_theta": 500_000.0,
"max_position_embeddings": 8192,
}
print(summarize_rope_config(llama3_like_config))この程度の確認でも、意図しない設定変更には気づきやすくなります。特に Hugging Face Transformers、vLLM、llama.cpp など複数の実行環境をまたぐ場合、同じモデル名でも設定の解釈が完全に同じとは限りません。変換時に config.json やメタデータを確認する習慣が重要です。
7. Llama 系モデルの設定をどう読めばよいのか?
Llama 3 では rope_theta = 500000.0 が使われ、Llama 3.1 以降の長文モデルではさらに RoPE scaling の設定が入ることがあります。この事実だけを見ると、「Llama 方式に合わせて 500000 にすればよい」と考えたくなります。
しかし、それは雑な理解です。重要なのは、値そのものではなく、その値で学習または継続学習されているかです。
たとえば、短いコンテキストで事前学習したモデルに対して、推論時だけ rope_theta を大きくしても、長文理解が必ず良くなるとは言えません。設定を変えることで、むしろ学習時に見ていた短距離の位置関係がずれる可能性もあります。
実務では、次の順番で読むと安全です。
- 元モデルの
rope_thetaと最大コンテキスト長を確認する rope_scalingがある場合、その方式と係数を確認する- 追加学習や長文 fine-tuning が行われているか確認する
- 自分の推論基盤がその設定を正しく解釈できるか確認する
- 長文タスクで評価してから本番設定にする
つまり、Llama の設定は参考になりますが、すべてのモデルにそのまま移植するものではありません。
8. 評価では何を見るべきなのか?
RoPE スケーリングの評価では、単に perplexity や短文ベンチマークを見るだけでは足りません。長文で何をしたいのかに合わせて、評価タスクを分ける必要があります。
見るべき観点は次の通りです。
| 評価観点 | 例 | 見たい失敗 |
|---|---|---|
| 長文検索 | Needle-in-a-Haystack | 遠い位置の情報を拾えない |
| 複数証拠統合 | 長い議事録から条件を統合 | 近い情報だけで答える |
| 長文要約 | 章ごとの要点を保った要約 | 後半偏重、冒頭条件の脱落 |
| 実運用プロンプト | 社内規程、仕様書、契約書 | 実データ特有の失敗 |
失敗しやすいのは、公開ベンチマークで良かったから本番でも大丈夫だと考えることです。公開ベンチマークは有用ですが、自分のユースケースを完全には代表しません。長文 RAG、契約書レビュー、コードリーディング、議事録分析では、それぞれ必要な能力が違います。
実務では、短い入力、学習時相当の長さ、拡張した最大長付近の 3 点で比較するのがよいです。短文性能が落ちていないか、元の長さでは安定しているか、最大長付近でどの失敗が増えるかを分けて見られるからです。
9. 本番導入前のチェックリスト
RoPE や位置エンコーディングの設定は、問題が起きても原因が見えにくい領域です。出力が完全に壊れるより、長文の一部だけを見落とすような形で現れることが多いからです。
本番導入前には、最低限次を確認したいところです。
- 元モデルの
rope_thetaを確認したか? -
rope_scalingの有無と方式を確認したか? -
max_position_embeddingsだけを増やして長文対応と誤解していないか? - 推論基盤が設定を正しく読み込んでいるか?
- 短文性能と長文性能を分けて評価したか?
- 長文の冒頭、中盤、後半から情報を取るテストを行ったか?
- 本番プロンプトに近い長文評価セットを用意したか?
- 失敗時に元のコンテキスト長へ戻せる設定を残したか?
ここで特に大事なのは、ロールバックです。長文対応を入れると、一見便利になりますが、短い入力で微妙に品質が落ちる場合もあります。ユーザーから見ると「長文は読めるが、普段の回答が少し悪くなった」という形で現れるため、検知が遅れやすいです。
10. まとめ
RoPE は、位置情報を回転として表現する仕組みであり、多くの LLM で長文処理を支える重要な部品です。ただし、rope_theta や RoPE scaling は、値を大きくすれば長文性能が上がるという単純な設定ではありません。
今回の要点を整理すると、次の通りです。
- 位置エンコーディングは、長文で情報を結びつけるために重要である
- RoPE は Query と Key に回転をかけ、位置と相対距離の情報を注意に反映する
rope_thetaは周波数スケールに関わる値であり、RMSNorm の安定化設定ではない- 長文拡張では、位置補間、NTK-aware、YaRN などの方式があり、評価なしに流用すべきではない
max_position_embeddingsだけを増やしても、長文理解が保証されるわけではない- 本番では、短文性能、長文検索、複数証拠統合を分けて評価する必要がある
RoPE スケーリングは、長文コンテキストを扱うための強力な技術ですが、同時に設定ミスが見えにくい領域でもあります。だからこそ、設定値の暗記ではなく、学習時の前提、推論基盤の実装、評価タスクをつなげて考えることが重要です。
11. 今回のブログの考察
RoPE の難しさは、数式そのものよりも、設定値が「いかにも簡単に変えられそう」に見えるところにあります。rope_theta や max_position_embeddings は設定ファイル上の数値なので、つい調整すれば長文対応できるように見えます。しかし実際には、その数値でモデルがどのように学習され、どの実装で推論され、どの長文タスクで評価されるかまで含めて初めて意味を持ちます。
これは、スケール則の議論ともつながっています。モデルを大きくするだけでは性能が決まらないように、コンテキスト長も上限値を伸ばすだけでは実用性能が決まりません。長文対応とは、位置表現、Attention、KV キャッシュ、データ、評価をまとめて設計する作業です。
実務では、まず元モデルの設定を尊重し、必要がある場合だけ長文拡張を検証するのが安全です。設定値を変えて一気に解決しようとするより、どの距離で、どのタスクで、どのように失敗するかを測る。そこから始めるほうが、結果的には信頼できる長文対応につながります。
参考文献
- Su, J., et al. (2021). “RoFormer: Enhanced Transformer with Rotary Position Embedding.”
- Press, O., et al. (2021). “Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.”
- Chen, S., et al. (2023). “Extending Context Window of Large Language Models via Positional Interpolation.”
- Peng, B., et al. (2023). “YaRN: Efficient Context Window Extension of Large Language Models.”
- Ding, Y., et al. (2024). “LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens.”
- Grattafiori, A., et al. (2024). “The Llama 3 Herd of Models.”

コメント