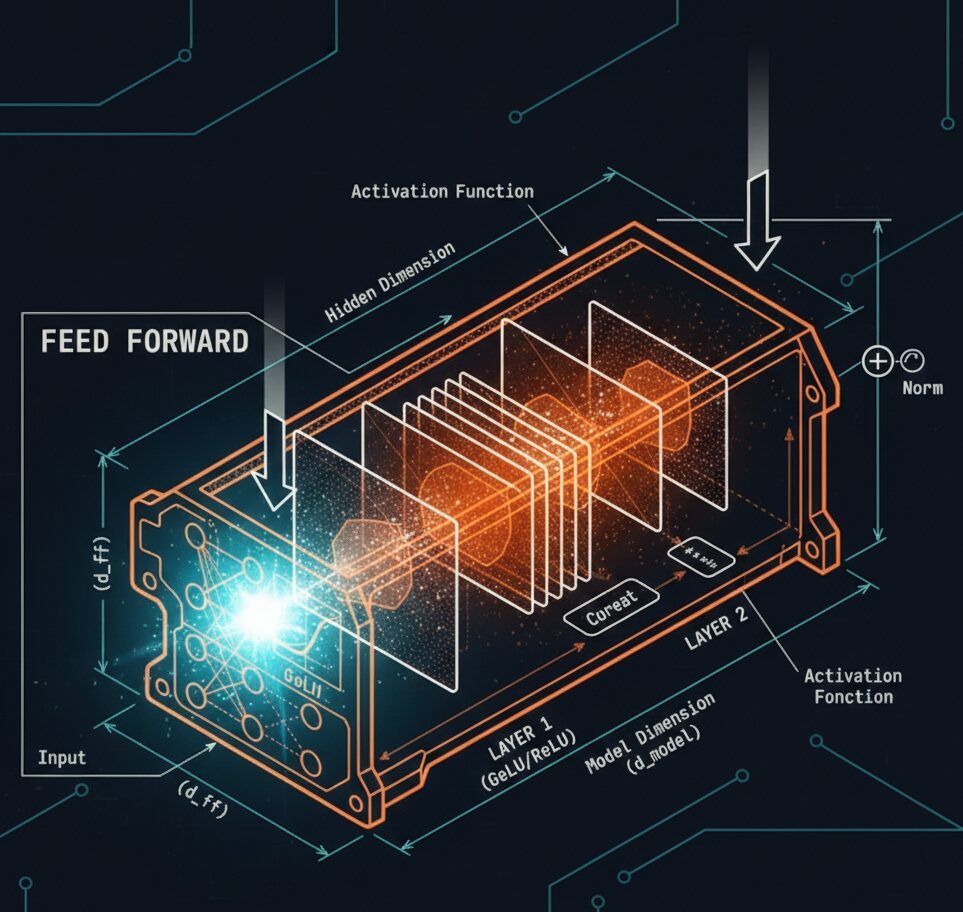
FFNと活性化関数:Transformerの知識を蓄える場所
前回は、Multi-Head Attention の詳細なメカニズムを学びました。今回は、そこで拾った文脈情報をどう扱うのかという視点から、Transformer のもう1つの重要な部品であるFeed Forward Network (FFN) と活性化関数を解説します。Attention が「関係を見つける」役割だとすると、FFN はその情報を「モデル内部の表現に変換して蓄える」役割を担います。
Feed Forward Network の役割:「知識の蓄積」
Multi-Head Attention で「トークン間の関係性」を把握した後、その情報をさらに整理し、次の層で扱いやすい形に変換するのが、Feed Forward Network (FFN) です。文脈を見つけるだけではモデルは十分に賢くなりません。見つけた関係を、どのような特徴として保持するかが必要になります。
Multi-Head AttentionとFFNの役割の違い
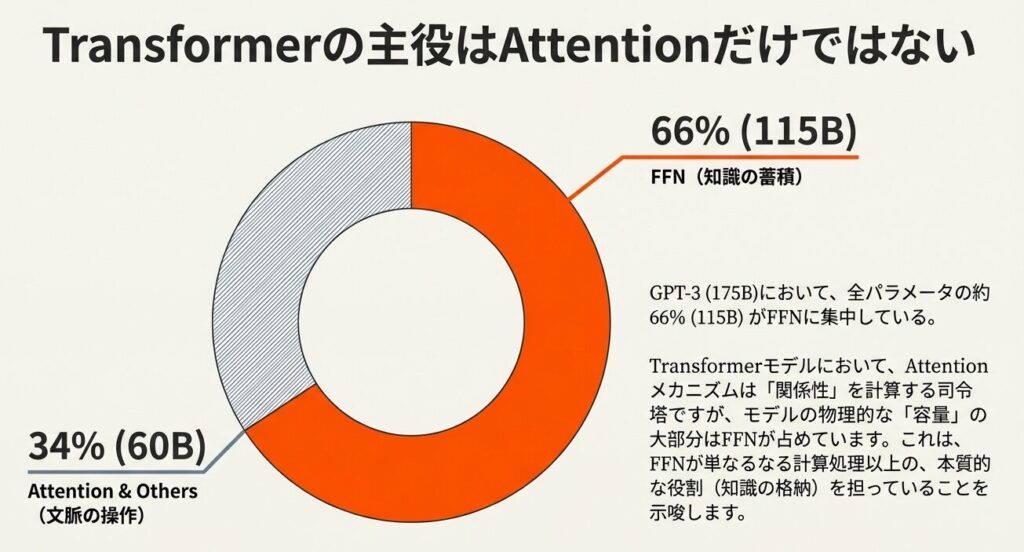
Transformer の全パラメータの約3分の2(66%)が FFN に集中しており、モデルが事前学習で獲得した知識を保持する主要な場所として機能しています。つまり、Attention が一時的に文脈を見ているのに対し、FFN はその結果を内部表現として蓄積しやすい構造だと考えられます。
| コンポーネント | 主な役割 | 特徴 |
|---|---|---|
| Multi-Head Attention | 関係性の把握 | トークン同士のつながり(文脈)を捉える。 |
| FFN | 知識の蓄積・変換 | モデル全体の「ニューラルメモリ」として知識を格納する。 |
FFNの構造:シンプルな2層MLP
入力ベクトル x (次元 = d_model)
↓
[ 線形層 W_1: d_model → 4×d_model ]
↓
[ 活性化関数(ReLU, GELU等)]
↓
[ 線形層 W_2: 4×d_model → d_model ]
↓
出力ベクトル y例えば、$d_{model} = 768$ の場合:
| ステップ | 次元 | 処理内容 |
|---|---|---|
| 入力 | 768次元 | – |
| 拡張 | 3072次元 | 4倍に拡張 |
| 活性化 | 3072次元 | 非線形変換 |
| 圧縮 | 768次元 | 元に戻す |
FFNが占めるパラメータ数の圧倒的な割合

GPT-3(総パラメータ数 175B)の場合:
| コンポーネント | パラメータ数 | 割合 |
|---|---|---|
| FFN | 約 115B | 66% |
| Multi-Head Attention | 約 60B | 34% |
つまり、Transformer の 2/3以上のパラメータがFFN に集中 しています。これは、FFN が単なる補足的な部品ではなく、モデルの表現力と知識保持を支える中核の部品であると見る理由になります。
FFN を知識メモリと解釈する
近年の研究(Geva et al. 2021)では、FFN が 「Key-Value メモリのように機能している」 という解釈が有力です。ここでは、その見方がなぜ自然なのかを、学習時と推論時に分けて確認します。
FFNが実現する知識の蓄積
学習と推論におけるFFNの挙動
訓練中(事前学習時):FFN は、入力パターンと出力の対応関係を少しずつ重みの中に取り込みます。
「猫は動物である」という文を見た時、
FFN 内の重み W_1, W_2 が、
「『猫』というパターンが入力されたら、
『動物という特性を持つ』という出力を返す」
という知識を学習・蓄積します。推論中(テキスト生成時):学習で蓄えた対応関係を使って、今の入力に続きやすい表現へ変換します。
「猫は」という入力が来た時、
FFN が事前学習で蓄積した知識から
「次は『動物的な特性に関連した単語』が来そうだ」
という情報を出力します。💡 ポイント
FFN は「モデル全体のニューラルメモリ」「事前学習で獲得した知識の格納庫」として機能しています。
活性化関数:非線形変換による表現力の増加
FFN の中で重要なのが、線形変換の間に挟まる活性化関数です。ここで非線形性を入れることで、単なる行列の掛け算では表せない変換が可能になります。

FFN の中間層に活性化関数を挟むと、入力の大きさや符号に応じて出力の振る舞いが変わります。ここが、表現力を高めるうえでの分岐点です。
活性化関数がない場合
出力 = W_2 × [ReLU(W_1 × 入力)]
↓ ReLUを削除すると
= W_2 × (W_1 × 入力)
= (W_2 × W_1) × 入力
= 単なる行列乗算(線形変換)線形変換だけでは、複雑な関係を表現しきれません。入力と出力の対応が単純な比例関係に固定されるため、モデルが学べるパターンの幅が狭くなるからです。
ReLU 活性化関数
$$\text{ReLU}(x) = \max(0, x)$$
入力:[-2, -1, 0, 1, 2]
↓ ReLU
出力:[0, 0, 0, 1, 2]負の値を0に、正の値はそのままにすることで、出力に明確な切り替えが生まれます。これが、単純な線形変換との違いです。
GELU 活性化関数(より高度)
$$\text{GELU}(x) = x \cdot \Phi(x)$$
ここで $\Phi(x)$ は標準正規分布の累積分布関数です。
| 特徴 | ReLU | GELU | SwiGLU |
|---|---|---|---|
| 滑らかさ | 折れ曲がる | 滑らか | 滑らか |
| 確率的解釈 | なし | あり(正規分布の累積分布関数に基づく) | なし(ゲート機構による制御) |
| 計算の複雑さ | 単純 | 複雑(正規分布に基づく) | 非常に複雑(3つの行列計算と要素積を使用) |
| 現在の主流 | 古いモデル(画像処理等:CNN) | GPT系列(最新の言語モデル) | 最新のLLM(Llama 3, Mistral, Gemini等) |
これらの非線形活性化関数により、FFN は複雑な入力-出力関係を学習でき、モデル全体の表現力が大きく向上します。つまり、Attention で拾った文脈を、次の層で使える特徴に変えやすくなります。
モデルの深層化に伴い、情報消失を防ぎながらより滑らかな表現を扱うため、LLM では GELU が広く使われてきました。さらに現在の LLM(2026年1月時点)では、SwiGLU のようなゲート付きの活性化関数も主流になっています。どちらを選ぶかは、表現力と計算コストのバランスを見ることになります。
まとめ
この記事では、FFN と活性化関数の役割を解説しました。ポイントは、FFN が単なる通過点ではなく、Transformer が見つけた文脈を内部表現として蓄える場所だという点です。
| 項目 | 内容 |
|---|---|
| FFNの構造 | 2層MLP(拡張→活性化→圧縮) |
| パラメータ割合 | Transformer全体の約66% |
| 役割 | 知識の蓄積・記憶(Key-Valueメモリ) |
| 活性化関数 | 非線形変換で表現力を向上 |
次回は、因果的 Attention Mask と自己回帰型生成について解説します。ここまでで文脈をどう受け取るかが見えたので、次は未来のトークンをどう制限しながら生成するかを見ていきます。
📖 参考文献
主要論文
- Geva, M., Schvartz, R., Shalev-Shwartz, S., & Schwartz, R. (2021): “Transformer Feed-Forward Layers Are Key-Value Memories”, EMNLP 2021
- Hendrycks, D., & Gimpel, K. (2016): “Gaussian Error Linear Units (GELUs)”, arXiv
- Ramachandran, P., Zoph, B., & Le, Q. V. (2017): “Swish: a Self-Gated Activation Function”, arXiv
- GLU Variants Improve Transformer, Noam Shazeer(2020): “GLU Variants Improve Transformer”, arXiv
- https://arxiv.org/abs/2002.05202
- SwiGLUを提案した、最も重要で直接的な論文
📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。


コメント