 事前学習
事前学習 LLM 事前学習:Transformer シリーズ総集編 vol.1
このページでわかることこのページは、大規模言語モデルの「事前学習:Transformer」シリーズ全体の案内ページです。ブログ A 〜 E を 1 ページにまとめ、一目で把握できるように整理しています。何を知りたいときにどのシリーズを見れば...
事前学習 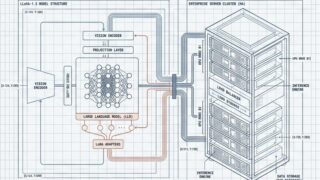 機械学習
機械学習  画像生成
画像生成  基礎理論
基礎理論  基礎理論
基礎理論 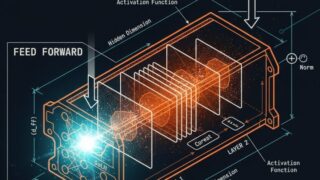 基礎理論
基礎理論  基礎理論
基礎理論  基礎理論
基礎理論  LLM
LLM  Claude
Claude