
Transformerモデル構造の全体像:3つの主要コンポーネント
前回の記事で、言語モデルがN-gramからRNN、そしてTransformerへと進化した流れを確認しました。今回は、そのTransformerがどの部品でできているのかを、全体像から順番にたどります。ここで押さえたいのは、個々の用語を暗記することではなく、どの部品が何のためにあるのかを理解することです。
以前のブログでもTransformerについて触れていますが、この記事ではそこから一歩進めて、構造を分解しながら確認します。全体像を先に見てから細部に入ると、後半のEmbeddingやAttentionの役割が読みやすくなります。

Transformerの全体像:ブロック構成
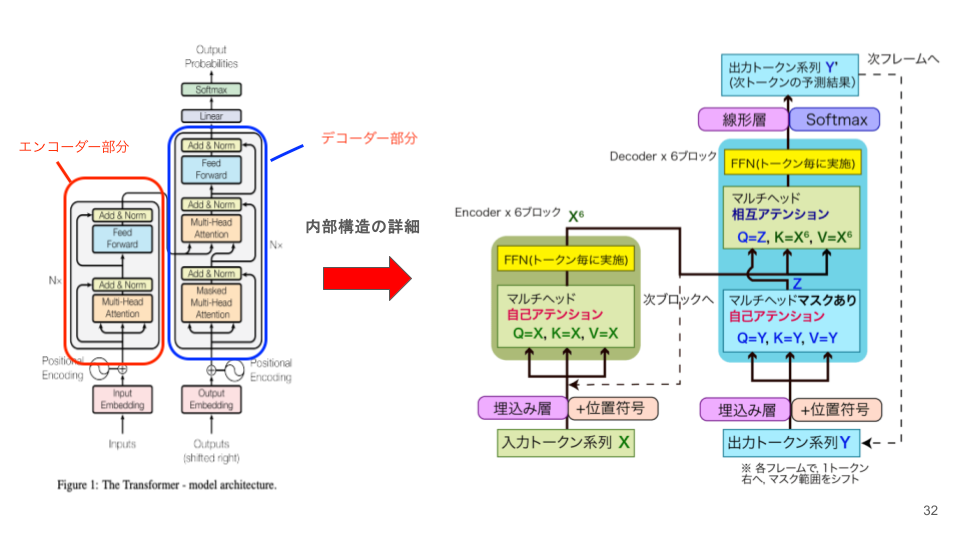
Transformerの基本的な構造は、エンコーダー と デコーダー という2種類の「ブロック」から成り立っています。元のTransformerは翻訳のように入力文を受け取って別の文を出すための構造でしたが、現在のGPT型モデルは主にデコーダー側だけを使います。まずはこの違いを押さえると、後続の説明が整理しやすくなります。
オリジナルTransformer vs 現代のGPT型モデル
| 種類 | 目的 | 構造 | 例 |
|---|---|---|---|
| オリジナルTransformer | 機械翻訳 | エンコーダー + デコーダー | 翻訳タスク |
| GPT型(Decoder-only) | テキスト生成 | デコーダーのみ | GPT-1〜4, ChatGPT |
このブログの後続セクションでは、主に Decoder-only型(つまりGPT型)の構造を詳しく解説します。生成系のLLMを理解したいなら、まずはこちらの構造に慣れておくと後の話がつながりやすくなります。
Transformerの3つの主要コンポーネント
Transformerは、以下の3つの主要な部品から構成されています。ここでは、それぞれを単独の機能として見るだけでなく、入力を受け取って文脈を作り、最後に知識としてまとめる流れとして見ていきます。
各コンポーネントの役割
1. Embedding層:「言葉を数字に翻訳する」
コンピュータは数字しか理解できないため、文字をそのままでは扱えません。まずはトークンをベクトルに変換して、モデルが計算できる形にします。
入力:「私」 → ID: 1050 → ベクトル: [0.2, -0.5, 0.8, ...]
「は」 → ID: 80 → ベクトル: [-0.1, 0.3, 0.2, ...]
「学校」→ ID: 2450 → ベクトル: [0.5, 0.1, -0.3, ...]2. Multi-Head Attention:「文脈に応じて重要な単語に注目する」
「学校へ行く」という文では、「へ」という助詞の意味は単独では決まりません。前後の単語との関係を見て初めて意味が定まります。Attentionは、この単語同士の関係性を文脈に応じて拾い上げる仕組みです。

3. FFN:「知識を記憶する」
Attentionで文脈を見たあと、その情報をもとに各単語の表現をさらに変換するのがFFNです。「学校」という単語を見た時、モデルは「教育の場」「複数の生徒がいる」「時間割がある」といった意味を、層内の重みとして保持します。これが、モデルが持つ知識の一部だと考えると分かりやすいです。
Embeddingと位置情報の統合
Transformerがテキストを処理するとき、最初に行うのがEmbedding層 による変換です。ここで重要なのは、単語を数字に置き換えるだけではなく、順序情報も一緒に扱えるようにすることです。
ステップ1:文字の分割(トークン化)
生のテキストは、まずトークン化によって最小単位に分割されます。ここでは、文章をそのまま入れるのではなく、モデルが扱いやすい単位へ分けるところから始めます。
入力テキスト:「今日の天気はいいですね」
↓
トークン化:「今日」「の」「天気」「は」「いい」「です」「ね」
↓
トークンID: [1001, 82, 1234, 80, 892, 456, 234]💡 ポイント
Byte Pair Encoding (BPE) という標準的なアルゴリズムを用いて、高頻出する単語は1個のトークン、稀な単語は複数のトークンに分割します。
ステップ2:ワードエンベディング
各トークンIDを、学習可能な数値ベクトルに変換します。学習を通じて、意味的に似た単語は近い位置に配置されます。つまり、Embeddingは単なる番号付けではなく、意味を持つ空間へ写像する処理です。
| 単語ペア | 関係 | ベクトル距離 |
|---|---|---|
| 「学校」と「大学」 | どちらも教育機関 | 近い |
| 「猫」と「犬」 | どちらも動物 | 近い |
| 「赤」と「青」 | どちらも色 | 近い |
これが「単語の意味がベクトルに埋め込まれている」という意味です。
ステップ3:位置エンコーディング(Positional Encoding)
Transformerは各トークンを「同時に」処理するため、トークンの順序情報 をモデルに明示的に与える必要があります。ここを省くと、単語の並びが変わったときに意味を取り違えやすくなります。
文:「私は学校へ行く」
0 1 2 3 4
位置情報なし:
[ベクトル_「私」, ベクトル_「は」, ベクトル_「学校」, ...]
→ どの順で並んでいるか分からない!
位置エンコーディング追加後:
[ベクトル_「私」 + 位置_0, ベクトル_「は」 + 位置_1, ...]
→ 順序がモデルに伝わります。このステップにより、Transformerは「何という単語か」と「どの位置にあるか」の両方の情報を同時に処理できるようになります。Embeddingだけでは足りない理由が、ここで見えてきます。
Add & Norm:学習を安定させるテクニック
深いニューラルネットワークを学習させると、「勾配消失」や「学習の不安定化」といった問題が生じます。Transformerでは、この弱点を和らげるために2つのテクニックを組み合わせています。ここは仕組みそのものより、なぜ必要なのかを押さえると理解しやすくなります。
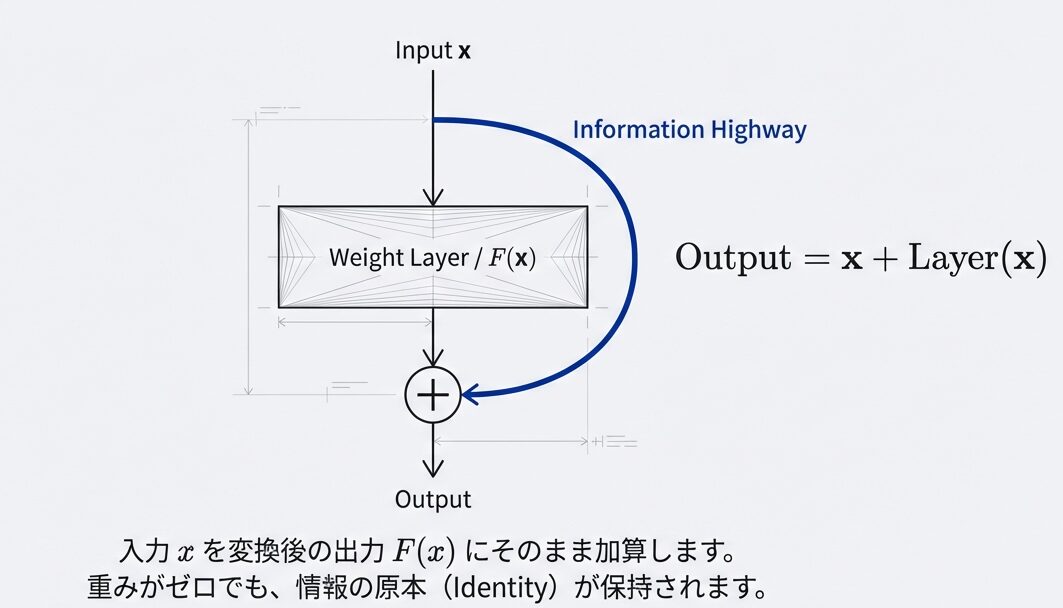
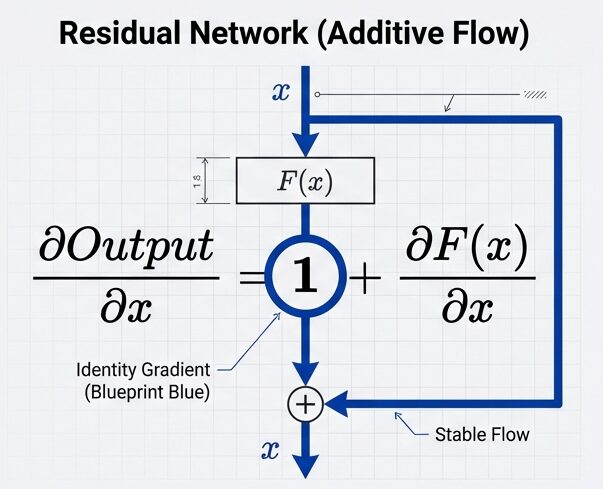
残差接続(Add: Residual Connection)
なぜ効果があるのか?
もし Attention がノイズだらけで役に立たなかったら、最終出力 ≈ y + x = (ノイズ) + x ≈ x(元のデータ)となります。
つまり、悪い時は「何もしない(恒等関数)」を容易に学習できます。これにより、モデルは「改善できない層」をスキップして、「改善できる層」に集中できるようになります。
レイヤー正規化(Norm: Layer Normalization)
各層から出力されるベクトル x = [x1, x2, x3, …] を以下の式で正規化します:
$$\text{正規化後} = \frac{x – \text{平均値}}{\sqrt{\text{分散} + \epsilon}}$$
これにより、各次元が-1〜1のスケールに正規化されます。
効果:
- ニューロンの出力スケールが統一される
- 学習率が安定し、収束が早くなる
- 深いモデルでも安定して学習できる
Transformerブロックの層状積み重ね
Transformerは、上述の「Embedding → Attention → FFN → Add & Norm」というブロックを、何十層も積み重ねることで、より複雑な言語理解を実現します。1層だけでは単純な特徴しか見られませんが、層を重ねることで、表層的な単語情報から文全体の意味へと段階的に広げられます。
| 層 | 理解する内容 |
|---|---|
| 層1 | 「「猫」という単語の意味を抽出」 |
| 層2 | 「「猫が」という2語の関係を理解」 |
| 層3 | 「「猫が好きだ」という文の意味を把握」 |
| 層4-6 | より抽象的な概念(話題、感情など)を理解 |
| 層7-12 | 文脈全体の深い意味を理解 |
各層が段階的に、より高度で抽象的な理解を構築していきます。ここまでを押さえると、Transformerは「一枚岩の魔法の箱」ではなく、役割の違う部品を積み上げた構造だと分かります。
まとめ
この記事では、Transformerの全体構造と3つの主要コンポーネントを解説しました。ポイントは、単語をベクトルに直し、順序を与え、文脈を見て、学習を安定させる流れが一つにつながっていることです。
| コンポーネント | 役割 |
|---|---|
| Embedding層 | 単語をベクトルに変換 + 位置情報を追加 |
| Multi-Head Attention | 全単語間の関係性を把握 |
| FFN | 知識を記憶・蓄積 |
| Add & Norm | 学習を安定化 |
次回は、Multi-Head Attentionの詳細なメカニズムを解説します。今回の構造が分かっていると、Attention がなぜ中心的な役割を持つのかがつながりやすくなります。
� 参考文献
主要論文
- Vaswani, A., et al. (2017): “Attention Is All You Need”, NeurIPS 2017
- Dai, Z., Yang, Z., Yang, Y., et al. (2019): “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, ACL 2019
- Press, O., Smith, N. A., & Lewis, M. (2022): “Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation”, ICLR 2022
補足資料
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016): “Layer Normalization”, NeurIPS 2016
- He, K., Zhang, X., Ren, S., & Sun, J. (2016): “Deep Residual Learning for Image Recognition”, CVPR 2016
�📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。

コメント