Attentionの可視化と解釈:LLM推論プロセスを理解する
LLM の Attention を可視化すると、モデルの判断根拠が少し見えたように感じます。ただし、ここで注意したいのは、見えることと分かることは同じではないという点です。Attention の図は強い手がかりになりますが、それだけで因果関係まで断定するのは危険です。
この記事では、Attention を「きれいな図」として眺めるのではなく、どの場面で役立ち、どこで読み違えやすいのかを整理します。特に、Multi-Head Attention のパターン、Feature Importance の見方、誤例分析の進め方、そして解釈時の注意点を順番に確認します。
1. なぜAttentionを可視化するのか
LLM は、入力から出力までの間に複数層の計算を通ります。人間から見ると、その途中で何が起きているのかは見えにくく、結果だけを見ても判断の根拠までは追いづらいです。Attention 可視化は、その見えにくさを少しでも減らすための方法です。
この章で押さえたいのは、可視化の目的は「モデルを完全に説明すること」ではなく、推論の傾向をつかみ、次の調査や改善につなげることだという点です。
可視化で得たいもの
| 目的 | 何を知りたいか | 具体的な使いどころ |
|---|---|---|
| 推論プロセスの理解 | どのトークン同士に関係を見ているか | 文脈理解の確認 |
| バイアスの発見 | 特定の属性や語に偏っていないか | 不公正な出力の確認 |
| エラー分析 | どこを見落としたのか | 誤答の原因特定 |
| 説明可能性の補助 | 判断根拠をどう説明するか | ユーザーへの説明 |
Attention が高いからといって、その情報がそのまま出力を決めたとは限りません。それでも、どこに注目しやすいかを見ることで、モデルの振る舞いを理解する入口にはなります。
2. 何を見ればよいのか
Attention の可視化をするときは、まず「どこを見れば意味があるのか」を決める必要があります。ここが曖昧だと、ヒートマップを眺めても印象だけで終わってしまいます。
2.1 Multi-Head Attention の役割分担
Multi-Head Attention は、複数の視点で同じ入力を見られるのが強みです。ひとつのヘッドが文法を追い、別のヘッドが意味的なつながりを追い、さらに別のヘッドが代名詞参照のような関係を拾うことがあります。
| Head の見方 | 見えやすい関係 | 例 |
|---|---|---|
| 文法的な関係 | 主語と述語、助詞と名詞 | 「can」→「lend」 |
| 意味的な関係 | 単語同士の関連 | 「bank」→「money」 |
| 参照関係 | 代名詞や指示語の解決 | 「it」→「cat」 |
たとえば “The bank can lend money to customers” という文では、あるヘッドは “bank” と “lend” の関係を強く拾い、別のヘッドは “to” と “customers” の関係を追う、といった見え方になります。重要なのは、一つのヘッドだけで全体を判断しないことです。
2.2 Attention ヒートマップの読み方
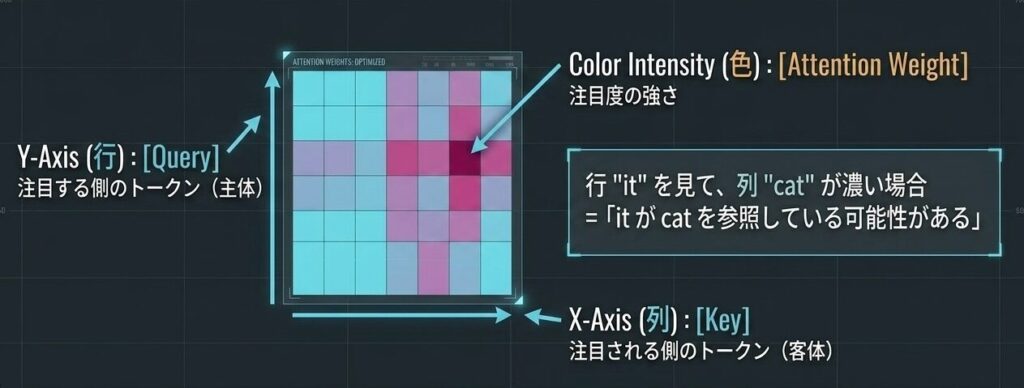
ヒートマップは、行と列の意味を取り違えるとすぐに誤読します。基本は次の通りです。
| 見方 | 意味 |
|---|---|
| 行 | Query。注目する側のトークン |
| 列 | Key。注目される側のトークン |
| 色の濃さ | Attention weight。注目度の強さ |
たとえば、it というトークンの行を見て cat の列が濃ければ、「it が cat を参照している可能性がある」と読めます。ただし、これはあくまで可能性です。実際の出力は FFN や残差接続も経由するため、Attention だけで結論を出さないほうが安全です。
2.3 層ごとの違い
Attention の見え方は、層によっても変わります。浅い層ほど局所的で、深い層ほど文脈全体に広がる傾向があります。

| 層 | 典型的な傾向 |
|---|---|
| 初期層 | 隣接トークン、品詞、短距離依存 |
| 中間層 | フレーズ単位の関係、構文の把握 |
| 後期層 | 長距離依存、文全体の意味、タスク特化のパターン |
ここで大事なのは、層の役割は固定ではなく、モデルや学習データによって揺れることです。あくまで傾向として捉えるほうが、過剰な断定を避けられます。
3. どう解釈するのか
可視化は、見えたものをどう使うかで価値が変わります。Attention を見たあとに必要なのは、「それが何を意味するか」を慎重に読むことです。
3.1 Attention Rollout
Attention Rollout は、複数層の Attention をまとめて、入力トークンが最終出力にどの程度関わったかを推定する考え方です。単一層だけを見るより、層をまたいだ影響の流れを追いやすくなります。
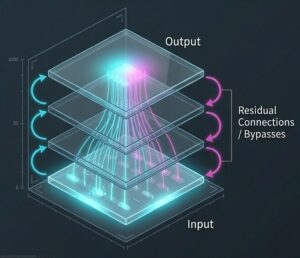
一般的には、次の流れで扱います。
- 各層の Attention 行列を取得する
- 残差接続を考慮して補正する
- 層をまたいで累積する
- 最終出力への影響度を推定する
この手法が役立つのは、単発の注視だけでは見えない流れを見たいときです。ただし、Rollout も万能ではなく、元の注意重みの情報を集約しているにすぎません。出力を完全に説明できるわけではありません。
3.2 Feature Importance
Feature Importance は、入力トークンのうちどれが出力に強く関わったかを見ようとする方法です。Attention と組み合わせると、「どの単語を見ていたか」をより具体的に追いやすくなります。
たとえば次の文を考えます。
“The cat sat on the mat because it was tired”
ここで it が cat を指すと解釈したい場合、cat と it の両方が高く出ると、参照解決の手がかりになります。一方で、because や tired も一定の重みを持っていれば、文全体の状態説明に関わっていると読めます。
重要なのは、Feature Importance は「出力に強く関わりそうな候補」を示すものであって、真の因果を証明するものではないという点です。
3.3 誤例分析
可視化が本当に役に立つのは、正解だけを見ているときではなく、間違えたときです。誤答のときにどこへ注目していたかを見ると、モデルの弱点が見えやすくなります。
誤りは、ざっくり次の三つに分けて考えると整理しやすいです。
| 誤りの種類 | 何が起きているか | 典型例 |
|---|---|---|
| 文法的誤り | 文法マーカーを見落とす | 主語と述語の不一致 |
| 知識的誤り | 事実に関わる語を取り違える | 首都や国名の誤認 |
| 文脈理解の誤り | 長距離依存を見逃す | 文頭の否定を拾えない |
たとえば、Is Tokyo the capital of France? に対して誤って Yes, Tokyo is the capital と返した場合、France への注視が弱かった可能性があります。ただし、ここでも Attention だけで断定はできません。誤答の原因候補を絞るための材料として使うのが妥当です。
4. 可視化結果を読むときの注意点
Attention 可視化は便利ですが、読み方を間違えると逆に誤解を増やします。ここはかなり重要です。
4.1 よくある誤解
| 誤解 | 実際にはどうか |
|---|---|
| 高注視度 = 因果関係 | そうとは限らない。参加の度合いを示すだけの場合がある |
| 単一層の Attention で全体が分かる | 出力は複数層の相互作用で決まる |
| 可視化だけで完全に理解できる | Attention は解釈の一部にすぎない |
特に最初の誤解は多いです。Attention が高いからといって、そのトークンが最終出力を決定したとまでは言えません。Attention は重要な手がかりですが、FFN、残差接続、層の積み重ねを含む全体の中で考える必要があります。
4.2 正しい読み方
Attention 可視化は、分析者のための正しいアプローチとして次のように使うと無理がありません。
仮説検証サイクル
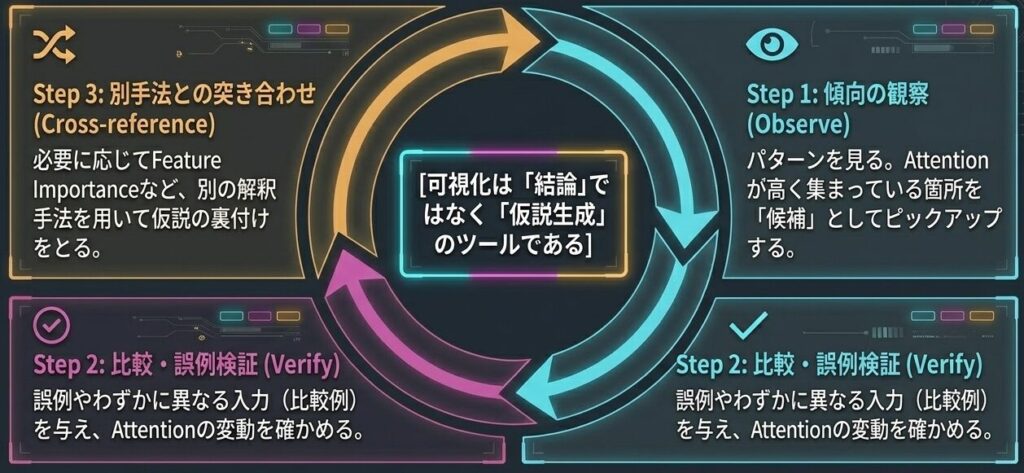
- まず傾向を見る
- その後に誤例や比較例で確かめる
- 必要なら別の解釈手法と突き合わせる
解釈の主役は Attention ですが、検証の主役は別の分析手法になることもあります。可視化を「結論」ではなく「仮説生成」として扱うと、読み違えが減ります。
5. 使うときの実践的な視点
可視化を実務で使うなら、ツール選びより先に「何を確かめたいか」を決めたほうがよいです。目的が決まれば、必要な粒度も自然に決まります。
5.1 代表的なツール
| ツール | 向いていること |
|---|---|
| BertViz | ヘッド別・層別の Attention を対話的に見る |
| Attention Flow | 層間の情報の流れを追う |
| Transformers Interpret | Feature Importance の算出と可視化 |
5.2 実装時の観点
実装上は、次のようなポイントを押さえると比較しやすくなります。
- Attention weight を保存しておく
- トークン境界を明示する
- 層番号とヘッド番号を一緒に出す
- 正答例と誤答例を並べて見る
- 異なるモデル同士も比較する
ここでの目的は、きれいな図を作ることではありません。比較できる状態を作ることです。比較できれば、どの層が何を拾いやすいか、どの誤りが再現しやすいかを追いやすくなります。
6. まとめ
Attention の可視化は、LLM のブラックボックス性を少しずつほどくための有力な手段です。ただし、Attention が高いからといって、そのまま因果関係まで言い切れるわけではありません。ここを取り違えると、可視化は説明材料ではなく、誤解の材料になります。
この記事で押さえたかった判断基準は次の通りです。
- 何に注目しているかを見たいなら Attention のパターンを見る
- 複数層をまたいだ影響を見たいなら Attention Rollout を使う
- どの入力が効いたかを見たいなら Feature Importance を併用する
- 間違いの原因を知りたいなら 誤例分析とセットで読む
- 断定ではなく仮説として扱う
次の記事では、データ品質や評価の話へ進みます。Attention の可視化で得た気づきを、評価体系全体の中でどう扱うかを整理していきます。
7. 今回のブログの考察
Attention の可視化は、LLM の内部を完全に説明するための道具というより、モデルの振る舞いを観察して仮説を立てるための入口だと分かります。Multi-Head Attention でどの関係を拾っているか、Rollout で層をまたいだ流れがどう見えるか、誤例でどこを見落としていたかをたどると、少なくとも「なぜその出力になったのか」を考える材料は増えます。ただし、その材料をそのまま因果関係として扱うと、読み違いが起きやすい点もこの記事で確認しました。
実務で難しいのは、可視化で見えたものをどこまで信用するかです。きれいなヒートマップが出たとしても、それだけでモデルの理解が完結したわけではありません。むしろ大切なのは、可視化をきっかけにして、誤答分析や比較検証へ進めることです。つまり、Attention は答えそのものではなく、次に何を調べるべきかを教えてくれる補助線として使うのが自然です。
その意味で、このテーマの本質は「説明できたか」ではなく、「説明の手がかりをどう扱うか」にあります。可視化を過信せず、かといって無視もしない。そのバランスを取れるようになると、Attention は単なる図ではなく、モデル改善のための実務的な観察装置になります。
📖 参考文献
主要論文
-
Arora, S., Liang, Y., & Ma, T. (2016): “A Simple but Tough-to-Beat Baseline for Sentence Embeddings”, ICLR 2017
-
Cer, D., et al. (2018): “Universal Sentence Encoders”, arXiv
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019): “BERT: Pre-training of Deep Bidirectional Transformers”, NAACL 2019
📚 シリーズ案内
ブログD:詳細設計書編では、LLMの評価体系とベンチマーク管理を解説しています。
このシリーズの記事:
- LLM評価の3層構造
- 標準ベンチマークの詳細解説
- データ汚染検出とドメイン横断性能
- Attentionの可視化と解釈(この記事)
- データ品質測定とモニタリング体制
関連シリーズ:
- ブログB:実装詳細編 – Multi-Head Attentionの詳細実装
- ブログA:基礎理論編 – Attentionメカニズムの理論
前の記事: データ汚染検出とドメイン横断性能
次の記事: データ品質測定とモニタリング体制

コメント