 現象の理解
現象の理解 LLM【スケール則:現象の理解 D-5】
Transformer、MoE、ViT等のアーキテクチャ別スケーリング特性を比較。α/β係数の違い、効率スコア、選択戦略を詳解。
現象の理解  最適配分戦略
最適配分戦略  事前学習
事前学習  実装詳細
実装詳細  実装詳細
実装詳細  実装詳細
実装詳細  基礎理論
基礎理論  基礎理論
基礎理論 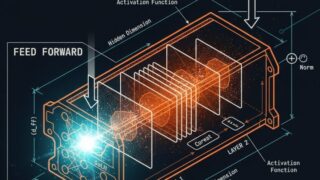 基礎理論
基礎理論  基礎理論
基礎理論