
前回までの流れで、同じ学習済みモデルでも推論設計次第で性能が変わることを見てきました。では次に実務で問題になるのは何かというと、「改善アイデアを本番で安定して動かせるか」です。
推論は、速くするだけでも、精度を守るだけでも不十分です。メモリ制約、遅延要件、数値の不安定化が同時に効いてくるため、運用では常にトレードオフ判断が発生します。この記事では、推論最適化と数値安定性を切り分けずに扱い、どこから手を付けると失敗しにくいのかを実装目線で整理します。
1. なぜ推論最適化と数値安定性を同時に見るのか?
推論最適化は、速度とメモリの改善が主目的です。数値安定性は、出力の再現性と品質維持が主目的です。
実務では、この 2 つを分けて考えると失敗しやすくなります。例えば、量子化で速度が上がっても数値誤差が増え、回答品質が下がることがあります。逆に、安定性を優先しすぎると、レイテンシ要件を満たせません。
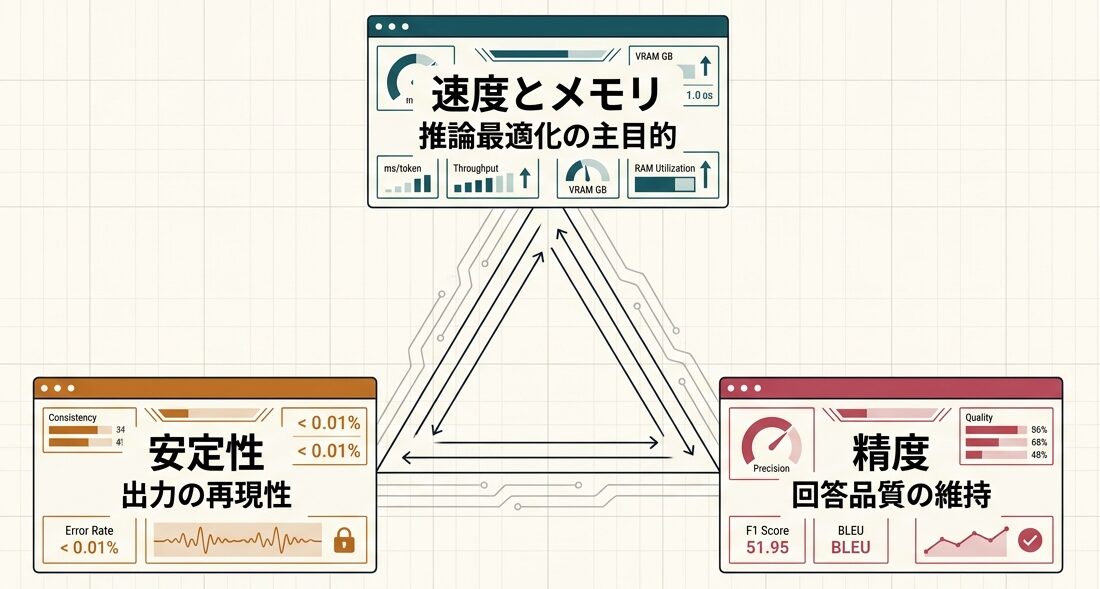
要点はシンプルです。推論パイプラインは、精度・速度・安定性の 3 軸で同時に設計する必要があります。
最小限の比較軸をコード化すると、次のように整理できます。
from dataclasses import dataclass
@dataclass
class EvalResult:
quality: float # 0.0 - 1.0
latency_ms: float
stability_score: float # 0.0 - 1.0
def overall_score(result: EvalResult, wq=0.5, wl=0.3, ws=0.2) -> float:
latency_score = 1.0 / (1.0 + result.latency_ms / 1000.0)
return wq * result.quality + wl * latency_score + ws * result.stability_score推論パイプラインは、これら3軸で同時に設計する必要がある。 最適化(速く・軽くする)と安定性(品質を守る)を分けて考えると、本番運用で必ず破綻してしまう。
2. 推論ボトルネックはどこにあるのか?
大規模モデル推論で最初に詰まりやすいのは、KV キャッシュのメモリ消費です。シーケンス長が伸びるほど、メモリ負荷は急増します。
KV キャッシュの目安は次の式で見積もれます。

この式の seq_len と batch が運用で増えやすいため、推論コストの支配要因になりやすいです。
小さな確認用コードは次の通りです。
def kv_cache_memory_gb(n_layers, n_heads, d_head, seq_len, batch_size, bytes_per_elem=2):
memory_bytes = 2 * n_layers * n_heads * d_head * seq_len * batch_size * bytes_per_elem
return memory_bytes / (1024 ** 3)
print(kv_cache_memory_gb(80, 64, 128, 2048, 1, 2)) # fp16 想定
print(kv_cache_memory_gb(80, 64, 128, 2048, 1, 1)) # fp8/int8 想定式のseq_lenとbatch が運用で動的に増えやすいため、推論コストの絶対的な支配要因となる。
3. メモリ最適化は何から始めるべきなのか?
現場では、次の順序で試すと判断しやすいです。
- KV キャッシュ量子化
- 注意機構のスパーシティ化
- ページング(GPU から CPU への退避)
それぞれの特徴は次の通りです。
| 手法 | 期待効果 | 主なリスク | 向いている場面 |
|---|---|---|---|
| KV キャッシュ量子化(fp16→fp8/int8) | メモリ削減が大きい | 精度劣化の可能性 | メモリ制約が厳しい推論 |
| 注意スパーシティ | 計算量とメモリの削減 | 長距離依存の性能低下 | 長文推論で速度を優先 |
| ページング | OOM 回避 | 遅延増加 | 単一 GPU で大型モデル運用 |
失敗しやすいのは、「削減率」だけ見て採用することです。実際は、タスクごとの品質変化を同時に計測しないと判断を誤ります。
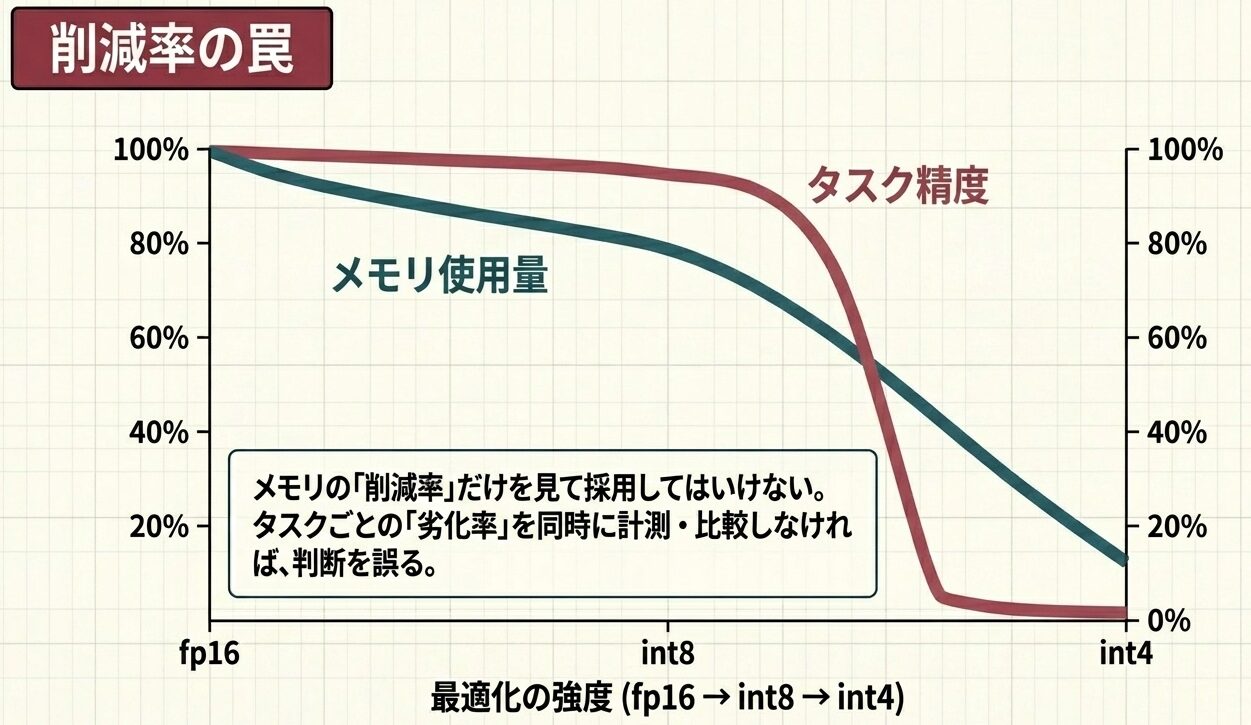
以下は、削減率と劣化率を同時に比較する最小例です。
def memory_reduction_ratio(baseline_gb: float, optimized_gb: float) -> float:
return (baseline_gb - optimized_gb) / baseline_gb
def quality_drop_ratio(baseline_score: float, optimized_score: float) -> float:
return (baseline_score - optimized_score) / baseline_score
baseline_mem = 24.0
fp8_mem = 12.0
baseline_quality = 0.842
fp8_quality = 0.831
print("memory_reduction:", f"{memory_reduction_ratio(baseline_mem, fp8_mem):.1%}")
print("quality_drop:", f"{quality_drop_ratio(baseline_quality, fp8_quality):.1%}")4. 数値安定性はどこで壊れやすいのか?
数値不安定は、突然の NaN だけではありません。出力の揺れ、層ごとの活性化の偏り、推論再現性の低下として現れることもあります。
特に監視すべきは次の 3 点です。
- 活性化分布(平均、標準偏差、最大絶対値)
- 勾配ノルム(学習・微調整を行う場合)
- 精度形式ごとの差分(fp16、bf16、fp32)
「推論だけだから勾配は不要」と考えがちですが、実務では LoRA 追加学習や継続学習が併走することが多く、同一環境で安定性課題が再発するケースがあります。
活性化の偏りを早期に検知するための最小監視コードは次の通りです。
import torch
def activation_health_stats(x: torch.Tensor) -> dict:
return {
"mean": float(x.mean()),
"std": float(x.std()),
"max_abs": float(x.abs().max()),
"has_nan": bool(torch.isnan(x).any()),
"has_inf": bool(torch.isinf(x).any()),
}
def is_unstable(stats: dict, max_abs_threshold: float = 100.0, std_low: float = 1e-3) -> bool:
if stats["has_nan"] or stats["has_inf"]:
return True
if stats["max_abs"] > max_abs_threshold:
return True
if stats["std"] < std_low:
return True
return False5. 混合精度はどう使い分けるべきなのか?
一般的には、次の使い分けが現実的です。
- bf16: 安定性と性能のバランスが取りやすい
- fp16: 高速化しやすいが、スケーリング管理が必要
- fp32: 安定だがコストが重い
ただし、これはハードウェアと実装依存です。したがって、断定ではなく「検証前の仮説」として扱うのが安全です。
実務では以下の順で確認すると、意思決定が速くなります。
- 同一データで 3 精度を短時間ベンチマーク
- レイテンシ、スループット、品質指標を同時記録
- 品質劣化が許容範囲内なら低精度を採用
検証を短時間で回すためのベンチマーク骨子は次のように置けます。
import time
def benchmark_inference(run_fn, n_warmup=5, n_iter=30):
for _ in range(n_warmup):
run_fn()
start = time.perf_counter()
for _ in range(n_iter):
run_fn()
elapsed = time.perf_counter() - start
return {
"avg_latency_ms": (elapsed / n_iter) * 1000,
"throughput_iter_per_sec": n_iter / elapsed,
}ハードウェアと実装に依存するため、断定せず「検証前の仮説」として扱うのが安全。
6. 実務で起きやすい失敗は何か?
典型的な失敗は次の 3 つです。
- OOM 回避だけを優先し、出力品質評価を省略する
- 開発環境で安定していた設定を、本番トラフィックへそのまま適用する
- 監視指標を持たず、障害後に原因を追えなくなる
例えば、量子化でメモリを半減できても、ドメイン固有タスクで誤答率が上がる場合があります。このとき重要なのは「最適化が失敗した」のではなく、「何を最適化対象に置いたか」がずれていたと捉えることです。
本番反映前に品質回帰を止めるための簡易ガード例です。
def should_block_release(baseline_acc: float, candidate_acc: float, max_drop: float = 0.01) -> bool:
drop = baseline_acc - candidate_acc
return drop > max_drop
if should_block_release(0.84, 0.825, max_drop=0.01):
print("BLOCK: quality regression exceeded threshold")7. 本番導入前チェックリスト
- KV キャッシュが主要ボトルネックか、式と実測の両方で確認したか?
- 量子化後の品質低下を、主要タスクで測定したか?
- レイテンシ、スループット、品質の 3 指標を同時に記録したか?
- fp16、bf16、fp32 の比較結果を残したか?
- 異常検知指標(NaN、急激な分布変化、遅延スパイク)を監視に組み込んだか?
- 本番相当トラフィックで再検証したか?
チェックリストを CI で強制する場合の最小イメージです。
def validate_release_gate(metrics: dict) -> None:
assert metrics["quality_drop"] <= 0.01, "quality regression"
assert metrics["p95_latency_ms"] <= 1200, "latency regression"
assert metrics["nan_incidents"] == 0, "nan detected"
release_metrics = {
"quality_drop": 0.006,
"p95_latency_ms": 980,
"nan_incidents": 0,
}
validate_release_gate(release_metrics)8. まとめ
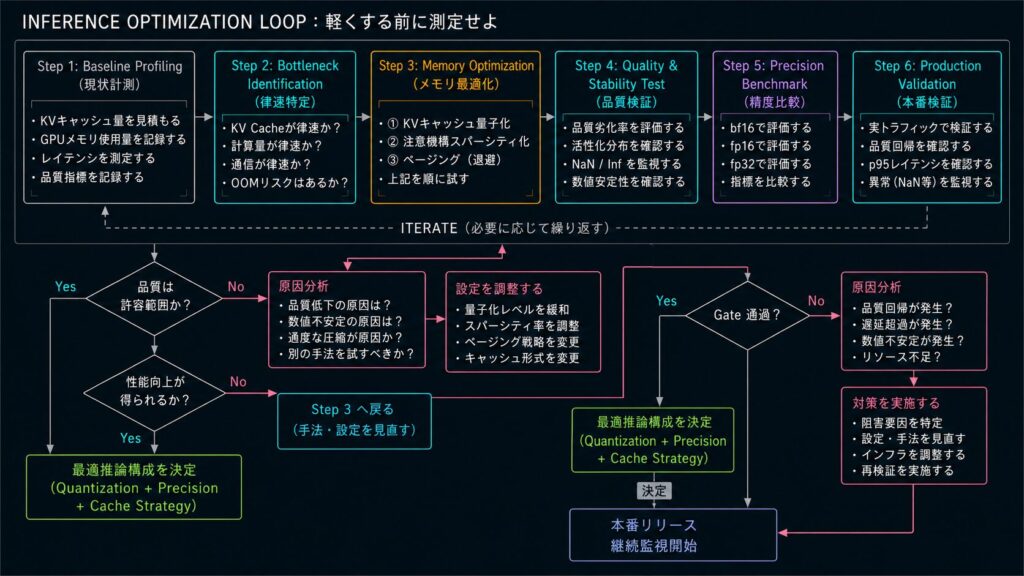
推論最適化は「軽くする技術」、数値安定性は「壊さない技術」です。どちらか一方だけでは、実務で継続運用できる推論基盤にはなりません。
重要なのは、改善施策を単発で入れることではなく、精度・速度・安定性を同じ指標セットで評価し続けることです。この運用があると、最適化の成否を感覚ではなく根拠で判断できるようになります。
9. 今回のブログの考察
推論最適化の議論は、しばしば「どれだけ速くできるか」に偏りがちです。しかし実務で本当に問われるのは、「速くなった状態を安全に維持できるか」です。今回扱った内容を通して見えてくるのは、最適化と安定性は別々の課題ではなく、同じ運用設計の中で扱うべきだという点です。
また、数値安定性はトラブル発生時に初めて意識されることが多いですが、本来は事前に監視すべき設計項目です。つまり、最適化とは魔法のテクニックではなく、失敗を先回りして管理する地道な仕組みづくりだと言えます。この視点を持てると、推論改善は単なる速度競争ではなく、信頼できるサービス品質への投資として位置づけられるはずです。
参考文献
- Micikevicius, P., et al. (2017). “Mixed Precision Training.” NVIDIA.
- Sheng, Y., et al. (2023). “FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU.”
コメント