前回までの記事では、スケール則をどう測るか、どう配分するか、どう計算効率を上げるかを見てきました。ここまで読むと、スケール則はかなり頼れる設計指針に見えますが、実務ではそのまま当てはまらない場面も出てきます。
この記事では、A4 で見た Chinchilla 則を前提にしつつ、どんな条件でスケール則が崩れやすいのかを整理します。データ品質、アーキテクチャ、計算環境の 3 つを中心に、どこで例外が生まれるのかを、実務で判断しやすい順番で見ていきます。
1. スケール則の限界とは何か?
Chinchilla 則は、固定計算予算の下でパラメータ数 N とデータ量 D のバランスを考えるための強い目安です。ただし、これは「いつでも同じ比率で成立する普遍法則」ではありません。
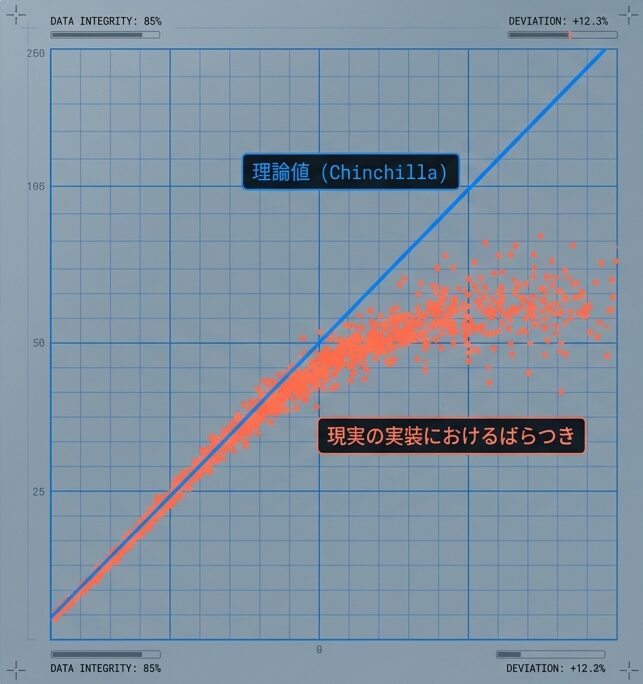
実務で問題になるのは、理論が間違っているというより、前提条件がずれていることです。データが汚れていたり、モデルの形が違っていたり、GPU の制約が強かったりすると、同じ比率を入れても期待した挙動にならないことがあります。
つまり、この章で見たいのは「スケール則が無効になる瞬間」ではなく、「どの条件が変わると、どこまでずれるのか」です。
スケール則が無効になるのではなく、「どの条件が変わると、どこまで偏差が生じるのか」を把握することが実務の第一歩です。
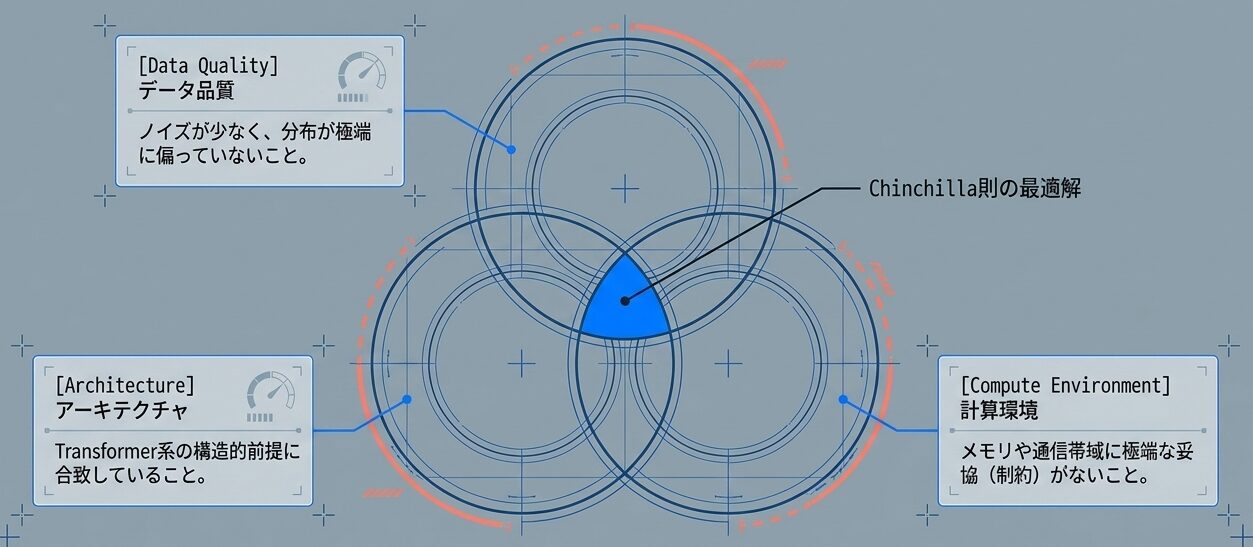
2. まず押さえるべき前提は何か?
Chinchilla 則が素直に効きやすいのは、少なくとも次の条件が比較的そろっているときです。
| 前提 | 何が必要か | ずれたときに起きやすいこと |
|---|---|---|
| データセット品質 | ノイズが少なく、分布が極端に偏っていないこと | 同じトークン数でも学習効率が下がる |
| アーキテクチャ | Transformer 系の前提に近いこと | 最適な D/N 比が変わる可能性がある |
| 計算環境 | メモリと通信帯域に極端な制約がないこと | 望むサイズまで素直に学習できない |
この 3 つのどれかが崩れると、理論上の最適比はそのままでは使いにくくなります。たとえば、計算式上は 20N 近辺がよさそうでも、実際にはモデルを載せるだけで苦しい環境や、雑音の多いデータが混ざる環境では、別の調整が必要になります。
3. データ品質が低いと何が変わるのか?
最も分かりやすい例はデータ品質です。きれいなデータとノイズの多いデータを同じ「1 トークン」として扱っても、学習への効き方は同じではありません。
たとえば、社内ドキュメント、重複の多い収集データ、文法が崩れたテキストが混ざっている場合を考えます。見かけ上のトークン数は増えても、モデルが学ぶべきパターンは薄まります。このときは、同じ性能に届くまでにより多くのデータを要することがあります。
| データ状態 | 学習効率 | 実務で起きやすいこと |
|---|---|---|
| 高品質 | 高い | 少ないデータでも改善しやすい |
| 中品質 | 中程度 | 追加データの効果が徐々に鈍る |
| 低品質 | 低い | トークンを増やしても伸びにくい |
ここで大事なのは、低品質データだから即失敗、という話ではないことです。重要なのは、同じ比率をそのまま適用してよいかを疑うことです。実務では、フィルタリングや重複除去をしたあとで、改めて配分を見直すほうが筋が通ります。
実装では、まずデータの重複率やノイズ率をざっくり見て、使えるトークン数を見積もり直すと判断しやすくなります。以下は、そのための最小例です。
from dataclasses import dataclass
@dataclass
class DatasetQualityReport:
total_tokens: int
duplicate_tokens: int
noisy_tokens: int
@property
def usable_tokens(self) -> int:
return max(self.total_tokens - self.duplicate_tokens - self.noisy_tokens, 0)
@property
def quality_ratio(self) -> float:
return self.usable_tokens / self.total_tokens if self.total_tokens else 0.0
def estimate_required_tokens(base_tokens: int, quality_ratio: float) -> int:
"""品質低下を考慮した必要トークン数を見積もる"""
if quality_ratio <= 0:
raise ValueError("quality_ratio must be positive")
return int(base_tokens / quality_ratio)
report = DatasetQualityReport(
total_tokens=100_000_000,
duplicate_tokens=12_000_000,
noisy_tokens=18_000_000,
)
print(f"usable_tokens={report.usable_tokens}")
print(f"quality_ratio={report.quality_ratio:.2f}")
print(f"required_tokens={estimate_required_tokens(20_000_000, report.quality_ratio)}")ノイズデータとクリーンなデータを同じ「1トークン」として計算してはいけません。 見かけのデータ量が増えても、学習効率は比例せず「実質的な学習価値」は希釈されます
4. アーキテクチャが違うとどうずれるのか?
スケール則は主に Transformer を強く意識して整理されてきました。つまり、CNN や RNN、Hybrid 構成にそのまま持っていくと、係数が変わる可能性があります。
| アーキテクチャ | 傾向 | 読み取り方 |
|---|---|---|
| Transformer | 基準として扱いやすい | Chinchilla 則の中心的な前提 |
| CNN | 係数がやや変わることがある | 同じ D/N 比で比較しないほうがよい |
| RNN / LSTM | スケールの効き方が異なりやすい | 単純な外挿は危険 |
| Vision Transformer | Transformer 系に近い | 近い前提で考えやすい |
たとえば、画像領域では ViT が NLP の Transformer に近い振る舞いを見せる場面がありますが、CNN や RNN のように再帰や局所受容野が強い構造では、同じ直感がそのまま使えないことがあります。ここでよくある失敗は、「LLM でよく効いた比率だから、別アーキテクチャでも同じだろう」と思ってしまうことです。
実務では、アーキテクチャごとに小さく検証してから比率を決めるほうが安全です。理論を捨てるのではなく、理論を初期値として使う感覚が近いです。
構造が異なる場合、既存の比率を盲信せず、必ず小規模な検証を挟んで係数をチューニングし直すこと。
5. 計算環境の制約はどう効くのか?
スケール則の理論は、計算資源が十分にある前提で語られやすいです。けれど、実際の現場ではメモリが足りない、通信が遅い、あるいは 1 台の GPU に収まらない、という理由で理論値どおりに試せないことがあります。
その代表例が Gradient Checkpointing です。中間活性を全部保存せず、必要なときに再計算することでメモリを節約できますが、そのぶん計算量は増えます。
| 手法 | メリット | 代償 |
|---|---|---|
| Gradient Checkpointing | メモリ使用量を抑えられる | 再計算で処理時間が増える |
| 大きめのバッチ | GPU を使いやすい | メモリを多く使う |
| 分散学習 | 大きいモデルを扱いやすい | 通信オーバーヘッドが増える |
たとえば、モデルがメモリに収まらずに断念するよりは、Gradient Checkpointing を使って学習を通すほうが現実的なことがあります。ただし、その場合は「理論上の最適比をそのまま守れた」とは言いにくくなります。実際には、計算時間とのトレードオフを受け入れた設計になります。
実務では、どれくらい計算が増えるのかを先に見積もっておくと、メモリ節約の価値を判断しやすくなります。
def compute_checkpoint_overhead(checkpoint_every: int) -> dict:
"""Gradient Checkpointing による追加計算を概算する"""
if checkpoint_every < 1:
raise ValueError("checkpoint_every must be >= 1")
overhead_ratio = (checkpoint_every - 1) / checkpoint_every
total_multiplier = 1 + overhead_ratio
return {
"overhead_ratio": overhead_ratio,
"total_multiplier": total_multiplier,
"additional_compute_percent": overhead_ratio * 100,
}
for checkpoint_every in [1, 2, 4, 8]:
overhead = compute_checkpoint_overhead(checkpoint_every)
print(
f"{checkpoint_every} layers -> +{overhead['additional_compute_percent']:.1f}% "
f"({overhead['total_multiplier']:.2f}x)"
)この見積もりを入れておくと、「メモリに収まるから使う」のか、「計算コストを払ってでも通す」のかを決めやすくなります。
「理論上の最適比」を犠牲にしてでも、計算時間というコストを払って実装の壁を越える決断が実務には不可欠です。
6. どんな失敗が起きやすいのか?
限界と例外の議論でありがちな失敗は、理論の不一致をすぐに理論否定へつなげてしまうことです。多くの場合は、理論が壊れているのではなく、比較条件がずれているだけです。
よくあるつまずきは次の通りです。
| 失敗例 | 何が問題か | どう直すか |
|---|---|---|
| ノイズデータを高品質データと同列に扱う | トークン数の意味が変わる | フィルタリング後に再評価する |
| 別アーキテクチャに同じ D/N 比を当てる | 前提が違う | 小規模実験で比率を再確認する |
| メモリ不足を理論誤差と混同する | 実装制約を見落とす | Checkpointing やバッチ調整を先に検討する |
| 1 回の実験だけで結論を出す | ばらつきを見逃す | seed や条件を変えて再確認する |
このあたりは、実験を急いだときほど起こりやすいです。スケール則は便利ですが、条件の違いを吸収してくれるわけではありません。だからこそ、理論を入れたあとに「何が違うのか」を見る姿勢が重要です。
7. どの順序で試せばよいのか?
限界や例外にぶつかったときは、いきなり理論を捨てるのではなく、原因を小さく切り分けるのがよいです。
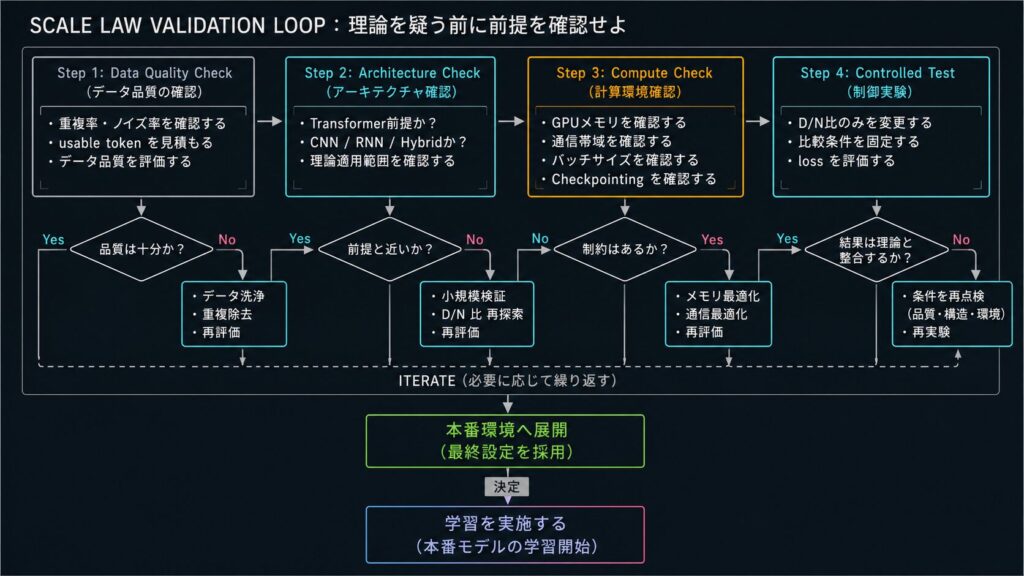
- まずデータ品質を確認する
- 次にアーキテクチャが想定と近いかを見る
- それでも合わないなら、計算環境の制約を疑う
- 条件をそろえたうえで、D/N 比や実験設定を少しずつ振る
この順番にしておくと、理論が外れているように見えても、実は前提条件が違っただけかどうかを追いやすくなります。逆に、全部を一度に変えると、どこが原因か分からなくなります。
実務では、まず小規模で比率を確認し、そのあとに本番環境へ広げるほうが安全です。理論は出発点として強いですが、最終判断は必ず自分のデータ、モデル、計算環境で下す必要があります。
8. まとめ
スケール則は、LLM の設計を考えるうえで非常に強い目安です。ただし、その前提はいつも同じではありません。データ品質、アーキテクチャ、計算環境のどれかが変われば、最適な比率もずれます。
今回の記事で見たかったのは、Chinchilla 則が間違っているかどうかではなく、どこで条件が変わるとそのまま使えなくなるか、という点です。そこを押さえておくと、理論を盲信せずに、必要な場面でだけうまく使えるようになります。
9. 今回のブログの考察
スケール則の限界を考えるとき、重要なのは「理論が外れる例外を探すこと」よりも、「どの条件が揃っていれば理論がよく働くか」を見極めることだと言えます。今回の記事で見たように、データ品質が低ければ同じトークン数でも効率は落ちますし、アーキテクチャが違えば係数は変わります。さらに、計算環境の制約が強ければ、理論上の最適解をそのまま試すことすらできません。
実務では、この見極めを飛ばして「スケール則どおりにやったのにうまくいかない」と感じることが起こりがちです。けれど、その多くは理論の失敗ではなく、前提のズレです。だからこそ、スケール則を使うときは、比率を覚えること以上に、データ、モデル、計算資源のどこが違うのかを点検する姿勢が大切です。
つまり、この章の本質は、スケール則を万能の答えとして扱わず、条件が揃ったときにだけ強い判断材料として使うことにあります。そこを押さえておくと、例外に出会っても慌てずに原因を切り分けられますし、次の実験設計もずっと具体的になります。
参考文献
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.
- Chen, T., et al. (2016). “Training Deep Nets with Sublinear Memory Cost.”

コメント