
残差接続と層正規化の詳細実装
12層以上の深いTransformerを安定して訓練するには、残差接続(Skip Connection) と 層正規化(Layer Normalization) が不可欠です。本記事では、これらの技術がなぜ必要で、どう実装するかを詳解します
残差接続と層正規化の詳細については下記を参照してください。
【残差接続と層正規化の詳細】


残差接続 (Skip Connection) の効果
LLMの「深さ」を支える勾配消失防止と学習安定化の技術
なぜ「深さ」が課題になるのか?

基本的な計算フロー
残差接続:情報の「近道」を作る

入力』を変換後の出力 $F$($x$) にそのまま加算します。重みがゼロでも、情報の原本(Identity)が保持されます。
入力:x (32, 100, 768)
↓
[Attention または FFN 処理]
↓
中間出力:y = f(x)
↓
残差接続を適用
↓
最終出力:x + y (要素ごとの加算)
↓
出力:(32, 100, 768)ポイント:入力 x がそのまま出力に加算される「近道(ショートカット)」が存在
勾配伝播への効果
通常のニューラルネット(残差接続なし):
連鎖律による「掛け算」の繰り返し。1より小さい値が続くと、勾配はゼロに近づきます(勾配消失)。
損失 L
↓
∂L/∂y12 = ∂L/∂y12 (層12の勾配)
↓
∂L/∂y11 = ∂L/∂y12 × ∂y12/∂y11 (層11の勾配)
↓
... (層を遡るたびに勾配が小さくなる)
↓
∂L/∂y1 ≈ 0 (初期層の勾配が消失!)
問題:12層の掛け算で勾配が0.9^12 ≈ 0.28 に減衰残差接続ありの場合:
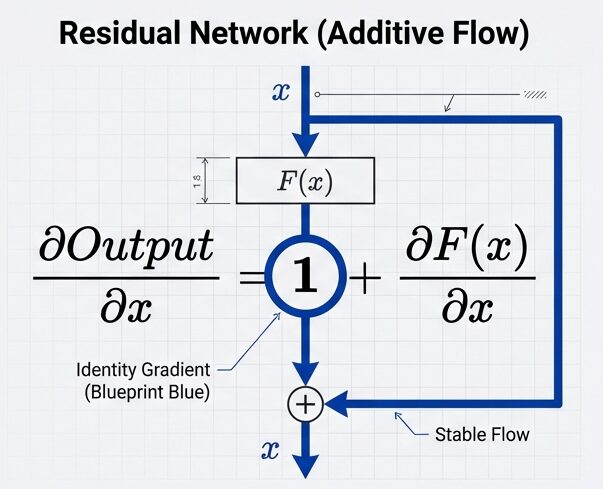
勾配に「+1」の項が含まれるため、どれだけ層が深くても勾配が消失せず、初期の層まで確実に届きます。
∂L/∂y = ∂L/∂output × ∂output/∂y
= ∂L/∂output × (∂f(y)/∂y + 1) ← "+1" が重要!
この "+1" により、勾配が0でない値が保証される
→ 深い層でも勾配が消失しない学習に与える影響
もし層fが有用でなければ:
∂f(x)/∂x ≈ 0
→ y = f(x) + x ≈ x
→ 層が「何もしない」を学習できる
つまり、12層の深さでも、
不必要な層をスキップして、
有用な層に集中できる構造になる。
これが「ResNet」や「HighwayNetwork」の着想源
- スキップ接続の必要性は?
- スキップ接続は、ある層の出力をそのまま入力に足す仕組みです。
- これにより、逆伝播で勾配が「近道」を通って伝わりやすくなり、勾配消失が起きにくくなります。
- 結果としてモデルは元の入力情報を保ちながら、その「差分」だけを学べるため、多くの層を重ねても学習が安定し、高性能を出せます。
レイヤー正規化 (Layer Normalization) の実装
層正規化:データの分布を整える
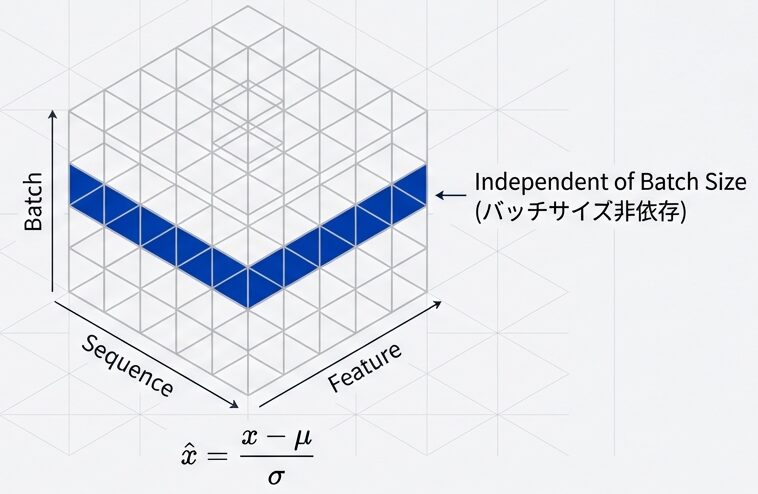
- 目的:各層の入力を平均0、分散に正規化し、学習を安定化させる
- 特徴:バッチサイズやシーケンス長に依存しないため、Transformerに最適
計算手順

入力ベクトル:x = [x1, x2, x3, ..., x_d] (1トークンのベクトル)
ステップ1:平均を計算
μ = (1/d) × Σ x_i
ステップ2:分散を計算
σ² = (1/d) × Σ (x_i - μ)²
ステップ3:正規化
x_norm_i = (x_i - μ) / √(σ² + ε)
ε は数値安定性のための小さい値(例:1e-5)
ステップ4:スケーリングとシフト(学習可能パラメータ)
y_i = γ × x_norm_i + β
γ (ガンマ):スケーリング係数(学習対象)
β (ベータ):シフト係数(学習対象)正規化によって失われる表現力を、ネットワークが必要に応じて復元できるように$γ$($scale$)と$β$($shift$)を導入します。
数値例
入力:x = [2.0, -1.0, 3.0, 0.5]
ステップ1:平均
μ = (2.0 - 1.0 + 3.0 + 0.5) / 4 = 1.125
ステップ2:分散
σ² = ((2.0-1.125)² + (-1.0-1.125)² + (3.0-1.125)² + (0.5-1.125)²) / 4
= (0.766 + 4.516 + 3.516 + 0.391) / 4
= 2.297
ステップ3:正規化(σ = √2.297 ≈ 1.516)
x_norm = [(2.0-1.125)/1.516, (-1.0-1.125)/1.516,
(3.0-1.125)/1.516, (0.5-1.125)/1.516]
≈ [0.576, -1.405, 1.236, -0.407]
ステップ4:スケーリング(γ=1, β=0の場合)
y ≈ [0.576, -1.405, 1.236, -0.407]
結果:平均0、分散1に正規化されたベクトル正規化の効果
正規化前の分布(不均一):
[2.0, -1.0, 3.0, 0.5]
平均:1.125、分散:2.297
正規化後の分布(均一):
≈ [0.576, -1.405, 1.236, -0.407]
平均:0、分散:1
利点:
- 学習が安定する(スケールに依存しない)
- 初期化の影響が減る
- 学習率をより大きくできる
- 収束が速くなるDropout:過学習防止の正則化手法
訓練中にニューロンをランダムに一時的に無効化することで、過学習を防ぎます。
Dropoutの原理
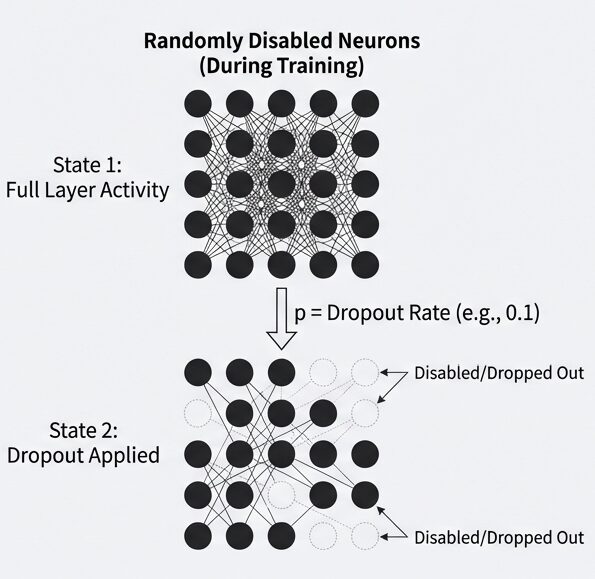
訓練時の動作:
入力ベクトル:x = [x1, x2, x3, x4, x5] (5次元)
ドロップアウト確率 p = 0.5 の場合:
- 各要素について、50% の確率でゼロに設定
例:
マスク = [1, 0, 1, 0, 1] (ランダムに生成)
適用後:y = [x1×1, x2×0, x3×1, x4×0, x5×1]
= [x1, 0, x3, 0, x5]
推論時の動作:
Dropout は適用しない(すべてのユニットを使用)
出力を(1-p)で正規化:y_inference = y_train / (1 - p)Transformerでの適用位置
Transformer ブロック内での Dropout 配置:
入力:x
↓
Multi-Head Attention
↓
Dropout(p=0.1)← 1つ目
↓
残差接続 + LayerNorm
↓
FFN(線形層1 + 活性化 + 線形層2)
↓
Dropout(p=0.1)← 2つ目
↓
残差接続 + LayerNorm
↓
出力:y設定の一般的な値:
- Attention 出力後:p = 0.1(軽い)
- FFN 出力後:p = 0.1(軽い)
- Pre-training では低め(過度な正則化を避ける)
- Fine-tuning では高め(過学習防止を重視)
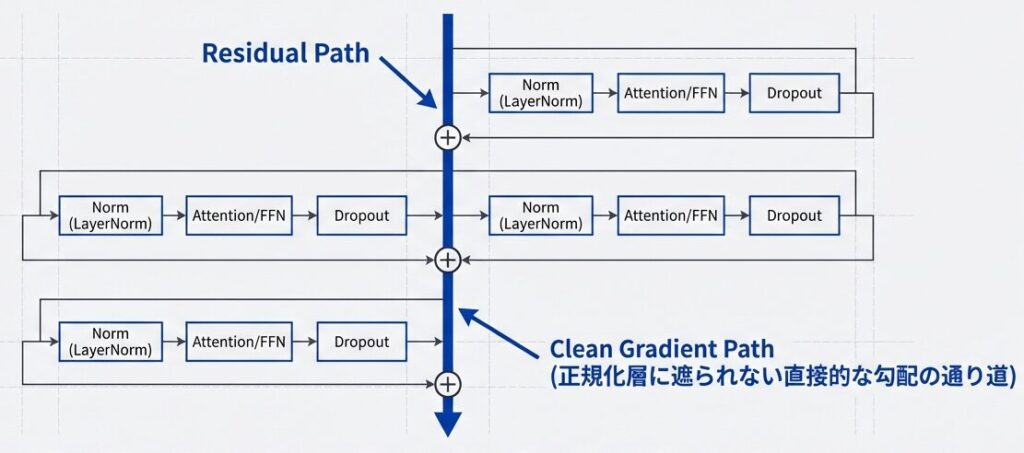
Pre-norm vs Post-norm:正規化タイミングの選択
正規化のタイミングには、入力側で行うPre-normと出力側で行うPost-normの2種類があり、それぞれ学習安定性や互換性で利点が異なります。
配置の選択

Post-norm(従来的)
構造:
Attention → [出力] → LayerNorm → 残差接続
↓
FFN → [出力] → LayerNorm → 残差接続
計算グラフ:
x → Attention(x) → LN → + x → y
(Attention の出力を正規化)特徴:
- 各変換後に正規化
- 比較的安定(小規模モデルで有効)
- 深いモデルでは勾配が不安定になる傾向
Pre-norm(現代的)
構造:
x → LayerNorm → Attention → [出力] → 残差接続 → y
x → LayerNorm → FFN → [出力] → 残差接続 → y
計算グラフ:
x → LN → Attention → + x → y
(入力を正規化してから Attention へ)特徴:
- 各変換前に正規化
- より深いモデルで安定(GPT-3等で採用)
- 勾配流がより効率的
性能比較
なぜ現代のLLMはPre-normを選ぶのか?
モデル規模による比較:
小規模(<1B パラメータ):
Post-norm: 安定、訓練が容易
Pre-norm: やや不安定
→ Post-norm 推奨
中規模(1-10B):
Post-norm: 勾配が薄れやすい
Pre-norm: より安定
→ Pre-norm 推奨
大規模(>10B):
Post-norm: 訓練が困難(勾配消失)
Pre-norm: 安定的に訓練可能
→ Pre-norm 必須
実証例:LLaMA, GPT-3等
ほぼすべての大規模LLMが Pre-norm を採用GPT-3などの超深層モデル(数十〜百層)では、学習の安定性のためにPre-normが必須となります。勾配が邪魔されずに流れることが重要です。
実装の違い
# Post-norm 版
class TransformerBlockPostNorm:
def forward(self, x):
# Attention
attn_out = self.attention(x)
x = self.norm1(x + attn_out) # ← 後に正規化
# FFN
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out) # ← 後に正規化
return xPost-norm: サブ層出力を残差と足してからLayerNormを適用(x = Norm(x + Sublayer(x)))。従来設計だが深いモデルで不安定になりやすい。
# Pre-norm 版
class TransformerBlockPreNorm:
def forward(self, x):
# Attention
x = x + self.attention(self.norm1(x)) # ← 前に正規化
# FFN
x = x + self.ffn(self.norm2(x)) # ← 前に正規化
return x
- Pre-norm: サブ層入力を先にLayerNormしてから処理し、残差を足す(x = x + Sublayer(Norm(x)))。勾配伝播が安定し深いモデルで有利。
完全な形状追跡(Embedding → Output)

Embeddingでトークンを(batch, seq, dim)のテンソルに変換し、各層で同じ形状を保ってAttention/FFNで変換→最終的に線形層+softmaxで出力確率へ。
入力から出力までの全形状変化
【入力】
テキスト:「私は学校へ行く」
↓ トークン化
トークンID:[1050, 80, 2450, 94, 1234]
↓ Embedding + PE追加
形状:(batch=32, seq_len=5, d_model=768)
【エンコーディング開始】
ブロック1入力:(32, 5, 768)
Sub-layer 1: Multi-Head Attention
Q, K, V生成:各(32, 5, 768)
各ヘッド処理:(32, 5, 96) → (32, 5, 96)
ヘッド統合:(32, 5, 768)
Attention出力:(32, 5, 768)
↓
残差接続 + 正規化:(32, 5, 768)
Sub-layer 2: FFN
入力:(32, 5, 768)
拡張層:(32, 5, 3072)
活性化関数:(32, 5, 3072)
圧縮層:(32, 5, 768)
FFN出力:(32, 5, 768)
↓
残差接続 + 正規化:(32, 5, 768)
ブロック1出力:(32, 5, 768)
↓
ブロック2-12:同じプロセスを11回繰り返し
↓
最終層出力:(32, 5, 768)
【デコーディング】
線形層:(32, 5, 768) @ (768, vocab_size)
= (32, 5, 50257)
Softmax:(32, 5, 50257)
→ 各位置で確率分布
【出力】
確率分布:(batch=32, seq_len=5, vocab_size=50257)入力をトークン化→Embedding+位置埋め込みで (32,5,768)。各TransformerブロックはMHAとFFNで形状を維持(FFNは内部で3072に拡張→768に戻す)。12層通過後の (32,5,768) を語彙行列(768×50257)で投影し (32,5,50257)、softmaxで各位置の確率分布を得る。
パラメータ数の内訳(GPT-3相当)
総パラメータ:175B
1. Embedding層
Token Embedding:50257 × 768 = 38.6M
Position Embedding:2048 × 768 = 1.6M
計:40.2M ≈ 0.02%
2. Transformer層(12層)
各層:
- MHA:(768 × 768 × 4) + (768 × 768) = 2.4M
- FFN:(768 × 3072) + (3072 × 768) = 4.7M
- LayerNorm:768 × 2 ≈ 1.5K
計:7.1M / 層
全12層:7.1M × 12 = 85.2M
3. 出力層
最終Linear:768 × 50257 = 38.6M
合計:40.2 + 85.2 + 38.6 = 164MEmbeddingは約40.2M(0.02%)、出力層は38.6M、12層のTransformerが合計85.2M。合計約164Mで大部分は各層のFFN/MHAが占める。
メモリとパラメータのプロファイリング
Activations Dominate Memory

訓練時のGPUメモリの大半は、パラメータそのものではなく、バックプロパゲーション用に一時保存された「アクティベーション」が占有します。
訓練時メモリ使用量(推定)
バッチサイズ:32
系列長:2048
精度:BF16(2バイト/パラメータ)
モデルパラメータ:175B × 2 bytes = 350GB
勾配(パラメータ同じ):175B × 2 bytes = 350GB
活性化値(チェックポイント無し):
各層での中間活性化 = 32 × 2048 × 768 × 2 bytes × 12層
≈ 1.2TB
オプティマイザー状態(Adam):
first moment(m):175B × 2 bytes = 350GB
second moment(v):175B × 2 bytes = 350GB
合計メモリ(推定):
350GB + 350GB + 1.2TB + 700GB ≈ 2.6TB
推奨:
- 80GBのA100 GPU × 32個(2.56TB)
- または H100 で同等学習に必要なメモリは約2.6TB。内訳はモデル本体350GB+勾配350GB+Adam状態700GB+活性化約1.2TB(BF16、batch32、seq2048想定)。推奨は80GB A100×32またはH100相当。
📖 参考文献
主要論文
- He, K., Zhang, X., Ren, S., & Sun, J. (2016): “Deep Residual Learning for Image Recognition”, CVPR 2016
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016): “Layer Normalization”, NeurIPS 2016
- Zhang, B., & Sennrich, R. (2019): “Root Mean Square Layer Normalization”, NeurIPS 2019
- Santurkar, S., Tsipras, D., Ilyas, A., & Madry, A. (2018): “Understanding Batch Normalization”, NeurIPS 2018
📚 シリーズ案内
ブログB:実装詳細編では、Transformerの各構成要素を実装レベルで解説しています。


コメント