
Causal Maskingと並列学習:訓練と推論の効率化
前回はMulti-Head Attentionの計算フローを学びました。今回は、テキスト生成に不可欠なCausal Maskの実装と、訓練・推論の違いを解説します。
因果的マスク(Causal Mask)の実装
自己回帰型生成の仕組みとCausal Maskの役割
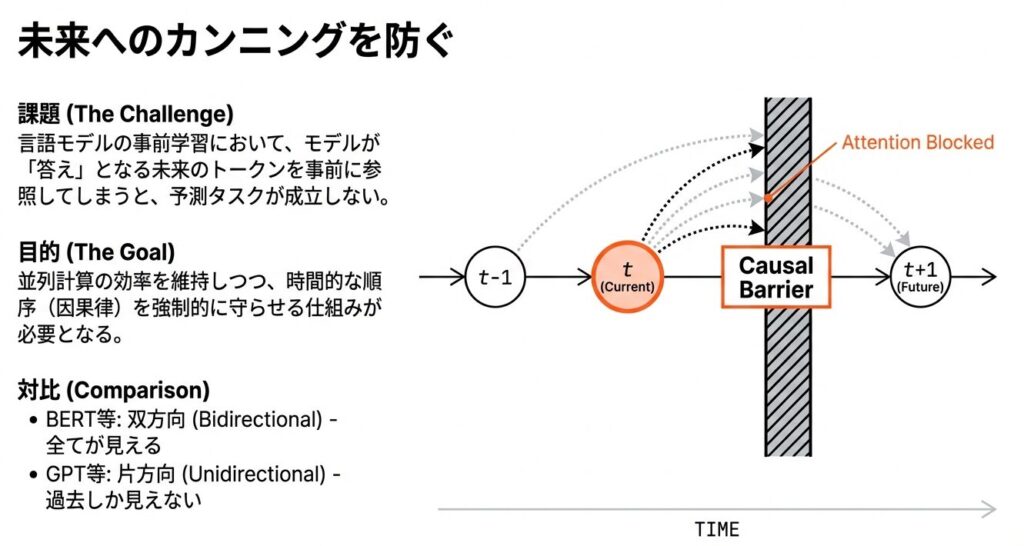
【Causal Attention Maskの詳細】

マスク行列の構造
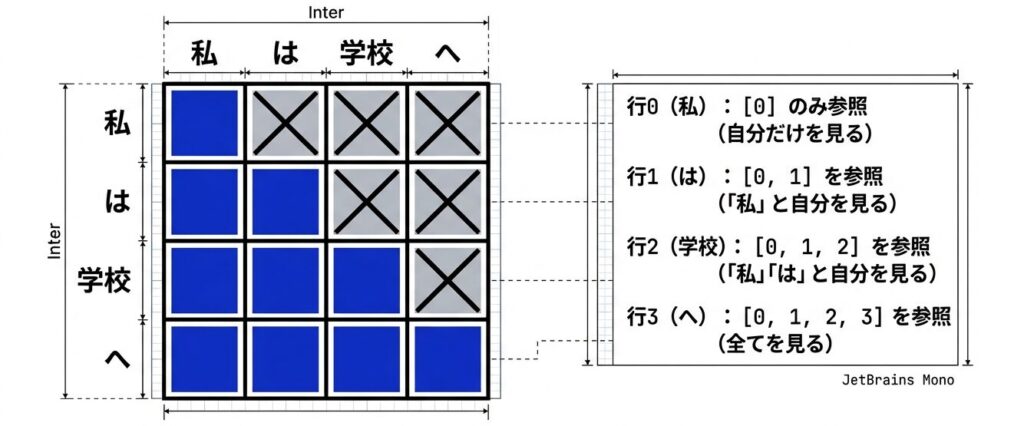
テキスト生成時:「私は学校へ」(4トークン)
通常のScoreマトリクス(4×4):
[s00, s01, s02, s03]
[s10, s11, s12, s13]
[s20, s21, s22, s23]
[s30, s31, s32, s33]
Causal Maskマトリクス(4×4、下三角):
[1, 0, 0, 0] ← トークン0は自分のみ参照可
[1, 1, 0, 0] ← トークン1は位置0,1を参照可
[1, 1, 1, 0] ← トークン2は位置0,1,2を参照可
[1, 1, 1, 1] ← トークン3は全位置を参照可マスクの意味
| 行 | 参照可能な位置 | 意味 |
|---|---|---|
| 0 | [0] | 「私」は自分だけを見る |
| 1 | [0, 1] | 「は」は「私」と自分を見る |
| 2 | [0, 1, 2] | 「学校」は「私」「は」と自分を見る |
| 3 | [0, 1, 2, 3] | 「へ」は全てを見る |
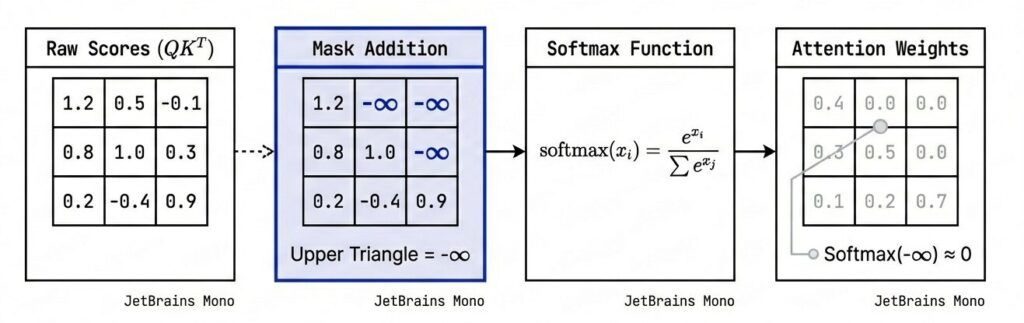
マスク適用の実装
Attentionスコア計算後、Softmax を適用する直前に、未来のトークンに対応する要素に『-∞(マイナス無限大)』を加算します。
💡 ポイント
この性質を利用することで、未来のトークンへのAttention Weight
(注目度)を完全にゼロにし、情報の流出を数学的に遮断する。つまり、各トークンは「自分自身と過去のトークンのみ」に注意を払い、未来の情報には一切アクセスできなくなります。
疑似コード
このコードは、Causal Masking(因果マスキング) を実装しています。
<strong>create_causal_mask</strong>:下三角行列を生成。対角線より上の部分を0にしますapply_causal_mask:マスク値が0の位置(未来のトークン)に極めて小さい値(-1e9)を挿入。その後Softmaxに通すことで、未来のトークンに対する注意重みをほぼ0にします
def create_causal_mask(seq_len):
"""下三角マスクを生成"""
mask = torch.tril(torch.ones(seq_len, seq_len))
return mask # 1: 参照可, 0: マスク
def apply_causal_mask(scores, mask):
"""マスクを適用(未来を-∞に)"""
# maskが0の位置に-1e9を加算
masked_scores = scores.masked_fill(mask == 0, -1e9)
return masked_scores効果:テキスト生成時に、各トークンが「自分より後ろのトークン」を参照できないようにします。これにより、モデルが「まだ見ていない情報をカンニングする」のを防ぎます。
数値例
【イメージ図】
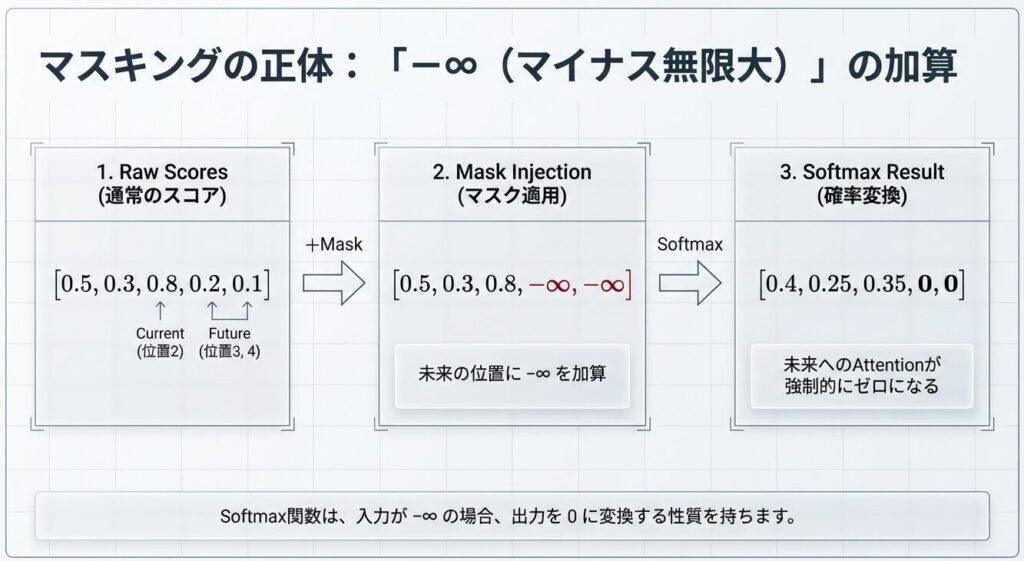
スケール後のスコア(位置0のクエリ):
[1.5, -0.2, 2.1, 0.8]
マスク:
[1, 0, 0, 0]
Causal Maskの影響:
[1.5, -1e9, -1e9, -1e9]
≈ [1.5, -∞, -∞, -∞]
Softmax適用後:
[1.0, 0.0, 0.0, 0.0]
(位置0のみを参照 → 合計1.0)💡 ポイント
Softmax(-∞) ≈ 0 となるため、未来のトークンへの注目度が完全に0になります。
並列学習 vs 推論時の処理
1つのアーキテクチャに2つの挙動
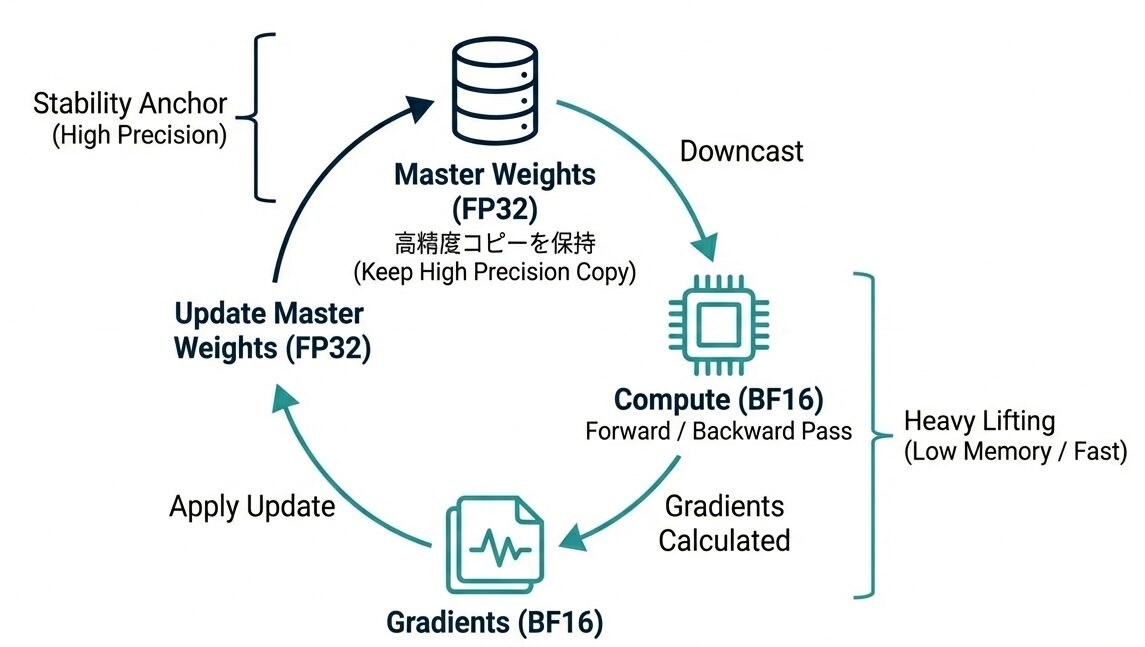
訓練時(並列学習)
並列学習とTeacher Forcing(教師強制)
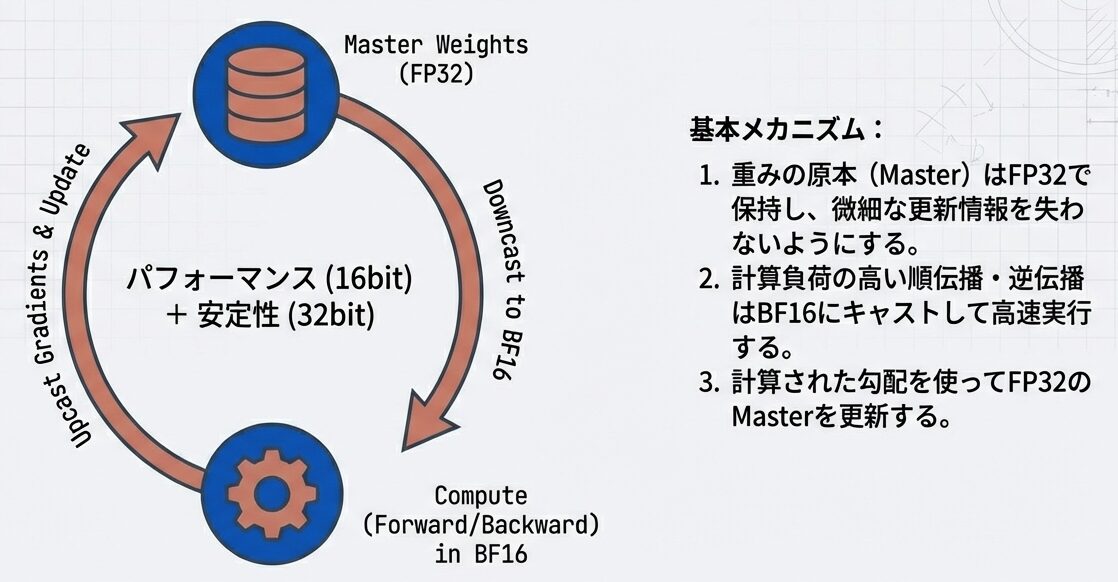
入力文全体:「私は学校へ行く」
[t1, t2, t3, t4, t5]
Causal Maskで全ステップを同時計算:
ステップ1:t1 → 予測 t2(t2-t5 をマスク)
ステップ2:t1,t2 → 予測 t3(t3-t5 をマスク)
ステップ3:t1,t2,t3 → 予測 t4(t4-t5 をマスク)
ステップ4:t1,t2,t3,t4 → 予測 t5(t5 をマスク)
→ 全てが1回の順方向パスで計算される(並列化!)Teacher Forcing(教師強制)とは、RNNやTransformerなどの逐次的なモデルの学習において、「訓練中、生徒(モデル)が間違った答えを出しても、先生が即座に正解を教えて次の問題に進ませるスパルタ教育法」のようなアルゴリズムです。
推論時(自己回帰型生成)
自己回帰型生成
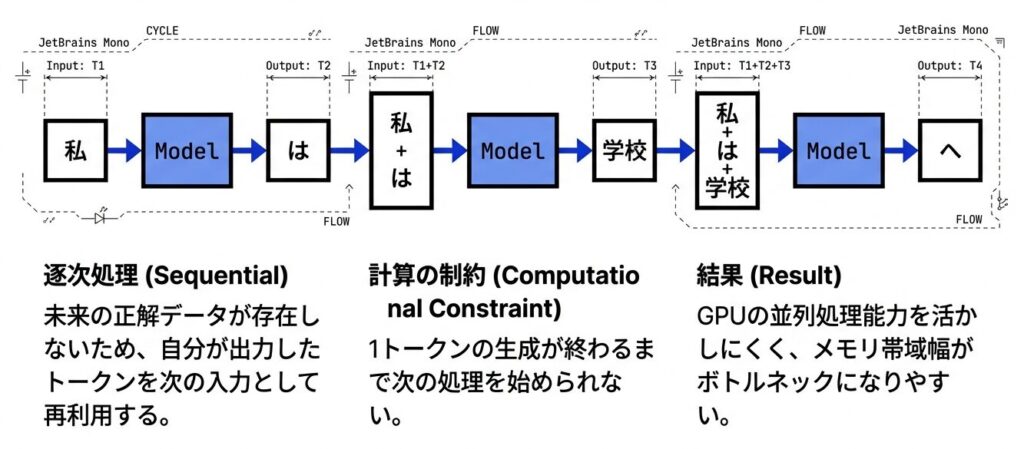
ステップ1:
入力:[<START>]
出力:t1 = 「私」
ステップ2:
入力:[<START>, 「私」]
出力:t2 = 「は」
ステップ3:
入力:[<START>, 「私」, 「は」]
出力:t3 = 「学校」
...
→ 各ステップで新しいトークンを1つずつ生成比較表
訓練vs推論
訓練時は並列処理で効率を最大化し、推論時は逐次処理とならざるを得ない。
| 項目 | 訓練時 | 推論時 |
|---|---|---|
| 処理方式 | 並列 | 逐次 |
| 計算効率 | 高い(GPU活用) | 低い(1トークンずつ) |
| メモリ使用 | 大(全系列保持) | 小〜中(KVキャッシュ) |
| 目的 | パラメータ更新 | テキスト生成 |
💡 ポイント
この並列性により、Transformerは GPU/TPU の並列計算能力を最大限に活用 でき、学習時間が劇的に短縮されました。
実装例:PyTorch
このコードは、Causal Self-Attention(因果的自己注意)を実装しています。
create_causal_mask,apply_causal_mask:前述を参照CausalSelfAttention:
Q、K、Vすべてが同じ入力 $x$ から生成される(Self-Attention)
生成したマスクを適用し、各トークンが未来のトークンを参照できないようにします
import torch
import torch.nn as nn
def create_causal_mask(seq_len, device):
"""因果的マスクを生成"""
# 下三角行列(対角含む)
mask = torch.tril(torch.ones(seq_len, seq_len, device=device))
return mask.unsqueeze(0).unsqueeze(0) # (1, 1, seq, seq)
def apply_causal_mask(scores, mask):
"""マスクを適用(未来を-∞に)"""
masked_scores = scores.masked_fill(mask == 0, -1e9)
return masked_scores
class CausalSelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
def forward(self, x):
seq_len = x.size(1)
# 因果的マスクを生成
mask = create_causal_mask(seq_len, x.device)
# Self-Attention(Q=K=V=x)
output = self.mha(x, x, x, mask=mask)
return output効果:テキスト生成時に、
n番目のトークンはn番目より後ろのトークンを「見えない」状態にします。これにより、まだ生成されていない情報をカンニングするのを防ぎます。
KVキャッシュによる推論高速化
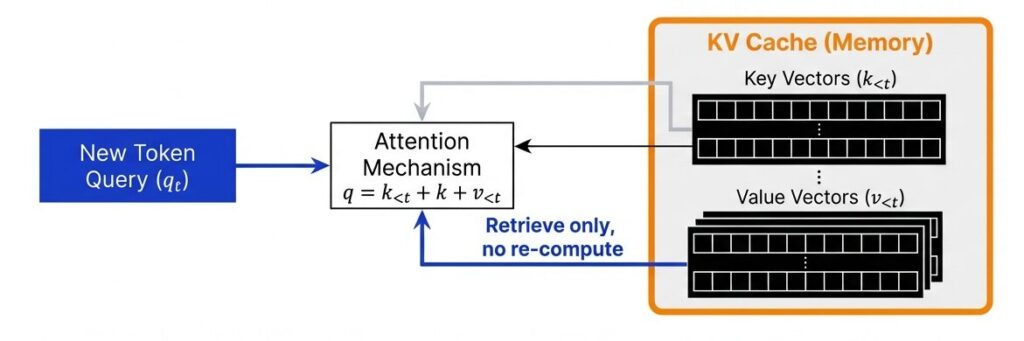
課題:推論時に毎回「過去の全トークン」の計算をやり直すのは無駄である。
解決策:過去のKeyとValueの計算結果をメモリに保持(キャッシュ)し、新規トークン分のみを計算する。
効果:計算量を削減し、生成速度を向上させる(現代のLLM推論における必須技術)。
class CausalSelfAttentionWithCache(nn.Module):
def forward(self, x, kv_cache=None):
# 新しいトークンのみ計算
if kv_cache is not None:
# 過去のK, Vを再利用
K = torch.cat([kv_cache['K'], new_K], dim=2)
V = torch.cat([kv_cache['V'], new_V], dim=2)
else:
K = new_K
V = new_V
# キャッシュを更新
new_cache = {'K': K, 'V': V}
return output, new_cache💡 A-3との関連
A-3で学んだ「Self-Attention(Q=K=V=x)」では、毎回全系列を処理していました。ここではそれを最適化し、テキスト生成時の推論速度を飛躍的に向上させています。これはGPTなどの実用的なLLMで必須の技術です。
訓練時の効率化テクニック
Teacher Forcing
訓練時は、正解トークンを入力として使用:
入力: [<START>, 「私」, 「は」, 「学校」, 「へ」]
正解: [「私」, 「は」, 「学校」, 「へ」, 「行く」]
→ 各位置で次トークンを予測
→ Cross Entropy Loss で全位置の誤差を一括計算Teacher Forcing(教師強制)とは、RNNやTransformerなどの逐次的なモデルの学習において、「訓練中、生徒(モデル)が間違った答えを出しても、先生が即座に正解を教えて次の問題に進ませるスパルタ教育法」のようなアルゴリズムです。
損失計算の並列化
パディング位置を除外した損失計算
A-3で学んだ「Self-Attention」では全トークンを処理していましたが、ここでは訓練時に不要なパディング部分を損失計算から除外します。これにより、モデルが無駄に「パディングの予測を学習する」のを防ぎ、訓練効率を向上させます。
def compute_loss(logits, targets, mask):
"""全位置の損失を一括計算"""
# logits: (batch, seq_len, vocab_size)
# targets: (batch, seq_len)
loss = F.cross_entropy(
logits.view(-1, vocab_size),
targets.view(-1),
reduction='none'
)
# パディング位置を除外
loss = (loss * mask.view(-1)).sum() / mask.sum()
return loss💡 ポイント
- mask値の意味:1=有効トークン、0=パディング
- 計算順序:形状変更 → 損失計算 → マスク適用 → 正規化
- 重要性:実用的なLLM訓練では、このようなマスク処理は必須です。不正確だとモデルの性能が低下します
まとめ
この記事では、Causal Maskの実装と訓練・推論の違いを解説しました。
| 項目 | 内容 |
|---|---|
| Causal Mask | 下三角行列で未来をマスク |
| 適用方法 | -∞を加算 → Softmax(0) |
| 訓練時 | 並列計算(効率的) |
| 推論時 | 逐次生成(KVキャッシュで高速化) |
次回は、FFNと活性化関数の実装を解説します。
📖 参考文献
主要論文
- Kwon, W., Li, Z., Zhuang, S., et al. (2023): “vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention”, SOSP 2023
📚 シリーズ案内
次に読む
- B4: FFNと活性化関数の実装 – 知識を蓄える層の実装


コメント