
基礎用語集と確認問題:Transformerの理解度チェック
これまでの【Transformer:基礎理論 A-1〜A-5】で学んだ内容は、理解したつもりでも、用語が混ざるとすぐに曖昧になりやすいです。そこでこの記事では、重要用語を一覧で整理し、そのあと確認問題で「どこまで説明できるか」を確かめます。ここでは新しい概念を増やすのではなく、A-1〜A-5 の理解を定着させることを目的にします。
重要用語(20語)
アーキテクチャ関連
| 用語 | 日本語 | 簡潔な定義 |
|---|---|---|
| Language Model | 言語モデル | テキストの生起確率 をモデル化したもの |
| Transformer | トランスフォーマー | 2017年に提案されたニューラルネットワークアーキテクチャ。Attentionメカニズムを最大限活用 |
| RNN | リカレントニューラルネットワーク | トークンを順次処理する古いアーキテクチャ。勾配消失の問題あり |
| N-gram | エヌグラム | 直近 N-1 個の単語だけを見て次の単語を予測する言語モデル |
| Decoder-only Architecture | デコーダーのみ型アーキテクチャ | GPT型モデルの構造。エンコーダーを持たず、デコーダーのみで構成 |
Attention関連
| 用語 | 日本語 | 簡潔な定義 |
|---|---|---|
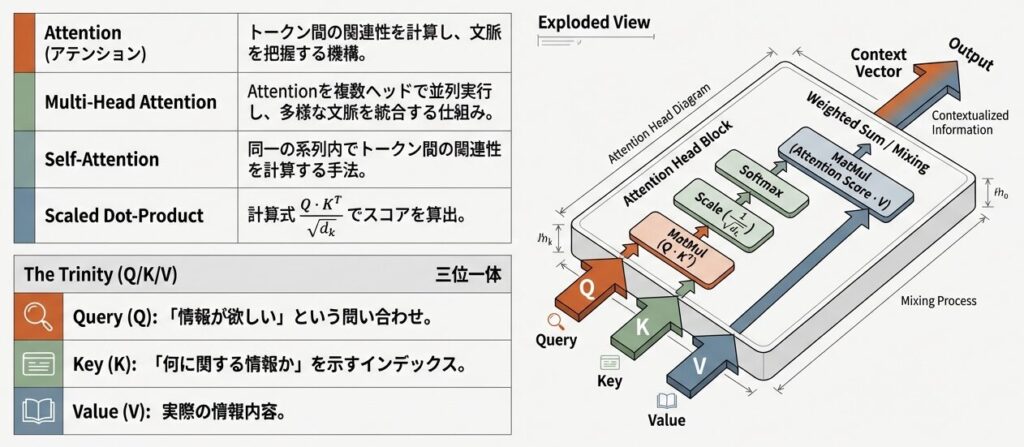
| Attention | アテンション | トークン間の関連性を計算し、文脈を把握する機構 |
| Multi-Head Attention | マルチヘッドアテンション | Attention処理を複数ヘッドで並列実行し、結果を統合 |
| Query (Q) | クエリ | Attention計算で「情報が欲しい」という問い合わせを表すベクトル |
| Key (K) | キー | Attention計算で「何に関する情報か」を示すインデックス |
| Value (V) | バリュー | Attention計算で実際の情報内容を持つベクトル |
| Self-Attention | セルフアテンション | 同一の系列内でトークン間の関連性を計算するAttention |
| Scaled Dot-Product Attention | スケール付き内積アテンション | dkQ⋅KT という計算式でAttentionスコアを算出 |
| Causal Attention Mask | 因果的アテンションマスク | テキスト生成時、未来のトークンへのアテンションをマスクする技法 |
コンポーネント関連
| 用語 | 日本語 | 簡潔な定義 |
|---|---|---|
| Embedding | エンベディング | 離散的な単語を連続値の高次元ベクトルに変換するプロセス |
| Tokenization | トークン化 | テキストを最小処理単位(トークン)に分割するプロセス |
| Positional Encoding | 位置エンコーディング | 各トークンの位置情報をベクトルに追加 |
| Feed Forward Network (FFN) | フィードフォワードネットワーク | Transformerの中間層。2層のMLPで知識を蓄積 |
| Residual Connection | 残差接続 | ブロックの入力を出力に加算し、深い層の学習を安定させる技法 |
| Layer Normalization | レイヤー正規化 | 各層の出力を正規化し、学習を安定させる技法 |
| Softmax | ソフトマックス | 入力ベクトルを確率分布に変換する関数。Attentionで使用 |
確認問題(10問)
以下の問題では、用語の意味を覚えているだけでなく、「なぜその構造や制約が必要だったのか」まで説明できるかを確認します。答えを見返すときは、単語の定義だけでなく、A-1〜A-5 のどの話とつながるかも意識すると整理しやすくなります。
問1:言語モデルの根本的な役割
Q: 言語モデルの根本的な役割は何か、簡潔に述べよ。
💡 解答例
言語モデルは、テキストの生起確率 $P(x_1, x_2, \cdots, x_L)$をモデル化し、与えられた文脈から次の単語を予測すること で、テキスト生成や自然言語理解を実現する。
問2:RNNとTransformerの違い
Q: RNNとTransformerの主な違いを、「計算方法」と「長距離依存性」の2点から説明せよ。
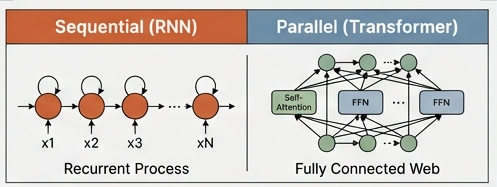
💡 解答例
計算方法:
RNN:トークンを順次処理(逐次的)。各ステップが前のステップに依存
Transformer:全トークンを同時に処理(並列)。逐次依存がない
長距離依存性:
RNN:勾配が層を遡る過程で消失するため、遠い過去の情報を学習できない
Transformer:全トークン間に直接的な接続があるため、任意の距離の依存関係を学習可能
問3:Attentionが解決した問題
Q: Attention メカニズムが解決した「RNNの2つの根本的な問題」を述べよ。
💡 解答例
1. 勾配消失問題:Attentionでは全トークン間に直接接続があるため、勾配の経路が短くなり、消失しない
2. 学習の遅さ:Transformerの並列計算により、RNNの逐次処理から脱却でき、GPU/TPUを最大限活用可能
問4:Multi-Headの理由
Q: Multi-Head Attention で複数ヘッドを使う理由を述べよ。
💡 解答例
各ヘッドが異なる線形変換を用いることで、テキストの異なる側面(文法的関係、意味的関係、共参照関係など)を並列に学習 でき、単一ヘッドでは捉えられない多角的な情報を獲得できるから。
問5:スケーリングの理由
Q: なぜ Attention スコアの計算で、内積を dk で割る(スケーリング)のか?
💡 解答例
次元数 $d_k$ が大きいほど、内積の分散が増大するため、スケーリングなしではスコアが非常に大きな値になり、Softmax関数の出力が一部のトークンに極端に集中してしまう。スケーリングにより、Softmaxの出力を「バランスの取れた確率分布」に保つ。
問6:FFNのパラメータ割合
Q: FFN が占めるパラメータ数が全体の 2/3 以上である理由は何か?
💡 解答例
FFN は モデルの「知識」を蓄える主要な場所 であり、事前学習で学習した大量のテキストからの知識(意味、文法、常識等)をニューラルメモリの形で保持しているため。
問7:位置エンコーディングの必要性
Q: Embedding層で位置エンコーディングが必要な理由を述べよ。
💡 解答例
Transformerは全トークンを同時に処理するため、トークンの順序情報が自動的には含まれない。位置エンコーディングを追加することで、「どの位置にあるトークンか」という情報を明示的にモデルに与える。
問8:Causal Maskの役割
Q: Causal Attention Mask は、訓練時にどのような問題を防ぐのか?
💡 解答例
訓練時に全ての正解トークンが与えられているため、マスクがなければモデルが未来のトークン情報を参照して「カンニング」してしまう。これにより、推論時(1トークンずつ生成)の挙動と訓練時の挙動に矛盾が生じるのを防ぐ。
問9:残差接続と層正規化
Q: Residual Connection と Layer Normalization は、なぜ深いTransformerの学習に必須なのか?
💡 解答例
必須であると言える。これらがなければ、20層以上のTransformerは安定して訓練できない。
- 残差接続:入力を出力に加算することで、勾配の経路を短くし、勾配消失を防ぎ、深い層の学習を安定させる
- 層正規化:各層の出力スケールを統一し、学習の不安定性を防ぎ、収束を早める
問10:Transformerが採用され続ける理由
Q: Transformerが「2017年以降、ほぼ基本構造を変えずに採用され続けている」理由を述べよ。
💡 解答例
- 汎用性が高い:Encoder-Decoder型、Decoder-only型など、様々な応用に対応可能
- スケーラブル:パラメータ数を増やすことで性能が向上する scaling law に従い、大規模化による性能向上が期待できる
- 並列計算に最適:GPUの並列計算能力を最大限活用でき、訓練効率が良い
- 理論的に洗練されている:Attention、正規化、活性化関数など、各コンポーネントがバランスよく設計されている
まとめ
ここまでで、Transformer の基本構造から Attention、FFN、Causal Mask までを一通り整理できました。次は大規模言語モデル入門【Transformer:実装編B】へ進み、各要素が実装上どのように組み合わさるのかを見ていきます。
基礎理論Aで学んだ内容
| セクション | 内容 |
|---|---|
| A-1 | 言語モデルの進化(N-gram → RNN → Transformer) |
| A-2 | Transformerの全体構造と3つのコンポーネント |
| A-3 | Multi-Head Attentionの詳細メカニズム |
| A-4 | FFNと活性化関数(知識の蓄積) |
| A-5 | Causal Maskと自己回帰型生成 |
| A-6 | 用語集と確認問題(本記事) |
📖 参考文献
主要論文・用語出典
- Vaswani, A., et al. (2017): “Attention Is All You Need”, NeurIPS 2017
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013): “Efficient Estimation of Word Representations in Vector Space”, ICLR 2013
- Sennrich, R., Haddow, B., & Birch, A. (2016): “Neural Machine Translation of Rare Words with Subword Units”, ACL 2016
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016): “Layer Normalization”, NeurIPS 2016
- He, K., Zhang, X., Ren, S., & Sun, J. (2016): “Deep Residual Learning for Image Recognition”, CVPR 2016
補足資料
- Hochreiter, S., & Schmidhuber, J. (1997): “Long Short-Term Memory”, Neural Computation
- Radford, A., et al. (2019): “Language Models are Unsupervised Multitask Learners”
📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。


コメント