
推論最適化と実装上の工夫:Mixed Precision, Gradient Checkpointing, 数値安定性
175Bパラメータのモデルを訓練するには、単純な実装では2.5TB以上のメモリが必要です。本記事では、このような超大規模モデルを現実的なハードウェアで訓練するための実装上の工夫を詳解します。
以下はTransformerにおけるGPUメモリ制約を解決するための方法とモデル軽量化についてです。是非参考にしてみてください。

Mixed Precision Training(混合精度訓練)
- 混合精度訓練とは?
- FP32(32ビット)の代わりにBF16(16ビット)などの低精度を活用することで、メモリ消費を大幅に抑え、計算速度を向上させます。
- 高精細写真 vs 圧縮画像
- FP32(32ビット):
- ポスター印刷にも耐えられる超高解像度データ。ただし、スマホのメモリを即座に使い果たします。
- •BF16(16ビット):
- 見た目の美しさは変わらないが、容量を半分に抑えたスマートな画像形式。
- FP32(32ビット):
- なぜこれが不可欠なのか?
- メモリ削減とコスト削減: メモリ半減による劇的なコスト削減。
- 処理スピードの爆発的向上: データ軽量化による学習の大幅な高速化。
Mixed Precisionの本質
- 「混合精度」とは、単に精度を下げることではありません。
- 重みのマスターコピーは、学習の微細な変化を記録するために「FP32」で保持する。
- 莫大な計算が発生する順伝播・逆伝播 のみを「BF16」で行う。 これが、精度を維持しながらリソースを節約するためのエンジニアリングの知恵です。
【混合精度訓練についての詳細】
背景と動機
通常、Transformerは FP32(32ビット浮動小数点数) で訓練されますが、メモリとスピードに大きな負担があります。
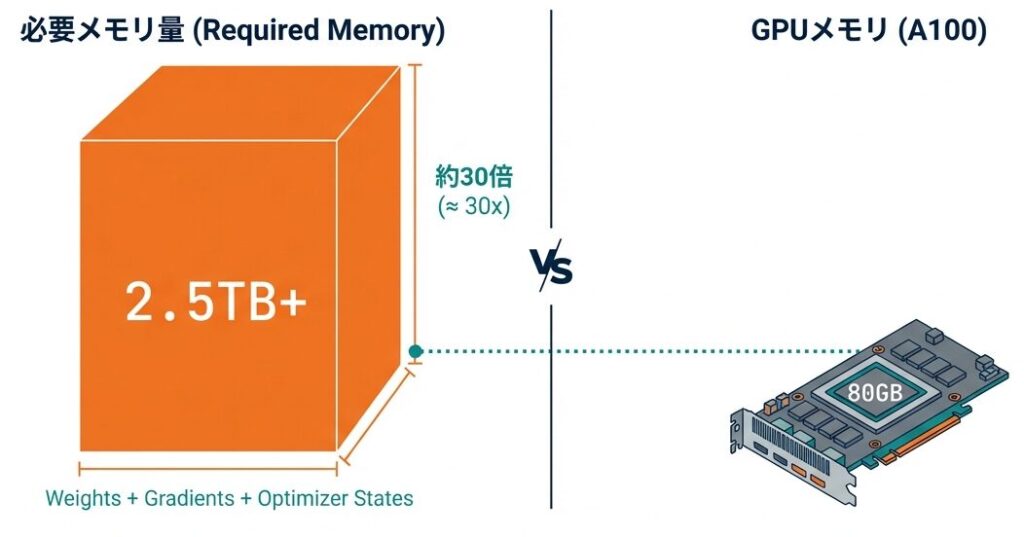
- 単純実装が失敗する物理的理由:単純な実装では、訓練開始すら不可能
- 175B(1750億)ものパラメータを持つ超大規模モデルでは、単純な実装だと2.5TB以上のメモリが必要になるため、これを現実的なハードウェアで訓練可能にすることが主な目的
【メモリ使用量の比較】
モデル: GPT-3 (175B パラメータ)
FP32 訓練:
パラメータ: 175B × 4 bytes = 700GB
勾配: 700GB
オプティマイザ状態(Adam): 1.4TB
活性化値: ~100-200GB
─────────────────────
合計: ~2.5TB
推奨GPU: H100 × 128個(各80GB VRAM)
FP16/BF16 訓練:
パラメータ: 175B × 2 bytes = 350GB
勾配: 350GB
オプティマイザ状態(FP32保持): 700GB
活性化値: ~50-100GB
─────────────────────
合計: ~1.5TB
推奨GPU: H100 × 96個(メモリ削減 40%)BF16の利点
- BF16がFP16よりも優れている理由は?
- BF16はFP16より指数部が大きく、数値の表現範囲が広いため学習が安定します。勾配が大きくなってもオーバーフローを防ぎ、エラーなく訓練を継続できる点が強みです。精度と範囲のバランスに優れ、実用的な安定性が高いため、現在のLLM学習における数値計算の主流となっています。
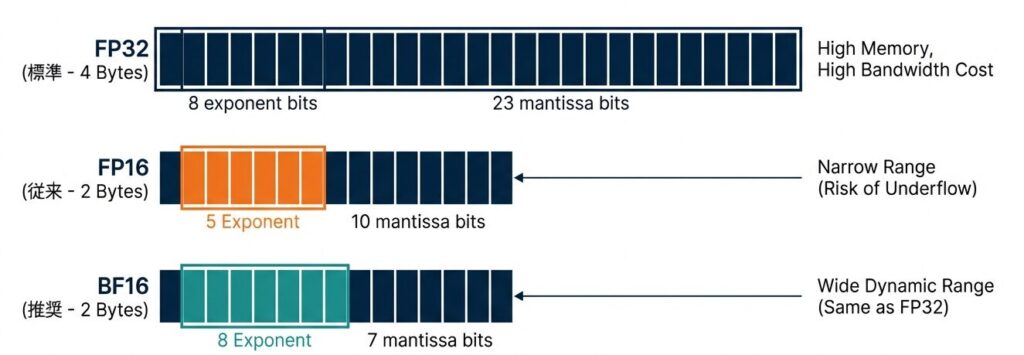
BF16はFP32と同じダイナミックレンジ(指数部8bit)を維持しつつ、メモリ使用量を半減させる。
BF16の優位性
BF16 の利点:
✓ メモリ削減(FP32比40-50%)
✓ 計算速度向上(Tensorコア対応で 2-3倍)
✓ 精度低下最小(指数部が同じため)
FP16 vs BF16:
FP16: 仮数部10bit, 指数部5bit → 表現範囲狭い
BF16: 仮数部7bit, 指数部8bit → FP32と同じ表現範囲
→ BF16の方が数値的に安定Mixed Precisionの実装戦略
- 基本原理:異なる精度を場面によって使い分け
- 精度と速度のハイブリッド実装
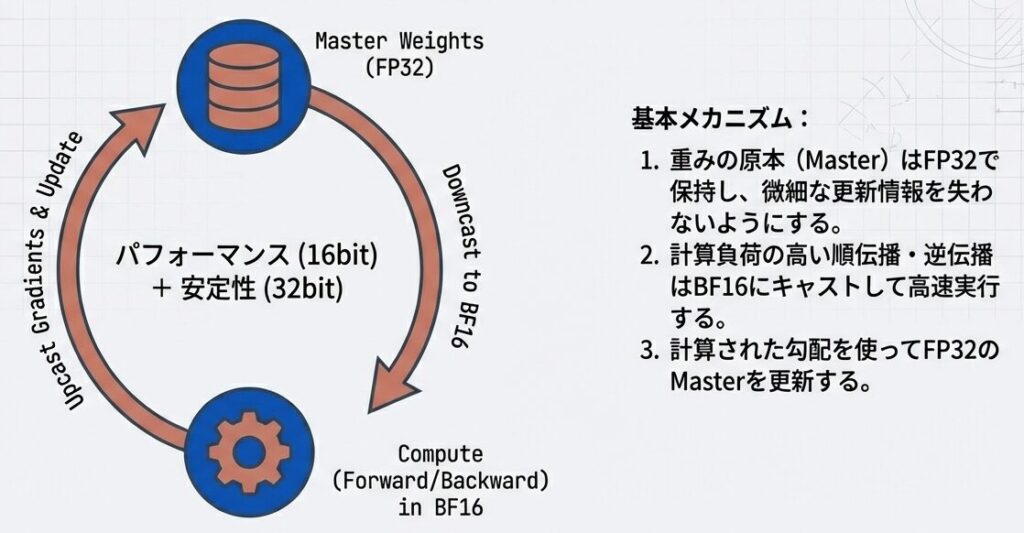
Mixed Precisionの本質
- 「混合精度」とは、単に精度を下げることではありません。
- 重みのマスターコピーは、学習の微細な変化を記録するために「FP32」で保持する。
- 莫大な計算が発生する順伝播・逆伝播 のみを「BF16」で行う。 これが、精度を維持しながらリソースを節約するためのエンジニアリングの知恵です。
実装イメージと詳細

【訓練ループでの精度使い分け】
入力: トークンID(int型)
↓
Embedding + Position Encoding:
計算精度: BF16
メモリ: BF16(削減済)
↓ 出力: (batch, seq_len, d_model)
Transformer層(各層で繰り返し):
Attention計算:
Q, K, V: BF16 計算
Softmax: FP32(数値安定性のため)← 重要
出力: BF16
FFN計算:
Linear層: BF16
活性化: FP32(GELUの精度確保)
出力: BF16
LayerNorm:
計算: FP32(正規化では高精度が重要)
出力: BF16
線形層(最終層):
計算: BF16
出力: (batch, seq_len, vocab_size)
↓
損失計算:
交差エントロピー: FP32
↓
逆伝播:
勾配計算: BF16
勾配スケーリング: FP32 ← 勾配爆発防止
↓
パラメータ更新:
マスター重み(FP32)更新
→ BF16 コピーに反映実装例(疑似コード)
- Forward Pass:
autocast(bfloat16)で計算を低精度化(メモリ削減、高速化)- Softmax・LayerNormは自動的にFP32に昇格(数値安定性確保)
- 損失計算:
- FP32で計算して精度を維持
- スケール勾配:
- 損失に
loss_scale(≈2^15=32768)を乗じる - 理由:bfloat16は仮数部が少ないため、勾配が小さすぎるとアンダーフロー(0に丸まる)するのを防ぐ
- 損失に
- 逆伝播・勾配クリッピング:
- 勾配計算後、
loss_scaleで割り戻す(アンスケール) clip_grad_norm_で勾配爆発を防止(max_norm=1.0)
- 勾配計算後、
- パラメータ更新:
- クリップされた勾配でモデルを更新
def mixed_precision_training_step(batch, model, optimizer):
"""
Mixed Precision Training のステップ
"""
# Forward pass
with autocast(dtype=torch.bfloat16):
# BF16 で計算
outputs = model(batch['input_ids'])
logits = outputs.logits # (batch, seq_len, vocab_size)
# ただし Softmax と LayerNorm は自動的に FP32 へ昇格
# 損失計算は FP32
with autocast(enabled=False):
loss = compute_loss(logits, batch['labels'])
# スケール勾配(数値安定性確保)
scaled_loss = loss * loss_scale # loss_scale ≈ 2^15 = 32768
# Backward pass
optimizer.zero_grad()
scaled_loss.backward()
# 勾配アンスケール
for param in model.parameters():
if param.grad is not None:
param.grad.data.div_(loss_scale)
# 勾配クリッピング(爆発防止)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# パラメータ更新
optimizer.step()
return loss.item()性能向上の実績
【訓練速度と精度の比較】
モデル: LLaMA 2 70B
ハードウェア: H100 × 8
BF16 が推奨される理由:
✓ FP16より数値安定性が高い(指数部が同じ)
✓ スピード:FP16と同等
✓ 精度:FP32と同等(むしろ正則化効果で向上)
✓ TPU/モダンGPU で最適化済み| 精度形式 | 訓練速度 | メモリ使用 | 最終精度 | 収束速度 |
|---|---|---|---|---|
| FP32 | 1.0x | 1.0x | 100% | 1.0x |
| FP16 | 2.2x | 0.5x | 99.8% | 0.95x |
| BF16 | 2.5x | 0.5x | 100%+0.2% | 1.05x ⭐ |
Gradient Checkpointing(勾配チェックポイント)

勾配チェックポイントは、学習時のメモリ消費を大幅に節約するための手法です。順伝播時の計算結果を全て保持せず、特定層のみ残して他を破棄します。
- トレードオフ:計算負荷(再計算)を少し増やすことで、膨大なメモリ空間を解放する。
- 利点
- メモリ不足で困難な巨大モデルや長大な系列の学習が可能になる。
- 欠点
- 逆伝播時に破棄した値を再計算するため、学習時間が長くなる。
- 利点
【勾配チェックポイントの詳細】
メモリ削減のメカニズム
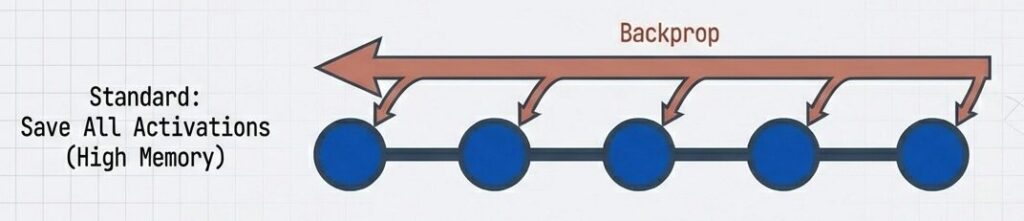
通常の訓練では、逆伝播時に全ての活性化値が必要であり、メモリを圧迫します。
【通常の訓練ループ】
Forward pass:
層1 入力 → 層1 出力 ← メモリに保存
層2 入力 → 層2 出力 ← メモリに保存
...
層12 入力 → 層12 出力 ← メモリに保存
メモリ使用: O(L × N) (L=層数, N=バッチ内の中間値数)
逆伝播時:
全て保存された活性化値にアクセス
ただしGPUメモリが満杯 → 勾配クリップ不可
結果: バッチサイズ制限 → 学習効率低下Gradient Checkpointingの解決策
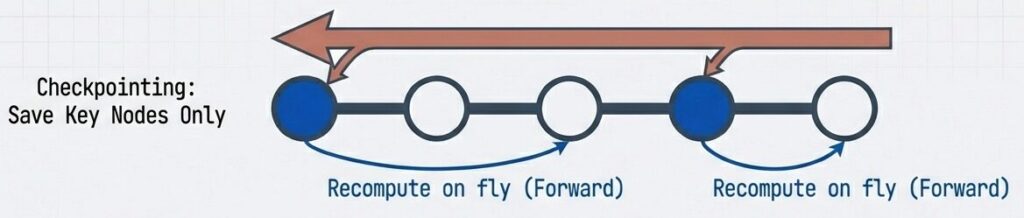
- 一部の活性化値のみ保存し、逆伝播時に必要な値を再計算:
- 逆伝播時に必要な中間データを全て保存せず、主要なチェックポイントのみ保持。
- 欠損部分は計算量(Compute)を支払って再構築し、メモリ(Memory)を節約する。
【Gradient Checkpointing】
Forward pass:
層1 入力 → 層1 出力 ← メモリに保存(Checkpoint)
層2 入力 → 層2 出力 ← スキップ
...
層8 入力 → 層8 出力 ← メモリに保存(Checkpoint)
...
層12 出力 ← 最終出力
メモリ使用: O(√L × N) (約 √12 = 3.5 個の Checkpoint のみ保存)
逆伝播時:
層12 → 層11 へ逆伝播
層11 の活性化値が必要 → 層8から層11を再計算して取得
層8 → 層7 へ逆伝播
層7 の活性化値が必要 → 層1から層7を再計算して取得
計算コスト: 再計算でCPU↔GPU通信増加(約30%の訓練速度低下)
メモリ削減: 50-70%実装例
- Forward時の中間結果を保存せず、逆伝播時に必要な値のみ再計算する
torch.utils.checkpoint.checkpointを使用。
- Transformerの4層ごとにチェックポイントを適用し、メモリ削減と計算のバランスを取ります。
- メリット:メモリ使用量が大幅削減
- デメリット:計算時間が増加
def gradient_checkpointing_wrapper(module, *args, **kwargs):
"""
モジュールの forward をチェックポイント版に置き換え
"""
if not requires_grad:
return module(*args, **kwargs)
# Forward: 入力のみ保存
def forward_fn(input_):
return module(input_, **kwargs)
# 逆伝播時に forward を再実行
return torch.utils.checkpoint.checkpoint(
forward_fn,
args,
use_reentrant=False # より効率的な実装
)
# 使用例
class TransformerWithCheckpointing:
def __init__(self, num_layers):
self.layers = ModuleList([
TransformerBlock() for _ in range(num_layers)
])
def forward(self, x):
for i, layer in enumerate(self.layers):
if i % 4 == 0: # 4層ごとにチェックポイント
x = gradient_checkpointing_wrapper(layer, x)
else:
x = layer(x)
return xメモリと速度のトレードオフ
戦略的トレードオフ:メモリ vS 演算速度
- 推奨設定:間引きチェックポイント
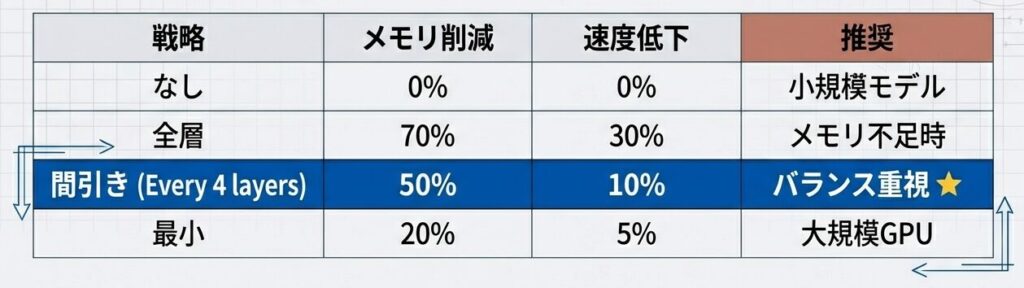
「4層ごとのチェックポイント」戦略が、わずか10%の速度犠牲でメモリを半減させる、最も効率的なスイートスポットである。
数値安定性の詳細と解決策
- 見えない敵:勾配の不安定化
- 12層を超える深いTransformerでは、逆伝播時に勾配が指数的に増減しやすい。一度 NaNが発生すると、学習プロセス全体が不可逆的に破壊される。
勾配爆発・消失の問題
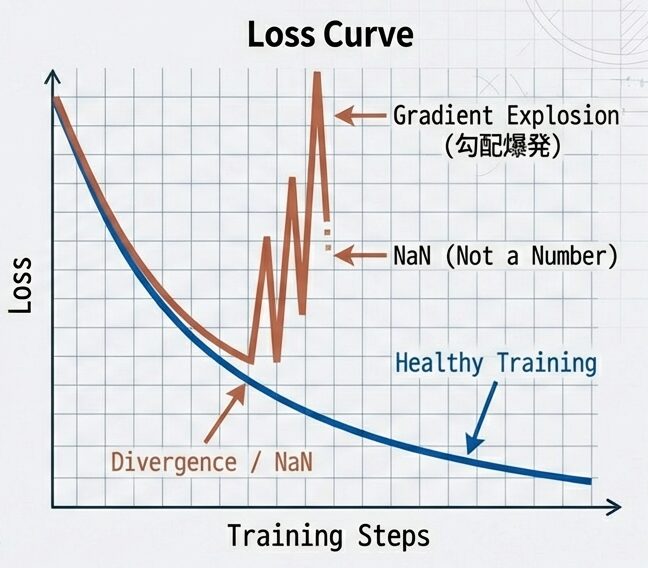
- 問題点:
- 勾配爆発
- 誤差逆伝播法において、ネットワークが深くなることで勾配(学習のための信号)が極端に大きくなり、学習が不安定になったり破綻したりする現象
- 勾配消失
- 誤差逆伝播法において、ネットワークが深くなったり系列が長くなったりすることで、過去の情報に対する勾配(学習のための信号)が極端に小さくなり、情報の更新が届かなくなる現象
- 勾配爆発
【勾配の増減メカニズム】
勾配は層を遡る際に乗算されていく:
∂L/∂w1 = ∂L/∂w2 × ∂w2/∂w1 × ∂w1/∂input
各層での勾配:
もし ∂w_layer/∂w_prev < 0.9 の場合:
勾配 = 勾配_prev × 0.9 × 0.9 × ... × 0.9
12層後: 勾配 = 勾配_prev × 0.9^12 ≈ 0.28(消失)
もし ∂w_layer/∂w_prev > 1.1 の場合:
勾配 = 勾配_prev × 1.1 × 1.1 × ... × 1.1
12層後: 勾配 = 勾配_prev × 1.1^12 ≈ 3.1(爆発)
結果: 初期層の学習が遅延または不安定解決策1:Gradient Clipping(勾配クリッピング)
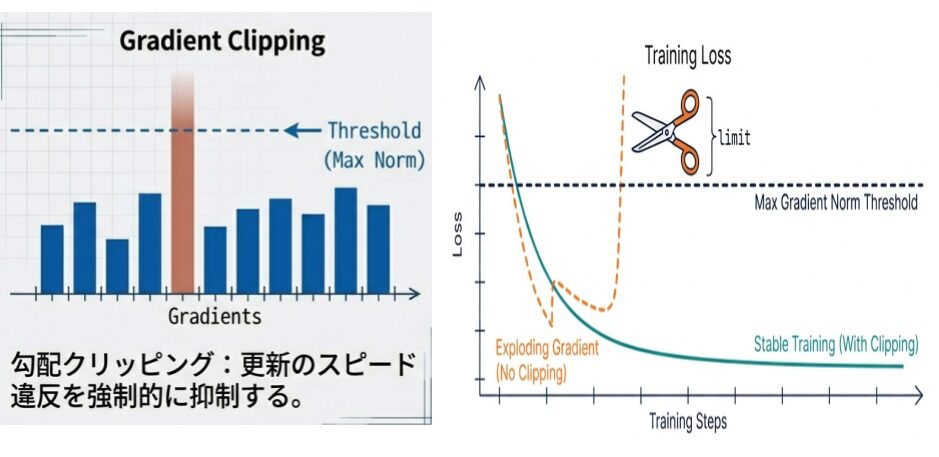
- 勾配クリッピング
- 勾配ノルムが闘値を超えた場合、強制的にスケーリング (クリッピング)して重み破壊を防ぐ。
大きすぎる勾配を制限:
gradient_clippingはモデル勾配のL2ノルムを計算し、その合計ノルムがmax_normを超える場合に全ての勾配を同じ比率で縮小して正規化します。- 戻り値は元の合計ノルムで、
loss.backward()の後・optimizer.step()の前に呼び、勾配爆発を防ぎます。
def gradient_clipping(model, max_norm=1.0):
"""
勾配のノルムが max_norm を超えないように正規化
"""
total_norm = 0.0
for p in model.parameters():
if p.grad is not None:
param_norm = p.grad.data.norm(2)
total_norm += param_norm ** 2
total_norm = total_norm ** 0.5
if total_norm > max_norm:
scale = max_norm / total_norm
for p in model.parameters():
if p.grad is not None:
p.grad.data.mul_(scale)
return total_norm
# 訓練ループ内で使用
loss.backward()
grad_norm = gradient_clipping(model, max_norm=1.0)
optimizer.step()
- 勾配クリッピング前: 勾配爆発 → 訓練不安定 → 発散
- 勾配クリッピング後: 勾配が [0, max_norm] に制限 → 安定訓練
解決策2:Weight Decay と Warmup
- 学習率スケジューリング:
- 学習スケジューリングは、大規模言語モデル(LLM)の訓練過程で、学習率などのハイパーパラメータを動的に調整する仕組みです。これにより、数兆トークン規模のデータを効率的かつ安定して処理できます。主要な要素には、モデルの最初の段階で学習率を徐々に増加させる「Warmup」と、過学習を防ぐために重みを徐々に減少させる「Weight Decay」が含まれます。これにより、安定した学習が実現します。
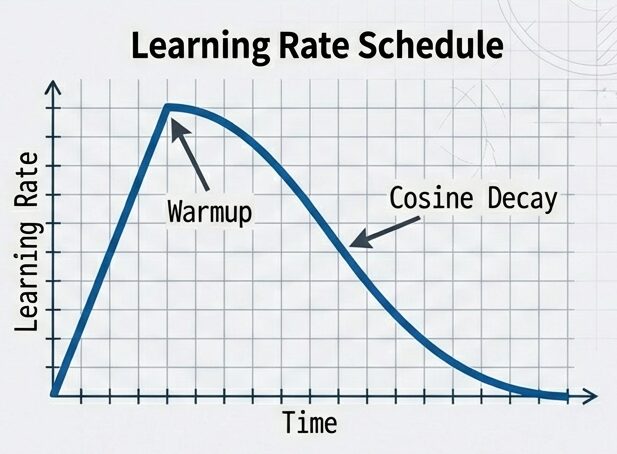
Warmup & Decayの詳細:
初期の急激な変動を防ぎ、収束を安定させる。
- Weight Decay(重み減衰):
- Weight Decay は、学習中にモデルのパラメータが大きくなるのを抑える正則化手法です。
- 重みが肥大化すると、モデルが訓練データの細かなノイズまで学習してしまい、過学習が発生しやすくなります。Weight Decayによって重みを小さく保つことで、ノイズの影響を軽減し、モデルの汎化性能を向上させることができます。
- Warmup:
- Warmup は、学習の初期段階で学習率を非常に小さい値から設定した最大値まで徐々に上昇させる期間を指します。
- このプロセスにより、初期のパラメータの不安定な振る舞いを回避し、モデルが急激な更新で破綻するのを防ぐ効果があり、より安定した学習が実現します。
訓練ステップ別の学習率推移:
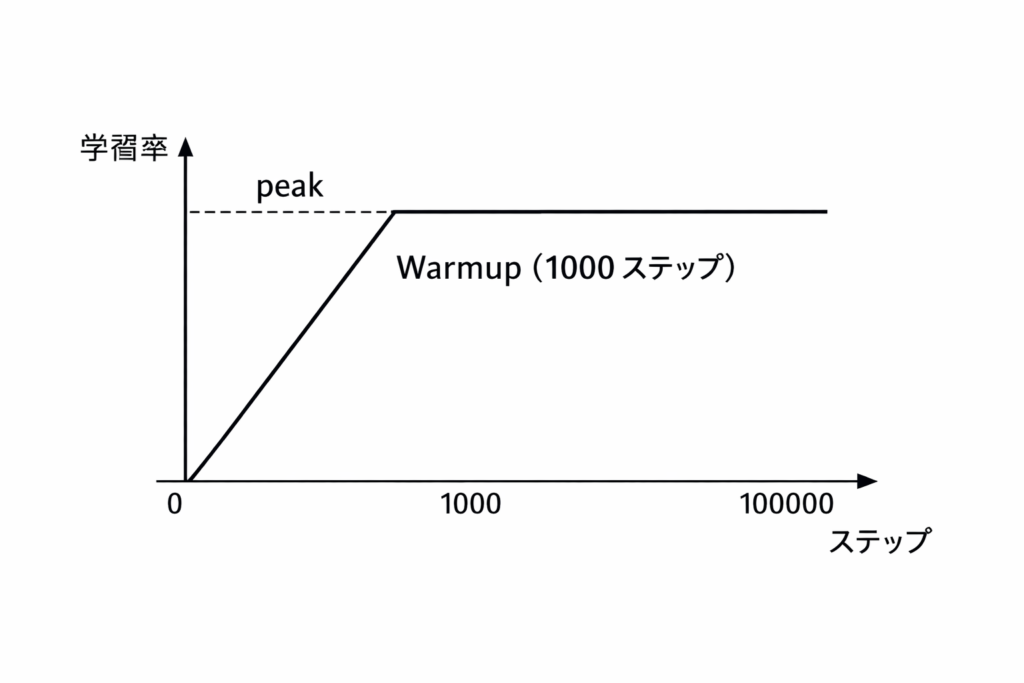
推奨パラメータ (LLaMA 2):
- 学習率: 1-2 × 10^-4 (大規模)
- Warmup ステップ: 2000
- Weight decay: 0.1
- Gradient clip: 1.0実装例:オプティマイザとスケジューラ
統合アーキテクチャ:実装の全体像
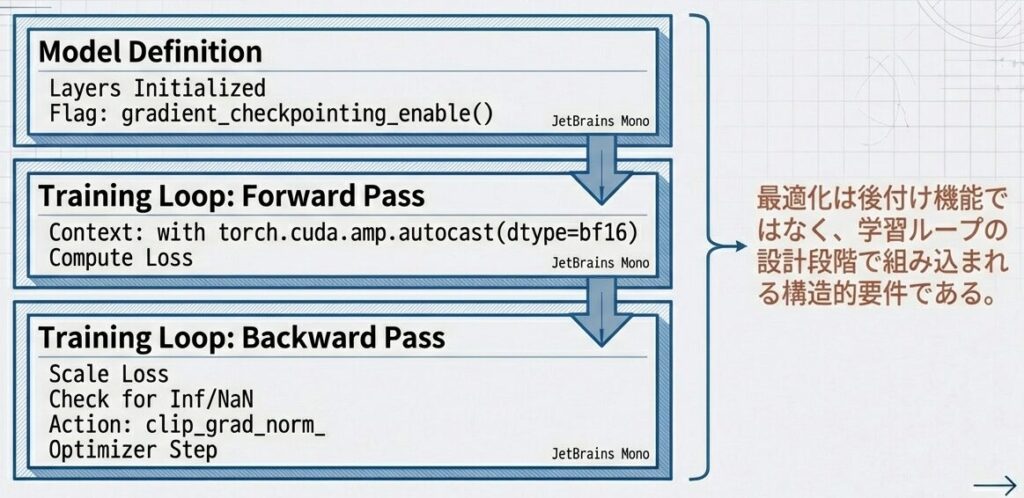
def get_optimizer_and_scheduler(model, total_steps):
optimizer = AdamW(
model.parameters(),
lr=1e-4,
weight_decay=0.1,
betas=(0.9, 0.95)
)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=2000,
num_training_steps=total_steps
)
return optimizer, scheduler
# 訓練ループ
scaler = torch.cuda.amp.GradScaler()
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
# Forward: BF16(Autocast)で高速化しつつ、必要箇所は自動でFP32に昇格
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
outputs = model(**batch)
loss = outputs.loss
# スケールして backward
scaler.scale(loss).backward()
# アンスケールしてから勾配クリッピング(正確なノルム計算のため)
scaler.unscale_(optimizer)
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 非有限な勾配はステップをスキップしてスケーラを更新
if torch.isfinite(torch.tensor(grad_norm)):
scaler.step(optimizer)
scaler.update()
scheduler.step()
else:
print(f"Skipping step {step} due to non-finite grad: {grad_norm}")
scaler.update()
optimizer.zero_grad()AdamW(lr=1e-4, weight_decay=0.1)とウォームアップ付きコサインスケジューラを返す。訓練ループはBF16でautocastし、
GradScalerで損失をスケール→backward→unscale→勾配クリップ→非有限ならステップをスキップ、正常時にscaler.step()/scaler.update()とscheduler.step()を実行。
実装上の統合チェックリスト
大規模モデル訓練の場合の実装の流れをチェックリストを使って全体像を見てみましょう。
【大規模モデル訓練の実装チェックリスト】
✅ 精度管理
[✓] Mixed Precision(BF16)有効化
[✓] Autocast で Softmax/LayerNorm を FP32 に昇格
[✓] 損失スケーリング実装(loss_scale = 2^15)
✅ メモリ管理
[✓] Gradient Checkpointing 有効化(4層ごと)
[-] Activation の削除(逆伝播後)← 運用で自動処理
[-] バッチサイズ最適化 ← 次シリーズ(ブログC)
✅ 数値安定性
[✓] Gradient Clipping(max_norm=1.0)
[✓] Learning Rate Warmup(2000ステップ)
[✓] Weight Decay(0.1)
[-] Pre-norm 使用 ← ブログA(アーキテクチャ選択)
【応用チェックリスト】※ 関連シリーズで展開
✅ 性能最適化
[→] Flash Attention 有効化 ← 第六回(ドメイン特化)
[→] 分散訓練(Data Parallel/Tensor Parallel)← 次シリーズ
[→] Gradient Accumulation ← 実装詳細(別記事)
✅ モニタリング・デバッグ
[→] 実装後の運用・デバッグ ← 専用記事ハードウェア要件の目安
- ハードウェア要件とリソース見積もり
- 最適化技術(ソフト)を駆使しても、175B規模の学習にはマルチGPU・マルチノード構成(ハード)が前提となる。Optimizer Statesがメモリの大部分を占める点に注意。
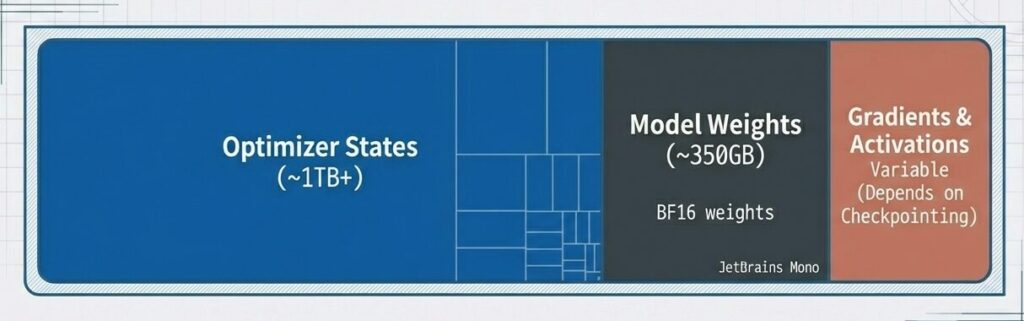
- 結論:マルチノード必須
175Bモデル訓練時のGPUメモリ構成。オプティマイザ状態(Adam)が1TB以上で最大ボトルネック。モデル重み(BF16)は固定値だが、勾配・活性化はCheckpointingの有無で大きく変動。超大規模モデル訓練では分散メモリ必須。
- モデルサイズ別の訓練ハードウェア要件表【モデルサイズ別GPU要件】
- この表では、各モデルサイズに対する様々なGPUの対応状況を示しています。
| モデルサイズ | 重みメモリ (BF16) | 訓練時合計 | 推奨GPU | Colab T4 | Colab L4 | Apple Silicon |
|---|---|---|---|---|---|---|
| 350M | 0.7GB | ~8GB | RTX 3090 | 問題なし | 問題なし | 問題なし |
| 1.5B | 3GB | ~24GB | A100 40GB | 動作可能 | 問題なし | 動作可能 |
| 7B | 14GB | ~80GB | A100 80GB | 厳しいかも | 問題なし | 動作可能 |
| 13B | 26GB | ~160GB | A100 × 2 | 厳しい | 動作可能 | やや厳しい |
| 70B | 140GB | ~800GB | H100 × 8-16 | 不可能 | 不可能 | 不可能 |
| 175B | 350GB | ~2.5TB | H100 × 32+ | 不可能 | 不可能 | 不可能 |
各LLMモデルの規模に応じた、BF16精度での重みメモリと訓練時総メモリ使用量、推奨GPU構成の対応関係を示す参照表。350Mから175Bまでのスケール別に、実装計画と予算設計の判断基準を提供します。
📚 シリーズ案内
ブログB:実装詳細編では、Transformerの各構成要素を実装レベルで解説しています。


コメント