
因果的Attentionマスクと自己回帰型生成:GPTの生成原理
前回は、FFNと活性化関数の役割を学びました。今回は、GPT型モデルがどのようにテキストを生成するのか、その核心である自己回帰型生成 と Causal Attention Mask を解説します。
自己回帰型生成:「未来の情報を見ない」制約
GPT型のモデルは、テキストを 1トークンずつ順番に生成 します(自己回帰型):
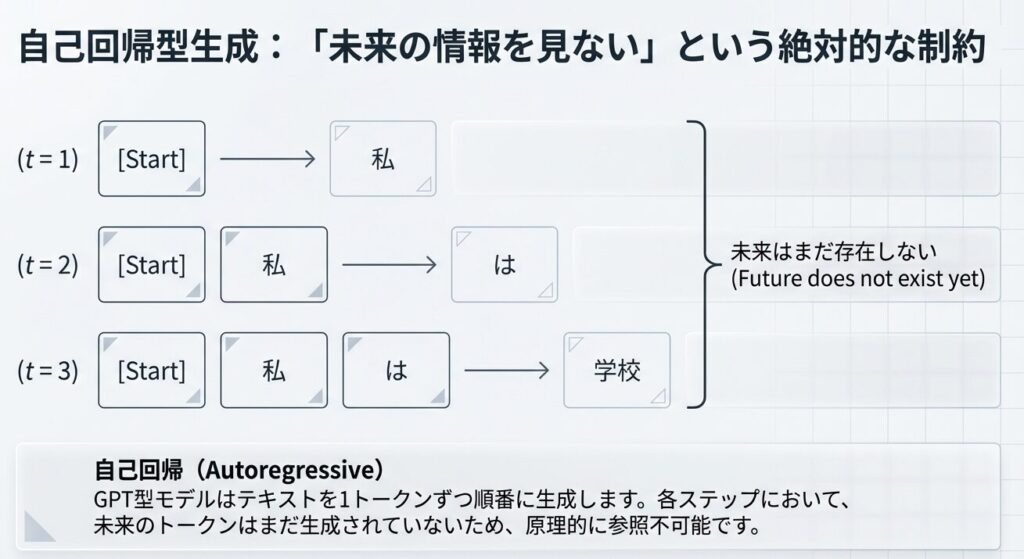
各ステップで、未来のトークンはまだ存在しないため、参照できません。
学習時の課題
上図のように訓練時には、正解の文全体が既に与えられています:
正解文:「私は学校へ行く」
入力ベクトル:[「私」, 「は」, 「学校」, 「へ」, 「行く」]⚠️ 問題
もし制約がなければ、「へ」という単語を予測する時に、未来の「行く」という情報も参照でき、『カンニング』してしまいます!これは推論時の挙動と矛盾し、モデルが実際のテキスト生成で失敗します。
Causal Attention Mask:マスキングで未来を隠す
この問題を解決するため、訓練時に Causal(因果的)Attention Mask を適用します。
マスキングの仕組み
Attentionスコア計算後、Softmax を適用する直前に、未来のトークンに対応する要素に『-∞(マイナス無限大)』を加算します。
例:3番目のトークン「学校」のAttention計算時
| ステップ | 位置0 | 位置1 | 位置2 | 位置3 | 位置4 |
|---|---|---|---|---|---|
| 通常のスコア | 0.5 | 0.3 | 0.8 | 0.2 | 0.1 |
| マスク適用後 | 0.5 | 0.3 | 0.8 | -∞ | -∞ |
| Softmax適用 | 0.4 | 0.25 | 0.35 | 0 | 0 |
結果として、各トークンは「自分自身と過去のトークンのみ」に注意を払い、未来の情報には一切アクセスできなくなります。
マスク行列の可視化
下三角行列の形になり、各位置は自分より前の位置のみを参照できます。
並列学習の実現
Causal Maskのもう1つの大きな利点は、全トークンの損失を同時に計算できることです。
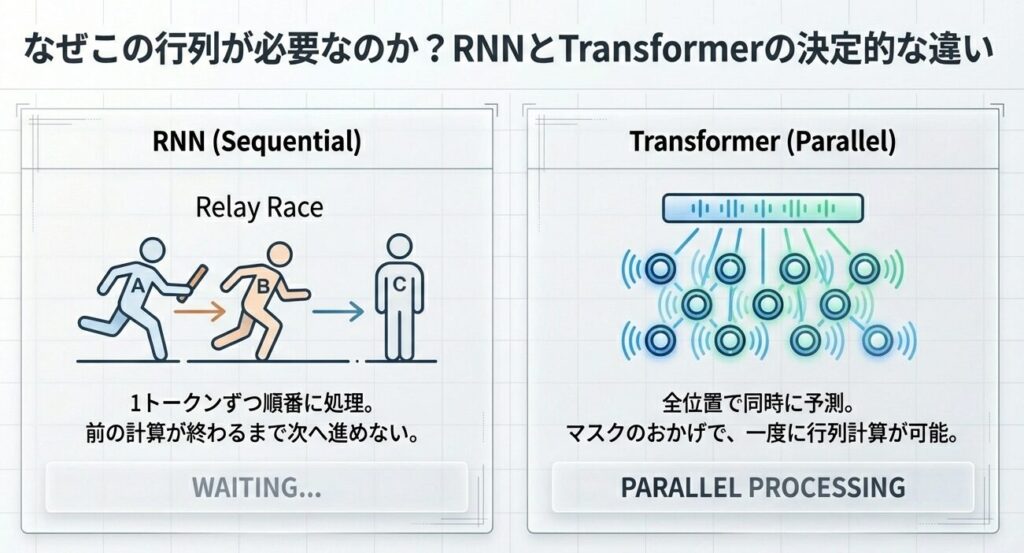
RNN vs Transformer の学習方式
| 方式 | 処理 | ステップ数 |
|---|---|---|
| RNN(順次学習) | 1トークンずつ順番に処理 | T ステップ必須 |
| Transformer(並列学習) | 全位置で同時に予測 | 1 ステップで完了 |
RNN(順次学習):
Transformer(並列学習):

全ての位置で同時に次トークン予測 → 全損失を並列計算
(T 個のトークンでも 1 ステップで計算完了!)Causal Maskにより、全トークンの損失(LOSs)を同時に計算できます。
💡 ポイント
この並列性により、Transformerは GPU/TPU の並列計算能力を最大限に活用 でき、学習時間が劇的に短縮されました。
なぜ「因果的」と呼ぶのか
「Causal(因果的)」という名前は、因果関係 の概念に由来します:
- 原因(過去)→ 結果(未来) という時間の流れを尊重
- 未来の情報が過去に影響を与えることはない(因果律)
- テキスト生成でも、前の単語が後の単語に影響を与える
テキスト生成において時間の流れと因果律を数学的に保つためのマスクなので、「因果的 Attention マスク」と呼ばれます。
まとめ
この記事では、自己回帰型生成とCausal Attention Maskを解説しました。

| 項目 | 内容 |
|---|---|
| 自己回帰型生成 | 1トークンずつ順番に生成 |
| 学習時の課題 | 未来の情報でカンニングしてしまう |
| Causal Mask | 未来のトークンを-∞でマスク |
| 効果 | 過去のみ参照 + 並列学習が可能 |
次回は、基礎用語集と確認問題でこれまでの内容を復習します。
📖 参考文献
主要論文
- Holtzman, A., Butz, D., Cohan, A., Fine, S., & Turian, J. (2020): “The Curious Case of Neural Text Degeneration”, ICLR 2020
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019): “BERT: Pre-training of Deep Bidirectional Transformers”, NAACL 2019
補足資料
3. Sennrich, R., Haddow, B., & Birch, A. (2016): “Neural Machine Translation of Rare Words with Subword Units”, ACL 2016
📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。
次に読む
- 【Transformer:基礎理論A-6】: 基礎用語集と確認問題 – これまでの内容を復習


コメント