言語モデルの本質と進化軌跡:N-gramからTransformerへ
スマートフォンのキーボードで「私は学校へ」と入力した時、次に出現しそうな単語を予測する機能が働きます。この「次に来そうな単語を予測する能力」こそが、言語モデル(Language Model) の本質です。
この記事では、言語モデルがどのように進化し、現在のChatGPTやGPT-4を支えるTransformerアーキテクチャに至ったのかを解説します。
言語モデルとは何か?
定義:確率で捉える言語
言語モデルは、単語の系列(テキスト)の生起確率をモデル化したもの です。数式で表すと:
$$P(x_1, x_2, \cdots, x_L) = \text{「単語列 } x_1, x_2, \cdots, x_L \text{ が出現する確率」}$$
この確率は、連鎖律(チェーンルール)により分解できます:
$$P(x_1, x_2, \cdots, x_L) = P(x_1) \cdot P(x_2|x_1) \cdot P(x_3|x_1, x_2) \cdots P(x_L|x_1, \cdots, x_{L-1})$$
つまり、「最初の単語の確率」× 「その後の各単語が前の情報から予測できる確率」の積で全体の確率が決まる、ということです。
実践:テキスト生成への道
この条件付き確率を活用することで、テキスト生成が実現します:
例1:決定的生成
- 入力:「日本の首都は」
- モデルの判定:$$P(\textrm{「東京」}|\textrm{「日本の首都は」}) = 0.95$$(最も高い確率)
- 出力:「東京」
例2:確率的生成(サンプリング)
同じ入力「日本の首都は」に対して、確率分布に基づいてランダムにサンプリング:
| 候補 | 確率 |
|---|---|
| 東京 | 95% |
| 京都 | 3% |
| 大阪 | 2% |
この確率分布から複数回サンプリングすることで、多様なテキストを生成できます。
デジタル時代以前の言語モデル:N-gramの限界
コンピュータが今ほど高性能でなかった時代、言語モデルはどのように実装されていたでしょうか?
N-gram言語モデルの登場
N-gramは、「直近の N-1 個の単語だけを使って次の単語の確率を推定する」という簡潔なアプローチです:
$$P(x_t | x_1, x_2, \cdots, x_{t-1}) \approx P(x_t | x_{t-n+1}, \cdots, x_{t-1})$$
具体例(3-gram の場合):
訓練データ:「私は毎日学校へ行く。私は毎日勉強する。」
学習結果:
- P(「行く」| 「毎日」, 「学校へ」) = 0.8
- P(「勉強」| 「毎日」, 「学校へ」) = 0.2N-gramの2つの根本的問題
問題1:データスパースネス(データの疎性)
N-gramが長くなるほど、訓練データ内での出現頻度が急速に減少します:
| N-gram | 例 | 出現回数 |
|---|---|---|
| 1-gram | 「学校」 | 1000回 |
| 2-gram | 「へ行く」 | 100回 |
| 3-gram | 「学校へ行く」 | 5回 |
| 4-gram | 「学校へ行く」 | 0回(見たことない!) |
見たことのないパターンは確率が計算できず、モデルは新しい文章の理解に失敗します。
問題2:長距離の関係を理解できない

N-gramは「直近 N-1 個」の単語しか見ないため、遠く離れた単語との関係を全く把握できません:
例文:「私が学生の時に習った先生は、
今も同じ学校で教えている。」
↑
これが何を指すのか?
N-gramは遠くの「先生」を見られないこの2つの問題が、N-gramベースの言語モデルを実用化から遠ざけていました。
ニューラル言語モデルへの転換
データスパースネスと長距離依存性の問題を解決するため、コンピュータサイエンスは新たな道を探ります。その答が、ニューラルネットワーク を使った言語モデリングでした。
【ニューラルネットワークの詳細】

【ニューラルネットワークを使った言語モデリング(RNN)の詳細】

RNN(再帰型ニューラルネットワーク)の登場
RNNは、各時刻の状態を次の時刻に「隠れ状態」として引き継ぐ構造を持ちます:

RNNは、長い系列全体を処理して「文脈」を保持できるため、遠い単語との関係を理解できます。
RNNの致命的な問題:勾配消失と学習の遅さ
しかし、RNNは深刻な2つの問題を抱えていました:
問題1:勾配消失(Vanishing Gradient)

遠い過去の情報を学習する際、勾配が層を遡る過程で段々と0に近づいてしまいます。結果として、遠い過去の単語情報は学習に反映されません。
問題2:学習の並列化が不可能
RNNは逐次的に処理するため、各タイムステップの計算が前のステップに依存します。最新のGPUでも各ステップを同時処理できないため、1000個のトークンを処理するのに最低1000ステップの計算時間が必要 でした。

Transformerの革命:「Attention Is All You Need」(2017年)
2017年、Google の研究チームが発表した論文 「Attention Is All You Need」 は、これまでの言語モデリングに革命をもたらしました。
【Attentionまでの言語モデリングの経緯】

Transformerの2つの根本的な革新
革新1:Attentionメカニズムによる長距離依存性の解決
Transformerは、全てのトークン間に直接的な接続を確立 します:
入力トークン: [「私」, 「は」, 「学校」, 「へ」, 「行く」]
↓ ↓ ↓ ↓ ↓
←→ ←→ ←→ ←→ ←→ (全ペアを直接つなぐ!)
↓ ↓ ↓ ↓ ↓
出力: 文脈情報を含んだ新しいベクトル💡 ポイント
任意の距離の単語間関係を1ステップで捉えられるため、勾配消失問題を解決し、理論上「無限に遠い関係」も学習可能になりました。
革新2:並列計算による学習の劇的な高速化
RNNと異なり、Transformerは 全トークンを同時に処理 できます:
| 方式 | 1000トークン処理 |
|---|---|
| RNN(順次処理) | 1000ステップ必須 |
| Transformer(並列処理) | 1ステップで完了 |
結果として、GPU の並列計算能力をフルに活用でき、大規模データでの訓練時間が数十分の一に短縮 されました。
Transformerがもたらした大規模言語モデル時代
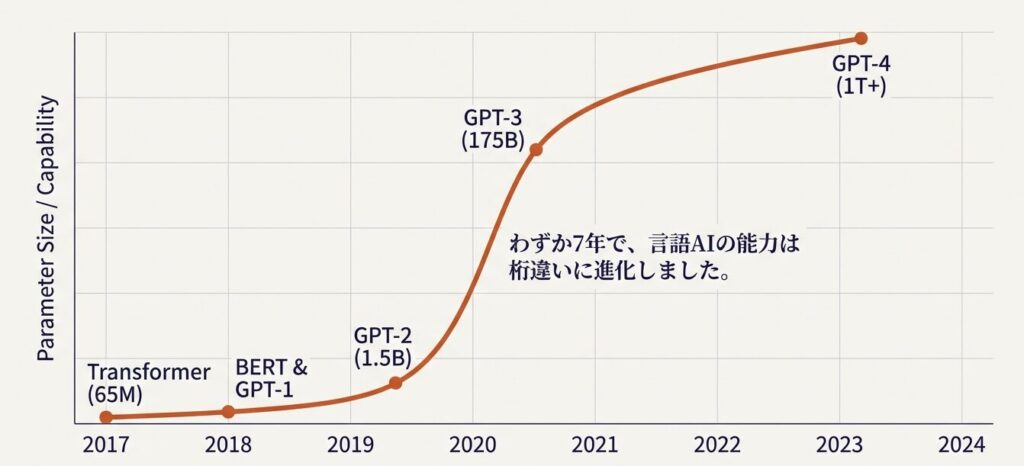
Transformerアーキテクチャの誕生により、LLM開発は急速に加速しました:
| 時期 | モデル名 | パラメータ数 | 特徴 |
|---|---|---|---|
| 2017年 | Transformer (元論文) | 65M | アーキテクチャ提案 |
| 2018年 | BERT | 340M | 双方向Transformer |
| 2018年 | GPT-1 | 117M | 単方向Transformer(生成) |
| 2019年 | GPT-2 | 1.5B | 大規模化の可能性を実証 |
| 2020年 | GPT-3 | 175B | Few-shot 学習の驚異的な能力 |
| 2023年 | GPT-4 | 1-1.8T (推定) | 高度な推論能力 |
| 2024年 | Gemini 2.5 | 規模未公開 | マルチモーダル性能 |
このように、Transformerはわずか7年で、言語処理のパラダイム全体を塗り替えた のです。
まとめ
この記事では、言語モデルの本質から、N-gram、RNN、Transformerへの進化を解説しました。
| 技術 | 長距離依存性 | 並列計算 | 課題 |
|---|---|---|---|
| N-gram | ❌ 不可 | ✅ 可能 | データスパースネス |
| RNN | △ 限定的 | ❌ 不可 | 勾配消失、遅い |
| Transformer | ✅ 完全解決 | ✅ 可能 | メモリ使用量 |
次回は、Transformerの具体的なモデル構造を詳しく解説します。
参考文献
主要論文
- Vaswani, A., et al. (2017): “Attention Is All You Need”, NeurIPS 2017
- https://arxiv.org/abs/1706.03762
- 現代LLMの基盤となるTransformerアーキテクチャを提案
- Hochreiter, S., & Schmidhuber, J. (1997): “Long Short-Term Memory”, Neural Computation
- https://www.bioinf.jku.at/publications/older/2604.pdf
- RNNの勾配消失問題を解決するLSTM
- Bahdanau, D., Cho, K., & Bengio, Y. (2015): “Neural Machine Translation by Jointly Learning to Align and Translate”, ICLR 2015
- https://arxiv.org/abs/1409.0473
- Attentionメカニズムの登場
補足資料
- Mikolov, T., et al. (2013): “Efficient Estimation of Word Representations in Vector Space”, ICLR 2013
- https://arxiv.org/abs/1301.3781
- Word2Vec。分散表現の基礎理論
📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。


コメント