
Multi-Head Attentionの詳細メカニズム:文脈理解の核心
前回は、Transformerの全体構造を学びました。今回は、その心臓部であるAttentionメカニズムを詳しく解説します。ここで押さえたいのは、Attentionが単なる「重み付け」ではなく、文脈の中でどの単語を重視するかを決める仕組みだという点です。
以前のブログでもTransformerについては触れていますが、この記事ではそこから一歩進めて、Attentionが何を解決しようとしているのかを、図と例を見ながら順番に確認します。細かな数式を暗記するより、まずは流れをつかむことを優先します。

Attentionの本質:「文脈に応じた注視」
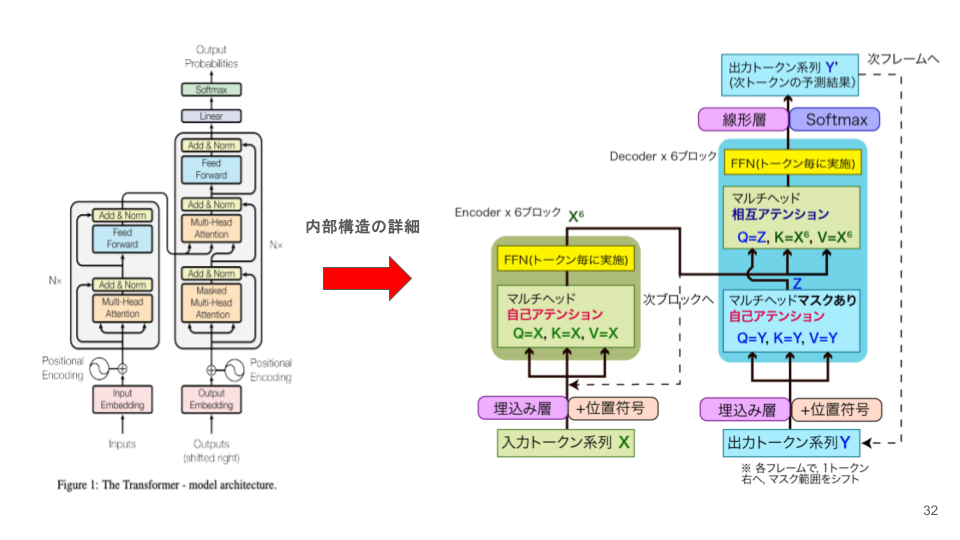
上図ではTransformer全体図を扱っていますが、現在の大規模言語モデルの多くは「Decoder-only(デコーダーのみ)」のアーキテクチャを採用しています。そのため、ここでは全体図を踏まえたうえで、実際のLLMで中心になるMulti-Head Attentionに焦点を当てます。まずは、Attentionがなぜ必要なのかという視点で見ていきます。
言語を理解するときに難しいのは、単語そのものの意味ではなく、「この状況で、どの単語が重要か?」 を判断することです。同じ単語でも、周囲の文脈によって役割が変わるからです。
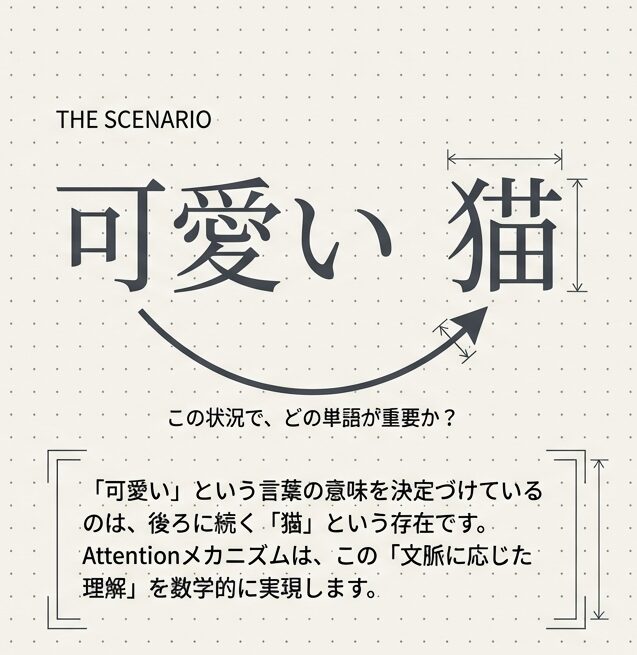
例:
文1: 「銀行に行った」
↑ 「銀行」は金融機関の意味
文2: 「川の土手に行った」
↑ 「土手」という単語が文脈を変える単語の意味は、周囲の文脈に依存しています。Attentionメカニズムは、この「どの単語を、どれくらい見るべきか」をモデル自身に決めさせる仕組みです。ここが、単語を単純に並べるだけの方式との大きな違いです。
Scaled Dot-Product Attention:4ステップで分かる仕組み
Scaled Dot-Product Attentionとは、Attentionメカニズムの具体的な計算アルゴリズムです。ここでは、入力シーケンス内の単語同士がどれだけ関係しているかを、数値として順番に計算します。
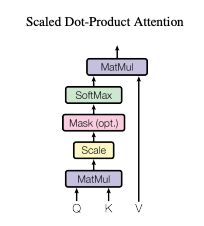
Attentionは、以下の4つのステップで計算されます。流れを先に見ておくと、Q・K・V の役割が後から整理しやすくなります。
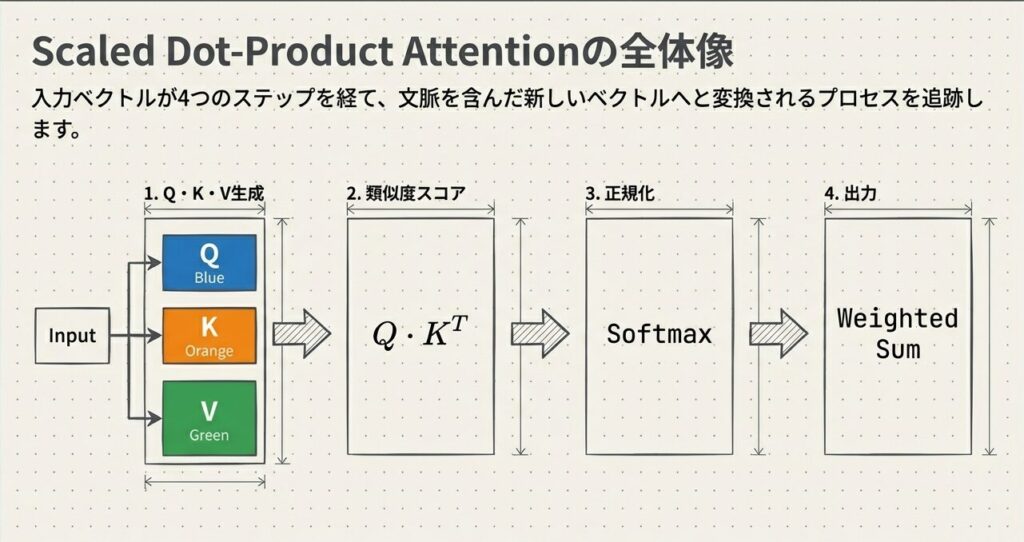
ステップ1:Q, K, Vベクトルの生成
入力ベクトル $x$ から、3種類のベクトルを線形変換で生成します:
Attentionメカニズムの文脈理解は、Q・K・V を作り、類似度を計算し、重みを正規化し、最後に文脈を反映した出力を作る、という流れで進みます。
$$Q = x \cdot W^Q, \quad K = x \cdot W^K, \quad V = x \cdot W^V$$
| ベクトル | 名前 | 役割 |
|---|---|---|
| Q | Query(問い合わせ) | 「何について情報が欲しいのか?」 |
| K | Key(鍵) | 「何に関する情報か?」 |
| V | Value(値) | 「実際の情報内容」 |
具体例:
入力:「猫は可愛い」
Q生成:「このトークンの意味を理解したい」という問い合わせ
K生成:「このトークンは何に関連しているか」のインデックス
V生成:「このトークンの情報(意味・文法等)」ステップ2:類似度スコアの計算
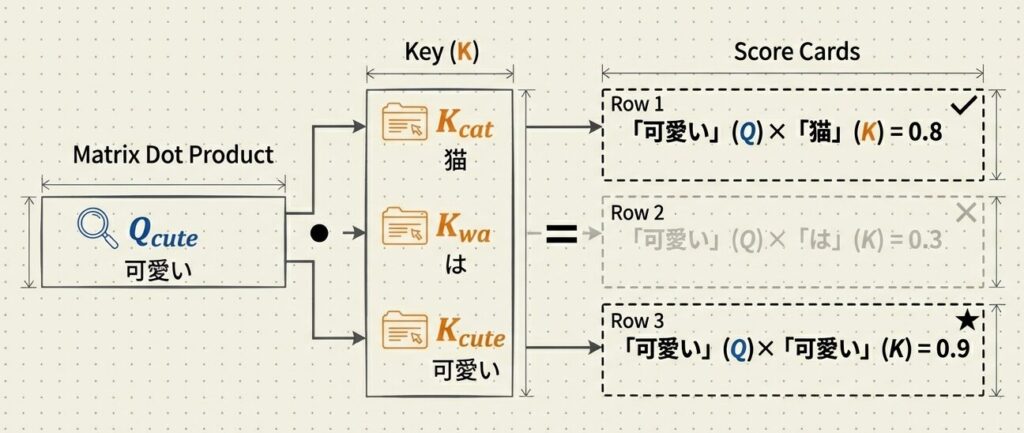
Qベクトルと全てのKベクトルの内積を計算し、「どのトークンが関連しているか」を数値化します:
$$\text{Score} = Q \cdot K^T / \sqrt{d_k}$$
ここで $\sqrt{d_k}$ は、スコアの分散を安定させるためのスケーリングファクターです。
具体例(「可愛い」という単語に対する計算):
| 組み合わせ | スコア | 解釈 |
|---|---|---|
| 「可愛い」のQ × 「猫」のK | 0.8 | 高い相関 → 関連度 高 |
| 「可愛い」のQ × 「は」のK | 0.3 | 低い相関 → 関連度 低 |
| 「可愛い」のQ × 「可愛い」のK | 0.9 | 自分自身 → 最高 |
ステップ3:Attention Weight の正規化
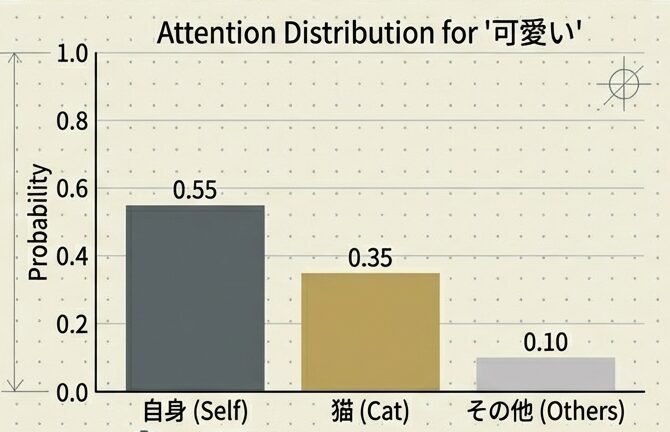
スコアを Softmax関数 に通し、合計が1になるように正規化します:
$$\text{Weight} = \text{Softmax}\left(\frac{Q \cdot K^T}{\sqrt{d_k}}\right)$$
スコア: [0.8, 0.3, 0.9]
↓ Softmax
Weight: [0.35, 0.10, 0.55]
(合計 = 1.0)これが「注意の重み(Attention Weight)」で、「各トークンにどれだけ注意を払うか」を表します。
ステップ4:出力ベクトルの生成
Attention Weight とVベクトルを掛け合わせ、加重平均を計算します:
$$\text{Output} = \sum_{i} \text{Weight}_i \cdot V_i$$
Output = 0.35 × 「猫」のV + 0.10 × 「は」のV + 0.55 × 「可愛い」のV結果:「可愛い」という単語の意味が、主に「可愛い」自身(55%)と「猫」(35%)という文脈から形成される新しいベクトルになります。
【Scaled Dot-Product Attentionの詳細】
スケーリング係数 $\sqrt{d_k}$ の役割
$\sqrt{d_k}$ は、スコアの分散を安定させるためのスケーリングファクター
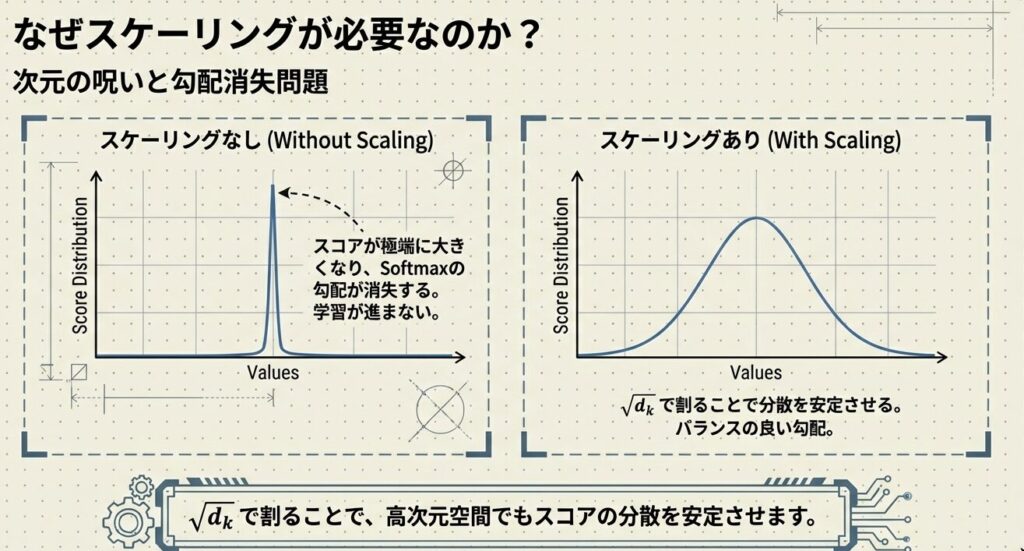
Attention計算では、なぜ内積を次元数の平方根で割る必要があるのか?
次元が大きいと内積が大きくなる原因
ベクトルの次元数 $d$ が大きいほど、内積は自動的に大きな値になります:
| 次元数 | 標準偏差 |
|---|---|
| d=64 | ≈ 8 |
| d=1024 | ≈ 32 |
Softmax関数への悪影響
大きなスコアをSoftmaxに通すと、一部に極端に集中してしまいます:
| スコア | Softmax後の分布 | 状態 |
|---|---|---|
| [0.1, 0.2, 0.3] | [0.29, 0.33, 0.37] | バランス良い |
| [10, 20, 30] | [0.0000, 0.0001, 0.9999] | 一部に集中! |
スケーリングによる解決
$$\frac{Q \cdot K^T}{\sqrt{d_k}}$$
で割ることで、スコアの分散を安定させ、Softmaxの出力を「バランスの取れた分布」に保ちます。
スケーリング前: [10, 20, 30] → 分散が大きい(問題あり)
スケーリング後: [1.25, 2.5, 3.75] → 分散が適切に
Softmax後: [0.15, 0.23, 0.62] → バランスが取れているMulti-Head Attention:複数の視点から理解する
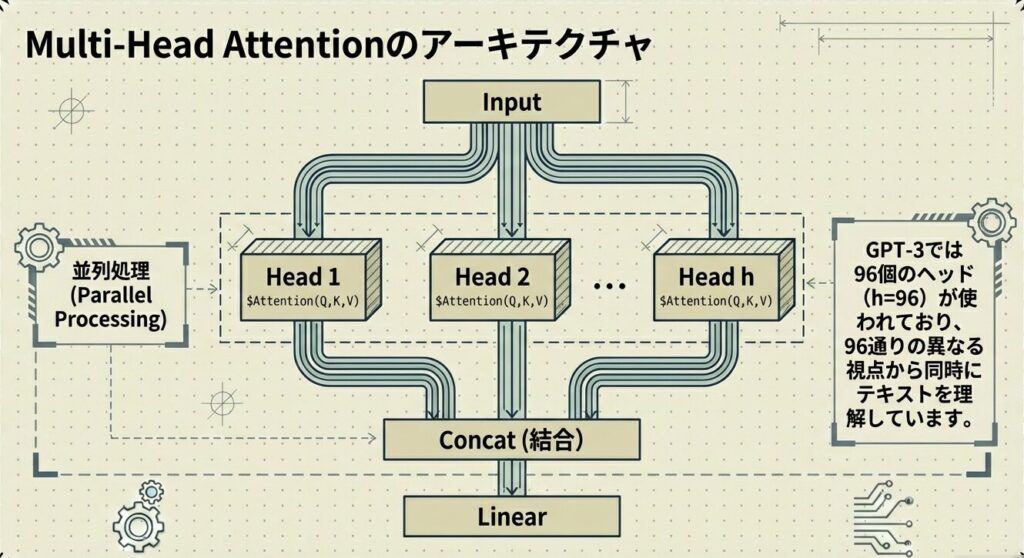
Attentionの計算を1回だけ行うのではなく、異なる線形変換を使って複数回(複数ヘッド)実行し、その結果を統合する のが Multi-Head Attention です。つまり先ほどのScaled Dot-Product Attentionを複数回実行し、その結果を統合するAttention機構であるということです。
なぜ複数ヘッドなのか?
| ヘッド | 注目する関係性 | 例 |
|---|---|---|
| ヘッド1 | 文法的な関係性 | 「名詞」「動詞」の品詞関係 |
| ヘッド2 | 意味的な関係性 | 「主語」「目的語」の役割関係 |
| ヘッド3 | 共参照的な関係性 | 「猫」と「その」の指示対象 |
| ヘッド4-8 | その他の多角的な関係性 | … |
各ヘッドが異なる側面からトークン間の関係を捉え、それらを統合することで、より豊かで正確な文脈理解が実現されます。
実装:並列実行と統合
💡 ポイント
GPT-3では、通常 h=96 個のヘッド が使われており、96個の異なる視点からテキストを理解しています。
まとめ
Attentionメカニズムの文脈理解のプロセス
| ステップ | 処理内容 |
|---|---|
| 1. Q, K, V生成 | 入力から3種類のベクトルを生成 |
| 2. スコア計算 | Q・Kの内積で類似度を算出 |
| 3. 正規化 | Softmaxで確率分布に変換 |
| 4. 出力生成 | Weightとの加重平均で最終出力 |
Multi-Head Attentionにより、複数の視点からの文脈理解が可能になります。Attention を1回だけ使うのではなく、役割の違う複数の視点を並行して持たせることで、文法だけでなく意味や指示対象まで拾いやすくなります。
📖 参考文献
主要論文
- Vaswani, A., et al. (2017): “Attention Is All You Need”, NeurIPS 2017
- Jain, S., & Wallace, B. C. (2019): “Attention is Not Explanation”, ACL 2019
- Michel, P., Levy, O., & Neubig, G. (2019): “Are Sixteen Heads Really Better than One?”, NeurIPS 2019
📚 シリーズ案内
この記事は「LLM事前学習シリーズ」の一部です。

コメント