
標準ベンチマークの詳細解説:GLUE、MMLU、BLEU、ROUGEの完全ガイド
LLM評価では、指標名は知っていても「何を測っているのか」「どのベンチマークを使えばよいのか」が曖昧なままになりやすいです。この記事では、標準ベンチマークの役割を整理し、GLUE、MMLU、SQuAD、BLEU、ROUGEをどう読み分けるかを確認します。
この記事で扱うのは、代表的な標準ベンチマークの構成、スコアの見方、選び方です。独自評価系の設計や実装最適化は扱わず、まずは比較の土台をそろえることに絞ります。
実務で迷いやすいのは、スコアそのものよりも「この数字で何を判断してよいのか」です。GLUE が高いからといって知識問題に強いとは限りませんし、ROUGE が高いからといって翻訳品質まで保証されるわけでもありません。重要なのは、ベンチマークを定義の暗記として見るのではなく、用途ごとの判断材料として読むことです。
| ベンチマーク | 主な対象 | 何を測るか | 見方の要点 |
|---|---|---|---|
| GLUE | 言語理解 | 分類、推論、類似度 | 総合的な理解力を見る |
| MMLU | 知識・推論 | 多分野の4択問題 | 知識の広さと推論力を見る |
| SQuAD | 質問応答 | 文章から答えを抜く力 | 抽出精度と完全一致を見る |
| BLEU | 翻訳 | 参照文との一致度 | 正確に訳せているかを見る |
| ROUGE | 要約 | 参照要約との重複度 | 重要情報を落としていないかを見る |
この整理だけでも、ベンチマークごとに見ている能力が違うことは分かります。以下では、まず言語理解の基準になる GLUE から見て、そのあとに知識・推論、質問応答、生成品質、信頼性の順で確認します。
1. テキスト分類系:GLUE
GLUE は、標準ベンチマークの中でも最初に押さえたい基準です。個別タスクの違いを追う前に、言語理解の総合評価としてどう見られているかを理解しておくと、後続の MMLU や SQuAD も読みやすくなります。
言い換えると、GLUE は「モデルが文章をどれくらい素直に理解できるか」を最初に見るための入口です。分類、推論、類似度といった基本能力を広く押さえたいときに向いています。
1.1 GLUEとは
GLUE(General Language Understanding Evaluation) は、言語理解能力を測る基本的なベンチマークセットです。
GLUE の基本情報は次の通りです。
| 項目 | 内容 |
|---|---|
| 目的 | 言語理解能力の総合評価 |
| 構成 | 9つのタスク |
| スコア | 各タスクの平均(0-100) |
| 言語 | 英語 |
1.2 GLUE 構成タスク(9個)
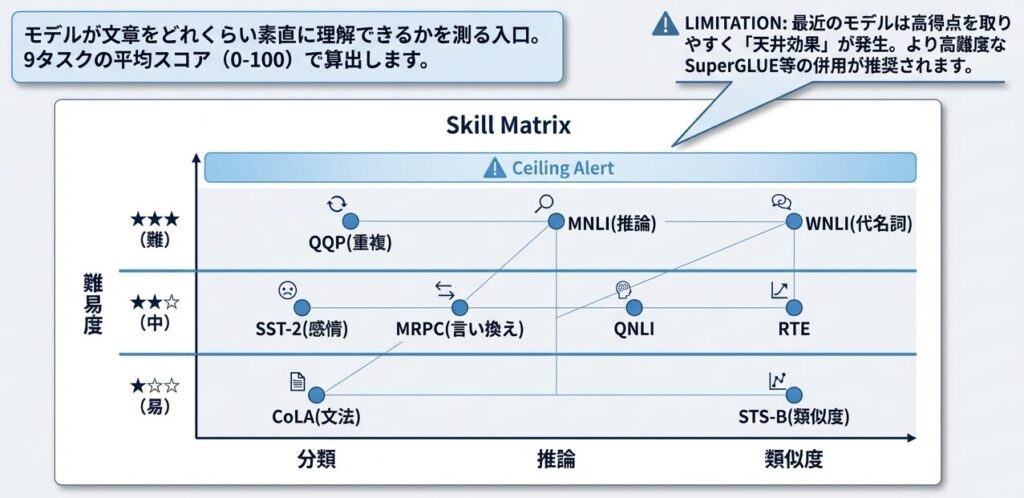
GLUE の 9 タスクは、次のように整理できます。
| タスク | 主な内容 | データ数 | メトリック | 難易度 |
|---|---|---|---|---|
| CoLA | 文法判定 | 8,551文 | Matthews相関係数 | ★☆☆ |
| SST-2 | 感情分析(肯定/否定) | 67,000映画レビュー | Accuracy | ★★☆ |
| MRPC | 言い換え判定 | 5,749ペア | F1、精度 | ★★☆ |
| QQP | 質問重複判定 | 363,849ペア | F1、精度 | ★★★ |
| MNLI | 自然言語推論 | 392,702 | 精度 | ★★★ |
| QNLI | 質問と文の対応判定 | 108,436 | 精度 | ★★☆ |
| RTE | 推論が成立するか | 2,490 | 精度 | ★★☆ |
| WNLI | 代名詞解析 | 635 | 精度 | ★★★ |
| STS-B | 文の意味的類似度 | 5,749ペア | Pearson相関係数、Spearman相関 | ★☆☆ |
1.3 GLUE スコアの計算
GLUE の統合スコアは、9 タスクの平均で見るのが基本です。
| 例 | スコア |
|---|---|
| GPT-2 | 72.8/100 |
| BERT | 80.5/100 |
| RoBERTa | 88.3/100 |
| GPT-3 | 87.7/100 |
1.4 GLUEの限界
GLUE は有用ですが、これだけで最新モデルの性能を語るには不十分です。比較的簡単なタスクが多く、モデルが高得点を取りやすくなったため、今では後継ベンチマークとあわせて見るのが自然です。
GLUE には限界もあります。
- タスクが比較的「簡単」になった
- 最新モデルでは天井効果が出やすい
- 人間超えを達成するモデルが増えた
後継としては、より難しい 8 タスクを含む SuperGLUE や、多言語版の XTREME が使われます。
2. 知識・推論系:MMLU
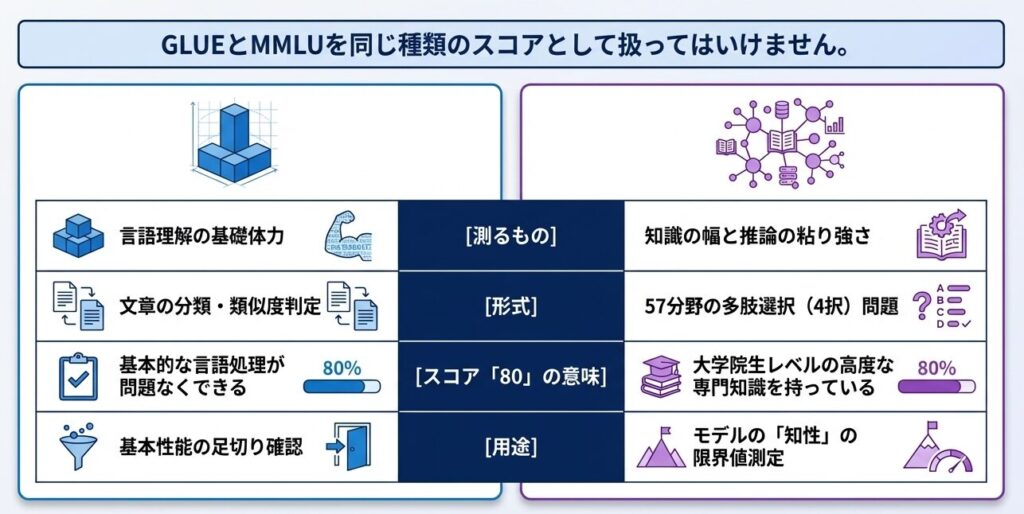
GLUE が「言語理解の基礎」だとすると、MMLU は「幅広い知識と推論をどこまで扱えるか」を見る基準です。モデルの一般知識の強さを確認したいときに、特に差が出やすい指標です。
ここで大事なのは、GLUE と MMLU を同じ種類のスコアとして扱わないことです。GLUE が言語理解の基礎体力を見るのに対し、MMLU は知識の幅と推論の粘り強さを見るため、同じ 80 点台でも意味はかなり異なります。
2.1 MMLUとは
MMLU(Massive Multitask Language Understanding) は、大規模言語モデルの知識・推論能力をテストします。
MMLU の概要は次の通りです。
| 項目 | 内容 |
|---|---|
| 規模 | 57,000+ 選択肢問題 |
| 分野 | 57 カテゴリ |
| 言語 | 英語 |
| 形式 | 4択の多肢選択問題 |
| 難易度 | 大学レベル〜大学院レベル |
2.2 57分野の分類
MMLU の 57 分野は、大きく次の 4 群に分かれます。
| 区分 | 主な分野 |
|---|---|
| STEM(14分野) | 数学、物理、化学、生物学、コンピュータ科学、電気工学、天文学、統計学など |
| 社会科学(15分野) | 経済学、政治学、心理学、社会学、地理学、法学、経営学など |
| 人文科学(14分野) | 歴史、文学、哲学、倫理学、宗教学、言語学、芸術など |
| その他(14分野) | 医学、法律、会計、ビジネス、看護学、薬学、マーケティングなど |
2.3 性能比較表

| モデル | 性能(スコア) | 難易度対応 |
|---|---|---|
| ランダム回答 | 25% | 最低 |
| GPT-3(175B) | 43.9% | 基礎知識 |
| GPT-3.5 | 70% | 大学レベル |
| GPT-4 | 86.4% | 大学院レベル |
| Claude 3 Opus | 86.8% | 大学院レベル |
| 人間平均 | 89% | 専門家レベル |
2.35 GLUE vs MMLU
2.4 MMLUの解釈
MMLU のスコアは、単に高いか低いかだけでなく、どの知識層まで安定して答えられるかを見るのに向いています。25〜35% ならほぼランダムに近く、70% を超えてくると、大学レベルの知識問題にかなり対応できていると考えやすくなります。
MMLU のスコア解釈は、次のように見ると分かりやすいです。
- 25〜35%: ランダム回答レベル。知識をほとんど持っていない状態です。
- 35〜50%: 基礎的な知識レベル。一般常識が中心です。
- 50〜70%: 大学学部レベル。専門知識の基礎があります。
- 70〜85%: 大学院レベル。専門的な知識を持っています。
- 85%+: 専門家レベル。人間専門家に近い水準です。
3. 質問応答系:SQuAD
SQuAD は、文章を読んでその中から答えを抜き出す力を測ります。生成系の評価とは違い、答えが文中にある前提でどれだけ正確に拾えるかを見るので、検索や抽出寄りのユースケースと相性が良いです。
そのため、SQuAD は「知っているか」よりも「見つけて抜き出せるか」を見る指標と考えると理解しやすくなります。RAG や検索支援のように、根拠が与えられる前提のタスクでは特に参考になります。
3.1 SQuADとは
SQuAD の概要は次の通りです。
| 項目 | 内容 |
|---|---|
| 正式名称 | Stanford Question Answering Dataset |
| タスク | 文章中から質問の答えを抽出 |
| 形式 | 入力は文章 + 質問、出力は該当箇所(span) |
| バージョン | 1.1 は全件に答えあり、2.0 は答えなし質問を含む |
3.2 評価メトリック
SQuAD では、EM と F1 の両方を並べて見るのが基本です。完全一致だけだと少しの表記差を見落としますし、F1 だけだと意味の違いを拾い切れないため、両方を使うと評価の粒度が揃います。
| 指標 | 見るもの | 補足 |
|---|---|---|
| Exact Match (EM) | 完全一致した回答の割合 | 正解と完全一致したかを見る |
| F1スコア | 部分一致も含めた指標 | Precision と Recall の両方を使う |
性能例としては、BERT が EM=85.1%、F1=93.2%、RoBERTa が EM=89.8%、F1=95.4%、人間が EM=82.3%、F1=91.2% です。最新モデルは人間を超えることもありますが、完全一致だけでは拾えない差があるため、F1 も併記した方が解釈しやすくなります。
4. 品質測定系:BLEU と ROUGE
ここからは、生成文の品質をどう読むかに移ります。翻訳と要約では良し悪しの見方が違うため、BLEU と ROUGE を分けて考えることが大切です。
一言でいうなら、BLEU は「どれだけ正確に合わせられたか」、ROUGE は「重要な内容をどれだけ落とさなかったか」を見る指標です。似たように見える生成評価でも、用途が変わると見るべき数字も変わります。
4.1 BLEU スコア
BLEU は、機械翻訳の品質評価でよく使われます。
| 項目 | 内容 |
|---|---|
| 正式名称 | Bilingual Evaluation Understudy |
| 用途 | 機械翻訳の品質評価 |
| 定義 | 生成テキストと参照テキストの N-gram 重複度 |
| 範囲 | 0-100(100が最高) |
計算の考え方は、N-gram の一致度に brevity penalty を掛ける形です。スコアの目安は、10 未満ならかなり不正確、10〜30 でかろうじて理解可能、30〜50 で読める翻訳、50〜70 で高品質、70 超で優秀と見ます。
4.2 ROUGE スコア
ROUGE は、テキスト要約の品質評価で使います。
| 項目 | 内容 |
|---|---|
| 正式名称 | Recall-Oriented Understudy for Gisting Evaluation |
| 用途 | テキスト要約の品質評価 |
| 定義 | 生成要約と参照要約の重複率(Recall重視) |
| 範囲 | 0-1(1が最高) |
代表的なバリアントは、ROUGE-1 が単語レベルの重複、ROUGE-2 が 2 語連鎖の重複、ROUGE-L が最長共通部分列の重複です。スコアは 0.30 未満で低品質、0.30〜0.40 で中程度、0.40〜0.50 で良好、0.50 超で優秀と見ます。
4.3 BLEUとROUGEの違い
この2つは似て見えても、重視している方向が違います。翻訳のように「どれだけ正確に一致しているか」を見るなら BLEU、要約のように「重要な内容を落とさず含めているか」を見るなら ROUGE が向いています。
BLEU と ROUGE の違いは次の通りです。
| 項目 | BLEU | ROUGE |
|---|---|---|
| 用途 | 翻訳評価 | 要約評価 |
| 重視 | Precision(正確さ) | Recall(網羅性) |
| 範囲 | 0-100 | 0-1 |
| N-gram | 1〜4gram平均 | 1, 2, L 個別 |
使い分けとしては、翻訳なら BLEU、要約なら ROUGE を見るのが自然です。
5. 新興ベンチマーク:幻覚と信頼性
最近は、単純な正答率だけでは見えない問題も重視されるようになっています。幻覚やバイアスのような信頼性の指標をあわせて見ると、実運用での安心感を判断しやすくなります。
これは、ベンチマークの数字が高くても、そのまま実運用で安心して使えるとは限らないからです。見た目の性能と運用上の信頼性を分けて考えることで、評価結果の読み違いを減らせます。
5.1 幻覚(Hallucination)検出
幻覚(Hallucination)は、モデルが「ありもしない情報を生成する」ことです。例としては、「日本の首都は?」に対して「東京とニューヨークの中間点」のような回答を返すケースが該当します。
検出では、Fact-checking API による照合、確信度スコア、エントロピーの確認が使われます。幻覚率は「幻覚を含む回答 / 全回答数」で見て、5% 未満なら非常に高信頼、5〜15% なら実用的、15〜30% なら要注意、30% 超なら信頼性に問題があると考えます。
5.2 信頼性総合スコア
信頼性の総合スコアは、幻覚率、バイアススコア、有害出力率、一般化スコアを組み合わせて見ます。たとえば、幻覚率 10%、バイアス 5%、有害出力率 2%、一般化スコア 85% なら、信頼性スコアは 0.90 × 0.95 × 0.98 × 0.85 = 0.71 です。

6. How: ベンチマークの選び方
ここまで見てきた通り、ベンチマークは用途ごとに役割が違います。評価の目的を先に決めてから指標を選ぶと、スコアの解釈を誤りにくくなります。
重要なのは、何が有名かで選ぶことではありません。どの失敗を避けたいか、どの能力を確認したいかで選ぶことです。つまり「何があるか」より「どの問題に何が効くか」で見る方が、実務では判断しやすくなります。
6.1 目的別ベンチマーク選択
目的別の選び方は、次のようにまとめられます。
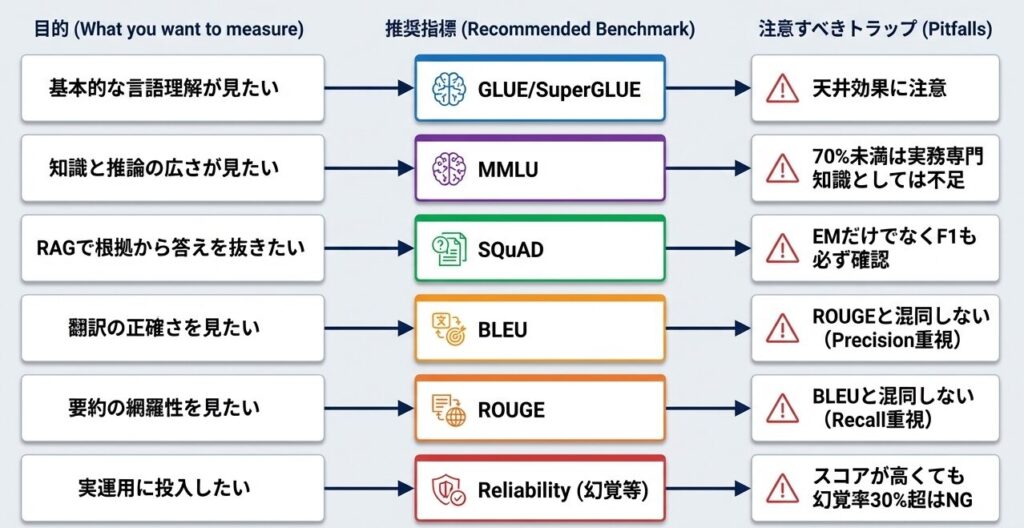
最初の判断を単純化するなら、次の見方で十分です。
- 基礎的な言語理解を見たいなら GLUE
- 知識と推論の広さを見たいなら MMLU
- 根拠文から答えを抜く力を見たいなら SQuAD
- 翻訳の正確さを見たいなら BLEU
- 要約の情報保持を見たいなら ROUGE
- 実運用の安心感を見たいなら信頼性指標
6.2 スコア比較の注意点
特に注意したいのは、異なるベンチマークの数字をそのまま横並びで比べないことです。スコアは条件が揃って初めて意味を持つので、同じベンチマーク、同じバージョン、同じ設定で比較するのが前提になります。
比較するときの注意点は 3 つです。
- 異なるベンチマーク間の数字は、そのまま比較しない
- バージョン違いは難易度が異なる前提で見る
- 同じベンチマーク、同じバージョン、同じ設定で比較する
よくある失敗は、手元にある数字をそのまま並べて「こちらのモデルの方が上」と結論づけてしまうことです。GLUE 85% と MMLU 85% は同じ意味ではありませんし、SQuAD 1.1 と 2.0 も難しさが違います。評価を設計するときは、数字の大きさより比較条件を先に固定する方が重要です。
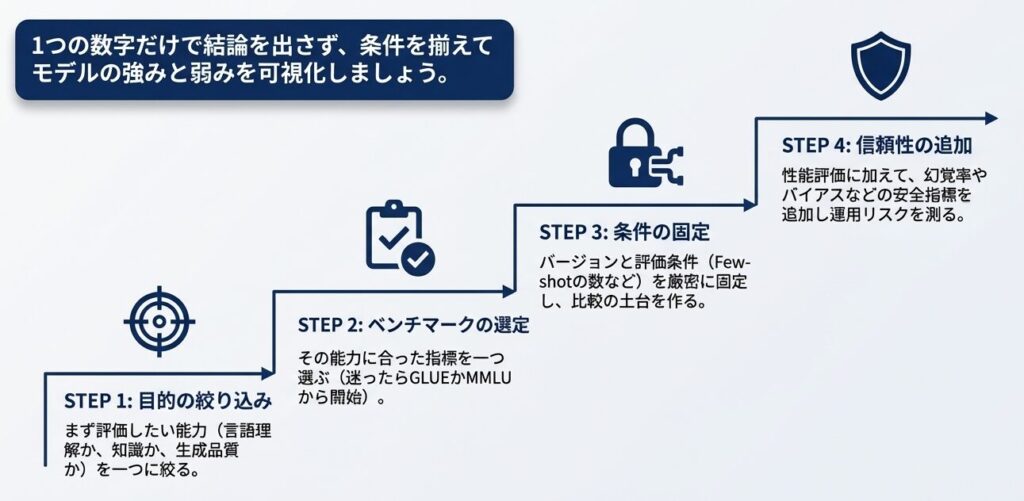
6.3 評価環境を構築する4ステップ
7. よくある読み違いと対策
ここまでの内容を実務に落とすときは、スコアの意味を取り違えないことが一番の注意点です。ベンチマークは便利ですが、読み方を誤ると判断がずれます。
失敗1:GLUE や MMLU の数字を同じ尺度で見てしまう
GLUE は言語理解の基礎体力、MMLU は知識の広さと推論力を見る指標です。数字がどちらも 80 点台だからといって、同じ意味ではありません。対策は、ベンチマークごとの役割を分けて見ることです。
失敗2:SQuAD を EM だけで判断してしまう
完全一致だけを見ると、少しの表記揺れで過小評価しやすくなります。逆に F1 だけだと、答えの本質的な違いを見落とすことがあります。対策は、EM と F1 をセットで見ることです。
失敗3:BLEU と ROUGE を用途外で使ってしまう
BLEU は翻訳、ROUGE は要約に向いた指標です。翻訳で ROUGE を見ても、要約で BLEU を見ても、判断はぶれやすくなります。対策は、用途に合う指標を先に決めることです。
失敗4:幻覚率を平均精度の中に埋もれさせる
精度が高くても、危険な誤答を時々出すモデルは実務で扱いづらいです。対策は、信頼性を別指標として切り出して確認することです。
8. Next action: 次に確認すること
次にやることは、使うベンチマークを一つ決めて、バージョンと評価条件を固定することです。まずは GLUE か MMLU のどちらかを選び、同じ条件で比較できる状態を作ると、スコアの意味がぶれにくくなります。
標準ベンチマークを正しく読むコツは、1つの数字だけで結論を出さないことです。何を測る指標なのか、どの条件で取った数字なのかをそろえて見ると、モデルの強みと弱みが見えやすくなります。
もし最初の一歩で迷うなら、次の順序で十分です。
- まず評価したい能力を一つに絞る
- その能力に合ったベンチマークを一つ選ぶ
- バージョンと設定を固定して比較する
- 必要なら信頼性指標を追加する
次の記事では、この評価の土台を前提に、より実運用に近い観点へ進みます。
9. 今回のブログの考察
標準ベンチマークを整理してみると、評価は単に有名なスコアを覚える作業ではなく、「何を測っている数字なのか」を見分ける作業だと分かります。GLUE は言語理解の基礎体力、MMLU は知識と推論の広さ、SQuAD は根拠文から答えを抜き出す力、BLEU と ROUGE は生成品質の見方の違いを表しています。今回の記事で伝えたかったのは、同じ“高スコア”でも意味は揃っていない、という当たり前だが見落としやすい点です。
実務で迷いやすいのは、どの指標が高いかではなく、どの失敗を避けたいかです。翻訳の精度を見たいのに ROUGE を見てしまったり、知識の広さを測りたいのに GLUE だけで判断してしまったりすると、評価の数字は並んでいても意思決定はずれていきます。だからこそ、ベンチマークは“点数表”ではなく、“用途に応じた確認項目”として読む必要があります。
その意味で、この記事の本質は、指標を増やすことではなく、指標の役割を分けて考えることにあります。何を測るか、どの条件で比較するか、そしてその数字で何を判断するのかが整理できていれば、評価はモデルの優劣を競うだけの作業ではなく、開発方針を誤らないための実務的な判断材料になります。
📖 参考文献
主要論文
-
Raffel, C., et al. (2020): “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”, JMLR 2020
-
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020): “BERTScore: Evaluating Text Generation with BERT”, ICLR 2020
-
Lin, C. Y. (2004): “ROUGE: A Package for Automatic Evaluation of Summaries”, ACL Workshop 2004
📚 シリーズ案内
ブログD:詳細設計書編では、LLMの評価体系とベンチマーク管理を解説しています。
このシリーズの記事:
- LLM評価の3層構造
- 標準ベンチマークの詳細解説(この記事)
- データ汚染検出とドメイン横断性能
- Attentionの可視化と解釈
- データ品質測定とモニタリング体制
関連シリーズ:
- ブログA:基礎理論編 – 事前学習パイプライン理論
- ブログB:実装詳細編 – モデルアーキテクチャの実装
前の記事: LLM評価の3層構造 次の記事: データ汚染検出とドメイン横断性能


コメント