
小規模vs大規模LLM:スケール選択の完全ガイド
LLM導入では、まず「何を作るか」より先に「どの規模で作るか」を決める場面が多くあります。ここを曖昧にしたまま進めると、性能が足りないモデルを選んでしまうか、逆に重すぎて運用できない構成を選んでしまいます。
この記事では、小規模LLMと大規模LLMを、リソース、コスト、タイムライン、性能の4つの観点で整理します。最後に、どのような組織ならどちらを選びやすいかまで、判断しやすい形でまとめます。
1. スケール選択で最初に見るべき軸は何か
モデルサイズの選択は、パラメータ数だけで判断すると失敗しやすいです。最初に見るべきなのは、予算、配置場所、応答速度、知識深度、対応ドメインの5軸です。ここをそろえると、後の比較がかなり明確になります。
| 軸 | 小規模LLMで強い条件 | 大規模LLMで強い条件 | 判断の目安 |
|---|---|---|---|
| 予算規模 | 数百万円から始めたい | 数千万円以上を投資できる | 予算の上限が先に効くかを見る |
| デプロイ場所 | エッジ、社内サーバー、小規模環境 | クラウド、大規模データセンター | 置ける場所が限られるなら小規模寄り |
| 応答速度 | 低遅延を優先したい | 多数同時接続をさばきたい | 1件の速さか、全体のスループットかで分かれる |
| 知識深度 | 基本知識で十分 | 深い知識や推論が必要 | 難しい質問をどこまで任せるかで変わる |
| ドメイン対応 | 限定領域で使う | 多言語・広範な領域で使う | 対象範囲が狭いほど小規模で足りやすい |
この5軸のうち、1つでも要件が極端なら、その時点で候補はかなり絞られます。たとえば「エッジで動かしたい」「まず少人数で試したい」なら小規模側に寄りやすく、「多言語で高精度の応答が必要」「大人数が同時に使う」なら大規模側に寄ります。
つまり、最初の判断は「どちらが強いか」ではなく、「どの制約が先に効くか」を見ることです。
2. 小規模LLMはどんな場面で有効なのか?
小規模LLMは、制約が明確な組織ほど使いやすい選択肢です。まず社内向けに試したい、推論を低コストで回したい、オンプレミスやエッジで動かしたい、といった条件があるときに力を発揮します。
2.1 代表的な小規模LLM
| モデル | パラメータ | 特徴 | 主な用途 |
|---|---|---|---|
| Llama-2 7B | 7 billion | 単一GPUで扱いやすい | モバイルアプリ、エッジ推論 |
| Mistral 7B | 7.3 billion | 7B帯でも高速で扱いやすい | リアルタイムチャット、ローカル処理 |
| Phi-2 / Phi-3 | 2.7B – 7B | 教育用途に寄せやすい | 学習支援AI、Q&A |
小規模LLMで重視したいのは、性能の絶対値よりも「十分な精度を、どれだけ軽く出せるか」です。モデルが軽ければ、検証を早く回せますし、失敗したときのやり直しも小さく済みます。
2.2 リソース要件の詳細
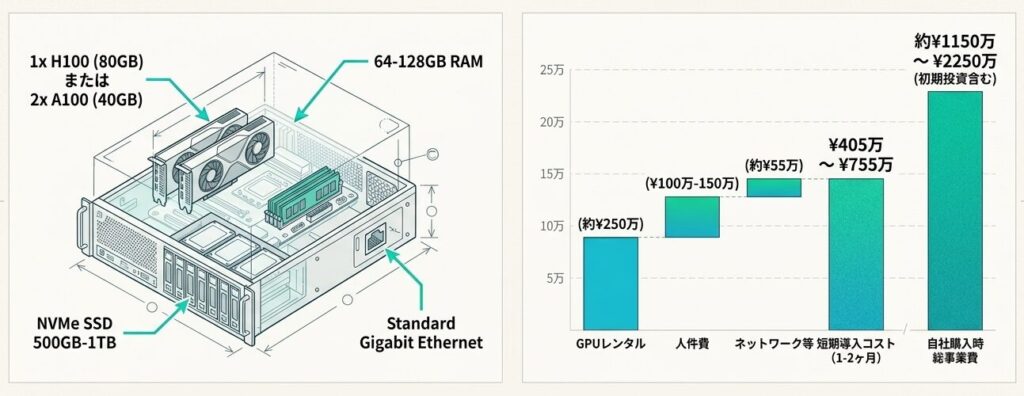
| 項目 | 想定例 | 見積もりの目安 |
|---|---|---|
| GPU | A100 40GB × 2枚、または H100 80GB × 1枚 | 2×A100 40GBで約¥400万-600万、1×H100 80GBで約¥600万-900万 |
| CPU / メモリ | Intel Xeon または AMD EPYC、64-128GBメモリ | 小規模導入なら一般的なサーバー構成で足りる |
| ストレージ | NVMe SSD 500GB-1TB | 学習データとチェックポイントを置ける容量を確保する |
| ネットワーク | ギガビットEthernet、同一マシン内のPCIe / NVLink | 高速な専用線までは不要になりやすい |
| 初期投資 | GPU、サーバー、ストレージ、冷却、ラックを含む | 合計で約¥750万-1500万 |
ここで重要なのは、小規模でも「ゼロコスト」ではないことです。ただし必要なGPU数と周辺設備が比較的少ないため、初期投資の見積もりが立てやすく、組織内の説明もしやすくなります。
初期投資の見積もりが立てやすく、組織内の承認を得やすい「フェイルセーフ」な選択肢。
2.3 タイムラインの詳細
| フェーズ | 期間の目安 | 主な作業 |
|---|---|---|
| 準備フェーズ | 1-2週間 | GPU納入、ドライバ設定、データ確認、PyTorch / HuggingFaceのセットアップ |
| 学習フェーズ | 1-2週間 | 連続GPU使用、トークン学習、学習率スケジュール調整 |
| 評価・最適化フェーズ | 3-5日 | GLUE評価、量子化、サンプリング検証 |
| デプロイフェーズ | 2-3日 | APIサーバー構築、ロードテスト、本番化 |
| 総期間 | 4-6週間 | パラレル実行できれば短縮しやすい |
小規模の強みは、導入までの道筋が短く、段階的に改善しやすい点にあります。学習や評価を小さく回して、必要なら量子化や再学習で詰めていく進め方と相性が良いです。
2.4 コスト内訳
| 費用項目 | 月額・短期の目安 | 補足 |
|---|---|---|
| GPUレンタル | p4d.24xlarge(8×A100)で約¥250万/月 | 自社購入なら減価償却で月額換算する |
| ストレージ | 1TBで約¥5万/月 | S3やAzure Blobを想定 |
| ネットワーク転送 | 10TBで約¥50万 | データ転送量が増えると効いてくる |
| 人件費 | ML Engineer ×1で約¥100万-150万/月 | 小規模でも実装・検証の人手は必要 |
| 短期総コスト | 約¥405万-755万 | 1-2ヶ月導入を想定 |
| 自社購入時の総事業費 | 約¥1150万-2250万 | 初期投資を含めた見積もり |
コストは月額だけで比較すると不十分です。短期導入ならレンタル中心で済みますが、長く使うなら自社購入の減価償却も含めて判断する必要があります。
2.5 期待される性能
| 指標 | 小規模LLMの目安 |
|---|---|
| 言語理解(英語) | GLUEスコア 75-82、SQuAD F1 85-90% |
| 知識 | MMLU 40-50%、TriviaQA 65-75% |
| 生成品質 | BLEU 25-35、ROUGE 0.30-0.40 |
| 推論速度 | 約100 tokens/sec、遅延50-200ms程度 |
| 信頼性 | 幻覚率15-20%、日本語は基本的な文なら対応可能 |
小規模LLMは、汎用の最先端性能を狙うよりも、限定した用途を安定して回すための選択肢です。要求が「まず動かすこと」にあるなら有力ですが、「広い知識を自然に扱うこと」まで求めると限界が見えやすくなります。
3. 大規模LLMはどんな場面で必要なのか?
大規模LLMは、単に高性能だから選ぶものではありません。多言語対応、深い知識、複雑な推論、高い同時接続数が必要になったときに、はじめて投資に見合う選択肢になります。
3.1 代表的な大規模LLM
| モデル | パラメータ | 特徴 | 主な用途 |
|---|---|---|---|
| Llama-2 70B | 70 billion | 大規模基盤モデルとして使いやすい | エンタープライズ基盤モデル |
| Mistral Large / Mixtral | 約176 billion(MoE) | 推論コストの最適化を狙いやすい | APIサービス基盤 |
| GPT-like Large Model | 200B+ | 汎用性を重視した構成 | 汎用AIサービス |
ここでの判断基準は、「モデルを大きくすれば便利になるか」ではなく、「その規模を運用するだけの要求が本当にあるか」です。要求が明確でない段階で大規模に振ると、コストだけが先に膨らみます。
3.2 リソース要件の詳細
| 項目 | 想定例 | 見積もりの目安 |
|---|---|---|
| GPU | H100 80GB × 100-500枚 | 学習スケール次第で大きく変動する |
| インターコネクト | InfiniBand NDR 200Gbps、Nvidia Quantumスイッチ | 購入・設置で約¥1億-5億 |
| ストレージ | 高速NAS、100TB級 | 約¥5000万-1億 |
| ネットワーク | 高速スイッチ、専用線運用 | 約¥1000万-2000万、運用費は別途大きい |
| 冷却・電源 | 冷却装置、電力供給 | 約¥1000万-5000万、電力供給で約¥5000万-1億 |
| 初期投資 | 100×H100を想定した全体構成 | 約¥15-25億 |
| クラウド利用時 | AWS / Azureでのトレーニング | 約¥1-3億(3-4ヶ月) |
大規模側では、GPUの枚数だけでなく、通信、冷却、電源、復旧手順まで含めて設計しないといけません。つまり、モデル開発というよりも、分散システムと運用基盤の構築に近い仕事になります。
3.3 タイムラインの詳細
| フェーズ | 期間の目安 | 主な作業 |
|---|---|---|
| 準備フェーズ | 2-4週間 | インフラ検証、通信テスト、スケーリング測定 |
| データ準備 | 4-6週間 | 大規模データ統合、多言語品質管理、データローダ最適化 |
| 分散訓練システム構築 | 1-2週間単位で並行 | All-reduce最適化、checkpoint / recovery、監視基盤構築 |
| 学習フェーズ | 4-6週間 | 100-500GPU利用、5-10 trillion tokens、学習率調整 |
| 評価・最適化フェーズ | 約2週間 | 多言語評価、MMLU評価、幻覚検出、量子化・圧縮 |
| デプロイフェーズ | 1-2週間 | vLLM / TGIでの推論基盤、マルチGPUチューニング、本番化 |
| 総期間 | 10-14週間 | 約3-3.5ヶ月 |
時間がかかるのは、学習そのものより準備と検証に手間がかかるからです。大規模では「動けば終わり」ではなく、途中の失敗をどう回復するかまで含めてプロジェクトとして成立させる必要があります。
3.4 コスト内訳
| 費用項目 | 月額・短期の目安 | 補足 |
|---|---|---|
| GPUクラウドレンタル | 8×H100のp5.48xlargeを複数並列で利用すると約¥3-4億/月 | 100×H100級の想定 |
| ストレージ | 100TBで約¥500万/月 | Dolmaなどの大規模データを想定 |
| ネットワーク | 専用線運用で約¥2000万/月 | 高速InfiniBand前提 |
| 施設コスト | ラック、電力、冷却で約¥5000万/月 | データセンター運用の負担 |
| 人件費 | ML Engineer ×5 + 専門家で約¥500万-700万/月 | 実運用ではチーム体制が必要 |
| 短期総コスト | 約¥14.6億 | 3-4ヶ月導入を想定 |
この規模になると、コストはもはや実験費ではなく設備投資に近い扱いになります。したがって、単価の安さではなく、どれだけ広い利用範囲をカバーできるかで回収の見通しを立てる必要があります。
3.5 期待される性能
| 指標 | 大規模LLMの目安 |
|---|---|
| 言語理解(多言語対応) | GLUE 88-92、SQuAD F1 94-97%、多言語GLUE 85-90% |
| 知識 | MMLU 80-85%、TriviaQA 92-95% |
| 生成品質 | BLEU 45-55、ROUGE 0.48-0.55 |
| 推論速度 | 約50 tokens/sec、遅延200-500ms程度 |
| 同時接続 | 1000人以上を支援しやすい |
| 信頼性 | 幻覚率8-12%、54言語以上に対応しやすい |
大規模LLMの価値は、単に精度が高いことではなく、難しい入力でも破綻しにくいことにあります。組織横断で使う、多言語で使う、説明責任が重い、といった条件が重なるほど優位性が出ます。
4. 小規模と大規模の違いを一枚で見る
ここまでの内容を、判断しやすいように一度まとめます。比較表は単なる一覧ではなく、「どの条件ならどちらが勝つか」を見極めるための道具として使うのがポイントです。
| 指標 | 小規模 (7B) | 大規模 (70B+) | 見方 |
|---|---|---|---|
| GPU必要数 | 1-2枚 | 100-500枚 | 導入ハードルの差が大きい |
| 総メモリ要件 | 16-80GB | 数TB-数十TB | インフラ設計の重さが違う |
| 初期投資 | ¥750万-1500万 | ¥15億-25億 | 投資判断のレベルが別物 |
| 学習期間 | 1-2週間 | 4-6週間 | 立ち上がりの速さは小規模が有利 |
| 準備期間 | 2-3週間 | 4-6週間 | 大規模は事前設計の比重が高い |
| 総期間 | 4-6週間 | 10-14週間 | 立ち上げのスピード差が出る |
| 月額運用コスト | 約¥250万-300万 | 約¥3.5億-4億 | まず比較したい差分 |
| 知識精度(MMLU) | 45-50% | 80-85% | 精度を重視するほど大規模が強い |
| 言語対応 | 英語+基本 | 54言語完全対応 | 多言語前提なら大規模が有利 |
| 推論速度 | 約100 tok/s | 約50 tok/s | 単純な速さだけではなく全体処理量を見る |
| 同時接続支援 | 10-50ユーザ | 1000+ユーザ | 利用者数が増えるほど差が広がる |
| 運用難易度 | 低い(単一GPU) | 高い(cluster管理) | 体制の厚さが問われる |
| リスク | 低い(fail-safe) | 中程度(複雑) | 失敗時の戻しやすさも違う |
| ROI | 高い(短期) | 高い(長期) | 回収の時間軸が異なる |
この表を見ると、小規模は導入速度と始めやすさで優れ、大規模は広い利用範囲と精度の高さで優れています。言い換えると、前者は試しやすさ、後者は適用範囲の広さに強みがあります。
5. どの組織にどちらを勧めるのか?
最後に、組織の事情に落とし込んで考えます。実際の現場では、性能指標だけでなく、人数、予算、運用体制、失敗許容度が判断を左右します。
5.1 組織タイプ別推奨スケール
| 組織属性 | 小規模 (7B) 推奨 | 大規模 (70B+) 推奨 |
|---|---|---|
| 従業員数 | 500人未満 | 1000人超 |
| 部門数 | 1-2部門 | 3部門以上 |
| LLM利用者数 | 100人未満 | 1000人超 |
| 対応言語 | 1-2言語 | 3言語以上 |
| ドメイン数 | 1-2の特化領域 | 5以上の広範な領域 |
| ナレッジ深度 | 基本・初級 | 深度・専門家レベル |
| 総予算 | ¥2000万未満 | ¥2億超 |
| 実装期間 | 3ヶ月未満 | 3-4ヶ月以上 |
| 予算優先度 | コスト重視 | 品質重視 |
| 失敗許容度 | 高い(試験的) | 低い(本番必須) |
| 運用チームサイズ | 2-3人 | 10-20人 |
| 継続性・投資計画 | 短期・実験的 | 長期・基幹システム |
このマトリックスは、「どちらが優れているか」を決める表ではありません。むしろ、自社の条件がどちらに近いかを見て、無理のない選択肢を選ぶための表です。
5.2 具体的な組織例
| 組織例 | 推奨 | 理由 |
|---|---|---|
| FastAI Startup | 小規模 (7B) | まずは検証速度とコストを優先しやすい |
| FinTech(スケールアップ中) | 小規模 (7B)、将来拡張 | 段階的に運用を広げやすい |
| Global Conglomerate | 大規模 (70B+) | 多言語、多部門、広い利用者数に向く |
| Medical Institution | 小規模 (Path C/D) | 限定用途から始めた方が運用しやすい |
| 成熟Tech Company | 大規模 (70B+) | 基幹システムとして使う前提と相性がよい |
組織例で見ると、最初から大規模が必要なケースは意外に限られます。多くの組織では、小規模で始めて使い方を固め、必要になった段階で大規模へ移る方が現実的です。
6. 迷ったときはどう判断するのか?
最終的には、次の順番で考えると判断しやすくなります。
- まず、予算と運用体制が小規模を許すかを見る。
- 次に、必要な精度が小規模で足りるかを確認する。
- それでも足りないなら、大規模に必要な投資を回収できるかを考える。
この順で見れば、モデルサイズを「夢」で決めずに済みます。実務では、最先端モデルを選ぶことよりも、組織が継続して使い切れる構成を選ぶほうが結果につながりやすいです。
7. 今回のブログの考察
小規模LLMと大規模LLMの比較は、単なる性能表の読み比べではありません。今回の記事で見えてくるのは、モデルサイズの選択そのものよりも、組織がどの制約を先に受け入れるかという判断です。小規模は導入速度と運用の軽さに強く、大規模は広い適用範囲と深い知識に強いですが、どちらも万能ではありません。
実務で難しいのは、性能だけを見れば大規模が魅力的に見える一方で、予算、体制、運用期間を含めると小規模のほうが現実的に回りやすい場面が多いことです。ここで重要なのは、どちらが上かを決めることではなく、自社がどこまでの複雑さを引き受けられるかを先に見極めることだと考えられます。
その意味で、この比較の本質は「最初から大きく始めるべきか」ではなく、「最初にどの失敗を小さくしたいか」にあります。まず素早く検証したいなら小規模、広い利用範囲まで見据えて基幹システム化したいなら大規模、という整理をしておくと、モデル選定はかなりぶれにくくなります。実務では、性能の理想形よりも、継続して運用できる現実解のほうが、最終的な成果に直結しやすいです。
参考文献
主要論文
-
Karpukhin, V., et al. (2020): “Dense Passage Retrieval for Open-Domain Question Answering”, EMNLP 2020
-
Lewis, P., Perez, E., Piktus, A., et al. (2020): “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, NeurIPS 2020
-
Nakano, R., et al. (2021): “WebGPT: Browser-assisted question-answering with human feedback”, arXiv
このシリーズの案内
ブログE:組織戦略編では、LLM導入の組織戦略を解説しています。
このシリーズの記事:
- LLM導入の意思決定フレームワーク
- 小規模vs大規模シナリオの詳細分析(この記事)
- LLM事前学習開始企業のチェックリスト
- LLM学習への段階的アプローチ
関連シリーズ:
- ブログD:詳細設計書編 – スケール別の性能期待値
- ブログC:データセット戦略編 – データセット規模との関係
前の記事: LLM導入の意思決定フレームワーク 次の記事: LLM事前学習開始企業のチェックリスト

コメント