
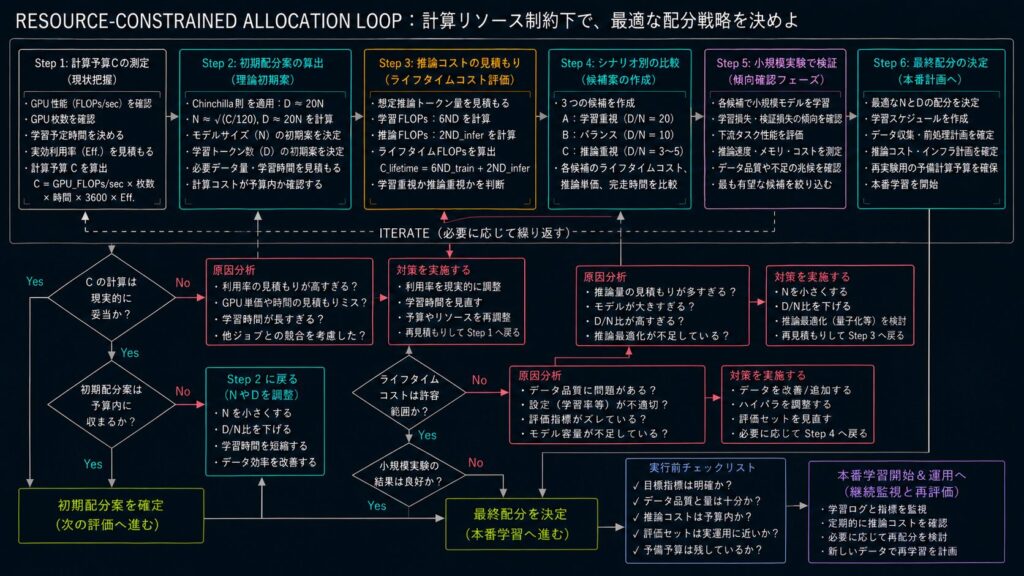
前回の C1 では、固定計算予算下での理論基盤として Chinchilla 則(D ≈ 20N)を整理しました。C2 ではそこから一歩進めて、「実際の予算制約でどう配分を決めるか?」に焦点を当てます。
実務では、理論上の最適点だけで意思決定できることは多くありません。GPU 稼働率のブレ、推論リクエストの増減、運用期間の長さによって、同じ N と D でも総コストは変わります。この記事では、計算予算 C の測り方、ライフタイムコストの見方、シナリオ別の判断順を具体的に示します。
1. なぜ C2 で「配分戦略」を扱うのか?
C1 の理論は強力ですが、実務では次の問いが先に来ます。
- 今月の GPU 予算で、どこまで学習できるのか?
- 学習コストと推論コストのどちらを優先すべきなのか?
- 研究用途と商用用途で、同じ配分が正解なのか?
この章の役割は、理論を否定することではなく、理論を運用へ接続することです。
言い換えると、C1 で得た D ≈ 20N を、そのまま覚えるだけでは不十分です。実際の現場では、月ごとの予算、実効 GPU 稼働率、学習後にどれだけ推論が回るかまで含めて判断しないと、最初の見積もりがすぐに古くなります。
2. 計算リソース C はどう測るべきなのか?
まずは計算予算 C を、運用で再現できる形で見積もります。
$$ C = \text{GPU FLOPs/sec} \times \text{GPU枚数} \times \text{学習時間} \times \text{利用効率} $$
最小実装は次の通りです。
def estimate_train_flops(gpu_flops_per_sec, num_gpus, duration_hours, utilization):
return gpu_flops_per_sec * num_gpus * duration_hours * 3600 * utilization
# 例: V100 8枚を2週間、利用効率60%
total_flops = estimate_train_flops(
gpu_flops_per_sec=31.4e12,
num_gpus=8,
duration_hours=14 * 24,
utilization=0.60,
)
print(f"C ≈ {total_flops:.2e} FLOPs")この時点で重要なのは、ピーク性能ではなく実効利用率を使うことです。ここを理想値で置くと、後段の配分が過大になります。
ここでいう利用効率は、単に GPU が稼働している時間ではありません。データ読み込みの待ち時間、チェックポイント保存、分散学習の通信待ちなども含めた「実際に FLOPs を出せている割合」です。表面上は 8 枚の GPU を使っていても、実効利用率が 60% 前後なら、見積もりはかなり変わります。
3. C から N と D の初期案はどう出すのか?
Chinchilla 則を初期案として使うと、見積もりが速くなります。
$$ C \approx 6ND, \quad D \approx 20N $$
これより、
$$ N \approx \sqrt{\frac{C}{120}}, \quad D \approx 20N $$
を得られます。
import math
def chinchilla_initial_plan(train_flops):
n_params = math.sqrt(train_flops / 120.0)
d_tokens = 20.0 * n_params
return n_params, d_tokens
n, d = chinchilla_initial_plan(total_flops)
print(f"N ≈ {n/1e9:.2f}B params")
print(f"D ≈ {d/1e9:.2f}B tokens")ただし、これは「初期案」です。C1 でも触れた通り、データ品質や用途が変われば最適点は動きます。
ここで大事なのは、初期案をそのまま最終案にしないことです。まず計算予算から候補を出し、そのあとに評価対象、データの汚れ、推論量の見込みを重ねていくと、修正の理由が説明しやすくなります。
4. 学習最適とライフタイム最適はなぜズレるのか?
ここが C2 の核心です。Chinchilla 則は学習効率の最適化に強い一方で、商用では推論コストが支配的になる場合があります。
ライフタイムの概算式

def lifetime_flops(n_params, d_train, d_infer):
train = 6 * n_params * d_train
infer = 2 * n_params * d_infer
return train + infer, train, infer
# 1B model / 12ヶ月で推論トークンが大きいケース
n = 1e9
for d_train in [20e9, 10e9, 3e9]:
total, train, infer = lifetime_flops(n, d_train, d_infer=1200e9)
print(d_train/1e9, total)この比較で見えるのは、「学習時の最適」と「運用全体の最適」は一致しないことがある、という点です。これがいわゆる Chinchilla Trap の実務版です。
たとえば、学習時だけを見れば 20:1 の配分が妥当に見えても、1 年間の問い合わせ数や API 利用数が多い環境では、推論回数のほうが支配的になります。この場合、少し学習トークンを減らしてでも、推論単価を下げたほうが総コストは小さくなることがあります。
5. シナリオ別にどう配分すべきなのか?
ここでは意思決定を単純化し、3 つの規模で考えます。
| シナリオ | 典型的な環境 | 優先する判断軸 | 推奨 D/N の目安 |
|---|---|---|---|
| 小規模(研究室・初期スタートアップ) | GPU 1-4 枚 | まず学習完走 | 10-20 |
| 中規模(ベンチャー) | GPU 8-32 枚 | 学習と推論の両立 | 10 前後 |
| 大規模(大企業) | GPU 100+ 枚 | ライフタイム最小化 | 3-20(用途依存) |
補足すると、研究用途では Chinchilla 寄り(D/N=20)が扱いやすく、商用 API や高トラフィック運用では D/N を下げて推論単価を抑える設計が合理的な場合があります。
この見方は、モデルの強さだけではなく、使われ方の強さを見るためのものです。研究室では 1 回の実験で良い結果が出れば十分でも、商用サービスでは 1 回の回答より 10 万回の回答の積み上げが重くなります。その差が、配分の考え方を分けます。
6. どの順序で判断すれば失敗しにくいのか?
実務では、次の順序で決めるとブレにくいです。
Cの実効値を見積もる- Chinchilla で初期案(N, D)を置く
- 推論量を入れてライフタイムコストを比較する
- 3 案程度(学習重視・バランス・推論重視)で小規模検証する
この判断フローを簡単に書くと次のようになります。
以下の関数は厳密な最適化器ではありませんが、少なくとも議論の出発点にはなります。最初に候補を大まかに分類できると、チーム内で「まず何を測るか」が合意しやすくなります。
def choose_dn_ratio(monthly_budget_level, inference_priority):
if monthly_budget_level == "small":
return 20 if inference_priority == "low" else 10
if monthly_budget_level == "medium":
return 10
# large
return 5 if inference_priority == "high" else 107. 比較表で何を確認すべきなのか?
1B モデルの単純比較例です(概算)。
| 指標 | 学習重視(D/N=20) | バランス(D/N=10) | 推論重視(D/N=3) |
|---|---|---|---|
| 学習トークン | 20B | 10B | 3B |
| 学習 FLOPs | $1.2 \times 10^{20}$ | $6.0 \times 10^{19}$ | $1.8 \times 10^{19}$ |
| ライフタイム FLOPs(推論多) | 相対的に高い | 中 | 低 |
この表の読み方は、「最小値を探す」より「どの条件で順位が入れ替わるか」を見ることです。推論量が小さい組織と大きい組織では、最適戦略が同じにならないためです。
たとえば研究用途では、学習 FLOPs の差がそのまま判断材料になりやすい一方で、SaaS では推論 FLOPs の累積が後から効いてきます。つまり、同じ 1B モデルでも、置かれる環境が違えば評価の軸も変わるということです。
8. 実務で起きやすい失敗は何か?
配分戦略でよくある失敗は次の通りです。
- 学習予算だけで判断し、推論予算を別管理にしてしまう
- GPU 理論性能を前提にして、実効利用率を過大評価する
- D/N 比を固定値として扱い、用途ごとの再評価をしない
特に 2 つ目は起きやすく、見積もり段階では回る想定だったのに、実運用で学習期間が延びるケースは少なくありません。
この失敗は、単に「計算が足りなかった」のではなく、前提条件を固定しすぎたことから起きます。利用率を 80% と置いたが実際は 55% しか出なかった、というズレが積み重なると、学習期間もコストも予定から外れます。
9. 本番計画に入る前に何を確認すべきなのか?
最適配分は、表計算だけで決めるものではありません。本番計画に進む前に、少なくとも次を確認したほうがよいです。
- 目標は事前学習損失か、下流タスク性能か?
- 必要なデータ量だけでなく、データ品質を確認したか?
- モデルサイズを先に固定しすぎていないか?
- 推論コストを見積もったか?
- 小規模実験で
NとDの傾向を確認したか? - 評価セットが実運用に近いか?
- 再実験用の計算予算を残しているか?
ここで大切なのは、最適配分を一度で当てようとしないことです。小規模実験で傾向を見て、データ品質を直し、評価セットを調整し、もう一度見積もる。この反復がないと、理論上はきれいでも実務では外れやすくなります。
確認事項の役割は、学習を止めることではありません。むしろ、後戻りのコストが高い段階へ進む前に、見落としやすい前提を先に潰すことです。ここを通しておくと、あとから「なぜその配分にしたのか」を説明しやすくなります。
10. まとめ
C2 が示した重要な教訓は、D ≈ 20N をそのまま適用するのではなく、計算予算・推論コスト・運用期間を含めて配分を考えることです。同じ計算予算でも、学習と推論のどちらを重く見るかで最適点は変わります。
今回の要点は次の通りです。
- 計算予算
Cは、GPU 性能だけでなく利用効率まで含めて見積もる必要がある - Chinchilla 則は初期案として有効だが、ライフタイムコストではズレることがある
- 小規模・中規模・大規模で、推奨される
D/Nの考え方は変わる - 本番前には、小規模検証と比較表での確認が欠かせない
- 配分戦略は、一度決めて終わりではなく、再評価を前提に運用するべきである
最適配分とは、数式で一発で答えを出す作業ではありません。理論で基準線を引き、実験で補正し、運用制約で現実に合わせる作業です。
したがって、C2 の実務的なゴールは、唯一の正解を見つけることではありません。限られた計算予算の中で、説明可能で、再検証可能な配分案を作れるようにすることです。
11. 今回のブログの考察
C2 の本質は、D ≈ 20N を否定することではなく、「いつその比率を使い、いつ外すべきか」を判断可能にすることです。理論の価値は、正解を固定することではなく、比較の出発点を与えることにあります。
この点が見えると、Chinchilla 則は「守るべきルール」ではなく「比較の基準」に変わります。基準があるからこそ、データ品質が高いのか、推論が多いのか、配布後の利用期間が長いのか、といった条件差を議論しやすくなります。
実務で強いチームは、最初に大規模学習へ進むのではなく、C1 の理論を C2 の配分フレームで具体化し、小規模検証で差分を確認してから拡張します。次の C3 では、この配分判断をデータ品質とデータ調達の現実へ接続していきます。
参考文献
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.
- Meta AI (2024). “Llama 3 Technical Report.”
コメント