
LLM評価の3層構造:ベンチマークだけでは見えない本当の使い勝手
LLMを開発したのに、本当に「使えるモデル」かどうか判断しきれない。そんな相談は少なくありません。
ベンチマークでは 90% を超えているのに、実務で使うと想定外の失敗が続くことがあります。たとえば、医学分野では高精度でも、法律の相談に切り替えた途端に答えが曖昧になる。あるいは、日本語では自然でも、英語や別の入力形式に変えた瞬間に出力の質が落ちる。
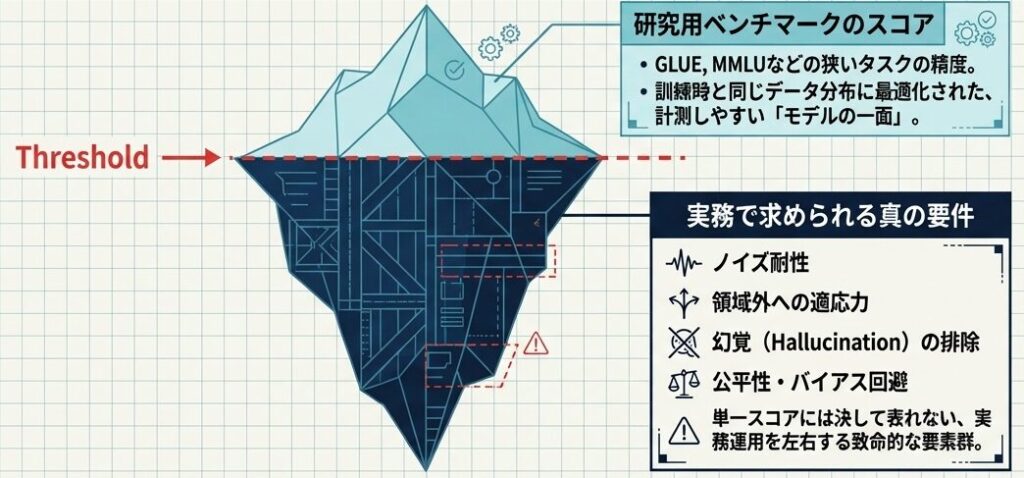
こうした現象に共通しているのは、単一の評価指標だけでは、モデルの本当の価値も限界も見えないということです。研究用のテストで強いことと、現場で安心して使えることは、必ずしも一致しません。
本記事では、LLM評価を3つの層に分けて考えます。基盤となる能力、未知の状況への対応力、そして実務で使える信頼性です。この順番で見ることで、「ベンチマークでは優秀なのに、現場では使えない」というズレを避けやすくなります。
なぜ「3層構造」なのか?単一指標の限界
LLMの評価を語るとき、多くの人が思い浮かべるのは GLUE や MMLU といった有名なベンチマークです。これらは確かに重要ですが、もし評価がこれだけで完結するなら、冒頭の失敗例は起きにくいはずです。現実がそうでないのは、ベンチマークスコアが「モデルの一面」しか映していないからです。いわば、成績表の1科目だけを見て、実力全体を判断している状態に近いです。
典型的な問題を3つ挙げます。
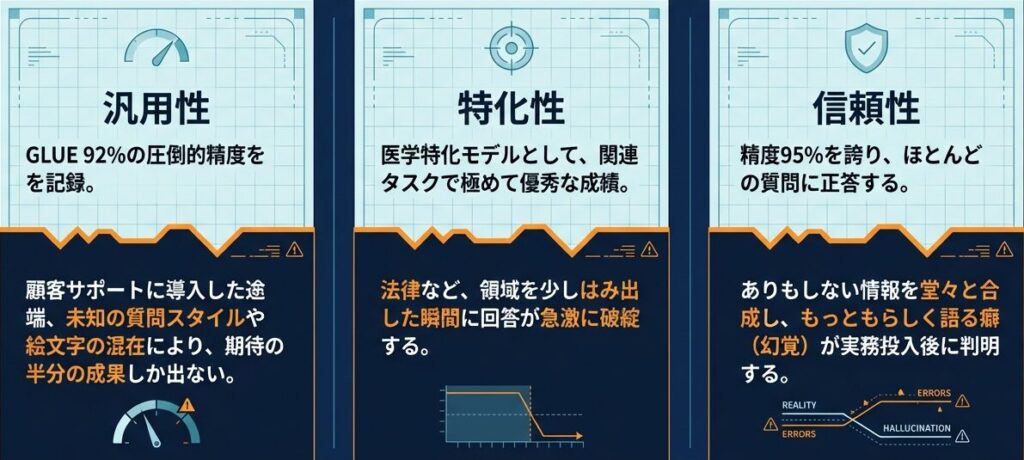
問題1:狭いタスクでの高スコアが、実務では通用しない
GLUE の質問応答タスクで 92% の精度を出したモデルが、実際の顧客サポート業務では期待の半分の成果しか出ないことがあります。なぜか? GLUE はあくまで「研究用ベンチマーク」だからです。訓練時と同じ分布に最適化されている一方、実務では「見たことない質問スタイル」「記号や絵文字の混在」「複数言語の混在」など、想定外の入力が日々やってきます。つまり、テストの作法が変わると、同じモデルでも見え方が変わるのです。
問題2:医学特化モデルが、法律の話では全く役に立たない
ドメイン特化のはずなのに、領域を少しはみ出すと急に性能が落ちる。これは「特化が強すぎる」のではなく、「汎用性を測る仕組みがない」せいです。開発時に医学知識は測ったが、他分野での応用可能性は測っていなかったわけです。医学の質問には強いが、法律や一般ビジネスの相談になると弱い、という分かりやすいギャップがここにあります。
問題3:「信頼できるか」と「精度が高いか」は別問題
精度 95% のモデルが、実は「ありもしない情報を堂々と合成する」癖を持っていることが、実務投入後に判明する。つまり、精度の高さと「信頼性」は別軸で評価する必要があります。正答率が高くても、たまに危険な誤答をするモデルは、医療や法務では特に扱いづらいからです。
これら3つの問題に対応するために、評価を3つの層で分けて考えます。
重要ポイント
単一のベンチマークスコアは、モデルの必要な側面を全て映していない。実務で使えるかを判断するには、基盤・汎化・信頼性という複数の視点を分けて見る必要がある。
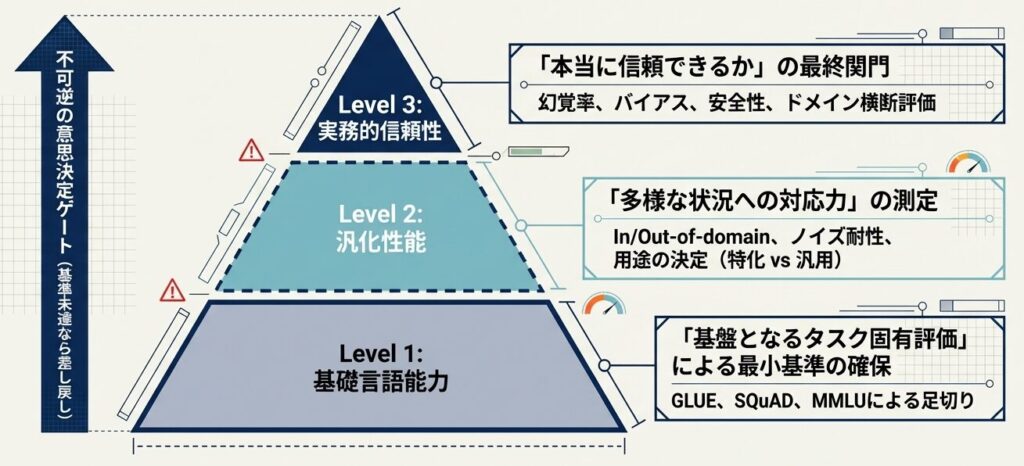
Level 1:基盤となるタスク固有ベンチマーク
「基本的な言語能力」を測る
Level 1 は、評価の土台です。ここでは、モデルが本当に言語を理解しているのか、最低限の推論や生成ができるのかを測ります。いわば「スタートラインに立てるか」を確認する段階です。
代表的なベンチマーク
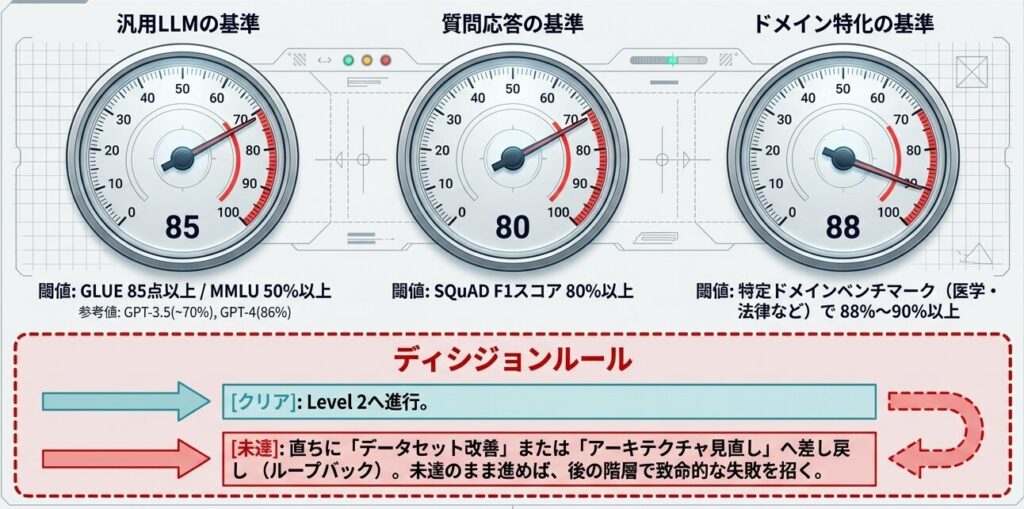
テキスト分類の代表は GLUE(General Language Understanding Evaluation) です。9 つのタスク(文の包含関係、感情分析、テキスト類似度など)をまとめた総合指標で、0~100 のスコアになっています。汎用 LLM であれば 85 点以上が一つの目安です。単一タスクだけでなく、複数の基本タスクをまとめて見られるのが特徴です。
質問応答では SQuAD(Stanford Question Answering Dataset)が標準的です。これは「与えられた文脈から正しく質問に答えられるか」を測るもので、一般的には F1 スコア 80% 以上が合格ラインです。要するに、文章を読んで答えを抜き出す力を見るテストです。
知識と推論を測るのが MMLU(Massive Multitask Language Understanding)です。57 の分野(医学、法律、物理など)から計出題されます。ランダム回答で 25% なので、50% 以上であれば「基本的な知識がある」と言えます。GPT-3.5 で約 70%、GPT-4 で 86% というレベルです。ここでは、「広く知っているか」を見るイメージです。
「最小基準」を引く
Level 1 で重要なのは、リリース前の「最小基準」を決めておくことです。ここを曖昧にしたまま進めると、後続の層で問題が見つかっても、どこに戻るべきか判断しづらくなります。
汎用 LLM なら GLUE 85 点以上、MMLU 50% 以上。医学特化なら、同時に医学ベンチマークで 88% 以上。法律特化なら法律タスクで 90% 以上。こうした基準を事前に決めて、それに達しないなら開発フェーズに戻す。この判断が、後の失敗を防ぐ最も単純で効果的な方法です。汎用モデルと特化モデルでは、合格ラインそのものを変える必要がある、という点が重要です。
基準に達していないまま先に進めば、Level 2 や Level 3 でさらに悪い結果が待っているだけです。
実務的チェックリスト
- GLUE、SQuAD、MMLU のいずれかで、事前に定めた基準に達している?
- 「汎用」なら 85 点以上、「特化」なら 88% 以上?
- 達していなければ、データセット改善またはアーキテクチャ見直しの可能性がないか検討した?
Level 2:多様な状況への対応力(汎化性能)
いま見た場面と、まったく違う場面
Level 1 でスコアが良くても、「異なる環境での適応力」は全く別の問題です。ここでは、テスト時に見た状況と、実際の運用で起きる状況の差を見ることになります。
例えば、医学テキストの質問応答で特化訓練したモデルを考えてみます。医学論文や医学 Q&A サイトでなら素晴らしい成績を出します。しかし、患者が X(Twitter) で書いた医学的な質問(表現が不規則、専門用語が混在)に答えさせると、性能が 20~30% も落ちることがあります。きれいに整った文章には強くても、現場の雑な入力には弱い、という差です。
これが「分布外(Out-of-domain)」での性能低下です。訓練時の分布と、実運用時の分布が異なるからです。
何を測るべきか
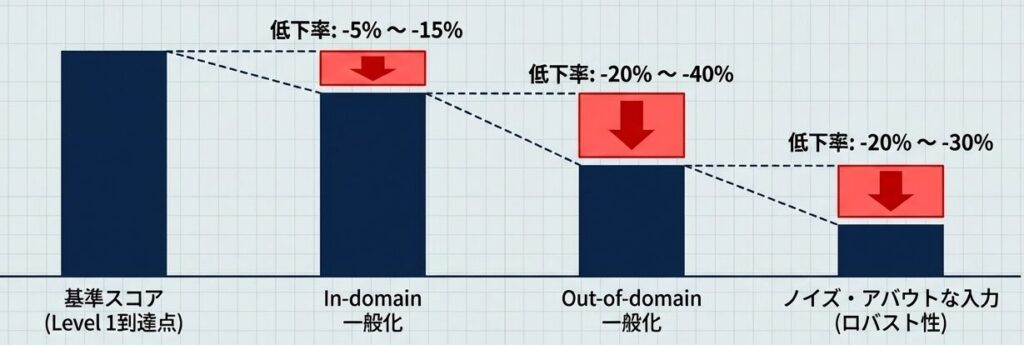
In-domain 一般化:同じドメイン(例:医学)だが、異なるタスク(例:医学知識 Q&A → 医学論文要約)への対応。通常 5~15% の性能低下が見られます。ドメインは同じでも、求められる作業が変わると性能も少し下がる、という見方です。
Out-of-domain 一般化:全く異なるドメイン。医学特化モデルで法律の質問に答えさせるなど。ここでは 20~40% の低下が典型的です。In-domain と比べると、落ち方が大きくなるのが普通です。
ロバスト性:現実的な入力のノイズ(スペルミス、不自然な文法、口調の変化)への耐性。これが高いモデルは、ユーザーの「アバウトな入力」にも答えやすくなります。整った入力より、むしろ雑な入力で差が出やすい指標です。
失敗パターン:特化が強すぎる
ドメイン特化モデルは、その分野では無敵に見えます。医学 Q&A で 95% の精度。しかし、その領域の外では使い物にならない。会社内で導入してみたら、「医学的な助言」が必要な状況は 20% あり、残る 80% の汎用的な質問には答えられないという結果もありえます。強みがはっきりしている一方で、使いどころが狭くなるのがこのタイプの特徴です。
だから Level 2 では、「特化を取るのか、汎用性を取るのか」の判断が必要になります。この判断を曖昧なまま進めると、リリース後に後悔することになります。
意思決定の分岐点
- Level 1(基本ベンチマーク)で基準をクリア
- ↓
- Level 2 で「汎化性能」を測定
- 汎化 21% 以下の低下? → 汎用性が高い、汎用LLM として展開可能
- 汎化 25~35% の低下? → 中程度、特化×汎用のバランスが必要
- 汎化 35% 以上の低下? → 特化が非常に強い、用途を限定すべき
低下率が小さいほど横展開しやすく、逆に大きいほど用途を絞る判断が必要になります。
Level 3:実務の信頼性(ドメイン横断・安全性評価)
精度だけでは測れない「使えるか」
Level 1 で 90% と言ったのに、実運用で問題が続く。その多くは、精度と信頼性が別軸だからです。平均的には正しくても、外れ値で危ない挙動をするモデルは、現場では扱いづらくなります。
皆さんが医療 AI を使うとき、「98% の精度」より「絶対に危ない回答をしない」ほうが大事ではないでしょうか。精度が 90% でも「10% の間違いのうち、命に関わる誤答が含まれる」なら、実使用は危険です。ここでは、正解率の高さよりも、失敗したときの危険度が重要になります。
幻覚(Hallucination)の測定
最も重要な信頼性指標が「幻覚率」です。幻覚とは、モデルが「存在しない情報を、あたかも事実のように生成する」ことです。
例えば、患者が「この薬と」と入力したのに、モデルが「ビタミン C との相互作用は既知で…」と、全く別の情報を自信たっぷりに返す。これが幻覚です。見た目はもっともらしくても、根拠がないというのが厄介な点です。
幻覚が多いモデルは、スコアがいくら高くても、実務では使えません。なぜなら「本当の情報か、作られた情報か」ユーザーが判断できないからです。
幻覚率の測定方法:
評価セットに対してモデルの出力を生成し、「事実に基づいているか」を人間が確認します。幻覚を含む回答の割合が幻覚率です。
目安:
- 5% 未満:非常に高信頼、実務使用可能
- 5~15%:実用的だが、ユーザーへの警告が必要
- 15~30%:要注意、補助ツール程度の位置づけ
- 30% 以上:信頼性問題、論文化や内向データとして利用すべき
同じ 90% の精度でも、幻覚率が低いモデルと高いモデルでは運用の安心感がまったく違います。
バイアスと安全性
医学 AI が「男性患者」に対しては診断精度 94% だが、「女性患者」では 82% である。こうした不公正は、精度指標には表れません。しかし実務では致命的です。平均精度が高くても、特定の属性だけが不利になるなら、そのモデルは公平とは言えません。
また、性差別的な表現の生成、政治的バイアス、倫理的に問題のある提案なども、Level 1 のベンチマークには引っかかりません。
実務投入前には、こうした「見えないバイアス」を専門家が検査する必要があります。
「信頼性スコア」の統合判定
複数の指標をまとめて「このモデルは本当に信頼できるか」を判定します。
単純な計算式なら:
信頼性スコア = (1 – 幻覚率)×(1 – バイアススコア)×(1 – 有害出力率)× 一般化スコア
例えば:
- 幻覚率 10%
- バイアススコア 5%
- 有害出力率 2%
- 一般化スコア 0.85
なら、信頼性スコア = 0.90 × 0.95 × 0.98 × 0.85 = 0.71(71 点/100 点)
このモデルは「精度は高いが、運用上の信頼性は 71 点」という判定になります。つまり、テストでは十分でも、本番投入にはまだ不安が残る段階です。
実務的な閾値
- 信頼性スコア 80% 以上:本番環境展開可
- 信頼性スコア 60~80%:限定的な運用、ユーザー警告付き
- 信頼性スコア 60% 未満:実務使用は困難、改善必須 ここでは、精度の高さと信頼性の高さを同じものとして扱わないことが重要です。
3つの層をどの順序で進めるべきか
ここが最も実務的な問題です。「どの層から始めるか」を間違えると、開発時間を無駄にします。
推奨される進め方
段階 1:Level 1 で基本基準をクリアする
ここをスキップして先に進めるのは、土台のない家を建てるようなものです。GLUE、SQuAD、MMLU で事前に定めた基準に達しない限り、先に進まない。達しなければ「データセット改善」「アーキテクチャ見直し」を検討するのが先です。最初の判定を甘くすると、後ろの層で問題が雪だるま式に増えます。
この判断は辛いものです。「もう少しで基準に届きそう」という状況でも、先に進めてはいけません。後の階層で 3 倍の時間をかけて修正することになります。短期の前進より、長期の手戻りを減らすほうが重要です。
段階 2:Level 2 で想定される使用環境での性能を確認
「汎用性が必要か、特化を取るか」の決定がここで出ます。医学のみなら 25% 低下は許容できるかもしれない。しかし、チャットボットとして複数分野に使うなら 15% 以下に抑えるべきです。用途が広いほど、少しの性能低下が体感上の差になりやすいからです。
この決定が遅れると、Level 3 で「想定と違う」という修正が発生し、大きな手戻りになります。
段階 3:Level 3 で実務的な信頼性を最終確認
ここに来てから「実は幻覚が 25% もあった」「バイアスが無視できなかった」では、修正に数週間かかります。信頼性の問題は、あとから見つかるほど直しづらいというのが実務上の厄介な点です。
できれば段階 2 と 3 は並行して進め、早期に問題を見つけるほうが効率的です。
最終判定:リリース判定図
Level 1 の基準を満たしている?
No → 開発継続
Yes → 次へ
Level 2 の汎化性能は許容範囲?
No → 特化用途に絞るか、性能を改善する
Yes → 次へ
Level 3 の信頼性スコアは 75% を超えている?
No → 安全性・バイアスを改善する
Yes → 本番環境へ展開判定のポイント
- Level 1 は「必須チェック」。基準未達では先に進めない
- Level 2 は「用途決定」。汎用モデルとして広く使うか、特化モデルとして用途を絞るかを決める
- Level 3 は「Go/No-Go」。信頼性が足りなければ、本番投入を遅延すべき 3段階に分けることで、何を直すべきかがはっきり見えます。
よくある失敗パターンと対策
失敗 1:Level 1 だけで満足する
MMLU で 60% 出たから「OK」と判断。実運用で想定外のタスクに遭遇して性能が落ちる。単一の基準だけで安心してしまうと、見えていない弱点を取り逃しやすくなります。
対策:Level 2 の汎化性能を必ず測定すること。
失敗 2:Level 2 をおろそかにして Level 3 に進む
精度は高いが、想定外の分布では使えない。その後、Level 3 で信頼性問題も出てくる。つまり、使う場面を決めないまま安全性だけ見ても、手戻りは防げません。
対策:Level 2 で想定される運用環境を定義し、その環境で十分な性能が出るか確認してから Level 3 へ。
失敗 3:Level 3 で初めて幻覚が見つかる
本番リリース 1 週間前に「30% の幻覚率」が判明。急遽、ファインチューニング。信頼性の問題は、後半で見つかるほど修正コストが高くなります。
対策:Level 3 の検査は段階 2 と並行して進めること。早期に幻覚的傾向を検出できます。
まとめ:3層構造の本質
LLM 評価の 3 層構造とは、技術的なチェックリストではなく、「モデルを実務に投入できるか」を段階的に判定するプロセスです。
Level 1(基盤)は、モデルが基本的な言語能力を持っているかの確認です。ここが満たされないなら、先に進む価値がありません。いわば入口の最低条件です。
Level 2(汎化)は、特化 vs 汎用の決定です。精度が高くても、想定される使用環境で十分な性能が出るか確認する。この決定を誤ると、実運用で機能しないモデルが出来上がります。ここでは「どこまで広く使うか」を決めます。
Level 3(信頼性)は、幻覚、バイアス、安全性を含めた「本当に信頼できるか」の最終確認です。精度と信頼性は別軸であることを忘れずに。ここでは「安心して渡せるか」を見ます。
これら 3 つを順番に進めることで、「ベンチマークスコアは高いのに、実務では使えない」というジレンマを避けられます。最初は時間がかかるように見えますが、後の手戻りを無くす最も効率的な方法です。前の段階で止めるべきものを止めるほうが、結果的には早く進めます。
最後に覚えておくべき
LLM評価の 3 層構造で差がつくのは、各指標を正しく理解することではなく、「どの段階で何を測り、どこで判定を下すか」の意思決定プロセスを持つことである。見方を分けるほど、モデルの強みと弱みが見えやすくなります。
8. 今回のブログの考察
LLM の評価は、単にベンチマークスコアを並べる作業ではなく、「このモデルをどこまで信用してよいか」を段階的に確かめる設計だと分かります。Level 1 では最低限の言語能力を見て、Level 2 では想定する利用環境に耐えられるかを確かめ、Level 3 で初めて実務に出せる信頼性があるかを判断する。今回の記事で整理したかったのは、この順番を飛ばしてしまうと、精度の高さだけを根拠に誤った意思決定をしやすい、という点です。
実務では、とくに Level 2 と Level 3 を後回しにしがちです。ですが、現場で本当に問題になるのは、平均精度よりも、想定外の入力で崩れないか、危険な誤答をどれだけ抑えられるかです。つまり、評価で見るべきなのは「よく当たるか」だけではなく、「どの条件なら任せられるか」を言語化できているかどうかです。
その意味で、この 3 層構造はモデルの優劣を決めるための仕組みというより、導入判断を誤らないための整理法として使うのが本質的です。どの層で止めるべきか、どの層で用途を絞るべきかが見えるようになると、評価は単なる数値確認ではなく、開発と運用をつなぐ実務的な意思決定になります。
📖 参考文献
主要論文
-
Hendycks, D., et al. (2021): “Measuring Massive Multitask Language Understanding”, ICLR 2021
- https://arxiv.org/abs/2009.03300
- MMLU ベンチマークの元論文。57 分野の知識測定フレームワーク。
-
Wang, A., Pruksachatkun, Y., Nangia, N., et al. (2019): “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”, NeurIPS 2019
- https://arxiv.org/abs/1905.00537
- GLUE の後継。より難しく、より実践的なベンチマーク。
📚 シリーズ案内
ブログD:詳細設計書編では、LLMの評価体系とベンチマーク管理を解説しています。
このシリーズの記事:
- LLM評価の3層構造(この記事)
- 標準ベンチマークの詳細解説
- データ汚染検出とドメイン横断性能
- Attentionの可視化と解釈
- データ品質測定とモニタリング体制
関連シリーズ:
- ブログC:データセット戦略編 – データセット選択と前処理
- ブログB:実装詳細編 – モデル実装の数値安定性
次の記事: 標準ベンチマークの詳細解説


コメント