
特化データセット戦略とドメイン最適化
汎用LLMを特定ドメインに特化させることで、専門タスクでの性能を大幅に向上できます。本記事では、ドメイン特化の戦略と注意点を詳解します。
1. FineWeb-edu:教育的テキストへの特化
汎用モデルが直面する「専門性の壁」
一般的なWebデータだけでは、専門用語の正確な定義や論理的な推論プロセスを学習するには不十分である。 「知識の定着」と「推論力」の鍵は、データ量ではなく「データの質と配合」にあります。
1.1 背景と戦略
FineWeb-eduは「教育的な文章のほうが、知識の定着や推論に向いている」という考え方を具体化したデータセットです。ここでは、その発想を土台にして、どんなテキストを選ぶのかを見ていきます。
FineWeb は実験的に「最高性能」を目指しましたが、実務では 教育的テキストの重要性 が認識されています。
標準的なWebテキストの問題点
- 短くて情報価値が低いテキストが多い
- スパム、釣りタイトル、低品質記事が混在する
- 知識的な深さが不足しやすい
教育的テキストの特性
- 段階的な説明構造がある
- 用語の定義が比較的正確
- 例示と解説が丁寧
- 推論や問題解決の流れが見えやすい
教育的な文章は、単なる情報の羅列ではなく「推論や問題解決の流れ」をモデルに教え込む。実務において「最高性能」を引き出す土台となる。
1.2 FineWeb-eduの構成
FineWeb-edu データセット構成
-
Wikipedia(日本語含む): 15%
- 百科事典的で、定義や体系化された知識に向く
-
教科書・教育プラットフォーム: 35%
- 段階的説明、例題、練習問題が多い
- 例: MIT OpenCourseWare、大学講義資料
-
学術論文(抜粋): 20%
- 専門性と厳密さがあり、参考文献も付く
- 例: arXiv、JSTORの要旨など
-
Q&Aサイト(高品質): 15%
- ユーザーの質問に対する専門家回答が得られる
- 例: Stack Exchange、数学系Q&A
-
ブログ・技術記事(高品質フィルタ): 15%
- 実践的な説明や深い解説が多い
総サイズ: 1.3〜1.4Tトークン
1.3 パフォーマンス特性
LLM 3B相当での性能比較
| STEM分野別 | 22.1% | 25.7% | +3.6% |
| 常識推論 | 55.2% | 58.4% | +3.2% |
デメリット
-
自然言語生成タスクでは FineWeb のほうがやや強い
- FineWeb: 32.1%
- FineWeb-edu: 29.4%(-2.7%)
- 理由: 教育的テキストは説明重視で、自然な会話パターンが少ない
-
コード生成では FineWeb-edu が不利になりやすい
- FineWebのコード比率: 30%
- そのぶんコード性能は下がりやすい
1.5 推奨用途
FineWeb-edu が最適
- 知識集約的なアプリケーション
- 推論・問題解決重視のモデル
FineWeb-edu が非適
- チャットボットやコード生成特化
- 創作・文学的生成
- カジュアルな対話システム
2. ドメイン別の特化戦略
4大ドメインの最適化マトリクス
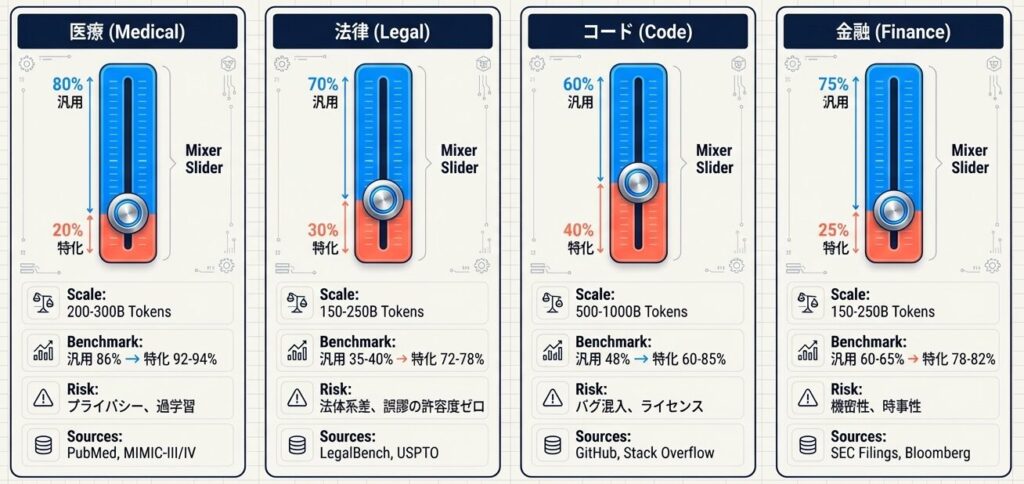
2.1 医療ドメイン
医療では、答えがそれっぽいだけでは不十分です。用語の正確さ、情報の更新性、そして誤情報をどれだけ避けられるかが、そのまま実運用の品質につながります。
データセット選択
- PubMed(公開論文): 100M+論文抄録
- MIMIC-III/IV(臨床記録): 60K+患者記録
- HealthTap Q&A: 医療専門家との対話
規模と課題
- 規模: 200〜300Bトークン(汎用の1/10程度)
- 課題: プライバシー対応が必須
- 課題: 倫理承認や利用許可の確認が必要
推奨配合
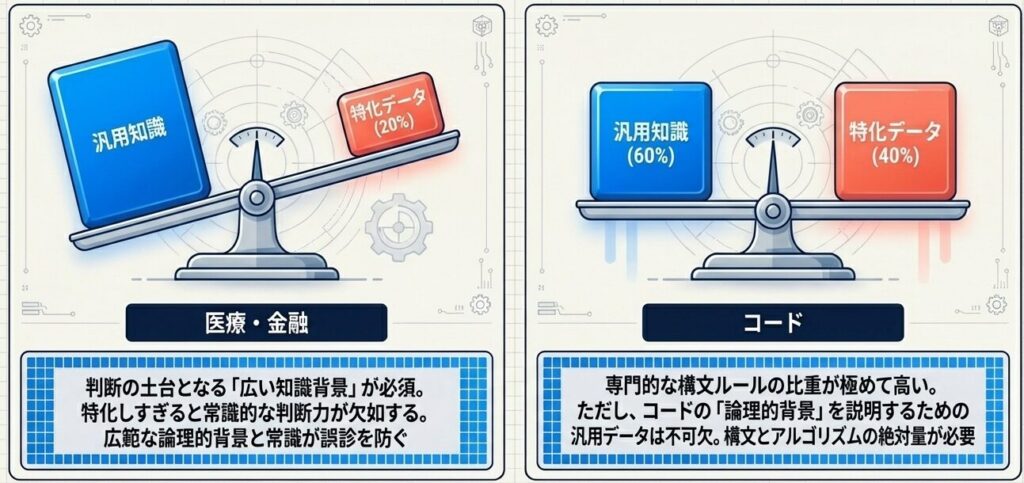
- 汎用データ 80% + 医療データ 20%
- 医療データだけだと、過学習や判断性能低下が起きやすい
性能目安
- 医療QAベンチマーク
- 汎用LLM(GPT-4): 86%
- 医療特化LLM: 92〜94%
- ただしドメイン外性能は下がる
実務では、診断支援よりも文書要約、患者向け説明、研究支援から始めるほうが安全です。
2.2 法律ドメイン
法律分野では、少しの誤りがそのままリスクになります。なので、性能の高さだけでなく、根拠を追えるかどうかが重要です。 データセット選択
- LegalBench(判例、契約書)
- USPTO(特許文書)
- 判例データベース(各国の判決文)
規模と課題
- 規模: 150〜250Bトークン
- 課題: 法律用語の正確性が重要
- 課題: 国別の法体系差で汎化しにくい
推奨配合
- 汎用データ 70% + 法律データ 30%
- 法律判断には基礎知識も必要
性能目安
- 法律相談ベンチマーク
- 汎用LLM: 35〜40%(信頼性が低い)
- 法律特化LLM: 72〜78%(実務利用段階)
契約書レビューや判例検索では、LLMを最終回答者ではなく下調べの補助役として使う設計が現実的です。
2.3 コード生成ドメイン
コード生成は、ドメイン特化の効果がわかりやすい分野です。ただし、学習データの量が多いだけでは足りず、正しい実装例と説明の両方が必要になります。 データセット選択
- GitHub(公開コード): 200M以上のリポジトリ
- Stack Overflow(Q&A)
- ArXivのコード
- Hugging FaceのAIコード例
規模と課題
- 規模: 500〜1000Bトークン
- 課題: バグを含む低品質コードが混ざる
- 課題: ライセンスの扱いが難しい
推奨配合
- 汎用データ 60% + コード 40%
- コードだけでは理論的背景が不足しやすい
性能目安
- HumanEval
- 汎用LLM(GPT-3.5): 48%
- Code特化(Codex): 85%
- Code特化(LLaMA-Code): 60〜65%
単純なコード補完だけでなく、既存コードの修正や説明付きの生成で差が出やすいです。
2.4 金融ドメイン
金融分野は、時事性と機密性の両方を意識しないといけません。文章の正確さに加えて、データの扱い方そのものがモデル設計の一部になります。 データセット選択
- SEC Filings(企業10-K報告)
- Bloomberg Terminalのデータ
- Financial News Archive
- 経済学論文
規模と課題
- 規模: 150〜200Bトークン
- 課題: 非公開データが多い
- 課題: 規制と機密性への配慮が必要
推奨配合
- 汎用データ 75% + 金融データ 25%
- 金融判断には広い知識背景が必要
性能目安
- 金融NLPベンチマーク(感情分析)
- 汎用LLM: 60〜65%
- 金融特化LLM: 78〜82%
市場分析では、ニュースの解釈だけでなく、数値の読み取りや業界用語の一貫した理解も重要です。
なぜ配合比率は異なるのか?
3. 過学習とドメイン特化のトレードオフ
3.1 特化度と性能の関係
ドメイン特化は、増やせば増やすほど良いわけではありません。一定までは効果が伸びますが、やりすぎると汎用性能が下がっていきます。
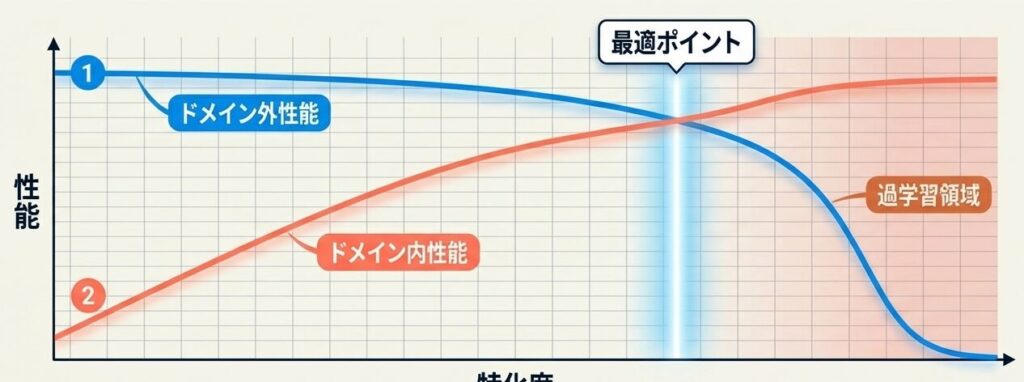
トレードオフは、次のように考えると分かりやすいです。
- 特化度を上げると、ドメイン内性能は伸びやすい
- ただし、上げすぎると過学習領域に入りやすい
- 最適ポイントは、ドメイン内性能が高く、ドメイン外性能の低下が許容範囲に収まる地点
「最適ポイントは、ドメイン内性能が高く、ドメイン外性能の低下が許容範囲に収まる地点」。増やせば増やすほど良いわけではない。
3.2 モデルサイズ別の推奨特化度
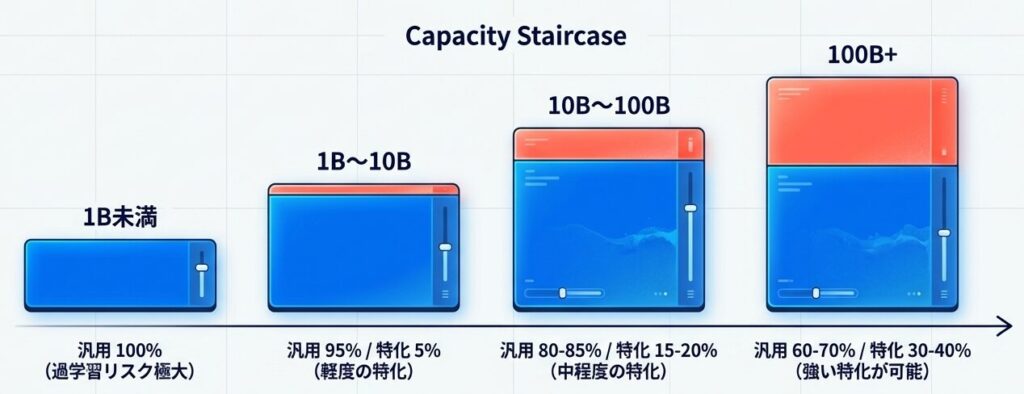
親モデルサイズ別推奨
-
1B未満(小規模)
- ドメイン特化は非推奨
- データ不足時に過学習リスクが高い
- 推奨: 汎用100%
-
1〜10B
- 軽度の特化がよい
- 推奨: 汎用95% + 特化5%
-
10〜100B
- 中程度の特化が現実的
- 推奨: 汎用80〜85% + 特化15〜20%
-
100B+
- 強い特化も可能
- 推奨: 汎用60〜70% + 特化30〜40%
親モデルの「器の大きさ」が、専門データを消化できる「濃度」を決定する。 小規模モデルでの無理な特化は破綻を招く。
3.3 特化の警告サイン
過学習が進んでいるときは、次のような兆候が出やすいです。
- ドメイン外タスクでの性能急落
- 汎用QAスコアが10%以上低下する
- 一般常識問題で不正解が増える
- 特定フレーズの過度な生成
- 専門用語を不自然に多用する
- 定型文が繰り返される
- 汎化性能の低下
- 新しい質問への対応力が落ちる
- パラフレーズに弱くなる
対策
- 特化データの比率を下げる
- より多様な汎用データを追加する
- 訓練を早期停止する
4. 特化データセットの構築ガイド
4.1 品質基準の設定
特化データは、集めた時点ではまだ「使えるデータ」ではありません。ソースの信頼性、古さ、ライセンス、偏りを一つずつ確認して、初めて学習用の土台になります。
ドメイン特化データの品質チェックリスト
-
ソースの信頼性
- 査読済み論文や公式文書か
- 専門家による作成・監修か
-
正確性の検証
- 事実誤認がないか
- 古い情報が混ざっていないか
-
法的・倫理的確認
- ライセンス条件を確認したか
- プライバシー情報を除去したか
- 利用許諾を取得したか
-
多様性の確保
- 特定のサブドメインに偏っていないか
- さまざまな形式のテキストを含んでいるか
4.2 配合比率の決定プロセス
配合比率は、一発で決めるより段階的に詰めるほうが現実的です。
- ベースラインを設定する
- 汎用データのみでモデルを訓練する
- ドメイン内・外の性能を測定する
- 少量追加で効果を測る
- 汎用95% + 特化5%で訓練する
- ドメイン内の性能向上を確認する
- 段階的に比率を調整する
- 汎用90% + 特化10%
- 汎用85% + 特化15%
- ドメイン外性能が許容範囲に収まる最大比率を探る
- 最適比率を決める
- ドメイン内性能とドメイン外性能のバランス点を選ぶ
集めただけのデータは使えない。この4つのフィルターを通過して初めて、学習の土台となる「高品質な成分」に変換される。
5. 実践例:教育特化モデルの構築
5.1 構成例
教育特化モデルは、完全に教育データだけで作るより、汎用データを土台にして教育系データを上乗せするほうが安定します。基礎知識と説明力の両方が必要だからです。
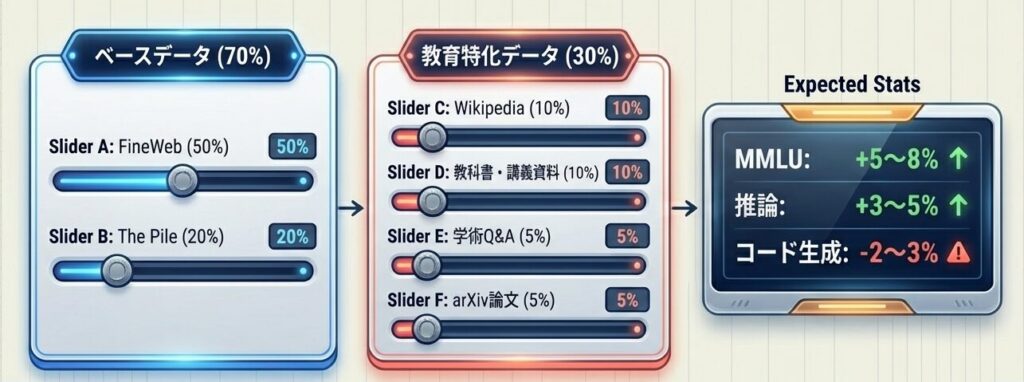
教育特化LLMの構成
-
ベースデータ(70%)
- FineWeb: 50%
- The Pile(バランス型): 20%
-
教育特化データ(30%)
- Wikipedia: 10%
- 教科書・講義資料: 10%
- 学術Q&A: 5%
- arXiv論文: 5%
総訓練トークン: 1T
完全な教育データ100%ではなく、汎用と高品質ベースを土台にすることで、説明力と基礎知識の安定した結合を実現する。
5.2 期待される性能
性能予測
- MMLU(知識): 汎用より +5〜8%
- 推論タスク: 汎用より +3〜5%
- コード生成: 汎用より -2〜3%
- 対話品質: 汎用より -1〜2%
全体としては、知識・推論重視のタスクで優位になりやすく、創作や対話では少し劣後しやすいです。
6. 今回のブログの考察
ドメイン特化は、単に専門データを増やせばよいわけではなく、汎用性をどこまで残すかを同時に決める設計だと分かります。今回のブログで見たように、FineWeb-eduは教育的な読みやすさを底上げし、医療・法律・コード・金融ではそれぞれ必要な知識を上乗せすることで性能を伸ばせます。一方で、特化を強めすぎると汎用性能が落ちやすいため、まずは汎用データを土台にし、用途に応じて少しずつ比率を調整する姿勢が現実的です。実務では、専門性だけでなく、運用時に説明できる構成かどうかも重要な判断基準になります。
📖 参考文献
主要論文
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019): “BERT: Pre-training of Deep Bidirectional Transformers”, NAACL 2019
-
Xue, L., et al. (2021): “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”, ACL 2021
-
Raffel, C., et al. (2020): “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”, JMLR 2020
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化(この記事)
- データブレンディングと将来の自動化戦略
関連シリーズ:
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: データセット選択ガイダンス 次の記事: データブレンディングと将来の自動化戦略

コメント