
Dolmaと前処理の体系化
2023年、AllenAIが公開したDolmaは、データセット前処理を「職人技」ではなく、再現可能な手順として整理しようとしたプロジェクトです。本記事では、透明性と再現性を重視した6段階パイプラインを追いながら、なぜDolmaが研究用途で評価されているのかを見ていきます。
1. Dolmaの位置付け
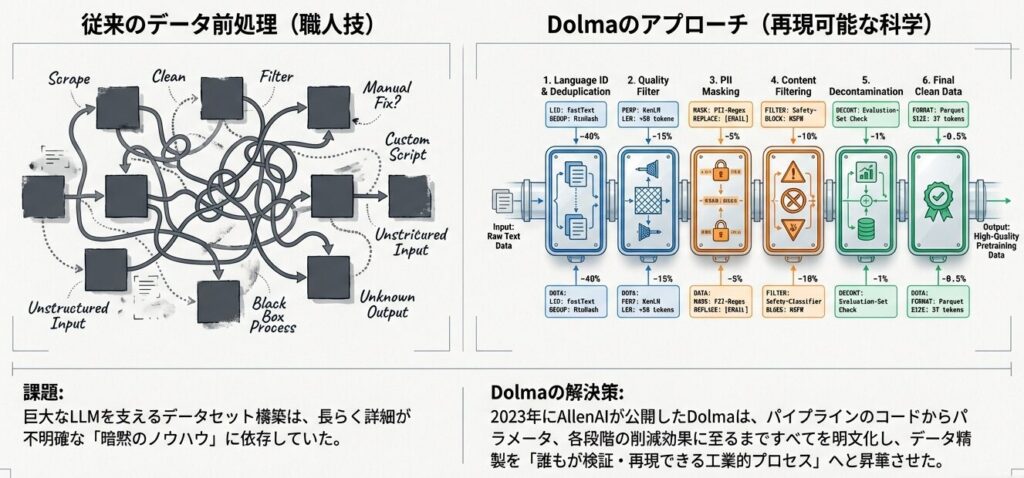
データセット前処理は「職人技」から「再現可能な科学」へ
1.1 進化の系譜
Dolmaは、これまでのデータセット設計の流れを一段進めた存在です。

- Common Crawl: まずは大規模なデータを確保するという発想
- C4: 初期的な品質フィルタリングを導入
- The Pile: 多様なソース構成の重要性を示す
- Dolma: それらを踏まえ、品質エンジニアリングを体系化する
特にDolmaの特徴は、「何をやったか」だけでなく、「なぜその処理が必要なのか」を含めて標準化しようとした点にあります。
1.2 Dolmaの特徴
Dolmaの設計思想
- 透明性
- すべての処理ステップを明文化する
- パイプラインのコードを公開する
- 再現性
- 同じ手順で同じ結果を得られるようにする
- 学術研究の信頼性を確保する
- 包括性
- 6段階の体系的なフィルタリングを導入する
- 各段階の効果を定量化する
2. 6段階処理パイプライン
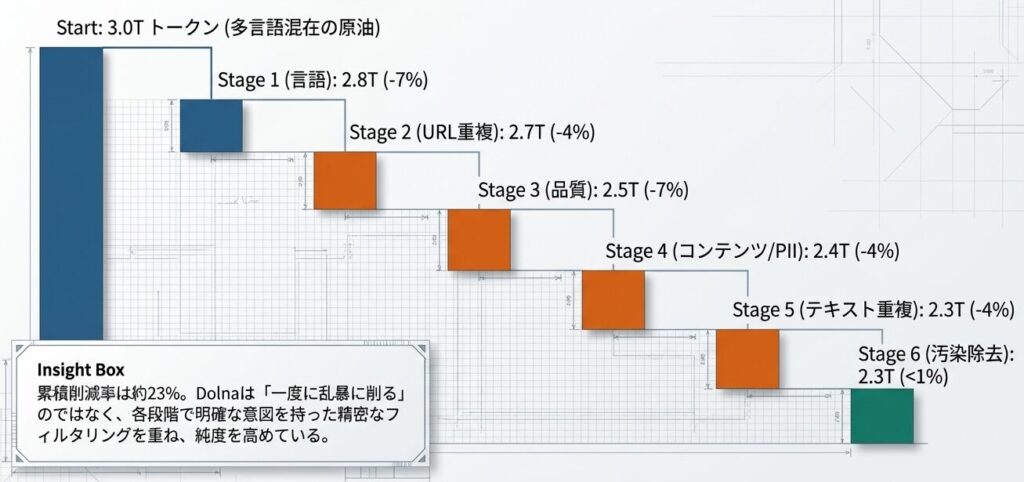
削減のウォーターフォール:微小な改善の積み重ね
ステージ1:言語フィルタリング
最初のステージは、言語の一貫性を確保する処理です。英語特化モデルを作るなら、ここで多言語混在をある程度整理しておく必要があります。

目的
- 非英語テキストを除去し、言語的一貫性を確保する
実装
fastTextの言語識別モデルを使用する- 判定基準は
P(英語) ≥ 0.5のテキストのみ保持する
効果
- 入力: 3.0Tトークン(多言語混在)
- 出力: 2.8Tトークン
- 削減率: 約7%
意義
- 英語モデルでは言語純度を高めることでノイズを減らせる
- 結果として、学習効率の改善につながる
ステージ2:URLベースの重複排除
次に行うのは、同じページが何度も入ってくる問題への対処です。ここでは、まず大きな単位で重複を削っていきます。

目的
- 同じソースからの重複を初期段階で除去する
実装
- ソースURL単位で重複を判定する
URL_hashが一致したら削除する
効果
- 入力: 2.8Tトークン
- 出力: 2.7Tトークン
- 削減率: 約4%
意義
- 同じページの複数クロールのようなマクロレベルの重複を効率よく排除できる
ステージ3:品質フィルタリング
ここでは、Web由来のテキストにありがちな崩れた文章を落としていきます。派手な処理ではありませんが、実務ではかなり効く部分です。

目的
- 構文的に不完全なテキストを除去する
実装
- ルールベースのフィルタを使う
- 句読点で終わらない段落を削除する
- 非常に短い段落を削除する
- リンクテキストの割合が高いものを削除する
- 異常な文字分布を示すものを削除する
効果
- 入力: 2.7Tトークン
- 出力: 2.5Tトークン
- 削減率: 約7%
意義
- テキストの基本的な質を保証できる
- モデルが正常な言語パターンを学びやすくなる
ステージ4:コンテンツフィルタリング
このステージでは、安全性とプライバシー保護を扱います。モデル性能だけでなく、実運用に耐えられるかどうかに直結する工程です。
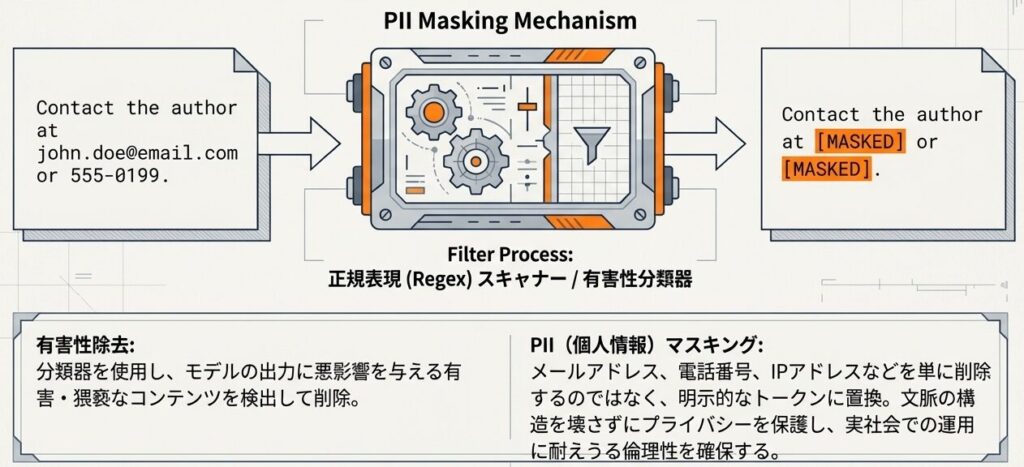
目的
- 有害・猥褻コンテンツを除去する
- 個人情報(PII)を検出してマスクする
実装1: 有害性判定
- 分類器を使って有害コンテンツを判定し、削除する
実装2: PII除去
- 正規表現でメールアドレスや電話番号などを検出する
- 検出した情報は
[MASKED]に置き換える
効果
- 入力: 2.5Tトークン
- 有害除去後: 2.45Tトークン
- PII除去後: 2.4Tトークン
- 削減率: 約4% + マスク処理
意義
- モデルの安全性と倫理性を確保できる
- 実社会での応用を考えるなら必須に近い工程になる
ステージ5:テキストレベルの重複排除
URL単位の重複を取ったあとでも、内容がほぼ同じ段落は残ります。ここでは、そうした細かな冗長性を落としていきます。

目的
- 段落単位での重複を除去する
- モデルが特定フレーズを過学習することを防ぐ
実装
Simhashなどのハッシング技術で段落の重複を判定する- 重複度が閾値以上なら削除する
効果
- 入力: 2.4Tトークン
- 出力: 2.3Tトークン
- 削減率: 約4%
意義
- ミクロレベルの冗長性を除去できる
- モデルの汎化性能の改善につながる
ステージ6:評価セット汚染除去(Decontamination)
最後のステージは、研究用途では特に重要です。評価データが訓練データに混ざっていると、モデルが本当に賢いのか、ただ暗記しているだけなのかが分からなくなります。
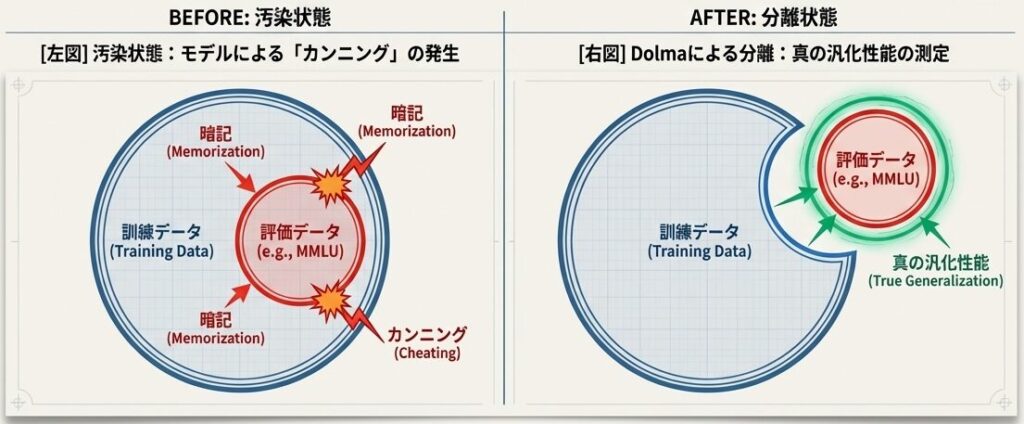
目的
- 評価用データセットに含まれるテキストを訓練データから除去する
- モデル性能評価の信頼性を科学的に確保する
実装
- 評価セット(GLUE、SuperGLUEなど)の段落をスキャンする
- 訓練データに含まれていないか検査する
- 含まれていた場合は削除する
効果
- 削減量は微小(<0.5%)
- それでも、性能評価の信頼性は大きく改善する
意義
- LLM研究の学術的厳密性を確保できる
- リーク、いわば「カンニング」を防止できる
- 学術界では標準化が望まれるプロセスである
これにより「真の汎化性能」を測るための学術的に厳密なベースラインが完成する。
3. 各ステージの削減効果
3.1 段階的削減の可視化
トークン数の推移を見ると、Dolmaが「一度に大きく削る」のではなく、小さな改善を積み上げていることが分かります。
- 入力: 3.0Tトークン
- ステージ1: 2.8T(-7%)言語フィルタ
- ステージ2: 2.7T(-4%)URL重複排除
- ステージ3: 2.5T(-7%)品質フィルタ
- ステージ4: 2.4T(-4%)コンテンツフィルタ
- ステージ5: 2.3T(-4%)テキスト重複排除
- ステージ6: 2.3T(<1%)デコンタミネーション
累積削減率は約23%です。削減率だけを見ると穏やかですが、そのぶん各段階の意図が明確です。
3.2 削減効果の比較表
| ステージ | 処理内容 | 入力 | 出力 | 削減率 |
|---|---|---|---|---|
| 1 | 言語フィルタ | 3.0T | 2.8T | 7% |
| 2 | URL重複排除 | 2.8T | 2.7T | 4% |
| 3 | 品質フィルタ | 2.7T | 2.5T | 7% |
| 4 | コンテンツフィルタ | 2.5T | 2.4T | 4% |
| 5 | テキスト重複排除 | 2.4T | 2.3T | 4% |
| 6 | デコンタミネーション | 2.3T | 2.3T | <1% |
4. Dolmaの最終規模と特徴
Dolmaは、複数ソースを統合した入力データに6段階パイプラインを適用し、最終的に3.0Tトークン規模のデータセットを構成します。

最終規模
- 5,334GB(圧縮)
- 3,084Bトークン
特徴
- 6段階の透明性の高い処理を採用している
- 各段階が科学的に正当化されている
- ベストプラクティスの標準化を目指している
- 再現可能性が高い
5. Dolmaの学術的意義
5.1 デコンタミネーションの重要性
なぜデコンタミネーションが重要か
- 問題は、評価セットのリークです
- 訓練データに評価セットの文章が含まれていると、モデルが答えを暗記してしまう
- その結果、性能評価が実力以上に見えてしまう
たとえば、MMLUの問題文が訓練データに含まれていたら、テスト時には「初見の問題」ではなくなります。これでは、本当の意味での汎化性能は測れません。
Dolmaは、主要ベンチマークのテキストをスキャンし、訓練データとの重複を除去することで、この問題に対処しています。
5.2 再現可能性の確保
研究の再現性
-
Dolma以前
- データセット構築の詳細が不明確なことが多かった
- 同じ結果を再現するのが難しかった
- 比較実験の信頼性にも疑問が残りやすかった
-
Dolma以後
- パイプラインのコードが公開された
- 各ステップのパラメータが明示された
- 誰でも同じデータセットを再構築しやすくなった
6. 実務での活用指針
6.1 Dolma利用のケース
Dolmaは、性能だけでなく評価の信頼性まで重視したい場面に向いています。特に研究や検証フェーズでは、かなり扱いやすい基準点になります。
適している場面
- 学術研究で信頼性の高いベースラインが必要
- デコンタミネーションが重要な評価実験
- 中〜大規模モデル(3〜70B)の訓練
- パイプラインを参考に自社構築したい
利点
- 学術的な信頼性が高い
- デコンタミネーションを実装済み
- 透明性と再現性が高い
- 3.0Tトークンの大規模データを扱える
6.2 Dolmaパイプラインの応用
自社データセット構築への応用
Dolmaの6段階は、そのまま真似するというより、自社パイプラインの設計図として使いやすいです。
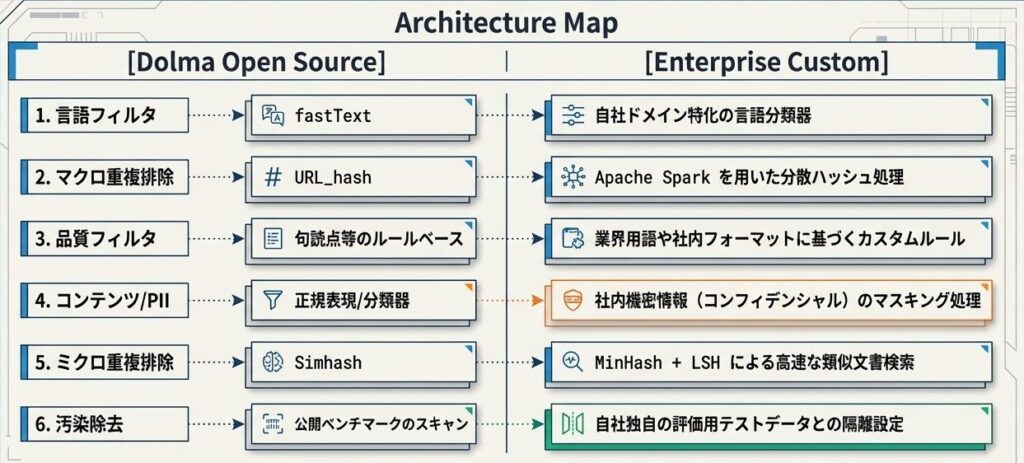
- 言語フィルタ:
fastTextなどを利用可能 - URL重複排除:
Sparkなどで実装しやすい - 品質フィルタ: ルールベースで調整可能
- コンテンツフィルタ: 分類器を用途に合わせてカスタマイズ可能
- テキスト重複排除:
MinHashやSimhashを活用可能 - デコンタミネーション: 対象ベンチマークを指定して実施可能
各ステップを調整することで、組織のニーズに合ったデータセット構築へつなげやすくなります。
📖 参考文献
主要論文
- Soldaini, L., et al. (2024): “Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research”, ACL 2024
- Gao, L., et al. (2020): “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, arXiv
- Xie, S. M., et al. (2023): “Doremi: Optimizing Data Mixture for Language Model Pre-Training”, arXiv
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化(この記事)
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ:
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: The Pileと多様性の発見 次の記事: FineWebと学習効率の最前線

コメント