
データセット選択ガイダンス
プロジェクトマネージャーや意思決定者にとって、データセット選びは技術課題であると同時に経営判断でもあります。本記事では、組織のニーズに合わせて選びやすくするための意思決定フレームワークを整理します。
1. 意思決定フロー
データセット選択は純粋な技術課題ではなく、経営資源の最適化プロセスである
The Trap
- 「なんとなく有名だから」「パラメータ数が最大だから」という理由での選択は、運用負荷の増大とプロジェクトの頓挫を招く。
The Strategy
- 最適なデータセットは、チーム規模、利用可能なGPU時間、そしてプロジェクトの現在のフェーズという「組織の制約」から逆算して決定されるべきである。
1.1 4つの質問で最適解を導く
まずは、次の4つの質問に答えるだけで候補がかなり絞れます。
ステップ1: 言語要件
- 英語特化なら: C4、The Pile、Dolma、FineWeb
- 多言語対応が必要なら: ROOTS、OSCAR なども検討する
ステップ2: 品質要件
- スケール重視なら: Common Crawl + 自社パイプライン
- 品質重視なら: Dolma(デコンタミネーション実装済み)
ステップ3: 計算リソース
- 限定的(1ヶ月未満): The Pile(325B)
- 中程度(1〜3ヶ月): Dolma(3.0T)
- 豊富(3ヶ月以上): FineWeb(18.5T)
ステップ4: 用途確認
- 学術的な厳密性が必須なら: Dolma
- 実証済み性能を優先するなら: FineWeb
1.2 質問ツリーの詳細
質問ツリーとして見ると、判断の流れは次のようになります。
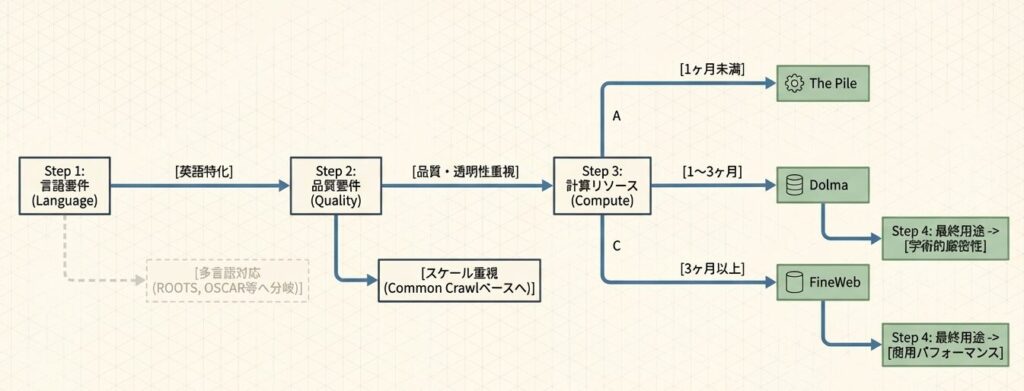
- Q1: 英語特化か、多言語対応か
- Q2: 品質重視か、スケール重視か
- Q3: 計算リソースはどこまで使えるか
- Q4: 学術的厳密性をどこまで求めるか
この順番で考えると、「なんとなく有名だから選ぶ」という判断を避けやすくなります。
2. プロジェクトフェーズ別の推奨
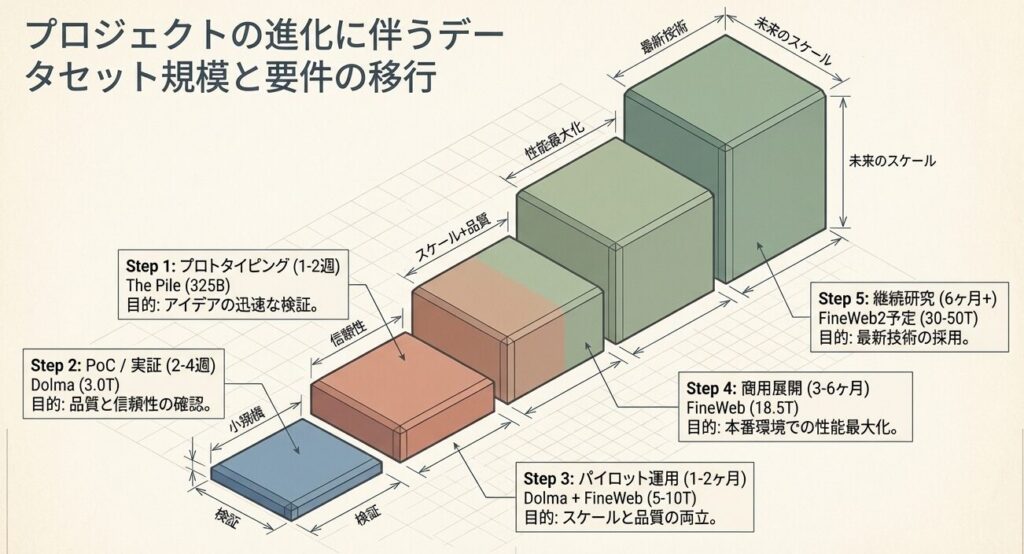
2.1 フェーズ別推奨マトリクス
| フェーズ | 期間 | 推奨データセット | 規模 | 理由 | 学習時間(A100 8x) | コスト |
|---|---|---|---|---|---|---|
| プロトタイピング | 1-2週 | The Pile | 325B | 多様性+速度 | 1-2週 | 低 |
| PoC/実証 | 2-4週 | Dolma | 3.0T | 透明性・品質重視 | 2-3週 | 中 |
| パイロット運用 | 1-2ヶ月 | Dolma + FineWeb | 5-10T | ハイブリッド | 4-8週 | 中 |
| 商用展開 | 3-6ヶ月 | FineWeb | 18.5T | 実証済み性能 | 8-12週 | 高 |
| 学術発表 | 2-3ヶ月 | Dolma + 自社 | 3-5T | 信頼性・再現性 | 3-6週 | 中 |
| 継続研究 | 6ヶ月+ | FineWeb2予定 | 30-50T | 最新技術採用 | 12-20週 | 非常に高 |
2.2 選択基準の解説
フェーズごとの違いは、目的の違いとして捉えると分かりやすいです。
プロトタイピング
- 目的: 素早くアイデアを検証する
- 選択: The Pile
- 理由: コストと速度を優先しつつ、多様性も確保しやすい
PoC(概念実証)
- 目的: 品質と信頼性を確認する
- 選択: Dolma
- 理由: 慎重な検証に向き、デコンタミネーションにも対応している
パイロット運用
- 目的: スケールと品質を両立する
- 選択: Dolma + FineWeb
- 理由: 両者を併用しながら段階的に拡大しやすい
商用展開
- 目的: 本番環境での性能最大化
- 選択: FineWeb
- 理由: 性能面での実績があり、大規模運用に向いている
学術発表
- 目的: 再現性と信頼性を確保する
- 選択: Dolma
- 理由: デコンタミネーションが重要で、パイプラインも公開されている
3. リソース別の推奨
計算資源とチーム規模がもたらす現実的な運用ボトルネック
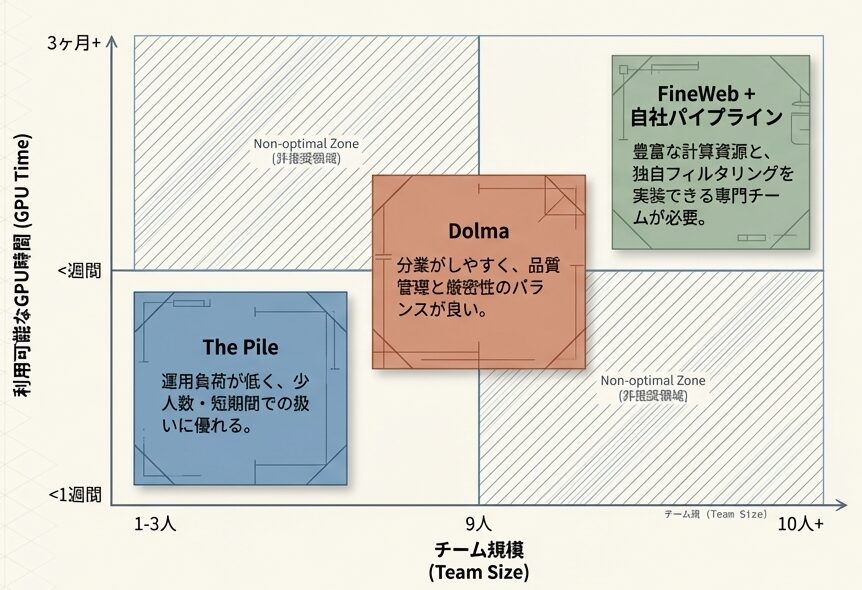
3.1 計算リソース別
ここでは、GPU時間を実務上の制約として考えます。どれだけ良いデータセットでも、回し切れなければ意味がありません。
GPU時間: 1週間以下
- 推奨: The Pile(325B)
- 理由: 小規模実験に向き、A100 8x なら短期間で回しやすい
GPU時間: 1〜4週間
- 推奨: Dolma(3.0T)
- 理由: 中規模プロジェクトに向き、品質と厳密性のバランスが良い
GPU時間: 1ヶ月以上
- 推奨: FineWeb(18.5T)
- 理由: 大規模商用開発に向き、学習効率も高い
GPU時間: 3ヶ月以上
- 推奨: FineWeb + ドメイン特化データ
- 理由: フルスケール開発とカスタマイズが可能になる
3.2 チーム規模別
チーム規模も、選択にかなり影響します。人が少ないと、データセットそのものより運用負荷がボトルネックになりやすいからです。
小規模チーム(1〜3人)
- 推奨: The Pile → Dolma
- 理由: 管理しやすく、ドキュメントも比較的充実している
中規模チーム(4〜10人)
- 推奨: Dolma → FineWeb
- 理由: 分業しやすくなり、カスタマイズの余地も広がる
大規模チーム(10人以上)
- 推奨: FineWeb + 自社パイプライン
- 理由: 独自フィルタやドメイン特化を本格的に進めやすい
4. 用途別の推奨
4.1 目的別選択ガイド
用途から逆算して選ぶと、判断はかなりシンプルになります。
研究・論文発表
- 推奨: Dolma
- 必須要件: デコンタミネーション、再現可能なパイプライン、透明性の高いドキュメント
商用プロダクト
- 推奨: FineWeb
- 必須要件: 実証済みの性能、大規模対応、ライセンスの明確さ
社内ツール・PoC
- 推奨: The Pile または Dolma
- 必須要件: コスト効率、素早い立ち上げ、柔軟なカスタマイズ
教育・学習目的
- 推奨: The Pile
- 必須要件: 多様な例題、ドキュメントの充実、オープンソースであること
4.2 ドメイン別の追加データセット
ドメイン特化を考える場合は、ベースデータセットに専門データをどう上乗せするかが重要です。
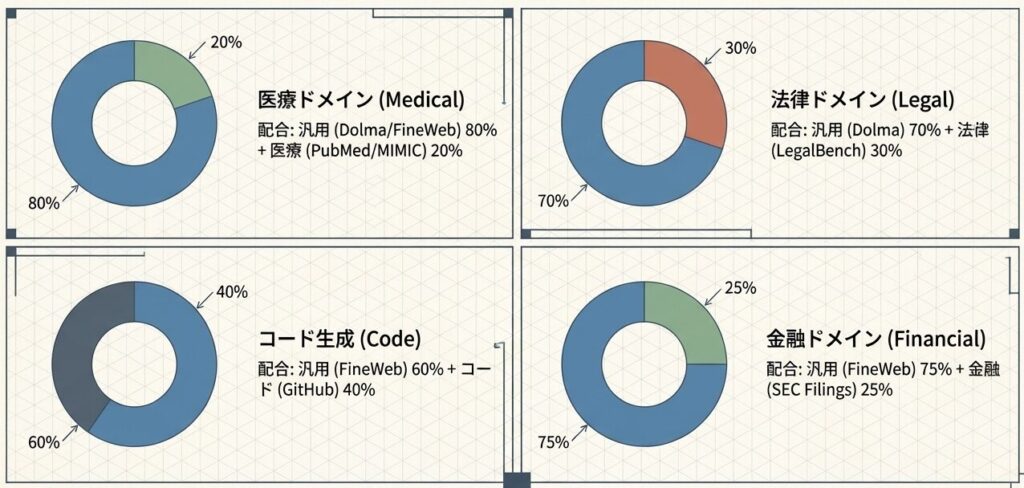
-
医療ドメイン
- ベース: Dolma または FineWeb
- 追加: PubMed、MIMIC-III/IV
- 配合: 汎用80% + 医療20%
-
法律ドメイン
- ベース: Dolma
- 追加: LegalBench、USPTO
- 配合: 汎用70% + 法律30%
-
コード生成
- ベース: FineWeb
- 追加: GitHub、Stack Overflow
- 配合: 汎用60% + コード40%
-
金融ドメイン
- ベース: FineWeb
- 追加: SEC Filings、Financial News
- 配合: 汎用75% + 金融25%
5. 意思決定チェックリスト
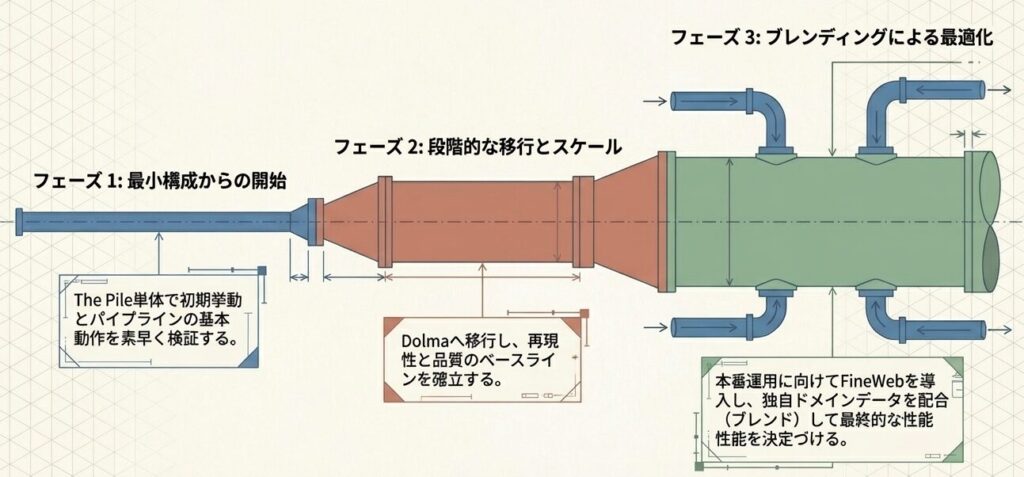
データセット選択は「単発の決定」ではなく「パイプラインの進化」である
5.1 プロジェクト開始前
-
言語要件を明確化したか
- 英語のみか、多言語対応か
-
品質要件を定義したか
- 学術的厳密性が必要か
- デコンタミネーションが必須か
-
リソース制約を把握したか
- 利用可能なGPU時間
- チーム規模
- 予算上限
-
用途を明確化したか
- 研究か、商用か、社内ツールか
- ドメイン特化が必要か
5.2 データセット選択時
- 上記4つの質問に回答したか
- フェーズに合ったデータセットを選択したか
- ライセンス要件を確認したか
- 必要なストレージ容量を確保したか
- ダウンロードと前処理の時間を見積もったか
5.3 実装開始後
- データセットの整合性を確認したか
- サンプルデータで動作確認したか
- 学習曲線をモニタリングしているか
- 必要に応じてブレンディング比率を調整できる状態か
6. よくある質問(FAQ)
プロジェクトを安全に進行させるための実装・運用チェックリスト

Q1: 複数のデータセットを組み合わせるべき?
A: フェーズによります。
- プロトタイプ段階なら、単一データセットでも十分です
- 本番段階では、ブレンディングの効果が大きくなります
- たとえば
FineWeb 70% + ドメインデータ 30%のような構成が考えられます
Q2: 予算が限られている場合は?
A: The Pileから始めるのが現実的です。
- 適度なサイズで扱いやすい
- 多様性が確保されている
- コスト効率が高い
必要に応じて、あとからDolmaやFineWebへ段階的に移行できます。
Q3: 学術論文を書く予定がある場合は?
A: Dolmaを強く推奨します。
- デコンタミネーションを実装済み
- 再現可能なパイプラインを持つ
- 学術コミュニティでも扱いやすい
7. 今回のブログの考察
データセット選択は「最も強いものを1つ選ぶ」作業ではなく、目的・リソース・運用体制をそろえて、無理なく回せる構成を決める作業だと分かります。今回のブログで見たように、The Pileは小さく素早く始める段階に向き、Dolmaは再現性と信頼性を確認する段階に向き、FineWebは本番運用で効率を取りにいく段階に向いています。実務では、まず用途を明確にし、次に制約条件を整理し、そのうえで最小構成から試すのが堅実です。特に、選択の基準を「有名かどうか」ではなく、「今の組織で回せるかどうか」に置くことが重要です。
📖 参考文献
主要論文
- Gao, L., et al. (2020): “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, arXiv
- Soldaini, L., et al. (2024): “Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research”, ACL 2024
- Penedo, G., et al. (2024): “The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale”, arXiv
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス(この記事)
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ:
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: データセット前処理戦略の比較分析 次の記事: 特化データセット戦略とドメイン最適化

コメント