
1. データブレンディングの基礎
1.1 なぜブレンディングが必要か
1つのデータセットだけで、あらゆるタスクに強いモデルを作るのは難しくなってきました。そこで重要になるのが、複数ソースをどう組み合わせるかです。
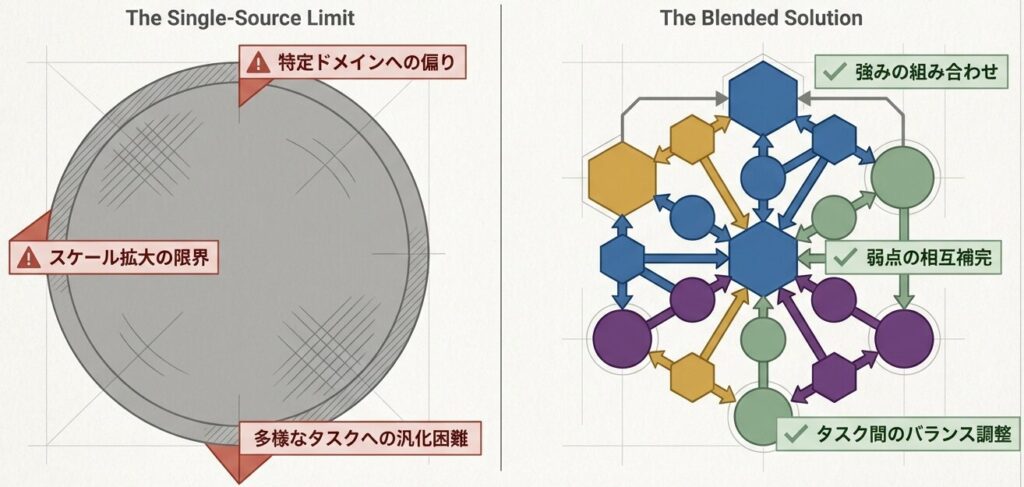
単一データセットの限界
- 特定ドメインに偏りやすい
- スケール拡大に限界がある
- 多様なタスクへの汎化が難しい
データブレンディングの必要性
- 各データセットの強みを組み合わせられる
- 弱点を相互に補完できる
- タスク間のバランスを調整しやすい
- スケールを確保しやすい
1.2 ブレンディングの基本原則
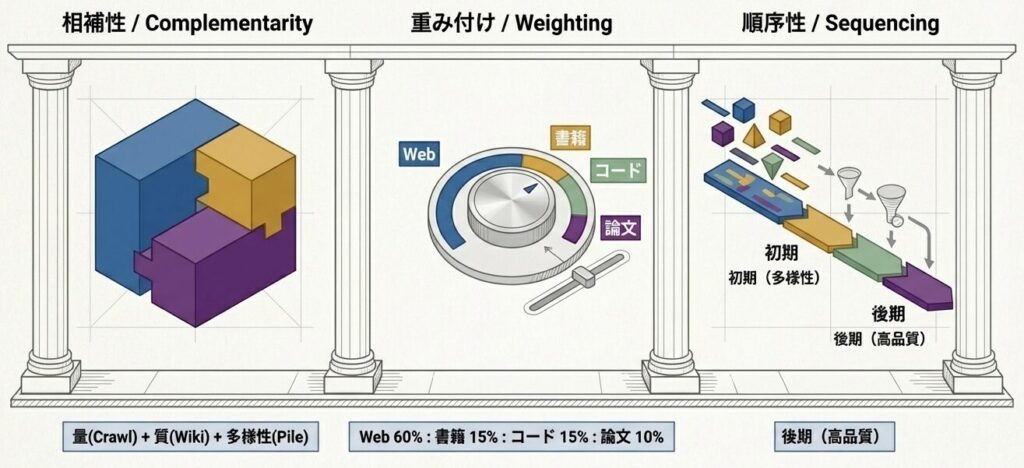
原則1: 相補性
- 異なる特性を持つデータセットを組み合わせる
- 例: 量(Common Crawl)+ 質(Wikipedia)+ 多様性(The Pile)
原則2: 重み付け
- 各データセットの貢献度を配合比率で制御する
- 例: Web 60% + 書籍 15% + コード 15% + 論文 10%
原則3: 順序性
- 訓練段階に応じて配合比率を変える
- 例: 初期は多様性重視、後期は高品質重視
2. ブレンディング比率の決定方法
2.1 主要な戦略
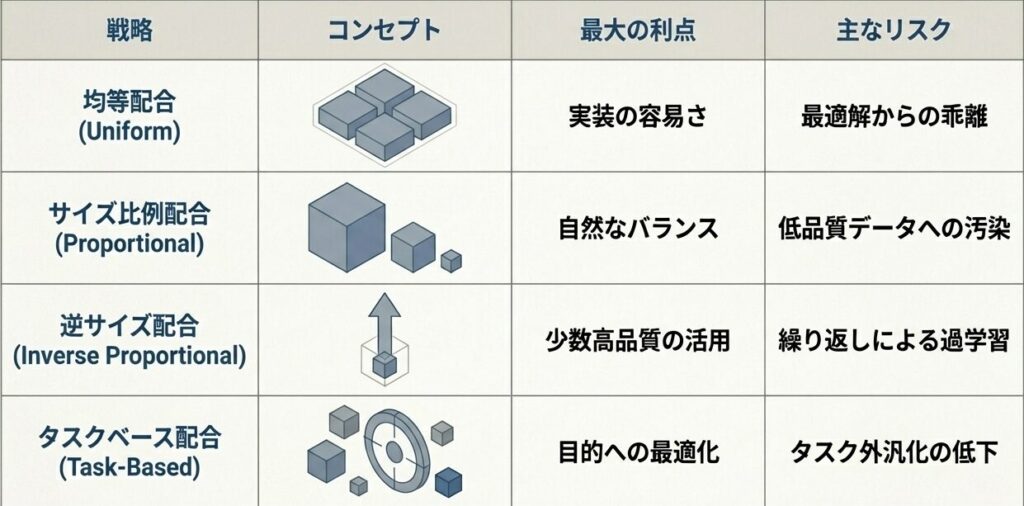
戦略1: 均等配合(Uniform)
- 全データセットを同じ比率で混合する
- 利点: 実装が簡単
- 欠点: 最適解から遠い可能性がある
戦略2: サイズ比例配合(Proportional)
- 各データセットのサイズに比例して配合する
- 利点: 自然なバランスになりやすい
- 欠点: 低品質データの影響を受けやすい
戦略3: 逆サイズ配合(Inverse Proportional)
- 小さいデータセットを重視してアップサンプリングする
- 利点: 少数の高品質データを活用しやすい
- 欠点: 繰り返しによる過学習リスクがある
戦略4: タスクベース配合(Task-Based)
- 目標タスクに基づいて配合比率を決める
- 利点: 目的に合わせて最適化しやすい
- 欠点: タスク外への汎化が弱くなりやすい
2.2 実践的な配合比率の例
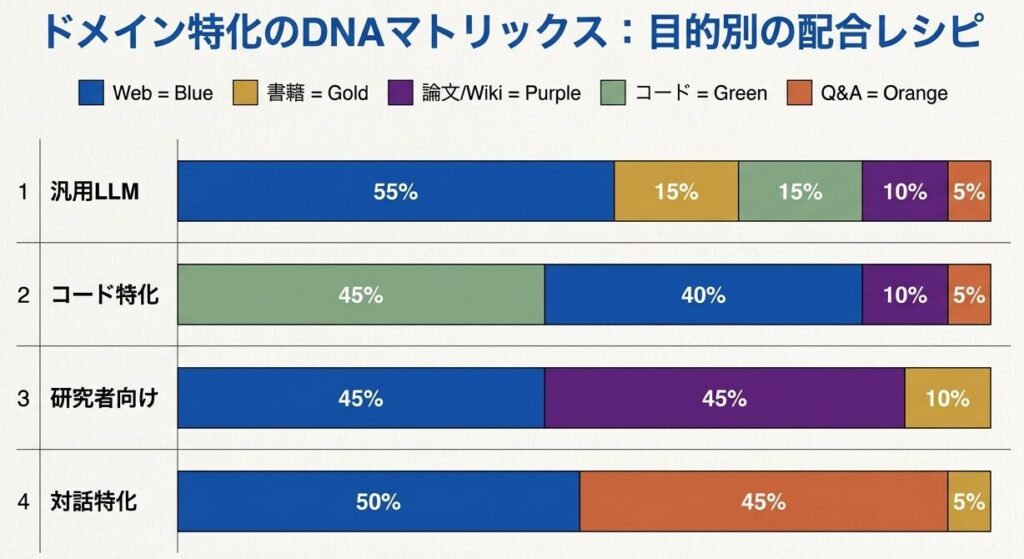
汎用LLMを想定するなら、次のような配合が出発点になりやすいです。
-
Webテキスト: 50〜60%
- Common Crawl、C4、FineWeb などをベースにする
-
書籍・出版物: 10〜15%
- Books3、Gutenberg など
-
学術・技術文書: 10〜15%
- arXiv、Wikipedia など
-
コード: 10〜15%
- GitHub、Stack Overflow など
-
対話・Q&A: 5〜10%
- Reddit、Stack Exchange など
2.3 ドメイン特化モデル向け配合
特化モデルでは、配合比率がそのまま性格を決めます。
-
コード生成特化
- 汎用Web: 40%
- コード: 45%
- 技術文書: 10%
- Q&A: 5%
-
研究者向け
- 汎用Web: 45%
- 論文: 30%
- Wikipedia: 15%
- 教科書: 10%
-
対話特化
- 汎用Web: 50%
- 対話データ: 30%
- Q&A: 15%
- 書籍: 5%
3. アブレーション実験による検証
3.1 アブレーション実験とは
アブレーション実験は、「何が効いているのか」を切り分けるための基本手法です。
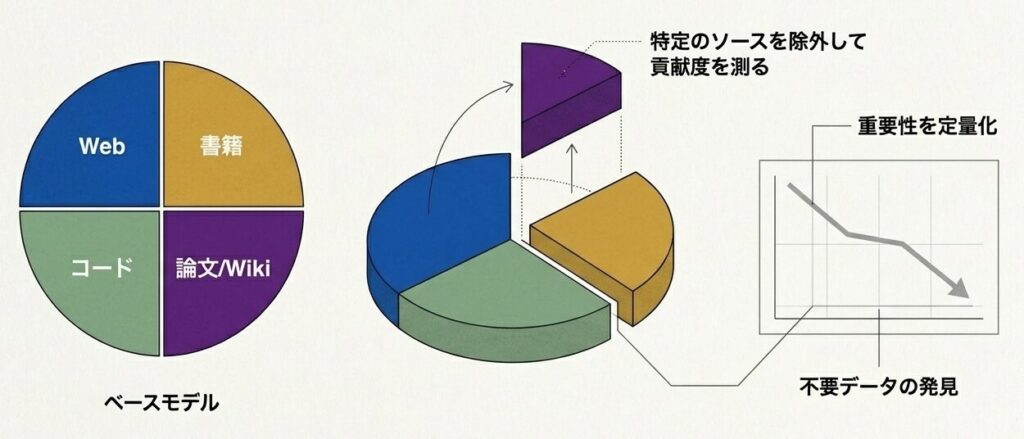
定義
- 特定の要素、ここではデータソースを除外して、その貢献度を測る実験
目的
- 各データソースの重要性を定量化する
- 最適な配合比率を探る
- 不要なデータソースを見つける
3.2 実験設計の例
たとえば、次のような設計で実験すると、配合の効き方が見えてきます。
ベースライン実験
- 配合: Web 50% + 書籍 20% + コード 20% + 論文 10%
- MMLU、推論、コード生成などで性能を測定する
除外実験
-
実験1: Web 50% + 書籍 30% + コード 20% + 論文 0%
- 論文の貢献度を測る
-
実験2: Web 50% + 書籍 0% + コード 30% + 論文 20%
- 書籍の貢献度を測る
-
実験3: Web 50% + 書籍 30% + コード 0% + 論文 20%
- コードの貢献度を測る
結果分析
- 各タスクでの性能変化を比較する
- どのデータソースがどのタスクに寄与しているかを特定する
3.3 アブレーション結果の典型例
仮想的な結果としては、次のような傾向がよく説明に使われます。
| 指標 | ベース | 論文除外 | 書籍除外 | コード除外 |
|---|---|---|---|---|
| MMLU(知識) | 45% | 42% | 43% | 44% |
| 推論タスク | 55% | 51% | 53% | 54% |
| コード生成 | 60% | 59% | 58% | 42% |
| 読解理解 | 62% | 60% | 58% | 61% |
この結果からは、次のように読めます。
- 論文は知識・推論に大きく寄与する
- 書籍は読解理解に効きやすい
- コードはコード生成に決定的な影響を持つ
3.4 コスト効率の考慮
ただし、アブレーション実験は理屈としてはきれいでも、計算コストが重くなりがちです。
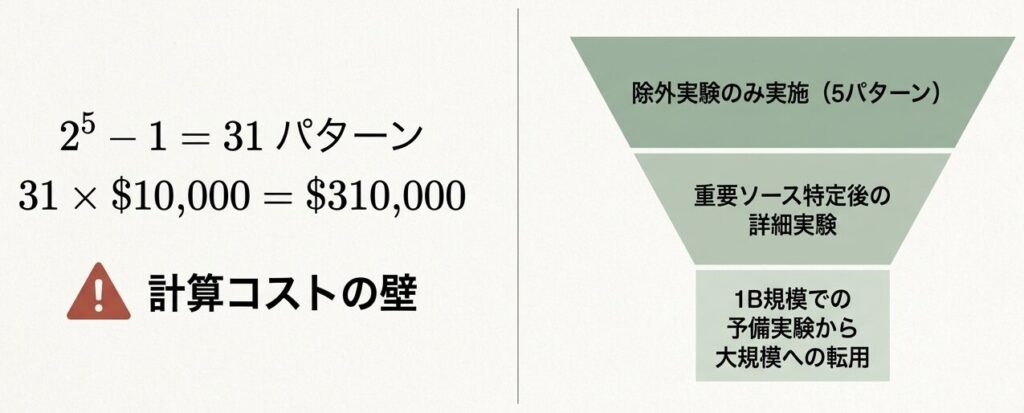
計算コストの現実
- フルアブレーション(5データソース)では
2^5 - 1 = 31パターンが必要になる - 各実験のコストを仮に
$10,000とすると、総額は$310,000になる
効率的なアプローチ
- まずは除外実験だけに絞る(5パターン)
- 重要なソースを特定してから詳細実験に進む
- 小規模モデル(1B程度)で予備実験し、大規模モデルへ知見を転用する
4. 訓練段階別のブレンディング
4.1 カリキュラム学習との統合
訓練段階ごとに配合を変える考え方は、カリキュラム学習と相性が良いです。最初から最後まで同じ比率で回すより、目的に応じて重みを変えるほうが素直な場面もあります。
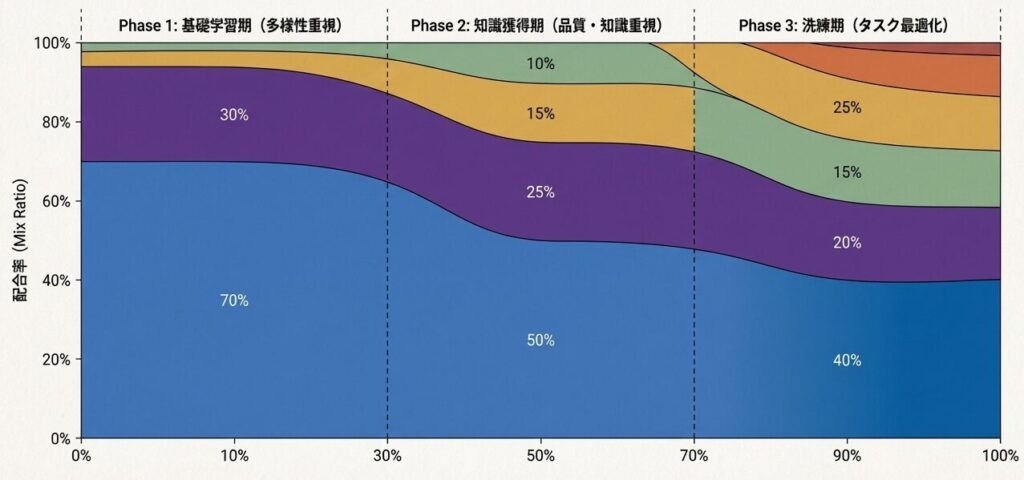
Phase 1: 基礎学習期(0〜30%訓練)
- 目標: 言語の基本構造を学ぶ
- 配合: 多様性重視
- Web: 70%
- 書籍: 15%
- その他: 15%
Phase 2: 知識獲得期(30〜70%訓練)
- 目標: 事実知識と推論能力を強化する
- 配合: 品質重視へ移行
- Web: 50%
- Wikipedia/論文: 25%
- 書籍: 15%
- コード: 10%
Phase 3: 洗練期(70〜100%訓練)
- 目標: タスク性能を最適化する
- 配合: 高品質データに集中
- FineWeb-edu: 40%
- 論文: 20%
- 高品質Web: 25%
- コード: 15%
4.2 動的配合調整
訓練中に配合を変える「適応的ブレンディング」も注目されていますが、実装難易度は高めです。
考え方
- バリデーションロスの推移や特定ベンチマークのスコアを監視する
- 性能低下が見えたら、該当ドメインのデータ比率を増やす
- 過学習が疑われるなら、多様性を増やす方向で調整する
実装上の難しさ
- リアルタイム評価のオーバーヘッドが大きい
- 配合変更のたびにデータパイプラインの再構成が必要になる
- 現状では研究段階の色合いが強く、実運用では固定配合が主流である
5. 将来の自動化パイプライン
5.1 現状の課題
自動化の話に入る前に、まずは現在の手動プロセスがどこで重くなっているのかを整理しておきます。
手動プロセスによるボトルネックマップ
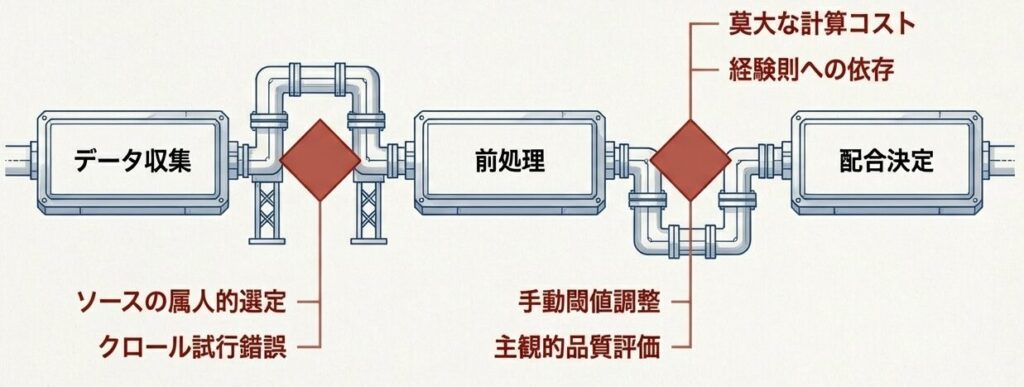
データ収集の課題
- ソース選定を人手で行う必要がある
- クロール設定の試行錯誤が多い
- 新規ソースの発見に時間がかかる
前処理の課題
- フィルタリング閾値を手動で調整している
- 品質評価に主観が入りやすい
- 言語別の個別対応が必要になる
配合決定の課題
- アブレーション実験の計算コストが高い
- 経験則に依存しやすい
- 最適解が保証されるわけではない
5.2 自動化の展望
ここから先は、現時点で広く定着した手法というより、「今後有力そうな方向性」として見るのが自然です。
近未来の自動化パイプラインのイメージ
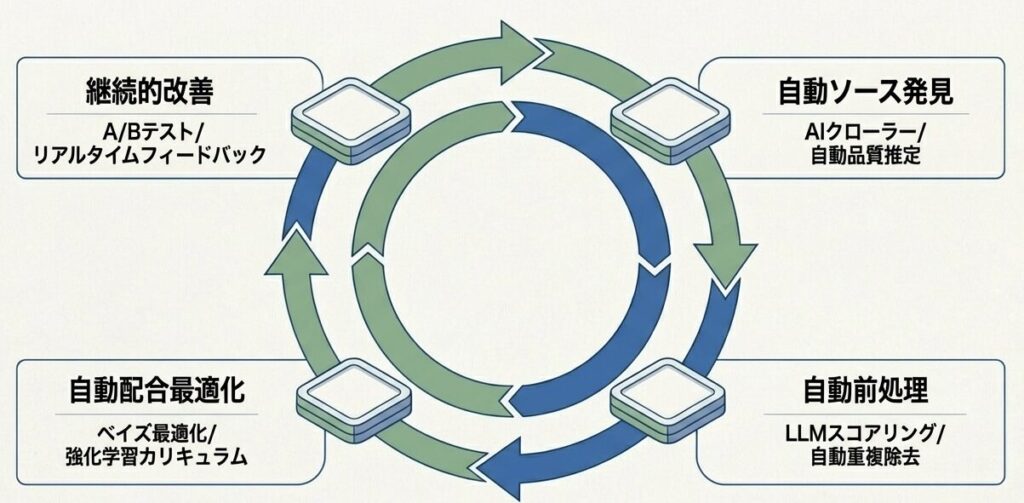
- 自動ソース発見
- Webクローラーの自動最適化
- 新規データソースの自動検出
- 品質推定による自動選別
- 自動前処理
- LLMによる品質スコアリング
- 言語検出や分類の自動化
- 重複除去パラメータの自動調整
- 自動配合最適化
- 小規模モデルでの予備実験
- ベイズ最適化による比率探索
- 強化学習を用いたカリキュラム設計
- 継続的改善
- 本番モデルの性能フィードバック
- データパイプラインの自動更新
- A/Bテストによる効果検証
ただし、これらの多くはまだ研究段階か、限定的な環境での実験に近いものです。
5.3 自動配合最適化の研究動向
自動配合の研究としては、いくつか注目されている流れがあります。ただし、ここも「すでに業界標準」とまでは言いにくく、研究成果として追うのが妥当です。
DoReMi(Google, 2023)
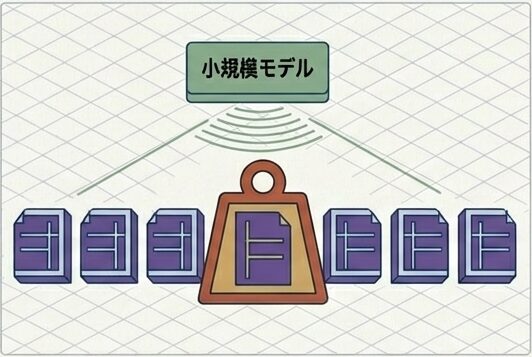
- 小規模モデルで各ドメインの「難しさ」を推定する
- 難しいドメインのデータを重点的にサンプリングする
- 配合比率を自動的に調整する
報告上は、手動配合より高い性能が得られる可能性が示されていますが、適用条件や再現性は個別に見ていく必要があります。
D4(Meta, 2024予想)
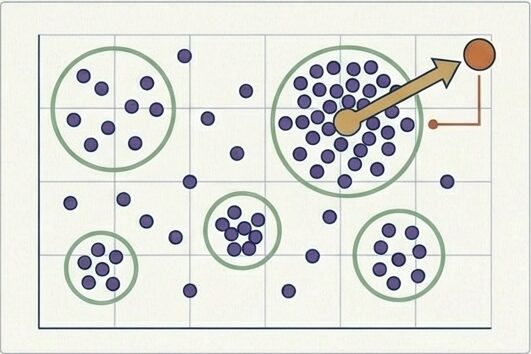
- データセットの多様性を自動測定する
- クラスタリングで冗長性を減らす
- 最適配合比率を探索する
ただし、これは現時点では将来の方向性として扱うのが安全です。期待される効果としては、同じ計算予算でより高い性能を目指しやすくなることや、データキュレーションの人手を減らせることが挙げられます。
6. 継続学習との統合
6.1 Pre-trainingとContinual Learningの接続
ブレンディングは、事前学習だけの話ではありません。継続学習まで含めると、データ配合の考え方はさらに重要になります。
従来のパイプライン
- Pre-training → Fine-tuning → デプロイ → 終了
継続学習パイプライン
- Pre-training → Fine-tuning → デプロイ
- その後、新規データを取り込みながら継続学習し、再デプロイする
6.2 継続学習でのデータブレンディング
継続学習では、Catastrophic Forgetting、いわゆる破滅的忘却が大きな課題になります。
課題
- 新しいデータで訓練すると、過去の知識を忘れてしまうことがある
対策としてのリプレイ
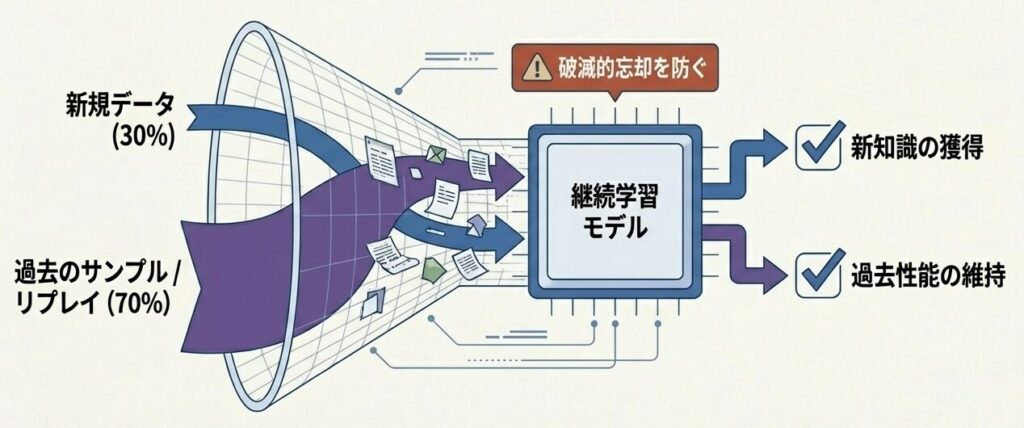
- 新規データと過去データのサンプルを混合する
- たとえば、新規データ30%、過去データ70%のような配合が考えられる
効果
- 新しい知識を取り込みつつ
- 過去の性能を維持しやすくなる
6.3 実運用での考慮事項
継続学習を実運用へ持ち込むと、配合だけでなく運用設計そのものが問われます。
- データの鮮度管理
- 古いデータの陳腐化にどう対応するか?
- 新しいデータの品質をどう保証するか?
- 計算リソースの制約
- 完全再訓練は現実的でないことが多い
- 効率的な更新手法が必要になる
- 評価の継続性
- 性能低下を早期に検出する仕組みが必要
- バージョン管理も重要になる
7. まとめと推奨事項
7.1 実践者向けチェックリスト
データストラテジストのための意思決定ツリーと実践チェックリスト
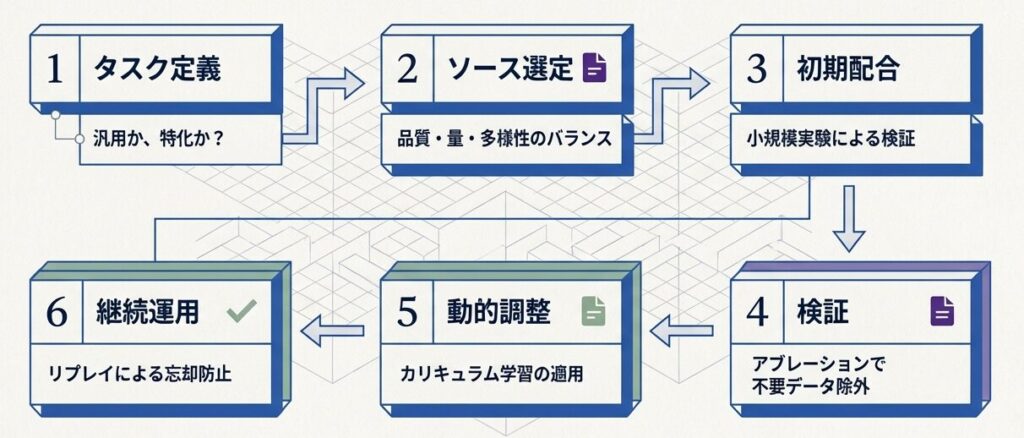
-
目標タスクを明確化したか?
- 汎用モデルか、ドメイン特化か?
- 重視するベンチマークは何か?
-
データソースを適切に選定したか?
- 各ソースの特性を理解しているか?
- 品質、量、多様性のバランスが取れているか?
-
配合比率を決めたか?
- 初期は推奨比率を参考にしたか?
- 小規模実験で検証したか?
-
アブレーション実験を検討したか?
- 各ソースの貢献度を定量化できるか?
- 不要なソースを除外できるか?
-
段階的配合を検討したか?
- カリキュラム学習を適用するか?
- 訓練段階ごとに調整するか?
-
継続的改善の計画を立てたか?
- フィードバックループをどう設計するか?
- 将来の更新にどう備えるか?
7.2 今後の展望
今後の展望としては、いくつかの方向性が見えています。ただし、ここで挙げるものは確定した未来像というより、今の研究・実務の流れから見た有力候補です。
静的な「錬金術」から、自律的な「産業化学」へ
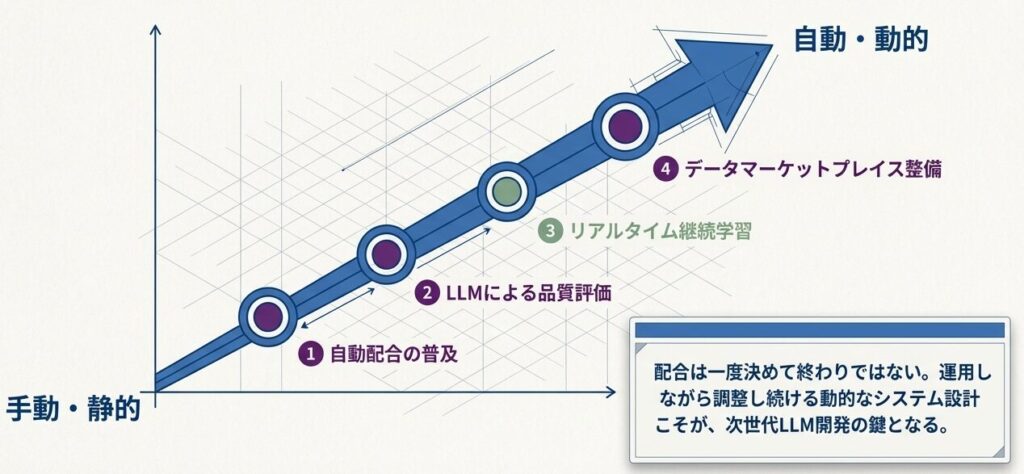
- 自動配合最適化の普及
- DoReMiのような考え方が広がる可能性がある
- ただし、完全に手動調整が不要になるとはまだ言い切れない
- 継続学習の成熟
- より効率的な更新手法が整っていく可能性がある
- リアルタイムに近いデータ統合も一部で進むかもしれない
- 品質評価の自動化
- LLMによるLLM評価はさらに進む見込みがある
- ただし、人間評価との整合は引き続き重要になる
- データマーケットプレイスの整備
- 高品質データの流通が進む可能性がある
- ライセンスや権利処理の標準化が焦点になりそうである
8. 今回のブログの考察
データブレンディングは、単にデータを混ぜる作業ではなく、どの能力をどの比率で育てるかを設計する工程だと分かります。今回のブログで見たように、Web、書籍、論文、コード、Q&A はそれぞれ役割が異なり、配合次第でモデルの性格が大きく変わります。さらに、アブレーション実験で効きを確かめ、カリキュラム学習や継続学習とつなげていくと、配合は一度決めて終わりではなく、運用しながら調整する対象になります。実務では、自動化の可能性を見据えつつも、まずは少数の高品質な組み合わせから始め、性能とコストの釣り合いを確認する姿勢が最も堅実です。
📖 参考文献
主要論文
-
Gao, L., et al. (2020): “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, arXiv
-
Touvron, H., et al. (2023): “LLaMA 2: Open Foundation and Fine-Tuned Chat Models”, arXiv
-
Penedo, G., et al. (2023): “The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only”, arXiv
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しました。
このシリーズの記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略(この記事)
次のシリーズ:
- ブログD:詳細設計書編 – 評価体系とベンチマーク設計
関連シリーズ:
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: 特化データセット戦略とドメイン最適化 次のシリーズへ: ブログD:詳細設計書編


コメント