
前回の C2 では、限られた計算予算の中で、モデルサイズと学習トークン数をどう配分するかを整理しました。C3 では、その配分を実際に支える「データセット戦略」に焦点を当てます。
計算予算が決まっても、学習させるデータが足りなければ計画は成立しません。逆に、データ量だけを増やしても、品質が伴わなければ学習効率は上がりません。この記事では、どの規模のデータを目標にすべきか、品質と量のどちらを優先すべきか、足りないときにどう補うかを、実務で判断しやすい順番で整理します。
1. なぜ C3 でデータセット戦略を扱うのか?
C2の理論は強力ですが、実務では次の問いが先に来ます。
- その計算予算で、実際に何トークン学習できるのか?
- 高品質データが足りないとき、どう補えばよいのか?
- 研究用途と商用用途で、同じデータ戦略が正解なのか?
この章の役割は、理論を否定することではなく、理論をデータという実体へ接続することです。
言い換えると、C2 で得た D ≈ 20N をそのまま覚えるだけでは不十分です。実際の現場では、月ごとの予算、実効 GPU 稼働率、そして何より「使えるデータがどれだけあるか」を含めて判断しないと、最初の見積もりがすぐに古くなります。
2. D_opt はどう決めるのか?
まずは最適データ規模 D_opt を、実務で再利用できる形で見積もります。
$$ D_{opt} = 20 \times N $$
これは Chinchilla 則をそのまま使った初期案です。たとえば N = 1B なら D_opt = 20B トークン、N = 70B なら D_opt = 1.4T トークンが目安になります。
def estimate_optimal_tokens(n_params, ratio=20):
return ratio * n_params
# 例1: 1B パラメータ
n = 1e9
d_opt = estimate_optimal_tokens(n)
print(f"N={n/1e9:.0f}B の場合、D={d_opt/1e9:.0f}B トークン必要")
# 例2: 70B パラメータ
n = 70e9
d_opt = estimate_optimal_tokens(n)
print(f"N={n/1e9:.0f}B の場合、D={d_opt/1e12:.1f}T トークン必要")
# 例3: 推論コストも考慮したバランス案
n = 1e9
d_balanced = estimate_optimal_tokens(n, ratio=10)
print(f"推論コスト考慮時: D={d_balanced/1e9:.0f}B トークン")この値を最終値ではなく、比較の出発点として扱うのが大切です。データ品質や用途が変われば、必要なトークン数は動きます。
3. 実在データセットをどう比較するのか?
データ戦略の難しさは、「何を集めるか」より「何を比較軸にするか」にあります。代表的なデータセットを、サイズ、言語、ドメイン、品質の観点で見ると整理しやすくなります。
| データセット | トークン数 | 言語 | ドメイン | 公開状況 | 品質スコア |
|---|---|---|---|---|---|
| C4 | 約156〜200B(トークナイザ依存) | 英語(mC4は多言語) | 一般Web | ✅ | 中 |
| The Pile | 約300B | 英語中心 | 学術 + Web + コード等 | ✅ | 中〜高 |
| FineWeb | 約15〜18.5T | 英語のみ | 一般Web | ✅(Hugging Face) | 高 |
| FineWeb2 | 多言語版(1000言語以上) | 多言語 | 一般Web | ✅ | 高 |
| Dolma | 約3T+ | 英語中心 | 学術 + Web | ✅ | 中〜高 |
| SlimPajama | 約627B | 英語 | Web + Code | ✅ | 中 |
品質スコアは、単に「良い・悪い」を示すものではありません。ノイズ量、重複率、言語品質、キュレーションの丁寧さを、実務上の判断に落とし込むための目安です。
from dataclasses import dataclass
@dataclass
class DatasetProfile:
name: str
tokens: float
language: str
domain: str
quality_score: int
datasets = [
DatasetProfile("C4", 200e9, "多言語", "一般 Web", 60),
DatasetProfile("FineWeb", 20e12, "多言語", "一般 Web", 85),
]
for ds in datasets:
print(ds.name, ds.quality_score)この表とコードで見たいのは、データセット名ではなく、「自分の用途に近いのはどれか」です。モデルの種類が違えば、必要なデータの質も量も変わります。
4. データ品質と規模はどうトレードオフするのか?
ここで重要なのは、トークン数が多ければ良いわけではない、という現場感です。高品質データは少なくても効きやすく、低品質データは大量にあっても伸びにくい傾向があります。
| 品質スコア | サイズ効果 | 推奨 D/N 比 | 性能の目安 |
|---|---|---|---|
| 低 (< 40%) | 大量必要(1.5-2 倍) | 30-40x | 基礎的 |
| 中 (40-70%) | 標準 | 20x | 実用的 |
| 高 (> 70%) | 効率的(0.8-1 倍) | 15x | 優秀 |
データ品質が低い場合は、同じ性能に届くまでにより多くのトークンが必要になると考えられます。逆に、品質が高ければ、必要量を少し減らしても性能を保ちやすいです。
def adjusted_token_budget(base_tokens, quality_score):
if quality_score < 40:
return base_tokens * 1.8
if quality_score < 70:
return base_tokens * 1.0
return base_tokens * 0.85
print(adjusted_token_budget(20e9, 35)) # 低品質なら必要量が増える
print(adjusted_token_budget(20e9, 80)) # 高品質なら少し減らせる推奨戦略としては、まず高品質データで土台を作り、足りない部分を中品質で補う流れが扱いやすいです。量を増やす前に、品質を上げられないかを確認したほうが失敗しにくいです。
5. データ不足時にどう補うのか?
実務では、理想的な規模のデータが最初から揃うことは多くありません。そこで必要になるのが、複数データセットの合成、合成データの補完利用、キュレーション、カリキュラム学習です。
5-1. 複数データセットを合成する
足りない分を、複数の公開データセットで補う方法です。最も扱いやすく、最初に検討しやすい手段です。
datasets = {
"C4": 5e9,
"The Pile": 7e9,
"FineWeb": 8e9,
}
total_tokens = sum(datasets.values())
print(f"合計: {total_tokens/1e9:.0f}B トークン")5-2. 合成データを使う
合成データは便利ですが、使いすぎると元データの分布から離れるリスクがあります。補完用として使うなら有効ですが、全体の大半を置き換えるのは慎重に考えるべきです。
5-3. キュレーションで品質を上げる
量が足りないなら、まず既存データの質を上げるのが実務的です。重複除去、ノイズ除去、最小文字数フィルタのような基本処理でも、効き目はかなり変わります。
def is_high_quality_document(doc):
if len(doc) < 100:
return False
special_ratio = sum(1 for c in doc if not c.isalnum() and c != " ") / len(doc)
if special_ratio > 0.3:
return False
if check_similarity_with_existing(doc) > 0.8:
return False
return True5-4. 学習順序を工夫する
カリキュラム学習は、簡単な例から複雑な例へ進める方法です。データを増やせないときでも、学習の順序を工夫することで効率が上がる場合があります。
# カリキュラム学習:コンテキスト長を段階的に拡張する例
# 短いコンテキストで効率よく基礎言語能力を学習した後、長文に対応させる
curriculum_stages = [
{"context_length": 2048, "tokens": 1.0e12},
{"context_length": 8192, "tokens": 0.2e12},
{"context_length": 32768, "tokens": 0.05e12},
]
for stage in curriculum_stages:
model.set_max_position_embeddings(stage["context_length"])
model.train(dataset=target_dataset, train_tokens=stage["tokens"])5-5. 日本語・多言語 LLM の場合はどう補うのか
ここまでの議論は、英語データが潤沢にあることを前提にしています。しかし FineWeb(約15兆トークン)は英語専用データセットであり、多言語版は「FineWeb2」という別データセットとして提供されています。日本語 LLM を作る場合、この「英語前提の相場観」をそのまま適用すると、データ量を過大評価してしまいます。
日本語データで代表的なものには、以下があります。
| データセット | 概算トークン数 | 特徴 |
|---|---|---|
| CC-100 (ja) | ~100B | CommonCrawl から言語判定で抽出、ノイズはやや多め |
| Japanese CommonCrawl (mC4/ja 等) | ~100-200B | 多言語コーパスの日本語サブセット |
| Swallow Corpus | ~600B+ | 東工大が公開、日本語特化でクリーニング済み |
| llm-jp-corpus | ~数百B | LLM-jp プロジェクトが公開、複数ソースを統合 |
英語データに比べると一桁少ないため、D_opt = 20N をそのまま適用すると、日本語だけで学習を完結させるのは中規模モデル(数B〜数十B)が現実的な上限になりやすいです。実務での対応策は主に3つです。
- 英語+日本語の混合学習:英語データで一般的な言語能力を学び、日本語データで言語特化させる(Swallow など多くの日本語継続事前学習モデルがこの手法を採用)。
- 翻訳データの活用:英語の高品質データを日本語に機械翻訳して補う(品質劣化に注意)。
- 合成データの比重を上げる:5-2 で触れた合成データは、絶対量が少ない言語ほど「補完」ではなく「主力」になりやすい。
多言語 LLM を検討する読者は、表2の「言語」列を鵜呑みにせず、まず自分が対象とする言語のデータ量を先に確認することが出発点になります。
この章で大事なのは、「足りないから終わり」ではなく、「質を上げるか、組み合わせるか、順序を変えるか」という選択肢を持つことです。
6. 組織別にどんなデータ戦略を取るべきか?
集められるデータ量も、整備できるコストも、組織規模でかなり違います。だからこそ、戦略は一律ではありません。
| 組織タイプ | 推奨データセット | サイズ | D/N 比 | コスト |
|---|---|---|---|---|
| 研究室・スタートアップ | C4 + The Pile | ~10B | 10-20x | $0 |
| ベンチャー | FineWeb (抽出) | ~50-100B | 10-20x | $1k |
| 中堅企業 | FineWeb + Dolma | ~200B+ | 20x | $5k |
| 大企業 | カスタムデータセット | ~1T+ | 100-1000x+ | Overtraining(推論コスト削減とドメイン特化) |
組織規模が小さいほど、公開データの組み合わせとキュレーションが中心になります。規模が大きくなるほど、独自データの価値が増えますが、その分、管理コストも上がります。
def choose_dataset_strategy(org_size, domain_strength):
if org_size == "small":
return "public mix + curation"
if org_size == "medium":
return "public mix + extracted domain data"
if domain_strength == "strong":
return "custom dataset + curation pipeline"
return "public mix + domain supplement"この考え方は、モデルの性能だけではなく、運用できるかどうかまで含めて見るためのものです。自前データが多い組織ほど強い一方で、整備しきれないと逆に品質が不安定になります。
7. 実務で起きやすい失敗は何か?
データ戦略でよくある失敗は、次の 3 つです。
- トークン数だけで判断する
- 品質確認を後回しにする
- 目標を固定しすぎて、用途の違いを見落とす
特に多いのは、「見た目のデータ量は十分なのに伸びない」ケースです。これは、重複やノイズ、偏りが原因で、実質的な学習量が足りていないことが多いです。
また、推論向けに偏ったデータを入れすぎると、一般的な理解力や柔軟性が落ちる場合があります。どの用途を優先するのかは、学習前に決めておいたほうがよいです。
8. 次に進む前に何を確認すべきなのか?
本番計画に進む前に、少なくとも次を確認したほうがよいです。
- 目標は事前学習損失か、下流タスク性能か?
- 必要なデータ量だけでなく、データ品質を確認したか?
- モデルサイズを先に固定しすぎていないか?
- 推論コストを見積もったか?
- 小規模実験で
NとDの傾向を確認したか? - 評価セットが実運用に近いか?
- 再実験用の計算予算を残しているか?
ここで大切なのは、最適配分を一度で当てようとしないことです。小規模実験で傾向を見て、データ品質を直し、評価セットを調整し、もう一度見積もる。この反復がないと、理論上はきれいでも実務では外れやすくなります。
この確認は、学習を止めるためではありません。後戻りのコストが高い段階へ進む前に、見落としやすい前提を先に潰すためのものです。ここを通しておくと、次の C4 でアーキテクチャを選ぶときに、何を前提としてよいかが明確になります。
9. まとめ
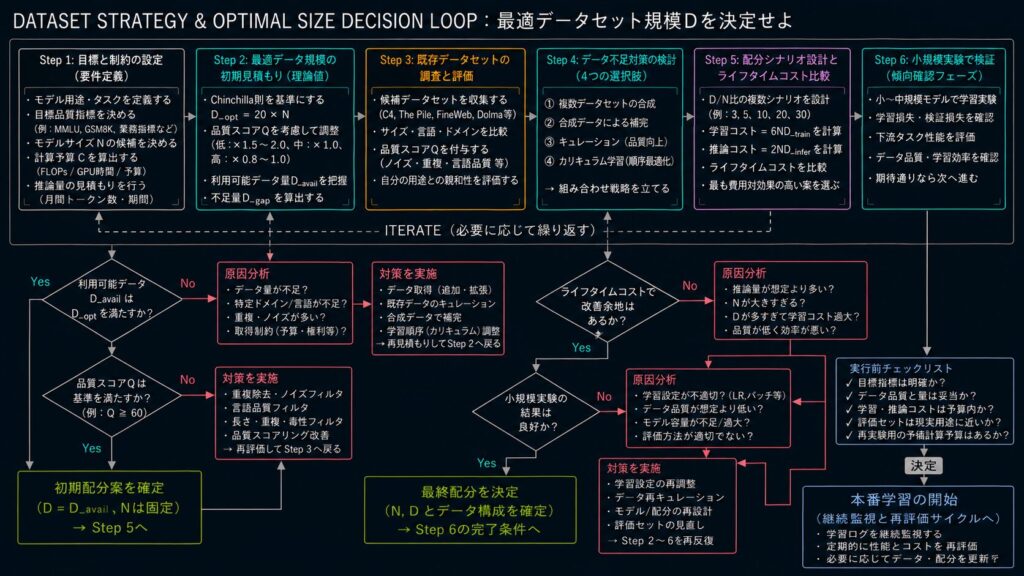
C3 が示した重要な教訓は、D_opt をそのまま当てはめるのではなく、データ品質、用途、組織規模を含めて配分を考えることです。同じトークン数でも、何を含んだデータかによって性能は大きく変わります。
今回の要点は次の通りです。
D_opt = 20Nは出発点として便利だが、絶対法則ではない- データセットは、名前よりもサイズ・品質・用途で比較するべきである
- 品質が高いデータは少なくても効きやすく、低品質データは大量に必要になりやすい
- データ不足時は、合成より先にキュレーションと重複除去を考える
- 組織規模によって、現実的なデータ戦略は変わる
最適なデータ戦略とは、たくさん集めることではありません。理論で必要量を見積もり、実際に使えるデータへ落とし込み、評価しながら補正していくことです。
10. 今回のブログの考察
C3 の本質は、データを「集めるもの」ではなく、「配分戦略を成立させる土台」として捉え直すことです。C2 で計算予算を決めても、その計算をどのデータに使うかが曖昧なままでは、配分戦略は完成しません。
この章で見たように、データ戦略は単なる収集作業ではなく、モデル性能と運用効率を左右する意思決定です。特に、品質の高いデータをどれだけ確保できるか、足りないときにどう補うかは、後続のアーキテクチャ選択やデプロイ戦略にもそのまま響きます。
次の C4 では、このデータ前提を受けて、どのアーキテクチャがその土台を最も活かせるのかを見ていきます。
参考文献
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.” DeepMind.
- Penedo, G., et al. (2024). “The FineWeb Datasets.” HuggingFace.

コメント