
前回までは、推論時スケーリング、KV キャッシュ、量子化、数値安定性など、個別の最適化手法を見てきました。どれも重要ですが、実務で最後に問題になるのは「どの順番で、どこまで大きくし、いつ止めるのか?」です。
大規模モデル開発では、モデルサイズ、データ量、学習計算量、推論コストを同時に増やせば、たしかに性能は伸びやすくなります。しかし、現実には予算、GPU 在庫、データ品質、評価期間、運用担当者の負荷が制約になります。つまり、スケーリング則を知っているだけでは不十分で、それをどう運用判断に落とし込むかが問われます。
この記事では、スケーリング戦略を「大きくする技術」ではなく、「限られた計算予算をどこへ投資するかを決める運用設計」として整理します。段階的な実験計画、飽和検出、データ不足への対処、推論コストとのバランス、失敗しやすい意思決定まで、実務で使える判断軸に落とし込みます。
1. なぜスケーリング戦略が必要なのか?
スケール則を学ぶと、モデルを大きくし、データを増やし、計算量を増やせば損失が下がる、という見通しを持てます。この見通しは強力です。実験前に必要な計算量を概算でき、無謀な学習計画を避けやすくなるからです。
ただし、スケール則は「大きくすれば必ず事業上の成功につながる」とまでは言ってくれません。そこには別の判断が必要です。
たとえば、検証用の小規模モデルで損失がきれいに下がっていたとしても、本番規模に上げた途端に次の問題が起きることがあります。
- データ品質の低い部分が性能の足を引っ張る
- 学習は成功しても、推論コストがサービス要件に合わない
- 評価指標は改善したが、実ユーザーの体感品質は変わらない
- 学習ログ上は安定していても、特定ドメインで失敗が増える
つまり、スケーリング戦略とは「どれだけ大きくするか」だけではなく、「何を見ながら大きくするか」を決めることです。ここを曖昧にしたまま進めると、GPU 時間を使い切った後に、そもそも改善対象がずれていたと気づくことになります。
2. スケーリングで最初に決めるべきものは何か?
最初に決めるべきなのは、モデルサイズではありません。計算予算と成功条件です。
実務では、次の 4 つを先に置くと判断がぶれにくくなります。
| 観点 | 決める内容 | 例 |
|---|---|---|
| 計算予算 | 使える GPU 時間や金額 | 事前検証に全体予算の 10-20% を使う |
| 品質目標 | 何が改善すれば成功か | 正答率、要約品質、人手評価、業務完了率 |
| 運用制約 | 本番で許されるコスト | p95 レイテンシ、月額推論費、メモリ上限 |
| 中止条件 | どこで止めるか | 改善率が閾値を下回る、データ不足が顕在化する |
この中で特に重要なのは、中止条件です。多くの失敗は「始め方」ではなく「止め方」が決まっていないことから起きます。
計算予算からモデルサイズとトークン数の目安を置くなら、次のような小さな関数でも十分に初期検討に使えます。ここでは Chinchilla 則でよく使われる「データトークン数はパラメータ数のおよそ 20 倍」という関係を、かなり単純化して扱っています。
from dataclasses import dataclass
@dataclass
class ScalingPlan:
params_b: float
tokens_b: float
train_flops: float
def estimate_chinchilla_plan(train_flops: float) -> ScalingPlan:
# C ~= 6ND, D ~= 20N とすると、C ~= 120N^2
n_params = (train_flops / 120) ** 0.5
n_tokens = 20 * n_params
return ScalingPlan(
params_b=n_params / 1e9,
tokens_b=n_tokens / 1e9,
train_flops=train_flops,
)
plan = estimate_chinchilla_plan(train_flops=3.0e21)
print(plan)もちろん、この結果をそのまま採用するのは危険です。Chinchilla 則の 20 倍という目安は、主に学習計算量だけを見たときの compute-optimal な配分です。実際のサービスでは、学習後に大量の推論が発生します。そのため、近年の公開モデルや推論コストを考慮した研究では、推論単価を抑えるためにモデルを相対的に小さくし、Chinchilla 最適より多くのトークンで長く学習させる設計が報告されています。
たとえば Llama 3 系列では、8B や 70B といったモデルが約 15T トークン規模で事前学習されており、単純な 20 倍則を大きく超えるトークン数が使われています。したがって、上のコードは「最終的な正解」ではなく、「学習計算量だけに着目した最初の仮説」を置くためのものです。推論需要が大きいサービスでは、この仮説からさらに、推論コスト込みの最適点へ補正する必要があります。
たとえば、あるモデルを 2 倍、4 倍、8 倍と大きくしていくとします。毎回少しずつ性能が上がるなら、もっと大きくしたくなります。しかし、改善幅が小さくなり、推論コストだけが大きくなる局面では、追加投資の合理性を説明しにくくなります。
スケーリングは勢いで進めると止まりにくいと言えます。だからこそ、実験前に「ここまで改善しなければ次の規模へ進まない」と決めておく必要があります。
学習計算量だけの最適化ならChinchilla則(データ20倍)が目安。 しかし、推論需要が大きいサービスでは、推論単価を下げるため「小さく・長く」学習する補正が必要。
3. 段階的スケーリングはどう設計すべきなのか?
段階的スケーリングの基本は、小さな実験で傾向を確認し、その傾向が十分に信頼できる場合だけ次の規模へ進むことです。
いきなり本命サイズで学習するのは、成功すれば速いように見えます。しかし、失敗したときの原因切り分けが難しくなります。損失が伸びなかった理由が、モデルサイズ、データ品質、学習率、評価セットのどこにあるのかを分けて考えにくくなるからです。
現実的には、次のような順番が扱いやすいです。
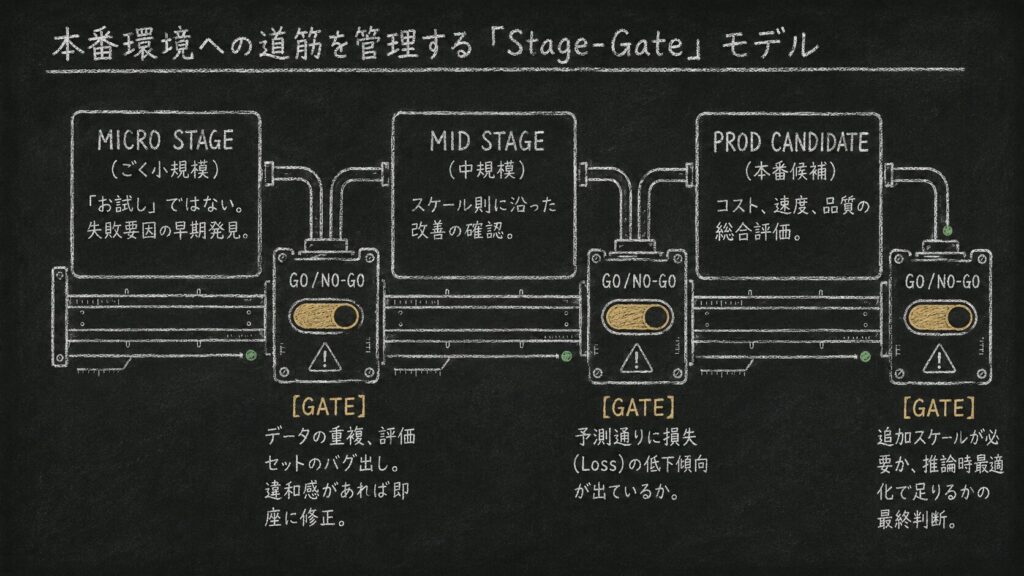
- ごく小規模なモデルでデータと評価の問題を洗い出す
- 中規模モデルでスケール則に沿った改善が出るか確認する
- 本番候補サイズでコスト、速度、品質を同時に評価する
- 追加スケールが必要か、推論時最適化で足りるかを判断する
このとき重要なのは、小規模実験を「お試し」と軽く見ないことです。小規模実験は、最終性能を当てるためだけではなく、失敗の種類を早く見つけるためにあります。
たとえば、データに重複が多い場合、小規模モデルでも検証損失の挙動に違和感が出ることがあります。評価セットが簡単すぎる場合も、小さいモデルの時点でスコアが頭打ちになります。こうした兆候を見逃して本番学習へ進むと、後から修正するコストが急に重くなります。
4. 計算予算はどこへ配分すべきなのか?
計算予算をすべて本番学習に投じるのは危険です。スケーリングの成否は、本番学習そのものだけでなく、事前検証、データ整備、評価、失敗時の再実験に左右されるからです。
目安としては、次のように分けて考えると実務に落とし込みやすいです。
| 用途 | 目的 | 予算配分の考え方 |
|---|---|---|
| 探索実験 | 傾向と失敗要因を見つける | 小さく複数回回す |
| データ検証 | 品質、重複、偏りを確認する | 学習前に必ず確保する |
| 本番候補学習 | 最終候補を作る | 十分な余力を残して実行する |
| 評価と再実験 | 品質回帰や設定ミスに対応する | 予備費として残す |
失敗談としてよくあるのは、学習本番に予算を寄せすぎて、評価や再実験の余力がなくなるケースです。学習が完走しても、結果が微妙だったときに「データを直してもう一度試す」余地がないと、原因が分からないまま終わります。
スケーリングでは、計算予算を「学習に使う燃料」と見るだけでは足りません。仮説を検証し、間違いを修正するための余白として扱う必要があります。
5. 飽和はどのように検出するべきなのか?
飽和とは、追加の計算やデータを投入しても、改善幅が小さくなる状態です。スケール則の文脈では、損失が滑らかに下がっていても、実務上は「この改善に追加費用を払う価値があるのか?」という問題になります。
飽和検出で見るべきなのは、単一のスコアではありません。最低でも次の 3 つを同時に見ます。
- 学習損失と検証損失の改善幅
- タスク別評価の改善幅
- 推論コストあたりの改善幅
たとえば、全体のベンチマークスコアは上がっているのに、実際に重要な業務タスクではほとんど改善していない場合があります。このとき「まだ損失が下がっているから続ける」と判断すると、事業上の価値が薄いスケールに投資してしまいます。
飽和を見つけるには、改善率を前回実験との差分で見るのが有効です。
| 実験 | 計算量 | 主要評価 | 前回からの改善 |
|---|---|---|---|
| A | 1x | 72.0 | – |
| B | 2x | 76.5 | +4.5 |
| C | 4x | 78.1 | +1.6 |
| D | 8x | 78.7 | +0.6 |
この例では、C から D への改善幅が小さくなっています。もちろん、重要な用途では +0.6 に大きな価値がある場合もあります。しかし、その判断は「スコアが上がったから」ではなく、「その改善がコストに見合うから」と説明できる必要があります。
この判断を毎回目視だけで行うと、人によって基準が揺れます。簡易的には、前回からの改善幅に対して、今回の改善幅がどれだけ残っているかを見る仕組みを入れておくと便利です。以下の例では、改善幅が前回の半分未満になったら飽和候補として扱います。
def detect_saturation(scores: list[float], gain_ratio_threshold: float = 0.5) -> bool:
if len(scores) < 3:
return False
previous_gain = scores[-2] - scores[-3]
latest_gain = scores[-1] - scores[-2]
if previous_gain <= 0:
return True
gain_ratio = latest_gain / previous_gain
return gain_ratio < gain_ratio_threshold
scores = [72.0, 76.5, 78.1, 78.7]
if detect_saturation(scores, gain_ratio_threshold=0.5):
print("追加スケールの前に、データ・評価・推論コストを再確認する")このコードはあくまで簡易判定です。実務では、全体スコアだけでなく、重要タスク別のスコアや推論単価も合わせて見ます。飽和検出は「止めるための自動判定」ではなく、「立ち止まって確認するためのアラート」として使うほうが現実的です。
損失が滑らかに下がっていても、コストに見合う見合う事業価値がなければ実務上は「飽和」である。1つでもレッドゾーンに入れば立ち止まることが必要。
6. データ不足はなぜスケーリングの壁になるのか?
モデルを大きくしても、データが足りなければ性能は伸びにくくなります。より正確に言えば、データ量だけでなく、データの多様性、品質、重複率、評価対象との一致度が効いてきます。
実務で厄介なのは、データ不足が単純な件数不足として現れないことです。たとえば、総トークン数は十分に見えても、特定ドメインのデータが薄い場合があります。カスタマーサポート向けモデルなら、一般的な Web テキストよりも、実際の問い合わせ、過去の対応履歴、製品仕様に近いデータのほうが効くかもしれません。
データ不足の兆候には、次のようなものがあります。
- モデルサイズを上げても特定タスクだけ改善しない
- 学習損失は下がるが、実運用に近い評価が伸びない
- 同じ種類の誤答が繰り返し出る
- ロングテールのユースケースで回答が一般論に戻る
ここでやるべきことは、すぐにモデルをさらに大きくすることではありません。まず、失敗しているタスクに対して、必要なデータが本当に含まれているかを確認することです。
これは地味ですが、かなり重要です。モデルサイズを増やすより、データの重複除去、低品質データの除外、ドメインデータの補強をしたほうが改善するケースは珍しくありません。断定はできませんが、特に業務特化型のモデルや RAG 前提のシステムでは、単純なパラメータ増加よりデータ設計のほうが効く場面が多いと考えられます。
近年のデータ戦略では、単に Web から大量に集めるだけでなく、品質フィルタリング、重複除去、合成データによる補強、モデルや分類器を使った品質スコアリングが重要になっています。特に合成データは、足りない形式のデータを補う手段として有効な場合がありますが、誤りや偏りを増幅するリスクもあります。そのため、合成データを使う場合も、実タスクに近い評価セットで効果を確認することが前提になります。
業務特化型モデルやRAG前提のシステムでは、単純なパラメータ増加よりもデータ設計が性能を支配する。
7. 学習時スケーリングと推論時スケーリングはどう使い分けるべきなのか?
B6 で扱ったように、推論時スケーリングは再学習なしで品質改善を狙える手段です。したがって、スケーリング戦略では「学習を大きくするか」「推論時に計算を増やすか」を比較する必要があります。
単純化すると、次のように考えられます。
| 状況 | 優先しやすい選択 |
|---|---|
| 幅広いタスクで基礎性能が不足している | 学習時スケーリング |
| 一部の推論タスクだけ精度を上げたい | 推論時スケーリング |
| レイテンシ制約が非常に厳しい | 学習側またはモデル圧縮 |
| 再学習予算がない | 推論時の工夫、プロンプト、RAG |
| 長期的に大量リクエストがある | 学習側改善で推論単価を下げる検討 |
たとえば、社内向けの分析支援ツールで、難しい質問だけ回答品質を上げたい場合は、全モデルを再学習するより、推論時に候補生成や再ランキングを入れるほうが現実的かもしれません。
一方で、毎日大量のリクエストを処理するサービスでは、推論時に毎回高コストな手順を追加すると運用費が膨らみます。この場合は、学習や蒸留、量子化、キャッシュ設計によって、1 リクエストあたりの単価を下げるほうが効く可能性があります。
重要なのは、学習時スケーリングと推論時スケーリングを対立させないこと。両者は目的が違う。学習時スケーリングはモデルの基礎能力を上げる投資であり、推論時スケーリングはタスクごとの使い方を調整する投資である。
8. 運用で失敗しやすいスケーリング判断は何か?
スケーリングの失敗は、技術的なバグだけで起きるわけではありません。むしろ、意思決定の前提が曖昧なまま進むことで起きます。
よくある失敗は次の 4 つです。
- 評価セットを固定しないまま規模を比較する
- 平均スコアだけを見て、重要タスクの劣化を見逃す
- 推論コストを後回しにして、本番で採算が合わなくなる
- データ品質の問題をモデルサイズで解決しようとする
特に危険なのは、評価セットの揺れです。モデル A とモデル B を比べているつもりでも、評価データや採点基準が変わっていれば、比較になりません。大きなモデルほど高価なので、比較条件の小さな揺れが大きな判断ミスにつながります。
もう一つの失敗は、「大きいモデルのほうが安全」という思い込みです。一般には大きなモデルほど性能が高い傾向がありますが、特定用途では、過剰な一般性が不要だったり、レイテンシやコストの悪化が致命的だったりします。実務では、最大モデルではなく、制約内で十分な品質を出すモデルが最適解になることが多いです。
9. 本番導入前に何を確認すべきなのか?
スケーリング実験で良い結果が出ても、そのまま本番導入してよいとは限りません。本番では、学習時には見えなかった制約が出ます。
最低限、次の観点は確認したいところです。
- 品質: 主要タスク、ロングテールタスク、失敗しやすいケースで評価したか?
- コスト: 1 リクエストあたりの推論費用を見積もったか?
- レイテンシ: p50 だけでなく p95 や p99 を見たか?
- 安定性: 長時間稼働、バッチ変動、入力長の変動で壊れないか?
- 監視: 品質劣化、遅延、エラー、異常出力を追えるか?
- ロールバック: 問題が出たときに前のモデルへ戻せるか?
ここで見落としやすいのは、品質監視です。レイテンシやエラー率は数値化しやすい一方で、回答品質の劣化は気づくのが遅れがちです。実運用では、サンプル監査、人手評価、ユーザーフィードバック、代表プロンプトの定期評価などを組み合わせる必要があります。
本番投入前のゲートをコードで表すと、次のような形になります。重要なのは、品質、レイテンシ、コストを同じ場所で判定することです。
def validate_release_gate(metrics: dict) -> None:
assert metrics["quality_drop"] <= 0.01, "quality regression is too large"
assert metrics["p95_latency_ms"] <= 1200, "p95 latency is too high"
assert metrics["cost_per_1k_requests"] <= 2.5, "inference cost is too high"
assert metrics["rollback_ready"] is True, "rollback path is not ready"
candidate_metrics = {
"quality_drop": 0.006,
"p95_latency_ms": 980,
"cost_per_1k_requests": 2.1,
"rollback_ready": True,
}
validate_release_gate(candidate_metrics)このようなチェックを入れておくと、「品質は上がったがコストが高すぎる」「速度は問題ないがロールバック手順がない」といった見落としを減らせます。スケーリング後の本番投入では、性能改善だけを合格条件にしないことが大切です。
モデルを大きくすると、性能だけでなく障害時の影響も大きくなります。だからこそ、スケーリング後の運用では「良くなったか」だけでなく、「悪くなったときに気づけるか」を設計しておくことが重要です。
10. まとめ
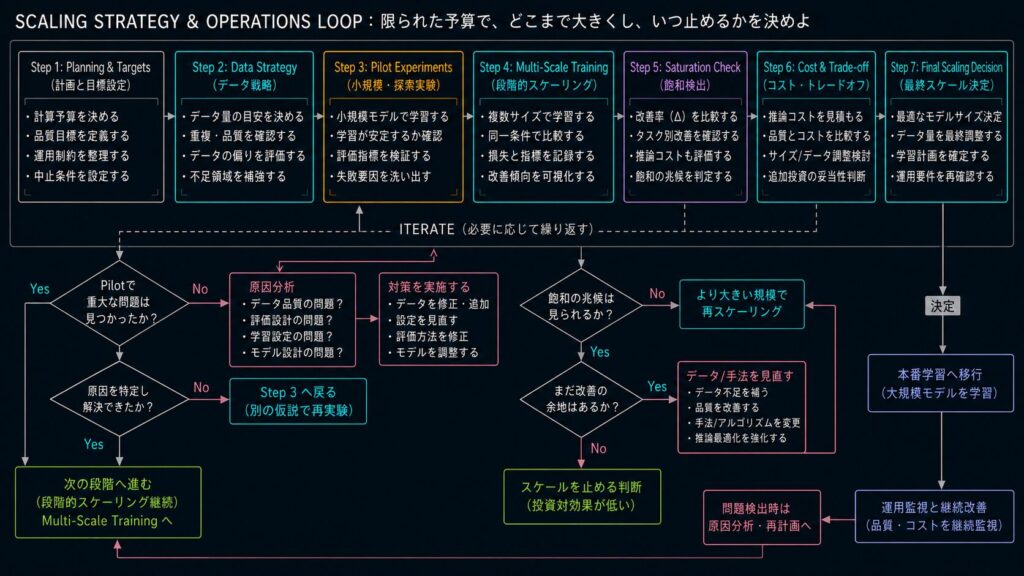
スケーリング戦略の本質は、モデルを大きくすることではありません。限られた計算予算を、モデル、データ、推論、評価、運用のどこへ配分するかを決めることです。
今回の内容を整理すると、重要な判断軸は次の通りです。
- 最初にモデルサイズではなく、計算予算と成功条件を決める
- 小規模実験は、最終性能の予測だけでなく失敗要因の発見に使う
- 飽和は損失だけでなく、タスク別品質と推論コストで見る
- データ不足は件数だけでなく、品質、多様性、ドメイン一致度で判断する
- 学習時スケーリングと推論時スケーリングを比較して投資先を決める
- 本番導入では、品質監視とロールバックまで含めて設計する
スケール則は、無駄な試行錯誤を減らすための強力な道具です。しかし、実務で価値を出すには、数式をそのまま信じるのではなく、評価、コスト、運用制約に接続する必要があります。
結局のところ、良いスケーリング戦略とは「大きくする勇気」と「止める判断」の両方を持つことです。伸びる見込みがあるところには計算を投じ、飽和やデータ不足が見えたら別の打ち手に切り替える。この切り替えを根拠を持って行えるかどうかが、大規模モデル開発の成否を分けます。
11. 今回のブログの考察
スケーリング則を学ぶと、どうしても「次はどれだけ大きなモデルを作れるか」に目が向きます。けれど、実務で本当に難しいのは、最大規模を狙うことではなく、限られた制約の中で納得できる判断を積み重ねることです。
特に印象的なのは、スケーリングの失敗が単なる技術不足ではなく、運用設計の不足として現れやすい点です。評価セットが揺れる、データ品質を見ない、推論単価を後回しにする、中止条件を決めない。こうした小さな曖昧さが、規模を大きくした瞬間に高価な失敗へ変わります。
一方で、段階的に進めればスケーリングはかなり扱いやすくなります。小さく試し、差分で見て、飽和を疑い、データを見直し、推論時の工夫も比較する。この順番を守るだけで、スケール則は単なる理論ではなく、現場の意思決定を支える道具になります。
大規模モデル開発において重要なのは、常に最大のモデルを選ぶことではありません。今の目的に対して、どの大きさが十分で、どこから先が過剰かを見極めることです。その判断を支えるのが、スケーリング戦略と運用上の考慮なのだと思います。
参考文献
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.”
- Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models.”
- Wei, J., et al. (2022). “Emergent Abilities of Large Language Models.”
- Sardana, N., et al. (2024). “Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws.”
- Grattafiori, A., et al. (2024). “The Llama 3 Herd of Models.”
- Su, D., et al. (2024). “Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset.”

コメント