
FLOPsと計算資源の理解:スケール則の定量的基盤
スケール則を実用的に使うには、「どれだけの計算資源を投じているのか」を正確に見積もる必要があります。ここを曖昧にしたまま進めると、モデル規模や学習トークン数の議論が感覚頼みになり、最終的なコスト見積もりもぶれやすくなります。
たとえば、同じ「高性能なGPUを使っている」という言い方でも、知りたいのは処理速度なのか? それとも学習全体に必要な総量なのか? で意味が変わります。FLOPs と FLOPS を混同すると、この前提がずれます。
この記事では、LLM の学習計画を立てるときに必要になる計算量の見方を、基礎から順番に整理します。対象は、スケール則を実装や予算に結びつけて理解したい人です。
1. この記事で学べること
- FLOPs(小文字)と FLOPS(大文字)の違い
- 計算量の公式 $C \approx 6ND$
- PF-days への単位変換
- 実際のモデル開発での計算量推定
1-1. 対象読者
- スケール則を実装に活用したいエンジニア
- 計算コストを見積もる必要がある PM
- LLM 開発の予算策定に関わる方
1-2. この話が重要になる場面
- モデル規模を上げるか、データ量を増やすか迷っている
- GPU の性能表示を見ても、学習期間のイメージが湧かない
- 研究論文の計算量を自分の環境に置き換えたい
このあたりに心当たりがあるなら、まず FLOPs と FLOPS の切り分けから確認すると理解しやすくなります。
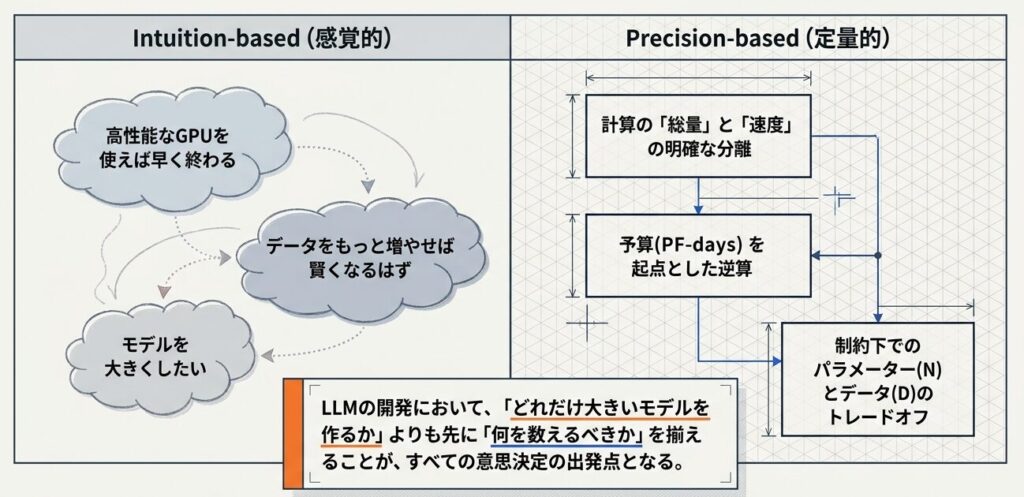
感覚的な議論から、精緻な定量設計へのシフト
2. FLOPs(小文字)vs FLOPS(大文字):混同しやすい2つの概念
LLM の文脈では、似た表記でありながら意味がまったく異なる指標が使われます。ここを取り違えると、学習に必要な計算量の見積もりと、ハードウェアの性能評価が混ざってしまいます。
| 項目 | FLOPs(小文字の s) | FLOPS(大文字の S) |
|---|---|---|
| 概念 | 必要な計算の「総量」 (Total Workload) |
ハードウェアの「処理速度」 (Processing Speed) |
| メタファー | 建設に必要なレンガの総数 | 1秒間に運べるレンガの数 |
| 役割 | 「どれだけ働く必要があるか」 | 「1秒にどれだけ働けるか」 |
| 用途 | 学習完了までの全体規模の見積もり | GPUやクラスタの性能評価 |
| 具体例 | GPT-3: $3.14 \times 10^{23}$ 回の基本演算 | H100: 1秒間に約990兆回(TFLOPS)の演算 |
2-1. FLOPs:必要な計算の「総量」
FLOPs(Floating Point Operations、小文字)は、計算を完了させるまでに必要な浮動小数点演算の総数です。
「浮動小数点演算」とは、加算や乗算のような基本計算の単位です。LLM の学習では、この基本計算を何十億回、何兆回という単位で繰り返します。
具体例:
- GPT-3の学習に必要な計算量(FLOPs): $3.14 \times 10^{23}$ FLOPs
- = 314 セプティリオン回の基本演算
- = 実運用では、かなり長時間の連続学習に相当する規模
2-2. FLOPS:ハードウェアの「処理速度」
FLOPS(Floating Point Operations Per Second、大文字の S)は、GPU などのハードウェアが 1 秒間に処理できる浮動小数点演算の数です。こちらは、機材そのものの「速さ」を表します。
具体例:
| GPU | 理論性能 |
|---|---|
| NVIDIA A100 | 約 312 TFLOPS |
| NVIDIA H100 | 約 990 TFLOPS |
| NVIDIA H200 | 約 1,979 TFLOPS |
言い換えると、FLOPs は「どれだけ働く必要があるか」、FLOPS は「1 秒にどれだけ働けるか」です。学習計画では、この 2 つを分けて考える必要があります。
「FLOPS」は機材そのものの速さを示す。しかし、学習の全貌を把握するには、この速さで「どれだけの期間」走り続ける必要があるのか(FLOPs)を知る必要がある
3. 計算量の公式:$C \approx 6ND$
LLM の学習に必要な総計算量 $C$ は、パラメータ数 $N$ とトークン数 $D$ から次のように概算できます。
$$C \approx 6 \times N \times D$$
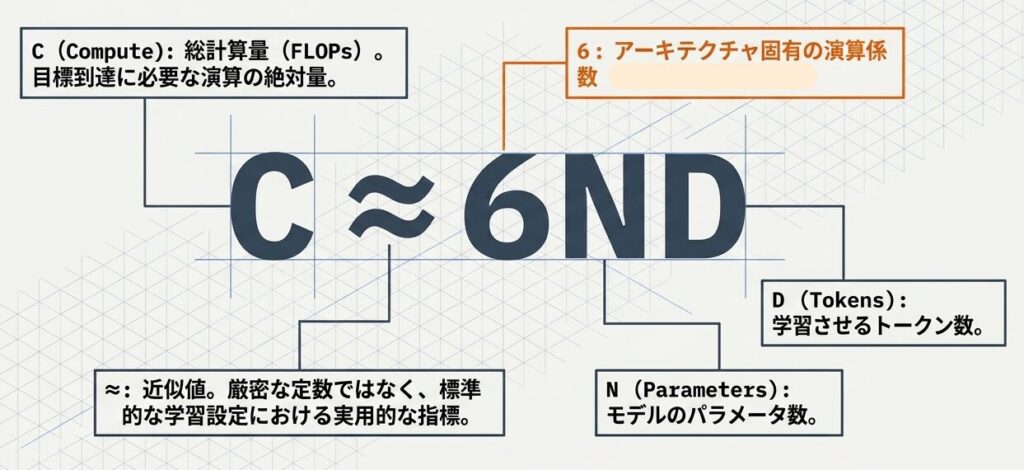
3-1. この「6」はどこから来るのか?
この係数は、Transformer の学習を大まかに分解したときの計算量の合計から来ています。厳密な定数ではなく、標準的な学習設定を置いた近似です。
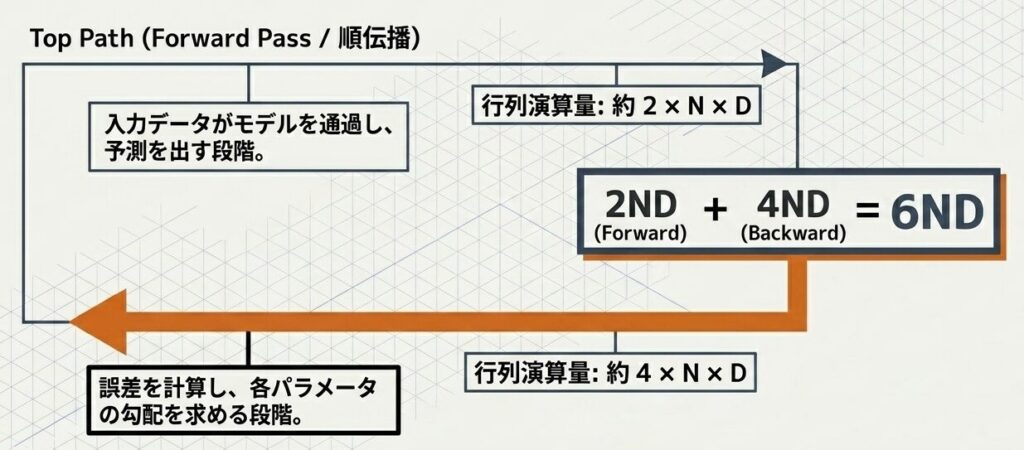
1. フォワードパス(順伝播)
- 入力データがモデルを通過して予測を出す段階で、各層に対する行列演算が発生します
- この段階で、ざっくり $N \times D \times 2$ 相当の計算が必要になります
2. バックワードパス(逆伝播)
- 誤差を計算し、各パラメータの勾配を求める段階では、さらに多くの計算が必要です
- この段階で、ざっくり $N \times D \times 4$ 相当の計算がかかります
3. 合計
- フォワードの 2 とバックワードの 4 を足して 6 になります
- そのため、$C \approx 6 \times N \times D$ と表せます
ここで大事なのは、この式が「万能の真理」ではないことです。モデル構造、最適化手法、実装の効率によって係数は前後します。ただし、学習規模をざっくり比較するには十分実用的です。
4. 計算量の単位:FLOPs から PF-days への変換
研究論文や開発報告では、計算量を FLOPs そのままで書く場合もあれば、PF-days に変える場合もあります。見た目の単位が違っても、意味は同じです。
4-1. 単位の定義
- PF = Petaflops(ペタフロップス)= $10^{15}$ FLOPS
- days = 1日の秒数(86,400秒)で計算
4-2. 変換公式
$$\text{PF-days} = \frac{\text{FLOPs}}{10^{15} \times 86400}$$
4-3. GPT-3 の計算量を PF-days で表すと
- FLOPs: $3.14 \times 10^{23}$
- PF-days: $\frac{3.14 \times 10^{23}}{10^{15} \times 86400} \approx 341$ PF-days
つまり、1 PFLOPS 相当の計算能力を持つ環境で 341 日分の計算を要する規模だと読めます。
ただし、これはあくまで換算です。実際には GPU の効率、並列化の仕方、通信オーバーヘッドによって、必要時間は上下します。単位変換だけで実運用時間が決まるわけではありません。
5. パラメータ数・トークン数から計算量を推定する実例
スケール則を実務に使うときは、モデルの大きさとデータ量から、どれくらいの計算資源が必要かを逆算します。
5-1. 事例: 新しい LLM を開発する場合
条件:
- 目標: パラメータ数 100 億(10B)のモデルを訓練したい
- 計算予算: 100 PF-days を利用可能
- 質問: 何トークン学習できるか?
計算:
まず、100 PF-days を FLOPs に変換: $$C = 100 \times 10^{15} \times 86400 = 8.64 \times 10^{21} \text{ FLOPs}$$
次に、トークン数を計算: $$D = \frac{C}{6N} = \frac{8.64 \times 10^{21}}{6 \times 10^{10}} = 1.44 \times 10^{11} \text{ tokens}$$
結果: 約 1440 億トークン(144B tokens)を学習できます。
5-2. 計算量・コスト早見表
| パラメータ数 | 学習トークン数 | 計算量(PF-days) | 推定コスト* |
|---|---|---|---|
| 1B | 20B | 1.4 | $1,000 |
| 7B | 140B | 68 | $50,000 |
| 13B | 260B | 234 | $170,000 |
| 70B | 1.4T | 6,790 | $5,000,000 |
クラウド GPU 単価に基づく概算
この表は、厳密な見積もりというより、規模感をつかむためのものです。実際のコストは、GPU の価格、並列効率、学習の失敗や再実行の有無で変わります。
6. スケール則を「実践的に」理解する
ここまでの内容を、実務でどう使うかに落とし込みます。
6-1. 計算量は測定可能である
$C \approx 6ND$ という式があるため、パラメータ数とトークン数から、学習に必要な計算量を見積もれます。
6-2. 計算量の単位を理解すると、リソース配分を決めやすくなる
例えば「1000 PF-days の計算予算がある」と分かれば、モデルを大きくするべきか、データを増やすべきかを比較できます。数字があるだけで、議論がかなり具体的になります。
Core Insight: 計算量の見積もりとは単なる算数でない。制約の中で「モデル規模」を取るか「データ量」を取るかという戦略的な投資配分そのものである。
6-3. スケール則の「線形性」とは、この計算量に対する線形性である
つまり、投入する計算量を増やしたとき、性能がどう変わるかを近似的に追える、ということです。ただし、ここも「増やせば必ず良くなる」と言い切る話ではありません。データ品質や学習設定が悪ければ、計算量を増やしても期待した改善は出ません。
6-4. つまずきやすい点
- FLOPS を FLOPs と読み違えると、速度と総量の議論が混ざる
- 係数 6 を絶対値だと誤解すると、過度に正確な見積もりをしてしまう
- PF-days を実行時間そのものと考えると、並列化や効率の差を見落とす
実務では、まず概算を作り、その後に実測で補正する流れが自然です。最初から完全な精度を狙うより、意思決定に使える精度を早く出すほうが役に立ちます。
リスク:PF-daysを「実際の実行時間」と同一視する。並列化の非効率性や 通オーバーヘッドにより、理論値と実測値には必ず 乖離が生じる。
7. まとめ
FLOPs は「どれだけ計算が必要か」、FLOPS は「どれだけ速く処理できるか」を表します。まずこの違いを分けておくと、学習計画の議論がずっと整理しやすくなります。
$C \approx 6ND$ は、LLM の学習計算量を考えるための実用的な近似式です。厳密さではなく、比較と見積もりに使う式だと捉えるのが安全です。
PF-days は、論文の数字を実際の計算資源の感覚に戻すための便利な単位です。モデル規模、データ量、GPU の処理速度を、同じ土俵で比較しやすくなります。
結局のところ、計算資源を理解する目的は、数字を暗記することではありません。限られた予算の中で、どこに投資すればよいかを判断できるようにすることです。
8. 今回のブログの考察
FLOPs と FLOPS の違い、$C \approx 6ND$ の近似式、PF-days への変換は、どれも単なる計算のための知識ではありません。この記事全体を通して見えてくるのは、LLM の学習計画では「どれだけ大きいモデルを作るか」よりも先に、「何を数えるべきか」を揃えることが重要だという点です。計算量の見方が曖昧なままだと、GPU の速さと学習全体の総量が混ざり、規模の議論がすぐに感覚論へ戻ってしまいます。
実務で大切なのは、式を正確に覚えることよりも、見積もりの粒度を揃えることだと考えられます。たとえば、まず FLOPs で全体量を見て、次に FLOPS で実行速度を見て、最後に PF-days で予算感に落とし込む。こうした順番で考えると、モデル規模やトークン数の議論が、初めて比較可能な形になります。逆に、最初から厳密な値を求めすぎると、係数の細部に気を取られて、判断そのものが遅れやすくなります。
つまり、このブログが伝えたかった本質は、計算資源を「後から読む数字」ではなく「最初に設計へ組み込む条件」として扱うことです。どれだけ計算できるかを先に把握できれば、モデルを大きくするのか、データを増やすのか、あるいは学習設定を見直すのかという判断が、かなり現実的になります。LLM 開発では、派手な最適化よりも、こうした地味な見積もりの精度が、結果を大きく左右すると言えます。
参考文献
- Kaplan, J. et al. (2020). “Scaling Laws for Neural Language Models.” arXiv:2001.08361
- Hoffmann, J. et al. (2022). “Training Compute-Optimal Large Language Models.” arXiv:2203.15556
このシリーズの案内
次の記事: A-3: スケール則の証拠と信頼性
前の記事: A-1: スケール則とは何か


コメント