
データ品質測定とモニタリング体制
LLM は、学習が終わった時点で完成するわけではありません。本番に出してから、どれだけ品質を保てるかで実用性が決まります。学習時には十分に見えたモデルでも、実運用に入ると入力分布の変化、知識の古さ、異常応答の増加によって、少しずつ使いにくくなることがあります。
本記事では、その変化を前提にした品質監視の考え方を整理します。何を監視対象にするべきか、どの頻度で確認するべきか、異常を見つけたあとにどう改善へつなげるかを、実務寄りに見ていきます。
1. なぜ本番監視が必要なのか
学習時の評価指標が高くても、本番で同じ性能が出るとは限りません。これはモデルの出来が悪いというより、実運用の条件が学習評価よりずっと揺らぎやすいからです。
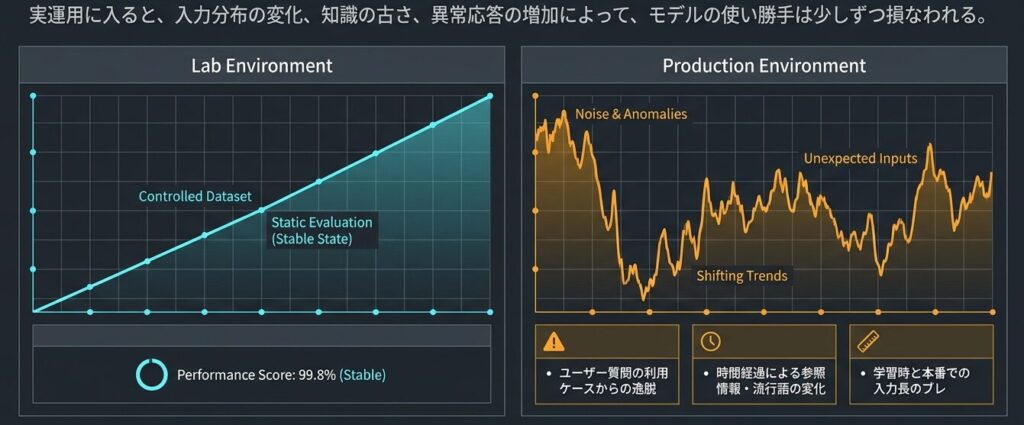
たとえば次のような変化は、現場でよく起こります。
- ユーザーの質問内容が、想定していた利用ケースから少しずつずれる
- 時間の経過とともに、参照すべき情報や流行語が変わる
- 入力の長さや形式が、学習時と本番で一致しない
- ある時点から、同じような誤答や繰り返し出力が増える
このとき重要なのは、「モデルが壊れた」と断定することではなく、何がどの方向に変わったのかを測ることです。監視がないと、問題が見えた時点ではすでにユーザー体験が大きく崩れていることがあります。
言い換えると、モニタリングの役割は、障害を検知することだけではありません。品質低下の兆候を早く捉え、軽いうちに手を打てるようにすることにあります。
「モデルが壊れた」のではなく「環境が変わった」ことを素早く測る仕組みが必要である。
2. 何を測るべきか
本番品質の監視は、1 つの指標だけで完結しません。少なくとも、出力の健全性、信頼性、経時変化の 3 つは分けて考えたほうが分かりやすいです。
| 観点 | 見るもの | 何が分かるか |
|---|---|---|
| 出力品質 | 確信度、エントロピー、繰り返し率、応答長 | 出力が不安定になっていないか |
| 信頼性 | 幻覚率、事実誤り率、矛盾回答率 | 答えの正しさと一貫性が保てているか |
| 経時変化 | 精度推移、F1、ドリフト量 | 本番分布の変化に追随できているか |
この分け方の利点は、異常の種類ごとに対応を変えやすいことです。たとえば繰り返し出力が増えているのと、幻覚率が上がっているのとでは、疑うべき原因が違います。
2.1 出力の多様性
出力の多様性が落ちると、モデルは同じ表現を繰り返したり、極端に短い応答に寄ったりします。これは、会話品質の低下として目に見えやすい症状です。
監視対象としては、次のようなものが使えます。
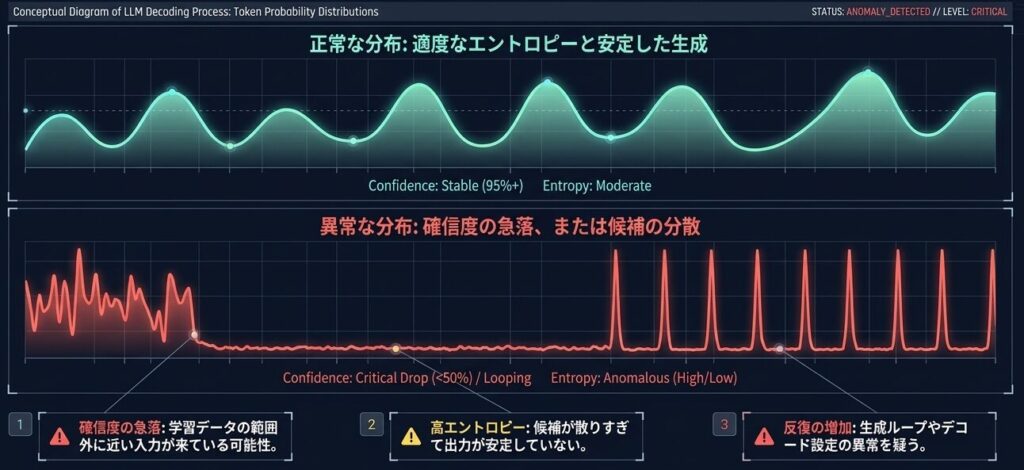
- 各タイムステップでの top-k トークンの確率分布
- 平均確信度(confidence)
- エントロピー
- 同一トークンの繰り返し回数
たとえば、確信度が急に下がるなら、学習データの範囲外に近い入力が来ている可能性があります。エントロピーが高すぎるなら、候補が散りすぎて出力が安定していないかもしれません。逆に、同じ語の繰り返しが増えるなら、生成ループやデコード設定の問題を疑う余地があります。
出力の不安定さは「確信度」と「エントロピー」に現れる
2.2 幻覚率
幻覚率は、「もっともらしいが事実ではない回答」がどれくらい混ざっているかを見る指標です。LLM を本番利用する際には、かなり重要になります。
幻覚の検出は単純ではありません。外部知識ベースとの照合や、文単位での確実性スコアの計算など、複数の手がかりを組み合わせる必要があります。
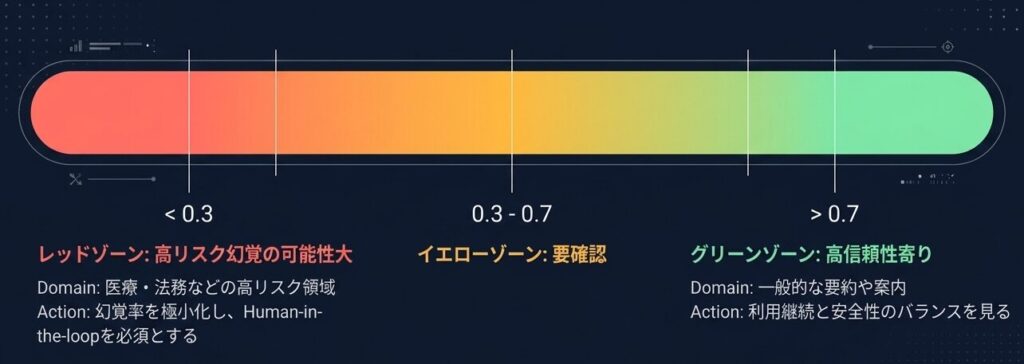
| スコア | 判定の目安 |
|---|---|
| 0.3 未満 | 高リスク幻覚の可能性が高い |
| 0.3 〜 0.7 | 要確認 |
| 0.7 超 | 高信頼性寄り |
目標値は業務領域によって変わります。医療や法務のような高リスク領域では、一般用途より厳しい基準が必要です。逆に、一般的な要約や案内であれば、リスクの見方も少し変わります。
| 領域 | 目標の考え方 |
|---|---|
| 医療 | かなり厳しく管理する |
| 一般用途 | 利用継続と安全性のバランスを見る |
| 高リスク領域 | 幻覚率を極小化し、人間確認を前提にする |
幻覚の検出は外部知識ベースとの照合や確実性スコアなど、複数の手がかりを組み合わせる必要がある。
2.3 コンセプトドリフト
コンセプトドリフトは、現実世界の分布が時間とともにずれていくことです。評価時点では十分だったモデルでも、数週間から数か月で性能が落ちることがあります。
たとえば、週次で評価したときに次のような推移が見えたとします。
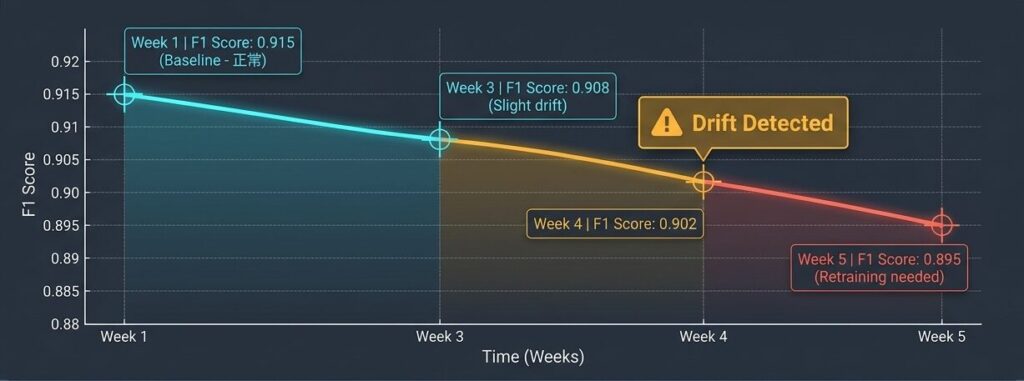
| week | accuracy | f1_score | note |
|---|---|---|---|
| 1 | 0.920 | 0.915 | baseline |
| 2 | 0.918 | 0.912 | stable |
| 3 | 0.915 | 0.908 | slight_drift |
| 4 | 0.910 | 0.902 | drift_detected |
| 5 | 0.905 | 0.895 | retraining_needed |
こうした推移は、1 回の異常値よりも厄介です。なぜなら、数週間かけて徐々に悪化するため気づきにくく、気づいたときには改善コストが大きくなっていることがあるからです。
3. どう監視体制を組むか
監視は、リアルタイムで回すものと、定期的に深掘りするものを分けて設計すると運用しやすくなります。全部をリアルタイム化するとコストが重くなりますし、逆に定期評価だけだと異常の初動が遅れます。
3.1 4 層で考える
| 層 | 主な役割 | 頻度 |
|---|---|---|
| Layer 1: 自動監視 | 確信度、繰り返し、異常応答の監視 | 常時 |
| Layer 2: 週次評価 | テストセットでの性能測定、ドリフト確認 | 週 1 回 |
| Layer 3: 月次分析 | エラーケース、バイアス、フィードバックの確認 | 月 1 回 |
| Layer 4: 四半期レビュー | トレンド確認、再学習判断、方針見直し | 四半期ごと |
この構造にしておくと、日々の監視と中長期の見直しを混同しにくくなります。リアルタイム監視で拾い切れない論点は、週次・月次・四半期で補う、という設計です。
各層の監視結果は上位層へ集約され、戦略的な意思決定とリソース配分の基盤となる。
3.2 チェックリストの作り方
監視項目は、最初から 25 個も揃える必要はありません。むしろ、最初は少数のコア指標に絞ったほうが運用しやすいです。
たとえば、初期セットとしては次の 6 つでも十分です。
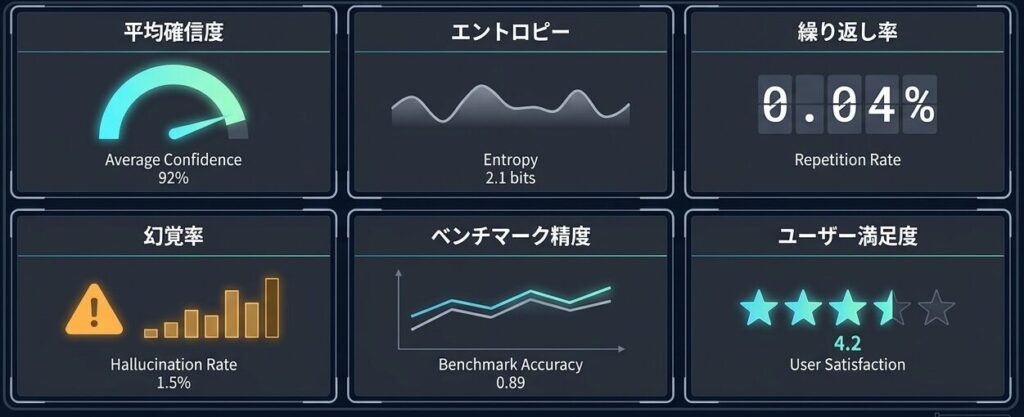
- 平均確信度
- エントロピー
- 繰り返し率
- 幻覚率
- ベンチマーク精度
- ユーザー満足度
ここで大事なのは、指標を増やすこと自体ではなく、異常の種類と対応責任者が紐づいていることです。指標が多すぎると、アラートが増えても誰も見なくなります。
最初から25個の指標は不要。重要なのは、指標の数よりも異常時に対応する『責任者」が紐づいていることである。
4. 実装はどう始めるか
理屈だけでは運用できないので、最低限の実装例も押さえておきます。ここでは、リアルタイム監視と週次評価の 2 段階を例にします。
4.1 リアルタイム監視の最小例
import numpy as np
def detect_repetition(tokens, window=5):
"""トークン繰り返しの検出"""
for i in range(len(tokens) - window):
pattern = tokens[i:i + window]
count = 0
for j in range(i + window, len(tokens) - window + 1):
if tokens[j:j + window] == pattern:
count += 1
if count > 2:
return count
return 0
def monitor_output(output_tokens, confidences, probs):
"""リアルタイム出力監視"""
avg_conf = np.mean(confidences)
entropy = -np.sum(probs * np.log(probs + 1e-10))
repeated = detect_repetition(output_tokens)
alerts = []
if avg_conf < 0.3:
alerts.append("low_confidence")
if entropy > 8.0:
alerts.append("high_entropy")
if repeated > 10:
alerts.append("repetition_loop")
return {
"avg_confidence": avg_conf,
"entropy": entropy,
"repetition_count": repeated,
"alerts": alerts,
}この例のポイントは、複雑な仕組みを最初から入れず、異常の兆候を 3 つに絞っていることです。いきなり高度な異常検知を入れるより、まずは「どんなときに危険信号を出すか」を明示したほうが改善しやすくなります。
4.2 週次評価の最小例
from datetime import datetime
def weekly_eval(model, test_set, history):
"""週次性能評価"""
results = evaluate_on_test_set(model, test_set)
history.append({
"week": len(history) + 1,
"accuracy": results["accuracy"],
"f1_score": results["f1"],
"timestamp": datetime.now(),
})
if len(history) >= 2:
drift = history[-2]["accuracy"] - results["accuracy"]
if drift > 0.03:
alert("CONCEPT_DRIFT_DETECTED", drift)
if drift > 0.05:
alert("RETRAINING_NEEDED", drift, priority="high")
return results
def alert(alert_type, value=None, priority="normal"):
"""アラート発行"""
message = f"[{priority.upper()}] {alert_type}"
if value is not None:
message += f": {value:.3f}"
send_notification(message, priority)ここでは、前回値との差分を見てドリフトを検知しています。絶対値だけを見るより、変化率を見るほうが本番環境では役立つことが多いです。
5. どう改善サイクルにつなげるか
監視は、異常を見つけて終わりではありません。異常を見つけたあとに、どのくらいの深刻度で、どの頻度で、何を変えるかまで決めておく必要があります。
5.1 PDCA に落とす
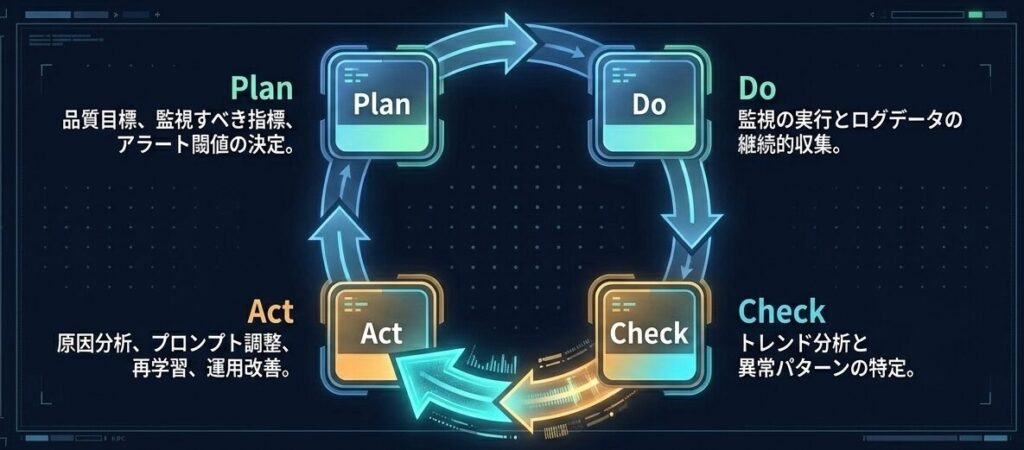
| フェーズ | やること |
|---|---|
| Plan | 品質目標、指標、閾値を決める |
| Do | 監視とログ収集を運用する |
| Check | トレンドと異常を分析する |
| Act | 原因分析、再学習、運用改善を行う |
この流れにすると、監視が単なるログ収集で終わりません。指標の変化を、実際の改善アクションにつなげやすくなります。
監視システムはアラームではなく、LLMを現実世界に適応させるためのエンジンとして機能しなければならない。
5.2 どの程度で動くか
対応の重さは、問題の大きさによって変えるのが現実的です。
| 深刻度 | 例 | 対応 |
|---|---|---|
| 軽微 | 単発の異常応答、一時的な低下 | ログ記録、監視強化 |
| 中程度 | 3% 以上の性能低下、特定ドメインの劣化 | 原因分析、プロンプトや軽微な微調整 |
| 大規模 | 5% 以上の低下、複数ドメインでの問題、安全性問題 | 再学習、データ見直し、設計変更の検討 |
ここでの数値は、あくまで出発点です。領域によって閾値は変えるべきで、医療や法務のような高リスク用途では、もっと厳しい判断が必要になるはずです。
6. ユーザーフィードバックをどう使うか
本番監視で見落としやすいのが、ユーザーの生の反応です。内部指標だけ見ていると、数字上は安定していても、実際の満足度が落ちていることがあります。
6.1 収集するもの
- 明示的フィードバック: 👍/👎、星評価、コメント
- 暗黙的フィードバック: 再生成率、修正率、中断率
- サポート経由の声: 問い合わせ、クレーム、改善要望
6.2 分析の流れ
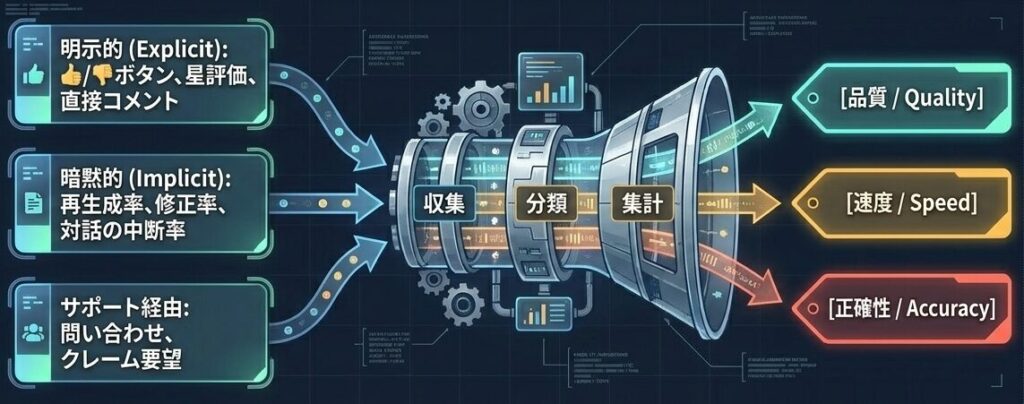
- 収集する
- 分類する
- 集計する
- 改善アクションに落とす
この流れの大事な点は、感想をそのまま並べるのではなく、品質、速度、正確性などに分けて扱うことです。分類できないフィードバックは、改善の優先順位を決めにくいからです。
感想をそのまま並べるのではなく、分類タグ付けを行うことで初めて改善の優先順位が決定できる。
7. 安全性と倫理性も監視対象に含める
品質監視は、単なる精度の話ではありません。バイアスや有害出力を見逃すと、数値上は良く見えても実運用では危険になります。
7.1 バイアス検出
同じ質問を属性だけ変えて投げ、回答差を比較する方法は、比較的わかりやすい入り口です。性別、人種、年齢、政治的傾向などの偏りを、統計的に見ていく発想です。
7.2 有害出力の監視
暴力的表現、差別的表現、個人情報漏洩、誤情報は、少なくとも監視対象に入れるべきです。ここで重要なのは、キーワードだけに頼らないことです。分類モデルや人間レビューを組み合わせたほうが、見逃しを減らしやすくなります。
安全性は「最後に付け足す項目」ではありません。本番運用では、品質と同じくらい最初から設計しておくべき要素です。
8. まとめ
LLM の本番品質は、1 回の評価で決まるものではありません。出力の多様性、幻覚率、コンセプトドリフト、ユーザーフィードバック、安全性の監視を組み合わせて、継続的に見ていく必要があります。
実務で大事なのは、指標を増やすことより、異常の種類に応じて何をいつ動かすかを決めておくことです。リアルタイム監視、週次評価、月次分析、四半期レビューを分けて運用し、軽い兆候のうちに改善へつなげる。この流れが作れれば、モデルは「出したら終わり」ではなく、運用しながら育てる対象になります。
最初の一歩としては、平均確信度、エントロピー、幻覚率、週次精度の 4 つだけでも十分です。まずは小さく始めて、そこからユーザー指標と安全性指標を足していくほうが、現実的で続けやすいでしょう。
8. 今回のブログの考察
データ品質のモニタリングは、単に異常を見つけるための仕組みではなく、モデルを「本番で育てる」ための土台だと考えられます。学習時の評価が高くても、運用が始まると入力の揺れや知識の陳腐化、ユーザーの期待値の変化によって、品質は少しずつ別の形で崩れていきます。今回の内容で見たように、その崩れ方は一様ではなく、出力の多様性低下、幻覚率の上昇、コンセプトドリフト、ユーザーフィードバックの悪化として現れます。
だからこそ、実務では「精度が高いかどうか」だけを見ていると不十分です。どの指標が落ちたのか、どの層の監視で検知できたのか、そして検知したあとに何を変えるのかまでを一続きで設計しておく必要があります。リアルタイム監視、週次評価、月次分析、四半期レビューを分けて考えるのは、監視項目を増やすためではなく、異常を扱う時間軸を分けるためです。
この観点で見ると、本記事の本質は「監視の項目を列挙すること」ではなく、「軽い兆候のうちに手を打てる運用をどう作るか」にあります。幻覚率や安全性は後から足すものではなく、最初から品質指標と同じレベルで扱うべきだといえます。モデルを出して終わりにしないためには、評価・監視・改善のサイクルを小さく回し続ける設計が欠かせません。
実務で意識したいのは、指標を増やすことそのものではなく、異常が起きたときに「何を止め、何を見直し、どこまで戻すか」を決めておくことです。そうして初めて、モニタリングは単なるダッシュボードではなく、品質を保ちながらモデルを運用し続けるための判断装置になります。
📖 参考文献
主要論文
-
Tatman, R., & VandeVelde, N. (2020): “Effects of Confidence and Explanation on Accuracy and Trust Calibration in AI-Assisted Decision Making”
-
Lipton, Z. C. (2017): “The Mythos of Model Interpretability: In Machine Learning, the Concept of Interpretability is Both Important and Slippery”, ACM Queue
-
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016): “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier”, KDD 2016
📚 シリーズ案内
ブログD:詳細設計書編では、LLMの評価体系とベンチマーク管理を解説しました。
このシリーズの記事:
- LLM評価の3層構造
- 標準ベンチマークの詳細解説
- データ汚染検出とドメイン横断性能
- Attentionの可視化と解釈
- データ品質測定とモニタリング体制(この記事)
次のシリーズ:
- ブログE:組織戦略編 – チーム編成、リスク管理、品質保証
関連シリーズ:
- ブログA:基礎理論編 – パイプラインの全体像
- ブログB:実装詳細編 – 実装上の工夫とモニタリング
前の記事: Attentionの可視化と解釈 次のシリーズへ: ブログE:組織戦略編
コメント