
データセット前処理戦略の比較分析:フィルタリング手法の系統的評価
これまで紹介してきた5つの主要データセットの前処理戦略を、系統的に比較分析します。どのフィルタリング手法がどれだけ効果的なのか、トレードオフは何かを明らかにします。
1. 前処理戦略の進化
1.1 時系列による進化
前処理戦略の変化は、データセットの歴史を見るとかなりはっきりします。
「量の追求」から「質の設計」へのパラダイムシフト

- Common Crawl: スケール重視で、まず大量のデータを確保する段階
- C4: 初期品質フィルタリングを導入する段階
- The Pile: 多様性の重要性が前面に出る段階
- Dolma: 透明性と標準化を重視する段階
- FineWeb: 実験結果に基づく効率最適化の段階
ざっくり言えば、量を集めるところから、品質と構成を設計する方向へ進んできたと捉えると分かりやすいです。
前処理の真の目的は「どれだけ削るか」ではなく、「何を残して何を捨てるか」を精密に設計することである。
1.2 フォーカスの変遷
この変化は、単にデータ量が増えたという話ではありません。何を重視するかが、時代ごとに変わってきたということです。
2015〜2018年: 量こそ力
- とにかく大きなデータを集める
- 品質は二の次になりやすい
2019〜2020年: 品質と多様性
- フィルタリングの重要性が認識される
- 複数ソースを組み合わせる価値が見えてくる
2021〜2023年: 標準化と透明性
- ベストプラクティスが整う
- 再現可能なパイプラインが重視される
2024年〜: 経験的最適化
- 実験によって最適パラメータを探る
- 学習効率の最大化を狙う
2. フィルタリング戦略の詳細比較
2.1 フィルタリング適用状況
| 前処理項目 | Common Crawl | C4 | The Pile | Dolma | FineWeb |
|---|---|---|---|---|---|
| 言語フィルタ | ○ | ● | ● | ● | ● |
| URLベース重複排除 | ○ | ○ | ● | ● | ● |
| 品質フィルタリング | ○ | ● | ● | ● | ● |
| テキスト重複排除 | ○ | ○ | ○ | ● | ● |
| コンテンツ/有害除去 | ○ | ○ | ● | ● | ● |
| PII検出・マスク | – | – | ● | ● | ● |
| 評価セット汚染除去 | – | – | ● | ● | ● |
凡例: ● 積極的実装 | ○ 部分実装 | – 未実装
2.2 詳細比較表(7×7マトリクス)
| フィルタ項目 | 効果 | Common Crawl | C4 | The Pile | Dolma | FineWeb |
|---|---|---|---|---|---|---|
| 言語フィルタ | 単一言語化 | 基本的 | 厳格 | 厳格 | 厳格 | 厳格 |
| URL重複排除 | 30%削減 | 基本的 | 基本的 | 詳細 | 詳細 | 詳細 |
| 品質フィルタ | 40-50%削減 | 基本的 | 詳細 | 詳細 | 詳細 | 詳細 |
| テキスト重複排除 | 15-20%削減 | 未実装 | 未実装 | 部分的 | 詳細 | 詳細 |
| コンテンツフィルタ | 有害/広告除去 | 基本的 | 基本的 | 詳細 | 詳細 | 詳細 |
| PII検出・マスク | プライバシー保護 | 未実装 | 未実装 | 未実装 | 詳細 | 詳細 |
| デコンタミネーション | 公正な評価確保 | 未実装 | 未実装 | 部分的 | 詳細 | 詳細 |
3. 各フィルタの効果分析
3.1 フィルタ別の削減効果
フィルタごとの典型的な削減効果を整理すると、どこにコストがかかり、どこが効率化につながるのかが見えやすくなります。
7つの主要フィルター解剖図:効果と投資対効果
- 言語フィルタリング
- 効果: 非英語テキストを除去する
- 削減率: 50〜60%(多言語ソースの場合)
- 推奨度: ⭐⭐⭐
- URL重複排除
- 効果: 同じURLからの重複を除去する
- 削減率: 10〜30%
- 推奨度: ⭐⭐
- 品質フィルタリング
- 効果: 低品質テキストを除去する
- 削減率: 40〜50%
- 推奨度: ⭐⭐⭐
- テキスト重複排除
- 効果: 段落レベルの重複を除去する
- 削減率: 15〜20%
- 推奨度: ⭐⭐
- コンテンツフィルタリング
- 効果: 有害・広告テキストを除去する
- 削減率: 5〜10%
- 推奨度: ⭐⭐⭐
- PII検出・マスク
- 効果: 個人情報を保護する
- 削減率: <1%(削除ではなくマスク)
- 推奨度: ⭐⭐
- デコンタミネーション
- 効果: 評価セットの漏洩を防止する
- 削減率: <1%
- 推奨度: ⭐⭐⭐
削減率が低い「デコンタミネーション」や「PII」も、AIの安全性と評価の公正さを担保する上で最重要のフィルターとして機能する。
3.2 累積削減効果
全フィルタを順番に適用すると、元データの一部だけが最終的に残ります。
- Common Crawl: 100%
- 言語フィルタ(-55%): 45%
- URL重複排除(-10%): 40%
- 品質フィルタ(-45%): 22%
- テキスト重複排除(-18%): 18%
- コンテンツフィルタ(-8%): 17%
- PII/デコンタミ(-1%): 16%
最終出力は元データの約16〜20%になります。
4. トレードオフ分析
4.1 品質・多様性・コストの3軸
各データセットは、品質・多様性・コストのどこに重心を置くかが異なります。
- Dolma: 品質優先
- デコンタミネーションを重視する
- 前処理コードとパイプラインの完全公開
- 学術的な再現性と評価の公正さを担保する金字塔
- FineWeb: 効率優先
- 経験的最適化を重視する
- The Pile: 多様性重視
- 22ソース統合で構成の広さを取る
- 単一ソースの偏りを防ぐ
- クロスドメインの汎化性能を飛躍的に向上させた
- C4: 初期品質フィルタリング
- 初の本格的な「品質」概念の導入
- Common Crawlから高品質な英語テキストのみを抽出
- 品質と規模のバランスを取った初期の成功例
- Common Crawl: スケール優先
- コストを抑えて大量のデータを確保する
- すべての派生データセットの「源流」
- ノイズが多く単体での高精度学習には不向き
経験的最適化の頂点:FineWeb もはやデータの量やフィルタの数ではない。いかに「学習効率」を高めるかという経験的最適化のフェーズへ突入した。
4.2 トレードオフ詳細
| 選択 | メリット | デメリット | 推奨シナリオ |
|---|---|---|---|
| 品質重視 | 学習効率向上、安全性確保 | データ量減少、コスト増 | 商用、学術 |
| 多様性重視 | 汎化性能向上、クロスドメイン | 品質にばらつき | 研究、汎用 |
| スケール重視 | データ量確保、コスト低 | 品質低下、ノイズ多 | 実験、初期段階 |
5. 実装戦略の選択指針
5.1 シナリオ別推奨
シナリオごとに考えると、選択はかなり整理しやすくなります。
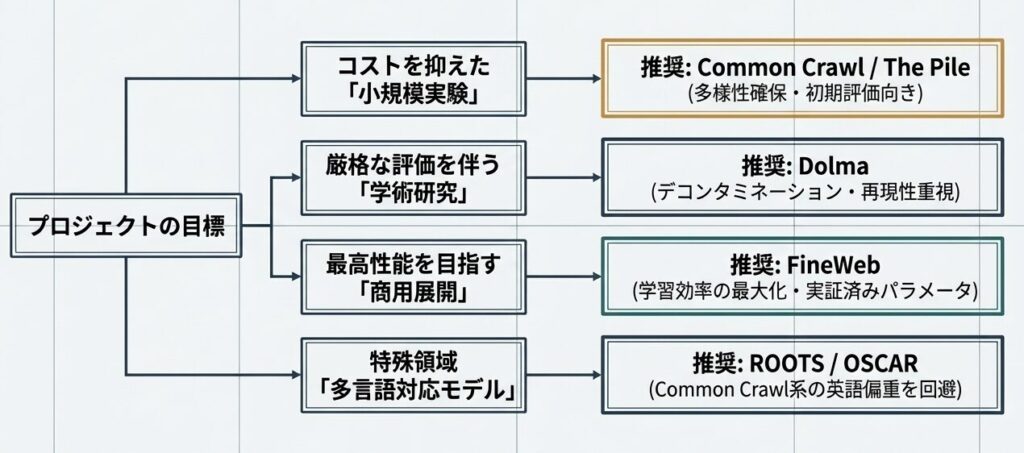
シナリオ1: 小規模実験
- 推奨: Common Crawl / The Pile
- 理由: コストを抑えたい、多様性を確保したい、品質はあとから改善しやすい
シナリオ2: 学術研究
- 推奨: Dolma
- 理由: デコンタミネーションが重要で、再現性と透明性も求められる
シナリオ3: 商用展開
- 推奨: FineWeb
- 理由: 学習効率が高く、実験的にも最適化されている
シナリオ4: 多言語対応
- 推奨: ROOTS / OSCAR(別データセット)
- 理由: 多言語に特化しており、Common Crawl系より偏りを避けやすい
目的を明確にし、要件に合致した「最小構成」から着手することが成功の鍵。
5.2 段階的導入の推奨
段階的に進めるなら、次のような流れが現実的です。
- Phase 1(プロトタイプ)
- The Pile(325B)で実験する
- 数日〜1週間で結果を確認する
- Phase 2(PoC)
- Dolma(3.0T)で本格検証する
- 2〜4週間で性能を評価する
- Phase 3(商用)
- FineWeb(18.5T)で最終訓練する
- 2〜3ヶ月で本番モデルを完成させる
6. 傾向と推奨まとめ
6.1 進化の傾向
観察される傾向をまとめると、以下の4点に集約できます。
前処理における4つのマクロトレンド
- フィルタリングが増えている
- 新しいデータセットほど、より多くのフィルタを適用する
- 品質向上への継続的な取り組みと見なせる
- 透明性が高まっている
- パイプラインの公開が標準化してきた
- 再現性と信頼性の確保につながる
- 経験的最適化が広がっている
- 理論よりも実験でパラメータを決める傾向が強い
- FineWebの成功がその流れを後押ししている
- 特化データセットが増えている
- FineWeb-eduのような用途特化版が登場している
- ユースケース別の最適化が進んでいる
7. 今回のブログの考察
前処理は「どれだけ削るか」ではなく、「何を残して何を捨てるか」を設計する工程だと改めて分かります。今回のブログで見たように、Common CrawlからFineWebへ進むほど、品質・多様性・再現性のバランスはより精密になりました。実務では、目的を先に決め、最小構成で試し、結果を見ながら段階的に最適化する姿勢が最も堅実です。特に、フィルタを増やすこと自体を目的化せず、コストと効果の釣り合いを見る視点が重要です。
📖 参考文献
主要論文
- Gao, L., et al. (2020): “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, arXiv
- https://arxiv.org/abs/2101.00027
- Soldaini, L., et al. (2024): “Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research”, ACL 2024
- https://arxiv.org/abs/2402.00159
- Penedo, G., et al. (2024): “The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale”, arXiv
- https://arxiv.org/abs/2406.17557
補足
- FineWeb-Edu は FineWeb の論文内で提案された教育向け派生データセットです。
- 本文中の FineWeb-edu の比較は、その公開実験で報告された傾向を要約したものです。
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析(この記事)
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: FineWebと学習効率の最前線
次の記事: データセット選択ガイダンス


コメント