
Common Crawlとスケール戦略:LLMデータセットの出発点
大規模言語モデル(LLM)の性能は、訓練データの量と質に大きく左右されます。では、その土台になるデータはどこから来るのでしょうか。本記事では、LLM訓練データの出発点としてよく挙げられるCommon Crawlと、その品質改善版であるC4を、できるだけイメージしやすい形で整理していきます。

Common Crawlとは
LLM性能の決定要因:量と質の関数
大規模言語モデル(LLM)の真の性能は、アーキテクチャの工夫以上に「訓練データの量と質」に大きく依存します。Web上の無尽蔵なテキストは、そのままでは使えません。高度な知能を生み出すためには、生データを高品質な「燃料」へと変換する精製プロセスが不可欠です。
インターネット全体をスナップショットとして
Common Crawlは、インターネット上の公開情報を定期的に収集し、その時点のWeb全体を丸ごと保存していくプロジェクトです。巨大なWeb空間をあとから学習用データとして再利用できるようにしている、と考えるとイメージしやすいでしょう。
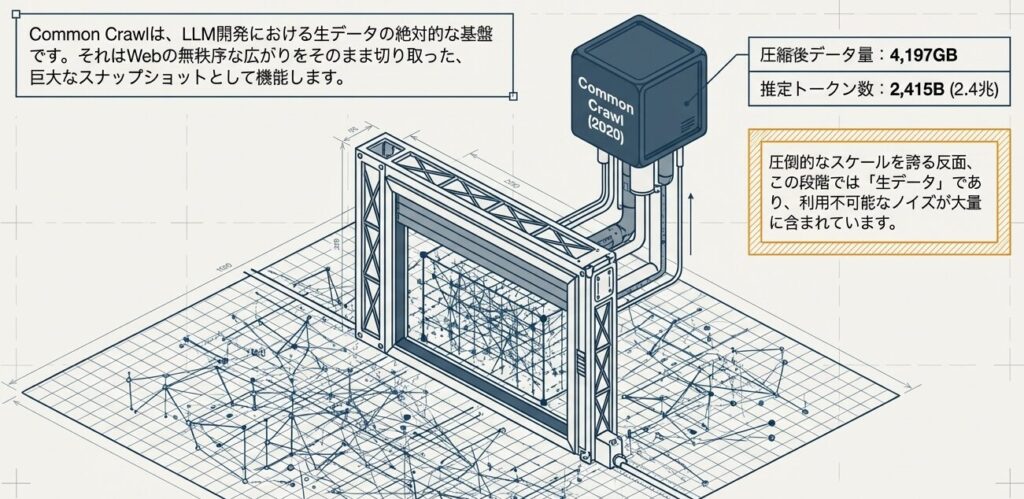
Common Crawlプロジェクトの概要
- 目的: インターネット上の公開情報を定期的にクロールし、アーカイブする
- 規模: 数十ペタバイト(PB級)
- クロール対象: 約3億5000万のドメイン
- 更新頻度: 月単位で新しいスナップショットを作成
- 保存期間: 複数年分のアーカイブを提供
データの多様性
- Webページ全体: HTML、テキスト、メタデータ
- 言語: 多言語。ただし英語が圧倒的多数
- ドメイン: ニュース、ブログ、フォーラム、学術サイトなど
LLM開発における位置付け
Common Crawlが重要になったのは、LLMが「少し大きい学習データ」では足りなくなり、桁違いの規模を必要とするようになってからです。ここでは、なぜこのデータが出発点になったのかを、流れが追いやすいように整理しておきます。
Common Crawlが果たした役割
- 1990〜2010年代: 言語モデルは、手書きデータセットや学術論文などを中心に構築されていた
- 2010年代後半: LLMのスケール化により、「膨大な規模」のデータが必要になった
- その結果: Common Crawlが、現実的に利用可能な大規模テキストソースとして注目された
代表的な利用例
- BERT(2018年): Common Crawl由来のテキストを利用し、数十GB規模でも十分な性能を示した
- GPT-3(2020年): テラバイト級のテキストが必要となり、Common Crawlが基盤となった
Common Crawlの品質問題とC4への進化
Common Crawlの課題
Common Crawlは規模こそ圧倒的ですが、Webそのものを集めたデータなので、そのままでは学習に使いにくい部分があります。まずは、どこに引っかかりやすいのかを見ておきましょう。
品質の課題
- ノイズが多い
- HTMLタグやJavaScriptコードが混在する
- 自動生成されたテキストが含まれる
- スパムコンテンツが多い
- 重複が発生しやすい
- 結果として、モデルがノイズを学習してしまう
- 言語が混在している
- 非英語テキストが大量に含まれる
- 言語判別が必要になるが、精度に限界がある
- 英語モデルでは性能低下の要因になる
- テキスト品質にばらつきがある
- 高品質記事とスパムが同じ土俵に並ぶ
- 学習に有効なテキストの割合が低い
C4(Colossal Cleaned Common Crawl)への改善
C4は、その課題に対するわかりやすい解答です。Common Crawlに品質フィルタリングを施し、学習に向いたテキストだけを残すようにしたデータセットだと考えるとよいでしょう。
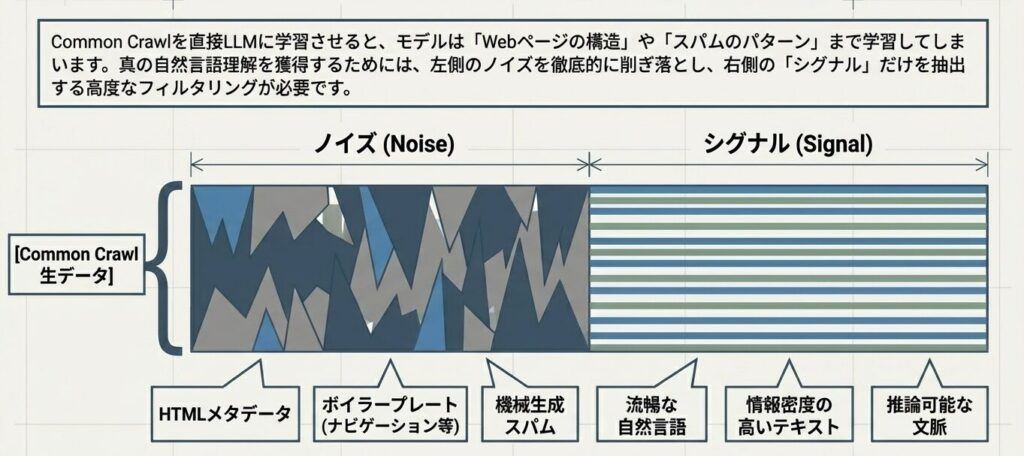
C4の戦略
Common Crawl + 品質フィルタリング = C4
フィルタリング方針
- HTMLタグを除去する
- 言語フィルタリングで英語のみに絞る
- 句読点ルールで、適切に終わらない段落を除去する
- URL単位で重複排除する
結果
- 元の10%〜30%まで圧縮される
- 平均的にノイズが低減する
- より学習に適したテキストになる
フィルタリングの効果(ウォーターフォール)
Common CrawlからC4へ進む流れは、単にデータを削る作業ではありません。学習価値の低い部分を落としながら、使えるテキストだけを丁寧に残していく工程です。ここが、ただの「量の圧縮」と少し違うところです。
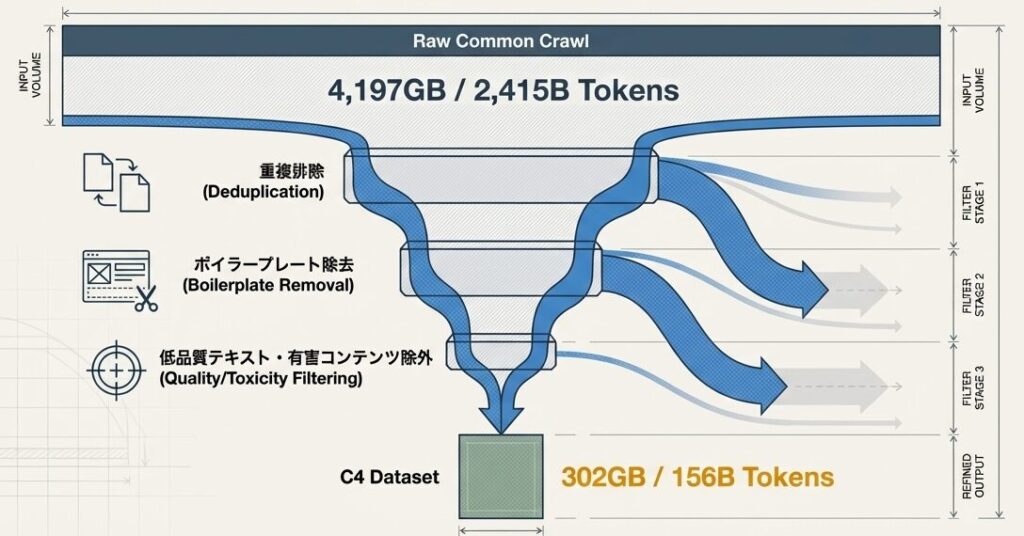
Common Crawl → C4 のフィルタリング効果
- ステップ0: 入力(Common Crawl Raw)
- データ量: 約1000〜2000TB
- 内容: 全Webページ、言語混在、低品質ページ多数
- ステップ1: 言語フィルタ
- 英語以外を削除する
- 削減率: 約50〜60%
- 出力: 約400〜1000TB
- ステップ2: 品質フィルタ
- スパム、短テキスト、低品質ページを削除する
- 削減率: 約40〜60%
- 出力: 約150〜400TB
- ステップ3: 重複排除(Deduplication)
- 同一・類似ページを削除する
- 削減率: 約10〜30%
- 出力: 約100〜280TB
- ステップ4: フォーマット化
- テキスト抽出とメタデータ整理を行う
- 最終出力: 約100TBの高品質テキスト
データセット規模の比較
統計的特性
| データセット | 年 | 圧縮後GB | トークン数 | 特徴 |
|---|---|---|---|---|
| Common Crawl | 2020年 | 4,197GB | 2,415B | 生データ、大量ノイズ |
| C4 | 2019年 | 302GB | 156B | フィルタリング済 |
| The Pile | 2020年 | 825GB | 300B | 多様性重視 |
| Dolma | 2023年 | 5,334GB | 3,084B | 6段階パイプライン |
| FineWeb | 2024年 | 実測TBD | 18,500B | 経験的最適化 |
言語分布の特性
言語分布の変化も、C4の効果を理解するうえで大事なポイントです。生のCommon CrawlとC4を比べると、英語の比率がかなり変わります。
| データセット | 英語の割合 | その他の言語 |
|---|---|---|
| Common Crawl | 約45〜50% | 中国語、スペイン語、フランス語など |
| C4 | 約95%以上 | 1〜2%程度まで大幅削減 |
この変化が、英語LLMの性能向上にしっかり効いてきました。
実務での活用指針
Common Crawl直接利用のケース
Common Crawlを直接使うのは、データ処理の設計を自分たちで持ちたい場合に向いています。扱う規模は大きいですが、そのぶん自由度も高くなります。
適している場面
- 独自のフィルタリングパイプラインを構築したい
- 多言語モデルを構築したい
- 特定ドメイン(ニュースサイトなど)を抽出したい
必要なリソース
- 大規模ストレージ(PB級)
- 高速なデータ処理パイプライン
- 品質フィルタリングの専門知識
C4利用のケース
C4は、英語特化のモデルを作りたいときや、まずは試作から始めたいときに扱いやすい選択肢です。最初から生のCommon Crawlを抱え込まなくてよいので、研究や検証の入り口としても向いています。
適している場面
- 英語特化モデルを構築したい
- フィルタリングコストを削減したい
- 研究・プロトタイピング段階
利点
- 品質フィルタリング済み
- 適度なサイズ(300GB級)
- 多くの研究で実績あり

Common CrawlやC4のようなWebスクレイピングデータは、インターネットの言語分布をそのまま反映します。その結果、データの大半を英語が占有するという構造的な偏りが生じます。
- Webデータの偏り
- 言語分布の現実
- 英語以外の言語の推論能力が著しく低下
改善策
- 抽出段階での意図的なサンプリング調整
- 言語ごとのデータリバランスが必要
📖 参考文献
主要論文
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019): “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, NAACL 2019
- https://arxiv.org/abs/1810.04805
- Brown, T. B., et al. (2020): “Language Models are Few-Shot Learners”, NeurIPS 2020
- https://arxiv.org/abs/2005.14165
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略(この記事)
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
次の記事: The Pileと多様性の発見

コメント