
Transformer進化系とスケーリング最適化:ALBERT, GQA, Flash Attentionの革新
オリジナルのTransformer(2017年)から7年、多くの革新的な改良が積み重ねられてきました。本記事では、現代の大規模LLMで採用されているALBERT、GQA、Flash Attentionなどの進化系技術を、実装レベルで解説します。
Transformerの課題
Transformerをそのままスケールすると破綻してしまうのは何故か?
従来のTransformerでは、各層が自己注意(Attention)やFFNなど固有の重みを持つため、層数に応じてパラメータ数が累積的に増える。これで層ごとに異なる表現を学べ精度向上に寄与する一方、メモリ・計算コストが大きくなる。
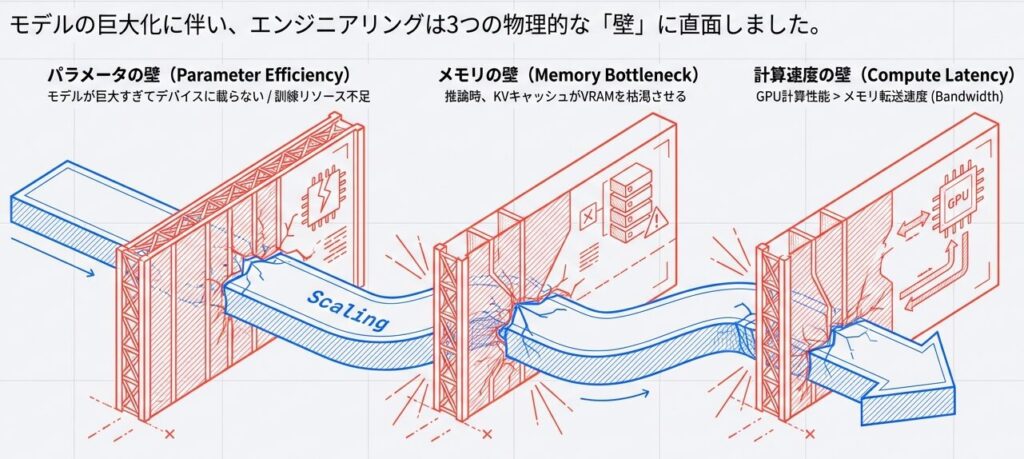
これら3つの壁をそれぞれ「ALBERT」「GQA」「Flash Attention」がいかにして乗り越えたかを紐解きます。
ALBERT:パラメータ共有による軽量化
パラメータの壁を越える:
- ALBERTと層間共有の発想
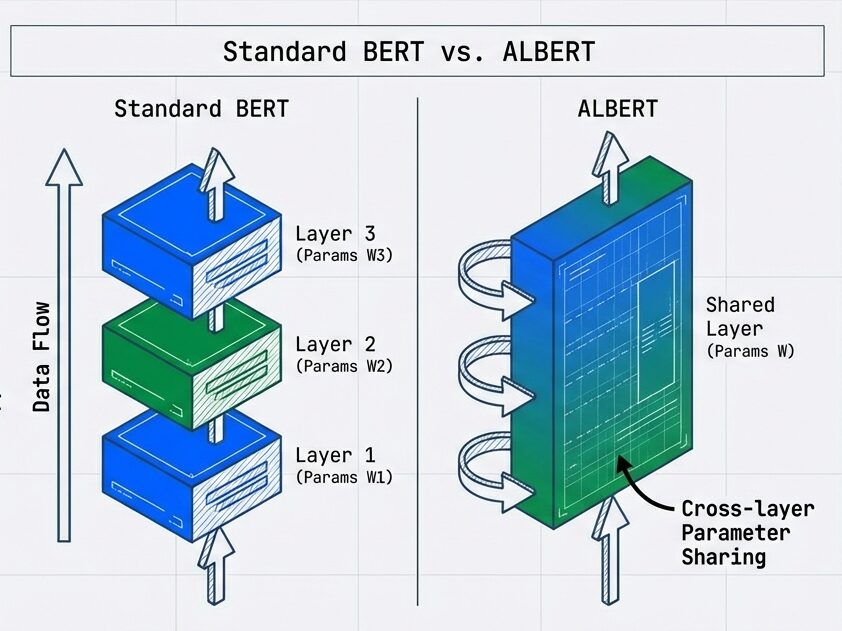
- 従来のBERTやGPTは、各層が独立したパラメータを持っています。しかし、全ての層は本質的に「同じAttentionプロセス」を実行しています。 「ならば、パラメータを使い回せるのではないか?」という問いがALBERTの出発点です。
ALBERTはBERT系のエンコーダー(双方向・マスクド言語モデル)です。
背景と動機
従来のTransformer(BERT, GPT等)では、各層が独立したパラメータを持っています。
Standard BERT:
層1: パラメータ 110M
層2: パラメータ 110M
...
層12: パラメータ 110M
─────────────────
合計: 1.32Bしかし、全ての層が同じプロセスを実行している点に着目し、ALBERTは 層間のパラメータ共有 を提案しました。
パラメータ共有の実装
- ALBERTモデルとは?
- 各層が独立した重みを持つ代わりに、AttentionやFFNなどのパラメータを層間で共有し、埋め込みの分解等と組み合わせてモデルサイズを大幅に削減する手法です。
- メモリ効率は向上するが表現力は若干低下するという特徴を持っています。
ALBERTの成果:劇的な軽量化とトレードオフ

ALBERT:
【共有パラメータ】
Attention层: 110M(全12層で共有)
FFN層: 110M(全12層で共有)
処理フロー:
入力 → 層1(共有パラメータA + B)
→ 層2(同じ共有パラメータA + B)
→ 層3(同じ共有パラメータA + B)
...
→ 層12(同じ共有パラメータA + B)
→ 出力
パラメータ削減:
標準BERT: 1.32B
ALBERT: 110M + 110M = 220M (83%削減)効果と特性
| 項目 | 標準BERT | ALBERT |
|---|---|---|
| 総パラメータ | 1.32B | 220M |
| パラメータ削減率 | – | 83% |
| 訓練時間 | 標準 | 約20%高速化 |
| 推論速度 | 標準 | 同等 |
| 精度(GLUE) | 82.1 | 80.1-81.8 |
| メモリ効率 | 標準 | 優 |
注意点:
- 共有パラメータにより、モデルの表現力がやや低下(精度 1-2% 低下)
- 訓練が不安定になりやすい
- 用途: リソース制約がある環境、エッジデバイス上での推論
GQA(Group Query Attention):推論速度の革命
GQAはQueryヘッドをグループ化し、各グループで1組のK・Vを共有するAttention手法。KVキャッシュを大幅に削減してメモリ負荷と推論時間を低減し、自回帰デコーダの推論最適化で特に有効。精度ほぼ維持で約25–30%の高速化を実現。
- KVキャッシュとは?
- KVキャッシュは自回帰推論で過去トークンのKey/Value行列を保存し、再計算を避けて高速化する仕組み。系列長・ヘッド数・次元に比例してメモリを消費するため、MQA/GQAで削減される。
- 自回帰推論とは?
- 自回帰推論は、モデルが次のトークンを逐次生成し、生成済みトークンを条件として次を予測する方式。デコーダは因果マスクで未来情報を遮断し、前ステップのK/VをKVキャッシュに保存して再利用することで高速化する。生成手法には貪欲法、サンプリング、ビームサーチなどがある。
KVキャッシュの問題点
推論メモリの壁:
- 推論メモリの壁:
- 通常のMulti-Head Attentionでは、各ステップで KV キャッシュ を保持する必要があります。
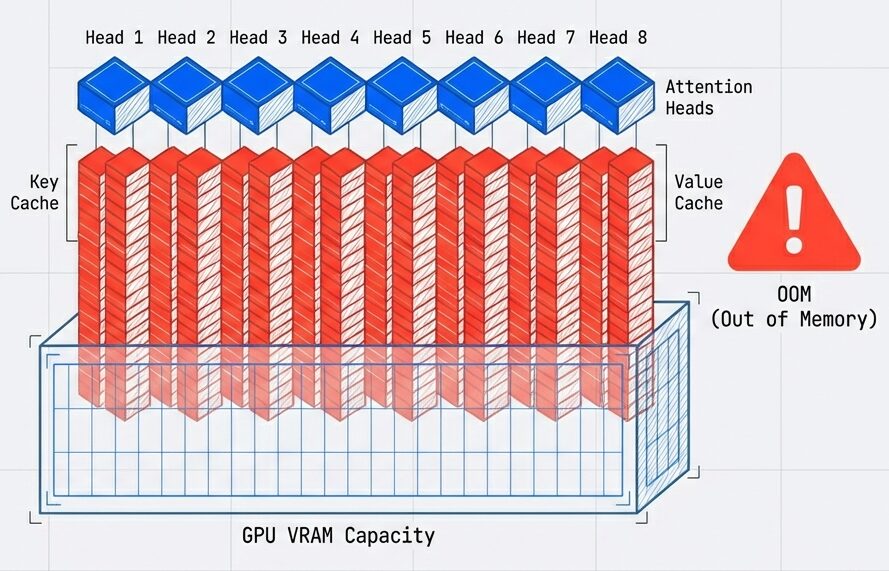
例)64ヘッド、系列長2048、精度BF16の場合
各ステップのKVキャッシュ:
K: 64ヘッド × 2048系列 × 128次元 × 2bytes = 33.5MB
V: 同じ = 33.5MB
合計(全ステップ): 33.5MB × 2048ステップ ≈ 68GB
このキャッシュがGPU メモリを圧迫 → 推論速度低下コンテキストが長くなるほど、KVキャッシュは指数関数的にメモリを圧迫し、バッチサイズを上げられなくなります。
GQAの解決策
- 賢い間引き戦略
- 全てのヘッドでKVを持つ必要はないが、1つだけでは心許ない。GQAは、複数のQueryヘッドで「1つのKVペア」を共有(グループ化)することで、バランスの取れた最適解を導き出しました。
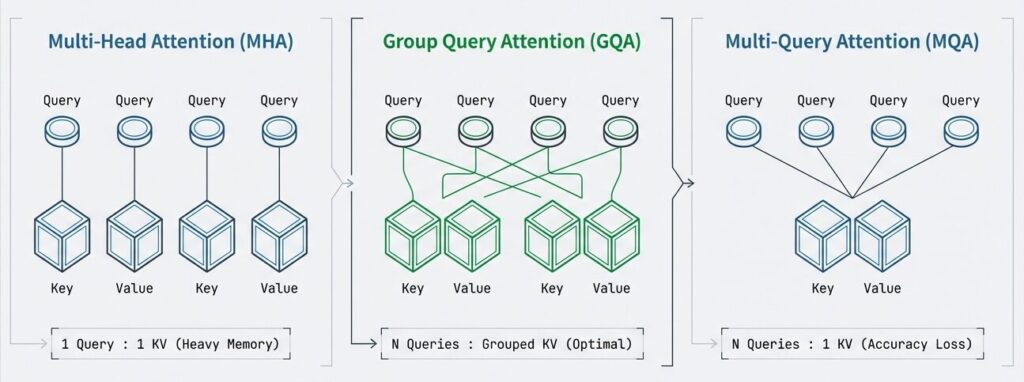
グループ化により、複数のQueryヘッドで 1つのK,Vペアを共有:
【標準 Multi-Head Attention】
Q1, Q2, Q3 ... Q64 ← 各ヘッド独立
K1, K2, K3 ... K64 ← 独立(64個のKVキャッシュ)
V1, V2, V3 ... V64 ← 独立
【GQA】
Query グループ1: Q1, Q2, Q3, Q4 ← 共有K1, V1
Query グループ2: Q5, Q6, Q7, Q8 ← 共有K2, V2
Query グループ3: Q9, Q10 ... Q64 ← 共有K_n, V_n
KVキャッシュ削減: 64 → 8(8グループの場合)
削減率: 87.5%
【MQA】
Query ヘッドはそのまま複数存在するが、K/V を全ヘッドで単一共有する方式:
Query: Q1, Q2, ... Q64 ← 独立
Key/Value: K_shared, V_shared ← 全ヘッドで共有(1組)
KVキャッシュ削減: 64 → 1(削減率 ≈98.4%)
利点: 推論時のメモリ・帯域節約が最大。実装も単純で高速化効果が大きい。
注意点: ヘッド間のK/V多様性が失われやすく、わずかな精度低下が出る場合があるため、推論最適化向けに多く採用される。- MQAとは?
- Multi-Query Attention(MQA)は、複数のQueryヘッドは維持しつつ、Key/Valueをヘッド間で共有(通常は1組)するAttention方式。KVキャッシュを劇的に削減し、自回帰デコーダの推論メモリと速度を改善する。
特徴の違い
MQAは「より大胆にKVを共有して最大削減」を目指し、GQAは「共有度を調整して精度と効率を両立」するイメージ。
| 手法 | 共有方針 | KVキャッシュ削減イメージ | メモリ/推論効果 | 精度/表現力 | 実装・適用場面 |
|---|---|---|---|---|---|
| 標準 Multi‑Head Attention | 各ヘッドが独立(Q/K/V各64) | 64 → 64(削減なし) | KVキャッシュ最大、メモリ負荷大 | ヘッド多様性最大、精度良好 | 汎用・トレーニング向け |
| Multi‑Query Attention (MQA) | Qは複数ヘッド、K/Vは全ヘッドで単一共有 | 64 → 1(理論上最大削減) | 推論メモリ・帯域節約最大 | K/V多様性低下で若干の性能劣化あり | 推論最適化、極限メモリ制約下 |
| Group Query Attention (GQA) | Qヘッドを複数グループ化し、グループごとにK/V共有 | 64 → 8(例:8グループ) | KVキャッシュ中程度削減(例≈87.5%)で推論高速化 | 一部独立性維持で精度低下は小さい | バランス重視の推論最適化(大規模モデル) |
実装例(疑似コード)
Transformerの進化と最適化を解説。ALBERTは層間パラメータ共有で大幅に軽量化、GQAはQueryをグループ化してKVキャッシュ削減で推論高速化、Flash Attentionはタイル化と再計算でメモリ/計算効率を改善。規模別推奨構成と実例(LLaMA2など)を示す。
def grouped_query_attention(Q, K, V, num_query_groups=8):
"""
Q: (batch, seq_len, d_model)
K, V: 通常より少ないヘッド数で計算
"""
num_q_heads = 64
num_kv_heads = num_query_groups # 8
# K, Vを計算(8ヘッド分のみ)
K_grouped = compute_KV(inputs, W_K_grouped) # 8ヘッド
V_grouped = compute_KV(inputs, W_V_grouped) # 8ヘッド
# Qを64ヘッド計算
Q_all = compute_Q(inputs, W_Q) # 64ヘッド
# グループ内での共有
for group_idx in range(num_kv_heads):
q_start = group_idx * (num_q_heads // num_kv_heads)
q_end = q_start + (num_q_heads // num_kv_heads)
Q_group = Q_all[:, :, q_start:q_end, :] # 8ヘッド分のQ
K_kv = K_grouped[:, :, group_idx, :]
V_kv = V_grouped[:, :, group_idx, :]
attention_output = scaled_dot_product_attention(
Q_group, K_kv, V_kv
)
return attention_outputGQAの効果
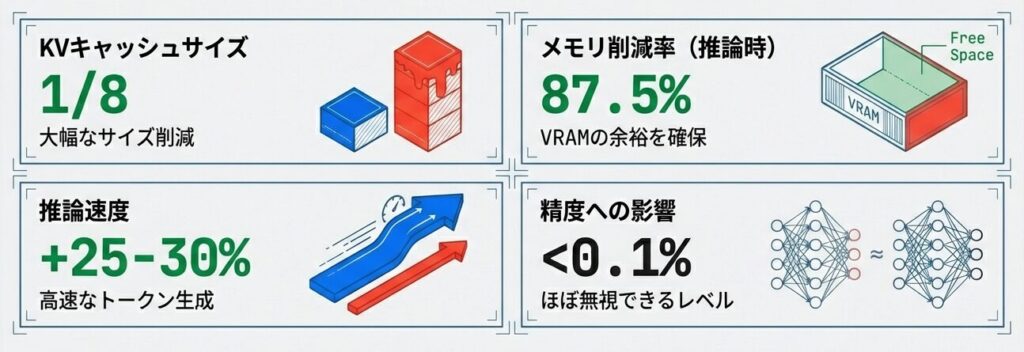
| 項目 | 標準MHA | GQA |
|---|---|---|
| KVキャッシュサイズ | 完全 | 1/8 |
| 推論速度 | 標準 | 25-30%高速化 |
| メモリ削減 | – | 87.5% |
| 精度低下 | – | 無視できる(<0.1%) |
| 採用モデル | – | LLaMA 2, Claude等 |
- LLaMA 2がGQAを採用した決定的な理由
- GOAは、精度を犠牲にすることなく、驚異的な効率化を実現しました。
- 現代の大規模モデル(LLaMA2, Claude等)におけるデファクトスタンダードです。
Flash Attention:計算効率の最適化
- Flash Attentionとは?
- Flash Attentionは、Attention行列を小ブロックで計算してGPUキャッシュ内で処理し、順伝播時の大規模中間結果保存を避け逆伝播で必要分を再計算することでメモリI/Oを削減し、スループットを大幅に向上させる手法。
背景:Attention計算の非効率性
- 標準的なAttention計算の課題
- GPU メモリバンド幅のボトルネックに陥ります。
- 現代のGPUは計算(Tensor Core)は極めて高速ですが、メモリ(HBM)からデータを運ぶ速度が追いついていません。標準的なAttention計算は、HBMとSRAMの間で無駄なデータの往復を繰り返しています。
- GPU メモリバンド幅のボトルネックに陥ります。
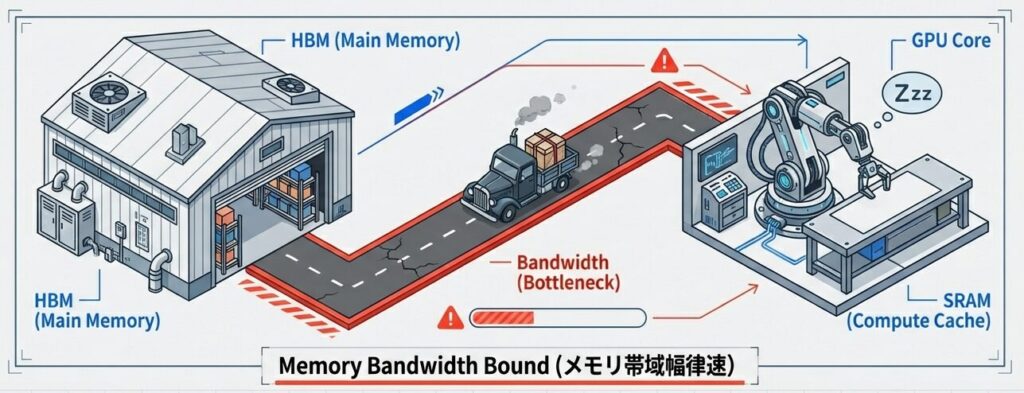
【メモリ I/O が支配的】
Q (seq_len×d_k) → GPU メモリから読込
K (seq_len×d_k) → GPU メモリから読込
スコア計算: Q @ K^T → 書き込み(seq_len×seq_len)
Softmax計算 → 読込直後に計算
注意の計算: Softmax @ V → 出力
現状:計算量 O(n²) に比べて、メモリ I/O が O(n²)
→ 計算効率が非常に低い(FLOPs 利用率 5-10%)Flash Attentionの最適化戦略
- SRAM内で計算を完結させる
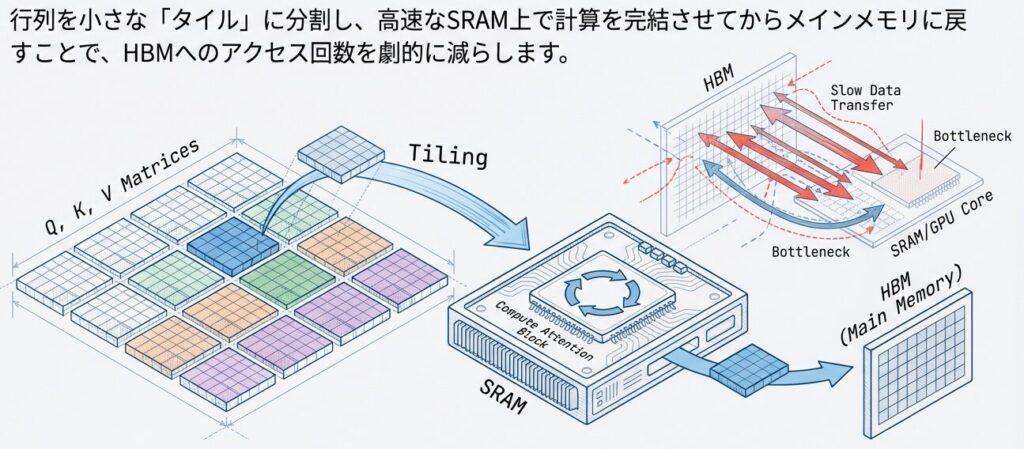
1. タイルベース計算:大きな行列を小さなブロックに分割
【標準方法】
Q全体 (2048 × 128) → K全体 (2048 × 128)
→ 注意スコア全体 (2048 × 2048)
【Flash Attention】
Q を64×128 ブロックに分割
K, V も64×128 ブロックに分割
各ブロック対で計算 → キャッシュに収まる
→ メモリ I/O 削減、キャッシュ局所性向上2. 逆伝播時の On-the-Fly 再計算:
順伝播: Q, K, V をメモリに保存(容量O(n²))
Flash Attention:
順伝播時: Q, K, V をメモリに保存(容量O(1))
逆伝播時: 必要に応じて再計算
→ メモリ削減 → 計算コスト増加は小(キャッシュ効率で補償)On-the-Fly 再計算:逆伝時、中間データを保存せずにその場で再計算する方が、メモリ読み出しより速いという逆転の発想。
性能結果
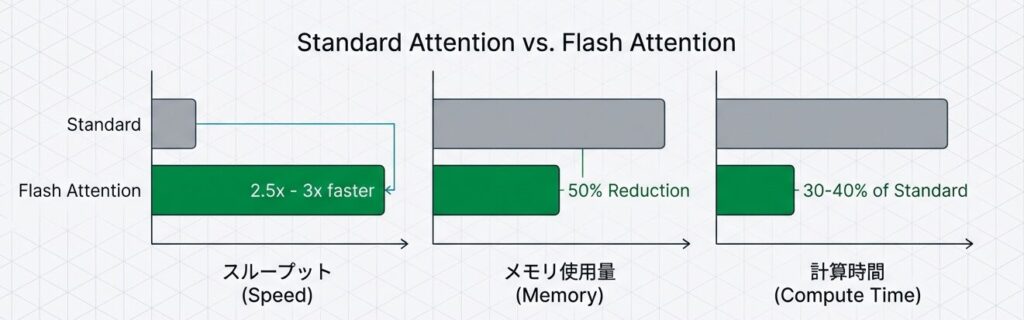
- Flash Attentionの圧倒的パフォーマンス
- 10(入出力)のボトルネックを解消することで、学習・推論の双方で劇的な高速化を実現しました。これなしでは、現在の長文脈(Long Context) モデルは存在し得ません。
| メトリック | 標準Attention | Flash Attention |
|---|---|---|
| 前向き計算時間 | 100% | 25-35% |
| 逆伝播時間 | 100% | 30-40% |
| ピークメモリ | 100% | 40-50% |
| スループット(tokens/sec) | 標準 | 2.5-3倍 |
スケーリング戦略の統合
コスト・精度・実装難易度のトレードオフを考慮し、モデル規模ごとに実用的な構成と導入順序を示した簡易ガイドです。小規模での検証を経て段階的に最適化してください。
モデルサイズ別推奨構成
【モデルサイズ別推奨構成】
<strong>小規模(< 1B):</strong>
├─ 標準 Transformer
├─ Post-norm (層正規化を出力後に配置)
└─ 通常のMulti-Head Attention
<strong>中規模(1B - 10B):</strong>
├─ Pre-norm (安定性向上)
│ └─ LayerNormを入力前に配置し勾配安定化
├─ Flash Attention (効率化)
│ └─ メモリI/O削減でスループット改善
└─ 標準Attention
<strong>大規模(10B - 100B):</strong>
├─ Pre-norm (必須)
│ └─ 深層化での学習安定性確保
├─ Flash Attention (必須)
│ └─ ピークメモリ削減とレイテンシ改善
├─ GQA (推論速度)
│ └─ KVキャッシュ削減で推論高速化
├─ Gradient Checkpointing (メモリ)
│ └─ 順伝播結果破棄で訓練メモリ節約
└─ Mixed Precision (BF16) (効率)
│ └─ FP32比で メモリ半減・スループット向上
<strong>超大規模(100B+):</strong>
├─ Pre-norm
├─ Flash Attention v2 (改良版)
├─ Multi-Query Attention または GQA
│ └─ MQA: 最大削減、GQA: バランス重視
├─ Tensor Parallelism (複数GPU)
│ └─ モデル分割で各GPUメモリ負荷低減
├─ Sequence Parallel (長系列対応)
│ └─ 系列方向の分割で大コンテキスト対応
├─ Gradient Checkpointing + Recompute
│ └─ メモリと計算時間のトレードオフ調整
└─ Pipeline Parallelism (複数GPU並列化)
└─ 層方向の分割で複数GPU有効活用計算効率の向上フロー
計算効率の向上フロー:
標準 (FLOP利用率 5-10%)
↓ Flash Attention
中程度 (15-25%)
↓ GQA + メモリ最適化
高効率 (40-60%)実例:LLaMA 2の採用技術
- 統合戦略
- LLaMA 2に見る現代的アーキテクチャ
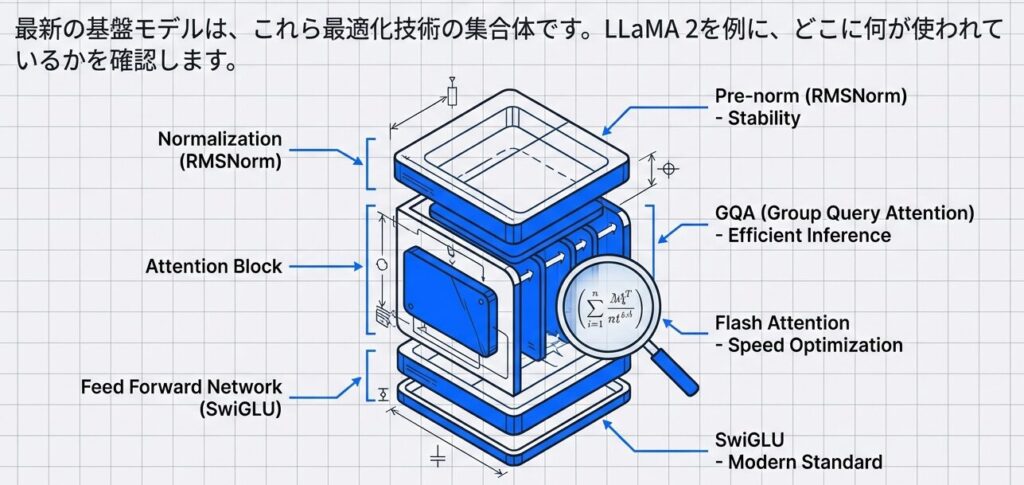
LLaMA 2 70B:
✓ Pre-norm レイヤー正規化
✓ SwiGLU 活性化関数
✓ RoPE (Rotary Position Embedding)
✓ GQA (推論最適化)
✓ Flash Attention 組み込み
結果:
- 標準 LLaMA 1 と比較して推論速度 2倍
- メモリ効率 30% 向上
- 精度維持(むしろ向上)Transformer進化系タイムライン
【2017-2024 進化の軌跡】
2017年: 元々のTransformer(Attention is All You Need)
└─ 基本アーキテクチャの確立
2019年: GPT-2, BERT
└─ 大規模事前学習の実証
2020年: ALBERT登場
└─ パラメータ共有による効率化開始
2021年: GPT-3 (175B)
└─ スケーリングの限界挑戦
2022年: GQA(Group Query Attention)
└─ 推論速度向上の革新
2023年: Flash Attention v2
└─ メモリ・計算効率の最適化
2024年: LLaMA 3, Claude 3
└─ 複数最適化の統合性能トレードオフ比較
どの技術が何を解決し、何を犠牲にするかを整理します。
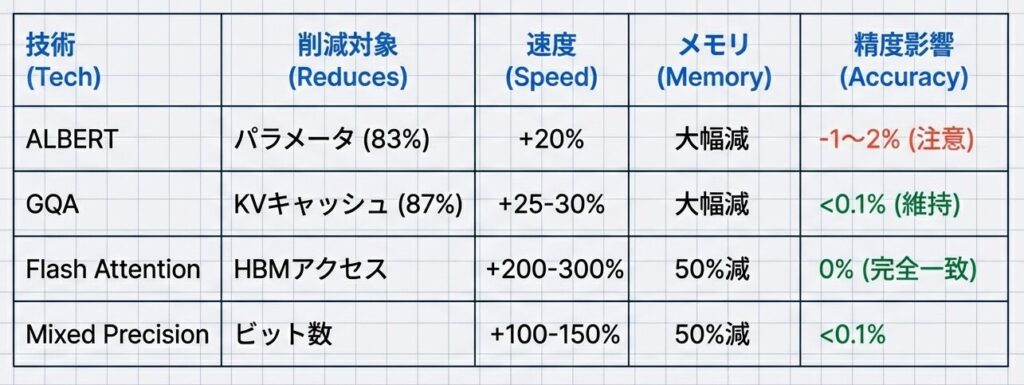
詳細
| 技術 | 主な工夫・アプローチ | 解決した課題 | 効果・インパクト |
|---|---|---|---|
| ALBERT | パラメータ共有(特に層間での重み共有) | モデルサイズの肥大化、メモリ・計算資源の制約 | モデルを劇的に軽量化し、リソース制約のある環境でもLLM展開を可能に |
| GQA(Grouped Query Attention) | Query をグループ化し、Key/Value を共有 | 推論時の KV キャッシュによるメモリ・計算負荷 | 精度を維持したまま応答速度を大幅に向上し、対話型AIの品質を改善 |
| Flash Attention | メモリアクセス最適化(タイル化・再計算)による高速Attention | メモリ帯域ボトルネック | 計算スループットを根本的に改善し、大規模モデルの訓練・運用を現実的に |
📖 参考文献
主要論文
- Hoffmann, J., et al. (2022): “Scaling Laws for Neural Language Models”, IMLR 2022
- Touvron, H., et al. (2023): “LLaMA: Open and Efficient Foundation Language Models”
- OpenAI (2023): “GPT-4 Technical Report”
📚 シリーズ案内
ブログB:実装詳細編では、Transformerの各構成要素を実装レベルで解説しています。


コメント