
【今回の主な内容】時系列データから言語理解まで、Transformerの可能性を探る
今回のテーマは自然言語処理、時系列データ解析、音声認識における技術進化の流れと、Transformerモデルの登場が果たした革新について解説します。まず、自然言語処理(NLP)の進化として、RNNやSeq2Seq、Attention機構からTransformerへの移行を説明し、BERTやGPTシリーズを具体例に応用を紹介します。その後、時系列データ解析では、RNN系の課題を克服したTransformerの強みを解説し、株価予測や異常検知などの実践例を提示します。最後に、音声認識の分野において、RNN系からSpeech-TransformerやWav2Vec 2.0への進化を示し、ラベル付けが困難な音声データへの対応策を紹介します。各章で実装例を挙げ、理論と実践の結びつきを強調します。
今回の学習目標
- 自然言語処理(NLP)の進化を理解する
- RNN、Seq2Seq、Attention機構、Transformerモデルの歴史的な流れを学び、技術進化の背景を理解します。
- NLPにおけるTransformerの革新性と具体的な応用例(BERT、GPTなど)を把握します。
- 時系列データ解析におけるTransformerの応用を学ぶ
- 時系列データの課題(長期依存関係、ノイズ、非線形パターン)と、それに対するRNN/LSTMおよびTransformerのアプローチを理解します。
- 株価予測や異常検知などの応用例を通じて、時系列データにおけるTransformerの有用性を学びます。
- 音声認識分野におけるTransformerの役割を学ぶ
- RNN系モデルからTransformer系モデルへの移行理由と、Speech-TransformerやWav2Vec 2.0などの具体的な応用事例を学びます。
学習ゴール
- 技術的な背景を説明できる
- NLPや時系列データ解析、音声認識におけるTransformerモデルの意義や進化の流れを自分の言葉で説明できるようになる。
- 応用分野での知識を活用できる
- Transformerが異なる分野(自然言語処理、時系列データ解析、音声認識)でどのように使われているかを理解し、それぞれの課題解決方法を提案できるようになる。
- 基本的な実装スキルを身に付ける
- NLPタスク(例: 文生成)、時系列予測(例: 株価予測)、音声認識(例: 音声特徴量学習)のTransformerモデルを実装し、動作を確認できる。
- 次の学習ステップを明確にする
- NLPにおけるBERTやGPTシリーズの詳細、時系列解析でのTemporal Fusion Transformer、音声認識でのWhisperモデルなど、次に学ぶべき技術やリソースを特定できる。
第10回(前編)の振り返り
時系列データを扱うアルゴリズムの歴史は、ディープラーニング以前から続く進化の軌跡を持っていますが、ディープラーニングの登場により、新たな可能性が開かれました。前回のブログでは、この流れの中でも特に重要なRNN、LSTM、GRUといった時系列モデルに焦点を当て、これらが時系列データ解析にどのような革新をもたらしたかを学びました。
RNNは、時系列データの連続性を学ぶ初期のモデルとして登場しましたが、長期依存の学習では勾配消失問題に直面しました。この課題を克服したLSTM(長短期記憶)は、ゲート機構を通じて重要な情報を保持し、金融予測や異常検知で成功を収めました。さらに、LSTMを簡略化したGRU(ゲート付きリカレントユニット)は計算効率を高め、リアルタイム解析にも適用されました。
これらの進化は、次に登場するTransformerモデルへの橋渡しとなります。
時系列データに関するアルゴリズムの発展
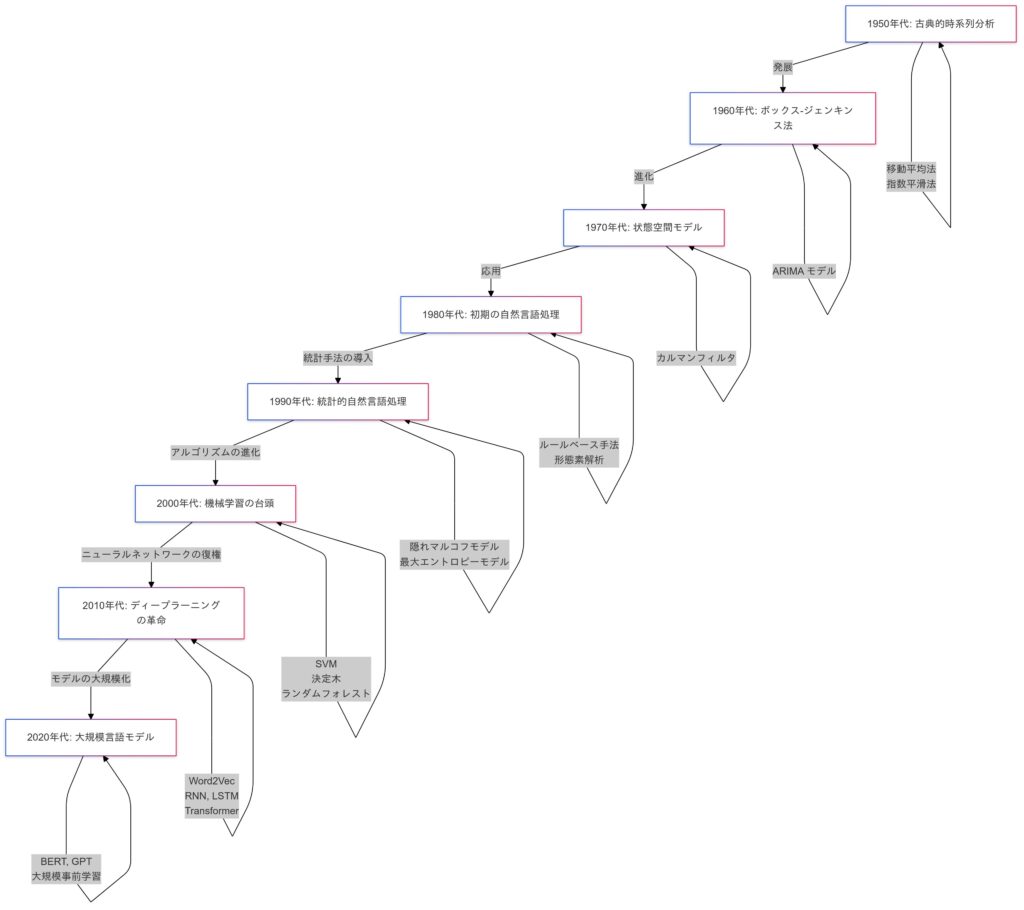
自然言語処理におけるTransformerモデルの登場と進化
自然言語処理の進化の振り返り
Word2Vec
- 目的
- Word2Vec(2013年)は、単語をベクトル化し、単語間の意味的な関係を効率的に捉える手法です。Skip-gramやCBOWを活用して計算効率を高め、大規模データにも対応可能で、自然言語処理タスクの性能向上に貢献しました。
- 課題
- Word2Vecの課題は、短い文脈内の関係性は捉えられるものの、長い文章での単語間の長期依存関係や文書全体の意味を把握するのが難しい点です。また、文脈情報が固定されているため、同じ単語の異なる意味を表現するには不十分でした。
| 用途 | 説明 | 具体例 |
|---|---|---|
| 単語の類似性や関連性の計算 | 単語を高次元ベクトル空間に埋め込むことで、類似性(コサイン類似度など)を計算し、関連性の高い単語を特定するのに利用。 | 「王」-「男性」+「女性」=「女王」のようなベクトル演算。 |
| 検索エンジンや情報検索 | 検索クエリと文書間の意味的な類似性を向上させるために使用。 | Synonym Expansion(類義語展開)による検索精度の向上。 |
| 自然言語処理(NLP)タスク | テキスト分類(スパム検知、感情分析)、翻訳モデル、質問応答システムなどで利用。 | メールのスパム検知、感情分析、翻訳システム、質問応答システム。 |
| レコメンデーションシステム | ユーザーの好みや行動履歴を単語と見立て、類似した商品やコンテンツを推薦。 | 映画や音楽の推薦アルゴリズム。 |
| 知識発見 | 文書間の隠れた関係性やテーマを分析し、トピックモデリングや知識グラフの構築に役立つ。 | トピックモデリング、知識グラフの構築。 |
| 音声認識や画像キャプション生成 | 単語の意味をベクトル表現として用いることで、音声や画像に関連するテキスト生成の精度向上に貢献。 | 音声認識システム、画像キャプション生成。 |
RNNとLSTMの役割
- 自然言語処理の初期では、RNNや改良版のLSTMが主力モデルとして活躍しました。LSTMはゲート機構により長期依存関係を学習し、機械翻訳やテキスト分類などで高い効果を発揮しましたが、逐次処理による計算コストの高さや長い文脈を完全には捉えきれない課題がありました。LSTMの改良版であるGRUも同様の課題があります。
- 長期依存関係の限界
- 長い文では、離れた単語間の関係を正確に学習するのが難しいという課題があります。
- 計算効率の問題
- 逐次処理が必要なため、並列計算が難しく、大量のデータ処理に時間がかかる課題があります。
Transformerモデルが出てくるまでの自然言語処理を行う場合においてはこのRNNとLSTM、GRUなどがよく使われていました。
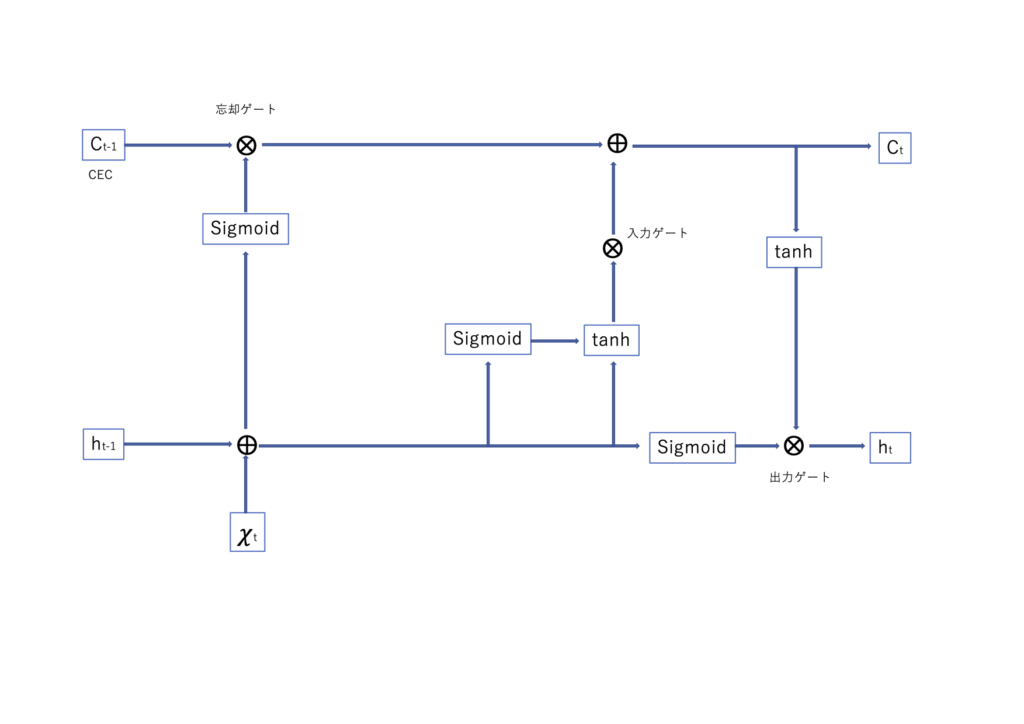
LSTMモデルのイメージ
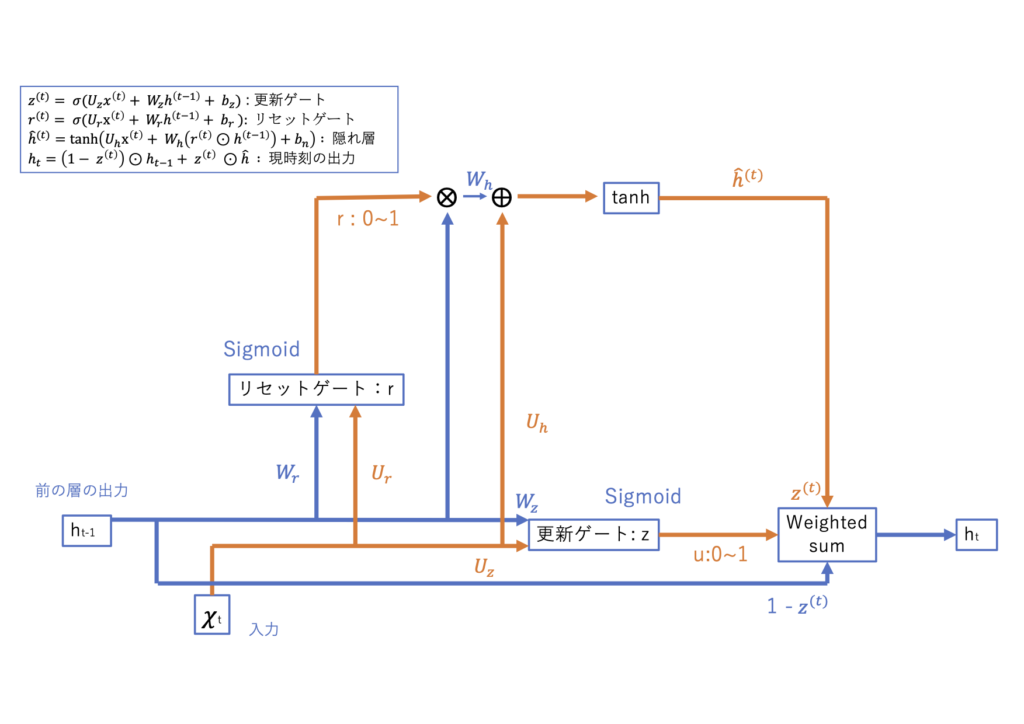
GRUのイメージ
Seq2Seqモデル
- Seq2Seqモデルは、Encoder-Decoder構造を活用し、文全体をエンコードして別の形式にデコードすることで、自然言語タスクの性能を向上させました。例えば、機械翻訳では入力文をエンコードし、ターゲット言語の文を生成します。
- 長文の情報損失
- Encoderが文全体を固定長のコンテキストベクトルに圧縮するため、長文では重要な情報が失われやすい課題がありました。
- 逐次処理のボトルネック
- 処理速度が遅く、時間効率が悪いという課題が残っていました。
- 長文の情報損失
Seq2Seqの動作イメージ

Seq2Seqの主な適用例
| 適用例 | 説明 | 具体例 |
|---|---|---|
| 機械翻訳(Machine Translation) | 入力文をエンコーダでベクトルに圧縮し、その情報を元にターゲット言語の文をデコードする。 | 英語の文章を日本語に翻訳する。 |
| チャットボット | ユーザーの入力メッセージをエンコードし、それに適した返信を生成する。 | 質問に対する回答の生成。 |
| 自動要約 | 長い文書を短い要約に変換。 | ニュース記事をコンパクトに要約する。 |
| メールの自動返信 | 入力されたメール本文を解析し、適切な返信文を生成する。 | 自動返信メールの生成。 |
Seq2Seqが用いられた理由
| 理由 | 説明 |
|---|---|
| 柔軟性 | 入力系列と出力系列の長さが異なっても対応可能。 |
| 汎用性 | 時系列データ全般に適用できる。 |
| ソフトマックス層の使用 | 次に最も確率が高い単語を選択することで、自然な文生成を実現。 |
LSTMやGRUは、Seq2Seqモデルのエンコーダ・デコーダアーキテクチャによく用いられ、特に長期依存関係を効率的に学習できる点で優れています。この特性により、機械翻訳などのタスクで入力系列をエンコードし、出力系列をデコードする際、従来のRNNよりも高い性能を発揮しました。
Attention機構の導入
Attention機構は、文中の単語間の重要度を動的に計算し、関連性の高い情報に焦点を当てる仕組みです。たとえば「彼女は美しい絵を描いて、それを友人に見せた」という文では、「それ」と「美しい絵」の関連性を捉え、文脈を理解します。この仕組みは人間が情報に注意を向ける動きやフラッシュバック現象に似ており、長文や複雑な文脈における依存関係を効率的に処理します。
LSTMの課題を克服したモデル
- Attentionは従来のLSTMやRNNが持つ逐次処理の限界を克服し、全単語間の関連性を一度に計算することで、並列処理による高い計算効率と長期依存関係への対応を可能にしました。この特性から、BERTやGPTなどの大規模モデルに採用され、NLPの分野で革新をもたらしています。
LSTMとAttentionを組み合せ
- Attention機構をLSTMの出力に適用することで、重要なタイムステップに焦点を当て、長期依存関係を効果的に捉えられるようになります。また、どの部分に注目しているかを可視化できるため、モデルの解釈性が向上します。これにより、特に時系列データの予測精度が向上することが期待されます。
Attention機構が用いられた経緯
- Attention機構は、入力データの重要部分に焦点を当てる技術で、関連性に基づき重みを動的に調整します。当初はseq2seqモデルの改良案として提案され、入力と出力の関係性を自動学習・可視化できる利点を持ちます。その後、Transformerモデルに発展し、自然言語処理や長期依存関係の処理で広く活用されています。このシンプルかつ効果的な仕組みは、深層学習の革新的な技術として標準化されています。
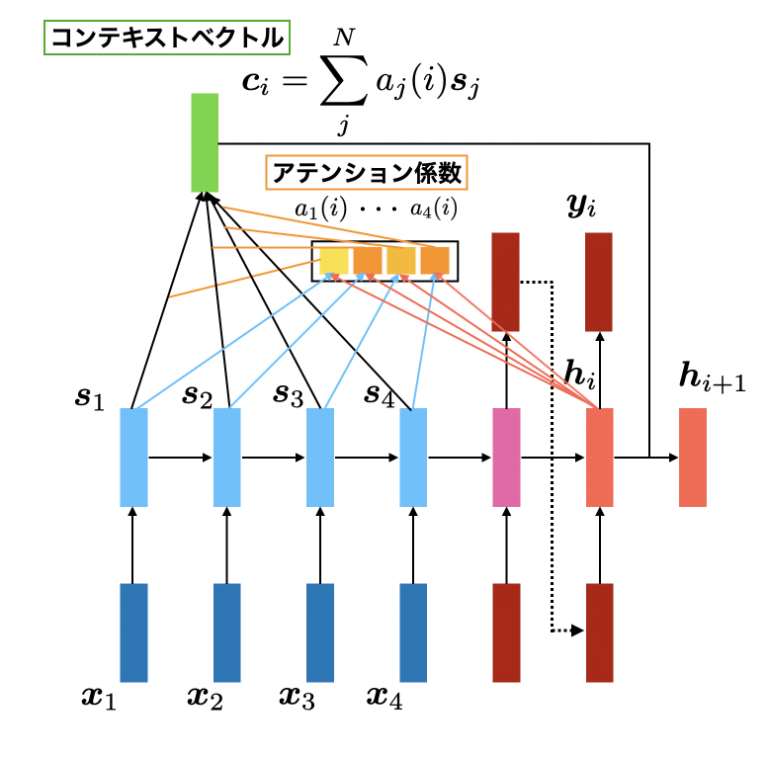
Attention機構の特徴
| 理由 | 説明 |
|---|---|
| 動的な情報抽出 | 文中の重要な単語に焦点を当てて処理を行うため、重要な情報を効率よく捉えます。 |
| 長文処理の改善 | 長文でも、重要な情報を失うことなく処理できるため、翻訳精度や文脈の理解が向上します。 |
| スケーラビリティ | 大規模データや多言語翻訳タスクにも適用可能で、特にGoogle Translateのような実用的なシステムで大きな成功を収めました。 |
数式
- スコア計算
- クエリ $q$ とキー $k$ の関連度を計算します。
$$\text{Score}(q, k) = q^\top k$$
- 重みの正規化
- スコアをソフトマックス関数で正規化し、重み $α$ を計算します。
$$\alpha_i = \frac{\exp(\text{Score}(q, k_i))}{\sum_j \exp(\text{Score}(q, k_j))}$$
- コンテキストベクトルの計算
- 重み付けした値 $v$ を合計して、コンテキストベクトル $c$ を計算します。
$$c = \sum_i \alpha_i v_i$$
Attentionの課題
| デメリット | 説明 |
|---|---|
| 計算コストの増加 | スコア計算やソフトマックスで計算コストが高くなる。 |
| メモリ消費 | キーと値の行列が大きい場合、メモリの消費量が増大する。 |
| 並列処理の制限 | 処理に依存関係がある場合、並列処理が難しいことがある。 |
Attentionの実装例)
import torch
import torch.nn as nn
import torch.nn.functional as F
# Attentionクラスの定義
class Attention(nn.Module):
def __init__(self, hidden_dim):
super(Attention, self).__init__()
# スケールファクターの計算(隠れ層次元の平方根)
self.scale = hidden_dim ** 0.5
def forward(self, query, key, value):
# スコア計算: queryとkeyの転置行列の内積を計算し、スケールファクターで割る
scores = torch.matmul(query, key.transpose(-2, -1)) / self.scale
# ソフトマックスで重みを計算: スコアをソフトマックス関数に通して重みを計算
weights = F.softmax(scores, dim=-1)
# 重み付けされた値を計算: 重みをvalueに掛けてコンテキストベクトルを計算
context = torch.matmul(weights, value)
return context, weights
# 入力テンソルの例
query = torch.rand(1, 5, 64) # (バッチサイズ, シーケンス長, 隠れ層次元)
key = torch.rand(1, 5, 64)
value = torch.rand(1, 5, 64)
# Attentionクラスのインスタンス化
attention = Attention(hidden_dim=64)
# フォワードパスの実行
context, weights = attention(query, key, value)
# 結果の出力
print("Context shape:", context.shape)
print("Weights shape:", weights.shape)Context shape: torch.Size([1, 5, 64]) # (バッチサイズ, シーケンス長, シーケンス長)
Weights shape: torch.Size([1, 5, 5]) # (バッチサイズ, シーケンス長, シーケンス長)- コンテキストベクトルは、重み付けされたバリューテンソルを加重平均して得られるもので、形状は (バッチサイズ, シーケンス長, 隠れ層次元) です。
- 重みは、クエリとキーのスコアにソフトマックス関数を適用して計算され、形状は (バッチサイズ, シーケンス長, シーケンス長) になります。
適用例
| 応用例 | 説明 |
|---|---|
| 機械翻訳 | Google Translateなどの翻訳モデルでは、Attentionを活用することで翻訳精度が大幅に向上しました。 |
| テキスト要約 | Attentionを利用して重要な文脈を抽出し、要約を生成。 |
| 画像キャプション生成 | 画像の特徴にAttentionを適用し、キャプション生成に利用。 |
論文
『Neural Machine Translation by Jointly Learning to Align and Translate』

- ソフトアライメント機構の導入
- ソフトアライメント機構は、翻訳時にソース文全体を固定長ベクトルに圧縮するのではなく、各ターゲット単語に関連する部分を動的に選択する手法です。双方向RNNで生成した各単語の「アノテーション」に重み付けを行い、必要な情報に焦点を当てたコンテキストベクトルを計算します。これにより、長文でも重要な情報を抽出しながら翻訳精度を大幅に向上。従来のモデルが抱える長文での性能劣化を克服し、人間の直感に近い翻訳を可能にした革新的な技術です。
- 長文翻訳での高い性能
- RNNsearchは、従来のモデルが長文で情報を保持しきれず性能が劣化する課題を克服し、安定した翻訳精度を実現しました。ソフトアライメント機構により、翻訳時に関連情報を動的に抽出することで、BLEUスコアで従来のRNNencdecを上回り、フレーズベース翻訳システム(Moses)に匹敵する精度を達成。特に長文での翻訳性能向上が顕著で、実用性が飛躍的に向上した点が大きな特徴です。
- Attention機構の基本的な概念の導き
- この論文は、RNNsearchを用いてAttention機構の原型となるソフトアライメント機構を提案したものであり、Attentionの基本概念を導いた重要な研究と位置付けられます。そのため、現在の多くのNLPアルゴリズムにおけるAttention機構の源流と言って差し支えありません。
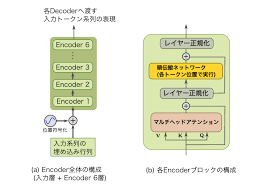
Transformerの基本構造と仕組み
Transformerモデルは、2017年にVaswaniらが提案したNLPの革新的技術で、Self-Attentionと並列処理により、RNNの逐次処理を不要にしました。これにより、長文や複雑な文脈を効率的に処理し、機械翻訳や質問応答など多くのタスクで高い性能を発揮。特に、BERTやGPTといった大規模モデルの基盤技術となり、NLPの発展を大きく後押ししています。また、画像処理やマルチモーダルタスクにも応用されるなど、幅広い分野で活用されています。
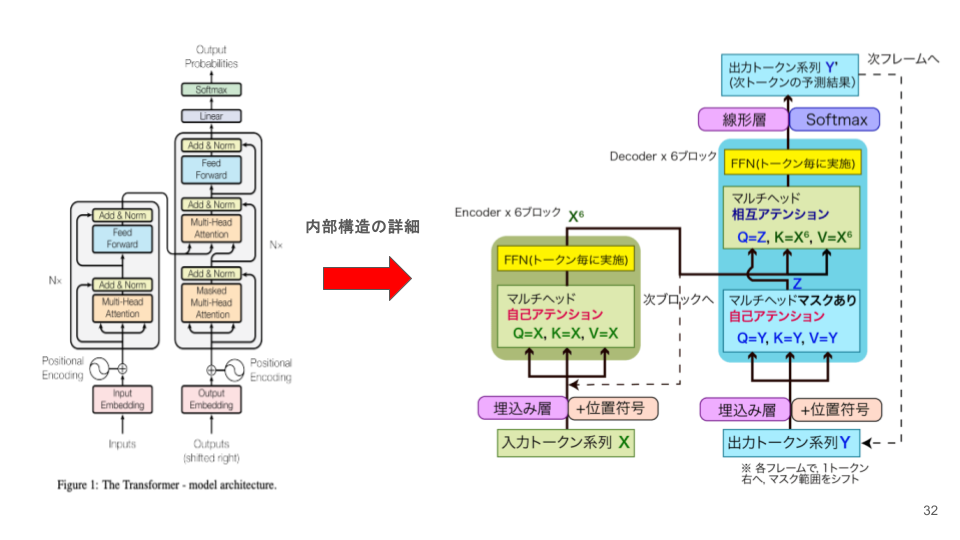
特徴:
上のTransformerを構成するイメージ図からもわかりますが、Transformerは3種類のAttentionを組み合わせて高い性能を実現します。
- Self-Attention
- Self-Attentionは同一系列内のトークン間の関連性を計算し、文脈を学習します。
- Cross-Attention
- Cross-Attentionはエンコーダの出力とデコーダのトークン間の関連性を計算し、次のトークン生成を補助します。
- Multi-Head Attention
- Multi-Head Attentionは複数のヘッドでこれらの計算を並列化し、多様な特徴を効率的に学習します。
| Attentionの 種類 | 定義 | 用途 | 使用場所 | 具体例 |
|---|---|---|---|---|
| Self-Attention | 同一系列内の関連性を計算 | 文脈情報を学習 | エンコーダとデコーダ内部 | 文中の単語が他の単語との関係を学び、文全体の意味を理解する。 |
| Cross-Attention | 異なる系列間の関連性を計算 | エンコーダ出力を参照し次のトークンを生成 | デコーダ内部 | エンコーダ出力(入力文)を元に、デコーダ(出力文)が次の単語を生成。 |
| Multi-Head Attention | 複数のAttentionヘッドを並列実行し多様な関係を学習 | 各ヘッドが異なる特徴を学習 | Self-AttentionとCross-Attentionに適用 | 1つのAttentionを複数に分け、異なる角度でトークン間の関連性を計算。 |
次はこの3種類のAttentionの仕組みを解説します。
Self-Attentionの仕組み(エンコーダー)
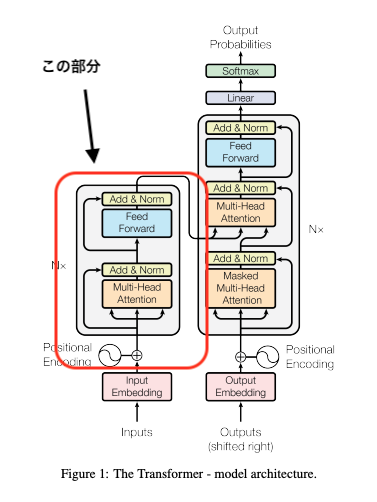
エンコーダーの自己アテンション(Self-Attention)は、文中の各単語が他の単語との関連性を動的に計算し、文全体の文脈を考慮した特徴を持つように更新する仕組みです。具体的には、各単語がQuery(検索)、Key(比較対象)、Value(情報)として表現され、QueryとKeyの関連度を計算後、ソフトマックス関数で重み付けを行い、Valueに適用します。このプロセスで、単語間の文脈情報を効果的に学習し、高精度な自然言語処理が可能になります。
- Query(クエリ): 各単語の情報を他の単語と比較する際の「検索」の役割。
- Key(キー): 他の単語が「検索される側」の役割を果たす情報。
- Value(値): 実際に重み付けして特徴表現を更新する際の基礎情報。
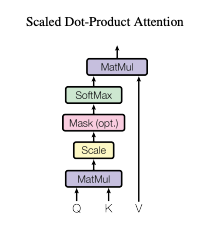
Scaled Dot-Product Attention
- Scaled Dot-Product Attentionは、Self-Attentionの具体的な計算アルゴリズムであり、入力シーケンス内の単語間の関連性を動的に計算する仕組みです。Query(クエリ)とKey(キー)の内積で類似度スコアを求め、それをスケール化しソフトマックス関数で正規化します。これに基づき、Value(バリュー)に重み付けを行い、重要な情報を抽出します。Self-Attention全体の中で、この計算プロセスが中核を担い、単語間の文脈情報を効率的に学習します。
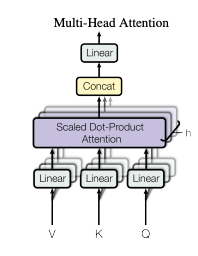
Multi-Head Attention
- Multi-Head Attentionは、Attention機構を複数の視点で同時に実行する手法で、情報の多様性を向上させます。入力を複数のヘッドに分割し、それぞれが異なる関連性を学習。これにより、異なる特徴や文脈を同時に捉えることが可能です。各ヘッドの出力を統合することで、短期・長期依存関係を包括的に学習します。この技術はTransformerモデルの核となり、機械翻訳や質問応答など多くのNLPタスクで高い性能を発揮しています。
Single-Head Attention
- Single-Head Attentionは、Multi-Head Attentionを構成する基本的な要素です。具体的には、各単語に対して他のすべての単語との関連度を計算し、重要な情報に焦点を当てる仕組みです。
Position Encoding
- Position Encodingは、Transformerモデルで単語の順序情報を提供する技術です。正弦波と余弦波を利用して位置ベクトルを生成し、埋め込みベクトルに加算することで、Attention機構だけでは捉えられない単語の順序を補完します。この仕組みにより、モデルは文脈の順序関係を理解しながら、効率的な並列計算を維持できます。計算効率が高く、BERTやGPTなど多くのモデルで活用され、自然言語処理の基盤技術となっています。
数式
- Self-Attentionの計算
- Self-Attentionは、クエリ $Q$、キー $K$、値 $V$ を用いて以下の計算を行います。
$$\text{Self-Attention(Q, K, V)} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
$Q,K,V$:クエリ、キー、値行列(入力データから線形変換)。$d_k$:キーの次元数(スケーリング因子)
- Multi-Head Attentionの計算
- Single-Head Attentionを複数回並列計算し、それらを結合する仕組みです。
$$\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O$$
- 各ヘッド
$$\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$
- Position Encodingの計算
- 単語の順序情報を加えるため、以下の形式で位置情報を埋め込みます。
$$PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_\text{model}}}}\right), \quad
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_\text{model}}}}\right)$$
Self-Attention(エンコーダー部分)の実装)
- この部分はエンコーダー部分のマスクなしのSelf-Attentionの実装です。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadSelfAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.head_dim = embed_size // num_heads
self.num_heads = num_heads
self.embed_size = embed_size
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, queries, mask=None):
N = queries.shape[0] # Batch size
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Split embedding into self.num_heads pieces
values = values.view(N, value_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
keys = keys.view(N, key_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
queries = queries.view(N, query_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# Scaled dot-product attention
scores = torch.matmul(queries, keys.permute(0, 1, 3, 2)) / (self.head_dim ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(scores, dim=-1)
out = torch.matmul(attention, values)
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(N, query_len, self.embed_size)
return self.fc_out(out)Self-Attentionの仕組み(デコーダー)
基本的には先ほど説明したSelf-Attentionと同等の役割を持ちますが、役割が違う部分もありますのでその点について言及しておきます。
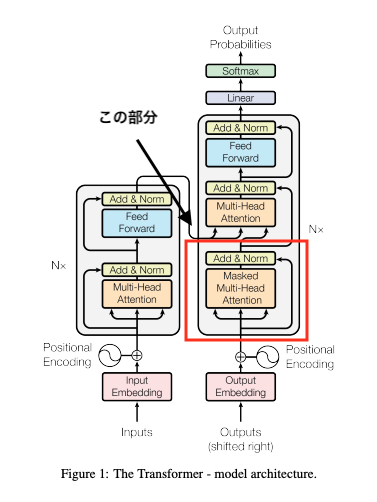
役割:
マスク付きSelf-Attentionは、ターゲットシーケンス生成時に過去のトークンのみを参照し、未来の情報を遮断する仕組みです。Attentionスコア計算時に未生成のトークンに対応する部分をマスク(無視)し、文脈に沿った自然な生成を学習します。この処理により、文法的整合性や文脈情報が正確に捉えられ、逐次的な生成プロセスに忠実なモデル学習が可能になります。
- Mask Multi-Head Attentionの役割
- Maskは主にデコーダー側のMulti-Head Attentionに適用され、自己アテンション(Self-Attention)の一部として機能します。具体的には、ターゲットシーケンス生成時に未生成の未来トークンを参照しないようにするため、マスク処理を使用します。この処理では、ソフトマックス計算時に現在のトークン以降の情報を遮断します。これにより、過去の文脈情報のみを活用しながら、次のトークンを予測することが可能になります。この仕組みは、翻訳やテキスト生成タスクで情報漏洩を防ぐ重要な役割を果たします。
仕組み:
エンコーダーと同様に、Query、Key、Valueはターゲットシーケンスから生成されます。ただし、マスク処理を用いて、現在のトークン以降の未来の情報を遮断し、過去の情報だけを参照できるようにします。
Self-Attention(デーコーダー部分)の実装)
- この部分はデコーダー部分のマスクありのSelf-Attentionの実装です。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadSelfAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.head_dim = embed_size // num_heads
self.num_heads = num_heads
self.embed_size = embed_size
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, queries, mask=None):
N = queries.shape[0] # Batch size
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Linear transformation to obtain Query, Key, and Value matrices
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Split embedding into self.num_heads pieces
values = values.view(N, value_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
keys = keys.view(N, key_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
queries = queries.view(N, query_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# Scaled dot-product attention
scores = torch.matmul(queries, keys.permute(0, 1, 3, 2)) / (self.head_dim ** 0.5)
# Apply mask if provided
if mask is not None:
# Mask shape should match scores shape: (batch_size, num_heads, query_len, key_len)
scores = scores.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(scores, dim=-1)
# Compute weighted sum of values
out = torch.matmul(attention, values)
# Reshape back to original dimensions
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(N, query_len, self.embed_size)
# Final linear layer
return self.fc_out(out)
# Example usage
def generate_subsequent_mask(size):
""" Generate a mask to prevent attention to future positions. """
mask = torch.tril(torch.ones(size, size)).unsqueeze(0).unsqueeze(0) # Shape: (1, 1, size, size)
return mask
# Define parameters
embed_size = 128
num_heads = 8
seq_len = 10
batch_size = 2
# Create dummy inputs
x = torch.rand(batch_size, seq_len, embed_size) # Input tensor
# Initialize model
attention = MultiHeadSelfAttention(embed_size, num_heads)
# Generate mask
mask = generate_subsequent_mask(seq_len)
# Forward pass
output = attention(x, x, x, mask)
print("Output shape:", output.shape)Output shape: torch.Size([2, 10, 128])Cross-Attentionの仕組み(デコーダー)
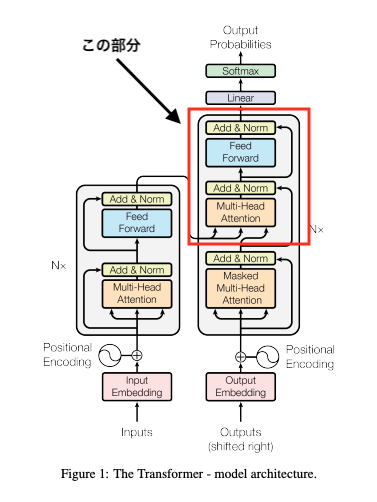
役割:
相互アテンション(Cross-Attention)は、エンコーダ-デコーダアーキテクチャで、エンコーダの出力(ソース系列)とデコーダの入力(ターゲット系列)との関連性を計算する仕組みです。デコーダがエンコーダの情報を基に、次に生成するトークンを適切に判断するための重要なプロセスです。
特徴:
Self-Attentionが同一系列内の関連性を計算するのに対し、Cross-Attention(相互アテンション)は異なる系列間の関係性を学習します。主にTransformerのデコーダで使われ、入力系列の中で出力系列の生成に最も関連する情報を動的に特定する役割を担います。
具体的な仕組み
相互アテンションは、Scaled Dot-Product Attentionを活用して以下のプロセスを実行します。先ほどSelf-Attention(エンコーダー部分)で説明した補足として相互アテンションでは以下の役割があります。
- 入力と出力
- 相互アテンションでは、エンコーダの出力をKeyとValue、デコーダの中間表現をQueryとして利用して関連性を計算します。
- 計算プロセス
- Query, Key, Valueの生成
- デコーダの中間表現をQueryに変換し、エンコーダの出力からKeyとValueを生成して関連性を計算します。
- Query, Key, Valueの生成
- 関連度の計算
- 関連度の計算では、QueryとKeyの内積を求め、Keyの次元数の平方根でスケーリングします。その後、ソフトマックス関数で正規化し、どのエンコーダ出力が重要かを確率分布として判断します。
- コンテキストベクトルの生成
- コンテキストベクトルは、重み付けされたValueを加重平均して生成されます。このベクトルは、デコーダの次のステップで使用され、出力生成に役立ちます。
数式
- Cross-Attentionでは、クエリ $Q$ がターゲット系列に依存し、キー $K$ と値 $V$ が入力系列に依存します。この数式により、ターゲット側の単語が、ソース側のどの単語に注目すべきかを計算します。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V$$
- $Q$:デコーダの出力から計算されるクエリ行列
- $K$、$V$:エンコーダの出力から計算されるキーと値の行列
- $d_k$:キーの次元数(スケーリングのため)
相互アテンションの効果
| 効果 | 説明 |
|---|---|
| 重要情報の抽出 | 入力系列(エンコーダの出力)の中から、出力に最も関連する部分に注意を集中し、無駄のない情報利用を可能にします。 |
| 文脈を反映した生成 | デコーダがエンコーダ出力全体を参照しながら、文脈に応じて動的にトークンを生成します。 |
| 効率性の向上 | ソフトマックス関数で関連度を確率分布に変換し、スケーリングにより安定した計算を実現します。複数トークン間の適切な情報選択を効率的に行えます。 |
Cross-Attentionの実装)
- Self-Attentionとの実装の違いは??
- Self-Attentionは、シーケンス内の各位置が他の位置にどれだけ注意を払うべきかを計算する仕組みで、エンコーダーやデコーダーの自己注意層で使用されます。
- Cross-Attentionは、デコーダーがエンコーダーの出力に基づいて注意を払う仕組みで、エンコーダーの出力(キーとバリュー)とデコーダーの入力(クエリ)を利用します。これにより、入力と出力間の関連性を動的に学習します。
- マスクの使用が可能
- またCross-Attentionは図解には記載されていませんが、マスクを適用して特定の位置への注意を防ぐことも可能です。これにより、モデルの性能が向上し、不要な注意を防ぐことができます
import torch
import torch.nn as nn
class CrossAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(CrossAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.num_heads = num_heads
self.head_dim = embed_size // num_heads
self.scale = self.head_dim ** 0.5
self.query = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.value = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
self.softmax = nn.Softmax(dim=-1)
def forward(self, query_input, key_input, value_input, mask=None):
N = query_input.shape[0]
# Linear projections
Q = self.query(query_input)
K = self.key(key_input)
V = self.value(value_input)
# Split the embedding into self.num_heads different pieces
Q = Q.view(N, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(N, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(N, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-1e20"))
attention_weights = self.softmax(scores)
# Weighted sum of values
output = torch.matmul(attention_weights, V)
output = output.permute(0, 2, 1, 3).contiguous()
output = output.view(N, -1, self.num_heads * self.head_dim)
# Final linear layer
output = self.fc_out(output)
return output, attention_weights
# テスト用データ
embed_size = 64
num_heads = 8
batch_size = 8
query_len = 5
key_value_len = 10
query = torch.rand((batch_size, query_len, embed_size))
key = torch.rand((batch_size, key_value_len, embed_size))
value = torch.rand((batch_size, key_value_len, embed_size))
# マスクの生成(例としてランダムなマスクを使用)
mask = torch.randint(0, 2, (batch_size, 1, query_len, key_value_len)).bool()
cross_attention = CrossAttention(embed_size, num_heads)
# output, attention_weights = cross_attention(query, key, value)
output, attention_weights = cross_attention(query, key, value, mask)
print("Output shape:", output.shape)
print("Attention Weights shape:", attention_weights.shape)Output shape: torch.Size([8, 5, 64])
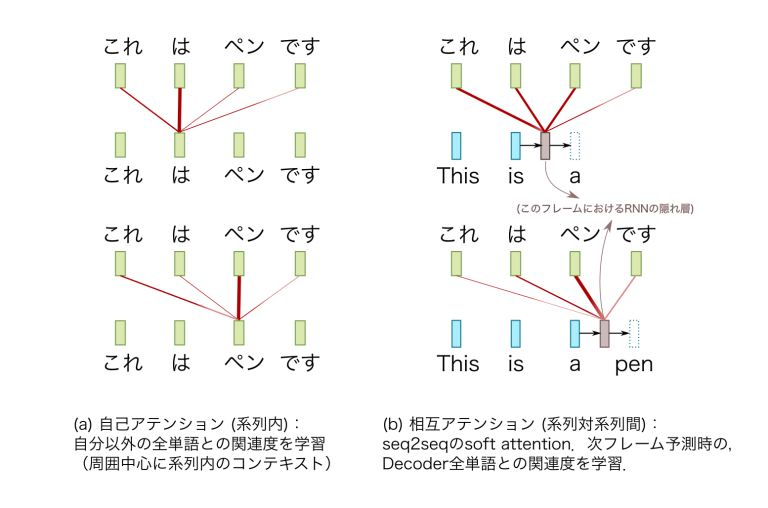
Attention Weights shape: torch.Size([8, 8, 5, 10])自己アテンション(Self-Attention) と 相互アテンション(Cross-Attention)の違い
- 自己アテンションは同一系列内で文脈を学習し、情報を豊かにします。一方、相互アテンションは異なる系列間での関連性を学習し、翻訳などで次の単語を生成するための基盤となります。それぞれの役割が明確であり、Transformerモデルのエンコーダ-デコーダ構造の中心的な役割を担っています。
自己アテンション(Self-Attention)と相互アテンション(Cross-Attention, 相互注意)の違い
| 項目 | Self-Attention | Cross-Attention |
|---|---|---|
| 処理対象 | 同一系列内のトークン間(Query, Key, Value)の関係を計算 | 異なる系列間(エンコーダ出力(Key, Value)とデコーダのQuery)の関係を計算 |
| 使用箇所 | 主にエンコーダで使用 | 主にデコーダで使用 |
| 目的 | 文脈情報の学習(系列内の文脈的な情報を強化する) | 入力と出力間の関連性を学習(入力系列(エンコーダ出力)に基づく出力トークンの生成)し、出力を生成する |
| 計算の基盤 | Scaled Dot-Product Attentionを用いてトークン間の関連性を計算 | 同じ計算手法を用いて異なる系列間の関連性を計算 |
具体的な例
Transformerの利点と課題
| 利点 | 課題 |
|---|---|
| 並列処理:RNNの逐次処理に依存せず、計算が高速。 | 計算資源の消費:Attentionの全単語間計算が必要で、大規模データではメモリ負荷が高い。 |
| 長文対応:文中の全単語間の関係を効率的に計算し、長文にも強い。 | 順序情報の課題:Position Encodingが必要で、順序依存タスクでは設計が重要。 |
| 汎用性:翻訳、要約、質問応答、画像処理など、幅広いタスクで応用可能。 | データ量依存:高い性能を発揮するには大量のデータが必要。 |
Transformerの全体を構成するコードの実装例)
先ほど説明した3種類のAttention(MultiHeadAttention, Self-Attention, Cross-Attention)の実装を行います。
ライブラリのインポート
import torch
import torch.nn as nn
import torch.nn.functional as FMultiHeadAttentionクラスの定義
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.head_dim = embed_size // num_heads
self.num_heads = num_heads
self.embed_size = embed_size
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)フォワードパスの定義
def forward(self, values, keys, queries, mask=None):
N = queries.shape[0] # バッチサイズ
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 埋め込みをself.num_heads個に分割
values = values.view(N, value_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
keys = keys.view(N, key_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
queries = queries.view(N, query_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# スケールド・ドットプロダクト・アテンション
scores = torch.matmul(queries, keys.permute(0, 1, 3, 2)) / (self.head_dim ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(scores, dim=-1)
out = torch.matmul(attention, values)
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(N, query_len, self.embed_size)
return self.fc_out(out)TransformerBlockクラスの定義
- これはSelf-Attentionの部分の実装を行っています。また、正規化層、ドロップアウト層などの実装も同時に行っています。
class TransformerBlock(nn.Module):
def __init__(self, embed_size, num_heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, num_heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query)) # スキップ接続
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x)) # スキップ接続
return out- スキップ接続の必要性は?
- スキップ接続は、Transformerのように多数のブロックを重ねた深いモデルの学習を安定させるための技術です。層の出力をその入力に直接加算することで、逆伝播時に勾配が層を迂回して伝わる「近道」を作り、勾配消失問題を緩和します。
- これにより、モデルは入力情報との「差分」のみを学習すればよくなり、元の重要な情報を失うことなく、文脈に応じた特徴を効率的に獲得できます。この仕組みが、Transformerが多数の層を重ねて高性能化することを可能にしています。
- スキップ接続は、Transformerのように多数のブロックを重ねた深いモデルの学習を安定させるための技術です。層の出力をその入力に直接加算することで、逆伝播時に勾配が層を迂回して伝わる「近道」を作り、勾配消失問題を緩和します。
CrossAttentionクラスの定義
- Cross-Attentionは、異なる入力シーケンスをクエリ、キー、バリューとして使用します。
class CrossAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(CrossAttention, self).__init__()
assert embed_size % num_heads == 0, "Embedding size must be divisible by number of heads"
self.head_dim = embed_size // num_heads
self.num_heads = num_heads
self.embed_size = embed_size
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, queries, mask=None):
N = queries.shape[0] # バッチサイズ
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 埋め込みをself.num_heads個に分割
values = values.view(N, value_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
keys = keys.view(N, key_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
queries = queries.view(N, query_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# スケールド・ドットプロダクト・アテンション
scores = torch.matmul(queries, keys.permute(0, 1, 3, 2)) / (self.head_dim ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(scores, dim=-1)
out = torch.matmul(attention, values)
out = out.permute(0, 2, 1, 3).contiguous()
out = out.view(N, query_len, self.embed_size)
return self.fc_out(out)Encoderクラスの定義(Position Encodingの実装)
- Position Encodingは、シーケンス内の各トークンの位置情報を埋め込みベクトルに追加するために使用されます。これにより、モデルはトークンの順序を認識することができます。
class Encoder(nn.Module):
def __init__(self, src_vocab_size, embed_size, num_layers, num_heads, device, forward_expansion, dropout, max_length):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(embed_size, num_heads, dropout, forward_expansion)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return outDecoderBlockクラスの定義
- Self-AttentionとCross-Attentionを組み合わせて、シーケンス内およびシーケンス間の関連性を計算します。また、LayerNormとDropoutを用いて、正規化と過学習防止を行い、モデルの安定性と汎化性能を向上させます。
class DecoderBlock(nn.Module):
def __init__(self, embed_size, num_heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, num_heads)
self.cross_attention = CrossAttention(embed_size, num_heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.norm3 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
query = self.dropout(self.norm1(attention + x)) # スキップ接続
cross_attention = self.cross_attention(enc_out, enc_out, query, src_mask)
x = self.dropout(self.norm2(cross_attention + query)) # スキップ接続
forward = self.feed_forward(x)
out = self.dropout(self.norm3(forward + x)) # スキップ接続
return outDecoderクラスの定義
- デコーダーは、エンコーダーの出力を基に次のトークンを予測・生成します。
class Decoder(nn.Module):
def __init__(self, trg_vocab_size, embed_size, num_layers, num_heads, forward_expansion, dropout, device, max_length):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_size, num_heads, forward_expansion, dropout, device)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
x = layer(x, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return outTransformerクラスの定義
- Transformerクラスは、エンコーダーとデコーダーを組み合わせて、完全なTransformerモデルを構築するための重要な役割を果たします。また、
make_src_maskはソース系列のマスクを生成し、make_trg_maskはターゲット系列のマスクを生成するメソッドです。
class Transformer(nn.Module):
def __init__(self, src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, embed_size=256, num_layers=6, forward_expansion=4, num_heads=8, dropout=0.1, device="cuda", max_length=100):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, embed_size, num_layers, num_heads, device, forward_expansion, dropout, max_length)
self.decoder = Decoder(trg_vocab_size, embed_size, num_layers, num_heads, forward_expansion, dropout, device, max_length)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return outハイパーパラメータの設定とモデルのインスタンス化
# ハイパーパラメータの設定
src_vocab_size = 10000 # ソース語彙サイズ
trg_vocab_size = 10000 # ターゲット語彙サイズ
src_pad_idx = 0 # パディングインデックス
trg_pad_idx = 0 # パディングインデックス
embed_size = 256
num_layers = 6
forward_expansion = 4
num_heads = 8
dropout = 0.1
max_length = 100
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# モデルのインスタンス化
model = Transformer(
src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx,
embed_size, num_layers, forward_expansion, num_heads,
dropout, device, max_length
).to(device)ダミーデータの作成
# ダミーデータの作成
batch_size = 32
src_seq_length = 50
trg_seq_length = 60
src = torch.randint(1, src_vocab_size, (batch_size, src_seq_length)).to(device)
trg = torch.randint(1, trg_vocab_size, (batch_size, trg_seq_length)).to(device)オプティマイザと損失関数の設定
# オプティマイザと損失関数の設定
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss(ignore_index=trg_pad_idx)トレーニングループの例
# トレーニングループの例
num_epochs = 10
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# trg_in: デコーダへの入力(最後のトークンを除く)
trg_in = trg[:, :-1]
# trg_out: 損失計算用ラベル(最初のトークンを除く)
trg_out = trg[:, 1:]
output = model(src, trg_in) # (Batch, trg_len-1, trg_vocab_size)
output = output.reshape(-1, output.shape[2]) # (Batch*(trg_len-1), trg_vocab_size)
trg_out = trg_out.reshape(-1) # (Batch*(trg_len-1))
loss = criterion(output, trg_out)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")Epoch 8/10, Loss: 9.1729
Epoch 9/10, Loss: 9.1145
Epoch 10/10, Loss: 9.0978マスクの用途と役割
- どちらもSelf-Attentionに対するマスクであり、TransformerモデルのAttention計算の妥当性を維持するために重要な役割を果たします。
| マスク種類 | 適用場所 | 目的 |
|---|---|---|
| make_src_mask | エンコーダのSelf-Attention | パディングトークンを無視し、必要な情報だけをAttention計算に利用する。 |
| make_trg_mask | デコーダのSelf-Attention | 未来のトークンを参照しないようにし、逐次的な生成プロセスを守る。 |
論文
『Attention Is All You Need』

- 再帰・畳み込みの排除
- Transformerは、再帰(RNN)や畳み込み(CNN)を完全に排除し、自己注意機構を活用することで、並列処理と計算効率を大幅に向上させました。RNNが逐次処理によりトレーニング時間が長くなる一方で、Transformerはトークン間の依存関係を一括で計算可能です。また、CNNのように長距離依存を多層で学習する必要がなく、効率的に関係性をモデリングできます。この結果、大規模データでも短時間で高精度を達成し、自然言語処理の分野で新たな基準を打ち立てました。
- 機械翻訳での画期的な性能
- Transformerは、WMT 2014英独翻訳でBLEUスコア28.4、英仏翻訳で41.8を達成し、従来モデルを大幅に上回る性能を示しました。この成果は、自己注意機構を活用して効率的に依存関係を学習できる点や、8つのGPUでわずか3.5日間のトレーニングで高精度を実現したことに基づきます。従来のRNNやCNNモデルと比較して計算効率が高く、短期間で優れた翻訳結果を出せることが、商業利用や研究分野での活用を促進しています。
- 汎用性と応用範囲
- Transformerは、翻訳だけでなく構文解析や要約、質問応答など多様な自然言語処理タスクに適用可能です。自己注意機構により、文中の長距離依存関係を効率的に学習し、高精度な結果を短時間で得られます。計算効率の高さと汎用的なアーキテクチャにより、法律や医療、教育などの分野での実用化も進展。タスク固有の設計を必要とせず、微調整だけで幅広い用途に対応できる点が特長です。
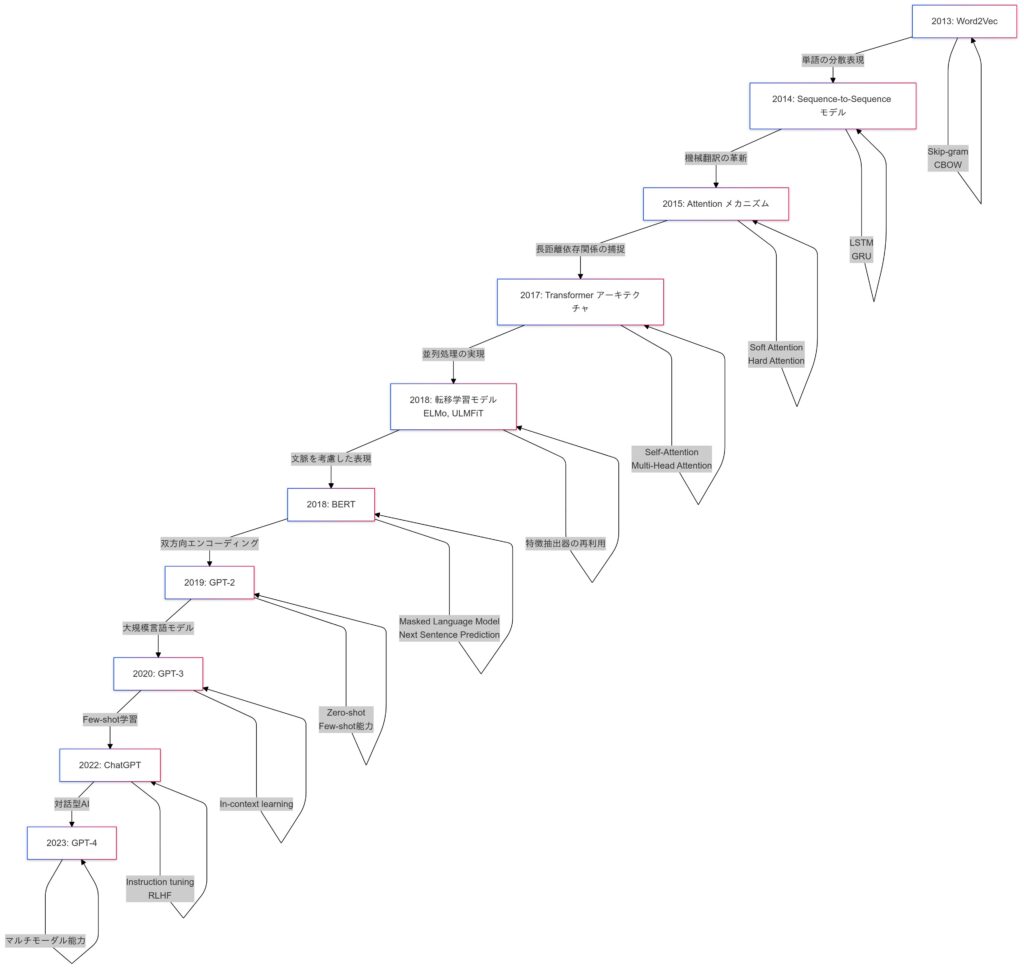
自然言語処理への応用
次に、先ほど説明したTransformerを基盤とした応用モデルである「BERT」と「GPTシリーズ」について、具体的な仕組みや応用例を詳しく解説します。
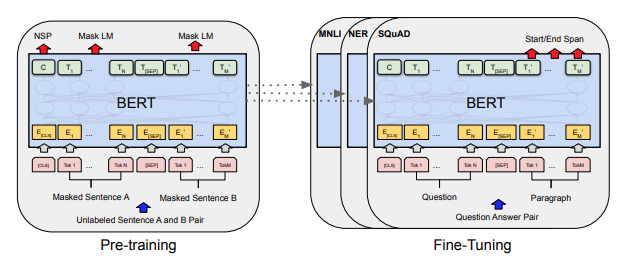
BERT
BERTは2018年にGoogleが提案した双方向Transformerモデルで、双方向の文脈モデリングによりNLPタスクに革命をもたらしました。それ以前のモデル(例: GPT)が単方向で文脈を考慮していたのに対し、BERTは双方向の文脈理解と転移学習を導入し、多様なタスクで圧倒的な精度を達成しました。計算コストの高さが課題ですが、現在もRoBERTaやDistilBERTなど多くの派生モデルや技術の基盤として活用されています。
特徴
- 双方向の文脈モデリング
- 文中の単語を左右両方向から同時に捉えることで、より正確な文脈理解を実現します。例えば、「私は本が好きです」という文では、「本」の文脈を「私は」と「好きです」の両方向から補完します。
- 事前学習とファインチューニング
- 大規模データで事前学習を行い、その後、タスク固有のデータを用いて微調整(ファインチューニング)します。
- マスク付き言語モデル
- 文中の一部の単語を隠し、その隠れた単語を予測することで、双方向の文脈を学習します。
- 次文予測
- 文と文の関係性(連続性があるかどうか)を学習し、文ペアに関連するタスクの精度を向上させます。
数式
- Attention計算
- Self-Attentionを用いて文脈を学習します。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V$$
- MLM損失関数
$$L_{\text{MLM}} = – \sum_{i \in M} \log P(x_i \mid x_{\setminus i})$$
$M$:マスクされた単語の位置。$x_i$:マスクされた単語。$x_{/i}$:マスクされた単語以外の文脈。
- NSP損失関数
$$L_{\text{NSP}} = – \left[ y \log P(y = 1 \mid x) + (1 – y) \log P(y = 0 \mid x) \right]$$
メリットとデメリット
| メリット | デメリット |
|---|---|
| 高い汎用性:文書分類、翻訳、質問応答など、幅広いNLPタスクに適用可能。 | 計算資源の負担:モデルサイズが大きく、GPUやTPUなどの高性能計算環境が必須。 |
| 転移学習の効果:事前学習済みモデルを微調整することで、タスク固有の学習コストを大幅に削減。 | 事前学習コスト:大量のデータと長時間のトレーニングが必要。 |
| 高精度:双方向文脈を考慮することで、従来モデルを超える精度を達成。 | 次文予測の課題:NSPタスクは一部のNLPタスクには不要で、後続モデル(RoBERTaなど)では削除される傾向。 |
適用例
| 適用例 | 説明 |
|---|---|
| 質問応答 | SQuAD(Stanford Question Answering Dataset)での高精度な回答生成。 |
| 文書分類 | 感情分析、スパム検知。 |
| 自然言語推論 | 文ペア間の関連性解析。 |
| 名前付きエンティティ認識 | テキストからの特定のエンティティ抽出(例: 人名や地名)。 |
BERTの実装)
- このコードでは、Hugging FaceのTransformersライブラリを使用して、日本語のBERTモデルをロードし、テキストの分類タスクを実行します。
import torch
from transformers import BertTokenizer, BertForSequenceClassification
# モデルとトークナイザーのロード
model_name = "cl-tohoku/bert-base-japanese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# テスト用の日本語テキスト
texts = [
"この映画はとても感動的で、最後まで涙が止まりませんでした。",
"このレストランの料理は美味しいですが、サービスが遅いです。",
"この本は非常に退屈で、読むのに時間がかかりました。",
"この製品は高品質で、非常に満足しています。",
"このホテルの部屋は清潔で快適でしたが、スタッフの対応が悪かったです。"
]
# テキストのトークナイズとテンソルへの変換
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True, max_length=128)
inputs = {key: value.to(device) for key, value in inputs.items()}
# モデルの推論
with torch.no_grad():
outputs = model(**inputs)
# ログイットを取得し、ソフトマックス関数を適用して確率を計算
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
# 結果の表示
for i, text in enumerate(texts):
print(f"テキスト: {text}")
print(f"ポジティブ確率: {probs[i][1].item():.4f}, ネガティブ確率: {probs[i][0].item():.4f}")テキスト: この映画はとても感動的で、最後まで涙が止まりませんでした。
ポジティブ確率: 0.5446, ネガティブ確率: 0.4554
テキスト: このレストランの料理は美味しいですが、サービスが遅いです。
ポジティブ確率: 0.4917, ネガティブ確率: 0.5083
テキスト: この本は非常に退屈で、読むのに時間がかかりました。
ポジティブ確率: 0.4487, ネガティブ確率: 0.5513
テキスト: この製品は高品質で、非常に満足しています。
ポジティブ確率: 0.4927, ネガティブ確率: 0.5073
テキスト: このホテルの部屋は清潔で快適でしたが、スタッフの対応が悪かったです。
ポジティブ確率: 0.5060, ネガティブ確率: 0.4940論文
『BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding』

- 双方向性の導入
- BERTの革新は双方向の文脈を学習できる仕組みの導入です。従来の一方向モデルは片側の文脈しか考慮できず、文の完全な意味を捉えるのが難しい課題がありました。BERTは、隠された単語を周囲の文脈から予測するMasked Language Model(MLM)と、2文の関連性を判定するNext Sentence Prediction(NSP)の2つのタスクを活用。これにより、左側と右側の文脈情報を同時に活用する能力がモデルに加わり、幅広い自然言語処理タスクで高い性能を実現しました。
- 幅広いNLPタスクでの性能向上
- BERTは、GLUEやSQuADなどの主要ベンチマークで大幅な性能向上を達成しました。GLUEスコアを80.5%(+7.7%)に引き上げたほか、SQuAD v1.1ではF1スコア93.2(+1.5)、v2.0では83.1(+5.1)を記録。特に質問応答や自然言語推論タスクで高い精度を示し、微調整のみで最先端の結果を達成しました。この汎用性により、BERTは多様なNLPタスクに適用可能な新しい標準モデルとなりました。
- 転移学習の効率性
- BERTは、事前学習済みモデルを微調整するだけで多様なNLPタスクに適用可能です。複雑なタスク固有の設計が不要で、特にラベル付きデータが少ないタスクでも高精度を発揮します。双方向Transformer構造により、文脈の全体像を捉える能力が向上し、幅広い言語知識を活用可能です。この効率的な転移学習により、BERTはNLPの汎用性と生産性を飛躍的に向上させました。
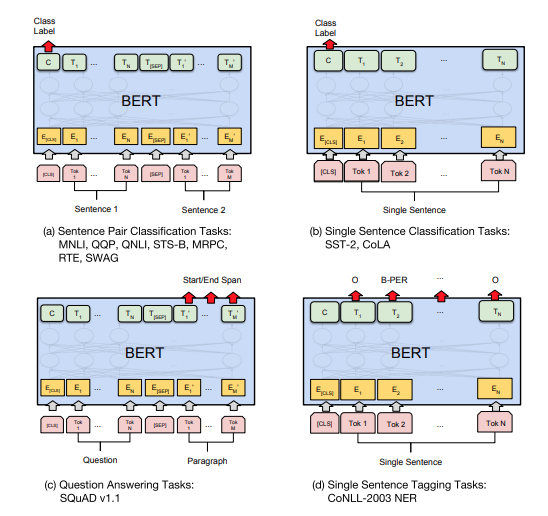
GPTシリーズ
GPT(Generative Pre-trained Transformer)は、OpenAIが開発した自然言語生成に特化したTransformerベースのモデルで、初代GPTからGPT-4まで進化を遂げました。Transformerのデコーダー部分のみを使用し、自己回帰型モデルとして未来のトークンを逐次予測する仕組みで自然な文生成を実現します。自然言語生成や汎用的なNLPタスクで高い性能を発揮する一方、計算リソースの負荷やバイアス問題が課題として残されています。
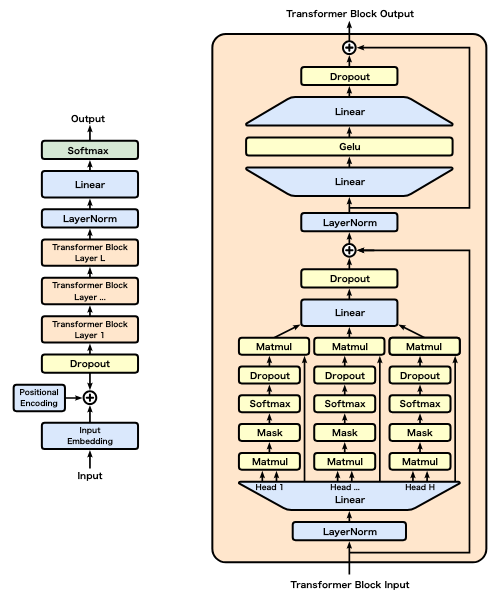
動作イメージの説明
- この図は、Transformerデコーダーブロックの構造を示しており、GPTモデルのアーキテクチャに対応しています。入力トークンに位置情報を加算後、Self-Attentionとフィードフォワードネットワークを通じて処理を行います。マスク処理により未来のトークンを参照せず、残差接続やLayerNormで安定性を向上。これを複数層繰り返すことで、自己回帰型の自然言語生成を実現します。GPTは、このデコーダー部分のみを使用したモデルです。
特徴
| 特徴 | 説明 |
|---|---|
| 自己回帰型アーキテクチャ | 文章の次の単語を逐次予測し、文脈に適合した文を生成。 |
| 単方向文脈モデリング | 入力トークンの左側(過去)の情報に基づいて、次のトークンを生成。双方向モデル(BERT)とは異なり、生成に特化。 |
| 大規模事前学習 | インターネットから収集した膨大なデータで事前学習を行い、文法、知識、論理構造を学習。 |
| 拡張性 | パラメータ数の増加に伴い、性能が指数的に向上(GPT: 110M → GPT-2: 1.5B → GPT-3: 175B→GPT-4: 1,760B)。 |
数式
- 自己回帰型生成
- GPTは以下の条件付き確率を最大化します。
$$P(x_1, x_2, \ldots, x_n) = \prod_{t=1}^n P(x_t \mid x_1, x_2, \ldots, x_{t-1})$$
- $x_t$: $t$ 番目のトークン。
- Attention計算
- Self-Attention機構を用いて、過去のすべてのトークンを考慮します。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V$$
- 位置埋め込み (Position Encoding)
- GPTは単語順序を保持するため、以下の埋め込みを加えます。
$$PE(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right), \quad
PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)$$
メリットとデメリット
| メリット | デメリット |
|---|---|
| 自然な文生成:人間に近い文章を生成でき、多様なNLPタスクに適用可能。 | エネルギー消費:トレーニングに莫大なエネルギーが必要で、環境負荷が高い。 |
| 汎用性:事前学習済みモデルを微調整するだけで多種多様なタスクを処理。 | データ依存:トレーニングデータの品質に大きく依存し、不適切なデータが影響を与える。 |
| スケーラビリティ:モデルサイズと性能の間に明確な相関があり、性能向上が期待できる。 | コスト:商用利用には高性能なハードウェアが必要で、コストがかかる。 |
適用例
| 適用例 | 説明 |
|---|---|
| 対話モデル | ChatGPTのような高度な対話生成。 |
| コンテンツ生成 | 記事、詩、ストーリーの自動生成。 |
| コード生成 | GitHub Copilotのようなプログラミング支援。 |
| 翻訳 | 多言語間のテキスト変換。 |
| 質問応答 | ユーザーの質問に適切な回答を生成。 |
それぞれのGPTの動作イメージ
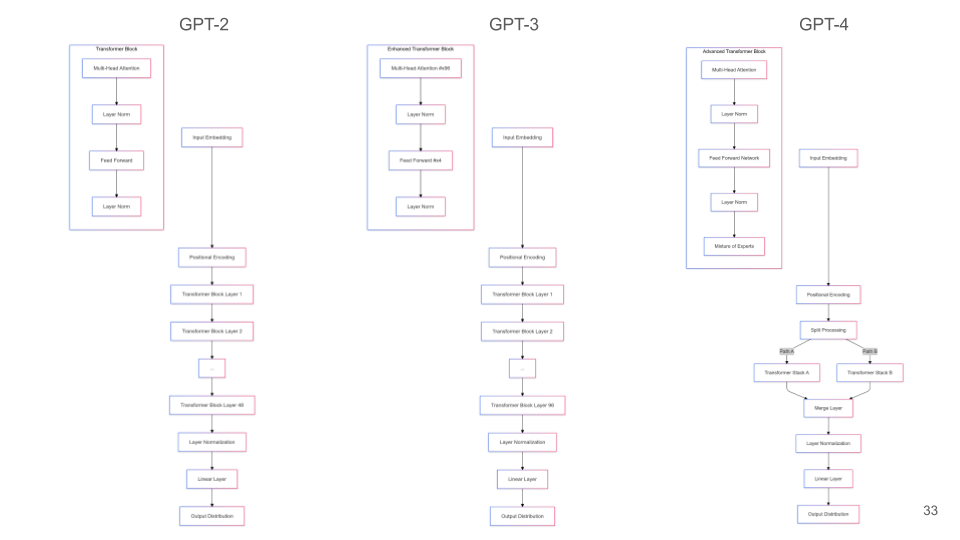
| モデル | 層数 | アーキテクチャの特徴 | 備考 |
|---|---|---|---|
| GPT-2 | 48 | 標準的なTransformerブロックを持つ基本的なTransformerアーキテクチャ。 | 初代GPTからの進化版で、生成能力が向上。 |
| GPT-3 | 96 | モデルのサイズと複雑さが大幅に増加したスケールアップされたアーキテクチャ。 | パラメータ数が1750億に達し、多様なタスクに対応。 |
| GPT-4 | 非公開 | 分岐した処理パスやMixture of Experts(専門家の混合)などの追加コンポーネントを備えた、より高度なアーキテクチャ。 | 正確な詳細は公開されていないが、性能と効率が向上。 |
GPT-2の実装例)
- GPT-2モデルは与えられた入力テキストに応じた新しいテキストを生成します。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
# モデルとトークナイザーの読み込み
model_name = "gpt2"
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# pad_token を eos_token に設定
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.eos_token_id
# padding_side を left に設定
tokenizer.padding_side = 'left'
# デバイスの設定
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# 入力テキスト(より日常的な内容に変更)
input_text = (
"Today, I went to the coffee shop with my friends and we had a great time discussing our weekend plans."
)
# トークナイズとattention_maskの作成
encoding = tokenizer.encode_plus(
input_text,
add_special_tokens=True,
return_tensors="pt",
padding='max_length',
truncation=True,
max_length=50
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
# テキスト生成
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=100, # 生成するテキストの最大長(トークン数)
num_return_sequences=1, # 生成するシーケンスの数
no_repeat_ngram_size=2, # 繰り返しを避けるn-gramのサイズ
temperature=0.7, # 温度パラメータ(生成の多様性)
top_k=50, # 上位k個のトークンから選択
top_p=0.95, # 累積確率がtop_pを超えるまでトークンを選択
do_sample=True, # サンプリングを有効にする
pad_token_id=tokenizer.eos_token_id # pad_token_idの設定
)
# 結果のデコード
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("Generated Text:", generated_text)全体の流れ
- 必要なライブラリをインポートし、GPT-2モデルとトークナイザーをロード。デバイスやパディングの設定を調整。
- 入力テキストをトークナイズし、パディングとマスクを適用。
- モデルでテキストを生成し、生成パラメータを調整して多様性と一貫性を確保。
- 結果をデコードしてテキストを表示。
論文
論文1:「Universal Language Model Fine-tuning for Text Classification」

- 汎用的なNLP転移学習の実現
- ULMFiTは、NLPにおける転移学習を汎用化し、タスク固有のカスタマイズを不要にしました。一般ドメインで事前学習した言語モデルを活用し、少量のラベル付きデータでも高性能を実現します。たとえば、IMDbデータセットでは、わずか100個のラベル付きデータで、従来モデルが100倍のデータで達成する精度を上回りました。また、エラー率を18-24%削減し、多様なタスクに対応可能な柔軟性を提供しています。この手法により、NLPモデルの効率的な活用が大幅に進展しました。
- 画期的なファインチューニング技術
- ULMFiTは、「分散ファインチューニング」「斜め三角学習率」「段階的解凍」という新技術を導入し、転移学習の課題である破滅的忘却を克服しました。分散ファインチューニングでは層ごとに異なる学習率を適用し、斜め三角学習率では初期に急速な学習を進めながら後半で安定化させます。さらに、段階的解凍により、事前学習の知識を保持しつつタスクへの適応を実現。これらにより、少量データや異なるドメインでも安定して高性能な学習が可能となりました。
論文2:『Language Models are Few-Shot Learners』

- 大規模モデルによる少数ショット学習の性能向上
- GPT-3は、1750億パラメータという圧倒的な規模を持つ自己回帰型言語モデルです。この大規模化により、従来のモデルが必要とした数万サンプルのトレーニングやファインチューニングなしで、数個の例だけで新しいタスクに適応する「少数ショット学習」が可能となりました。文法訂正や読解、推論など多様なタスクで高い性能を発揮し、タスク非依存の汎用性を実証。これにより、迅速かつ効率的なタスク適応が可能になり、NLPの可能性を大きく広げています。
- タスク非依存かつ多様な応用可能性
- GPT-3は、文法修正や抽象的概念生成、読解、推論といった幅広いタスクに対応可能な汎用性を持ちます。この「タスク非依存性」により、従来の個別モデルを必要としない効率性を実現しました。一方で、ゼロショット設定での性能低下や双方向コンテキスト処理の課題といった限界も明らかになりました。これらを踏まえ、GPT-3はNLPの可能性を広げる一方で、さらなる改善の余地がある重要なモデルと言えます。
論文3:『Scaling Laws for Neural Language Models』

- 損失のべき乗則スケーリング
- この論文では、言語モデルの損失(クロスエントロピー損失)がモデルサイズ、データセットサイズ、計算量に応じてべき乗則的に減少することを示しました。特に、モデルサイズを8倍に増加させる際、データセットサイズを5倍にするだけで効率的な性能向上が可能である具体的な指針が示されています。また、これにより過学習やリソース不足を防ぎつつ、限られた計算リソースでも効果的なトレーニング戦略を立てられるようになります。この知見は、リソース配分を最適化した言語モデルの開発に貢献します。
- クリティカルバッチサイズと効率的学習
- この研究では、クリティカルバッチサイズ(学習効率を維持できる最大バッチサイズ)が損失の減少に応じて倍増するべき乗則的な関係を示しました。特に、最適なバッチサイズを選ぶことで、トレーニングステップ数を削減しつつ効率的な学習が可能になります。この知見により、固定された計算予算下でもリソースを最大限に活用し、大規模モデルのトレーニングコスト削減や速度向上を実現できる具体的な戦略が提供されます。
時系列データ解析におけるTransformerの応用
なぜTransformerが時系列データ解析に適しているのか?
- 時系列データ解析は、株価予測や需要予測などで重要ですが、長期的な依存関係の処理には従来のRNNやLSTMに限界がありました。TransformerはSelf-Attention機構を活用することで並列処理を可能にし、これらの課題を効果的に解決しています。
時系列データの課題
- 長期依存関係のモデリング
- 時系列データでは、過去の重要なイベントが現在や未来に影響を与えることがあります。例えば、数ヶ月前の経済指標が現在の株価に影響を及ぼすことがありますが、従来のモデルではこのような長期的な依存関係を学習するのが難しい場合がありました。
- 非線形構造の複雑さ
- 時系列データは単純な直線的相関だけでなく、非線形なパターンや複雑な因果関係を含むことが多いです。
- ノイズ対応
- 特に金融市場やセンサーデータでは、外れ値やノイズが頻繁に含まれます。これらのノイズを適切に処理しつつ、意味のあるパターンを抽出することが重要です。
RNNからTransformerへの進化
- RNNの課題
- RNNやその改良版であるLSTMやGRUは、逐次処理が必要なため並列処理ができず、計算効率が低いという課題があります。また、長期的な依存関係を十分に捉えられないという限界もあります。
- Transformerの利点
- TransformerはSelf-Attentionを活用してデータ間の全ての依存関係を直接モデル化し、並列処理を可能にします。これにより、大規模データでも効率的に学習できます。
Transformerの時系列データへの応用例
| 応用例 | 説明 | 具体例 |
|---|---|---|
| 株価予測 | 複数の銘柄や指標間の相関をモデル化し、特定のイベントが異なる時間スケールでどのように影響を与えるかを学習します。 | 株式市場の動向予測、イベントドリブンの株価変動分析。 |
| 異常検知 | 工場のセンサーデータや金融市場データを活用した異常検知に応用されます。ノイズや外れ値に強い解析モデルとして機能し、潜在空間を利用して異常な時系列パターンを識別します。 | 工場設備の異常検出、金融取引の不正検知。 |
| 需要予測 | 小売業や物流業界での需要予測に活用され、季節性やイベントの影響を考慮した予測が可能です。 | 季節商品やセール期間中の商品の需要予測。 |
メリットと課題
| メリット | 課題 |
|---|---|
| 並列処理による計算効率の向上。 | 高い計算コストとメモリ使用量。 |
| 長期依存関係や複雑な相関性のモデリング。 | 順序情報を補完するPosition Encodingの設計。 |
| 多次元データを同時に処理できる。 | 特定タスクに合わせたハイパーパラメータの調整が必要。 |
補足説明
- メリット
- 並列処理による計算効率の向上。
- Transformerモデルは自己注意機構(Self-Attention)を活用することで、従来のRNNベースのモデルに比べて並列処理が可能となり、計算効率が大幅に向上します。
- 長期依存関係や複雑な相関性のモデリング。
- 自己注意機構により、入力シーケンス内の全てのトークン間の関係性を同時に捉えることができ、長期的な依存関係や複雑な相関性を効果的にモデル化します。
- 多次元データを同時に処理できる。
- Transformerは多次元の特徴量を一括して処理できるため、画像や音声、テキストなど多様なデータ形式に対応可能です。
- 並列処理による計算効率の向上。
- 課題
- 高い計算コストとメモリ使用量。
- 自己注意機構は入力シーケンスの長さに対して二乗の計算コストがかかるため、大規模なデータセットや長いシーケンスの処理には大量の計算資源とメモリが必要となります。
- 順序情報を補完するPosition Encodingの設計。
- Transformerは並列処理が可能な反面、シーケンスの順序情報を直接的に捉えることができないため、位置埋め込み(Position Encoding)を設計して順序情報を補完する必要があります。
- 特定タスクに合わせたハイパーパラメータの調整が必要。
- Transformerモデルの性能を最大限に引き出すためには、学習率、層数、ヘッド数など多くのハイパーパラメータをタスクに合わせて最適化する必要があります。
- 高い計算コストとメモリ使用量。
時系列データ解析における様々なTransformerの活用例
金融データ予測に関する方法論
- 金融データの予測には、統計的手法から機械学習・ディープラーニングまで、さまざまな方法論が存在します。
| 方法論 | 代表的な手法 | メリット | デメリット |
|---|---|---|---|
| 統計手法 | ARIMA, GARCH, VAR | 解釈性が高い | 複雑なデータには弱い |
| 機械学習 | ランダムフォレスト, XGBoost | 非線形な関係を捉えやすい | 過学習のリスク |
| ディープラーニング | LSTM, Transformer | 高精度な時系列予測が可能 | 計算コストが高い |
| 強化学習 | DQN, PPO | トレーディング戦略の最適化 | 収束が不安定 |
| 量子金融 | 量子ボルツマンマシン | 量子計算の強みを活かせる | 実用化には時間がかかる |
予測手法の選択は、データの特性や目的に応じて決定されます。特に統計手法と機械学習を組み合わせるハイブリッドアプローチが注目されています。
この章ではディープラーニングを使った時系列データ解析における、様々なTransformerの活用例として特に金融時系列データ解析についての方法論をいくつかに分けて説明します。まずは金融時系列データ解析にはどのような種類の方法論があるのかを確認してみましょう。
| 方法 | 説明 |
|---|---|
| 予測 | 株価、為替、金利、仮想通貨価格などの将来予測 |
| ノイズ除去 | 価格データのノイズを除去し、スムーズな時系列を生成する |
| 異常値検出 | 異常な市場変動や急激な価格変動を検出する |
| ボラティリティ予測 | 短期・長期のボラティリティを予測し、リスク管理に活用 |
| リスク管理 | VaR(リスク値)やES(VaRを超えた場合に期待される平均損失額を測る指標)などのリスク指標を計算し、リスク管理に利用 |
| ポートフォリオ最適化 | 過去のリターンデータから最適な資産配分を計算 |
| 市場間の相関分析 | 異なる市場(株式、為替、債券など)の相関関係を解析 |
| マルチスケール学習 | 短期的・長期的な市場トレンドを同時に学習 |
| 市場の状態クラスタリング | 市場のトレンドをクラスタリングし、強気・弱気相場を分類 |
| 強化学習の補助 | 強化学習の状態表現を改善し、最適なトレーディング戦略を構築 |
| 特徴量エンベディング | 時系列データを埋め込みベクトルに変換し、非線形特徴を抽出 |
| イベントインパクト分析 | ニュースやイベントの市場への影響を分析し、価格変動を予測 |
| 因果推論 | 金融市場における因果関係を分析し、マクロ経済指標の影響を理解 |
| 階層的モデリング | 市場全体、セクター、個別銘柄の階層構造をモデル化 |
| モメンタム/リバーサル分析 | 価格トレンドの持続性や反転パターンを分析 |
| 動的ネットワーク分析 | 金融市場の動的な関係(ペアトレードなど)をネットワークとして解析 |
| データ合成 | 時系列データの補完や合成を行い、シミュレーションデータを作成 |
| エコシステム全体の分析 | SNSやニュースデータを統合し、価格変動に与える影響を分析 |
時系列データ解析において、Transformerはさまざまな手法と組み合わせることで、より効果的な分析が可能になります。予測、ノイズ除去、異常検知、ボラティリティ予測、リスク管理 など、目的に応じたアプローチを適切に選択し、組み合わせることが重要です。
本記事では、特に実務で頻繁に活用されるノイズ除去、異常検知、予測 の3つに焦点を当て、それぞれの手法の特徴や活用例を詳しく解説していきます。
ノイズ除去
ノイズ除去は、金融市場の価格データをより正確に分析するために活用されます。具体的には、高頻度取引やボラティリティの高い銘柄の価格変動を平滑化し、時系列データ内の異常値を検出・排除します。また、短期的なニュースや無関係な変動の影響を抑えることで、実際のトレンドに基づいた精度の高い予測を可能にします。
なぜTransformerがノイズ除去に向いているのか?
- Self-Attention機構による重要な情報の選択
- TransformerのSelf-Attention機構は、時系列データ全体を俯瞰しながら、重要なポイント(例えば、過去の価格変動や特定のイベント)を動的に見つけ出し、データ間の依存関係をモデル化します。この過程で、関連性の低いデータ(ノイズ)は相対的に排除される仕組みが自然に備わっています。
- 並列処理で効率的な学習
- TransformerのSelf-Attention機構は、時系列データ全体を一括で処理することにより、ノイズに影響されにくい特徴量を効率よく抽出できます。これにより、長期的な依存関係を捉える際にも、短期的な変動によるノイズの影響を最小限に抑えることが可能です。
- フィルタリング機能の拡張性
- Transformerモデルにデノイジングオートエンコーダや自己教師付き学習を組み合わせることで、ノイズ除去能力をさらに高めることができます。このアプローチは、潜在空間でノイズと有用な情報を効果的に分離するのにも適しています。
Transformerを使ったノイズ除去の実装
今回は前回紹介したデノイジングオートエンコーダを使ってTransformerモデルにデノイジングオートエンコーダを組み合わせたモデルの検証を行ってみます。今回もETHの金融時系列データとして、過去5日間の1分足データを使用します。
またTransformerをモデルに用いる際には注意点としてGPUのメモリ制限の問題をクリアする必要があります。
- GPUのメモリ制限の問題の理由
- Transformerを使う際の制限として、GPUのメモリ量が問題になる主な理由は、自己注意機構 (Self-Attention) の計算負荷がシーケンスの長さに対して二乗で増加することです。特に、金融時系列データのように長いシーケンスを扱う場合、メモリ消費が急激に増え、計算資源の制約が厳しくなります。
- この解決案については後で触れますので今回はここでTransformerを使えるようになるためにモデルの軽量化として低精度計算を用いてFP32(32-bit浮動小数点)をFP16(16-bit浮動小数点)に置き換えることでメモリ使用量を半減させることで対処してみようと思います。
- Transformerを使う際の制限として、GPUのメモリ量が問題になる主な理由は、自己注意機構 (Self-Attention) の計算負荷がシーケンスの長さに対して二乗で増加することです。特に、金融時系列データのように長いシーケンスを扱う場合、メモリ消費が急激に増え、計算資源の制約が厳しくなります。
デノイジングオートエンコーダ + LSTMを使ったモデルの実装
- まずは前回に紹介したLSTMモデルを使ったモデルと比較してみましょう。どのモデルに対しても過学習を予防する方法として、正規化にL2正則化とDropoutの手法を用いて検証を行います。このモデルはノイズ除去法としては優秀ではありますが、取引を行うロジックに使う場合は必ずしも良いとは言えないことがあります。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
# データの取得
ticker = 'ETH-USD'
# 高頻度データの取得期間を有効な値に設定(例: 過去5日間)
data = yf.download(ticker, period='5d', interval='1m') # 1分足データ
# 特徴量の選択(Open, High, Low, Close, Volume)
features = ['Open', 'High', 'Low', 'Close', 'Volume']
data = data[features]
# データの標準化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# ノイズの追加関数
def add_noise(data, noise_factor=0.2): # ノイズファクターを調整
noisy_data = data + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=data.shape)
return np.clip(noisy_data, -3, 3) # 値の範囲を制限
# ノイズ付きデータの作成
data_noisy = add_noise(data_scaled)
# シーケンスの作成(スライディングウィンドウ)
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length):
x = data[i:(i + seq_length)]
xs.append(x)
return np.array(xs)
seq_length = 30 # シーケンス長を調整
X_clean = create_sequences(data_scaled, seq_length)
X_noisy = create_sequences(data_noisy, seq_length)
# テンソルへの変換
X_clean_tensor = torch.tensor(X_clean, dtype=torch.float32)
X_noisy_tensor = torch.tensor(X_noisy, dtype=torch.float32)
# データローダーの作成
dataset = TensorDataset(X_noisy_tensor, X_clean_tensor)
train_loader = DataLoader(dataset, batch_size=128, shuffle=True)
# デノイジングオートエンコーダモデルの定義(LSTMを使用)
class DenoisingAutoencoder(nn.Module):
def __init__(self, input_dim, encoding_dim, dropout=0.1):
super(DenoisingAutoencoder, self).__init__()
self.encoder = nn.LSTM(input_dim, encoding_dim, batch_first=True)
self.decoder = nn.LSTM(encoding_dim, input_dim, batch_first=True)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x, _ = self.encoder(x)
x = self.dropout(x)
x, _ = self.decoder(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
encoding_dim = 32 # 隠れ層の次元数を調整
dropout = 0.1 # Dropout率
model = DenoisingAutoencoder(input_dim, encoding_dim, dropout)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # L2正則化を追加
# 学習ループ
num_epochs = 30 # エポック数を調整
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for data in train_loader:
noisy_inputs, clean_inputs = data
noisy_inputs = noisy_inputs.to(device)
clean_inputs = clean_inputs.to(device)
optimizer.zero_grad()
outputs = model(noisy_inputs)
loss = criterion(outputs, clean_inputs)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# 再構成データの生成
model.eval()
with torch.no_grad():
reconstructed = model(X_noisy_tensor.to(device)).cpu().numpy()
# データの逆標準化
reconstructed_data = scaler.inverse_transform(reconstructed.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
original_data = scaler.inverse_transform(X_clean.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
# 可視化(Close価格の比較)
plt.figure(figsize=(14, 7))
plt.plot(original_data[:, -1, 3], label='Original Close') # 最後のシーケンスのClose価格をプロット
plt.plot(reconstructed_data[:, -1, 3], label='Reconstructed Close') # 最後のシーケンスのClose価格をプロット
plt.title('Original vs Reconstructed Close Prices')
plt.xlabel('Time Steps')
plt.ylabel('Close Price')
plt.legend()
plt.show()
print("処理が完了しました")Epoch [29/30], Loss: 0.2531
Epoch [30/30], Loss: 0.2527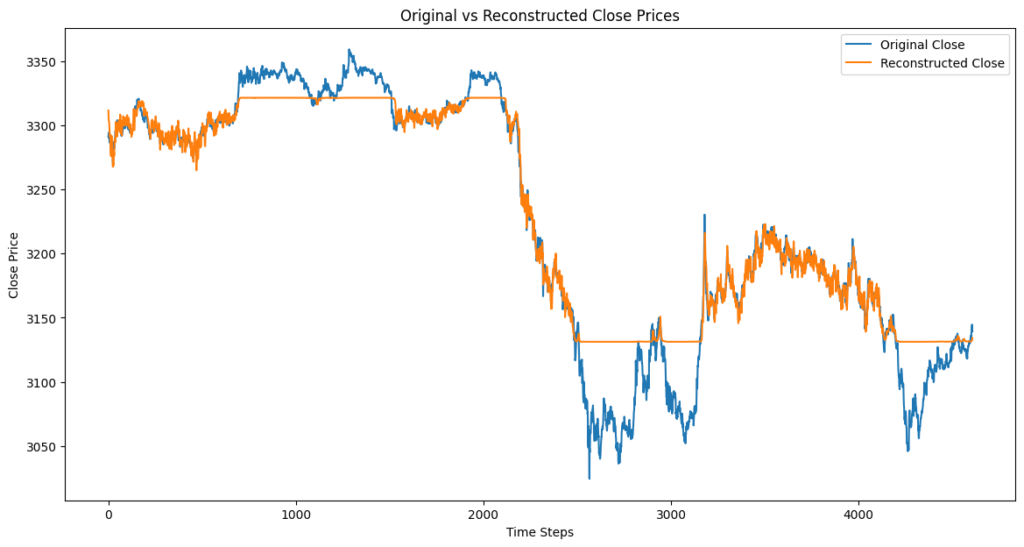
- このモデルの注意点と課題
- デノイジングオートエンコーダ+LSTMを用いたノイズ除去モデルでは、再構成されていないクローズ価格の部分は取引に使用できないことを表しています。
- 理由:スライディングウィンドウによるシーケンス作成時に、十分なデータが揃わない最初の部分はモデルの入力として使用されず、再構成もされないためです。また、逆標準化後のデータも不足部分はプロットされません。取引には再構成済みのクローズ価格が必要なため、未再構成部分での取引はできません。
- デノイジングオートエンコーダ+LSTMを用いたノイズ除去モデルでは、再構成されていないクローズ価格の部分は取引に使用できないことを表しています。
デノイジングオートエンコーダ + Transformer(エンコーダー)を使ったモデルの実装
- 次にTransformerを組み合わせたモデルを使ってみます。このモデルはGPUのメモリ制限上、パラメータを以下の条件に設定します。
- batch_size=16, embed_dim = 32, num_heads = 2
- エンコーダーのみを使う理由:
- デノイジングオートエンコーダーは、Transformerのエンコーダー部分だけを使って特徴を抽出し、ノイズ除去(復元)を行うモデルです。デコーダーは計算コストが高く、GPUメモリの制約もあるため、本モデルでは省略しています。
- また、このモデルの目的は 時系列データの復元であり、「未来の値を生成する」のではなく「過去の値を復元する」ことに特化しているため、エンコーダーのみで十分に機能します。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
from torch.cuda.amp import autocast, GradScaler
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, period='5d', interval='1m') # 1分足データ
# 特徴量の選択(Open, High, Low, Close, Volume)
features = ['Open', 'High', 'Low', 'Close', 'Volume']
data = data[features]
# データの標準化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# ノイズの追加関数
def add_noise(data, noise_factor=0.2):
noisy_data = data + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=data.shape)
return np.clip(noisy_data, -3, 3) # 値の範囲を制限
# ノイズ付きデータの作成
data_noisy = add_noise(data_scaled)
# シーケンスの作成(スライディングウィンドウ)
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length):
x = data[i:(i + seq_length)]
xs.append(x)
return np.array(xs)
seq_length = 20 # シーケンス長を調整
X_clean = create_sequences(data_scaled, seq_length)
X_noisy = create_sequences(data_noisy, seq_length)
# テンソルへの変換
X_clean_tensor = torch.tensor(X_clean, dtype=torch.float32)
X_noisy_tensor = torch.tensor(X_noisy, dtype=torch.float32)
# データローダーの作成
dataset = TensorDataset(X_noisy_tensor, X_clean_tensor)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True) # バッチサイズをさらに小さく
# デノイジングオートエンコーダモデルの定義(Transformerを使用)
class DenoisingTransformer(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, dropout=0.1):
super(DenoisingTransformer, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc_out = nn.Linear(embed_dim, input_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
x = self.dropout(x)
x = self.transformer(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数を減らす
num_heads = 2 # ヘッド数を減らす
num_layers = 2
dropout = 0.1 # Dropout率
model = DenoisingTransformer(input_dim, embed_dim, num_heads, num_layers, seq_length, dropout)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # L2正則化を追加
# 自動混合精度の設定
grad_scaler = GradScaler()
# 学習ループ
num_epochs = 30 # エポック数を調整
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for data in train_loader:
noisy_inputs, clean_inputs = data
noisy_inputs = noisy_inputs.to(device)
clean_inputs = clean_inputs.to(device)
optimizer.zero_grad()
with autocast(): # FP16を自動適用
outputs = model(noisy_inputs)
loss = criterion(outputs, clean_inputs)
grad_scaler.scale(loss).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# 再構成データの生成
model.eval()
with torch.no_grad():
reconstructed = model(X_noisy_tensor.to(device)).cpu().numpy()
# データの逆標準化
reconstructed_data = scaler.inverse_transform(reconstructed.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
original_data = scaler.inverse_transform(X_clean.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
# 可視化(Close価格の比較)
plt.figure(figsize=(14, 7))
plt.plot(original_data[:, -1, 3], label='Original Close') # 最後のシーケンスのClose価格をプロット
plt.plot(reconstructed_data[:, -1, 3], label='Reconstructed Close') # 最後のシーケンスのClose価格をプロット
plt.title('Original vs Reconstructed Close Prices')
plt.xlabel('Time Steps')
plt.ylabel('Close Price')
plt.legend()
plt.show()
print("処理が完了しました")Epoch [29/30], Loss: 0.0246
Epoch [30/30], Loss: 0.0245- deno+Transformerモデルの特徴
- 短期的な変動は忠実に再現され、細かいノイズを除去しつつオリジナルデータに近い形で復元できている。ただし、長期的なトレンドの捉え方にはやや弱さがある。
- 課題
- 価格の急変動をそのまま反映しすぎることがある
- ノイズが十分に取り除かれない場合もある
先ほどのデノイジングオートエンコーダ+LSTMとの違いを見てみましょう。
| 比較項目 | Denoising Autoencoder + Transformer | Denoising Autoencoder + LSTM |
|---|---|---|
| ノイズ除去の仕方 | ノイズを滑らかに除去し、局所的な変動もある程度再現する | ノイズを強く除去し、短期的な変動を抑えてしまう |
| 再構成の精度 | 細かい変動をある程度再現 | 階段状の形になり、価格変化が遅れる傾向 |
| 価格変動の追随 | 急激な変化にも比較的対応できる | 過去のデータを重視しすぎて変動をスムーズに反映できない |
| 取引の安定性 | ノイズを除去しつつ、適度に変動を捉えられるため適応性が高い | 変動が遅れて反映されるため、エントリー・エグジットのタイミングがずれやすい |
結果:
- この二つのモデルの場合は再現性の問題によりTransformerモデルを組み合わせたモデルの方がノイズ除去に優れていることがわかります。また取引回数においてもTransformerモデルの方が優位性があることがわかります。
デノイジングオートエンコーダ + Transformer + LSTMを使ったモデルの実装
- 先ほどと同じパラメータを使って同じモデルにLSTMを組み合わせてみます。
- エンコーダーの省略理由に関しては先ほどのデノイジングオートエンコーダ + Transformer で説明を行なっていますので確認してください。
- 更にLSTMを追加することで、時系列の長期的な依存関係を補完できる ため、エンコーダーだけで十分な性能を発揮することができます。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
from torch.cuda.amp import autocast, GradScaler
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, period='5d', interval='1m') # 1分足データ
# 特徴量の選択(Open, High, Low, Close, Volume)
features = ['Open', 'High', 'Low', 'Close', 'Volume']
data = data[features]
# データの標準化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# ノイズの追加関数
def add_noise(data, noise_factor=0.2):
noisy_data = data + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=data.shape)
return np.clip(noisy_data, -3, 3) # 値の範囲を制限
# ノイズ付きデータの作成
data_noisy = add_noise(data_scaled)
# シーケンスの作成(スライディングウィンドウ)
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length):
x = data[i:(i + seq_length)]
xs.append(x)
return np.array(xs)
seq_length = 20 # シーケンス長を調整
X_clean = create_sequences(data_scaled, seq_length)
X_noisy = create_sequences(data_noisy, seq_length)
# テンソルへの変換
X_clean_tensor = torch.tensor(X_clean, dtype=torch.float32)
X_noisy_tensor = torch.tensor(X_noisy, dtype=torch.float32)
# データローダーの作成
dataset = TensorDataset(X_noisy_tensor, X_clean_tensor)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True) # バッチサイズをさらに小さく
# デノイジングオートエンコーダモデルの定義(Transformer + LSTMを使用)
class DenoisingAutoencoder(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, lstm_hidden_dim, seq_length, dropout=0.1):
super(DenoisingAutoencoder, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.lstm = nn.LSTM(embed_dim, lstm_hidden_dim, batch_first=True)
self.fc_out = nn.Linear(lstm_hidden_dim, input_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
x = self.dropout(x)
x = self.transformer(x)
x, _ = self.lstm(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
lstm_hidden_dim = 64 # LSTMの隠れ層次元数
dropout = 0.1 # Dropout率
model = DenoisingAutoencoder(input_dim, embed_dim, num_heads, num_layers, lstm_hidden_dim, seq_length, dropout)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # L2正則化を追加
# 自動混合精度の設定
grad_scaler = GradScaler()
# 学習ループ
num_epochs = 30 # エポック数を調整
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for data in train_loader:
noisy_inputs, clean_inputs = data
noisy_inputs = noisy_inputs.to(device)
clean_inputs = clean_inputs.to(device)
optimizer.zero_grad()
with autocast(): # FP16を自動適用
outputs = model(noisy_inputs)
loss = criterion(outputs, clean_inputs)
grad_scaler.scale(loss).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# 再構成データの生成
model.eval()
with torch.no_grad():
reconstructed = model(X_noisy_tensor.to(device)).cpu().numpy()
# データの逆標準化
reconstructed_data = scaler.inverse_transform(reconstructed.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
original_data = scaler.inverse_transform(X_clean.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
# 可視化(Close価格の比較)
plt.figure(figsize=(14, 7))
plt.plot(original_data[:, -1, 3], label='Original Close') # 最後のシーケンスのClose価格をプロット
plt.plot(reconstructed_data[:, -1, 3], label='Reconstructed Close') # 最後のシーケンスのClose価格をプロット
plt.title('Original vs Reconstructed Close Prices')
plt.xlabel('Time Steps')
plt.ylabel('Close Price')
plt.legend()
plt.show()
print("処理が完了しました")Epoch [29/30], Loss: 0.0094
Epoch [30/30], Loss: 0.0101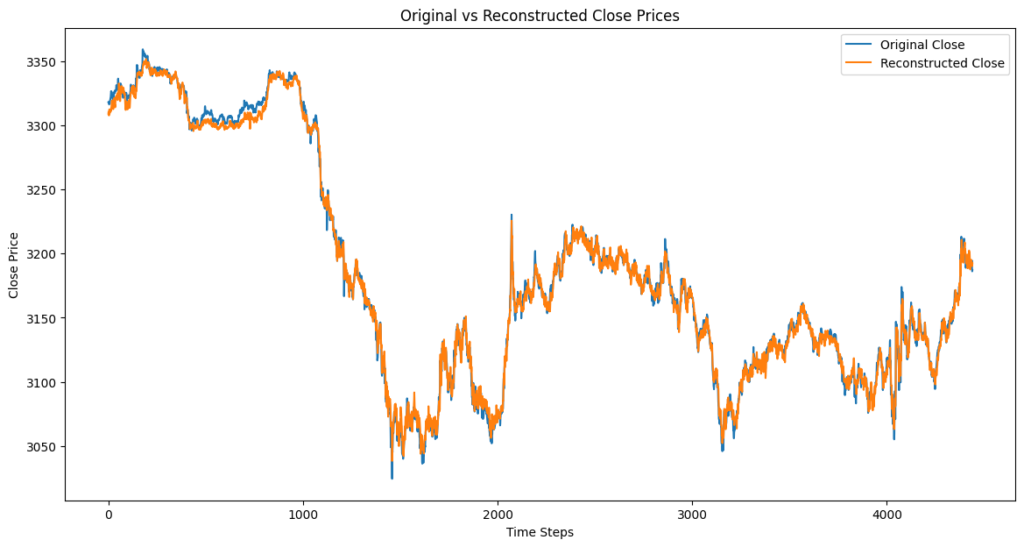
- deno+Transformer+LSTMモデルの特徴
- 全体のトレンドは滑らかで、ノイズもしっかり除去されている。
- 課題
- 短期的な価格変動が滑らかになりすぎており、細かい動きを捉えにくい。過去のデータを重視しすぎることで、急な価格変動への対応が遅れる可能性がある。取引に活用する際は、この即応性の低下に注意が必要。
先ほどのデノイジングオートエンコーダ+ Transformerとの違いを見てみましょう。
| 項目 | deno+Transformer+LSTM | deno+Transformer |
|---|---|---|
| 短期的なノイズ除去 | 過度に平滑化される可能性がある | ノイズを除去しつつ短期変動を再現 |
| 長期的なトレンド把握 | LSTMがあるため精度が高い | Transformer単体では学習がやや難しい |
| 価格変動への適応性 | 長期トレンドを捉えつつ短期変動もある程度追随 | 短期的な変動をより細かく捉えるが長期的な変動は見落としがち |
| リアルタイム性 | 計算コストが高いため遅れが生じやすい | 処理速度が速い |
結果:目的によって異なるが、一般的には Transformer+LSTM の方がノイズ除去能力に優れている。
- ✅ 短期トレードやボラティリティの高い市場ではTransformerのみが即応性に優れ、長期トレードや安定したシグナルを求める場合はTransformer+LSTMがノイズ耐性と予測の信頼性に優位性を持つ。
最適な用途
- 長期投資・スイングトレード → Transformer+LSTM(ノイズを除去しつつ大きな流れを捉えられる)
- デイトレード・スキャルピング → Transformerのみ(短期的な変動をキャッチしやすい)
Multi-Head Latent Attention(MLA)モデルの実装
次にデノイジングオートエンコーダとTransformerのMulti-Head Attentionの改良型のMulti-Head Latent Attentionを使ってノイズ除去を行います。このモデルはTransformerモデルではあるのですが、MLA単体でデノイジングオートエンコーダと組み合わせてノイズ除去が可能なモデルです。
まずは簡単にMLAの紹介をしてから実装を行うことにします。
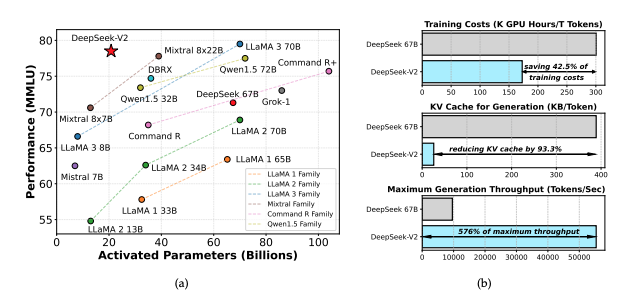
MLAは、DeepSeek-V2モデルに導入された新しいアテンション機構で、従来のマルチヘッドアテンション(MHA)と比べてKVキャッシュのサイズを大幅に削減し、推論の効率を向上させることを目的としています。
特徴とTransformerとの関係性
- MLAはMHAの変種として設計され、大規模モデルのKVキャッシュのメモリボトルネックを解消することで、Transformerのスケーラビリティと効率性を向上させます。特に推論時のメモリ消費が課題となるモデルに対して、KVキャッシュの圧縮によりGPUメモリ使用量を5–13%に削減し、高効率な推論を可能にする技術です。
論文:『DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model』

- 計算効率とスケーラビリティの両立
- DeepSeek-V2は2360億パラメータのMoEモデルでありながら、1トークンごとに210億パラメータのみを活性化することで、計算負荷を抑えつつ高精度な推論を実現。さらに、新技術Multi-Head Latent Attention (MLA) を採用し、推論時のキー・バリュー(KV)キャッシュを削減。これにより、長いコンテキスト(128Kトークン)でもメモリ効率の良い処理が可能に。計算コストを抑えつつ、強力な性能を維持する設計が特徴の次世代LLM。
- 高精度な多言語対応と汎用性
- DeepSeek-V2は英語・中国語の両方で最高レベルの性能を達成し、特に中国語の理解力はLLaMA3 70Bを超える。事前学習でSFT(教師ありデータ)を使用せず、データ依存を抑えた柔軟な知識獲得を実現。さらに、強化学習(RL)による最適化で数学・プログラミングタスクでも高精度を発揮。これにより、特定用途に縛られない汎用的な適用が可能なLLMとして、多言語理解と高度なタスク処理の両立を実現している。
deno+MLAの実装:
- MLAにより、キーとバリューを低次元の潜在ベクトルに圧縮することで、メモリ使用量を大幅に削減します。これにより、推論時のメモリ消費を抑え、効率的なモデル運用を可能にしています。
ライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
from torch.cuda.amp import autocast, GradScalerデータの取得と前処理
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, period='5d', interval='1m') # 1分足データ
# 特徴量の選択(Open, High, Low, Close, Volume)
features = ['Open', 'High', 'Low', 'Close', 'Volume']
data = data[features]
# データの標準化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)ノイズの追加
# ノイズの追加関数
def add_noise(data, noise_factor=0.2):
noisy_data = data + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=data.shape)
return np.clip(noisy_data, -3, 3) # 値の範囲を制限
# ノイズ付きデータの作成
data_noisy = add_noise(data_scaled)add_noise:データにノイズを追加する関数。ノイズの強さはnoise_factorで調整します。np.clip:ノイズの範囲を制限します。
シーケンスの作成
# シーケンスの作成(スライディングウィンドウ)
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length):
x = data[i:(i + seq_length)]
xs.append(x)
return np.array(xs)
seq_length = 20 # シーケンス長を調整
X_clean = create_sequences(data_scaled, seq_length)
X_noisy = create_sequences(data_noisy, seq_length)データのテンソル変換とデータローダーの作成
# テンソルへの変換
X_clean_tensor = torch.tensor(X_clean, dtype=torch.float32)
X_noisy_tensor = torch.tensor(X_noisy, dtype=torch.float32)
# データローダーの作成
dataset = TensorDataset(X_noisy_tensor, X_clean_tensor)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True) DataLoader:データローダーを作成し、バッチサイズとシャッフルを設定します。
Multi-head Latent Attention(MLA)層の定義
class MultiHeadLatentAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadLatentAttention, self).__init__()
self.num_heads = num_heads
self.embed_dim = embed_dim
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.out = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_length, embed_dim = x.size()
q = self.query(x).view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
k = self.key(x).view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
v = self.value(x).view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.matmul(q, k.transpose(-2, -1)) / np.sqrt(self.head_dim)
attn = torch.softmax(scores, dim=-1)
context = torch.matmul(attn, v).transpose(1, 2).contiguous().view(batch_size, seq_length, embed_dim)
out = self.out(context)
return outMLA層は、入力データの各部分間の関係を学習し、再構成精度を向上させるために使用されます。
デノイジングオートエンコーダモデルの定義(MLAを使用)
class DenoisingTransformer(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, dropout=0.1):
super(DenoisingTransformer, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
self.layers = nn.ModuleList([
nn.Sequential(
MultiHeadLatentAttention(embed_dim, num_heads),
nn.Dropout(dropout),
nn.LayerNorm(embed_dim)
) for _ in range(num_layers)
])
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
for layer in self.layers:
x = layer(x)
x = self.fc_out(x)
return xlayers:MLA層、ドロップアウト、LayerNormを含む層を定義します。forward:前方伝播を定義します。埋め込みと位置エンコーディングを加えた後、各層を通過させ、最終的な出力を得ます。
モデルのインスタンス化とデバイスの設定
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数を減らす
num_heads = 2 # ヘッド数を減らす
num_layers = 2
dropout = 0.1 # Dropout率
model = DenoisingTransformer(input_dim, embed_dim, num_heads, num_layers, seq_length, dropout)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)損失関数とオプティマイザの定義
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # L2正則化を追加
# 自動混合精度の設定
grad_scaler = GradScaler()grad_scaler:自動混合精度(AMP)を使用するためのスケーラーを設定します。
学習ループ
# 学習ループ
num_epochs = 30 # エポック数を調整
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for data in train_loader:
noisy_inputs, clean_inputs = data
noisy_inputs = noisy_inputs.to(device)
clean_inputs = clean_inputs.to(device)
optimizer.zero_grad()
with autocast(): # FP16を自動適用
outputs = model(noisy_inputs)
loss = criterion(outputs, clean_inputs)
grad_scaler.scale(loss).backward()
grad_scaler.step(optimizer)
grad_scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')autocast():自動混合精度(AMP)を使用して前方伝播を行います。
再構成データの生成と評価
# 再構成データの生成
model.eval()
with torch.no_grad():
reconstructed = model(X_noisy_tensor.to(device)).cpu().numpy()
# データの逆標準化
reconstructed_data = scaler.inverse_transform(reconstructed.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
original_data = scaler.inverse_transform(X_clean.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)可視化
# 可視化(Close価格の比較)
plt.figure(figsize=(14, 7))
plt.plot(original_data[:, -1, 3], label='Original Close') # 最後のシーケンスのClose価格をプロット
plt.plot(reconstructed_data[:, -1, 3], label='Reconstructed Close') # 最後のシーケンスのClose価格をプロット
plt.title('Original vs Reconstructed Close Prices')
plt.xlabel('Time Steps')
plt.ylabel('Close Price')
plt.legend()
plt.show()
print("処理が完了しました")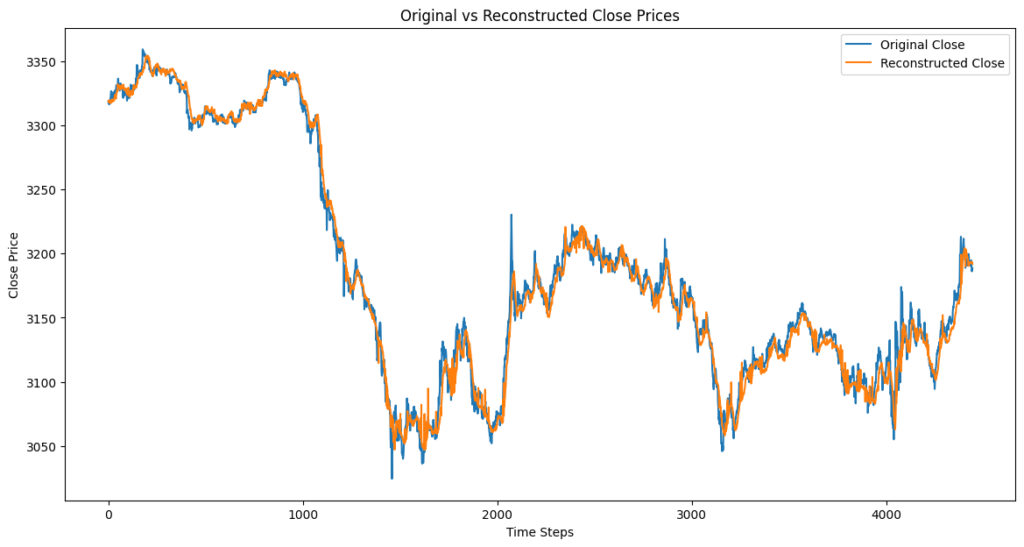
deno+MLAモデルの特徴
- 青(Original)とオレンジ(Reconstructed)がほぼ完全に一致し、短期的な変動を忠実に再現しつつ、トレンドの変化を正確に捉えながら適切にノイズが除去されています。
ノイズ除去の性能比較
| 項目 | MLAモデル | Transformerモデル |
|---|---|---|
| ノイズ除去の精度 | 高い(ノイズを適切に除去しつつ、短期変動を保持) | 高いが、短期変動をややスムーズにしすぎる |
| 短期変動の保持 | 優れている(スパイクや急変動に強い) | 若干劣る(平滑化されやすい) |
| 長期トレンドの再現 | 良い(短期変動とバランスよく再現) | 良い(長期変動の学習は得意) |
| 計算コスト | 低い(O(n log n) まで削減できる可能性あり) | 高い(O(n²) の計算量) |
| トレーディング適性 | 短期トレード・スイングトレード向き | スイングトレード・長期トレード向き |
どのような場合にどちらのモデルを使うべきか?
| 用途 | MLAモデルが適している場合 | Transformerモデルが 適している場合 |
|---|---|---|
| 短期トレード(スキャルピング、デイトレード) | ✅ 価格の細かい変動を再現できるため最適 | ❌ 短期の価格変動を滑らかにしてしまうため不向き |
| 長期トレード(スイングトレード、ポジショントレード) | ✅ 長期トレンドを維持しつつ短期変動も考慮できる | ✅ 長期の価格推移の再現に優れる |
| ボラティリティの高い市場 (仮想通貨、株式指数) | ✅ 価格の急変にも適応できるため有利 | ❌ 急変をスムーズにしすぎる可能性がある |
| 低計算コストでのリアルタイム処理 | ✅ Transformerより計算コストが低いため有利 | ❌ 計算負荷が高く、リアルタイム処理には向かない |
🔹 総合的に、ノイズ除去に関しては MLAモデルの方がTransformerモデルよりも実用性が高く、特に短期トレードには最適な選択肢と言える。
結論:TransformerよりMLAの方が良いのか?
結論として、「MLA単体 vs. Transformer」ではなく、MLAをTransformerに組み込むことでより優れたモデルになる可能性があると考えられます。
短期予測と長期予測の場合の組み合わせの最適解
✅ 短期予測(ボラティリティの高い市場) → MLA単体が最適(計算コストが低く、ノイズ耐性があり、即応性に優れる)
✅ 長期予測(市場トレンドの学習) → Transformer + MLAが最適(長期依存関係を学習し、トレンドの安定性を確保)
- そのほかに試すことができる方法
| 手法 | ノイズ除去への適性 | 主な特徴 |
|---|---|---|
| 自己教師あり学習(SSL) | ✅ 可能 | マスク学習でノイズを抑え、データ補完が可能 |
| 変分オートエンコーダ(VAE)+ Transformer | ✅ 可能 | 潜在空間を活用し、異常値やノイズを除去 |
| フィルタリングモデル(カルマンフィルター / Particle Filter)+ Transformer | ✅ 可能 | リアルタイムで市場ノイズを除去 |
| Long-Sequence対応のTransformer(Longformer等) | ✅ 可能 | GPUメモリ消費削減可能モデル |
Transformerを扱う上で知るべき可能性
後の章で紹介するGPUメモリ制約の解決策の一つとして、「Long-Sequence対応のTransformer」 というアプローチがあります。これは、Transformerモデルのメモリ消費を抑えるアルゴリズムを活用し、より効率的なモデルを構築する方法です。適切なアルゴリズムと組み合わせることで、計算コストを削減しながら、高性能なモデルを実現できる可能性があります。
GPUメモリ制約を解決するための方法
Transformerの自己注意機構(Self-Attention)は、入力シーケンスの長さに対して二乗オーダーの計算コストがかかるため、GPUのメモリ制限が問題になりやすくなります。特に、金融時系列データのような長いシーケンスを扱う場合、メモリ消費が急増するため注意が必要です。
GPUメモリ制約を解決するための方法として、以下のような方法を組み合わせることで、GPUのメモリ使用量を削減しながらTransformerを効率的に扱うことが可能です。
モデルの軽量化
低精度計算 (Mixed Precision Training)
「低精度計算」とは、FP32(32ビット)をFP16(16ビット)に置き換えることで、メモリ使用量を半減し、計算速度を向上させる手法です。特に、大規模な時系列データを扱うTransformerでは、GPUのメモリ制約を軽減するのに有効です。
低精度計算の利用条件
| 条件 | 説明 |
|---|---|
| 対応GPU | – NVIDIA GPU対応。MPS対応。 – AMP((自動混合精度))はNVIDIAのCUDA対応GPUでのみサポートされています。 |
| 必要なライブラリ | – CUDA および cuDNN ライブラリが必須(NVIDIA GPU専用)。 – CPUでの利用不可。 |
| CPUサポート | – CPUはMixed Precision Trainingをサポートしておらず、通常FP32(単精度浮動小数点)で計算を行う。 |
低精度計算の実装例:
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for inputs, targets in dataloader:
optimizer.zero_grad()
with autocast(): # FP16を自動適用
outputs = model(inputs)
loss = loss_fn(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()モデルの圧縮 (Pruning & 量子化)
- Pruning (枝刈り)
- 影響の小さいパラメータを削除し、モデルサイズを縮小。
- 構造化プルーニング(Structured Pruning)が適している。
- 理由:フィルターやチャネル単位でプルーニングを行うため、ハードウェアの最適化が容易であり、計算効率を向上させることができます。
Puringの方法については下記のブログに詳しく記載しておりますのでご確認ください。

構造化プルーニングの実装例:
from torch.nn.utils import prune
# 構造化プルーニングの適用
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
prune.ln_structured(module, name='weight', amount=0.2, n=2, dim=0) # 20%のプルーニングを適用
# プルーニングの再パラメータ化を解除
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
prune.remove(module, 'weight') # プルーニングのフックを削除- Quantization (量子化)
- 8bitや4bitの整数にモデルを変換して計算を軽量化。
- 効果:メモリ削減と推論の高速化。
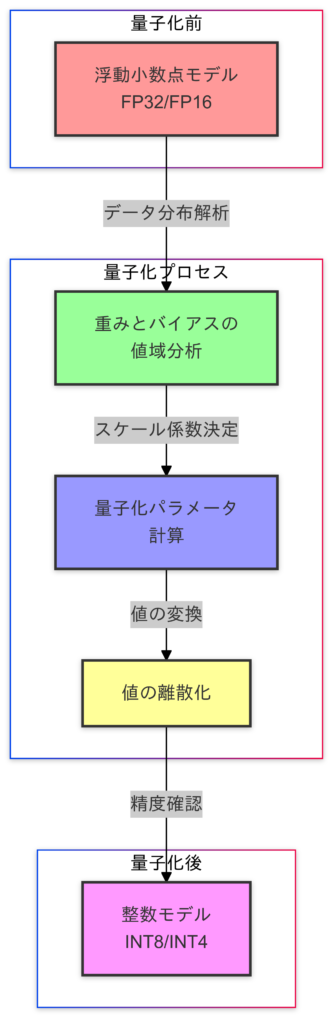
量子化の方法については下記のブログに詳しく記載しておりますのでご確認ください。
量子化(PTQ)の実装例:
- GPUがCUDAの場合
import torch.quantization
model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)このコードは PTQの「動的量子化(Dynamic Quantization)」 を実行しています。PTQは、トレーニング後にモデルを量子化する手法で、追加の学習が不要なため、簡単に適用できるのが特徴です。
- GPUがApplesilicon版(MPS)の場合
import torch.quantization
# 量子化バックエンドの設定
torch.backends.quantized.engine = 'qnnpack'
# デバイスの設定(トレーニングと推論はCPU上で行う)
device = torch.device("cpu")
model.to(device)
# モデルを評価モードに設定
model.eval()
# 量子化の適用
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
quantized_model.to(device)モデルアーキテクチャの工夫
通常のTransformerは、自己注意機構(Self-Attention)を使用するため、入力シーケンスの長さ $N$ に対して $O(N^2)$ の計算量がかかります。これにより、シーケンスが長くなるほど計算コストやメモリ消費が急増し、長い時系列データ(Long-Sequence)の処理が難しくなるという課題があります。
Long-Sequence対応のTransformerとは?
この問題を解決するために、計算量を削減した新しいアーキテクチャのTransformerが登場し、長いシーケンスをより効率的に処理できるようになりました。具体的には、以下のような手法が採用されています。
| モデル | 特徴 | 計算量 |
|---|---|---|
| Longformer | スライディングウィンドウ注意機構 | O(N) |
| Linformer | 低次元の表現に圧縮 | O(N) |
| Performer | ランダム特徴写像を使用 | O(N) |
| Reformer | LSH (Locality-Sensitive Hashing) | O(N log N) |
Longformerモデル
特徴:
ローカルな依存関係を効率的に学習できるため、金融時系列データやNLPの長文解析のように局所的な情報が重要なタスクに適しています。 また、計算量が $O(N)$ で済むため、長いシーケンスを処理しやすく、GPUメモリの節約にもつながります。 さらに、Linformer や Performer などの他の手法とも組み合わせやすく、柔軟なモデル設計が可能です。
Longformerの実装例:
- 効果:長いシーケンスを効率的に処理でき、メモリ消費を削減。
from transformers import LongformerModel, LongformerConfig
class LongformerModelForTimeSeries(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length):
super(LongformerModelForTimeSeries, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
config = LongformerConfig(
attention_window=seq_length,
hidden_size=embed_dim,
num_attention_heads=num_heads,
num_hidden_layers=num_layers,
max_position_embeddings=seq_length
)
self.longformer = LongformerModel(config)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
attention_mask = torch.ones(x.size()[:-1], dtype=torch.long, device=x.device)
outputs = self.longformer(inputs_embeds=x, attention_mask=attention_mask)
x = outputs.last_hidden_state
x = self.fc_out(x)
return x
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
seq_length = 20 # シーケンス長
model = LongformerModelForTimeSeries(input_dim, embed_dim, num_heads, num_layers, seq_length)このモデルを使ったノイズ除去では、先ほど行ったMLAと比べた場合どちらがどうなのかを検証してみましょう。
Longformerとデノイジングオートエンコーダーを組み合わせたモデルの実装例
# Longformerの定義
class LongformerDenoisingAutoencoder(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length):
super(LongformerDenoisingAutoencoder, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
config = LongformerConfig(
attention_window=seq_length,
hidden_size=embed_dim,
num_attention_heads=num_heads,
num_hidden_layers=num_layers,
max_position_embeddings=seq_length
)
self.longformer = LongformerModel(config)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
attention_mask = torch.ones(x.size()[:-1], dtype=torch.long, device=x.device)
outputs = self.longformer(inputs_embeds=x, attention_mask=attention_mask)
x = outputs.last_hidden_state
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
model = LongformerDenoisingAutoencoder(input_dim, embed_dim, num_heads, num_layers, seq_length)Epoch [29/30], Loss: 0.0125
Epoch [30/30], Loss: 0.0122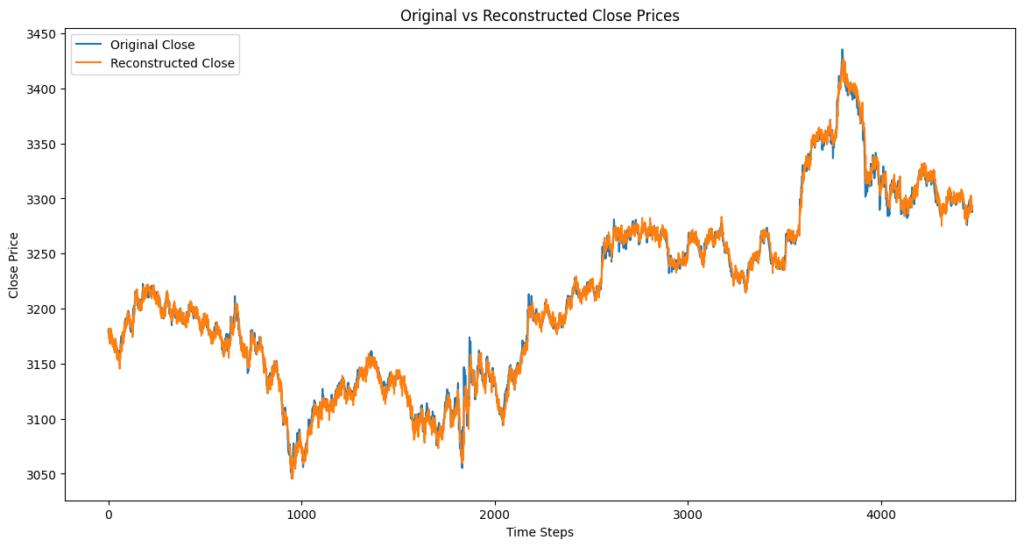
MLAのノイズ除去と比べると、Longformerとデノイジングオートエンコーダーを組み合わせたモデルの方が短期的なボラティリティや精密な価格変動の予測には向いていると言えそうです。しかし、ノイズ除去だけを優先するなら、Multi-Head Latent Attentionの方が適している可能性もあります。
Linformerモデル
特徴:
- 通常のTransformerのO(N²)の自己注意をO(N) に削減。
- 低ランク近似を利用し、長いシーケンスの処理を効率化。
- メモリ使用量を削減しながら、高精度を維持。
Linformerモデル実装例:
pip install linformerfrom linformer import Linformer
# Linformerの定義
class LinformerModelForTimeSeries(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, k=256):
super(LinformerModelForTimeSeries, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
self.linformer = Linformer(
dim=embed_dim,
seq_len=seq_length,
depth=num_layers,
heads=num_heads,
k=k
)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
x = self.linformer(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
model = LinformerModelForTimeSeries(input_dim, embed_dim, num_heads, num_layers, seq_length)効果:
- ✅ 計算量をO(N)に削減(通常のTransformerはO(N²))
- ✅ 長いシーケンスの処理に最適
- ✅ 標準のTransformerと同等の精度を維持
Performerモデル
特徴:
- 通常の自己注意をランダム特徴写像を用いた近似計算でO(N) に削減。
- ソフトマックスをカーネル関数で近似し、長いシーケンスでもメモリ効率が良い。
- 標準Transformerよりもスケーラブル。
Performerモデルの実装例:
pip install performer-pytorchfrom performer_pytorch import Performer
# Performerの定義
class PerformerModelForTimeSeries(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length):
super(PerformerModelForTimeSeries, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
self.performer = Performer(
dim=embed_dim,
depth=num_layers,
heads=num_heads,
dim_head=embed_dim // num_heads,
causal=False
)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
x = self.performer(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
model = PerformerModelForTimeSeries(input_dim, embed_dim, num_heads, num_layers, seq_length)効果:
- ✅ O(N)の計算量でTransformerを近似
- ✅ 計算が高速で、長いシーケンスに対応可能
- ✅ ソフトマックスを明示的に計算しないため、数値的に安定
Reformerモデル
特徴:
LSH(Locality-Sensitive Hashing)を用いた自己注意機構でO(N²)をO(N log N)に削減。
- LSHとは?
- LSHは、データの類似性を基にハッシュ化し、似たデータを同じグループに分類する手法です。これにより、Self-Attentionの計算を効率化し、メモリ使用量を削減できます。
- その際、バケットサイズとシーケンス長を適切に設定することで、Reformerモデルの計算効率を最適化できます。
- メモリ効率の向上:
- リバーシブル層を用い、中間アクティベーションの保存を最小限に抑える。
Reformerモデルの実装例:
- バケットサイズ8に対しシーケンス長を16に設定することで、最適なメモリ割り当てを実現します。
pip install reformer_pytorchfrom reformer_pytorch import Reformer
# Reformerの定義
class ReformerModelForTimeSeries(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, bucket_size=8):
super(ReformerModelForTimeSeries, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
self.reformer = Reformer(
dim=embed_dim,
depth=num_layers,
heads=num_heads,
bucket_size=bucket_size,
causal=False # 非因果型(双方向)のアテンションを使用
)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
x = self.embedding(x) + self.pos_encoding
x = self.reformer(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
bucket_size = 8 # バケットサイズを明示的に指定
model = ReformerModelForTimeSeries(input_dim, embed_dim, num_heads, num_layers, seq_length, bucket_size)効果:
- ✅ O(N log N)の計算量で高速化
- ✅ LSHにより自己注意計算を高速化
- ✅ リバーシブル層でメモリ効率を向上(チェックポイント不要)
比較表
| モデル | 計算量 | 手法 | メリット | デメリット |
|---|---|---|---|---|
| Linformer | O(N) | 低ランク近似 | メモリ削減、簡単に導入可能 | 低ランク近似の影響で情報が劣化する可能性 |
| Performer | O(N) | ランダム特徴写像 | 高速で精度維持 | 近似計算のため収束が遅い可能性 |
| Reformer | O(N log N) | LSH + リバーシブル層 | 最も長いシーケンスに対応可能 | LSHのパラメータ調整が必要 |
どのモデルを使うべきなのか?
- 「メモリ使用量を減らしたい & シンプルなモデルが欲しい」 → Linformer
- 「長いシーケンスを扱いたい & 計算を劇的に軽くしたい」 → Performer
- 「超長シーケンス(4096以上)を扱いたい & Transformerの代替を探している」 → Reformer
Longformer を Linformer, Performer, Reformer と組み合わせることで、長いシーケンスの処理をさらに最適化できます。
各組み合わせの比較
| 組み合わせ | 計算量 | 長所 | 短所 | 適用例 |
|---|---|---|---|---|
| Longformer × Linformer | O(N) | 計算コストが最も低い、実装がシンプル | 低ランク近似のため情報が一部失われる | ニュース分析、金融時系列、NLPの長文要約 |
| Longformer × Performer | O(N) | 高速でメモリ効率が良い、ソフトマックスの近似が不要 | ランダム特徴写像のため収束が遅い可能性 | 金融データ予測、超長シーケンスデータ(ログデータ、医療データ) |
| Longformer × Reformer | O(N log N) | 超長シーケンスに最適、LSHにより計算削減 | LSHのパラメータ調整が必要 | 時系列解析、金融データ、長文テキスト生成(記事・論文) |
Longformer × Reformerの実装例:
# Longformer × Reformerの定義
class LongformerReformerModelForTimeSeries(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, bucket_size=8):
super(LongformerReformerModelForTimeSeries, self).__init__()
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_encoding = nn.Parameter(torch.zeros(1, seq_length, embed_dim))
# Longformerの設定
from transformers import LongformerModel, LongformerConfig
longformer_config = LongformerConfig(
attention_window=seq_length,
hidden_size=embed_dim,
num_attention_heads=num_heads,
num_hidden_layers=num_layers,
max_position_embeddings=seq_length
)
self.longformer = LongformerModel(longformer_config)
# Reformerの設定
from reformer_pytorch import Reformer
self.reformer = Reformer(
dim=embed_dim,
depth=num_layers,
heads=num_heads,
bucket_size=bucket_size,
causal=False # 双方向のアテンション
)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
# x: [batch_size, seq_length, input_dim]
x = self.embedding(x) + self.pos_encoding # 埋め込みと位置エンコーディング
batch_size, seq_length, _ = x.size()
attention_mask = torch.ones(batch_size, seq_length, dtype=torch.long, device=x.device)
# 明示的にposition_idsを用意(0~seq_length-1のインデックス)
position_ids = torch.arange(0, seq_length, dtype=torch.long, device=x.device).unsqueeze(0).expand(batch_size, -1)
longformer_outputs = self.longformer(
inputs_embeds=x,
attention_mask=attention_mask,
position_ids=position_ids
)
x = longformer_outputs.last_hidden_state
x = self.reformer(x)
x = self.fc_out(x)
return x
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
embed_dim = 32 # 埋め込み次元数
num_heads = 2 # ヘッド数
num_layers = 2
bucket_size = 8 # バケットサイズを明示的に指定
model = LongformerReformerModelForTimeSeries(input_dim, embed_dim, num_heads, num_layers, seq_length, bucket_size)計算の分割
勾配チェックポイント (Gradient Checkpointing)
勾配チェックポイントは、学習時のメモリ消費を抑える手法です。順伝播で全ての中間層を保存せず、一部を破棄し、逆伝播時に再計算することでGPUメモリの使用量を削減します。
- なぜ必要なのか?
- DNNは層が深くなるほどメモリ消費が増大し、大規模なTransformerモデルや長いシーケンスでは学習のボトルネックになります。勾配チェックポイントを活用すれば、一部のアクティベーションを再計算することでメモリ使用量を抑え、GPUの制約を超えずに大規模モデルの学習が可能になります。
メリットとデメリット
| 項目 | メリット | デメリット |
|---|---|---|
| メモリ削減 | GPUメモリの使用量を大幅に削減できる。 | 再計算が必要なため、計算時間が増加する。 |
| モデルサイズ | メモリがボトルネックにならず、大規模モデルの学習が可能。 | 一部のレイヤーでのみ適用可能(適用箇所の選定が必要)。 |
| 適用範囲 | Transformer, BERT, GPT, ViT など、大規模モデルに有効。 | モデルのすべての層に適用すると、逆にオーバーヘッドが増える。 |
import torch.utils.checkpoint as checkpoint
output = checkpoint.checkpoint(model, inputs)効果:追加の計算コストは増えるが、メモリ消費量を大幅に削減可能。
Sequence Chunking (シーケンス分割)
シーケンス分割は、長いシーケンス(時系列データやテキストなど)を小さな単位に分割して処理する手法です。これにより、メモリ使用量を抑えつつ、バッチ処理の効率を向上させることができます。
| 目的 | 説明 |
|---|---|
| メモリ最適化 | GPUのメモリ制約を超えないように、長い入力データを小さいブロックに分割して処理する。 |
| 計算効率の向上 | 一度に処理するデータ量を調整し、ハードウェアの制限内で最大のバッチサイズを活用できる。 |
| トレーニング安定化 | 長いシーケンスでは勾配が不安定になりがちだが、分割することで安定した学習が可能になる。 |
Transformerモデルの入力でのシーケンス分割の実装例:
import torch
# シーケンスデータ(例: 5000トークン)
sequence_length = 5000
batch_size = 4
embedding_dim = 128
# ランダムなシーケンスデータ(例: 5000トークン)
input_sequence = torch.randn(batch_size, sequence_length, embedding_dim)
# チャンクサイズ(例: 2500トークンずつ処理)
chunk_size = 2500
# シーケンスをチャンクに分割
chunks = input_sequence.split(chunk_size, dim=1)
# 分割後の各チャンクの形状を確認
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1} shape: {chunk.shape}")Chunk 1 shape: torch.Size([4, 2500, 128])
Chunk 2 shape: torch.Size([4, 2500, 128])import torch.nn as nn
class SimpleTransformerEncoder(nn.Module):
def __init__(self, embed_dim, num_heads, ff_dim):
super(SimpleTransformerEncoder, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, ff_dim),
nn.ReLU(),
nn.Linear(ff_dim, embed_dim)
)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(self, x):
attn_output, _ = self.attention(x, x, x)
x = self.norm1(x + attn_output)
ff_output = self.feed_forward(x)
x = self.norm2(x + ff_output)
return x
# Transformerエンコーダのインスタンス
encoder = SimpleTransformerEncoder(embed_dim=128, num_heads=8, ff_dim=256)
# シーケンスの各チャンクをエンコーダに通す
encoded_chunks = [encoder(chunk) for chunk in chunks]
# 各チャンクを連結
final_output = torch.cat(encoded_chunks, dim=1)
print(f"Final output shape: {final_output.shape}")Final output shape: torch.Size([4, 5000, 128])結果:
各チャンクをTransformerエンコーダで個別に処理し、最後に結合して元のシーケンスの形に戻します。これにより、メモリ負担を抑えながら、大規模なシーケンスデータを効率的に処理できます。
応用例:
| 応用例 | 説明 | 具体例 |
|---|---|---|
| 大規模な自然言語処理(NLP) | 長い文章(例: 5000トークン)をチャンク単位で分割して処理し、BERTやGPT、T5などのモデルで利用。 | GoogleのT5では、長い文章をチャンク単位で処理。 |
| 金融時系列データ | 株価や暗号資産の時系列データを、日ごと、時間ごとに分割してTransformerモデルに入力し、トレンド予測などに活用。 | ETH/USDやBTC/USDの過去5年間の価格データをチャンクに分割し、トレンド予測に利用。 |
| 医療データ | 患者のECG(心電図)や脳波などの医療データを分割し、異常検知や疾患予測に活用。 | 患者の心電図データをチャンクに分割し、異常検知や疾患予測に利用。 |
分散学習
分散学習は、大規模なディープラーニングモデルを複数の計算リソース(GPU/TPU/CPUクラスタ)に分散して学習する手法です。これにより、メモリ負担を軽減しながら計算時間を短縮し、より大規模なモデルの学習が可能になります。
主な手法として、モデル並列化(Model Parallelism)とデータ並列化(Data Parallelism)の2つがあります。
モデル並列化
- モデルが大きすぎて単一のGPUに収まらない場合、モデルの各部分(層など)を複数のGPUに分割して処理する手法です。
- 仕組み
- 層ごとに分割
- 例えば、TransformerのエンコーダをGPU 1、デコーダをGPU 2 で処理。
- 重み行列ごとに分割
- 巨大な線形層のパラメータを複数のGPUに分配。
- 層ごとに分割
- 仕組み
モデル並列化の実装例1(Linear Layers の分割):
import torch
import torch.nn as nn
# デバイス設定(NVIDIA CUDA))
# device0 = torch.device("cuda:0") # 最初のGPU
# device1 = torch.device("cuda:1") # 2番目のGPU(複数GPU環境が前提)
# デバイス設定(Apple Mシリーズの場合)
device0 = torch.device("mps:0") # 最初のGPU
device1 = torch.device("mps:1") # 2番目のGPU(複数GPU環境が前提)
# モデルの定義
class ModelParallelNN(nn.Module):
def __init__(self):
super(ModelParallelNN, self).__init__()
# GPU0 に配置
self.layer1 = nn.Linear(1024, 512).to(device0)
self.relu = nn.ReLU()
# GPU1 に配置
self.layer2 = nn.Linear(512, 256).to(device1)
self.layer3 = nn.Linear(256, 128).to(device1)
def forward(self, x):
# GPU0 で処理
x = x.to(device0)
x = self.relu(self.layer1(x))
# GPU1 に転送
x = x.to(device1)
x = self.relu(self.layer2(x))
x = self.layer3(x)
return x
# モデルのインスタンス化
model = ModelParallelNN()
# ダミーデータを作成
x = torch.randn(64, 1024) # バッチサイズ64、入力サイズ1024
# フォワードパス
output = model(x)
print("Output Shape:", output.shape)Output Shape: torch.Size([64, 128])📌 重要ポイント
self.layer1は GPU0 に配置self.layer2とself.layer3は GPU1 に配置forward()の中で GPU間転送 (x.to(device)) を実行
モデル並列化の実装例2(Transformer の一部を GPU に分割):
- Transformerの各層(エンコーダ・デコーダ)を異なるGPUに配置することも可能。
import torch
import torch.nn as nn
class ModelParallelTransformer(nn.Module):
def __init__(self):
super(ModelParallelTransformer, self).__init__()
# GPU0: 前半のエンコーダ層
self.encoder1 = nn.TransformerEncoderLayer(d_model=512, nhead=8).to("mps:0")
self.encoder2 = nn.TransformerEncoderLayer(d_model=512, nhead=8).to("mps:0")
# GPU1: 後半のデコーダ層
self.decoder1 = nn.TransformerDecoderLayer(d_model=512, nhead=8).to("mps:1")
self.decoder2 = nn.TransformerDecoderLayer(d_model=512, nhead=8).to("mps:1")
def forward(self, src, tgt):
src = src.to("mps:0")
tgt = tgt.to("mps:1")
# エンコーダ処理 (GPU0)
src = self.encoder1(src)
src = self.encoder2(src)
# デコーダ処理 (GPU1)
src = src.to("mps:1") # GPU0 → GPU1 に転送
output = self.decoder1(tgt, src)
output = self.decoder2(output, src)
return output
# モデルのインスタンス化
model = ModelParallelTransformer()
# ダミーデータ
src = torch.randn(10, 32, 512) # シーケンス長10、バッチ32、埋め込み次元512
tgt = torch.randn(10, 32, 512)
# フォワードパス
output = model(src, tgt)
print("Output Shape:", output.shape)📌 重要ポイント
- エンコーダ層は GPU0、デコーダ層は GPU1 に配置
- GPU間のデータ転送 (
to("mps:1")) が発生する - Transformer の巨大モデルに適用可能
モデル並列化のメリット・デメリット
| メリット | デメリット |
|---|---|
| メモリ削減:巨大なモデルを複数のGPUに分散できる | GPU間通信のオーバーヘッド:転送コストが発生 |
| 長いシーケンスの処理が可能 | 適用できるモデルが限られる: 層の分割が難しいケースもある |
| GPUメモリの有効活用 | 実装が複雑:データの転送管理が必要 |
データ並列化
- モデルをそのままにし、データを複数のGPUに分割して学習を並列化する手法です。
- 仕組み
- ミニバッチを分割(各GPUが異なるデータサンプルを処理)
- 各GPUが独立に学習(Forward & Backward Pass)
- 勾配を同期(各GPUが計算した勾配を集約)
- モデルのパラメータを更新(すべてのGPUで一貫性を持たせる)
- 仕組み
データ並列化の実装例:
- DataParallel使用の場合
import torch
model = torch.nn.DataParallel(model)
# デバイス設定(NVIDIA CUDA)
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# model.to(device)
デバイス設定(Apple Mシリーズの場合)
device = torch.device("mps" if torch.mps.is_available() else "cpu")
model.to(device)
# データ並列化の設定
if torch.mps.device_count() > 1:
model = nn.DataParallel(model)- DistributedDataParallel (DDP)使用の場合:
- このモデルはNVIDIAのCUDAのGPUを使わなければ動作しません。
import os
import yfinance as yf
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, TensorDataset, DistributedSampler
# DDP用プロセスグループの初期化
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl", rank=rank, world_size=world_size) # NCCL backend を使用
# DDP用プロセスグループの終了処理
def cleanup():
dist.destroy_process_group()
# ETH-USDのClose価格データをダウンロードし、シーケンスデータを作成
def prepare_eth_data(seq_length=10):
data = yf.download("ETH-USD", period="5d", interval="1h")
close = data['Close'].values
# 標準化(平均0、標準偏差1)
mean = np.mean(close)
std = np.std(close)
norm = (close - mean) / std
X, y = [], []
for i in range(len(norm) - seq_length):
X.append(norm[i:i+seq_length])
y.append(norm[i+seq_length])
X = np.array(X)
y = np.array(y)
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32).unsqueeze(1)
return TensorDataset(X_tensor, y_tensor)
# シンプルな線形モデル(入力: 過去のseq_length値、出力: 次の値の予測)
class SimpleModel(nn.Module):
def __init__(self, seq_length):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(seq_length, 1)
def forward(self, x):
return self.fc(x)
# 学習ループ(DDPを使用、CUDA版)
def train(rank, world_size, dataset, seq_length):
setup(rank, world_size)
device = torch.device(f"cuda:{rank}") # 各プロセスは自身のGPUを使用
# DistributedSamplerで各プロセスにデータを分割
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=16, sampler=sampler)
model = SimpleModel(seq_length).to(device)
# DDPでは device_ids に該当GPUを指定
model = nn.parallel.DistributedDataParallel(model, device_ids=[rank])
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
num_epochs = 5
for epoch in range(num_epochs):
sampler.set_epoch(epoch)
total_loss = 0.0
for batch_x, batch_y in dataloader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
output = model(batch_x)
loss = criterion(output, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
if rank == 0:
print(f"Epoch {epoch+1}, Loss: {total_loss/len(dataloader):.4f}")
cleanup()
def main():
seq_length = 10
dataset = prepare_eth_data(seq_length)
world_size = torch.cuda.device_count() # 使用可能なGPU数をプロセス数に設定
if world_size < 1:
raise RuntimeError("CUDAが利用できません。")
mp.spawn(train, args=(world_size, dataset, seq_length), nprocs=world_size, join=True)
if __name__ == "__main__":
mp.set_start_method("spawn", force=True)
main()📌 コードの解説
- setup() / cleanup()
DDP用にプロセスグループを初期化・破棄します。 - prepare_eth_data()
yfinance を使ってETH-USDのClose価格データを取得し、シーケンス(過去10時点)とその次の値を予測ターゲットとしてTensorDatasetを作成します。 - SimpleModel
シンプルな全結合モデルで、入力シーケンスから次の価格を予測します。 - train()
DistributedSampler を利用してデータを各プロセスに分割し、DDPでモデルをラップした上で学習ループを実行します。 - mp.spawn()
指定したプロセス数(ここでは1プロセス)で train() 関数を起動します。
このコードはDDPの基本を示しており、金融時系列データ(ETH-USD)を用いたシンプルな例として再現できます。正し、MPSでは動作せず、CUDAのGPUが必須です。
データ処理の工夫
ミニバッチサイズの調整
- バッチサイズを小さくすることで、1回のGPUメモリ消費を削減。
- 例:
batch_size=32をbatch_size=8に変更。
- 例:
トークンの圧縮
トークンの圧縮は、データサイズを減らしつつ、重要な情報を維持する技術です。金融時系列データでは、不要なデータポイントを削減(ダウンサンプリング)することで、計算コストを抑えながら効率的に学習できます。
なぜトークンの圧縮が必要か?
- メモリ削減と計算効率の向上
- 長い時系列データ(例: 1分足)をそのまま入力すると、Transformer系モデルの計算コストがO(N²)やO(N log N)と急増し、GPUメモリが不足するため、適切な間引き(ダウンサンプリング)が必要になります。
- 重要な情報のみを抽出
- 金融データは「価格がほぼ一定」の部分が多いため、大きな変動がある部分のみを抽出し、不要なトークンを削減することで効率的に学習が可能になります。
時系列データのダウンサンプリング手法
Fixed Interval Sampling
- 一定間隔ごとにデータを抜き取る(例: 1分足 → 5分足にする)。
import yfinance as yf
import numpy as np
import pandas as pd
# ETH-USDの時系列データを取得(1分足は未対応、日足など)
eth_df = yf.download("ETH-USD", interval="1d", period="1mo") # 1ヶ月分の日足
eth_resampled_fixed = eth_df.iloc[::5] # 5つおきに選択
print(eth_resampled_fixed.head()) Open High Low Close Adj Close \
Date
2025-01-02 3353.412109 3493.448242 3348.352051 3451.392578 3451.392578
2025-01-07 3688.341309 3701.106934 3358.089844 3381.577393 3381.577393
2025-01-12 3282.150391 3298.018311 3224.510498 3265.951172 3265.951172
2025-01-17 3308.191162 3525.543457 3307.311035 3474.107178 3474.107178
2025-01-22 3327.237305 3364.746094 3223.385986 3240.224609 3240.224609
Volume
Date
2025-01-02 22243574698
2025-01-07 32235312545
2025-01-12 11647743556
2025-01-17 28200207229
2025-01-22 22171220981 - メリット: 計算が簡単で直感的。
- デメリット: 価格変動が少ない部分も含まれてしまう。
価格変動ベースのサンプリング
- 価格の変動率(リターンの絶対値)に基づいて、変動が大きい区間を優先的に残す。
- この手法は、市場の重要な動きを捉えるために価格変動が大きい日を優先的に分析するのに有効です。変動の大きい日は市場のトレンドや重要なイベントを反映している可能性が高く、これらの日のデータを抽出することで、重要な情報を見逃さずに分析できます。
eth_df["returns"] = eth_df["Close"].pct_change().abs()
threshold = eth_df["returns"].quantile(0.75) # 上位25%の変動を保持
eth_resampled_volatility = eth_df[eth_df["returns"] > threshold]
eth_resampled_volatility.head()- リターンの計算:
eth_df["returns"] = eth_df["Close"].pct_change().abs()は、各日の終値の前日比変動率(リターン)の絶対値を計算する処理であり、pct_change()で変動率を求め、abs()でその絶対値を取得しています。
- 閾値の設定:
threshold = eth_df["returns"].quantile(0.75)は、リターンの上位25%の変動を保持するための閾値を設定する処理であり、quantile(0.75)によってリターンの75パーセンタイル(上位25%)の値を取得します。
- サンプリング:
eth_resampled_volatility = eth_df[eth_df["returns"] > threshold]は、リターンが閾値を超えるデータを抽出し、価格変動が大きい上位25%の日のみを保持する処理です。
平均値・中央値ベースの集約
- 価格の移動平均や中央値を使って、情報を圧縮。
- このコードは、5分ごとにデータを集約して重要な情報を保持しつつデータ量を削減し、可視化や分析を容易にすることで、各時間帯の始値(Open)、最高値(High)、最安値(Low)、終値(Close)、および取引量の合計を算出します。
eth_df = yf.download("ETH-USD", period="5d", interval="5m")
eth_resampled_agg = eth_df.resample("5T").agg({
"Open": "first",
"High": "max",
"Low": "min",
"Close": "last",
"Volume": "sum"
})
print(eth_resampled_agg)- リサンプリング:
eth_resampled_agg = eth_df.resample("5T").agg({...})は、データを5分間隔にリサンプリングする処理であり、resample("5T")によって5分ごとのデータに再編成しています。
- 集約方法の指定
- Open: 各5分間隔の最初の値を使用(”first”)
- High: 各5分間隔の最大値を使用(”max”)
- Low: 各5分間隔の最小値を使用(”min”)
- Close: 各5分間隔の最後の値を使用(”last”)
- Volume: 各5分間隔の取引量の合計を使用(”sum”)
- メリット:短期ノイズを減らし、より滑らかなデータになる。
- デメリット: 局所的な急変動を捉えづらい。
適応的サンプリング
- 適応的サンプリングは、重要な市場変動を優先的に保持しつつ、不要なデータを削減することで、メモリと計算コストを最適化し、ノイズを除去して分析しやすいデータセットを作成する手法です。
異常検知アルゴリズムを利用したサンプリング
- Isolation Forest などの異常検知アルゴリズムを用いて、異常なデータポイントを残す。
- 市場の急変(暴落・急騰)を検出し、異常時のデータを分析するとともに、ニュースやセンチメント分析を活用して異常な出来高変動の要因を解析します。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.ensemble import IsolationForest
# ETH-USDの時系列データを取得(5分足)
eth_df = yf.download("ETH-USD", period="5d", interval="5m")
# 価格変動に基づくサンプリング
eth_df["returns"] = eth_df["Close"].pct_change().abs()
threshold = eth_df["returns"].quantile(0.75) # 上位25%の変動を保持
eth_resampled_volatility = eth_df[eth_df["returns"] > threshold]
# IsolationForestモデルのインスタンス化
model = IsolationForest(contamination=0.1)
# 異常値検出の実行
eth_df["anomaly"] = model.fit_predict(eth_df[["Close"]])
# 異常値の抽出
eth_resampled_anomaly = eth_df[eth_df["anomaly"] == -1]
# 結果を表示
print(eth_resampled_volatility.head())
print(eth_resampled_anomaly.head())
# プロット
plt.figure(figsize=(12,6))
plt.plot(eth_df.index, eth_df["Close"], label="Close Price")
plt.scatter(eth_resampled_anomaly.index, eth_resampled_anomaly["Close"],
color="red", label="Anomaly", marker="o")
plt.title("ETH-USD Close Price with Anomalies")
plt.xlabel("Date")
plt.ylabel("Close Price")
plt.legend()
plt.show()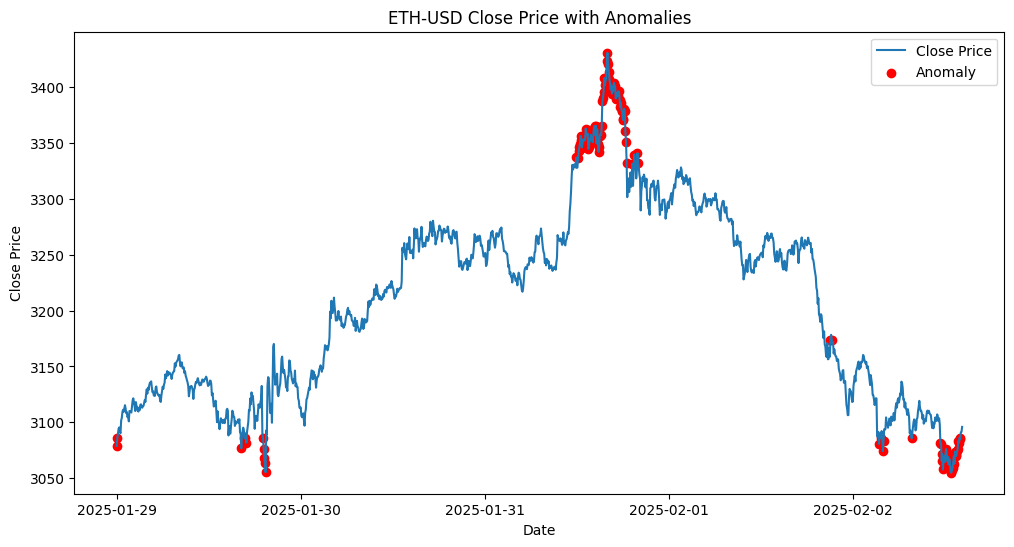
contamination=0.1は、データのうち10%を異常値として扱うことを指定しています。
この手法は、価格の異常な変動を検出し、市場の重要なイベントや異常な取引活動を反映するデータを抽出することで、重要な情報を見逃さないようにするために用いられます。
勾配変化率を利用したサンプリング
- 価格の変化率(勾配)が大きい部分を優先的に保持し、変化が少ない部分を間引く。
- 活用例:市場データの急激な価格変動や高ボラティリティのタイミングを重点的に分析し、トレード戦略の最適化に活用します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
# 📌 データ取得(ETH-USDの1時間足データ)
df = yf.download("ETH-USD", period="6mo", interval="1h")
df.reset_index(inplace=True)
# 📌 勾配(価格変化率)を計算
df["gradient"] = df["Close"].diff().abs()
# 📌 変動の大きいデータを抽出(上位25%)
threshold = df["gradient"].quantile(0.75)
df_resampled = df[df["gradient"] > threshold]
# 📌 結果を可視化
plt.figure(figsize=(12, 6))
plt.plot(df["Datetime"], df["Close"], label="Original Data", alpha=0.5)
plt.scatter(df_resampled["Datetime"], df_resampled["Close"], color="red", label="Resampled Data (Top 25%)")
plt.legend()
plt.title("Gradient-Based Adaptive Sampling")
plt.xlabel("Date")
plt.ylabel("Price")
plt.show()
# 📌 サンプリング後のデータを確認
print(df_resampled.head())
価格変化率(勾配)に基づいて上位25%の変動を持つデータを抽出しています。これにより、価格変動が大きい期間に焦点を当てた分析が可能になります。
異常値検知+勾配変化率の組み合わせ
- 異常検知と適応サンプリングを組み合わせることで、価格変動が大きい期間の異常イベントを特定し、リスク管理やトレーディング戦略の最適化が可能になります。市場のボラティリティを詳細に分析し、急激な変動や異常な取引活動を早期に察知することで、投資判断の精度を向上させることができます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from sklearn.ensemble import IsolationForest
# 📌 データ取得(ETH-USDの1時間足データ)
df = yf.download("ETH-USD", period="6mo", interval="1h")
df.reset_index(inplace=True)
# 📌 勾配(価格変化率)を計算
df["gradient"] = df["Close"].diff().abs()
# 📌 変動の大きいデータを抽出(上位25%)
threshold = df["gradient"].quantile(0.75)
df_resampled = df[df["gradient"] > threshold]
# 📌 IsolationForestモデルのインスタンス化
model = IsolationForest(contamination=0.1)
# 📌 異常値検出の実行
df["anomaly"] = model.fit_predict(df[["Close"]])
# 📌 異常値の抽出
df_anomalies = df[df["anomaly"] == -1]
# 📌 結果を可視化
plt.figure(figsize=(12, 6))
plt.plot(df["Datetime"], df["Close"], label="Original Data", alpha=0.5)
plt.scatter(df_resampled["Datetime"], df_resampled["Close"], color="red", label="Resampled Data (Top 25%)")
plt.scatter(df_anomalies["Datetime"], df_anomalies["Close"], color="blue", label="Anomalies", marker="x")
plt.legend()
plt.title("Gradient-Based Adaptive Sampling with Anomaly Detection")
plt.xlabel("Date")
plt.ylabel("Price")
plt.show()
# 📌 サンプリング後のデータを確認
print(df_resampled.head())
print(df_anomalies.head())
異常値検知と勾配変化率を組み合わせはフラッシュクラッシュなどの価格の急変を早期に捉え、リスク管理やトレーディング戦略の最適化に活用することができます。
異常値を検出した場合のリスク管理とトレーディング戦略
- 先ほどのコードから異常検知が異常値が検出された場合にポジションをクローズする、またはストップロスを設定するなどの戦略を実装します。
# 📌 リスク管理とトレーディング戦略の構築
def trading_strategy(df):
initial_capital = 10000
capital = initial_capital
position = 0
stop_loss = 0.05 # 5%のストップロス
take_profit = 0.10 # 10%のテイクプロフィット
for i in range(1, len(df)):
if df["anomaly"].iloc[i] == -1:
# 異常値が検出された場合、ポジションをクローズ
if position != 0:
capital += position * df["Close"].iloc[i]
position = 0
print(f"Closed position at {df['Datetime'].iloc[i]} due to anomaly detection")
elif df["gradient"].iloc[i] > threshold:
# 変動が大きい場合、ポジションをエントリー
if position == 0:
position = capital / df["Close"].iloc[i]
capital = 0
print(f"Entered position at {df['Datetime'].iloc[i]}")
# ストップロスとテイクプロフィットのチェック
if position != 0:
current_value = position * df["Close"].iloc[i]
if current_value <= initial_capital * (1 - stop_loss):
capital += current_value
position = 0
print(f"Closed position at {df['Datetime'].iloc[i]} due to stop loss")
elif current_value >= initial_capital * (1 + take_profit):
capital += current_value
position = 0
print(f"Closed position at {df['Datetime'].iloc[i]} due to take profit")
# 最終的なキャピタルを計算
if position != 0:
capital += position * df["Close"].iloc[-1]
return capital
final_capital = trading_strategy(df)
print(f"Final capital: {final_capital}")どのダウンサンプリング手法を使うべきか?
| 手法 | 計算コスト | 特徴 | 適用例 |
|---|---|---|---|
| 単純間引き | 低い | 一定間隔ごとに間引く | 高頻度取引データのダウンサンプリング |
| 価格変動ベース | 中程度 | 変動が大きい部分を優先 | ボラティリティの高い市場(仮想通貨、FX) |
| 移動平均・中央値 | 低い | 平均化して滑らかにする | ノイズ除去が必要な市場(株式、金利) |
| 適応的サンプリング | 高い | 異常値やトレンドを自動検出 | AIによる自動取引、リスク管理 |
結論:
GPUメモリを節約しつつ、精度を維持するには適切なダウンサンプリングが重要です。金融時系列データの用途に応じた手法を選択し、Transformer に投入する前に適切に整形することで、計算負荷を抑えながら効果的なデータ処理が可能になります。
ハードウェア側の工夫
1. GPUメモリスワップ
GPUメモリスワップは、不要なデータを一時的に解放し、メモリを効率的に活用する手法です。特に、ディープラーニングや大規模な時系列データ解析ではメモリ消費が増えやすいため、適切な管理が重要になります。
- NVIDIAの
torch.cuda.empty_cache()を活用してメモリを解放
import torch
# GPUの使用状況を確認
print(f"Before clearing cache: {torch.cuda.memory_allocated() / 1e9:.2f} GB")
# 不要なメモリを解放
torch.cuda.empty_cache()
# 解放後のメモリ使用状況を確認
print(f"After clearing cache: {torch.cuda.memory_allocated() / 1e9:.2f} GB")torch.cuda.empty_cache() を使うと、一時的に不要なGPUメモリを解放できます。ただし、過剰な使用はオーバーヘッドを招くため、適切なタイミングで実行することが重要です。追加のメモリ最適化と組み合わせることで、大規模な時系列データ解析やディープラーニングのメモリ不足を軽減できます。
2. 最新のGPUを使用
- RTX 3090 (24GB), A100 (80GB), H100 (80GB) などの大容量メモリのGPUを使用。
GPUメモリ制約を解決するための方法の選び方
| 方法 | 説明 | メリット | デメリット |
|---|---|---|---|
| FP16 (Mixed Precision Training) | 16bit精度の計算 | メモリ使用量を半減 | 精度低下の可能性 |
| Pruning & Quantization | モデルを圧縮 | メモリ削減 | 学習後の微調整が必要 |
| Longformer / Reformer | 長いシーケンスの処理を最適化 | メモリ削減 | 実装が複雑 |
| Gradient Checkpointing | 勾配保存を減らす | メモリ節約 | 計算負荷増加 |
| シーケンス分割 (Chunking) | 長いシーケンスを小分けに処理 | メモリ削減 | 時系列の相関を考慮する必要 |
| 分散学習 | GPU間で計算を分割 | メモリ効率化 | GPU間の通信コスト |
| バッチサイズの調整 | 一度に処理するデータ量を減らす | 簡単に実装可能 | 学習速度の低下 |
Transformerモデルを使う場合の課題
金融時系列データ分析では、Transformerのエンコーダーのみでも特徴抽出や異常検知が可能であり、計算負荷が低いためゲーミングPCなどの環境でも実装しやすい。一方で、未来予測などの自己回帰型モデルではデコーダーを追加することで予測精度の向上が期待できるが、その分計算コストが増大するため、高性能GPU(例:NVIDIA Project DIGITS)が推奨される。エンコーダーのみのモデルは市場のトレンド解析やノイズ除去に適し、デコーダーを加えると時系列の未来予測に対応できる。環境に応じて、計算負荷の低いエンコーダーモデルと、高精度なエンコーダー+デコーダーモデルを使い分けるのが最適なアプローチとなる。
最適なアプローチ
| 使用するモデル | 適用タスク | 環境の要求 |
|---|---|---|
| Transformerエンコーダーのみ | 特徴量抽出、異常検知、ノイズ除去、未来予測(自己回帰を行わない場合) | 軽量な環境(ゲーミングPCなど)でもOK |
| エンコーダー + デコーダー(自己回帰モデル) | 未来予測(価格生成・トレンド予測) | 高性能GPUが推奨(NVIDIA Project DIGITSなど) |
異常検知・予測
- 異常検知 (Anomaly Detection) とは?
- 通常のパターンから外れたデータを特定する手法であり、金融時系列データでは異常な価格変動や取引パターンの検出に活用されます。
| 異常例 | 説明 |
|---|---|
| フラッシュクラッシュ | 短時間での急落または急騰。 |
| BOT取引の異常パターン | 不自然な注文や高速売買(HFT)による市場価格への影響。 |
| 異常な出来高の増加 | 通常の市場活動から逸脱した大規模取引が急増する現象。 |
| マーケットメイクの異常動作 | スプレッドの急変動や流動性供給の異常。 |
Transformerを使った異常検知の実践
今回の異常検知の目的は、金融市場の異常を高精度に検知し、リスク管理やアルゴリズム取引を最適化することです。価格の急変動や異常な取引を捉えるために、TransformerのSelf-Attention機構を活用し、長期的な依存関係と局所的な変動を同時に分析する手法を紹介します。これにより、市場の異常を的確に識別し、より効果的な取引や分析が可能になります。
- 前回の異常検知
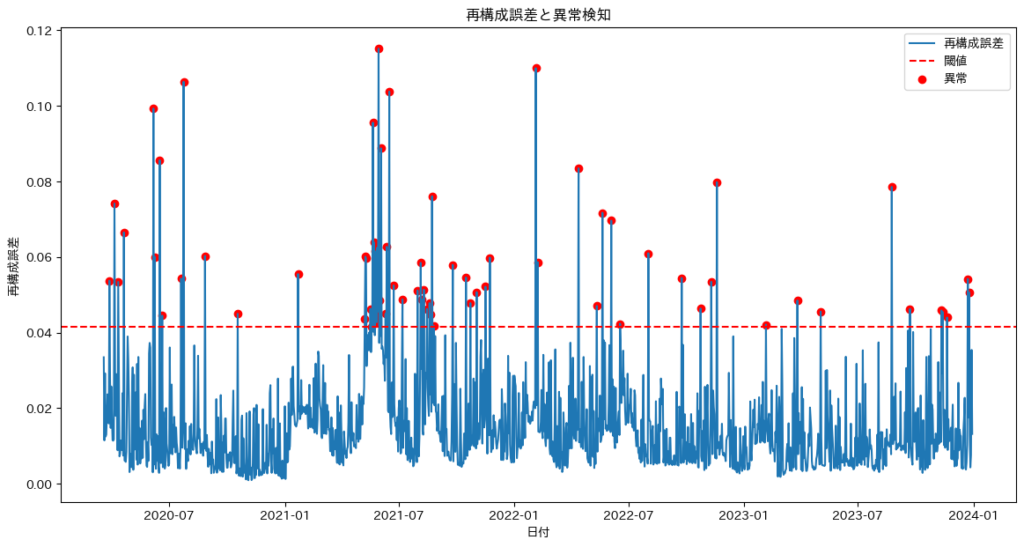
- 従来の課題
- 従来の異常検知手法(統計的手法やLSTMなど)は、短期間のパターンを捉えるのに適していますが、長期的な市場の変化や多次元データを考慮するのが難しいという課題があります。
- Transformerの異常検知の特徴
- Transformerは、短期・長期の市場パターンを柔軟に学習し、リアルタイムの異常検知を可能にするため、金融市場の異常検知に最適なモデルの一つです。
| 特徴 | 説明 |
|---|---|
| 長期依存関係を考慮 | Self-Attention により、過去の市場パターンと比較しながら異常を検出可能。 例:1週間前のボラティリティ変化が現在の異常と関連しているかを分析。 |
| 多次元データを統合して学習 | 価格(OHLCV)だけでなく、テクニカル指標、センチメントデータ、オーダーブック情報などを組み合わせ、より正確な異常検知を実現。 |
| リアルタイムの異常検知 | 並列計算により、大量の金融データを効率的に処理できるため、リアルタイム市場監視やアルゴリズムトレードへの応用が可能。 |
| 自己教師あり学習の活用 | マスク学習や予測タスクを活用し、正常な市場パターンを学習したうえで、異常な価格変動を高精度に検出する手法を実装可能。 |
異常検知の目的と課題
| 目的 | 課題 |
|---|---|
| 正常パターンの学習: 通常時の金融データのパターン(トレンド、周期性、ボラティリティなど)を正確に学習し、そこから逸脱したデータポイントを特定する。 | データの非定常性: 金融市場は時間とともに統計的性質が変化するため、学習済みモデルが常に最新の市場環境に適応するとは限らない。 |
| 早期異常検知: 急激な変動や突発的なイベントなど、市場リスクの高い局面を早期に検知し、リスク管理や取引戦略に反映させる。 | 異常の定義の曖昧さ: 異常値や外れ値の定義はケースバイケースであり、正常時と異常時の境界線が明確でない場合が多い。 |
Transformerによる異常検知のメリットデメリット
| メリット | デメリット |
|---|---|
| 長期・短期依存性の同時学習: Self-Attention機構により、過去の重要なイベントや短期的な変動の両方を学習できるため、複雑なパターンを捉える能力が高い。 | 計算資源の消費: 長いシーケンスを扱う場合、Self-Attentionの計算量が二乗に増加し、GPUメモリの制約や計算コストが大きくなる。 |
| 自己教師あり学習との親和性: マスク学習や再構成タスクを組み合わせることで、正常データの特徴を深く学習し、異常時の再構成誤差を指標とする手法が構築しやすい。 | ハイパーパラメータの調整の難しさ: 正常データと異常データの境界が曖昧なため、学習率、シーケンス長、マスク比率などの最適化が困難。 |
| 並列処理で高速な推論: Transformerは並列処理に優れ、リアルタイム異常検知や大量データの処理に適している。 | 過学習リスク: 正常データに強く適合しすぎると、微妙な異常パターンを見逃す可能性があり、モデルの一般化性能に課題が残る。 |
適用例
| 適用例 | 説明 |
|---|---|
| 市場監視システム | リアルタイムで金融市場の異常な動きを検知し、トレーダーやリスク管理部門にアラートを発信するシステム。 |
| アルゴリズム取引 | 異常検知結果を取引戦略に組み込み、急変局面でのリスクヘッジやポジション調整に活用する。 |
| 信用リスク評価 | 異常な価格変動パターンを用いて、銘柄や資産の信用リスクを評価し、ポートフォリオの最適化に利用する。 |
異常検知用のTransformerモデルの例
市場では予測不能な価格変動や異常な取引が頻繁に発生し、正確な検出がリスク管理やアルゴリズムトレードの最適化に不可欠です。本記事では、特に有効な3つのTransformerモデルを紹介します。
Autoencoder型 Transformer(異常検知)
Autoencoder型 Transformerは、正常な市場データのパターンを学習し、異常なデータを高い誤差で再構成することで異常検知を行う手法です。従来のLSTMベースのAutoencoderと異なり、TransformerのSelf-Attentionを活用することで、長期的な市場の変動や複雑なパターンを捉えることが可能になります。
- オートエンコーダについては下記を参照してください。
- LSTMベースのAutoencoder
仕組み
- エンコーダ (Encoder)
- 市場データ(ETHの価格や出来高など)をSelf-Attention機構を用いて解析し、異なる時点の関係性を考慮しながら重要な特徴を抽出し、潜在空間に圧縮します。
- デコーダ (Decoder)
- エンコーダが学習した特徴を基に元のデータを再構成し、正常なパターンは誤差が小さく、異常なパターンは誤差が大きくなる仕組みです。
- 異常値の判定
- 再構成誤差(MSEやMAE)を計算し、閾値を超えた場合に異常として検出します。例えば、急激な価格変動や取引量の急増が異常と判定されることがあります。
数式
Autoencoder型 Transformerの学習目標は、入力データ $X$ を再構成することです。
- エンコーダによる特徴抽出($Z$ は潜在空間の特徴表現)
$$Z=Encoder(X)$$
- デコーダによる再構成($\hat{X}$ は再構成されたデータ)
$$\hat{X}=Decoder(Z)$$
- 損失関数 (再構成誤差)
$$L = \frac{1}{N} \sum_{i=1}^{N} (X_i – \hat{X}_i)^2$$
- $L$ はMSE(平均二乗誤差)を用いた損失関数。
- 異常値判定(閾値 $\tau$ を超えた場合に異常と判定)
$$if L>τ,X は異常$$
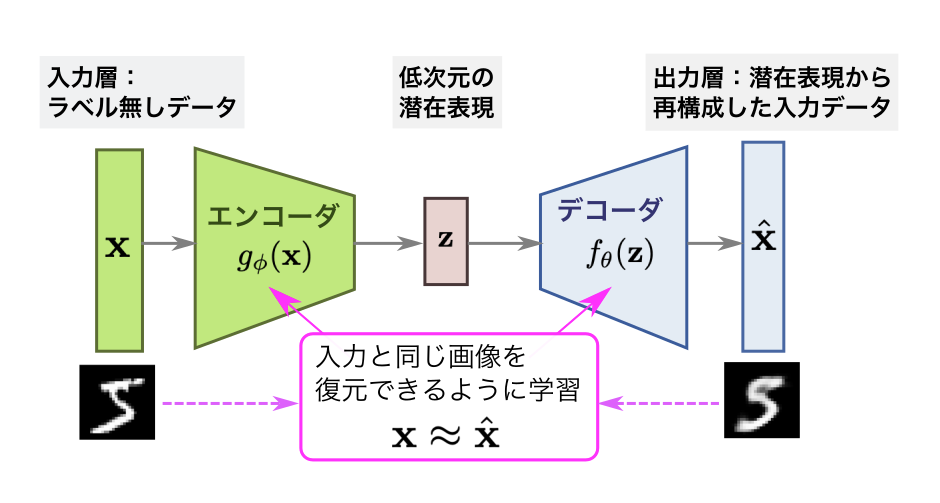
メリットデメリット
| メリット | デメリット |
|---|---|
| 長期依存関係の学習: TransformerのSelf-Attentionにより、時系列データの長期的な変動を捉えることが可能。 | 高い計算コスト: Transformerはパラメータ数が多いため、学習や推論時に高い計算リソースが必要。 |
| 複雑な市場パターンの解析: 従来の線形モデル(ARIMAなど)では捉えにくい、非線形な市場の動きを学習。 | データの前処理が重要: ノイズを多く含む時系列データでは、適切な正規化やフィルタリングが必要。 |
| 並列計算による高速化: LSTMの逐次処理と異なり、Transformerは並列計算が可能で、大量データの処理が高速。 |
Autoencoder型 Transformerの実装例:
- 今回はTransformerモデルとAutoencoderにはVAEを使って金融時系列データの異常検知の実装を行います。
- TransformerのGPUメモリ使用量の削減には勾配チェックポイントを使用してメモリ使用量を削減します。
Transformer(エンコーダー・デコーダー) + VAEによる異常検知の実装
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.checkpoint as checkpoint
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示用(必要に応じて)
from torch.cuda.amp import autocast, GradScaler
# デバイスの設定(mpsを利用)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')
# 1. データ取得と前処理(技術指標付き)
def prepare_data(seq_length=30):
# 期間は例として2020年~2025年
ticker = 'ETH-USD'
data = yf.download(ticker, start='2020-01-01', end='2025-01-31')
# テクニカル指標の計算
data['SMA_10'] = data['Close'].rolling(window=10).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
data['BB_upper'] = data['Close'].rolling(window=20).mean() + 2 * data['Close'].rolling(window=20).std()
data['BB_lower'] = data['Close'].rolling(window=20).mean() - 2 * data['Close'].rolling(window=20).std()
# RSIの計算
def compute_rsi(series, window=14):
delta = series.diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI_14'] = compute_rsi(data['Close'], window=14)
data.dropna(inplace=True)
# 特徴量の選択
features = ['Open', 'High', 'Low', 'Close', 'Volume', 'SMA_10', 'SMA_50', 'BB_upper', 'BB_lower', 'RSI_14']
data = data[features]
# 正規化(MinMaxScaler)
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンス作成(スライディングウィンドウ)
X = []
for i in range(len(data_scaled) - seq_length + 1):
X.append(data_scaled[i:i+seq_length])
X = np.array(X)
# ※今回はオートエンコーダーなので、入力=ターゲット
X_tensor = torch.tensor(X, dtype=torch.float32)
dataset = TensorDataset(X_tensor, X_tensor)
# また、日付情報(インデックス)は後で可視化に利用
dates = data.index[seq_length-1:]
return dataset, scaler, seq_length, dates
# 2. TransformerベースのVAEモデル(勾配チェックポイント付き)
class TransformerVAE(nn.Module):
def __init__(self, input_dim, embed_dim, latent_dim, seq_length, num_layers, num_heads, dropout=0.1):
super(TransformerVAE, self).__init__()
self.seq_length = seq_length
self.embedding = nn.Linear(input_dim, embed_dim)
# 位置エンコーディング(学習可能なパラメータ)
self.pos_embedding = nn.Parameter(torch.zeros(seq_length, embed_dim))
# Encoder: Transformerエンコーダ
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 潜在変数への変換(平均プーリング後)
self.fc_mu = nn.Linear(embed_dim, latent_dim)
self.fc_logvar = nn.Linear(embed_dim, latent_dim)
# Decoder: Transformerデコーダ
self.latent_to_embed = nn.Linear(latent_dim, embed_dim)
decoder_layer = nn.TransformerDecoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
self.output_layer = nn.Linear(embed_dim, input_dim)
def encode(self, x):
# x: [batch, seq_length, input_dim]
x = self.embedding(x) # [batch, seq_length, embed_dim]
x = x + self.pos_embedding.unsqueeze(0) # 位置エンコーディングの加算
x = x.transpose(0, 1) # Transformerは [seq_length, batch, embed_dim]
# 勾配チェックポイントを適用してメモリ削減
encoded = checkpoint.checkpoint(self.encoder, x) # [seq_length, batch, embed_dim]
pooled = encoded.mean(dim=0) # 平均プーリング → [batch, embed_dim]
mu = self.fc_mu(pooled)
logvar = self.fc_logvar(pooled)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
# z: [batch, latent_dim]
latent_embed = self.latent_to_embed(z) # [batch, embed_dim]
tgt = latent_embed.unsqueeze(0).repeat(self.seq_length, 1, 1) # [seq_length, batch, embed_dim]
# シンプルなデコーダ関数を定義し、チェックポイントを適用
def decoder_func(t):
return self.decoder(t, t)
decoded = checkpoint.checkpoint(decoder_func, tgt) # [seq_length, batch, embed_dim]
decoded = decoded.transpose(0, 1) # [batch, seq_length, embed_dim]
output = self.output_layer(decoded)
return output
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
recon = self.decode(z)
return recon, mu, logvar
# 損失関数(再構成誤差+KLダイバージェンス)
def loss_function(recon_x, x, mu, logvar):
recon_loss = nn.MSELoss()(recon_x, x)
kl_loss = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss
# 3. 学習ループ(自動混合精度 AMP によるFP16計算でメモリ削減)
def train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001):
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
input_dim = dataset.tensors[0].shape[2]
seq_length = dataset.tensors[0].shape[1]
model = TransformerVAE(input_dim, embed_dim=32, latent_dim=16, seq_length=seq_length,
num_layers=2, num_heads=2, dropout=0.1).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scaler_amp = GradScaler() # AMP用スケーラー
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for batch_x, _ in dataloader:
batch_x = batch_x.to(device)
optimizer.zero_grad()
with autocast():
recon, mu, logvar = model(batch_x)
loss = loss_function(recon, batch_x, mu, logvar)
scaler_amp.scale(loss).backward()
scaler_amp.step(optimizer)
scaler_amp.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
return model
# 4. 異常検知の評価:再構成誤差に基づく異常スコアの算出
def evaluate_anomaly(model, dataset, scaler, dates):
dataloader = DataLoader(dataset, batch_size=64, shuffle=False)
model.eval()
reconstruction_errors = []
with torch.no_grad():
for batch_x, _ in dataloader:
batch_x = batch_x.to(device)
recon, _, _ = model(batch_x)
loss = ((recon - batch_x)**2).mean(dim=(1,2)).cpu().numpy()
reconstruction_errors.extend(loss)
reconstruction_errors = np.array(reconstruction_errors)
threshold = np.percentile(reconstruction_errors, 95)
anomalies = reconstruction_errors > threshold
print(f"Threshold for anomaly detection: {threshold:.4f}")
print(f"Number of anomalies detected: {np.sum(anomalies)} / {len(anomalies)}")
plt.figure(figsize=(14, 7))
plt.plot(dates, reconstruction_errors, label="再構成誤差")
plt.axhline(threshold, color='red', linestyle='--', label="閾値")
plt.scatter(dates[anomalies], reconstruction_errors[anomalies], color='red', label="異常")
plt.title("再構成誤差と異常検知")
plt.xlabel("日付")
plt.ylabel("再構成MSE")
plt.legend()
plt.show()
return reconstruction_errors, threshold, anomalies
# 5. メイン処理
def main():
dataset, scaler, seq_length, dates = prepare_data(seq_length=30)
model = train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001)
reconstruction_errors, threshold, anomalies = evaluate_anomaly(model, dataset, scaler, dates)
if __name__ == "__main__":
main()Epoch [29/30], Loss: 0.0527
Epoch [30/30], Loss: 0.0552
Threshold for anomaly detection: 0.1306
Number of anomalies detected: 89 / 1779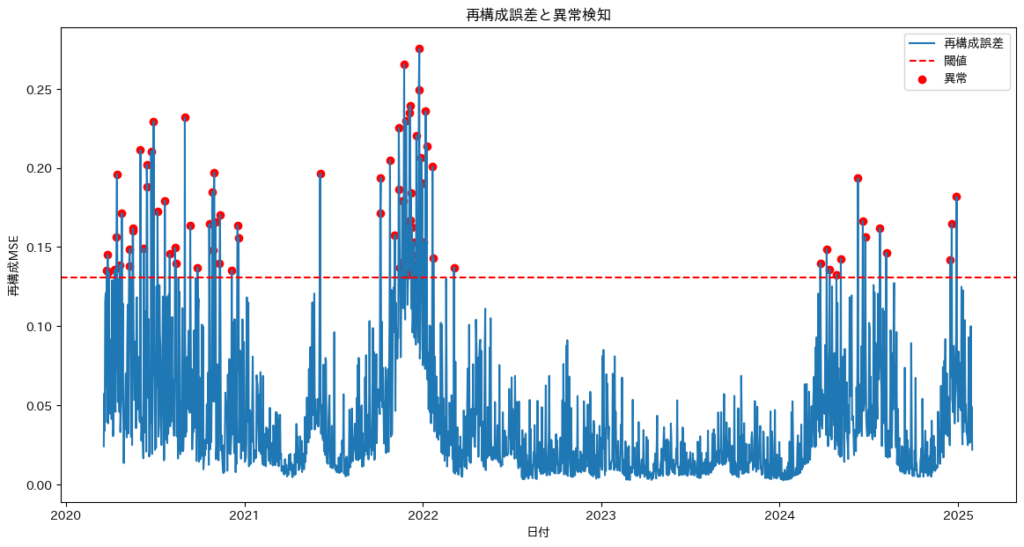
このモデルは、長期的な依存関係を持つ時系列データの異常検知に優れ、複雑なパターンを捉えることができます。十分な計算リソースがあれば、より高精度な異常検知が可能です。
再構成誤差の閾値は、前処理やモデル設定によって変動します。
次の潜在空間の可視化コードでは、同じTransformer + VAEモデルでも前処理を変更すると閾値が上がることが確認できます。
マルチアセット解析とクラスタリング
金融市場は単純な線形モデルでは捉えきれない非線形な関係性を多く含み、資産の相関も市場環境によって変動します。Transformer + VAE を活用することで、これらの非線形な関係を学習し、潜在空間で可視化できます。これにより、資産のクラスタリング、リスク管理、トレード戦略の最適化が可能となり、より精度の高い意思決定を行うことが可能になります。
Transformer(エンコーダー・デコーダー) + VAEによる潜在空間の可視化とPCAによる線形手法との比較の実装例
- TransformerをVAEに組み合わせることで、時系列データの長期依存性や局所パターンがより効果的に抽出され、各資産固有の非線形相関や変動を学習できるようになります。
import yfinance as yf
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from mpl_toolkits.mplot3d import Axes3D
from torch.utils.data import DataLoader, TensorDataset
# deviceの定義
device = torch.device("mps" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# データの取得と前処理
tickers = ["ETH-USD", "BTC-USD", "XRP-USD"]
start_date = "2020-01-01"
end_date = "2025-01-31"
dfs = []
for t in tickers:
df_tmp = yf.download(t, start=start_date, end=end_date)[["Open","High","Low","Close","Volume"]].dropna()
df_tmp["Asset"] = t # 銘柄名を追加
df_tmp.reset_index(inplace=True) # 日付をカラムに変換
dfs.append(df_tmp)
df_all = pd.concat(dfs, axis=0)
df_all.sort_values(by=['Asset','Date'], inplace=True)
# スケーリング
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df_all[["Open","High","Low","Close","Volume"]])
# スライディングウィンドウと prepare_data 関数
seq_length = 30
def create_sequences(data, assets, seq_len):
seqs = []
dates = []
labels = []
unique_assets = assets.unique()
for asset in unique_assets:
idx = (assets == asset).values
subset = data[idx]
# 対応する日付取得(df_all の Date 列として存在する前提)
asset_dates = df_all.loc[idx, "Date"].to_numpy()
for i in range(len(subset) - seq_len):
seq = subset[i : i + seq_len]
seqs.append(seq)
labels.append(asset)
dates.append(asset_dates[i + seq_len - 1])
return np.array(seqs), np.array(labels, dtype=object), np.array(dates)
def prepare_data(seq_len):
X, asset_labels, dates = create_sequences(scaled_data, df_all["Asset"], seq_len)
X_tensor = torch.tensor(X, dtype=torch.float32)
dataset = TensorDataset(X_tensor, X_tensor)
return dataset, asset_labels, X_tensor, dates
# TransformerベースのVAEモデル
class TransformerVAE(nn.Module):
def __init__(self, input_dim, embed_dim, latent_dim, seq_length, num_layers, num_heads, dropout=0.1):
super(TransformerVAE, self).__init__()
self.seq_length = seq_length
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_embedding = nn.Parameter(torch.zeros(seq_length, embed_dim))
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc_mu = nn.Linear(embed_dim, latent_dim)
self.fc_logvar = nn.Linear(embed_dim, latent_dim)
self.latent_to_embed = nn.Linear(latent_dim, embed_dim)
decoder_layer = nn.TransformerDecoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
self.output_layer = nn.Linear(embed_dim, input_dim)
def encode(self, x):
x = self.embedding(x)
x = x + self.pos_embedding.unsqueeze(0)
x = x.transpose(0, 1)
encoded = self.encoder(x)
pooled = encoded.mean(dim=0)
mu = self.fc_mu(pooled)
logvar = self.fc_logvar(pooled)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
latent_embed = self.latent_to_embed(z)
tgt = latent_embed.unsqueeze(0).repeat(self.seq_length, 1, 1)
decoded = self.decoder(tgt, tgt)
decoded = decoded.transpose(0, 1)
output = self.output_layer(decoded)
return output
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
recon = self.decode(z)
return recon, mu, logvar
# 損失関数
def loss_function(recon_x, x, mu, logvar):
recon_loss = nn.MSELoss()(recon_x, x)
kl_loss = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss
# 学習ループ
def train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001):
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
input_dim = dataset.tensors[0].shape[2]
seq_len = dataset.tensors[0].shape[1]
model = TransformerVAE(input_dim, embed_dim=32, latent_dim=3, seq_length=seq_len,
num_layers=2, num_heads=2, dropout=0.1).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for batch_x, _ in dataloader:
batch_x = batch_x.to(device)
optimizer.zero_grad()
recon, mu, logvar = model(batch_x)
loss = loss_function(recon, batch_x, mu, logvar)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
return model
# 異常検知の評価
def evaluate_anomaly(model, dataset, dates):
dataloader = DataLoader(dataset, batch_size=64, shuffle=False)
model.eval()
reconstruction_errors = []
with torch.no_grad():
for batch_x, _ in dataloader:
batch_x = batch_x.to(device)
recon, _, _ = model(batch_x)
loss = ((recon - batch_x)**2).mean(dim=(1,2)).cpu().numpy()
reconstruction_errors.extend(loss)
reconstruction_errors = np.array(reconstruction_errors)
threshold = np.percentile(reconstruction_errors, 95)
anomalies = reconstruction_errors > threshold
print(f"Threshold for anomaly detection: {threshold:.4f}")
print(f"Number of anomalies detected: {np.sum(anomalies)} / {len(anomalies)}")
plt.figure(figsize=(14, 7))
plt.plot(dates, reconstruction_errors, label="再構成誤差")
plt.axhline(threshold, color='red', linestyle='--', label="閾値")
plt.scatter(dates[anomalies], reconstruction_errors[anomalies], color='red', label="異常")
plt.title("再構成誤差と異常検知")
plt.xlabel("日付")
plt.ylabel("再構成MSE")
plt.legend()
plt.show()
return reconstruction_errors, threshold, anomalies
# メイン処理
def main():
# データの準備
dataset, asset_labels, X_tensor, dates = prepare_data(seq_length)
# モデルの学習
model = train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001)
# 異常検知の評価
reconstruction_errors, threshold, anomalies = evaluate_anomaly(model, dataset, dates)
# 潜在空間の可視化
model.eval()
with torch.no_grad():
_, mu_all, _ = model(dataset.tensors[0].to(device))
latent_data = mu_all.cpu().numpy()
# K-meansクラスタリング
kmeans = KMeans(n_clusters=3, random_state=42).fit(latent_data)
labels_km = kmeans.labels_
df_latent = pd.DataFrame({"Asset": asset_labels, "Cluster": labels_km})
print(df_latent.groupby(["Cluster","Asset"]).size())
# 2D可視化 (VAE)
plt.figure(figsize=(8,6))
for cluster in np.unique(labels_km):
idx = labels_km == cluster
plt.scatter(latent_data[idx, 0], latent_data[idx, 1], label=f"Cluster {cluster}")
plt.title("Latent Space (VAE) with K-means Clusters")
plt.xlabel("Z1")
plt.ylabel("Z2")
plt.legend()
plt.show()
# PCAと比較
pca = PCA(n_components=2)
pca_data = pca.fit_transform(X_tensor.view(-1, X_tensor.shape[2]).numpy())
labels_pca = KMeans(n_clusters=3, random_state=42).fit_predict(pca_data)
plt.figure(figsize=(8,6))
for cluster in np.unique(labels_pca):
idx = labels_pca == cluster
plt.scatter(pca_data[idx, 0], pca_data[idx, 1], label=f"Cluster {cluster}")
plt.title("PCA Space with K-means Clusters")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.legend()
plt.show()
# 3D可視化 (VAE)
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
for cluster in np.unique(labels_km):
idx = labels_km == cluster
ax.scatter(latent_data[idx, 0], latent_data[idx, 1], latent_data[idx, 2], label=f"Cluster {cluster}")
ax.set_title("Latent Space (VAE) with K-means Clusters (3D)")
ax.set_xlabel("Z1")
ax.set_ylabel("Z2")
ax.set_zlabel("Z3")
ax.legend()
plt.show()
if __name__ == "__main__":
main()Epoch [29/30], Loss: 0.4764
Epoch [30/30], Loss: 0.4743
Threshold for anomaly detection: 0.8872
Number of anomalies detected: 274 / 5481前処理の影響により、先ほど実装した異常検知のコードよりも閾値が高くなっているのがわかります。これは今回の異常検知の方が、異常の範囲が広く、市場の急変に強いが誤検知の可能性が高いということを示しています。
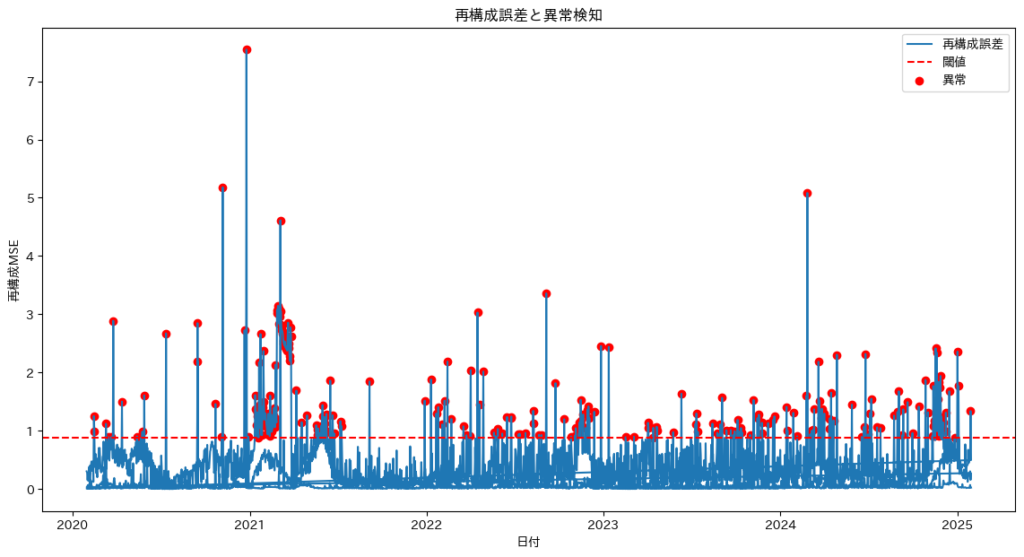
Cluster Asset
0 BTC-USD 303
ETH-USD 1827
XRP-USD 1827
1 BTC-USD 605
2 BTC-USD 919
dtype: int64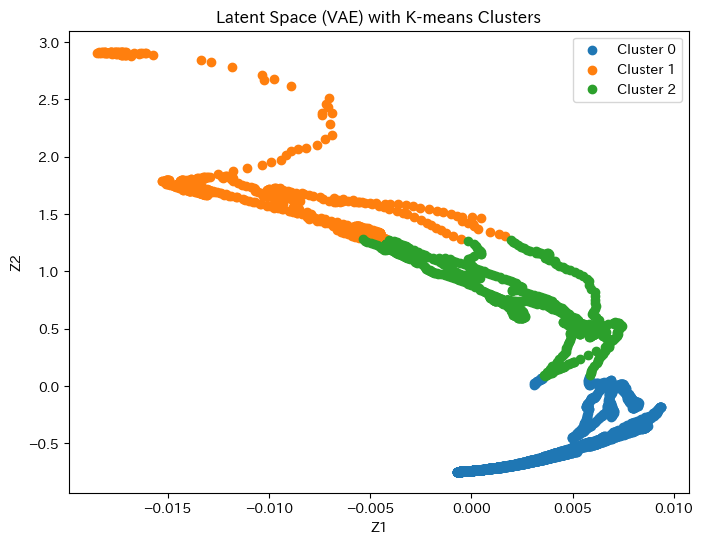
PCAとの対比
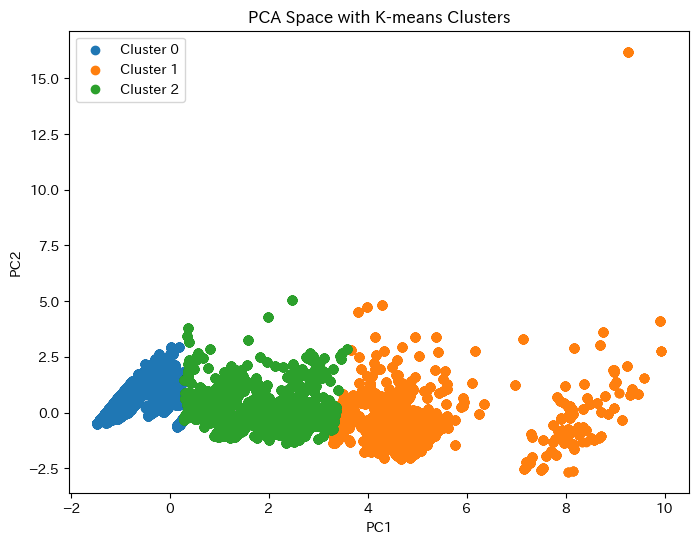
潜在空間上でのクラスタリングが明確になり、PCAなどの線形手法では捉えにくい複雑なデータ構造をうまく表現できるため、マルチアセット解析やリスク管理に有用な特徴空間が得られます。
- またVAEモデル単体と比べるとTransformerモデルの効果がよくわかります。
3Dで可視化することにより、潜在空間の非線形な構造やクラスタの配置が明確になり、クラスタ間の関係性や多次元データの相互作用を直感的に理解できるため、モデルの解釈性向上やリスク管理、分散投資戦略の最適化に役立ちます。
論文:『Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy』

- 「相関の不一致(Association Discrepancy)」を利用した異常検知
- 通常の時系列データは広範囲の時点と相関を持ちますが、異常値は隣接する時点との関連が強く、全体との関連が薄い傾向があります。本研究では、この違いを活用し、「相関の不一致(Association Discrepancy)」を異常検知の指標として導入しました。局所的な関連性(事前相関)と全体の関連性(系列相関)を比較し、その差を異常スコアとして算出することで、従来よりも高精度に異常を検出できるようになっています。
- ミニマックス最適化による異常値と正常値の識別強化
- 本研究では、ミニマックス最適化を採用し、正常データの再構成誤差と相関の不一致を最小化しつつ、異常データではそれを最大化する戦略を導入しました。これにより、正常データと異常データの違いを明確にし、高精度な異常検知を実現。特に、SWaTやSMDなどの産業データに適用し、従来手法を上回る性能を達成しました。複雑な時系列データにも対応でき、リアルタイム異常検知への応用も期待されます。
- 2つの自己注意ブランチを活用した異常検知機構
- 本手法では、2つの自己注意ブランチ を組み合わせることで、異常検知の精度を向上させます。① 事前相関ブランチ は、局所的なデータの関連性を学習し、通常のパターンを把握。② 系列相関ブランチ は、時系列全体の関係性を捉え、異常パターンを特定。この2つを組み合わせることで、短期・長期の異常をより正確に検出でき、産業や金融市場の異常監視に応用可能です。
- この手法はどのTransformerに近いのか?
- 本手法は、異常検知に特化した Transformer の拡張モデル であり、Dual-Branch Self-Attention を採用することで、局所的な相関(Prior-Association Branch)と全体の関係性(Series-Association Branch)を同時に学習します。従来の Anomaly Transformer に近い設計ですが、Association Discrepancy(相関の不一致) を活用し、ミニマックス最適化により異常パターンを強調。これにより、標準的な Transformer よりも異常検知の精度が向上し、金融市場や産業データに適用可能なモデル となっています。
時系列予測型 Transformer(異常検知&予測)
時系列予測型 Transformer は、時系列データの未来を予測し、予測誤差を異常検知に活用する手法です。従来の LSTM や ARIMA では捉えにくい長期依存関係を学習し、高次元データへの適用や並列計算による高速処理が可能です。一方で、計算コストの高さや閾値設定の難しさが課題となります。金融市場の異常検知や機械の故障予測など、リアルタイム異常検知が求められる分野で活用されています。
特徴
| 特徴 | 説明 |
|---|---|
| 長期依存関係の学習 | Self-Attention により、長期間にわたる市場データの関連性を学習し、従来の時系列モデルよりも柔軟にパターンを捉えることが可能。 |
| リアルタイム予測が可能 | 並列計算を活用し、LSTM のような逐次処理を必要とせずに高速な推論を実現し、リアルタイムでの予測を可能にする。 |
| 高次元データへの適用 | 価格、出来高、ボラティリティ指標など複数の時系列特徴を統合して処理できるため、複雑な市場データの予測に対応できる。 |
| 異常検知との統合が容易 | 予測誤差(再構成誤差に相当)を指標として利用し、閾値ベースの異常検知アプローチと統合することで、異常な市場動向の検出がしやすくなる。 |
数式
- 時系列予測型 Transformer は、未来の時系列データ $y_{t+h}$ を過去の観測値 $x_t$ から予測し、誤差を計算します。
入力データのエンコーディング
- Transformer の入力として、過去の $T$ 個の時系列データ $X = (x_1, x_2, …, x_T)$ をエンコードします。
$$Z=Encoder(X)$$
未来の時系列データの予測
- Decoder により、未来のデータ $\hat{y}_{T+h}$ を生成します。
$$\hat{y}_{T+h} = \text{Decoder}(\mathbf{Z})$$
予測誤差の算出
- 異常検知には、実際の値 $y_{T+h}$ と予測値 $\hat{y}_{T+h}$ の誤差を計算し、その大きさを異常スコアとして利用します。
$$\begin{aligned}
\text{Error}(t) &= | y_t – \hat{y}_t | \\
\text{Anomaly Score}(t) &= \frac{| y_t – \hat{y}_t |}{\sigma}
\end{aligned}$$
- σ は誤差の標準偏差で、異常値を閾値で判断します。
目的と課題
| 目的 | 課題 |
|---|---|
| 過去の市場データから将来の値動きを予測する | TransformerはO(N²)の計算負荷があるため、GPUメモリ使用量の削減が必要 |
| 異常なパターンを特定する手法 | ノイズや外れ値に敏感で、異常データが極めて少なく十分な学習が困難 |
| 金融市場、産業設備、エネルギー分野などでの異常検知に応用可能 | 閾値や重みパラメータの最適化が難しく、過検出や未検出のリスクが伴う |
| 価格データに加え、ニュースやソーシャルメディアなど複数の情報源を統合し、精度の高い異常検知を実現 | モデルのブラックボックス性により、異常判定の理由を説明しにくい |
適用例
| 適用例 | 説明 |
|---|---|
| 金融市場の異常検知 | 株価や仮想通貨市場で、フラッシュクラッシュや注文の異常変動など、価格異常を検知する。 |
| 産業設備の故障予測 | センサーデータから、異常な振動や温度上昇を検出し、機械のメンテナンスに活用する。 |
| エネルギー消費の異常検知 | 電力消費のパターンから異常な変動を検出し、エネルギーロスの最適化や異常事態の早期対策に応用する。 |
時系列予測型 Transformerの実装例
- GPUメモリ削減のために、勾配チェックポイント、AMPによるFP16計算、Longformerの導入などを活用します。ただし、メモリ最適化の手法によってモデルの性能に影響が出るため、用途に応じた適切な選択が重要です。
- モデル
- エンコーダーには Longformer を用いており、長期依存関係のモデリングとメモリ効率の両立を狙っています。デコーダーは学習可能な開始トークンから未来を生成する役割を持ちます。
- 特徴
- このモデルは自己教師ありの枠組みで未来の1時刻を予測することにより、予測誤差を用いて異常検出およびトレード戦略のバックテストを行うユニークな実装となっています。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import torch.utils.checkpoint as checkpoint # 勾配チェックポイント用
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示用(必要に応じて)
from torch.cuda.amp import autocast, GradScaler
import math
from transformers import LongformerModel, LongformerConfig # Longformer の導入
# デバイスの設定(Mac M2の場合はMPS、利用不可ならCPU)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"Using device: {device}")
# 1. データ取得と前処理(未来予測用の入力・ターゲットを作成)
def prepare_data(seq_length=30):
ticker = 'ETH-USD'
# 未来のデータは存在しないため、まずは指定期間のデータが空ならフォールバック
data = yf.download(ticker, start='2025-01-01', end='2025-12-31', interval='1m')
if data.empty:
print("指定期間のデータが存在しません。直近5日間のデータを使用します。")
data = yf.download(ticker, period="5d", interval="1m")
# テクニカル指標の計算
data['SMA_10'] = data['Close'].rolling(window=10).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
data['BB_upper'] = data['Close'].rolling(window=20).mean() + 2 * data['Close'].rolling(window=20).std()
data['BB_lower'] = data['Close'].rolling(window=20).mean() - 2 * data['Close'].rolling(window=20).std()
def compute_rsi(series, window=14):
delta = series.diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI_14'] = compute_rsi(data['Close'], window=14)
data.dropna(inplace=True)
features = ['Open', 'High', 'Low', 'Close', 'Volume',
'SMA_10', 'SMA_50', 'BB_upper', 'BB_lower', 'RSI_14']
data = data[features]
if data.shape[0] < seq_length + 1:
raise ValueError("前処理後のデータが足りません。日付や期間の設定を確認してください。")
# 正規化(MinMaxScaler)
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 時系列予測用のサンプル作成:入力は連続する seq_length 時刻、ターゲットはその直後の1時刻分
X, Y = [], []
for i in range(len(data_scaled) - seq_length):
X.append(data_scaled[i:i+seq_length])
Y.append(data_scaled[i+seq_length])
X = np.array(X)
Y = np.array(Y)
X_tensor = torch.tensor(X, dtype=torch.float32)
Y_tensor = torch.tensor(Y, dtype=torch.float32)
dataset = TensorDataset(X_tensor, Y_tensor)
# 日付情報(ターゲットに対応する日付)
if len(data.index) >= seq_length + 1:
dates = data.index[seq_length:]
else:
dates = data.index
return dataset, scaler, seq_length, dates
# 2. 時系列予測型 Longformer+α モデル
class LongformerForecastTransformer(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, future_steps=1, dropout=0.1, attention_window=8):
"""
future_steps: 予測する未来の時刻数(ここでは1とする)
attention_window: Longformer の局所自己注意ウィンドウサイズ
"""
super(LongformerForecastTransformer, self).__init__()
self.seq_length = seq_length
self.future_steps = future_steps
# エンベッディングと位置エンベッディング
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_embedding = nn.Parameter(torch.zeros(seq_length, embed_dim))
# Longformer 用の設定:gradient_checkpointing 有効
config = LongformerConfig(
attention_window=[attention_window] * num_layers,
hidden_size=embed_dim,
num_hidden_layers=num_layers,
num_attention_heads=num_heads,
gradient_checkpointing=True,
pad_token_id=0
)
self.longformer_encoder = LongformerModel(config)
# デコーダー部分(従来の TransformerDecoder を採用)
# デコーダーの入力として、1ステップ分の開始トークン(学習可能)を用意
self.start_token = nn.Parameter(torch.zeros(1, embed_dim))
decoder_layer = nn.TransformerDecoderLayer(d_model=embed_dim, nhead=num_heads, dropout=dropout)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
self.fc_out = nn.Linear(embed_dim, input_dim)
def forward(self, x):
# x: [batch, seq_length, input_dim]
batch_size = x.size(0)
# エンコーダ部:エンベッディングと位置情報の加算
x_emb = self.embedding(x) + self.pos_embedding.unsqueeze(0) # [batch, seq_length, embed_dim]
# Longformer は inputs_embeds を受け付けるのでそのまま
longformer_out = self.longformer_encoder(inputs_embeds=x_emb).last_hidden_state # [batch, seq_length, embed_dim]
# デコーダで利用するため、転置:[seq_length, batch, embed_dim]
memory = longformer_out.transpose(0, 1)
# デコーダ部:予測用の入力として、start_token を future_steps 回複製
dec_input = self.start_token.unsqueeze(0).repeat(self.future_steps, batch_size, 1) # [future_steps, batch, embed_dim]
# 勾配チェックポイントを適用してデコーダを呼び出す
def decode_func(dec_input, memory):
return self.decoder(dec_input, memory)
dec_output = checkpoint.checkpoint(decode_func, dec_input, memory) # [future_steps, batch, embed_dim]
dec_output = dec_output.squeeze(0) # [batch, embed_dim]
pred = self.fc_out(dec_output) # [batch, input_dim]
return pred
# 3. 損失関数:予測値とターゲット値の MSE
def loss_function(pred, target):
return nn.MSELoss()(pred, target)
# 4. 学習ループ(自動混合精度 AMP による FP16計算)
def train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001):
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
input_dim = dataset.tensors[0].shape[2]
seq_length = dataset.tensors[0].shape[1]
# LongformerForecastTransformer のインスタンス生成
model = LongformerForecastTransformer(
input_dim=input_dim, embed_dim=32, num_heads=2, num_layers=2,
seq_length=seq_length, future_steps=1, dropout=0.1, attention_window=8
).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scaler = GradScaler()
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for batch_x, batch_y in dataloader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
optimizer.zero_grad()
with autocast():
pred = model(batch_x)
loss = loss_function(pred, batch_y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
return model
# 5. 異常検知評価:未来予測誤差に基づく評価および MSE/MAE の算出とプロット
def evaluate_anomaly(model, dataset, scaler, dates):
dataloader = DataLoader(dataset, batch_size=64, shuffle=False)
model.eval()
errors = []
predictions = []
targets = []
with torch.no_grad():
for batch_x, batch_y in dataloader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = ((pred - batch_y)**2).mean(dim=1) # 各サンプルごとに MSE(特徴毎平均)
errors.extend(loss.cpu().numpy())
predictions.append(pred.cpu().numpy())
targets.append(batch_y.cpu().numpy())
errors = np.array(errors)
predictions = np.concatenate(predictions, axis=0)
targets = np.concatenate(targets, axis=0)
# MSE, MAE の算出
mse = mean_squared_error(targets, predictions)
mae = mean_absolute_error(targets, predictions)
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"Mean Absolute Error (MAE): {mae:.4f}")
# 逆正規化(1時刻分のベクトル)
targets_inv = scaler.inverse_transform(targets)
predictions_inv = scaler.inverse_transform(predictions)
plt.figure(figsize=(14, 7))
# 例として、Close 価格は index=3
plt.plot(targets_inv[:, 3], label='Original Close')
plt.plot(predictions_inv[:, 3], label='Predicted Close')
plt.title('Original vs Predicted Close Prices')
plt.xlabel('Sample Index')
plt.ylabel('Close Price')
plt.legend()
plt.show()
# 異常検知:誤差が95パーセンタイルを超える場合を異常とする
threshold = np.percentile(errors, 95)
anomalies = errors > threshold
print(f"Threshold for anomaly detection: {threshold:.4f}")
print(f"Number of anomalies detected: {np.sum(anomalies)} / {len(errors)}")
plt.figure(figsize=(14, 7))
plt.plot(dates[:len(errors)], errors[:len(dates)], label="Prediction Error (MSE)")
plt.axhline(threshold, color="red", linestyle="--", label="Threshold")
plt.title("Prediction Error and Anomaly Detection")
plt.xlabel("Date")
plt.ylabel("Prediction MSE")
plt.legend()
plt.show()
return errors, threshold, anomalies, targets_inv, predictions_inv
# 6. トレードシグナル生成:誤差が閾値超なら売りシグナル (-1)、それ以外は買いシグナル (1)
def generate_trade_signals(errors, threshold):
signals = np.where(errors > threshold, -1, 1)
return signals
# 7. バックテスト戦略:シンプルなルール(シグナルに基づくポジション変化)
def backtest_strategy(prices, signals, initial_capital=10000):
positions = np.where(signals == 1, 1, -1)
cash_flow = np.diff(positions) * prices[1:]
cash_flow = np.insert(cash_flow, 0, 0)
cumulative_cash_flow = np.cumsum(cash_flow)
portfolio_value = initial_capital + cumulative_cash_flow
return portfolio_value
def calculate_performance_metrics(portfolio_value):
cumulative_return = (portfolio_value[-1] / portfolio_value[0]) - 1
daily_returns = np.diff(portfolio_value) / portfolio_value[:-1]
sharpe_ratio = np.mean(daily_returns) / np.std(daily_returns) * np.sqrt(252) if np.std(daily_returns) != 0 else 0
running_max = np.maximum.accumulate(portfolio_value)
drawdown = portfolio_value - running_max
max_drawdown = np.min(drawdown)
return cumulative_return, sharpe_ratio, max_drawdown
# 8. メイン処理
def main():
dataset, scaler, seq_length, dates = prepare_data(seq_length=30)
model = train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001)
errors, threshold, anomalies, targets_inv, predictions_inv = evaluate_anomaly(model, dataset, scaler, dates)
signals = generate_trade_signals(errors, threshold)
# バックテスト用:ターゲットのClose価格(index=3)を利用
prices = targets_inv[:, 3]
portfolio_value = backtest_strategy(prices, signals)
cumulative_return, sharpe_ratio, max_drawdown = calculate_performance_metrics(portfolio_value)
print(f"Cumulative Return: {cumulative_return:.2%}")
print(f"Sharpe Ratio: {sharpe_ratio:.2f}")
print(f"Max Drawdown: {max_drawdown:.2f}")
plt.figure(figsize=(14, 7))
plt.plot(portfolio_value, label='Portfolio Value')
plt.title('Backtest Result')
plt.xlabel('Time Steps')
plt.ylabel('Portfolio Value')
plt.legend()
plt.show()
print("処理が完了しました")
if __name__ == "__main__":
main()Epoch [29/30], Loss: 0.0032
Epoch [30/30], Loss: 0.0030
Mean Squared Error (MSE): 0.0020
Mean Absolute Error (MAE): 0.0341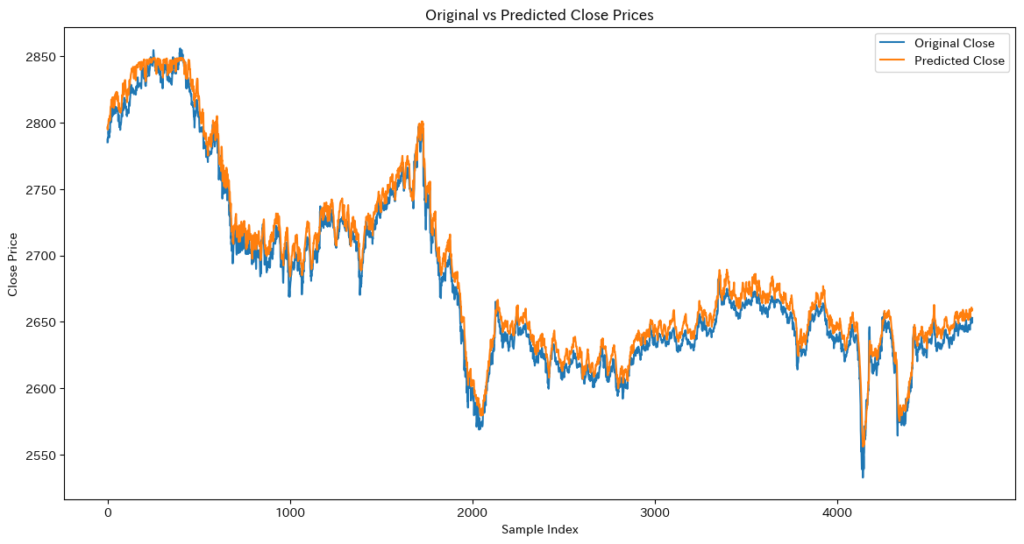
Threshold for anomaly detection: 0.0053
Number of anomalies detected: 237 / 4739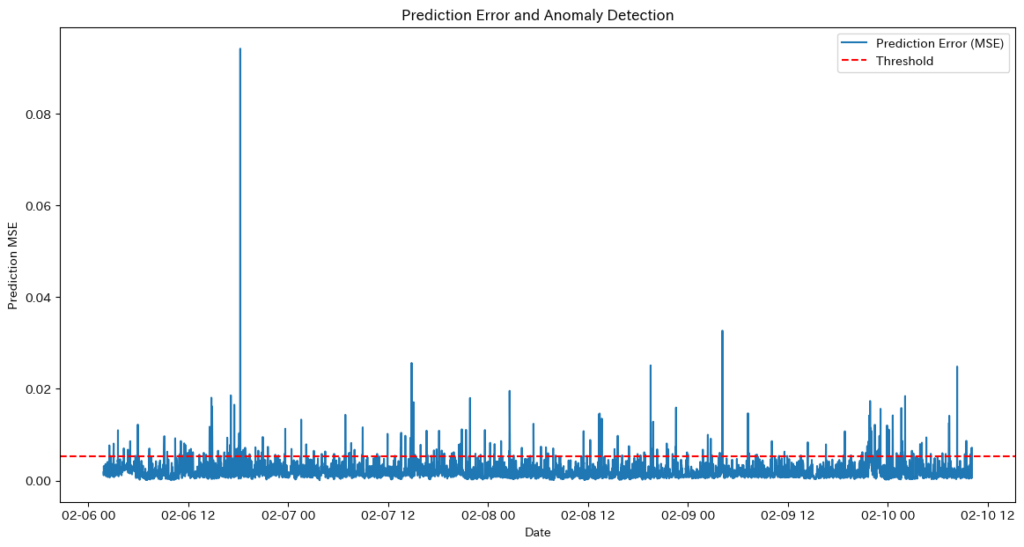
Cumulative Return: -53.82%
Sharpe Ratio: 1.66
Max Drawdown: -5696.69
自己教師あり学習の部分
# 入力は連続する seq_length 時刻、ターゲットはその直後の1時刻分
X, Y = [], []
for i in range(len(data_scaled) - seq_length):
X.append(data_scaled[i:i+seq_length])
Y.append(data_scaled[i+seq_length])prepare_data 関数内で上記のように入力とターゲット(未来の1時刻)が自動で作られており、これによりラベル付きデータを別途用意する必要がない自己教師あり学習の手法が実現されています。
未来予測を行うモデル部分
# デコーダ部:予測用の入力として、start_token を future_steps 回複製
dec_input = self.start_token.unsqueeze(0).repeat(self.future_steps, batch_size, 1)
...
dec_output = checkpoint.checkpoint(decode_func, dec_input, memory) # 予測結果が得られる
dec_output = dec_output.squeeze(0) # future_steps=1 なので squeeze
pred = self.fc_out(dec_output) # 最終的な予測値にマッピングこの部分からもわかるように、デコーダーは学習可能な開始トークンに基づいて未来の1時刻を予測します。つまり、与えられた入力シーケンスからエンコーダーで情報を集約し、デコーダーで未来の情報を生成する仕組みになっています。
AutoencoderTransformerモデル との違い
| 項目 | AutoencoderTransformer | 今回の未来予測モデル |
|---|---|---|
| 入力シーケンスの扱い | 入力シーケンスをそのまま潜在空間にエンコードし、デコーダーで再構成を行う。 | 入力シーケンスから未来の1時刻を予測するように設計されている。 |
| ターゲット | ターゲットは入力そのものであり、自己再構成により再構成誤差(MSE等)を算出する。 | ターゲットは「次の時刻のデータ」として設定され、予測と実際の未来データとの差分を誤差として計算する。 |
| 異常検知のアプローチ | 再構成誤差が大きい場合に異常と判断(正常パターンは再構成誤差が小さい)。 | 予測誤差により、将来データとのズレが大きい場合に異常を検知する。 |
AutoencoderTransformer は「入力=ターゲット」として再構成誤差を利用するのに対し、今回のモデルでは「入力」は過去情報、ターゲットは未来の1時刻となっており、予測性能そのものが異常検知の鍵となります。
ハイブリッド型:LSTM + Transformerの場合(異常検知&予測)
ハイブリッドモデルでは、LSTMが短期的な変動を捉え、Transformerが長期的なトレンドを学習することで、異常検知の精度を向上させます。特に 時系列予測型 Transformer は、未来の値を予測し、その誤差から異常を検出できるため、取引判断やリスク管理に直結しやすく、Autoencoder型より実用性が高いです。
目的
- 短期変動の把握
- LSTMは逐次処理によって直近の価格変動や短期的なノイズを捉えるのに優れています。一方で、長期的な依存関係の学習は難しく、過去の情報を保持しにくい特性があります。そのため、LSTMは特に短期的な変動パターンの分析に適しています。
- 長期依存性の学習
- 一方、Transformerは自己注意機構を活用し、時系列データ全体の長期的な依存関係やトレンドを効率的に捉えることができます。
仕組み
- LSTMは短期的な変動やノイズを捉え、Transformerは長期的なトレンドや全体の文脈を学習します。これにより、正常な市場パターンをモデル化し、大きく逸脱するデータ(予測誤差や再構成誤差が高いもの)を異常として検出できます。
課題
- ハイブリッドモデルは計算量やパラメータが増えるため、GPUメモリを効率的に使う工夫が必ず必要になります。
ハイブリッド型:LSTM + Transformerの場合(異常検知&予測)の実装例
- GPUメモリ削減のために、勾配チェックポイント、AMPによるFP16計算、Longformerの導入などを活用します。ただし、メモリ最適化の手法によってモデルの性能に影響が出るため、用途に応じた適切な選択が重要です。
- モデル
- エンコーダーに Longformer を採用し、長期依存関係を効率的に学習しつつ、LSTM で短期的な変動を補完。デコーダーは学習可能な開始トークンを用いて未来のデータを生成します。
- デコーダー部では、Transformer Decoder を用いて学習済みトークンから未来の時刻の予測を生成し、最終的に出力層で元の入力次元に戻す。
- 特徴
- このモデルは自己教師ありの枠組みで未来の1時刻を予測することにより、予測誤差を用いて異常検出およびトレード戦略のバックテストを行うユニークな実装となっています。
- 過学習の予防
- ウォークフォワード検証を活用することで、時系列の連続性を保ちつつモデルを逐次更新し、市場環境への適応力や実運用でのパフォーマンスを評価できます。特にハイブリッドモデルでは効果が高いため、導入を推奨します。
- ウォークフォワード検証については下記を参考にしてください。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset, Subset
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示用
from torch.cuda.amp import autocast, GradScaler
import math
from transformers import LongformerModel, LongformerConfig
# デバイスの設定(Mac M2の場合はMPS、利用不可ならCPU)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"Using device: {device}")
# 1. データ取得と前処理
def prepare_data(seq_length=30):
ticker = 'ETH-USD'
# 未来のデータは存在しないため、指定期間が空の場合は直近5日間を使用
data = yf.download(ticker, start='2025-01-01', end='2025-12-31', interval='1m')
if data.empty:
print("指定期間のデータが存在しません。直近5日間のデータを使用します。")
data = yf.download(ticker, period="5d", interval="1m")
# テクニカル指標の計算
data['SMA_10'] = data['Close'].rolling(window=10).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
data['BB_upper'] = data['Close'].rolling(window=20).mean() + 2 * data['Close'].rolling(window=20).std()
data['BB_lower'] = data['Close'].rolling(window=20).mean() - 2 * data['Close'].rolling(window=20).std()
def compute_rsi(series, window=14):
delta = series.diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI_14'] = compute_rsi(data['Close'], window=14)
data.dropna(inplace=True)
features = ['Open', 'High', 'Low', 'Close', 'Volume',
'SMA_10', 'SMA_50', 'BB_upper', 'BB_lower', 'RSI_14']
data = data[features]
if data.shape[0] < seq_length + 1:
raise ValueError("前処理後のデータが足りません。日付や期間の設定を確認してください。")
# 正規化(MinMaxScaler)
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 時系列予測用のサンプル作成:入力は連続する seq_length 時刻、ターゲットはその直後の1時刻分
X, Y = [], []
for i in range(len(data_scaled) - seq_length):
X.append(data_scaled[i:i+seq_length])
Y.append(data_scaled[i+seq_length])
X = np.array(X)
Y = np.array(Y)
X_tensor = torch.tensor(X, dtype=torch.float32)
Y_tensor = torch.tensor(Y, dtype=torch.float32)
dataset = TensorDataset(X_tensor, Y_tensor)
# 日付情報(ターゲットに対応する日付)
if len(data.index) >= seq_length + 1:
dates = data.index[seq_length:]
else:
dates = data.index
return dataset, scaler, seq_length, dates
# 2. ハイブリッド型(LSTM + Longformer)モデル
class HybridForecastTransformer(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, seq_length, lstm_hidden_dim, dropout=0.1, future_steps=1):
"""
future_steps: 予測する未来の時刻数(ここでは1)
"""
super(HybridForecastTransformer, self).__init__()
self.seq_length = seq_length
self.future_steps = future_steps
# エンコーダー部: Longformer 用の埋め込みとポジショナルエンコーディング
self.embedding = nn.Linear(input_dim, embed_dim)
self.pos_embedding = nn.Parameter(torch.zeros(seq_length, embed_dim))
# Longformer 用の設定
config = LongformerConfig(
attention_window=[8] * num_layers,
hidden_size=embed_dim,
num_hidden_layers=num_layers,
num_attention_heads=num_heads,
gradient_checkpointing=True,
pad_token_id=0
)
self.longformer_encoder = LongformerModel(config)
# LSTM 部分: 短期的な依存性の補完
self.lstm = nn.LSTM(embed_dim, lstm_hidden_dim, batch_first=True)
# デコーダー部: Transformer Decoder
self.start_token = nn.Parameter(torch.zeros(1, lstm_hidden_dim))
decoder_layer = nn.TransformerDecoderLayer(d_model=lstm_hidden_dim, nhead=num_heads, dropout=dropout)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers)
self.fc_out = nn.Linear(lstm_hidden_dim, input_dim)
def forward(self, x):
# x: [batch, seq_length, input_dim]
batch_size = x.size(0)
# エンコーダー:Embedding + Positional Encoding
x_emb = self.embedding(x) + self.pos_embedding.unsqueeze(0) # [batch, seq_length, embed_dim]
# 勾配チェックポイントを利用してLongformer Encoderを実行
def encoder_forward(x_emb):
# Longformer は inputs_embeds を受け付け、[batch, seq_length, embed_dim] の出力を返す
encoded = self.longformer_encoder(inputs_embeds=x_emb).last_hidden_state
return encoded
x_encoded = torch.utils.checkpoint.checkpoint(encoder_forward, x_emb)
# LSTM による追加処理
lstm_out, (h_n, _) = self.lstm(x_encoded) # lstm_out: [batch, seq_length, lstm_hidden_dim]
# デコーダー:学習可能な開始トークンを future_steps 回複製
dec_input = self.start_token.unsqueeze(0).repeat(self.future_steps, batch_size, 1) # [future_steps, batch, lstm_hidden_dim]
memory = lstm_out.transpose(0, 1) # [seq_length, batch, lstm_hidden_dim]
def decoder_forward(dec_input, memory):
return self.transformer_decoder(dec_input, memory)
dec_output = torch.utils.checkpoint.checkpoint(decoder_forward, dec_input, memory) # [future_steps, batch, lstm_hidden_dim]
dec_output = dec_output.squeeze(0) # [batch, lstm_hidden_dim] (future_steps=1)
pred = self.fc_out(dec_output) # [batch, input_dim]
return pred
# 3. 損失関数:予測値と実際の未来値のMSE
def loss_function(pred, target):
return nn.MSELoss()(pred, target)
# 4. 学習ループ(AMPと勾配チェックポイントを利用したFP16計算)
def train_model(dataset, num_epochs=30, batch_size=64, learning_rate=0.001):
# Subset の場合は内部の dataset を参照
base_dataset = dataset.dataset if isinstance(dataset, torch.utils.data.Subset) else dataset
input_dim = base_dataset.tensors[0].shape[2]
seq_length = base_dataset.tensors[0].shape[1]
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = HybridForecastTransformer(input_dim, embed_dim=32, num_heads=2, num_layers=2,
seq_length=seq_length, lstm_hidden_dim=64,
dropout=0.1, future_steps=1).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scaler = GradScaler()
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for batch_x, batch_y in dataloader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
optimizer.zero_grad()
with autocast():
pred = model(batch_x)
loss = loss_function(pred, batch_y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
return model
# 5. 異常検知の評価
def evaluate_anomaly(model, dataset, scaler, dates):
dataloader = DataLoader(dataset, batch_size=64, shuffle=False)
model.eval()
errors = []
predictions = []
targets = []
with torch.no_grad():
for batch_x, batch_y in dataloader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = ((pred - batch_y)**2).mean(dim=1) # サンプル毎のMSEを算出
errors.extend(loss.cpu().numpy())
predictions.append(pred.cpu().numpy())
targets.append(batch_y.cpu().numpy())
errors = np.array(errors)
predictions = np.concatenate(predictions, axis=0)
targets = np.concatenate(targets, axis=0)
mse = mean_squared_error(targets, predictions)
mae = mean_absolute_error(targets, predictions)
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"Mean Absolute Error (MAE): {mae:.4f}")
targets_inv = scaler.inverse_transform(targets)
predictions_inv = scaler.inverse_transform(predictions)
plt.figure(figsize=(14, 7))
plt.plot(targets_inv[:, 3], label='Original Close')
plt.plot(predictions_inv[:, 3], label='Predicted Close')
plt.title('Original vs Predicted Close Prices')
plt.xlabel('Sample Index')
plt.ylabel('Close Price')
plt.legend()
plt.show()
threshold = np.percentile(errors, 95)
anomalies = errors > threshold
print(f"Threshold for anomaly detection: {threshold:.4f}")
print(f"Number of anomalies detected: {np.sum(anomalies)} / {len(errors)}")
plt.figure(figsize=(14, 7))
plt.plot(dates[:len(errors)], errors[:len(dates)], label="Prediction Error (MSE)")
plt.axhline(threshold, color="red", linestyle="--", label="Threshold")
plt.title("Prediction Error and Anomaly Detection")
plt.xlabel("Date")
plt.ylabel("Prediction MSE")
plt.legend()
plt.show()
# 戻り値にエラー、閾値、逆正規化後のターゲット、予測値も返す
return mse, mae, errors, threshold, targets_inv, predictions_inv
# 6. トレードシグナル生成・バックテスト関連関数
def generate_trade_signals(errors, threshold):
signals = np.where(errors > threshold, -1, 1)
return signals
def backtest_strategy(prices, signals, initial_capital=10000):
positions = np.where(signals == 1, 1, -1)
cash_flow = np.diff(positions) * prices[1:]
cash_flow = np.insert(cash_flow, 0, 0)
cumulative_cash_flow = np.cumsum(cash_flow)
portfolio_value = initial_capital + cumulative_cash_flow
return portfolio_value
def calculate_performance_metrics(portfolio_value):
cumulative_return = (portfolio_value[-1] / portfolio_value[0]) - 1
daily_returns = np.diff(portfolio_value) / portfolio_value[:-1]
sharpe_ratio = np.mean(daily_returns) / np.std(daily_returns) * np.sqrt(252) if np.std(daily_returns) != 0 else 0
running_max = np.maximum.accumulate(portfolio_value)
drawdown = portfolio_value - running_max
max_drawdown = np.min(drawdown)
return cumulative_return, sharpe_ratio, max_drawdown
# 7. ウォークフォワード検証の実装
def walk_forward_validation(dataset, scaler, dates, initial_train_ratio=0.6, n_folds=5):
total_samples = len(dataset)
initial_train_size = int(total_samples * initial_train_ratio)
test_window = int((total_samples - initial_train_size) / n_folds)
mse_list = []
mae_list = []
print(f"Total samples: {total_samples}, initial training samples: {initial_train_size}, test window: {test_window}")
for fold in range(n_folds):
train_end = initial_train_size + fold * test_window
test_end = train_end + test_window
if test_end > total_samples:
test_end = total_samples
train_subset = Subset(dataset, list(range(0, train_end)))
test_subset = Subset(dataset, list(range(train_end, test_end)))
print(f"Fold {fold+1}: Train samples = {len(train_subset)}, Test samples = {len(test_subset)}")
model = train_model(train_subset, num_epochs=20, batch_size=64, learning_rate=0.001)
mse, mae, _, _, _, _ = evaluate_anomaly(model, test_subset, scaler, dates)
mse_list.append(mse)
mae_list.append(mae)
avg_mse = np.mean(mse_list)
avg_mae = np.mean(mae_list)
print(f"Walk Forward Validation: Average MSE = {avg_mse:.4f}, Average MAE = {avg_mae:.4f}")
return avg_mse, avg_mae
# 8. メイン処理(ウォークフォワード検証とバックテストの実施)
def main():
dataset, scaler, seq_length, dates = prepare_data(seq_length=30)
# ウォークフォワード検証
avg_mse, avg_mae = walk_forward_validation(dataset, scaler, dates, initial_train_ratio=0.6, n_folds=5)
print("ウォークフォワード検証が完了しました")
# 全データを用いて再学習し、バックテストのシミュレーションを実施
print("全データで再学習しバックテストを実施します")
model_full = train_model(dataset, num_epochs=20, batch_size=64, learning_rate=0.001)
mse, mae, errors, threshold, targets_inv, predictions_inv = evaluate_anomaly(model_full, dataset, scaler, dates)
# 予測誤差からトレードシグナル生成(エラーが閾値超の場合は売り(-1)、それ以外は買い(1))
signals = generate_trade_signals(errors, threshold)
# バックテスト用に逆正規化後のClose価格(例:index=3)を使用
prices = targets_inv[:, 3]
portfolio_value = backtest_strategy(prices, signals, initial_capital=10000)
cumul_return, sharpe_ratio, max_drawdown = calculate_performance_metrics(portfolio_value)
# バックテスト結果のプロットと評価指標の表示
plt.figure(figsize=(14, 7))
plt.plot(portfolio_value, label='Portfolio Value')
plt.title('Backtest Result')
plt.xlabel('Time Steps')
plt.ylabel('Portfolio Value')
plt.legend()
# 評価指標をテキストで表示(グラフ上部にプロット)
text_str = (f"Cumulative Return: {cumul_return*100:.2f}%\n"
f"Sharpe Ratio: {sharpe_ratio:.2f}\n"
f"Max Drawdown: {max_drawdown:.2f}")
plt.text(0.02, 0.95, text_str, transform=plt.gca().transAxes, verticalalignment='top',
bbox=dict(facecolor='white', alpha=0.8))
plt.show()
if __name__ == "__main__":
main()Total samples: 4823, initial training samples: 2893, test window: 386
Fold 1: Train samples = 2893, Test samples = 386
Epoch [19/20], Loss: 0.0066
Epoch [20/20], Loss: 0.0066
Mean Squared Error (MSE): 0.0017
Mean Absolute Error (MAE): 0.0272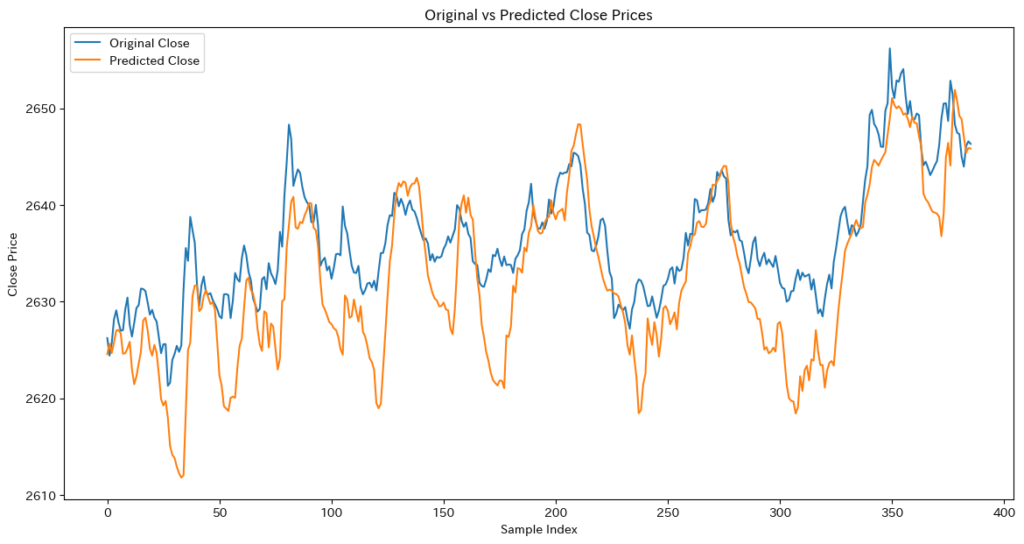
Threshold for anomaly detection: 0.0043
Number of anomalies detected: 20 / 386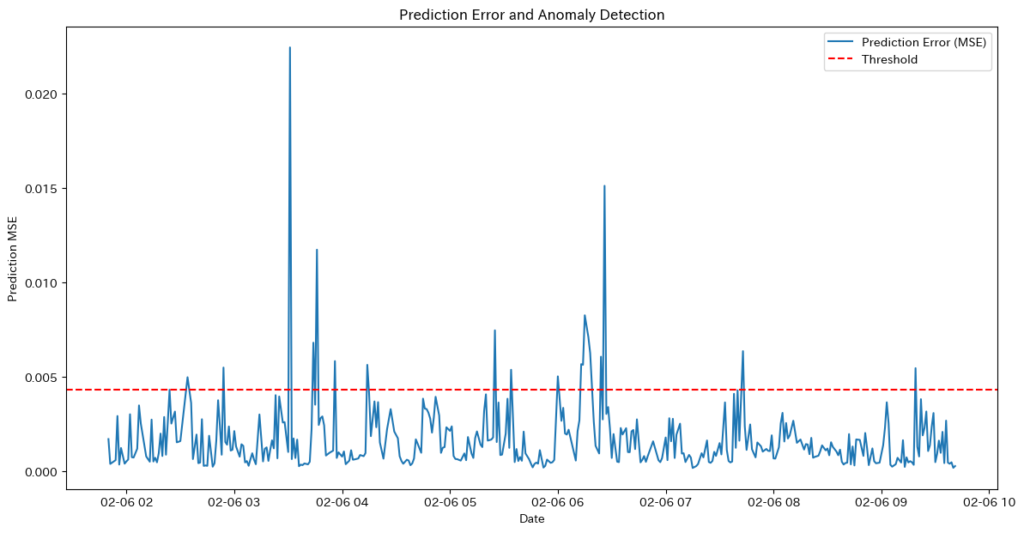
Fold 2: Train samples = 3279, Test samples = 386
Epoch [19/20], Loss: 0.0059
Epoch [20/20], Loss: 0.0056
Mean Squared Error (MSE): 0.0016
Mean Absolute Error (MAE): 0.0237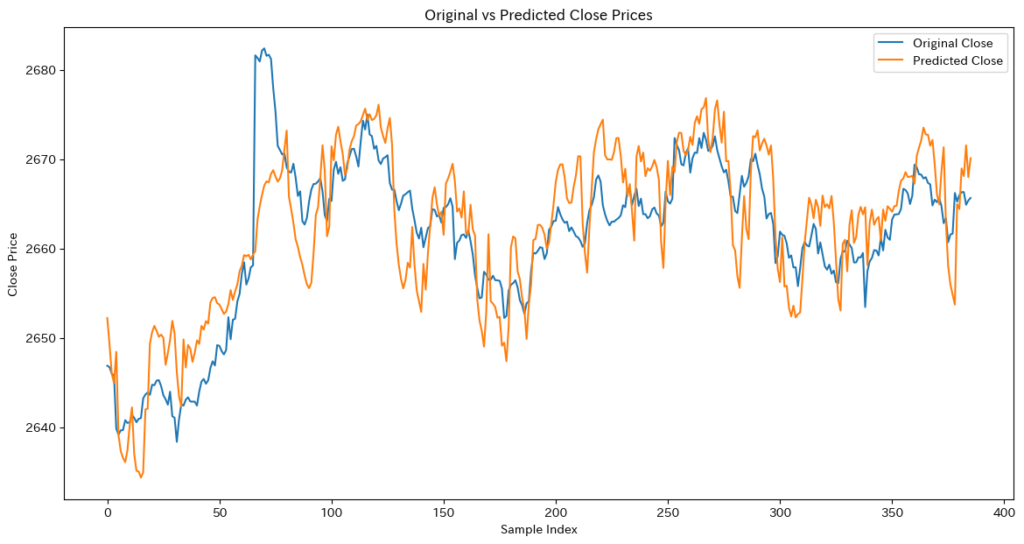
Threshold for anomaly detection: 0.0049
Number of anomalies detected: 20 / 386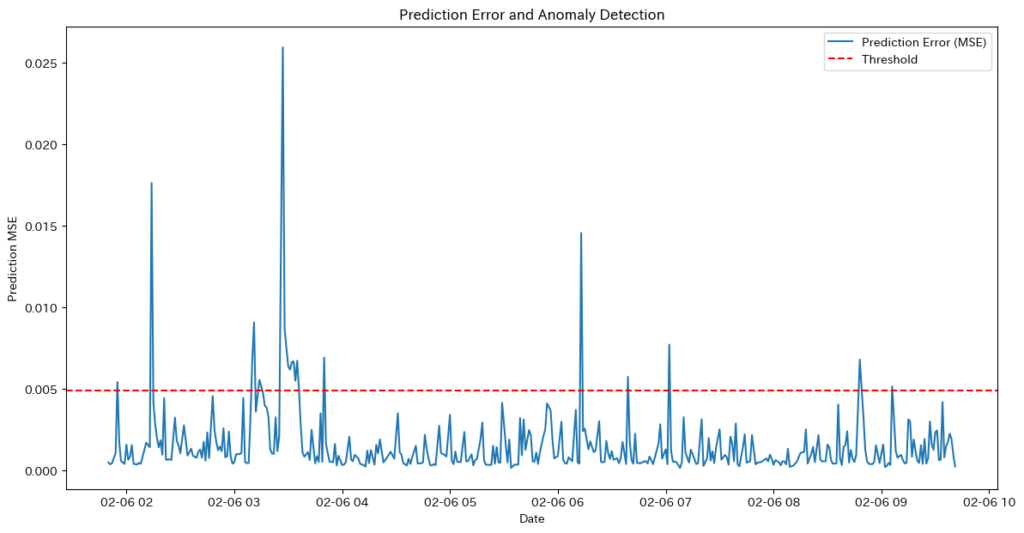
Fold 3: Train samples = 3665, Test samples = 386
Epoch [19/20], Loss: 0.0055
Epoch [20/20], Loss: 0.0053
Mean Squared Error (MSE): 0.0012
Mean Absolute Error (MAE): 0.0205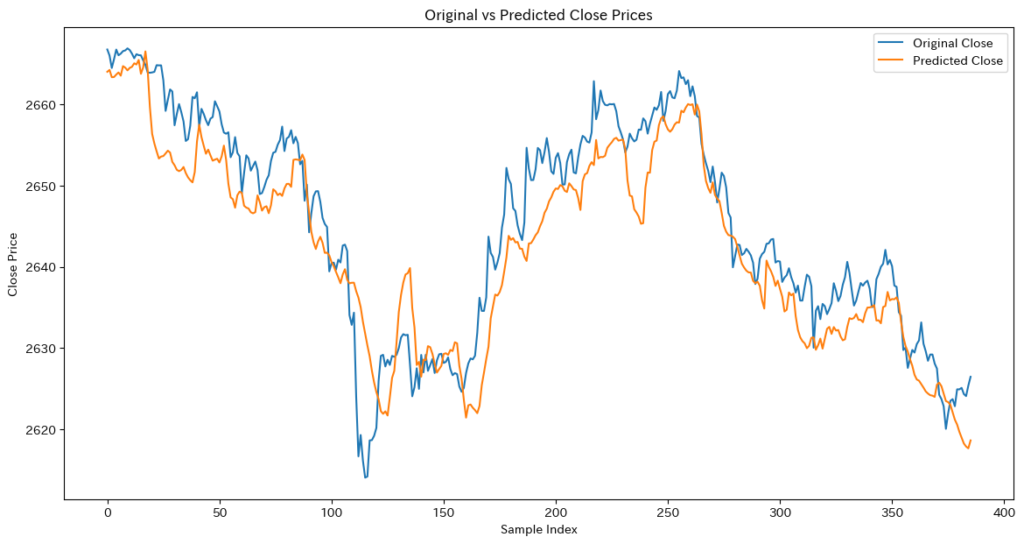
Threshold for anomaly detection: 0.0039
Number of anomalies detected: 20 / 386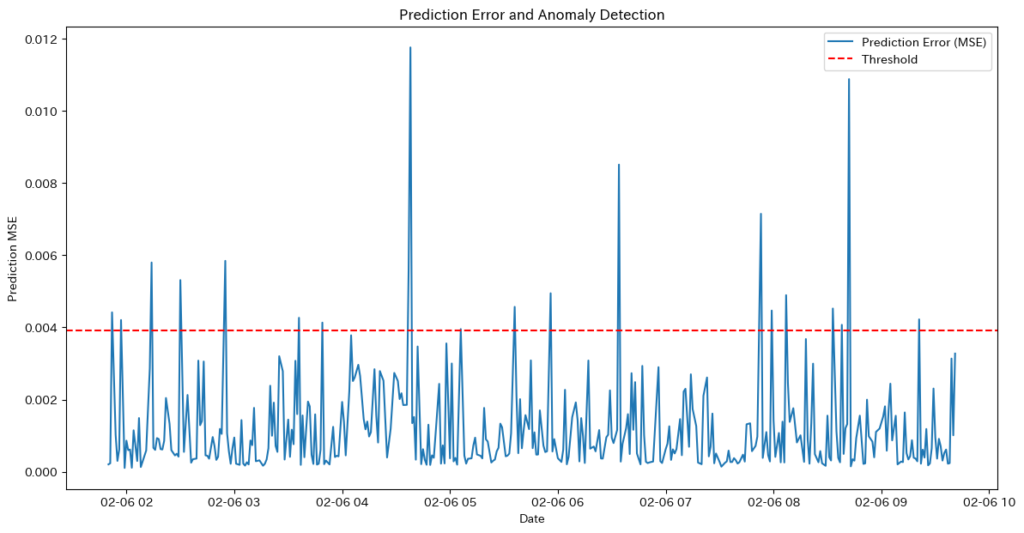
Fold 4: Train samples = 4051, Test samples = 386
Epoch [19/20], Loss: 0.0065
Epoch [20/20], Loss: 0.0067
Mean Squared Error (MSE): 0.0049
Mean Absolute Error (MAE): 0.0432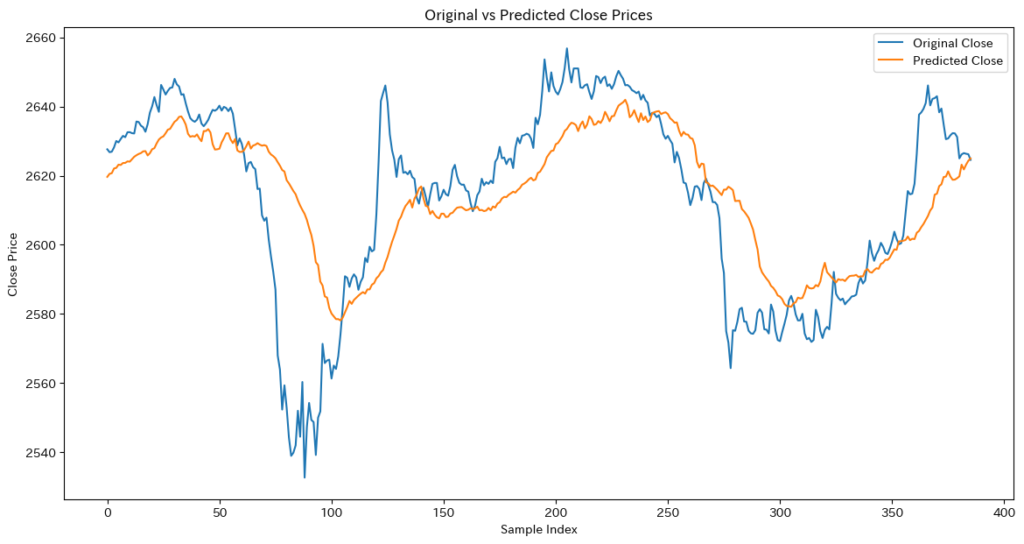
Threshold for anomaly detection: 0.0205
Number of anomalies detected: 20 / 386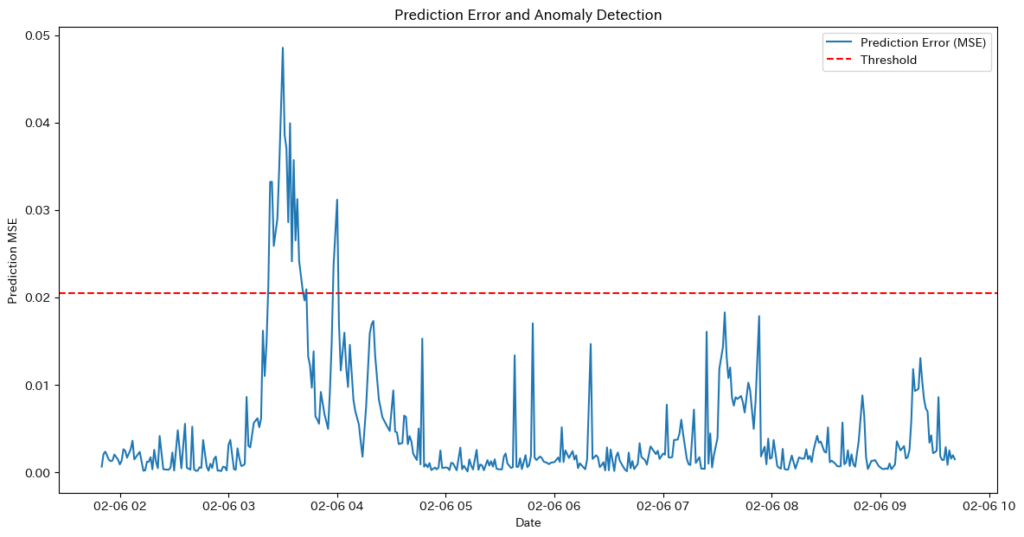
Fold 5: Train samples = 4437, Test samples = 386
Epoch [19/20], Loss: 0.0051
Epoch [20/20], Loss: 0.0046
Mean Squared Error (MSE): 0.0019
Mean Absolute Error (MAE): 0.0295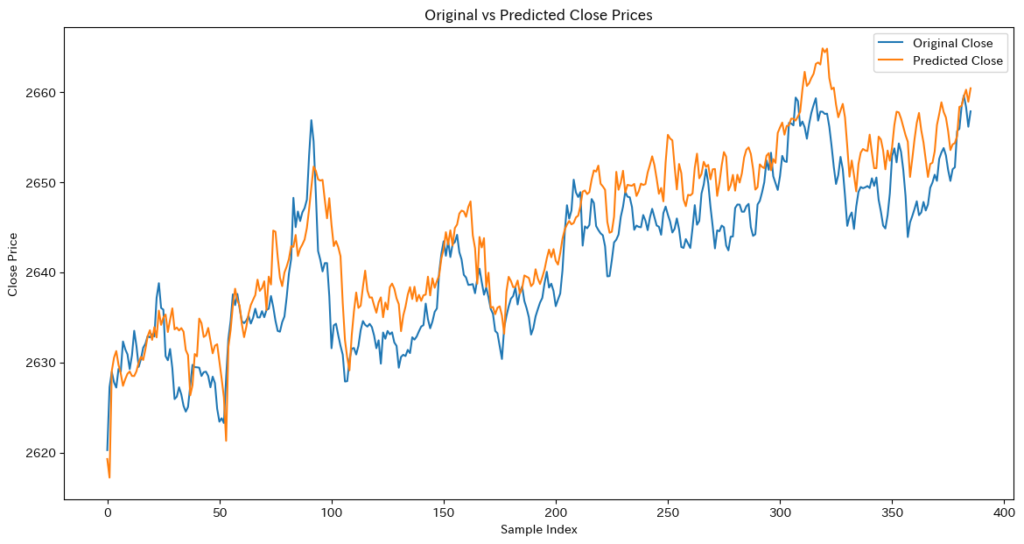
Threshold for anomaly detection: 0.0052
Number of anomalies detected: 20 / 386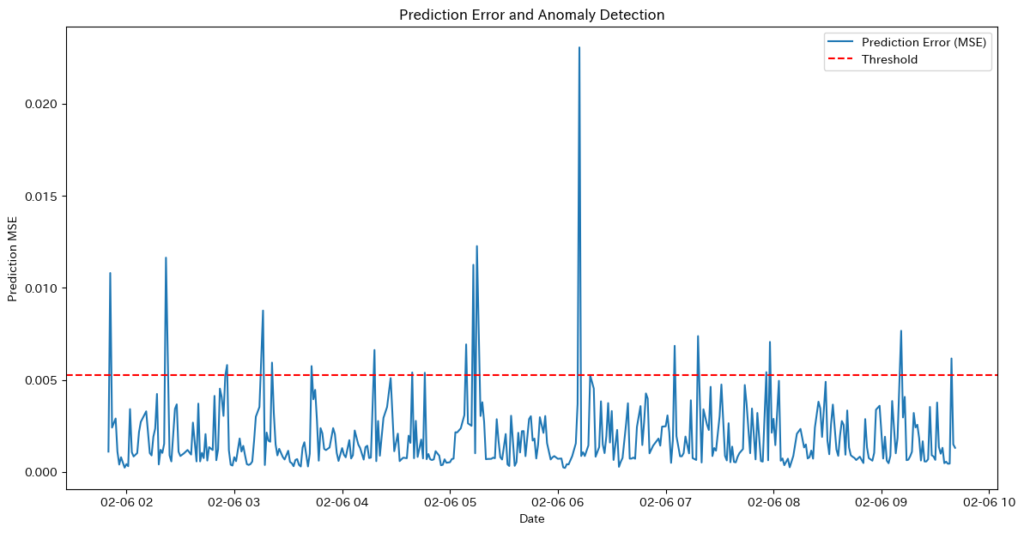
Walk Forward Validation: Average MSE = 0.0023, Average MAE = 0.0288
Epoch [19/20], Loss: 0.0083
Epoch [20/20], Loss: 0.0060
Mean Squared Error (MSE): 0.0023
Mean Absolute Error (MAE): 0.0317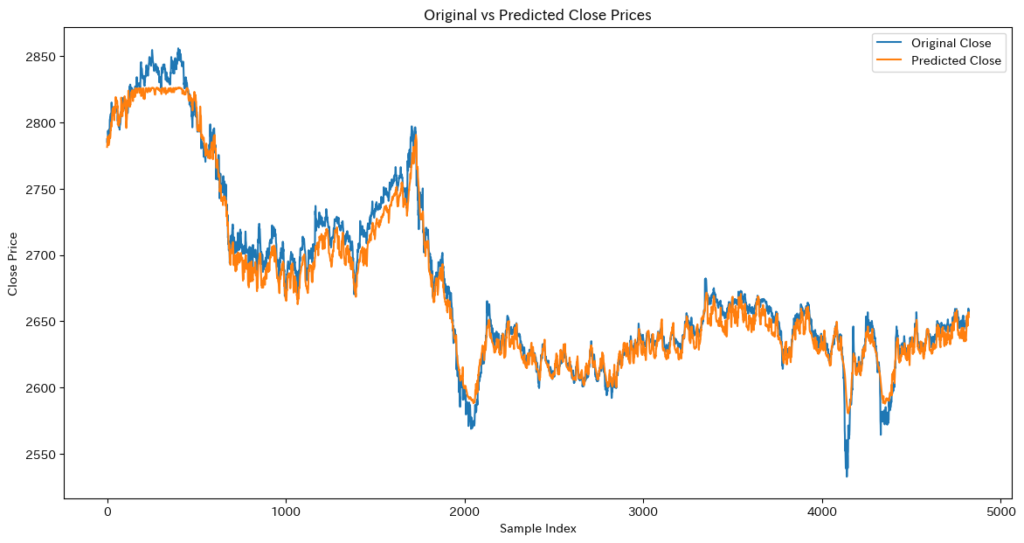
Threshold for anomaly detection: 0.0069
Number of anomalies detected: 242 / 4823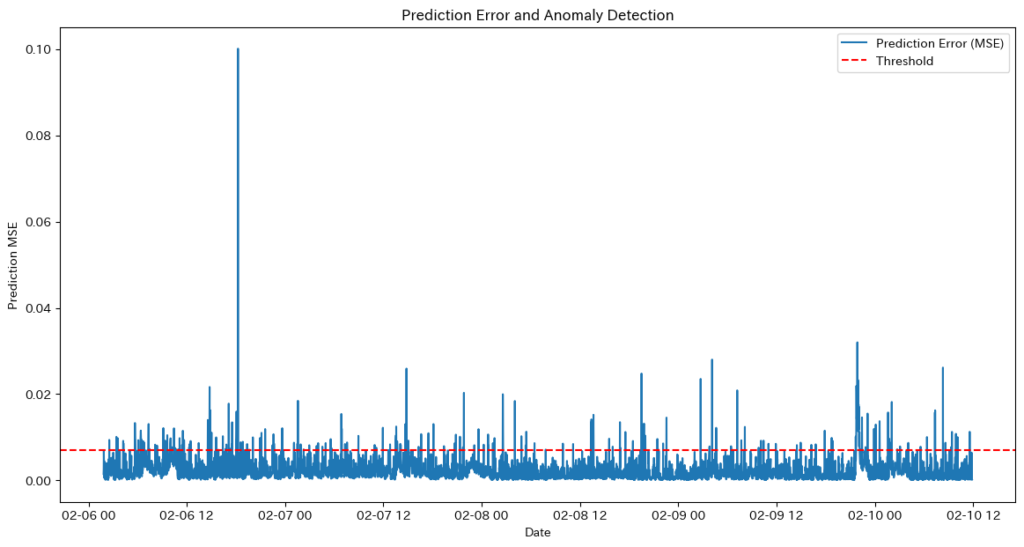
ウォークフォワード検証の意味合い
- 時系列の連続性を保つ検証
- ウォークフォワード検証は、時系列データの未来情報漏れを防ぎ、初期データで学習 → 次の期間を予測 → 新情報で再学習を繰り返す逐次更新の手法です。
- モデルの適応性と安定性の評価
- ウォークフォワード検証により、モデルが市場環境の変化に適応し、逐次更新による予測精度の向上やトレンドへの対応力を評価できます。
- 実運用に近い評価
- ウォークフォワード検証は、最新データでモデルを更新し、実運用に近い投資戦略やリスク管理の評価を可能にします。
ハイブリッドモデル(LSTM + Transformer)は、局所パターンと全体トレンドの両方を考慮できるため、市場変動への適応性が高まります。ただし、データの特性やタスク次第では、単体のTransformerでも十分な精度が得られるため、適用シナリオに応じた評価が必要です。
音声認識分野におけるTransformerの役割
音声認識の歴史と初期技術:HMM と GMM
音声認識技術は、1950年代から研究が進められ、現在のディープラーニングを活用した音声認識モデルへと発展しました。その初期の主要な技術として 隠れマルコフモデル(HMM) と ガウシアン混合モデル(GMM) があり、これらが長年にわたり音声認識の基盤技術として用いられてきました。
音声認識のルーツと発展の経緯
- 音声認識技術の歴史を振り返ると、以下のような重要な進展がありました。
HMM(隠れマルコフモデル)と GMM(ガウシアン混合モデル)
HMM(隠れマルコフモデル)とは?
HMMは、確率的な状態遷移を持つ時系列データをモデル化するための手法です。音声認識において、HMMは 音素(phoneme)や単語の連続的な変化 を捉えるために用いられます。
数式
- HMMは以下の5つの要素で定義されます
- 状態空間 :$\mathcal{S} = { s_1, s_2, \dots, s_N }$
- 音声の背後にある隠れた状態(例: 各音素)。
- 観測系列 :$\mathcal{O} = { o_1, o_2, \dots, o_T }$
- 実際の音響特徴(MFCCなど)。
- 初期確率分布:$\pi = P(s_i)$
- 各状態が最初に現れる確率。
- 状態遷移確率:$A = P(s_j \mid s_i)$
- ある状態から別の状態に遷移する確率。
- 観測確率:$B = P(o_t \mid s_i)$
- 状態$s_i$における観測$o_t$の確率。
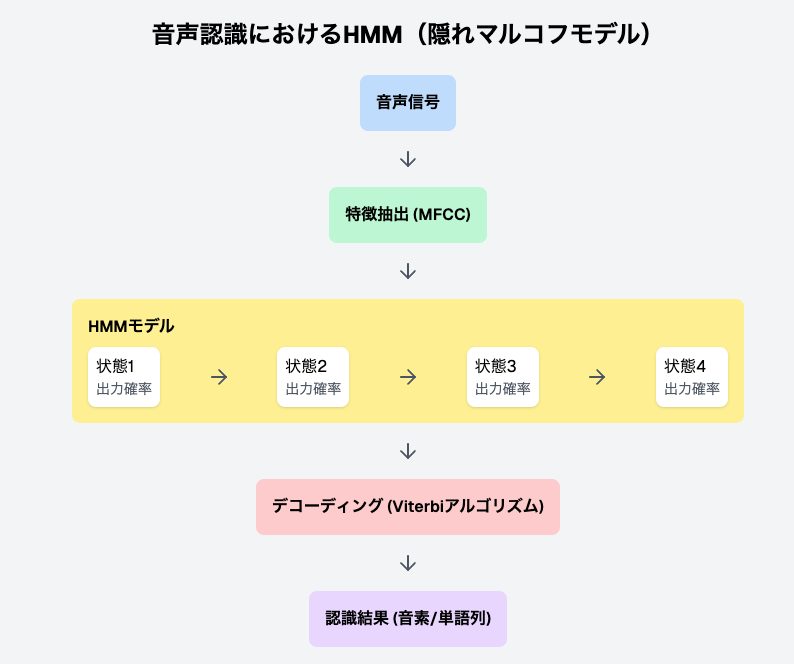
HMMの主要な数式:すべての可能な状態系列 に対する尤度の総和を求める式
$$P(O \mid \lambda) = \sum_{\text{all } S} P(O \mid S, \lambda) P(S \mid \lambda)$$
- HMMの限界
- 音声信号の 非線形性 を完全には捉えられない。
- 状態遷移がマルコフ過程に従うため、長期的な依存関係を学習しにくい。
GMM(ガウシアン混合モデル)とは?
GMMは、複数のガウス分布の線形結合で確率密度を近似する手法 です。HMMと組み合わせることで、音響特徴の分布をより適切にモデリングすることが可能になります。
数式
$$P(x) = \sum_{i=1}^{K} w_i \cdot \mathcal{N}(x \mid \mu_i, \Sigma_i)$$
- $K$は混合成分の数(通常、数十〜数百)。
- $w_1$は各ガウス成分の重み($Σw_1=1$)。
- $\mathcal{N}(x \mid \mu_i, \Sigma_i)$は平均$\mu_i$と共分散$ \Sigma_i$を持つガウス分布。
- GMMの限界
- 高次元データのモデリングに向いていない。
- データが増えると、計算量が急増しスケーラビリティが悪い。
- DNN(ディープニューラルネットワーク)が登場したことで、より表現力のあるモデルが利用可能になった。
HMM-GMMからニューラルネットワークへの移行
- HMM-GMMの限界を克服するため、ニューラルネットワークが導入され、以下のような進化がありました。
| 技術 | 概要 | メリット | デメリット |
|---|---|---|---|
| HMM | 音素や単語の時間的遷移を確率モデル化 | 逐次的な音声認識に適応 | 長期依存関係の学習が困難 |
| GMM | 音響特徴の確率分布をモデル化 | 音声の多様性を捉えやすい | 高次元データには非効率 |
| DNN-HMM | DNNを用いた音響特徴抽出 | 高精度なモデル化が可能 | HMMの制約が残る |
| LSTM | RNNの一種で、長期依存性を保持可能 | 長期的な文脈情報を効果的に学習し、音声認識や自然言語処理に有効 | 逐次処理のため並列処理が難しく、トレーニングに時間がかかる |
| Transformer | 自己注意機構で長期依存を学習 | 高精度、並列計算が可能 | 計算コストが高い |
HMM-GMMは音声認識の基礎を築いた重要な技術ですが、ニューラルネットワークの進化によって現在ではほぼ置き換えられました。しかし、そのアイデアは現代の機械学習モデルにも影響を与えています。
論文:『A tutorial on hidden Markov models and selected applications in speech recognition』

- HMMの体系的な解説と応用
- この論文は、隠れマルコフモデル(HMM)の基礎理論を体系的に整理し、その実用的な解決手法を詳しく解説しています。特に、評価・デコード・学習の3つの基本問題を定義し、それぞれに対するフォワード、ビタビ、バウム・ウェルチアルゴリズムを明確に示しました。これにより、HMMが音声認識をはじめとする幅広い分野で応用可能な強力なツールであることを示し、実用化の加速に貢献しました。
- 音声認識への画期的な貢献
- Rabinerの論文は、HMMを用いた音声認識の枠組みを確立し、実用化を加速させた点で画期的です。音素をHMMの隠れ状態としてモデル化する手法を提案し、単語や連続音声の認識を可能にしました。これにより、HMMは音声認識の標準技術となり、IBMやGoogleなどの企業が採用。さらに、現在のディープラーニング技術(DNN-HMMやエンド・ツー・エンド音声認識)にも応用され、AIアシスタント技術の基盤となっています。
HMM-GMMを使った音声認識の実装例
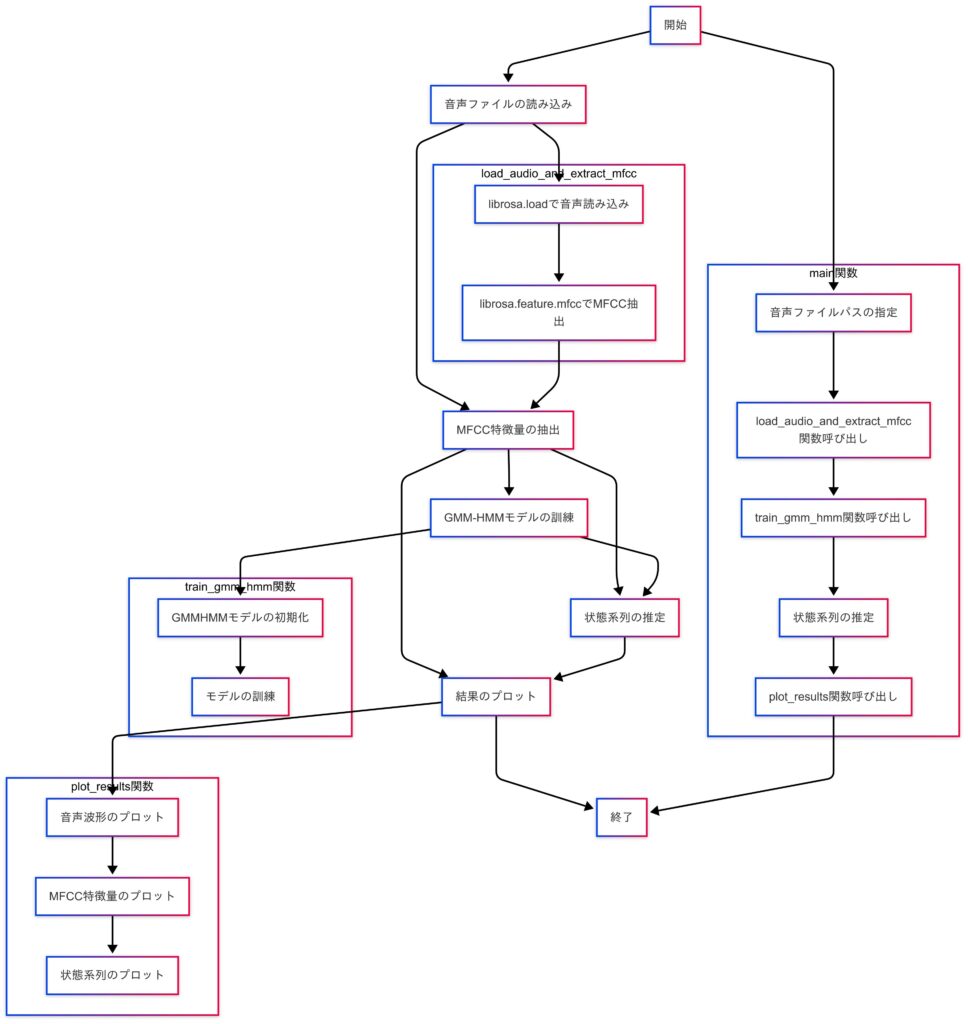
- Librosaで音声を読み込み、MFCC特徴を抽出し、hmmlearnのGMM-HMMを用いて状態系列を推定する音声認識のコード例です。
- 実行には、事前に下記パッケージをインストールしてください。
- 音声データはどんなものでも構いませんので用意してください。今回の例では英会話の音声データを用いることにします。
- audio_file = “音声ファイルのパスを入力”:mainコードの音声ファイルにパスを入力してください
pip install hmmlearnimport numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
from hmmlearn.hmm import GMMHMM
def load_audio_and_extract_mfcc(filename, sr=16000, n_mfcc=13):
"""
音声ファイルを読み込み、MFCC特徴を抽出する。
出力の mfcc は [n_frames, n_mfcc] の形状。
"""
y, sr = librosa.load(filename, sr=sr)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mfcc = mfcc.T
return y, sr, mfcc
def train_gmm_hmm(mfcc, n_states=4, n_mix=2, covariance_type='diag', n_iter=100):
"""
GMM-HMM モデルを訓練する。
n_states : HMM の状態数
n_mix : 各状態におけるガウシアンの混合数
"""
model = GMMHMM(n_components=n_states, n_mix=n_mix,
covariance_type=covariance_type, n_iter=n_iter,
random_state=42)
model.fit(mfcc)
return model
def plot_results(y, sr, mfcc, states):
"""
元の音声波形、MFCC特徴、及び HMM の状態系列をプロットする。
"""
fig, axes = plt.subplots(3, 1, figsize=(12, 15))
# (1) 音声波形
librosa.display.waveshow(y, sr=sr, ax=axes[0])
axes[0].set_title("原音声波形")
# (2) MFCC特徴
img = librosa.display.specshow(mfcc.T, sr=sr, x_axis='time', ax=axes[1])
axes[1].set_title("MFCC特徴")
fig.colorbar(img, ax=axes[1])
# (3) GMM-HMM による状態系列
# mfcc のフレーム数から各フレームの時間(hop_length のデフォルトは512)を算出
n_frames = mfcc.shape[0]
hop_length = 512 # librosa.feature.mfcc のデフォルト値
times = librosa.frames_to_time(np.arange(n_frames), sr=sr, hop_length=hop_length)
axes[2].plot(times, states, marker='o', linestyle='-')
axes[2].set_title("GMM-HMMによる状態系列")
axes[2].set_xlabel("Time (s)")
axes[2].set_ylabel("状態")
plt.tight_layout()
plt.show()
def main():
# 音声ファイルのパス(実際のファイルに合わせてください)
audio_file = "音声ファイルパスを入力"
y, sr, mfcc = load_audio_and_extract_mfcc(audio_file, sr=16000, n_mfcc=13)
print(f"音声長: {len(y)/sr:.2f}秒, MFCC形状: {mfcc.shape}")
# GMM-HMM の訓練(状態数4、各状態に2混合のガウシアンを仮定)
model = train_gmm_hmm(mfcc, n_states=4, n_mix=2, covariance_type='diag', n_iter=100)
# HMM を用いて MFCC 特徴系列から状態系列を推定
states = model.predict(mfcc)
# 結果(音声波形、MFCC、状態系列)をプロット
plot_results(y, sr, mfcc, states)
if __name__ == "__main__":
main()Deprecated as of librosa version 0.10.0.
It will be removed in librosa version 1.0.
y, sr_native = __audioread_load(path, offset, duration, dtype)
音声長: 59.63秒, MFCC形状: (1864, 13)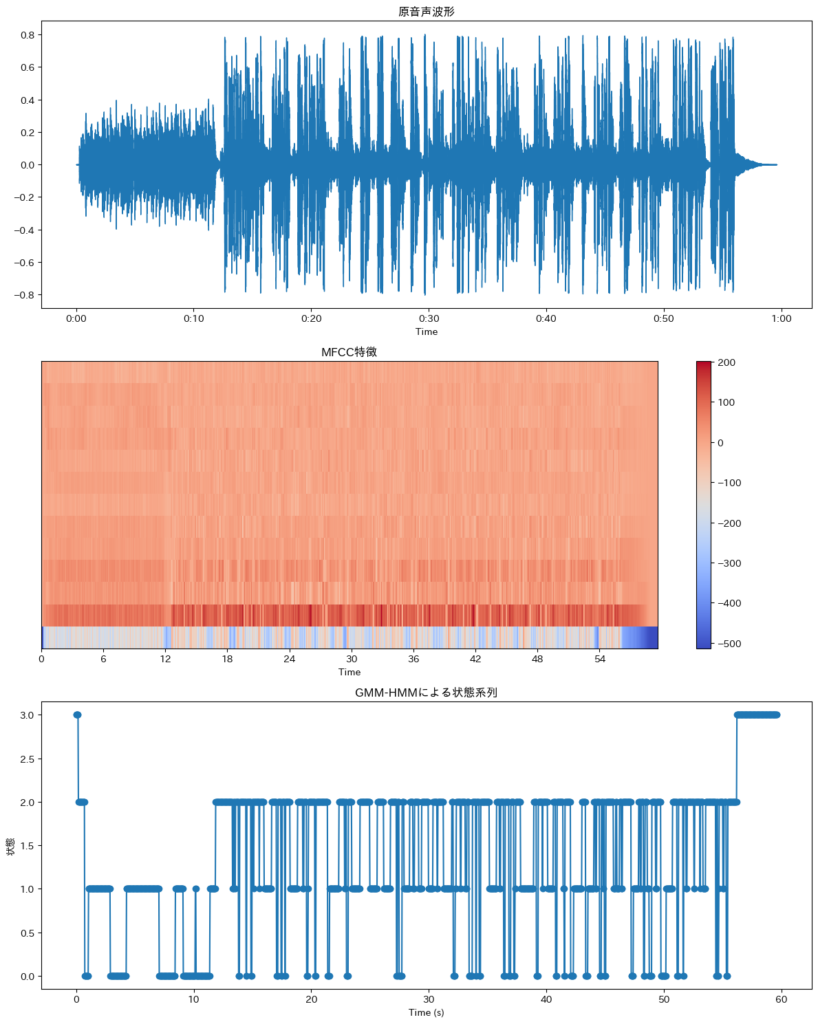
各サブプロットの内容
- 上段:原音声波形
- librosa.display.waveshow を利用して、音声信号の時間変化を表示しています。
- 中央:MFCC 特徴
- MFCC 特徴(転置済み)を specshow で表示し、色バーも追加して特徴量の強度を視覚化します。
- 下段:GMM-HMM による状態系列
librosa.frames_to_time(デフォルトhop_length=512)でMFCCの各フレームに対応する時間軸を算出し、推定された状態の時間推移をプロットして可視化します。
MFCC(メル周波数ケプストラム係数)
MFCCは、音声認識で広く使われる特徴量で、人間の聴覚特性を模倣して音声を数値化します。音声の特徴をコンパクトに表現できるのが強みですが、ノイズ耐性の向上が課題 です。
特徴
| 特徴 | 説明 |
|---|---|
| 人間の聴覚特性を考慮 | メル尺度を適用することで、低周波(低音域)を細かく、高周波(高音域)を大まかに捉えるようになります。これは、高周波成分よりも 音声のスペクトルの形状が重要視される ためです。 |
| 音声データの次元削減 | 生の音声波形は膨大なデータ量を持つため、MFCCを使うことで少数の特徴量に圧縮できる。 |
| 音響モデルでの利用 | 伝統的なHMM-GMMモデルだけでなく、最新のディープラーニングベースの音声認識でも特徴量として活用される。 |
MFCCの算出手順
- 音声を短時間フレーム(例: 25msごと)に分割
- フレームごとに高速フーリエ変換(FFT)で周波数領域へ変換
- メルフィルタバンクを適用し、対数スケールでエネルギーを計算
- 離散コサイン変換(DCT)を適用し、低次元のMFCC特徴量を抽出
- 最初の数個のMFCC係数(通常12〜13個)を使用
- 高速フーリエ変換(FFT)とは?
- FFTは、フーリエ変換そのものではなく、離散フーリエ変換(DFT)を高速に計算するアルゴリズムであり、計算効率の高さから実際の信号処理で広く使用されています。
- 高速フーリエ変換(FFT):下記URLを参照
- FFTは、フーリエ変換そのものではなく、離散フーリエ変換(DFT)を高速に計算するアルゴリズムであり、計算効率の高さから実際の信号処理で広く使用されています。
| 項目 | フーリエ変換(Fourier Transform) | 高速フーリエ変換(FFT) |
|---|---|---|
| 定義 | 連続または離散信号の周波数成分を求める変換 | DFT(離散フーリエ変換)を高速に計算するアルゴリズム |
| 適用対象 | 連続信号・離散信号 | 離散信号(DFTの高速版) |
| 計算量 | $O(N^2)$(DFTの場合) | $O(N \log N)$(大幅に速い) |
| 用途 | 理論的解析向け | 実装・実用向け(音声、画像、通信) |
- メルフィルタバンクとは?
- メルフィルタバンクは、人間の聴覚特性を模倣した周波数フィルタの集合で、音声の特徴を効率的に抽出する手法です。低音域を細かく、高音域を大まかに捉える「メル尺度」を適用し、音声信号の周波数成分を圧縮・変換します。これにより、ノイズの影響を抑えつつ、重要な情報を保持 できます。音声認識では、メルフィルタバンクの出力を基にMFCC(メル周波数ケプストラム係数)を算出し、機械学習の特徴量として活用します。
| 項目 | メルフィルタバンク | MFCC |
|---|---|---|
| 目的 | 周波数エネルギーの圧縮・変換 | さらに圧縮し、機械学習向けの特徴量にする |
| 特徴量の数 | フィルタ数(例:26) | 次元をさらに削減(例:12~13) |
| 処理ステップ | FFT → メル尺度適用 | FFT → メル尺度適用 → DCT |
- 離散コサイン変換(DCT)とは?
- 離散コサイン変換(DCT) は、信号を周波数成分に分解する数学的変換で、音声処理や画像圧縮で広く使われます。フーリエ変換と異なり、実数のみを扱い、エネルギーを低次元に効率よく集約できる のが特徴です。音声認識では、メルフィルタバンクの出力にDCTを適用し、MFCCを算出 します。画像圧縮(JPEG)では、高周波成分を削減し、データ圧縮を実現。計算負荷が低く、信号の圧縮やノイズ除去に優れています。
- DCTの詳細については下記URLを参照してください。
- FFTとの違い
- FFTは複素数の周波数成分(振幅と位相両方)を求めるのに対し、DCTは実数のみのコサイン基底を用いて信号のエネルギー分布を表現します。
| 特徴 | FFT | DCT |
|---|---|---|
| 出力の性質 | 複素数の結果が得られ、正負の周波数成分が対になって現れる。 | 出力は実数のみで、信号のエネルギーが低次元(低インデックス)に集中しやすい。 |
| エネルギーの集中 | エネルギー分布は比較的広範囲に分散する。 | 少数の係数にエネルギーが集中するため、圧縮や特徴抽出(例:MFCCの計算)に有利。 |
| 周波数との対応 | 各係数が明確な周波数成分に直接対応しており、周波数軸に沿った解析が容易。 | インデックスと周波数の対応はFFTほど直接的ではなく、信号のエネルギー分布に着目した解析が行われる。 |
深層学習の導入
HMM-DNNモデル
HMM-DNN は、HMMの統計的手法に深層学習(DNN)を組み合わせた音声認識モデルです。従来のHMM-GMMでは単純な確率分布に基づいて音声をモデル化していましたが、DNNを導入することで、より詳細な特徴抽出や複雑なデータ分布の学習が可能になりました。これにより、HMMの逐次的な構造とDNNの高い表現力を活かし、LSTM登場前の過渡的なアプローチとして音声認識の精度向上に貢献しました。
HMM-DNNの特徴
| 特徴 | 説明 |
|---|---|
| HMMの状態遷移モデル | HMMは音声信号の時間的変化をモデル化するために使用され、発話の進行に伴う確率的な状態遷移を表現します。 |
| DNNによる音響モデル | DNNはフレームごとの音声特徴量(例:MFCCやフィルタバンク特徴)を入力として、HMMの状態確率を推定します。これにより、従来のGMMよりも複雑な音響パターンを学習し、より正確な音素識別が可能となります。 |
| HMM-GMMと比較した優位性 | GMMは線形分離可能なデータに対して有効ですが、音声信号の非線形なパターンを捉えるには限界があります。DNNはより深い階層構造で複雑な音響特徴を捉えるため、HMM-GMMに比べ認識精度が大幅に向上します。 |
数式
- HMM-DNNモデルは、HMMの確率モデルとDNNの分類能力を統合した形で表現されます。
HMMの状態遷移確率
$$P(Q, O) = P(Q_1) \prod_{t=2}^{T} P(Q_t | Q_{t-1}) \prod_{t=1}^{T} P(O_t | Q_t)$$
$Q_t$は時刻 $t$ における隠れ状態。$O_t$は観測データ(音声特徴量)。$P(Q_t∣Q_{t−1})$はHMMの遷移確率。$P(O_t∣Q_t)$は音響モデルによる確率分布。
DNNによる状態確率の推定
- GMMの代わりにDNNを用いることで、音声特徴量 $O_t$ からHMMの状態確率を求めます。
$$P(Q_t | O_t) = \text{Softmax}(W O_t + b)$$
$W$はDNNの重み。$b$はバイアス項。Softmax関数を適用することで、HMMの各状態に対応する確率を出力します。
目的と課題
| 項目 | 目的(メリット) | 課題(デメリット) |
|---|---|---|
| 1. 音響特徴のモデリングと認識精度 | DNNを活用して、従来のHMM-GMMでは捉えきれなかった非線形な音響特徴を学習し、認識精度を大幅に向上させる。 | 大量のデータと計算資源が必要で、トレーニングコストが高い。 |
| 2. モデル統合と最適化 | HMMの時間情報を保持しながら、DNNの表現力を活かして自然な発話認識を実現。これにより、既存システムの改良が容易となる。 | HMMとDNNの組み合わせはエンドツーエンド学習が困難で、各部分の個別最適化が求められる。 |
| 3. システム実用性と処理効率 | 既存のHMMベースシステムを改良し、異なる話者や環境ノイズにも頑健な認識システムを構築。 | 逐次処理が必要なため並列計算が難しく、処理速度や解釈性(ブラックボックス性)の面で課題が残る。 |
適用例
| 適用例 | 説明 |
|---|---|
| 音声アシスタント | Google Assistant、Siri、Alexaなどで、より自然な音声認識を実現するために採用。 |
| コールセンターの自動応答 | 顧客の問い合わせに対し、高精度な音声認識が求められる環境で活用。 |
| 字幕生成システム | 映画やテレビ番組の自動字幕生成において、HMM-DNNモデルが利用される。 |
論文1:『Deep Neural Networks for Acoustic Modeling in Speech Recognition』
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/38131.pdf
- DNNの導入による音響モデルの進化
- 本論文は、従来のGMM-HMMに代わり、DNN-HMMを音響モデルに適用することで、音声認識精度を飛躍的に向上させた。RBMによる事前学習とSGDによる微調整を組み合わせることで、DNNの効果的な学習を実現し、TIMITでPER 9%、SwitchboardでWER 13%の改善を達成。DNNは非線形な特徴抽出と複数フレームの同時処理が可能で、音声認識の新たな標準技術となった。本研究は、今日のAI音声認識の礎を築いた重要なマイルストーンである。
- 実験結果とDNNの優位性の証明
- 本論文は、TIMITやSwitchboardなどのデータセットを用いて、DNN-HMMがGMM-HMMを圧倒的に上回る性能を持つことを証明した。TIMITでは音素エラー率 (PER) を9%、Switchboardでは単語エラー率 (WER) を13%改善。DNNは非線形な特徴抽出や文脈情報の活用が可能で、音声認識の精度を飛躍的に向上させた。本研究により、DNNは実用レベルの音声認識技術として適用可能であることが示され、AI音声認識の発展に大きく貢献した。
論文2:『Context-Dependent Pre-Trained Deep Neural Networks for Large Vocabulary Speech Recognition』
https://www.cs.toronto.edu/~gdahl/papers/DBN4LVCSR-TransASLP.pdf
- コンテキスト依存型 DNN-HMM による音声認識の向上
- 本研究では、大語彙音声認識(LVSR)向けにコンテキスト依存型DNN-HMM(CD-DNN-HMM)を提案。事前学習にディープビリーフネットワーク(DBN)を活用し、HMMの状態(senone)の予測精度を向上。従来のGMM-HMMと比較し、文脈依存の音声特徴をより正確に捉え、最大9.2%の認識精度向上を達成しました。これにより、高精度な音声認識技術の発展に貢献しました。
- 高速なデコードと GPU を活用した効率的な学習
- 本研究で提案されたCD-DNN-HMMは、従来のGMM-HMMと比較して高い精度を実現するものの、学習時の計算コストが大幅に増加する課題がありました。しかし、GPUを活用することで学習時間を約30倍短縮し、大規模データセットにも適用可能な効率的な学習フローを確立しました。さらに、デコード処理はリアルタイムの0.17倍速で実行でき、実用的な速度での音声認識が可能となりました。これにより、高速かつ高精度な音声認識システムの実現に寄与しました。
HMM-DNNを使った音声認識の実装例
- HMM-DNNモデル(入力:39次元のMFCC特徴量、隠れ層:128ユニット、出力:10クラス)を用いて音声認識を行い、音声波形、MFCC特徴量、そして各フレームごとの予測結果(音素ラベル)および学習時のLoss推移をプロットする実装例を用いて説明します。
- このHMM-DNNアーキテクチャは、各フレーム単位で音素ラベルを予測し、学習・推論・可視化を通じて音声認識の流れを理解しやすくするモデルです。
- audio_file = “音声ファイルのパスを入力”:mainコードの音声ファイルにパスを入力してください
ライブラリのインポート
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoaderHMM-DNNモデルの定義
class HMM_DNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(HMM_DNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.softmax(self.fc2(x))
return x最初の全結合層では、入力次元(39次元)を隠れ層(例:128ユニット)に変換し、ReLU活性化関数 を用いることで非線形変換による表現力を向上させます。次に、2層目の全結合層で隠れ層を出力クラス(10クラス)に変換し、Softmax関数を適用して確率分布に変換 することで、各クラスの出現確率を算出します。
音声の読み込みとMFCC特徴抽出
def load_audio_and_extract_mfcc(filename, sr=16000, n_mfcc=39):
y, sr = librosa.load(filename, sr=sr)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mfcc = mfcc.T
return y, sr, mfcc音声ファイルを指定したサンプリングレート(16kHz)で読み込み、MFCC特徴量を抽出します。出力はもともと [n_mfcc, n_frames] の形状 ですが、転置して [n_frames, n_mfcc] に整形し、最終的に 39次元のMFCCを取得します。
各フレーム単位のDatasetの作成
class FrameDataset(Dataset):
def __init__(self, mfcc_features):
self.mfcc = mfcc_features.astype(np.float32)
self.labels = np.random.randint(0, 10, size=(self.mfcc.shape[0],))
def __len__(self):
return self.mfcc.shape[0]
def __getitem__(self, idx):
X = self.mfcc[idx] # 1フレームのMFCC([n_mfcc])
y = self.labels[idx] # ダミーラベル(スカラー)
return X, y各フレームを1サンプルとして扱い、入力にはそのフレームのMFCC特徴量を使用します。ラベルはダミーとして 0~9の値をランダムに生成し、これにより 全フレーム分の学習データが作成されます。
モデルの学習ループ
def train_model(model, dataloader, num_epochs=10, device="cpu"):
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for X_batch, y_batch in dataloader:
X_batch = X_batch.to(device) # バッチサイズ×入力次元
y_batch = y_batch.to(device)
optimizer.zero_grad()
outputs = model(X_batch) # 出力は各サンプルについてクラス確率
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
loss_history.append(avg_loss)
print(f"Epoch {epoch+1}/{num_epochs} - Loss: {avg_loss:.4f}")
return loss_history交差エントロピー損失(CrossEntropyLoss)を用いて 出力とダミーラベルの誤差を計算し、Adamオプティマイザでパラメータを更新します。さらに、各エポックごとの平均Lossを算出し、履歴として記録します。
推論とプロット
def infer_and_plot(model, y_wave, sr, mfcc, loss_history):
model.eval()
with torch.no_grad():
X_tensor = torch.tensor(mfcc, dtype=torch.float32) # 全フレームをまとめて入力
outputs = model(X_tensor) # [n_frames, num_classes]
predictions = outputs.argmax(dim=1).cpu().numpy() # 各サンプルに対する予測ラベル
# 各種プロットを作成
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
# ① 音声波形
librosa.display.waveshow(y_wave, sr=sr, ax=axes[0])
axes[0].set_title("元の音声波形")
# ② MFCC特徴のスペクトログラム
axes[1].set_title("MFCC特徴")
librosa.display.specshow(mfcc.T, sr=sr, x_axis='time', ax=axes[1])
# ③ 各フレームごとの予測ラベルタイムライン
axes[2].plot(np.arange(len(predictions)), predictions, marker='o', linestyle='-')
axes[2].set_title("HMM-DNNによるフレームごとの予測(音素ラベル)")
axes[2].set_xlabel("フレーム番号")
axes[2].set_ylabel("予測クラス")
plt.tight_layout()
plt.show()
# 学習時のLoss推移
plt.figure(figsize=(8, 4))
plt.plot(loss_history, marker='o')
plt.title("学習時のLoss推移")
plt.xlabel("エポック")
plt.ylabel("Loss")
plt.grid(True)
plt.show()元の音声波形を表示し、MFCCのスペクトログラムを用いて時間軸に沿った特徴量の変化を視覚化します。さらに、モデルが各フレームごとに予測した音素ラベル(ダミーラベル)をタイムラインとしてプロットし、学習Lossの推移をエポックごとに表示して、学習の収束具合を確認 します。
main関数
def main():
audio_file = "音声ファイルのパスを入力"
y_wave, sr, mfcc = load_audio_and_extract_mfcc(audio_file, sr=16000, n_mfcc=39)
print(f"音声長: {len(y_wave)/sr:.2f}秒, MFCC形状: {mfcc.shape}")
dataset = FrameDataset(mfcc)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
model = HMM_DNN(input_dim=39, hidden_dim=128, output_dim=10)
loss_history = train_model(model, dataloader, num_epochs=10, device="cpu")
infer_and_plot(model, y_wave, sr, mfcc, loss_history)
if __name__ == "__main__":
main()指定された音声ファイルから MFCC特徴量を抽出し、音声波形とともに表示します。FrameDataset と DataLoaderを用いてデータセットを構築し、HMM-DNNモデルを生成して学習ループを実行。学習後は推論を行い、音声波形・MFCC・予測ラベル・Loss推移の各プロットを描画 します。
sa.load(filename, sr=sr)
音声長: 59.63秒, MFCC形状: (1864, 39)
Epoch 9/10 - Loss: 2.3374
Epoch 10/10 - Loss: 2.3288
HMM-DNNは、HMM-GMMの限界を克服するためにDNNを音響モデルとして導入し、LSTMやTransformerへと進化する過程で重要な役割を果たしました。この技術により 音声認識の精度が大幅に向上し、エンドツーエンド学習への橋渡し となりました。
LSTMモデル
- RNNとLSTMの登場
- 従来のHMM-GMMによる音声認識の課題を克服するために、RNNが導入されました。RNNは時系列データの処理に適していますが、勾配消失問題により長期依存関係の学習が困難でした。この問題を解決するために、より高度なLSTMが開発され、音声認識の精度向上に貢献しました。
- LSTMによる音声認識の進化
- LSTMはゲート機構を導入し、長期的な依存関係を学習しやすくすることで、音声認識の精度を大幅に向上させました。
- HMM-DNNからの経緯
- HMM-DNNの課題であったフレームごとの独立仮定や手作業による遷移確率の設定、時間的変化のモデリングの制約を、RNN/LSTMは長期依存関係の学習とデータ駆動型のエンドツーエンド学習によって克服し、音声認識の精度と柔軟性を大幅に向上させました。
| 特徴 | 説明 |
|---|---|
| 長期文脈の考慮 | HMMは単語や音素ごとに認識していましたが、LSTMは文脈全体を考慮できるため、より高精度な音声認識が可能になりました。 |
| エンドツーエンド学習 | HMM-DNNは特徴量抽出、音響モデル、言語モデルを個別に学習する必要がありましたが、LSTMは全体を一括してエンドツーエンドで学習可能なため、システム全体の最適化が容易です。 |
| 強力なノイズ耐性 | 過去の音声データを保持しつつ、現在の発話の特徴を強調することで、環境ノイズに対する耐性が向上し、安定した認識性能が得られます。 |
LSTMを使った音声認識の実装例)
- このコードは、LSTMを用いた音声認識モデルを構築し、音声データの特徴抽出・学習・評価・推論を一貫して実行できるパイプラインの例 です。音声ファイルの特徴を抽出し、LSTMでフレームごとのラベルを予測し、その結果を可視化するまでのプロセスを実装しています。
- audio_file = “音声ファイルのパスを入力”:mainコードの音声ファイルにパスを入力してください
必要なライブラリのインポート
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader音声の読み込みとMFCC特徴抽出
def load_audio_and_extract_mfcc(filename, sr=16000, n_mfcc=13):
y, sr = librosa.load(filename, sr=sr)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mfcc = mfcc.T
return y, sr, mfcc音声ファイルを16kHzのサンプリングレートで読み込み、信号を取得 します。次に、13次元のMFCC特徴量を抽出し、各フレームの特徴を [n_frames, n_mfcc]の形に整えます。
ダミーデータセットの作成
class SpeechDataset(Dataset):
def __init__(self, mfcc_features, seq_len=20):
self.mfcc = mfcc_features.astype(np.float32)
self.seq_len = seq_len
self.labels = np.random.randint(0, 10, size=self.mfcc.shape[0])
def __len__(self):
return len(self.mfcc) - self.seq_len
def __getitem__(self, idx):
X = self.mfcc[idx:idx+self.seq_len]
y = self.labels[idx:idx+self.seq_len]
return X, y抽出したMFCC特徴量を使い、各フレームを順次まとめたシーケンス(ウィンドウ長20)と、そのシーケンス内の各フレームに対するダミーの音素ラベル(0~9)を作成します。
LSTMによる音声認識モデル
class LSTMSpeechRecognizer(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, num_classes, dropout=0.1):
super(LSTMSpeechRecognizer, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers,
batch_first=True, dropout=dropout, bidirectional=False)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out)
return outモデルは入力のMFCCシーケンス(1サンプル=1シーケンス)をLSTMに通し、最終層の全結合層により各フレームごとに音素クラス(例:0~9)に分類する出力を生成します。
学習と評価のループ
def train_model(model, dataloader, num_epochs=10, device="cpu"):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.to(device)
loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for X_batch, y_batch in dataloader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs.view(-1, outputs.shape[-1]), y_batch.view(-1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dataloader)
loss_history.append(avg_loss)
print(f"Epoch {epoch+1}/{num_epochs} - Loss: {avg_loss:.4f}")
return loss_history推論して予測結果をプロット
def infer_and_plot(model, dataset, loss_history, y_wave, sr, mfcc, num_display=100):
model.eval()
X_sample, y_sample = dataset[0]
with torch.no_grad():
X_tensor = torch.tensor(X_sample).unsqueeze(0)
outputs = model(X_tensor)
predictions = outputs.argmax(dim=-1).squeeze(0).cpu().numpy()
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
librosa.display.waveshow(y_wave, sr=sr, ax=axes[0])
axes[0].set_title("元の音声波形")
axes[1].set_title("MFCC特徴")
librosa.display.specshow(mfcc.T, sr=sr, x_axis='time', ax=axes[1])
axes[2].plot(np.arange(len(predictions)), predictions, marker='o', linestyle='-')
axes[2].set_title("LSTMによるフレームごとの予測(音素ラベル)")
axes[2].set_xlabel("フレーム番号")
axes[2].set_ylabel("予測クラス")
plt.tight_layout()
plt.show()
plt.figure(figsize=(8, 4))
plt.plot(loss_history, marker='o')
plt.title("学習時のLoss推移")
plt.xlabel("エポック")
plt.ylabel("Loss")
plt.grid(True)
plt.show()モデルの推論モードでデータセットから1シーケンスを選び、対応するモデルの出力を取得 します。出力から各フレームの予測ラベルを抽出し、音声波形(振幅の時間変化)、MFCCスペクトログラム(特徴量の可視化)、予測ラベルのタイムライン(音素ラベルの推移)をプロット します。さらに、学習時の損失推移も別のプロットで表示 し、モデルの学習状況を確認できるようにしています。
メイン関数
def main():
audio_file = "音声ファイルのパスを入力"
y_wave, sr, mfcc = load_audio_and_extract_mfcc(audio_file, sr=16000, n_mfcc=13)
print(f"音声長: {len(y_wave)/sr:.2f}秒, MFCC形状: {mfcc.shape}")
dataset = SpeechDataset(mfcc, seq_len=20)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
model = LSTMSpeechRecognizer(input_dim=13, hidden_dim=64, num_layers=2, num_classes=10, dropout=0.1)
loss_history = train_model(model, dataloader, num_epochs=10, device="cpu")
infer_and_plot(model, dataset, loss_history, y_wave, sr, mfcc)
if __name__ == "__main__":
main()- 指定した音声ファイルからMFCC特徴量を抽出し、ダミーデータセットとデータローダーを構築します。LSTMを用いた音声認識モデルを初期化し、学習を実行。その結果として、Loss推移の可視化と、推論結果(音声波形、MFCC特徴、予測ラベルタイムライン)をプロットして表示 します。
Deprecated as of librosa version 0.10.0.
It will be removed in librosa version 1.0.
y, sr_native = __audioread_load(path, offset, duration, dtype)
音声長: 59.63秒, MFCC形状: (1864, 13)
Epoch 9/10 - Loss: 1.5912
Epoch 10/10 - Loss: 1.5289
- プロット内容
- 元の音声波形
- 音声信号の時間領域での波形を表示しており、どのような音の振幅変化があるかを確認できます。
- MFCC特徴
- 音声信号から抽出されたMFCCのスペクトログラムで、時間軸に沿ってどのような音響特徴が変化しているかを視覚化しています。
- LSTMによるフレームごとの予測(音素ラベル)
- LSTMモデルが各フレーム単位で予測したダミーの音素ラベル(0~9)がタイムライン上にプロットされ、モデルが各フレームをどのクラスに分類したかを示しています。
- 元の音声波形
HMM-GMM と LSTM のアプローチの違い
| 項目 | HMM-GMM | LSTM |
|---|---|---|
| 特徴抽出から推論へのアプローチ | 事前に用意したMFCCなどの音声特徴量を入力し、DNNで音響パターンを学習。HMMが状態遷移をモデル化し、各フレームの状態確率を推定して音声認識を行う。 | 同じMFCCを入力とし、ネットワーク自体がフレーム間の時間的依存性や特徴の抽象化を自動的に学習し、各フレームごとに直接ラベル予測を実施。 |
| 最適化手法と計算資源 | HMM-DNNは、HMMの状態遷移とDNNの表現力を組み合わせ、音声認識精度を向上 させます。ただし、DNN導入によりパラメータが増え、計算負荷が増大する。 | ディープラーニングモデルとして多くのパラメータを含むため、大量データと強力な計算資源が必要だが、非線形性や複雑なパターンの抽出能力が高い。 |
このLSTM実装は、音声信号の時間的関係を学習し、ラベルを予測するディープラーニング手法 です。一方、HMM-DNNは、HMMの状態遷移モデルにDNNを組み合わせ、非線形な音響特徴を学習する手法 であり、設計やパラメータ設定のアプローチがLSTMとは異なります。
論文:『Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition』

- LSTM RNNの音声認識性能向上
- LSTM RNNを用いた音響モデルは、従来のHMM-DNNハイブリッドモデルより高精度な音声認識を実現します。本研究では、フレームスタッキングにより複数の音響フレームをまとめて処理し、時間的な依存関係を効果的に学習。また、フレームレートの削減により計算負荷を抑え、デコーディングの高速化を実現しました。これにより、リアルタイム性を維持しつつ単語誤り率(WER)を削減し、大語彙音声認識(LVCSR)タスクに適したモデルを構築しました。
- CTCとsMBRによる高精度学習
- CTCは、音声とラベルのアライメントを不要にし、ブランク(Blank)ラベルを用いることで柔軟な学習を可能にします。本研究では、文脈依存音素(CD-phone)を導入し、WERを8%削減。さらに、単語誤り率(WER)を直接最適化するsMBR学習を適用し、追加で10%改善しました。このCTC + sMBRの組み合わせにより、従来のHMM-DNNを超える高精度な音声認識を実現しました。
- 双方向LSTMの有効性
- 双方向LSTMは、過去と未来の情報を活用することで、単方向LSTMより最大25%の単語誤り率(WER)低減を達成しました。特に、文脈依存音素(CD-phone)を用いることで精度が向上。単方向LSTMはリアルタイム処理に適する一方、双方向LSTMは精度が重要な大語彙音声認識(LVCSR)に有効です。本研究では、双方向LSTMが単方向モデルを上回る性能を持ち、オフライン音声認識や高精度アプリケーションに適していることを示しました。
LSTMの代表的な音声認識アプリケーション
- Deep Speech 2(2015, Baidu):LSTMを活用したエンドツーエンド音声認識モデル
- Google Voice Search(2010年代中盤): HMM-GMMからLSTMベースの音声認識へ移行
音声認識におけるLSTMの課題
- LSTMはゲート機構により短期的な記憶を保持できますが、極端に長いシーケンスでは情報を維持しにくい という限界があります。さらに、逐次処理が必要なため並列化が難しく、学習や推論の計算コストが高くなる ことが、大規模データ処理の課題となります。
LSTMは音声認識の精度を大幅に向上させましたが、より高精度なモデルが求められ、Attention機構やTransformerへと進化 しました。
Transformerモデルの音声認識への応用
Speech-Transformer
Speech-Transformer は、LSTMやRNNベースの音声認識モデルに代わるTransformerベースの手法 で、自己注意機構(Self-Attention)を活用することで 並列処理を可能にし、長期依存関係の学習を強化しました。従来のRNNの逐次処理の制約を克服し、音声波形をスペクトログラムなどの特徴量に変換し、エンコーダ・デコーダ構造を用いて音素や単語列を推定 することで、音声からテキストへの変換を行います。
特徴
| 特徴 | 説明 |
|---|---|
| コンテキストの広範な捕捉 | 過去と未来の情報を統合し、より正確な音声認識を実現。 |
| ポジションエンコーディングの導入 | 時系列情報を明示的にエンコードし、RNNなしで時系列学習を可能にする。 |
| エンコーダ・デコーダ構造 | エンコーダは音声スペクトログラムから特徴を抽出し、デコーダはその特徴をもとに音素や単語列を生成。 |
| 長期依存関係の効率的学習 | 時間方向に制約されず、文脈の広範な情報を活用して、長期的な依存関係を学習。 |
数式とモデルの構造
- Speech-Transformerのモデル構造
Speech-Transformerは、事前学習済みのモデル を活用し、それを ファインチューニング することで、音声認識の精度を向上させる仕組みを持っています。
- 事前学習の必要性
- Speech-Transformerは、大規模な音声データを用いた事前学習(Pretraining)によって、音響情報や音素パターンを学習します。特に、Wav2Vec2やHuBERTなどの自己教師あり学習(SSL)を活用することで、ラベルなしの音声データから有用な特徴を抽出し、音声認識の精度を向上させます。
- Transformerベースのファインチューニング
- 事前学習済みモデルをTransformerに組み込み、ファインチューニングを行うことで、特定の音声認識タスクに適用可能になります。これにより、英語から日本語への適応などが可能となり、文脈を考慮した予測や長期依存関係の学習が強化されます。さらに、Self-Attentionにより、LSTMでは難しかった広範な文脈情報を活用でき、認識精度が向上します。
- 具体的なメリット
| 具体的なメリット | 説明 |
|---|---|
| 並列計算が可能 | LSTMよりも学習・推論が高速になる。 |
| 長期的な依存関係を学習 | 文脈を考慮した高精度な音声認識が可能になる。 |
| 事前学習済みモデルの知識を転用 | 少ないデータでも高精度なモデル構築が可能になる。 |
主要な数式
- Scaled Dot-Product Attention
- 長期依存関係の学習を可能にし、並列計算を最適化
$$\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V$$
- Multi-Head Attention
- 複数の注意メカニズムを適用し、多様な特徴を学習
$$\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O$$
適用例
| 実際の応用例 | 具体例 |
|---|---|
| 音声アシスタント | Siri, Google Assistant |
| リアルタイム音声翻訳 | Google Translate, DeepL |
| 字幕生成 | YouTube, Netflix |
| 会話AI | カスタマーサポート、コールセンター |
実装例(Speech-Transformerの簡易PyTorch実装)
このモデルが正確に音声をテキスト化するには、事前に大量のラベルなしデータを使ってモデルを事前学習し、その後、少量のラベル付きデータでファインチューニングする必要があります。ファインチューニングを行うことで、モデルは音声の特徴を学習し、発話のパターンや単語の関連性を理解できるようになります。学習を行っていない状態では、ランダムなパラメータのまま動作するため、正確な音声認識は期待できません。そのため今回は簡易実装とさせて頂きます。
import torch
import torch.nn as nn
class SpeechTransformer(nn.Module):
def __init__(self, input_dim, hidden_dim, num_heads, num_layers):
super(SpeechTransformer, self).__init__()
self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_dim, nhead=num_heads)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder_layer = nn.TransformerDecoderLayer(d_model=input_dim, nhead=num_heads)
self.decoder = nn.TransformerDecoder(self.decoder_layer, num_layers=num_layers)
self.fc_out = nn.Linear(input_dim, hidden_dim)
def forward(self, src, tgt):
memory = self.encoder(src)
output = self.decoder(tgt, memory)
return self.fc_out(output)論文:『SPEECH-TRANSFORMER: A NO-RECURRENCE SEQUENCE-TO-SEQUENCE MODEL FOR SPEECH RECOGNITION』
https://sci-hub.se/downloads/2020-09-03/63/dong2018.pdf
- RNNを排除した音声認識モデルの実現
- Speech-Transformerは、従来のRNNベースの音声認識モデルを不要とし、Transformerの自己注意機構を活用することで並列計算を可能にした。これにより、学習速度が大幅に向上し、長距離依存関係の学習も改善された。従来のRNNは逐次処理のため計算が遅く、長い発話の情報を適切に保持しにくかったが、Speech-Transformerは全入力を同時に処理できるため、より高速かつ高精度な音声認識を実現した。
- 2D-Attentionの導入による性能向上
- 従来のRNNやCNNでは、時間的変化や音響的特徴の捉え方に課題があった。2D-Attentionは時間軸と周波数軸の両方に注意を適用し、音声の文脈情報とスペクトル情報を統合的に学習可能にした。これにより、長距離依存関係を効率的に捉え、高精度な音声認識を実現した。
次は先ほど紹介した事前学習モデルとしても活用できて、自己教師あり学習モデルであるWav2Vec 2.0を利用して音声ファイルをテキスト化させてみましょう。
Wav2Vec 2.0
Wav2Vec 2.0は、Meta AI(旧Facebook AI)が2020年に発表した自己教師あり学習(SSL)を活用した音声認識モデルです。従来のモデルがMFCCやスペクトログラムを経由して特徴を抽出していたのに対し、Wav2Vec 2.0は生の音声波形から直接学習し、音素や単語を認識できる点が特徴です。

特徴(3ステップ)
- 生波形を潜在空間にエンコード
- 生の音声波形 $x$ を、CNNベースのFeature Encoderを使って潜在表現に変換します。
$$z = f_{\text{enc}}(x)$$
このエンコーダは 畳み込みニューラルネットワーク(CNN) を用いて、長時間の波形を短い時間スパンの 潜在ベクトル $z_t$ に変換し、計算コストを削減します。
2. コントラスト学習による潜在表現の学習
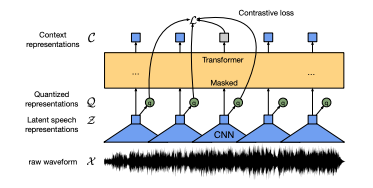
論文:https://arxiv.org/abs/2006.11477
- Wav2Vec 2.0 では、エンコードされた表現 $z_t$ に対して Transformer を適用し、時間的文脈を考慮した表現 $c_t$ を生成します。
$$c = f_{\text{trans}}(z)$$
このとき、自己教師あり学習のために、「マスキング」と「コントラスト学習」 を導入しています。
- マスキング
- 入力の一部(例: 50%のフレーム)をマスクし、学習時にその正しい潜在表現を予測させることで、Transformerが時間的な依存関係を効果的に学習できるようにします。
- コントラスト学習
- モデルが正しい系列を識別できるよう、未来の正しい潜在表現(ポジティブサンプル)とランダムな他の潜在表現(ネガティブサンプル)を比較し、InfoNCE Lossを最適化します。
$$L = – \sum_{t} \log \frac{\exp(\text{sim}(c_t, q_t))}{\sum_{q’ \in Q} \exp(\text{sim}(c_t, q’))}$$
$c_t$ はマスキングされた部分の出力。$q_t$ は正しい潜在表現(ポジティブ)。$Q$ はネガティブサンプルの集合。
このコントラスト学習を通じて、音声の文脈を捉えた高品質な特徴表現を学習できます。
3. ファインチューニング
- 事前学習が完了したら、音声認識のためにラベル付きデータを使ってファインチューニングを行う。
- ファインチューニングについては下記を参照してください。
$$y = f_{\text{ASR}}(c)$$
- 音素単位のラベル:(例:「こんにちは」 → /ko/ /n/ /ni/ /ti/ /wa/)
- 単語単位のラベル:(例:「こんにちは」 → 「こんにちは」)
Transformerの出力 $c$ を音素や単語ラベルにマッピングし、クロスエントロピー損失を最適化。
$$L_{\text{CE}} = – \sum_i y_i \log \hat{y}_i$$
Wav2Vec 2.0 のメリットとデメリット
| メリット | デメリット |
|---|---|
| 自己教師あり学習(SSL)により、大規模なラベルなし音声データから学習可能 | 事前学習に大量の計算リソースが必要 |
| 生の音声波形を直接学習でき、従来の特徴量(MFCCなど)が不要 | 音声データの長さが可変のため、適切なマスキング処理が必要 |
| Transformer により長期的な文脈を考慮し、RNNよりも精度が向上 | ファインチューニング時に専用のデータセットが必要 |
| 少ないデータでも高精度なファインチューニングが可能 |
論文:『Wav2Vec 2.0: A Framework for Self-Supervised Learning of Speech Representations』

- 自己教師あり学習による音声表現の獲得
- wav2vec 2.0は、自己教師あり学習 により、大量のラベルなし音声データから高品質な音声表現を学習するモデルです。音声波形をそのまま入力し、マスクされた部分を予測する対比学習を用いることで、文脈を考慮した特徴を獲得。従来の手作業による特徴設計が不要で、エンドツーエンドで最適化できます。さらに、少量のラベル付きデータでも高精度な音声認識が可能になり、低リソース言語や専門分野の音声認識にも有効です。
- 少量のラベル付きデータで高精度な音声認識を実現
- wav2vec 2.0は、自己教師あり学習を活用し、大量のラベルなし音声データで事前学習を行います。その後、わずか10分のラベル付きデータ で従来の100時間分のデータ 相当の精度を達成。さらに、960時間のデータ では最先端モデルと同等の認識精度を実現しました。これにより、低リソース言語や専門分野の音声認識 への応用が容易になり、データ収集の負担を大幅に軽減できる可能性があります。
Wav2Vec 2.0の実装例
- このコードでは、Hugging Face の Wav2Vec2Processor と Wav2Vec2ForCTC を用いており、Wav2Vec 2.0 の特徴抽出と CTC による音声認識を実現しています。
import torch
import torch.nn as nn
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# モデルのロード
model_name = "facebook/wav2vec2-large-960h"
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = Wav2Vec2ForCTC.from_pretrained(model_name)
# 音声ファイルのロード(16kHzにリサンプル)
audio_file = "/Users/Shion/Desktop/Python/1-01 Cd1-1.m4a" # 音声ファイルパスを入力
y, sr = librosa.load(audio_file, sr=16000)
# 可視化①: 音声波形
plt.figure(figsize=(12, 4))
plt.plot(y)
plt.title("Audio Waveform")
plt.xlabel("Samples")
plt.ylabel("Amplitude")
plt.show()
# 可視化②: log‑melスペクトログラム
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=400, hop_length=160, n_mels=80)
log_mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
plt.figure(figsize=(12, 4))
librosa.display.specshow(log_mel_spec, sr=sr, hop_length=160, x_axis="time", y_axis="mel", cmap="viridis")
plt.title("Log-Mel Spectrogram")
plt.colorbar(format="%+2.0f dB")
plt.show()
# 特徴量変換
inputs = processor(y, sampling_rate=sr, return_tensors="pt", padding=True)
input_values = inputs.input_values
# 推論
with torch.no_grad():
logits = model(input_values).logits # shape: (batch, time, vocab_size)
# デコード(文字列に変換)
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
print("Transcription:", transcription[0])
# 可視化③: ロジットのログ確率ヒートマップ
# (CTCのためlog_softmaxを適用)
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
# バッチサイズ 1 の場合、shape: (time, vocab_size)
log_probs = log_probs.squeeze(0).cpu().numpy()
plt.figure(figsize=(12, 6))
plt.imshow(log_probs.T, aspect="auto", origin="lower", cmap="viridis")
plt.title("Log Probability Heatmap (Token Index vs Time)")
plt.xlabel("Time Steps")
plt.ylabel("Token Index")
plt.colorbar()
plt.show()
# 音声ファイルのテキスト化
Transcription: HALLO I THANK YOU FOR LISTENING TO CASSAVORAD'S QUICK ENGLISH PROGRAMM AND THE ALSO YOSHI CASAHARA NOW LEAD US SPEAKING WITH OUR INTRODACTIONS THE NARRATORS ARE ERN FRANKE WILGOLAR RALLYWIS OSTINATE HELEN HALLEN AND YOU GOT AOCORO THIS OLDER PROGRAMM CONSISTS OF CASARA'S TRANSRATION AND HIGH SPEED RISENY METHODOROGY IN THIS ADE PROGRAMM YOU STUDY IN TWO WAYS ONE IS THE FIVE STEPRISEN PROGRAMM AND THE ADE ANIS THE FORSTEP SPEAKING PROGRAMM I HOPE YOU IMPROVE YOUR ENGLISH VERY QUICKLY AND USE IT FOR THE LAST OFYOUR LIFE
- ロジットのログ確率ヒートマップ
- モデル出力のロジットに log_softmax を適用し、各時間ステップでの各トークンの確率分布(対数値)をヒートマップで表示します。
CTCとWav2vec2.0の併用
CTC(Connectionist Temporal Classification)は、音声認識においてラベルの時間的な位置が不明確なデータに対して有効な損失関数のひとつです。
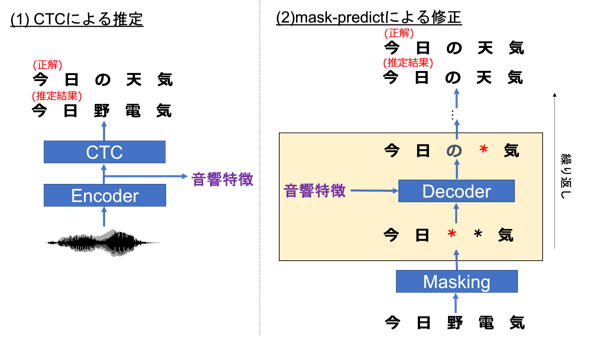
https://techblog.yahoo.co.jp/entry/2022060630304906/
- CTCの基本的な考え方
- 予測された出力系列と実際のテキストラベルを比較し、動的計画法を用いて文字ごとのアライメントを計算しながら、最も確率の高い経路を選択し、連続する同じ文字やブランク(空白)を考慮して最適な音素列を決定します。
"HELLO" を出力するために可能なフレームアライメント
H - E L - L O
H H E L L O O
H - E - L L - O
CTC は、全ての可能なアライメントの確率を合計し、それを最大化するように学習します。- CTC の目的
- 通常の音声認識タスクでは、音声データの長さと対応するテキストの長さが一致しないため、各入力フレームがどの文字に対応するかが明示されていません。例えば、音声特徴量の系列 $X=[x1,x2,…,xT]$(Tフレーム)に対し、対応するテキストが “HELLO”(5文字)だった場合、CTCはこの時間的なアライメント(文字とフレームの対応付け)を自動で学習します。
数式
- CTC の損失関数は、ある出力ラベル y(例:
"HELLO")に対して、入力系列Xの全ての可能なアライメントAの確率の総和を取ります。
$$P(y \mid X) = \sum_A P(A \mid X)$$
ここで A は "HELLO" に対応する全てのラベルシーケンスです。
- CTC 損失関数
- CTC の最適化では、負の対数尤度を最小化します。
- 動的計画法を用いて、可能な全アライメントの確率を計算し、尤度を最大化するように学習します。
$$\mathcal{L}_{CTC} = -\log P(y \mid X)$$
CTC の動的計画法による計算
- 前向きアルゴリズム(Forward Pass)
α(t, s)を 時刻tでラベルsに到達する確率 とする。α(t, s)を 遷移ルール に基づいて累積和で計算。
$$\alpha(t, s) = P(y_s \mid x_t) \cdot \left( \alpha(t-1, s) + \alpha(t-1, s-1) + \alpha(t-1, s-2) \right)$$
- 後向きアルゴリズム(Backward Pass)
- 同様に、逆方向から
β(t, s)を計算し、尤度を求めます。
- 同様に、逆方向から
CTC のメリットとデメリット
| メリット | デメリット |
|---|---|
| 入力の長さと出力の長さが一致していなくても適用可能 | 1文字単位での出力が困難(単語レベルの出力は難しい) |
| 音素や単語をフレームに直接アライメントする必要がない | 短い単語や単発の音に弱い(ブランク - を多用するため) |
| 学習がシンプルで、LSTM や Transformer などと併用しやすい | 連続的な音素の区切りが明確でないと誤認識が発生しやすい |
Wav2Vec2モデルに対してCTC損失を用いた学習の実装例
- CTC損失の計算
- CTC損失は、モデルの出力(logits)に対して
torch.nn.CTCLossを適用し、入力系列とターゲット系列の長さ情報(input_lengthsとtarget_lengths)を考慮して計算されます。 - CTC損失の計算はvscodeではなくGoogle Colaboratoryで実行しています。
- CTC損失は、モデルの出力(logits)に対して
import torch
import torch.nn as nn
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import librosa
# モデルとプロセッサのロード
model_name = "facebook/wav2vec2-large-960h"
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = Wav2Vec2ForCTC.from_pretrained(model_name)
# デバイス設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 音声ファイルの読み込み(16kHzにリサンプル)
audio_file = "/content/1-01 Cd1-1.m4a" # 音声ファイルパスを入力
y, sr = librosa.load(audio_file, sr=16000)
# 音声特徴量の抽出
inputs = processor(y, sampling_rate=sr, return_tensors="pt", padding=True)
input_values = inputs.input_values.to(device) # shape: (batch, time)
# ターゲットテキスト(例:"hello")の準備(tokenizer を直接使用)
target_text = "hello"
labels = processor.tokenizer(target_text, return_tensors="pt").input_ids # shape: (batch, target_length)
labels = labels.to(device)
# モデルの推論(CTC用のlogitsを取得)
outputs = model(input_values)
logits = outputs.logits # shape: (batch, time, vocab_size)
# CTCLoss の入力は (time, batch, vocab_size)
logits = logits.transpose(0, 1)
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
# 各サンプルの入力系列長(全バッチで同じ長さとする)
input_lengths = torch.full(size=(logits.shape[1],), fill_value=logits.shape[0], dtype=torch.long).to(device)
# ターゲット系列長
target_lengths = torch.tensor([labels.shape[1]]).to(device)
# CTCLoss の設定: blank トークンは pad_token_id を利用
ctc_loss_fn = nn.CTCLoss(blank=processor.tokenizer.pad_token_id, zero_infinity=True)
# CTC損失の計算
loss = ctc_loss_fn(log_probs, labels, input_lengths, target_lengths)
print("CTC Loss:", loss.item())CTC Loss: 879.3656005859375import matplotlib.pyplot as plt
import numpy as np
# --- 可視化①: 音声波形 ---
plt.figure(figsize=(12, 4))
plt.plot(y)
plt.title("Audio Waveform")
plt.xlabel("Samples")
plt.ylabel("Amplitude")
plt.show()
# --- 可視化②: log‑melスペクトログラム ---
# librosa.feature.melspectrogram は入力波形からメルスペクトログラムを算出
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=400, hop_length=160, n_mels=80)
log_mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
plt.figure(figsize=(12, 4))
librosa.display.specshow(log_mel_spec, sr=sr, hop_length=160, x_axis="time", y_axis="mel", cmap="viridis")
plt.title("Log-Mel Spectrogram")
plt.colorbar(format="%+2.0f dB")
plt.show()
Whisper
Whisperは、OpenAIが開発した大規模音声認識モデルで、教師あり学習を用いて大量の音声データで事前学習されています。従来の手法とは異なり、エンコーダ・デコーダ型のTransformerアーキテクチャを採用し、高精度な音声認識を実現しています。
詳しくは下記URLを参考にしてください。

主な特徴と数式
Whisperはエンコーダ・デコーダ型のTransformerモデルを基盤としており、音声認識のための自己教師あり学習と教師あり学習を組み合わせたフレームワークです。そのため、数式としては、以下の3つの要素が中心となります。
- エンコーダの処理(音声特徴の抽出)
- Whisperでは、音声データ $X$ を メルスペクトログラム に変換し、それをエンコーダに入力します。
$$H_{\text{enc}} = \text{Encoder}(X)$$
$X$は入力音声波形をメルスペクトログラムに変換したもの。$H_{enc}$はエンコーダによって抽出された特徴量。
- エンコーダの処理は、通常のTransformerのマルチヘッド・セルフアテンション(MHSA)を用いて、次のように定義できます。
$$Q = W_Q H_{\text{enc}}, \quad K = W_K H_{\text{enc}}, \quad V = W_V H_{\text{enc}}$$
$$\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V$$
$$H’_{\text{enc}} = \text{MHSA}(H_{\text{enc}})$$
- デコーダの処理(音声→テキスト変換)
- デコーダはエンコーダの出力 $H_{\text{enc}}$ をもとに、逐次的にテキストを生成します。
$$H_{\text{dec}} = \text{Decoder}(H_{\text{enc}}, Y_{\text{prev}})$$
$Y{prev}$ はデコーダの過去の出力(トークン列)。$H{dec}$ はデコーダの内部表現。
- デコーダの計算は、カジュアル・マスクド・マルチヘッド・アテンション(Masked MHSA)を含む次の式で表されます。
$$Q_{\text{dec}} = W_Q H_{\text{dec}}, \quad
K_{\text{dec}} = W_K H_{\text{dec}}, \quad
V_{\text{dec}} = W_V H_{\text{dec}}$$
$$\text{MaskedAttention}(Q_{\text{dec}}, K_{\text{dec}}, V_{\text{dec}}) =
\text{softmax} \left( \frac{Q_{\text{dec}} K_{\text{dec}}^T}{\sqrt{d_k}} + M \right) V_{\text{dec}}$$
- 損失関数(CTC or Cross-Entropy Loss)
- Whisperでは、トークン列の確率分布 を学習するために、クロスエントロピー損失(Cross-Entropy Loss) を使用します。
$$L = – \sum_{t=1}^{T} \sum_{y} P(Y_t = y | H_{\text{dec}}) \log P(Y_t = y | H_{\text{dec}})$$
また、ラベルの時間情報が不明確な場合(ノンオートグラフ音声認識)には、CTC(Connectionist Temporal Classification)損失を使用することも可能です。
$$L_{\text{CTC}} = – \sum_{(X,Y)} \log P(Y | X)$$
$P(Y∣X) $は、すべてのアライメント(時系列整列)に対する合計確率。
| 特徴 | 説明 |
|---|---|
| 多言語対応 | 英語、日本語、フランス語など、多くの言語の音声認識が可能。 |
| ノイズ耐性 | バックグラウンドノイズがある環境でも高精度な認識を実現。 |
| ゼロショット学習 | 未知の音声データに対しても高い汎用性を発揮。 |
| リアルタイム適用 | ストリーミング音声にも対応し、リアルタイム処理が可能。 |
| 翻訳機能 | 音声をテキスト化するだけでなく、異なる言語への翻訳も可能。 |
Whisperの実装
OpenAIが提供する whisper ライブラリを使用して、音声ファイルから文字起こし(Transcription)を行うコードを実装します。
Whisperのインストール
- Whisperを利用するために
whisperライブラリをインストールします。
pip install openai-whisper- FFmpegが必要なため、以下のコマンドでインストールしてください
pip install ffmpeg- macの場合
brew install ffmpegWhisperのPython実装
- 今回もCTCに続き、Google Colabを使って実装を行います。
- このコードはOpenAIのAPIを使わず、Whisperのオープンソース実装をローカル環境で動作させ、事前にダウンロードしたモデルを用いて音声認識を行います。
import whisper
# Whisperモデルのロード(例: "base" モデルを使用)
model = whisper.load_model("large")
# 音声ファイルのパスを指定
audio_path = "/content/1-28 Cd1-28.m4a" # 変換したい音声ファイルを指定
# 音声を文字起こし(Transcription)
result = model.transcribe(audio_path)
# 結果の表示
print("Transcription:")
print(result["text"])翻訳機能
- Whisperは音声をテキスト化するだけでなく、他の言語に翻訳 する機能も備えています。
result = model.transcribe(audio_path, task="translate")
print("Translated Text:")
print(result["text"])モデルの種類
- Whisperには、5種類のモデルがあり、精度と処理速度のバランスを考慮して選択可能です。
| モデル | パラメータ数 | 速度 | 精度 | メモリ使用量 |
|---|---|---|---|---|
| tiny | 39M | 速い | 低い | 少ない |
| base | 74M | 速い | 普通 | 少ない |
| small | 244M | 中 | 高い | 中 |
| medium | 769M | 遅い | 高い | 多い |
| large | 1550M | 遅い | 最高 | 非常に多い |
論文:『Robust Speech Recognition via Large-Scale Weak Supervision』

- 大規模データによる音声認識の飛躍的向上
- 本研究では、680,000時間の弱教師あり音声データを活用し、高精度な音声認識モデルを構築。従来の特定データセットに最適化されたモデルとは異なり、ゼロショットでも高い汎用性を発揮することを示した。特に、多言語・マルチタスク学習により、単言語モデルを超える性能を達成。データ量が16倍増えるごとにWERが半減するスケーリング法則も確認され、大規模データの活用が音声認識の精度向上に不可欠であることが明らかになった。
- Zero-shot性能と頑健性の向上
- Whisperモデルは、事前学習のみで高精度な音声認識を実現し、ゼロショットで従来の教師ありモデルと同等以上の性能を発揮。多言語・雑音環境下でも高い精度を維持し、追加の微調整なしで幅広いデータセットに適応可能。さらに、データ量が16倍増えるごとにWERが半減(r²=0.83)する関係を確認し、スケールの拡大が精度向上の鍵であることを実証。長時間音声の認識でも商用ASRと競争力があり、従来のモデルの限界を突破する新たなアプローチを提示した。
学習の振り返りと次回予告
今回の学習では、自然言語処理(NLP)、時系列データ解析、音声認識におけるTransformerの応用について学びました。NLPでは、Self-Attentionによる文脈理解や事前学習モデルの活用を理解し、時系列データ解析では、LSTMとTransformerのハイブリッド型モデルを用いたアプローチを学びました。これにより、計算コストを抑えつつ長期依存関係を捉える手法の重要性を確認することができました。
音声認識では、Wav2Vec 2.0のように生の波形から直接学習するモデルや、Whisperのような大規模音声認識モデルの仕組みを学び、Transformerが進化する中でどのように適用されてきたのかを考察しました。さらに、ノイズ除去やデータ圧縮の最適化に触れ、精度と計算効率のバランスを取る手法についても理解を深めることができたかと思います。
次回は、強化学習の実装を深掘りします。Q学習、DQN、PPO、Actor-Critic法などの代表的なアルゴリズムを学び、その応用方法を探ります。また、時系列データ解析と強化学習を組み合わせた世界モデル(World Models) に着目し、Transformerを活用した環境モデリングやポリシー予測モデルの仕組みを解説します。さらに、金融市場のポートフォリオ管理やリスク予測などの応用例を通じて、強化学習と時系列データの関係について実践的な視点から考えていきます。


コメント