この記事のゴール
本記事では、以下の“判断軸”を最短時間で獲得します。
- RLHF と DPO のどちらを使うべきか、一発で決められる
- LoRA を中心とした PEFT の選び方が分かる
- GPU メモリの制約下で最適な戦略が立てられる
- bfloat16 / fp16 の違いと使いどころが理解できる
🧭 目次
- はじめに
- LLM 微調整の全体像
- RLHF と DPO の最適選択
- PEFT(軽量微調整)の選択マトリクス
- LoRA がデファクトになった理由
- bfloat16 / fp16 / fp32 の違いと選択
- GPU が小さい場合に使う戦略一覧
- まとめ:判断軸のクイックリファレンス
- 今後の拡張トピック
はじめに
LLMの登場以降、LLM微調整のための手法は爆発的に増えました。
しかし実務では、「どれを選べばいいか」の判断が非常に難しくなっています。
この記事は、
研究の深い背景ではなく、実務での意思決定を最短にすること
を目的にしています。
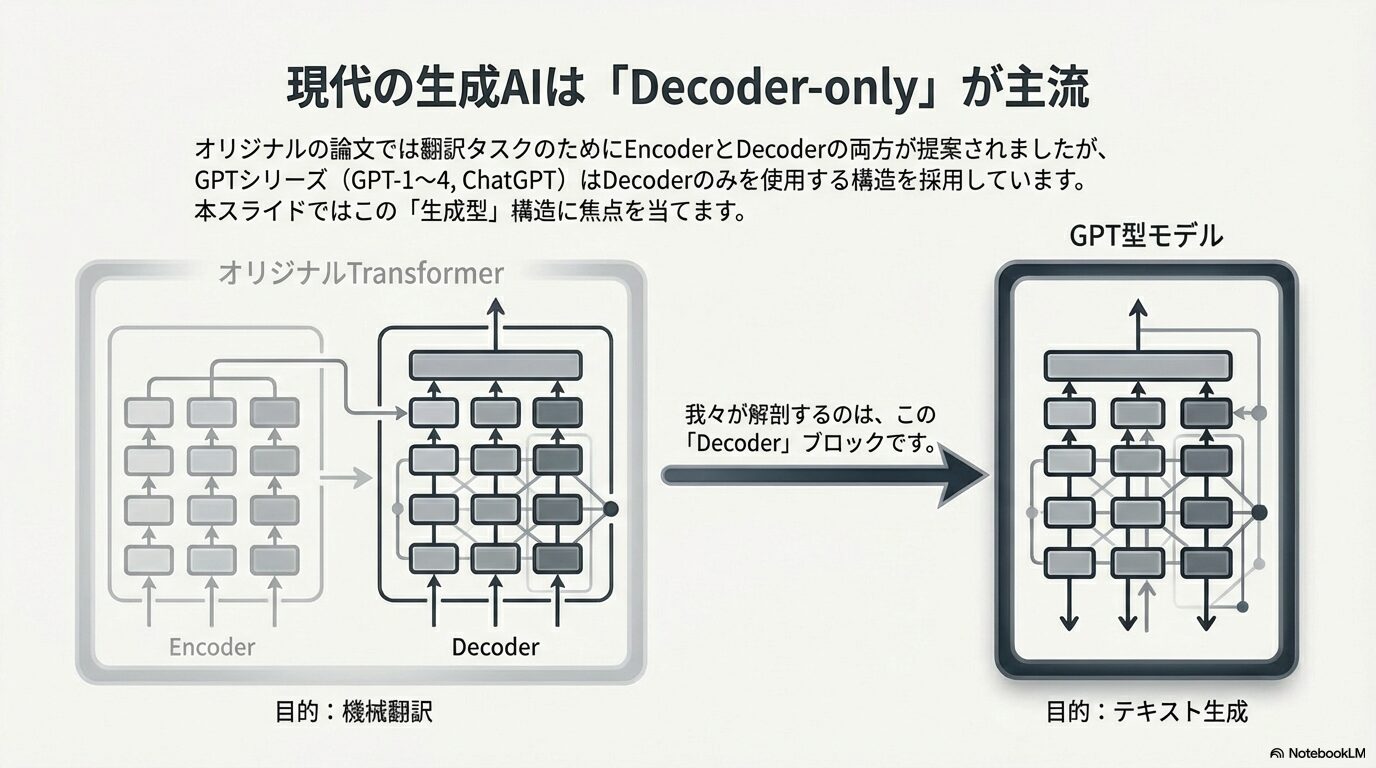
LLM 微調整の全体像
LLM 微調整の方法は大きく次の3層に分類できます。
■ 1. 事前学習モデルの選択
- Llama 系
- Mistral
- Qwen
- Mixtral
- Gemma
最初の選択で実務の 8 割が決まると言われるぐらい重要。
※上記はオープンソースモデルを例として挙げています。
■ 2. 微調整方式
A. RLHF 系(探索重視)
- 人間による報酬モデル
- 強化学習でポリシー改善
- 大規模データ・GPU 必須
B. DPO 系(効率重視)
- 好ましいペアを比較学習
- 報酬モデル不要
- 軽いタスク向き
■ 3. パラメータ効率化(PEFT)
- LoRA
- QLoRA
- Prefix Tuning
- IA³
- Adapters
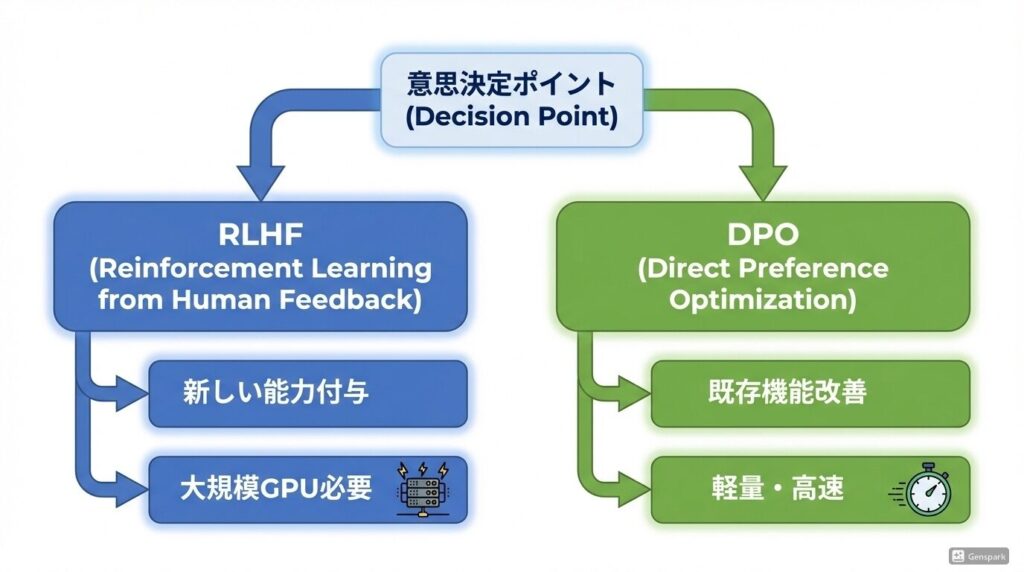
RLHF と DPO の最適選択
実務判断のコアは以下の3行に集約できます。
新しい能力を付与したい → RLHF
例:
- モデルに「倫理判断能力」そのものを与えたい
- モデルの行動方針を根本から変えたい
既存機能の改善・挙動修正がしたい → DPO
例:
- 出力の一貫性を上げたい
- 敬語スタイルの安定性を高めたい
GPU が弱い or 期間が短い → DPO 一択
PEFT の選択マトリクス
| 課題 | 最適解 |
|---|---|
| 基本的な軽量微調整 | LoRA |
| 多タスクを同時に扱いたい | Adapters |
| 推論速度を重視 | IA³ |
| 既存プロンプトの強化 | Prefix Tuning |
| VRAM が非常に小さい | QLoRA |
LoRA がデファクトになった理由
LoRA は以下の点で圧倒的に優れています。
- 学習パラメータ量が少ない
- 通常の学習と互換性がある
- 実装が容易
- 多くのモデルが最適化済み
結論:
迷ったら LoRA。例外は少ない。
数値フォーマット:bfloat16 / fp16 / fp32 の判断
| フォーマット | 特徴 | 使いどころ |
|---|---|---|
| fp32 | 精度最良 / メモリ重い | 開発初期、古い GPU |
| fp16 | 軽いがオーバーフローリスク | 特に理由がなければ使わない |
| bfloat16 | fp32 と同じ指数部 / 安全 | 標準推奨(A100, H100, L40 など) |
結論:
新しい GPU なら bfloat16 一択。
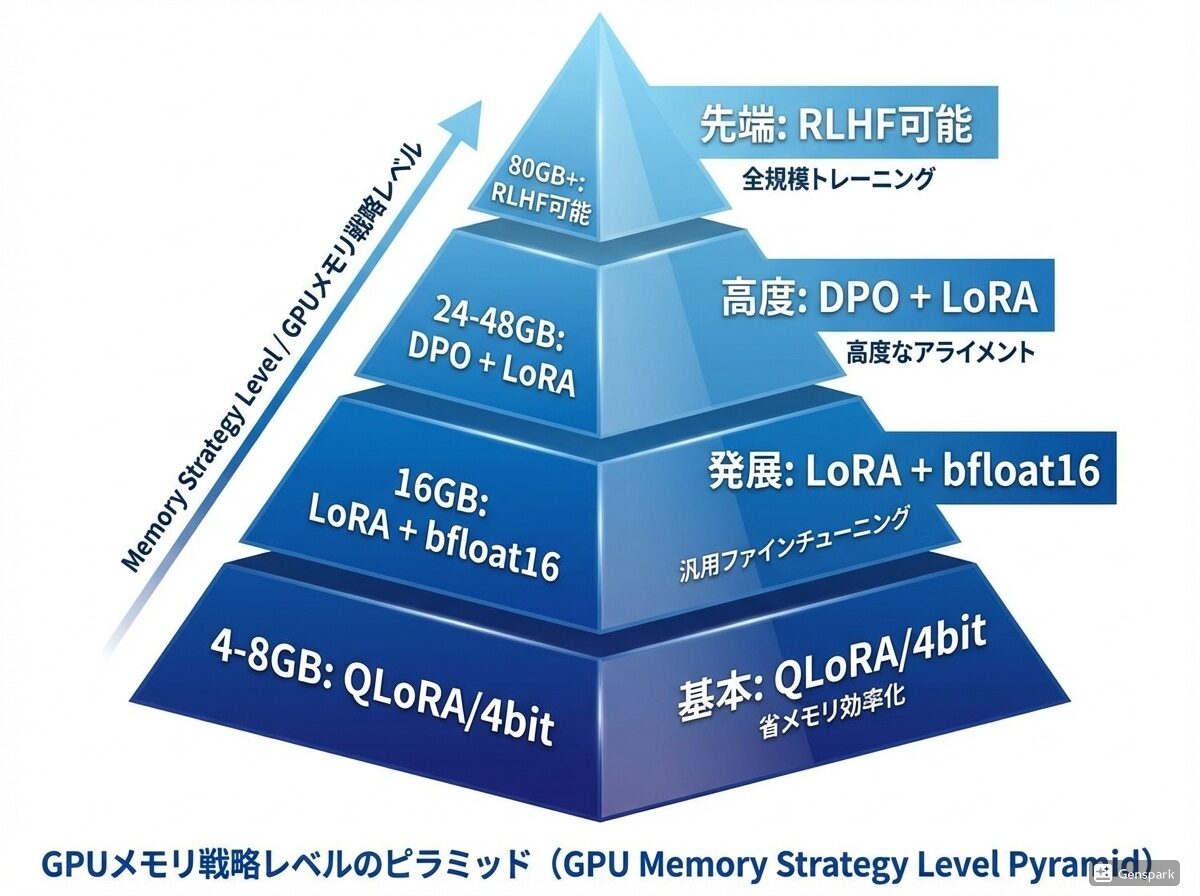
GPU が小さいときの戦略リスト
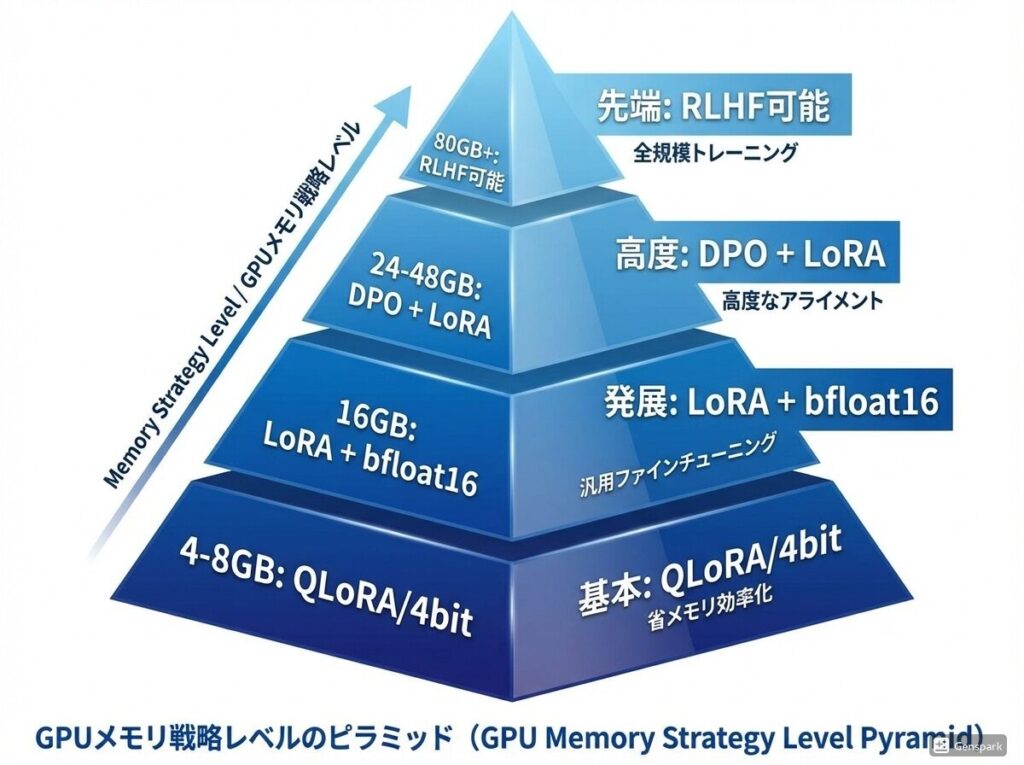
| VRAM | 推奨戦略 |
|---|---|
| 4GB〜8GB | QLoRA / 4bit quantization |
| 16GB | LoRA + bfloat16 |
| 24GB〜48GB | DPO + LoRA |
| 80GB〜 | RLHF 可能 |
最後のまとめ:実務の判断軸
- 新規能力 → RLHF
- 既存改善 → DPO
- 迷ったら PEFT = LoRA
- GPU が小さい → QLoRA
- 新しい GPU → bfloat16
以上の判断軸さえ手元にあれば、もう膨大な手法の比較検討で時間を浪費することはありません。 技術選定という「迷い」をこれらの鉄則に任せることで、皆さんの貴重なリソースを「どのようなデータを学習させるか」「どんな独自価値を生み出すか」という、最もクリエイティブな領域に集中させることができます。 まずは手元の環境に合った戦略を選んでみることが大事であると言えるでしょう。


コメント