
FineWebと学習効率の最前線
2024年、Hugging Faceが公開したFineWebは、データセット設計に新しい見方を持ち込みました。理論で方針を決めるだけでなく、実験で一つずつ確かめながら最適化していく。その考え方が、FineWebの大きな特徴です。
1. FineWebの戦略:経験的アプローチ
1.1 従来のアプローチとの違い
従来のアプローチ
- 「多様性は良い」「重複排除は必須」「品質フィルタは重要」といった仮説を前提に設計する
- 各フィルタの効果は、どちらかというと定性的に見積もられていた
FineWebのアプローチ
- 実際に検証しながら最適な組み合わせを発見する
- 数十の小規模モデルで実験する
- 結果から最適なパイプラインを逆算する
- 各フィルタの効果を定量的に測る
1.2 大規模なアブレーション実験
FineWebの面白さは、設計思想だけではありません。どのフィルタが効くのかを、かなり大きな規模で検証している点にあります。
実験の規模
- Llamaアーキテクチャの小規模モデルを70個以上学習
- 各モデルで異なるパイプラインを適用する
- 重複排除の有無
- 言語フィルタリングの閾値
- 品質フィルタリングの厳しさ
- コンテンツフィルタリングの有無
- その他の組み合わせ
結果として、各段階がモデル性能に与える影響を定量化できた
2. FineWebの成果:18.5Tトークンと学習効率
2.1 最終規模と特性
前例のない規模:18.5Tトークンの抽出
FineWebは、Common Crawlを土台にしつつ、Webテキストに強く寄せた大規模データセットです。
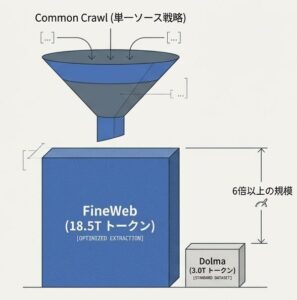
FineWeb の規模
- ソース: Common Crawlのみ
- 処理後: 18,500Bトークン = 18.5Tトークン
特徴
- 圧倒的な規模を持つ
- Dolma(3.0T)の6倍以上
- 単一ソース戦略を取っている
- ウェブテキストに特化しやすい
- そのぶんパイプライン最適化に集中できる
- 70回以上の実験結果に基づく経験的最適化がある
- 理論的予測ではなく実測値を重視している
2.2 学習効率の実証
学習効率は、訓練初期の伸び方を見ると分かりやすいです。
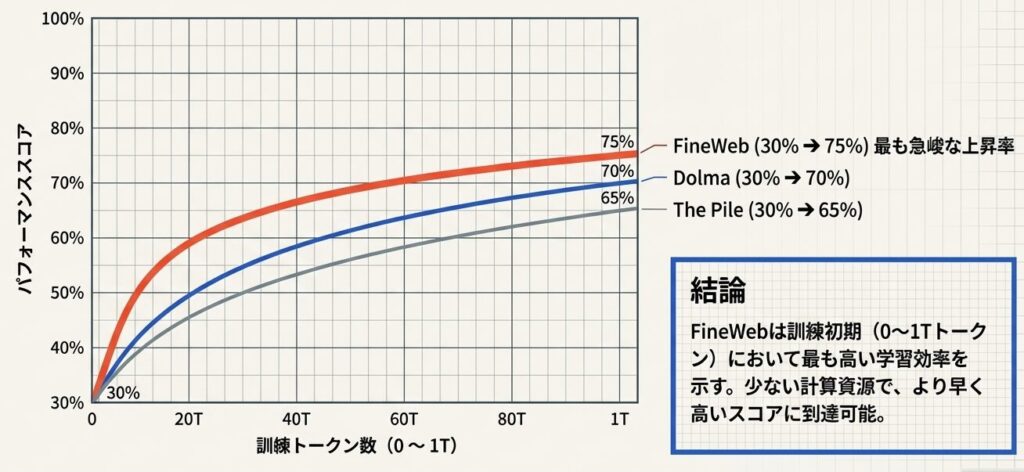
- FineWeb: 0トークン〜1Tトークンで 30% → 75%
- 上昇率が最も急峻
- Dolma: 同期間で 30% → 70%
- 上昇はやや緩い
- The Pile: 同期間で 30% → 65%
- さらに緩い
この比較から、FineWebで学習したモデルは訓練初期から一貫して高いスコアを出しやすく、学習効率が高いと読み取れます。
3. FineWeb-edu:教育的テキストへの特化
3.1 構成と特徴
FineWeb-eduは、FineWebの中から「学ぶのに向いた文章」を集めた派生版です。一般的なWebテキストよりも、説明の流れがはっきりしている点が特徴です。
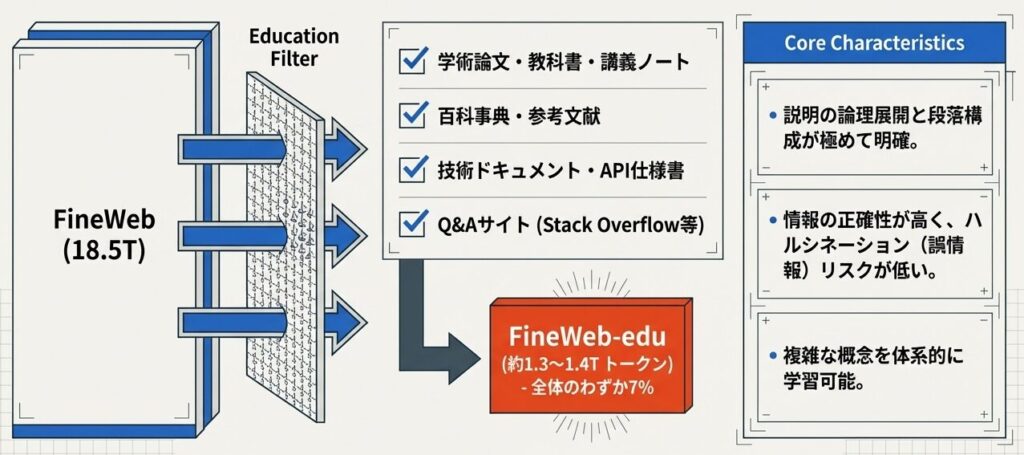
FineWeb-edu の特徴
- ソース: FineWebの全18.5Tトークンから、教育的・学術的なテキストを抽出している
- 規模: 約1.3〜1.4Tトークン(FineWebの約7%)
選択基準
- 学術論文・教科書・講義ノート
- 百科事典・参考文献
- 技術ドキュメント・API仕様書
- Q&Aサイト(Stack Overflowなど)
- 学習教材
特徴
- 段落構成や論理の流れがはっきりしている
- 正確性が重視され、誤情報が比較的少ない
- 複雑な概念や知識を体系的に説明している
3.2 パフォーマンス比較
ベンチマーク比較(論文で報告された傾向を見やすく整理)
| ドメイン | FineWeb | FineWeb-edu | 性能差 |
|---|---|---|---|
| MMLU | 75% | 82% | +7% |
| HumanEval | 68% | 76% | +8% |
| HellaSwag | 85% | 82% | -3% |
| ARC Challenge | 72% | 81% | +9% |
傾向
- 知識が必要なタスクでは FineWeb-edu が優位になりやすい
- 論理、数学、科学的推論など
- 一般的な会話や感情理解では FineWeb のほうが優位な場合がある
- ここはトレードオフになる
3.3 推奨用途
FineWeb-edu が最適
- 研究者用LLM、医療AI、学問的タスク
- 知識集約的なアプリケーション
- 推論・問題解決重視のモデル
オリジナル FineWebが最適
- チャットボット、コード生成特化
- 創作・文学的生成
- カジュアルな対話システム
4. FineWeb2:次世代への展望
4.1 次世代の多言語パイプライン
FineWeb2は、FineWebの流れを受けて提案された次世代のデータ処理パイプラインです。FineWebの「英語中心の経験的最適化」に対して、FineWeb2は多言語への一般化を強く意識している点が特徴です。
FineWeb2 の計画
- 発展方向: FineWebの設計思想を、より広い言語圏に拡張する
- 規模: 約20TB、1000以上の言語を対象にした多言語コーパス
改善予定項目
- より厳格な品質フィルタ
- 新しいフィルタリング技術の組み込み
- より細かいアブレーション実験
- 非英語言語への対応拡大
期待される効果
- 言語ごとの前処理を一律ではなく最適化しやすくなる
- 非英語コーパスでも品質と多様性の両立を狙いやすい
- 多言語モデルの学習基盤として使いやすい
4.2 言語対応の拡大
言語対応計画
- FineWeb: 主に英語、他言語はごく少量
- FineWeb2: 1000以上の言語を対象に、各言語に合わせたパイプライン調整を行う
- 結果として、より多様で汎用性の高いモデルを目指す
5. FineWebファミリーの位置づけ
5.1 データセット進化の系譜
FineWebを単体で見るより、C4やThe Pile、Dolmaの流れの中に置くと役割がはっきりします。各世代が何を最優先にしていたかを見ると、設計の変化が追いやすくなります。
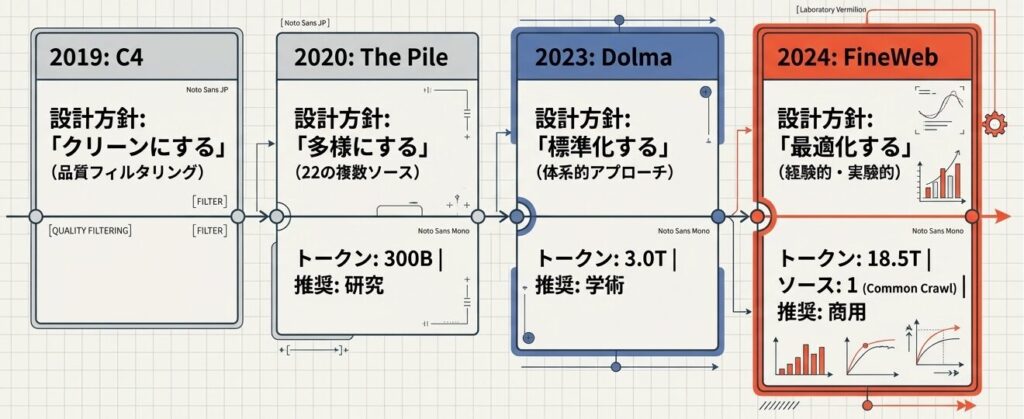
2017〜2024年の進化の軌跡
- 2017年: Transformer登場
- 2019年: C4(品質フィルタリング)
- 2020年: The Pile(多様性)
- 2023年: Dolma(体系化)
- 2024年: FineWeb(経験的最適化)
各世代のフォーカス
- C4: 「クリーンにする」
- The Pile: 「多様にする」
- Dolma: 「標準化する」
- FineWeb: 「最適化する」
Core Insight: データセットの歴史は「定性的な収集」から「実験的な最適化」への移行の歴史である。
5.2 比較サマリー
| 項目 | The Pile | Dolma | FineWeb |
|---|---|---|---|
| トークン数 | 300B | 3.0T | 18.5T |
| ソース数 | 22 | 複数 | 1(Common Crawl) |
| 設計方針 | 多様性 | 透明性 | 効率 |
| 最適化方法 | 定性的 | 体系的 | 実験的 |
| 推奨用途 | 研究 | 学術 | 商用 |
6. 実務での活用指針
6.1 FineWeb利用のケース
FineWebは、英語中心の大規模モデルを本格的に作るときに特に強みがあります。
適している場面
- 商用LLMの本格開発
- 大規模モデル(10B+)の訓練
- 学習効率を最大化したい場合
- 単一言語(英語)モデル
利点
- 学習効率が高い
- 18.5Tという大規模さがある
- 実験的に最適化されている
- 商用利用しやすい
6.2 モデルサイズ別の推奨
モデルサイズ別の最適選択
-
7Bパラメータ
- 推奨: FineWeb-edu または The Pile
- 理由: 小規模では汎用データセットで十分なことが多い
-
13Bパラメータ
- 推奨: FineWeb または FineWeb-edu のミックス
- 理由: バランスを取りやすい
-
70Bパラメータ
- 推奨: FineWeb + 専門データ
- 理由: 規模があるため多様性の効果が出やすい
-
100B+パラメータ
- 推奨: FineWeb2(公開時) + ドメイン特化データセット
- 理由: 大規模モデルでは多様性で精度が伸びやすい
データセットはもはや「集めるもの」ではなく、「実験的に精製する」時代へ。 用途と規模に合わせた最適なレシピの選択が、モデル競争力を決定づける。
📖 参考文献
主要論文
- Penedo, G., et al. (2024): “The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale”, arXiv
- Penedo, G., et al. (2025): “FineWeb2: One Pipeline to Scale Them All — Adapting Pre-Training Data Processing to Every Language”, arXiv
補足
- FineWeb-Edu は FineWeb の論文内で提案された教育向け派生データセットです。
- 本文中の FineWeb-edu の比較は、その公開実験で報告された傾向を要約したものです。
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線(この記事)
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ:
- ブログA:基礎理論編 – Transformerの基本理論
- ブログB:実装詳細編 – 各レイヤーのデータ要件
前の記事: Dolmaと前処理の体系化 次の記事: データセット前処理戦略の比較分析

コメント