
スケール則とは何か?LLM 性能予測の基礎
大規模言語モデル(LLM)が急速に進化してきた背景には、単に「モデルを大きくしたから」というだけでは説明しきれない考え方があります。重要なのは、性能の伸び方をある程度予測しながら、モデル、データ、計算資源の配分を決めるという発想です。
この考え方を支えるのが、今回の主題であるスケール則(Scaling Law)です。
1. この記事で学べること
- スケール則の定義と、何を予測しているのか
- パラメータ数、データセットサイズ、計算資源の関係
- なぜ小さな実験から大きなモデルの見通しを立てられるのか
- どこまで信頼でき、どこから注意が必要なのか?
1-1. 対象読者
- AI に興味があるが、スケール則を体系的に学びたい人
- LLM を導入・活用する判断を下す必要がある経営者・PM
- 研究者だが、スケーリングの全体像を把握したい人
2. スケール則とは何か?
スケール則とは、LLM の性能が、投入する資源を増やすことで予測しやすい形で改善していくという経験則です。
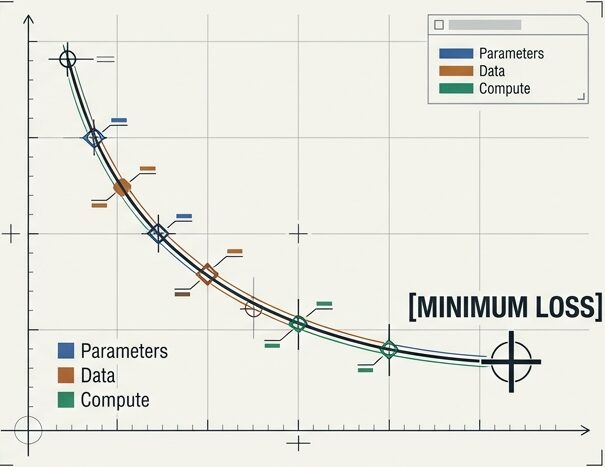
ここでいう「性能」は、主に事前学習における損失(Loss)で見ます。損失は小さいほどよく、次の単語をどれだけ正確に予測できるかの指標として使われます。
スケール則が扱うのは、主に次の 3 つです。
- モデルのパラメータ数(N)
- 学習に使うデータセットサイズ(D)
- 学習に使う計算資源(C)
この 3 つのどれかを増やすと、損失が下がる傾向があります。しかも、その下がり方がある程度規則的なので、小さな実験結果から大きな設定の性能を見積もりやすくなります。
たとえば、100M パラメータのモデルと 1B パラメータのモデルを比べると、単純には後者のほうが高性能になりやすいです。ただし、データが足りないままモデルだけ大きくしても、期待したほど伸びないことがあります。ここに「ただ大きくすればよいわけではない」という重要な注意点があります。
スケール則の目的 次の単語をどれだけ正確に予測できるか(LOSSの最小化)。
3. スケール則を支える 3 つの要素
3-1. パラメータ数(N)とは何か?
パラメータは、モデルが内部で持つ調整可能な値です。Transformer モデルでは、埋め込み層、Attention 層、FFN 層などの重みがこれに当たります。
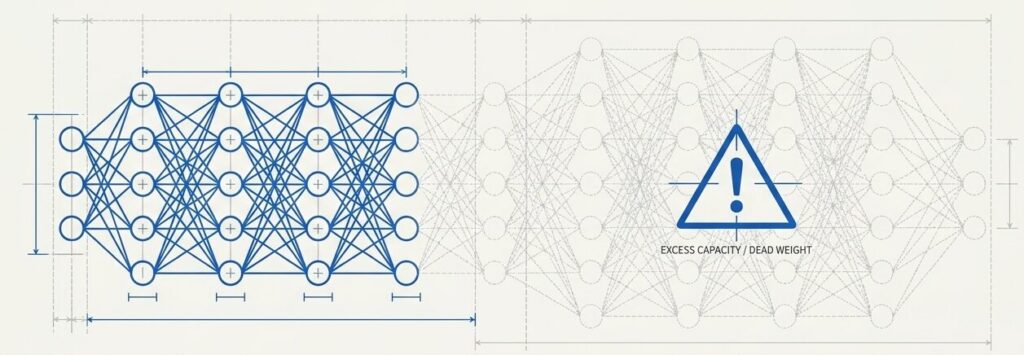
パラメータ数が増えると、モデルはより複雑な関係を表現しやすくなります。たとえば、短い文脈だけではなく、少し長い依存関係や、表現の揺れを吸収しやすくなります。
ただし、ここでよくある誤解があります。パラメータ数は「多ければ多いほど良い」わけではありません。学習データや計算量が追いつかなければ、モデル容量だけが余ってしまい、効率が悪くなります。
具体例:
| モデル | 発表年 | パラメータ数 |
|---|---|---|
| GPT-1 | 2018年 | 1.2億個 |
| GPT-2 | 2019年 | 15億個 |
| GPT-3 | 2020年 | 1750億個 |
| GPT-4 | 2023年 | 非公開(さらに大規模) |
この推移を見ると、モデル規模が短期間で急拡大してきたことが分かります。ただし、年ごとの単純な倍率比較だけで性能を断定するのは正確ではありません。学習手法、データ品質、評価方法も同時に変わるためです。
戦略的注意点 「多ければ多いほど良い」は誤り。学習データや計算量が追いつかなければ、モデル容量が余り、ただの非効率な「重り」になる。
3-2. データセットサイズ(D)とは何か?
これはモデルが学習する文量です。実務感覚で言えば、「どれだけ多くの教科書や会話例を読ませたか」に近いです。
重要なのは、単なるファイル容量ではなく、トークン数で考えることです。トークンはテキストを分割した最小単位で、単語やサブワードに相当します。
データ量が増えると、モデルは文法や語彙だけでなく、より幅広い表現パターンに触れられます。逆に、同じ規模のモデルでも、データが偏っていると学習結果が安定しません。
具体例:
| モデル | 学習トークン数 |
|---|---|
| GPT-3 | 約3000億トークン |
| Chinchilla(DeepMind, 2022年) | 約1.4兆トークン |
| Llama 2(Meta, 2023年) | 約2兆トークン |
3-3. 計算資源(C)とは何か?
これは学習に使う総計算量です。モデルを訓練するには、同じデータを何度も見ながら大量の演算を繰り返します。その積み上げ全体が計算資源です。
計算量は FLOPs という単位で表されます。ここで混同しやすいのは、FLOPs が「必要な演算総量」を指すのに対して、FLOPS は「1 秒あたりの処理速度」を表す点です。
計算資源を増やせば、より大きなモデルやより多くのデータを扱えます。ただし、計算資源だけ増やしても、モデルとデータのバランスが悪ければ効率は上がりません。
具体例:
- GPT-3の学習に必要な計算量: 約 $3.14 \times 10^{23}$ FLOPs
- これを「PF-days(ペタフロップス・日)」という単位で表すと、GPT-3は約341 PF-daysの計算量を必要としました
4. 3 つの要素と性能の関係はどう見ればよいか?
スケール則の核心は、N、D、C を増やしたときの損失の下がり方が、比較的規則的だという点です。
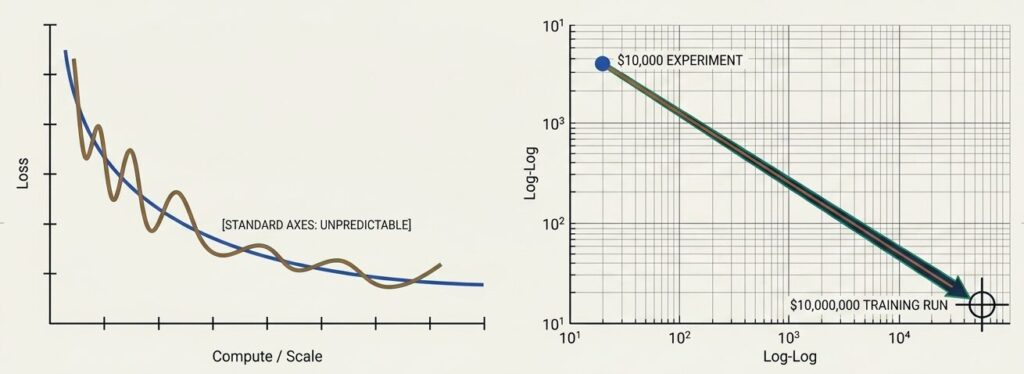
N(パラメータ数)、D(データセットサイズ)、C(計算資源)のいずれかを増やすと、Test Loss が両対数グラフ上でおおむね直線的に減少する。
両対数グラフとは、縦軸も横軸も対数目盛にしたグラフです。通常のグラフでは、リソースを 2 倍にしたときの伸びが曲線的に見えますが、対数グラフにすると関係が直線に近づくことがあります。
この見え方が重要なのは、小規模実験の結果を使って、大規模設定の性能を見積もれるからです。もちろん完全に当たるわけではありませんが、無計画に大規模学習へ突っ込むより、はるかに現実的です。
たとえば、実験予算が限られているときに「モデルを少し大きくした場合」と「データを少し増やした場合」のどちらが効きそうかを比較できます。これがスケール則の実務的な強みです。
戦略的価値 限られた予算で行う「小規模な実験」の結果から、無計画に突っ込むことなく「大規模な設定」の性能を正確に見積もることができる。
5. なぜスケール則は LLM 開発に革命をもたらしたのか?
スケール則の価値は、性能改善を勘ではなく見積もりで進めやすくしたことにあります。
LLM の学習には、大きな計算コストがかかります。モデルが大きくなるほど、失敗したときの損失も増えます。そのため、事前に小さな実験から見通しを立てられることは、技術的にも経営的にも重要です。
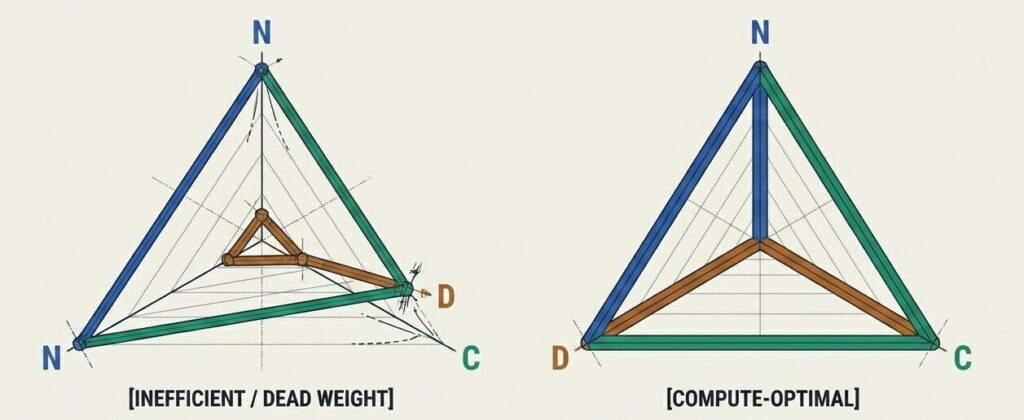
計算資源(C)とパラメータ(N)だけを増やしても、データ(D)が少なければ構造は崩壊する。 モデルを大きくすること自体が目的化すると、コストだけが増大し、期待した性能は得られない。
たとえば、同じテーマで 2 つの学習設定を比べるとします。
- 設定 A: モデルは大きいが、データが少ない
- 設定 B: モデルはやや小さいが、データを十分に確保している
このとき、どちらが有利かは直感だけでは判断しにくいです。スケール則の考え方があると、少なくとも「どの要素がボトルネックになっていそうか」を整理できます。
この予測可能性があるからこそ、研究開発では「まず小さく試す」「その結果から次の規模を決める」という進め方がしやすくなりました。
6. よくある誤解は何か?
スケール則を学び始めると、次のような誤解が起きやすいです。
6-1. パラメータ数を増やせば必ず勝てるのか?
答えはいいえです。データや計算量が足りなければ、モデル容量を持て余します。むしろ、学習効率が悪くなりやすいです。
6-2. スケール則は絶対に成り立つのか?
これもいいえです。スケール則は法則というより経験則です。学習データの質、アーキテクチャ、最適化手法、評価方法が変わると、見え方も変わります。
6-3. 失敗はどこで起きやすいのか?
現場では、モデルを大きくすること自体が目的化しやすいです。すると、データ整備や学習設定の見直しが後回しになります。結果として、コストだけ増えて性能が伸びない、という失敗につながります。
この失敗を避けるには、「何を増やすのか」だけでなく、「何が足りていないのか」を先に見る必要があります。
7. まとめ
スケール則は、LLM の性能がリソース投入に対して予測可能に変化していくという経験則です。
要点を整理すると次の通りです。
- パラメータ数、データセットサイズ、計算資源の 3 つが基本要素になる
- これらの関係は、両対数グラフで見ると直線に近づくことがある
- 小規模実験から大規模設定の見通しを立てやすくなる
- ただし、スケール則は万能ではなく、データ品質や学習条件の影響を受ける
最初の理解としては、「モデルを大きくすればよい」ではなく、「どの資源を、どの順番で、どの程度増やすと効率がよいかを考えるための道具」と捉えると分かりやすいです。
8. 今回のブログの考察
スケール則は、LLM の性能が単純な気合いや規模拡大ではなく、パラメータ数、データセットサイズ、計算資源のバランスで決まっていくことを教えてくれます。今回の記事で見たように、重要なのは「どれを大きくするか」だけではなく、「何が足りていないのか」を見極めることです。モデルだけを大きくしても、データや計算が追いつかなければ期待した伸びは得にくく、逆に小さな実験でも、配分の考え方があれば次の一手をかなり具体的に考えられます。
実務で大切なのは、スケール則を万能の答えとして扱わないことです。これはあくまで経験則であり、データ品質や学習条件が変われば結果も揺れます。それでもなお有用なのは、議論を「なんとなく強そう」から「どこを増やせばよいか」に進めてくれるからです。つまりスケール則は、LLM 開発を感覚論から少しずつ引き離し、判断の筋道をつくるための考え方だと言えます。
参考文献
- Kaplan, J. et al. (2020). “Scaling Laws for Neural Language Models.” arXiv:2001.08361
- Hoffmann, J. et al. (2022). “Training Compute-Optimal Large Language Models.” arXiv:2203.15556
- Brown, T. et al. (2020). “Language Models are Few-Shot Learners.” arXiv:2005.14165
このシリーズの案内
次の記事: A-2: FLOPsと計算資源の理解
シリーズホーム: LLM スケーリング則完全ガイド


コメント