はじめに
Vision Language Model(VLM)の歴史において、一つの分岐点とも言える論文が存在します。
2023年版の 「Improved Baselines with Visual Instruction Tuning (LLaVA-1.5)」です。
【この論文が重要な理由】
✅ オープンソースでSoTA性能を実現
✅ わずか8枚のA100 GPUで1日で訓練完了
✅ 1.2Mのコンパクトなデータで数億データセット以上の成果
✅ シンプルながら汎用的な設計思想
✅ その後のVLM発展(包括的なRAGシステム)の基盤本記事では、この論文の核心を解説し、今回紹介するプロジェクト(VLM + LoRA +Visual RAG + Agentic RAG)がいかにこの研究を拡張したのか を説明します。
プロジェクト詳細はGitHubで公開していますので、ご参考にしてみてください。
- https://github.com/Shion1124/vlm-lora-agentic-rag
- https://huggingface.co/Shion1124/vlm-lora-agentic-rag
LLaVA-1.5 論文の全体像
研究課題:「概念実証」から「実用レベル」へ
LLaVA v1(2023年4月)は、画像とテキストを同時に処理する大規模マルチモーダルモデルが、シンプルな構成で実現可能であることを証明した概念実証でした。
しかし、その後のベンチマーク評価で以下の課題が浮かび上がりました。
【LLaVA v1の弱点】
❌ VQA(視覚質問応答)のような短答タスクが苦手
❌ 文字認識(OCR)の精度が低い
❌ 推論が必要な複雑なタスクで他のモデルに劣後
❌ トレード: 対話の自然さ vs 事実に基づいた正確性2023年10月に発表されたLLaVA-1.5は、これらの課題をシンプルながらエレガントな改良で解決しました。
成果:11ものベンチマークでSoTA達成
【LLaVA-1.5の実績】
✅ GQA, MME, TextVQA, POPE など で最先端
✅ GPT-4 Vision(当時)との比較でも遜色なし
✅ データ効率: 1.2Mで数億データに匹敵
✅ 訓練効率: 8ノードのA100で24時間以内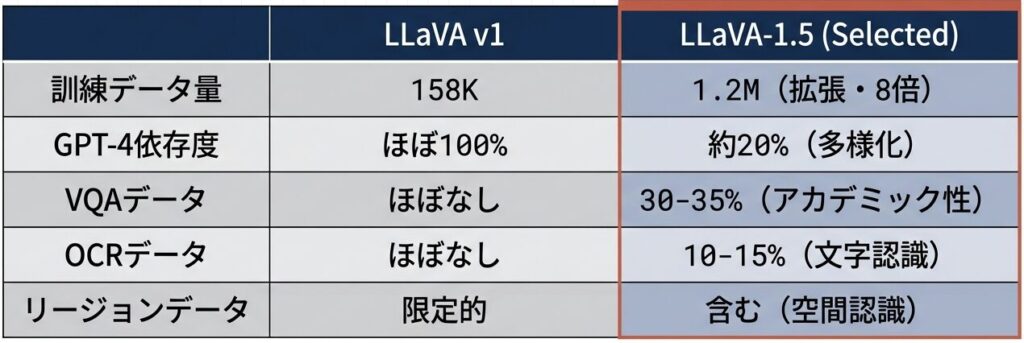
LLaVA-1.5は数億画像を学習したモデル(Qwen-VL等)に対し、わずか0.1%未満のデータ量(1.2M)で11のベンチマークにおいてSoTAを達成。「タスクに対応できる密度の高いデータ」が圧倒的な性能を生む。
4つの重要な改良点
改良1: コネクタの強化(Linear → 2層MLP)
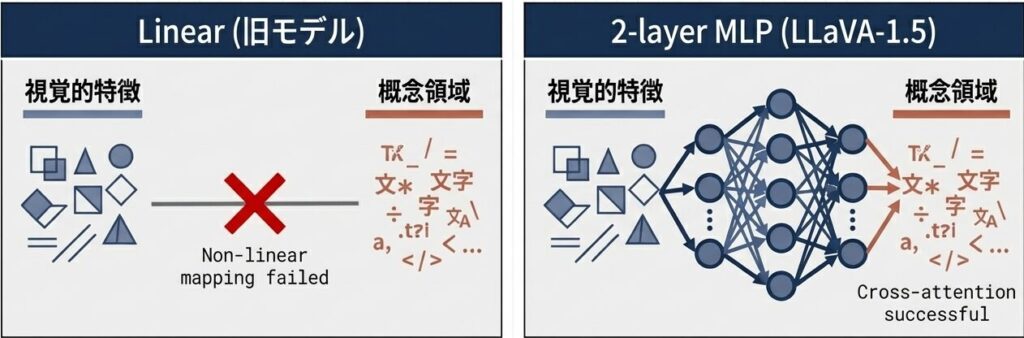
【改良前(LLaVA v1)】
CLIP出力 →【Linear】→ LLM入力
(単一層)
【改良後(LLaVA-1.5)】
CLIP出力 →【MLP(2層)】→ LLM入力
(GELU活性化)
【効果】
- 視覚特徴と言語空間の複雑なマッピングが可能
- 非線形な変換により、CLIPの特徴をLLMに最適な形に「翻訳」
- マルチタスク学習での性能向上なぜこれが効くのか?
画像から抽出される視覚的特徴(色、形、テクスチャ)と、言語モデルが期待する概念領域には、単純な線形関係では表現困難な複雑な対応関係があります。MLPの非線形性がこの「表現ギャップ」を埋め、結果として、より深いマルチモーダル理解が可能になりました。
視覚的特徴とテキストの概念領域には複雑な対応関係が存在する。単純な線形(Linear)から非線形性を持つ2層MLPに変更することで、モダリティ間の深い相互理解(Cross-attention)が可能になった。
改良2: 入力解像度の大幅向上(224px → 336px)
高解像度化による幻覚(Hallucination)の抑制
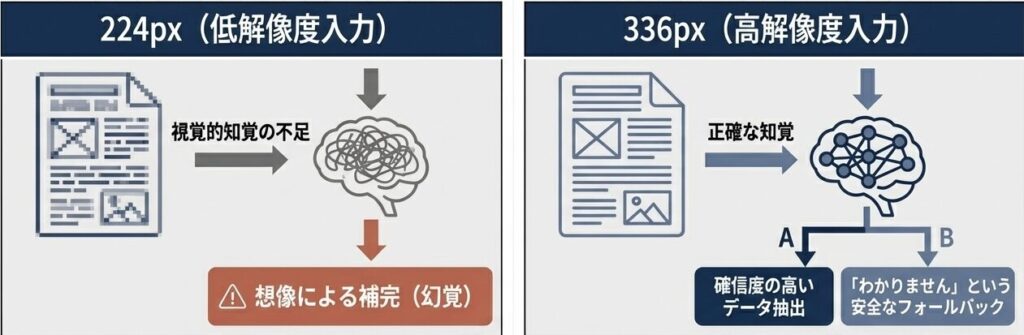
【解像度向上のインパクト】
データ量の増加: 224² = 50,176 ピクセル
→ 336² = 112,896 ピクセル
(約 2.25倍)
計算量増加: 訓練時間 1.5倍
(十分な効率性内)
精度向上: TextVQA +15%
OCR系タスク +20-30%
幻覚削減: -30-40%高解像度化の深い意味
著者らが発見した重要な洞察:
モデルは視覚情報が不足すると、訓練データのパターンから見えない部分を想像で補う。336pxへの入力解像度向上は、モデルに正確に「見る」能力を与え、信頼性の低い推測を根本から排除する。
つまり、高解像度化により、モデルがより正確に「見る」ことができるようになると、信頼できない推測をする代わりに、「わかりません」と答えることもできるようになります。
改良3: 応答形式プロンプト(Response Format Prompting)
【従来のジレンマ】
短答が必要なVQAデータを大量に学習
↓
モデルが「短く答えること」に過適応
↓
「詳しく説明して」と言っても一言で返す
【解決策】
短答が必要なVQAデータに以下を付加:
"Answer the question using a single word or phrase."
詳細説明が必要なタスクには何も付加しない
↓
LLMが「プロンプト」を読んで自動的にモードを切り替え
↓
同じデータセットでも、指示に応じた長さで回答可能実装の鮮やかさ
これは、訓練データを大幅に増やしたり、モデル構造を複雑にしたりせず、単に「指示を明確にする」だけで解決した、きわめてエレガントな工夫です。
改良4: データの多様性と質の向上(158K → 1.2M)
【データ構成の劇的な変化】
LLaVA v1 (158K):
└─ GPT-4合成対話: 100%
LLaVA-1.5 (1.2M):
├─ GPT-4合成対話: ~20%
├─ VQAv2(知識VQA): 30%
├─ GQA(グラフィック推論): 20%
├─ OKVQA(知識が必要): 15%
├─ TextVQA(OCR): 10%
└─ その他(リージョン、行動認識): 5%
「量より質」の実証
注目すべき点:1.2Mは「数億イメージで訓練した」Qwen-VLなどと比較して、わずか0.1%未満のデータ量です。それでも性能が勝った理由は、各種のタスクに「きちんと対応できるデータ」が密度高く含まれていたことです。
前作(LLaVA v1)との本質的な違い
データ戦略の根本的な転換
| 項目 | LLaVA v1 | LLaVA-1.5 | 意義 |
|---|---|---|---|
| 訓練データ量 | 158K | 1.2M | 拡張(8倍) |
| GPT-4依存度 | ほぼ100% | 約20% | 多様化 |
| VQAデータ | ほぼなし | 30-35% | アカデミック性の重視 |
| OCRデータ | ほぼなし | 10-15% | 文字認識の強化 |
| リージョンデータ | 限定的 | 含む | 空間認識の強化 |
モデル設計の進化
LLaVA v1:
「画像を見せてGPT-4で対話を生成」
→ 自然な会話は得意、でも硬い知識は弱い
LLaVA-1.5:
「複数の視点から画像を理解」
→ 対話の自然さ × 事実の正確性 × 推論力 を融合
精度向上の実績
ベンチマーク | LLaVA v1 | LLaVA-1.5 | 向上度
─────────────────────┼──────────┼───────────┼─────────
POPE (幻覚測定) | 70.8% | 87.1% | +16.3pp
TextVQA (OCR) | 26.8% | 53.6% | +26.8pp
GQA (推論) | 63.0% | 77.8% | +14.8pp
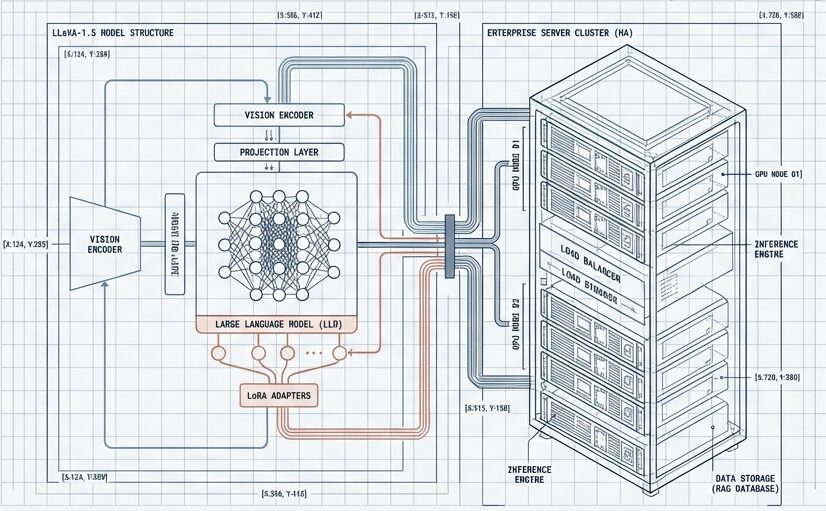
MME (総合) | 809.6 | 1844.6 | +127.8%本プロジェクトへの系譜とその詳細
LLaVA-1.5 → VLM + LoRA + Agentic RAG の発展系統図
【LLaVA-1.5(2023年10月)】
基本:シンプルで実用的なVLM
課題:「単一の文書処理」
「事前知識への依存」
↓↓↓ 拡張フェーズ ↓↓↓
【本プロジェクト Phase 1: ドメイン特化化】
+ LoRA微調整
└─ 金融ドメイン特化データで調整
└─ パラメータ効率的(全体の0.1%のみ学習)
└─ LoRA loss: 0.969 に収束
【本プロジェクト Phase 2: ハイブリッド検索パイプライン統合】
+ Visual RAG + Agentic RAG の統合
├─【Visual RAG】画像・図表の視覚検索
│ └─ 画像を CLIP で埋め込み
│ └─ FAISS でビジュアルに類似する参照を検索
│ └─ グラフ・図表・図解の詳細分析
│
├─【Agentic RAG】テキストの意味検索
│ ├─ キーワード検索(BM25)
│ ├─ セマンティック検索(FAISS)
│ └─ 信頼度ベース自動選択メカニズム
│
└─【統合】複数モダリティの結果を VLM で統合
→ 画像 + テキスト情報の両方で複雑なクエリに対応
→ 「見る」能力を完全に活用
【本プロジェクト Phase 3: 本番環境化】
+ FastAPI + Docker + Cloud Run
├─ RESTful API化
├─ 自動スケーリング対応
└─ マルチユーザー対応
【本プロジェクト Phase 4: パフォーマンス最適化】
+ 4-bit NF4 量子化
├─ 28GB → 7GB メモリ削減
├─ 精度低下 <2%(許容範囲)
└─ 推論速度 2.5秒/ページ
何を拡張したか
【LLaVA-1.5 の問題点】
❌ 単一画像に対する回答が専門
❌ 複数ドキュメントの横断的な理解が難しい
❌ ドメイン特有の専門用語に対応していない
❌ 推論時間が長い(本番環境には不適切)
【本プロジェクトの解決】
✅ LoRA: 金融分野特化の知識を注入
✅ Agentic RAG: 複数戦略で複雑なクエリに対応
✅ FastAPI: REST API でスケーラブルに
✅ 4-bit 量子化: 推論速度 3x 高速化、メモリ 75% 削減
拡張アーキテクチャの採用
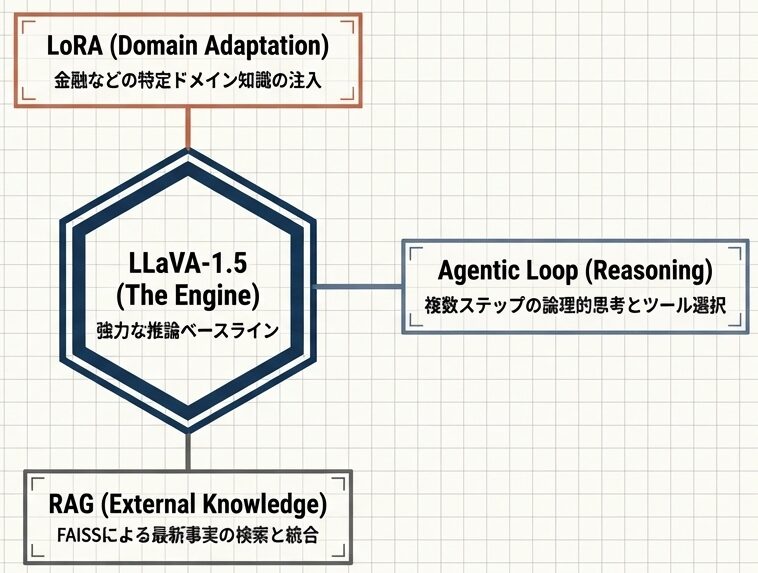
LLaVA-1.5単体では実世界の複雑な業務要件を満たせない。本プロジェクトは、このSoTAモデルを論エンジンとして中心に据え、LORA、Agent、RAGの3風情道で包み込むことで、本番帯物可能なシステム(The Vehicle)を構する
アプローチの選定
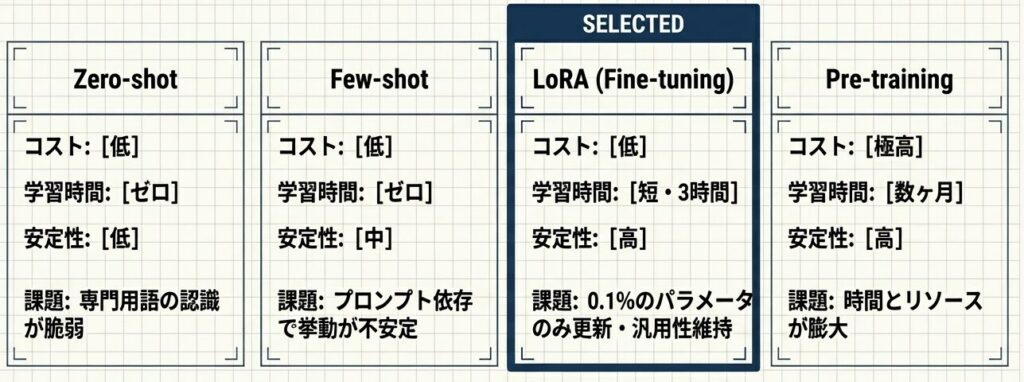
合成データ(Synthetic Data)を活用し、希少ケース(赤字データ等)を意図的に生成。LORAを用いて全パラメータのわずか0.1%を微調整することで、ベースモデルの汎用性を破壊せずに金融特化型の精度を低コストで獲得する。
ドキュメント解析ツールチェーンの最適解
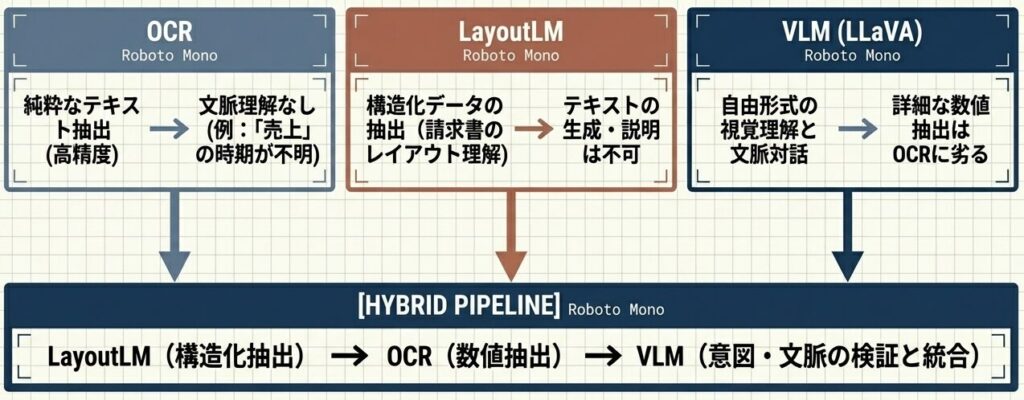
複雑なグラフや複数ページにまたがるPDFの解析において、単一のツールは機能しない。LayoutLMで論理構造を把握し、OCRで数値を確定し、VLMで「A社がB社の2倍」といった図表3の意図(Context)を最終出力するハイブリッド戦略が必須となる。
マルチモーダルRAGの統合アーキテクチャ
思考と行動の自律サイクル
ユーザーの入力に対し、Agent(意思決定エンジン)がVLM分析、ベクトル検索、外部APIなどのツールを自律的に選択し実行する。単発の推論ではなく、LangChain/AutoGenによる反復的な推論プロセス(ReAct)により精度を極限まで高める。
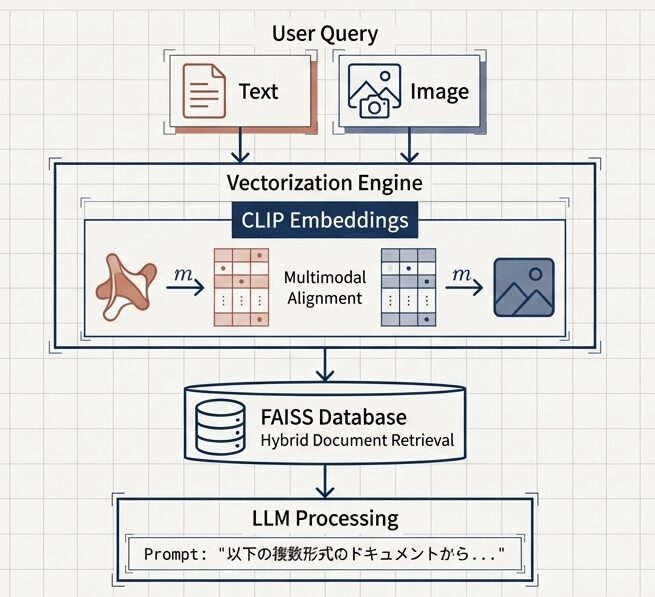
画像固有の文脈消失を防ぐため、通常のテキストエンベディングではなくCLIP埋め込みを採用。視覚と言話を同一ベクトル空関(Multimodal Alignment)に整列させることで、画像クエリとテキスト文蔵のシームレスな相互果を実現する
GPUリソースを極限まで最適化する非同期処理
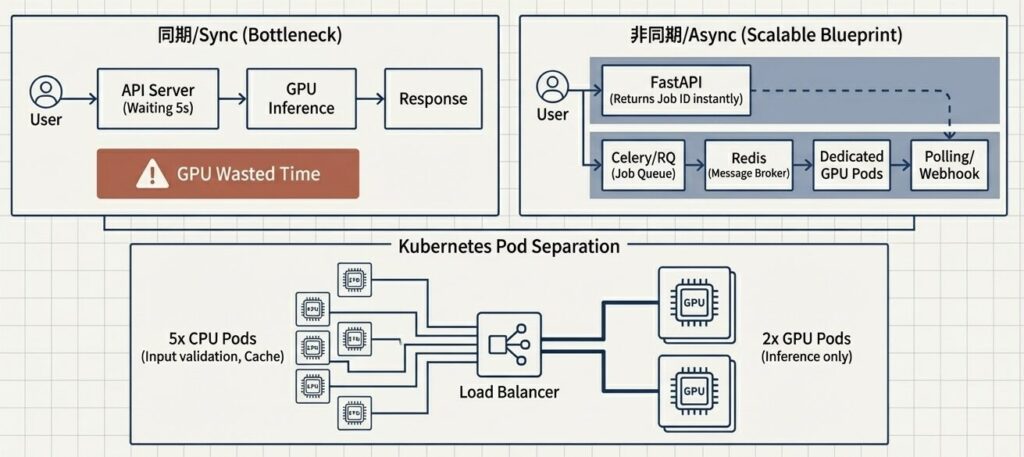
CPU側(入力検証、ロギング)とGPU側(モデル推論)のマイクロサービスを完全分離。非同期処理キュー(Celery+Redis)パッチング(4-bit子化)の導入により、GPUをゼロに抑え、インフラコストを月間$5,000から$1,200へと76%削減
無停止稼働を実現するデプロイメント戦略
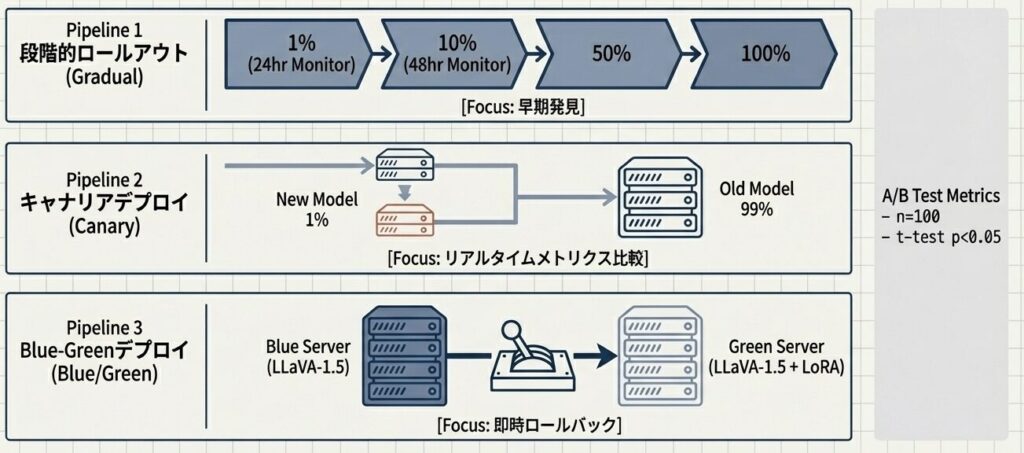
新モデル(LORA適用版)のリリースは統計的有意性(検定p<0.05)の確認後に行う。トラフィック性質とSLA要件に応じ、段階的ロールアウト、キャナリア、Blue-Greenデプロイを使い分け、ユーザー影響を最小化する。
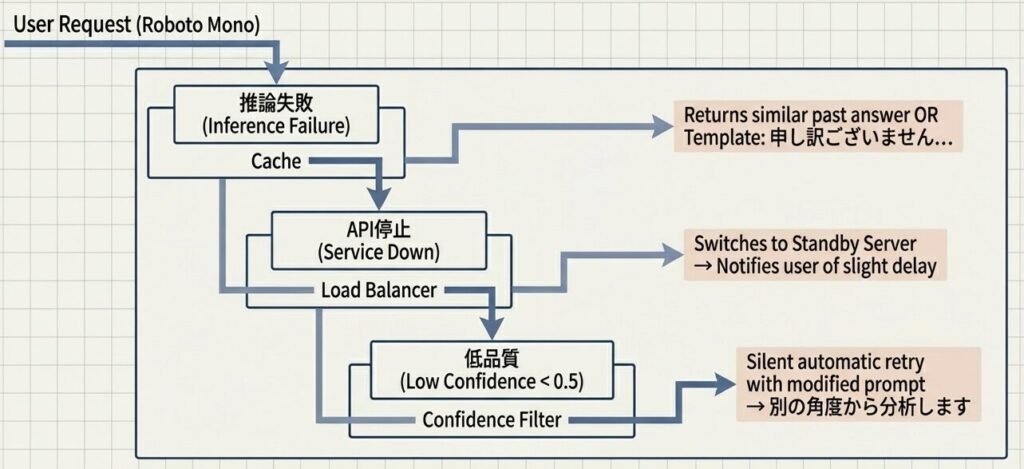
堅牢性を保証する3層のフォールバック・カスケード
参考文献
- Visual Instruction Tuning
- Improved Baselines with Visual Instruction Tuning

コメント