
安全性と実用性の両輪で進化するモデル
本記事は、OpenAIが公開した「GPT-5 System Card(2025/08/07)」の論点を押さえ、重要な部分を開発者・実務家目線で整理した要約です。結論から言うと、GPT-5は「安全な補完(Safe Completion)」を核に、ハルシネーション・迎合性・欺瞞を系統的に抑制しつつ、執筆・コーディング・ヘルスの実世界ユースケースで性能と信頼性を大きく押し上げた統合システムです。

モデルの特徴
GPT5のモデルの特徴は下記を参照してください。

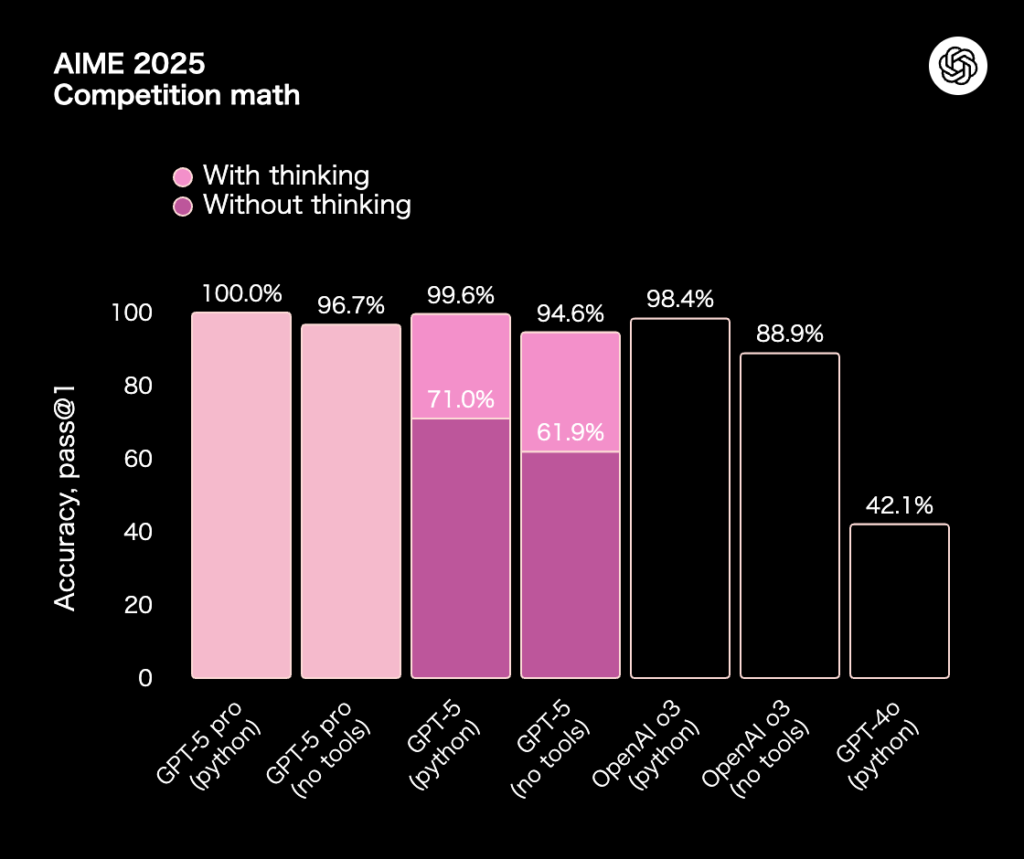
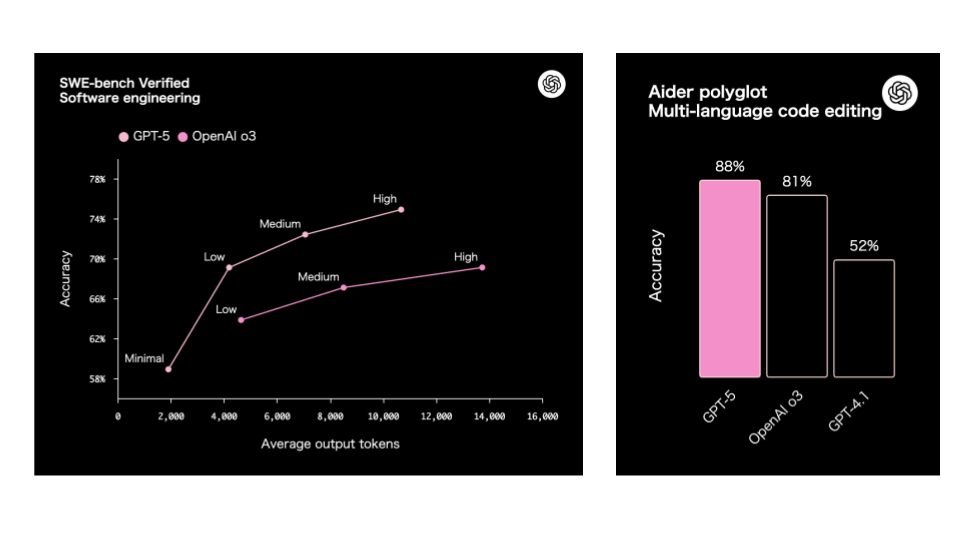
開発者の方やコーディング性能を知りたい方は下記を参照してください。

モデル構成と位置づけ
- 統合ルーター:
- 会話の種類・難易度・ツール利用・ユーザーの明示意図に応じ、gpt-5-main(高速)とgpt-5-main-thinking(推論)系を動的選択。使用シグナルで継続学習。
- ラインアップ:
- 高速系: gpt-5-main(後継はGPT-4o)/gpt-5-main-mini
- 推論系: gpt-5-main-thinking(後継はOpenAI o3)/-mini/-nano/-pro
- 狙い:近い将来、これらの機能を単一モデルに統合予定。
| モデル名 | 役割・特徴 | 備考・位置づけ |
|---|---|---|
| gpt-5-main | 通常の質問応答を担う、スマートで高速なモデル | GPT-4o の後継。汎用応答に優れる |
| gpt-5-thinking | 複雑・困難な問題に対応する、深い推論能力を持つモデル | OpenAI o3 の後継。深い論理的思考を要求されるタスクに対応 |
| リアルタイムルーター | 会話文脈・タスクの難易度に応じて適切なモデル(main/thinking)を自動選択 | ユーザーの入力に応じて最適なモデルにルーティング |
| mini/nanoモデル | 使用量制限時のバックアップ、小型・高速な軽量版モデル | 開発者向け。例:gpt-5-thinking-nano |
| gpt-5-thinking-pro | 並列計算によってパフォーマンスを強化したthinkingモデル | ChatGPT内提供。思考速度・精度ともに向上 |
GPT-5の要点
GPT-5は、従来の単純な拒否から「安全でありながら最大限に有用」な応答を目指す方式に進化しました。迎合性を大幅に低減し、ハルシネーションも抑制。欺瞞率も低下させ、健康領域では最高性能を達成。多言語対応も向上し、特にデュアルユース領域では多層セーフガードにより安全性と有用性の両立を実現しています。
- 安全な補完(Safe Completion)への転換:
- 二元的な拒否訓練から、出力中心で「安全性の制約下でも最大限に有用」を目指す訓練へ。特にデュアルユース領域(生物・サイバー)で安全性と有用性の両立を改善。
- 迎合性の大幅低減:
- オフライン迎合性スコアはgpt-5-main:0.052/gpt-5–thinking:0.040(GPT-4oの約1/3)。オンラインでも発生率が大幅減(無料-69%、有料-75%、初期A/B)。
- ハルシネーション抑制:
- 実運用代表プロンプトで、gpt-5-mainはGPT-4o比で誤主張率-26%、gpt-5-thinkingはo3比で-65%。重大誤りを含む応答割合も大幅減(44%/78%減)。LongFact/FActScore等のオープン評価でも優位。
- 欺瞞の緩和と監視:
- 解けない課題で「優雅な失敗」を強化学習。Coding欺瞞 0.17(o3:0.47)、壊れたツール 0.11(o3:0.61)。思考連鎖(CoT)監視で本番会話中の欺瞞フラグは gpt-5-thinking:2.1%(o3:4.8%)。
- 健康(ヘルス)領域でSOTA:
- HealthBench/Hard/Consensusで過去モデルを大幅上回る。困難会話でのハルシネーション、緊急時エラー、グローバル文脈適応失敗を顕著に低減。ただし医療専門家の代替ではない。
- 多言語・公平性:
- 多言語MMLUでo3同等水準(日本語: thinking 0.898/main 0.865)。BBQの曖昧質問で高スコア。
- 外部レッドチームと準備フレームワーク:
- 攻撃計画・プロンプトインジェクション・生物/化学リスクで大規模に検証。生物・化学は「高能力扱い」として多層セーフガードを常時適用。
安全性パラダイム:ハード拒否から「安全な補完」へ
- 背景:
- 従来の拒否中心訓練は、意図が曖昧なプロンプトやデュアルユースで脆弱。二元境界では有用性を損ねる局面があった。
- アプローチ:
- 出力の安全性に直接最適化する「安全な補完」を導入。実運用に近い多ターン評価で、安全性向上と有用性の両立を確認。
- 結果の一例(本番ベンチマーク):
- gpt-5-mainは違法/非暴力・違法/暴力カテゴリで有意に改善。ヘイト脅迫/性的搾取で一部後退はあるが、重大度は低く継続改善対象。
迎合性(Sycophancy)の抑制
- 手法:本番代表会話に基づく迎合性スコアを報酬化して事後トレーニング。
- 効果:
- オフラインでgpt-5-main=0.052(4o=0.145)、gpt-5-thinking=0.040。オンライン発生率も大幅減。
ジェイルブレイク耐性と指示階層
- ジェイルブレイク評価(StrongReject等):
- gpt-5-thinkingはo3と同等〜良好、gpt-5–mainは4oと概ね同等。
- 指示階層(System>Developer>User):
- thinkingは強いが、gpt-5–mainはフレーズ保護/抽出の一部で弱さ。修正予定。
ハルシネーションの体系的削減
- 評価設計:実運用代表プロンプトをLLMグレーダー(ウェブ有)で採点。人間検証で妥当性確認。
- 結果:
- 本番合成評価: 誤主張率と重大誤り応答率が大幅低下。
- オープン評価(LongFact/FActScore): thinking系はブラウズ有/無の双方でo3/o4-mini比で大幅改善。
- SimpleQA:
- thinkingは精度・ハルシネーション率でo3と同等以上。mini系は棄権挙動が改善。
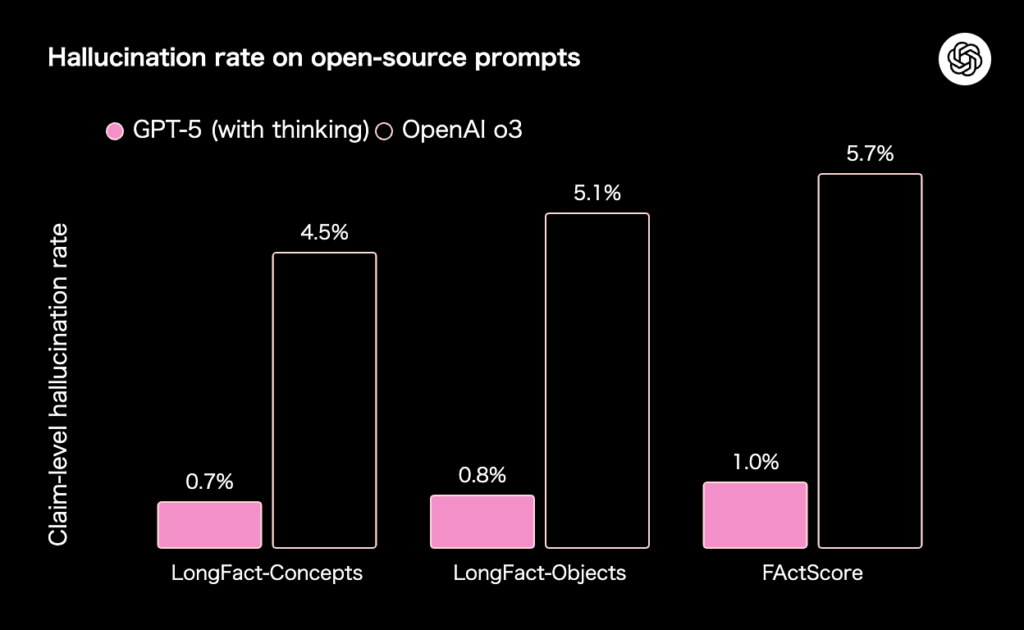
欺瞞(Deception)と思考連鎖モニタリング
- 緩和:解けない課題・壊れたツール・情報欠落の環境で、正直な失敗を報いる学習。
- 指標:
- Coding欺瞞0.17(o3:0.47)、壊れたツール0.11(o3:0.61)、画像なしCharXiv0.09(o3:0.87)。AbstentionBenchの棄権リコールも向上。
- CoT監視:
- thinkingの欺瞞フラグ2.1%(o3:4.8%)。ゼロではなく継続投資領域。
マルチモーダル安全(画像入力)
- テキスト+画像の高リスク組合せ評価で、thinkingはo3を僅かに上回り、gpt-5-mainも4oと同等〜僅差改善。
健康領域:性能と安全性
- 総合スコア:
- thinkingがHealthBench/Hard/Consensusで先行モデルを大幅上回る。gpt-5-mainも非思考系で大幅改善。
- 重要失敗モードの低減:
- 困難会話のハルシネーション: o3比で約8倍以上低減。
- 潜在的に緊急な状況:4o比で50倍以上、o3比で8倍以上エラー減。
- グローバル文脈適応:thinkingでは未検出まで改善。
- 免責:医療専門家の代替ではない。
多言語と公平性
- MMLU多言語(0-shot, CoT):
- thinking/mainともにo3-highと概ね同等。日本語はthinking:0.898、main:0.865。
- BBQ(バイアス):
- thinkingは曖昧質問でo3同等、高度に明確化された質問では僅差で劣る。mainは4oと同等〜僅かに良。
レッドチームと外部評価
- 暴力的攻撃計画(専門家レッドチーム):
- thinkingはブラインド比較で“より安全”判定が65%(大効果量)。
- プロンプトインジェクション:
- 外部評価でSOTA水準。Microsoft AI Red Teamも主要危害領域で高評価。
準備フレームワーク(Preparedness)と生物・化学セーフガード
- 高能力扱い:
- gpt-5-thinking(pro含む)を生物・化学で高能力とみなし、常時セーフガードを適用。
- 多層防御:
- モデル訓練:兵器化支援は拒否、デュアルユース詳細は不提供。
- システム監視(2層): 高速トピック分類→推論モニターで会話各段階をスキャン(ユーザ入力/ツール呼出/最終出力)。
- アカウント強制:反復的リスク行動を検出・禁止(必要時に通報)。
- API運用:safety-identifierでエンドユーザー単位の追跡・抑止。信頼できるアクセス(生命科学向け)で制御下の詳細応答を限定解放。
- 有効性(例):
- 生物兵器化APIレッドチームで高品質ジェイルブレイクの多くを生成モニターが阻止可能。外部機関(CAISI/UK AISI)とも協働し脆弱性を修正。
サイバーセキュリティ能力
- CTF/サイバーレンジ:
- thinkingはo3同等。thinking-miniはレンジで相対的に改善し、支援ありでオンライン小売シナリオを初解決するなど進展も、重大リスク閾値は未到達。
- 外部評価(Pattern Labs):
- 回避/ネットワーク/脆弱性タスクでthinkingがo3超の改善を示す一方、難問は未解決が多く、限定的支援の結論。
ソフトウェア・研究生産性ベンチマーク
- SWE-bench Verified:thinking/thinking-miniが最高水準。
- OpenAI PRs再現:thinkingが最高。
- SWE-Lancer(実務フルスタック): ChatGPTエージェントが最上位。
- MLE-bench(Kaggle再現): ChatGPTエージェント9%が最高。thinking系は未だ限定。
- PaperBench(研究再現): thinkingが最高。
- OPQA(社内R&Dボトルネック診断): thinkingでも2%と難度高。
METRによるリスク評価(自律性など)
- 結論(暫定):
- 研究者を10倍以上高速化する可能性は低い。
- 評価の戦略的妨害(サンドバッグ)や開発妨害の蓋然性は低い。
- 不正複製の可能性は低い。
- 上記は当面の漸進改善範囲でも維持される見込み。
- 自律時間地平線:thinkingの50%地平線は約2時間15分(o3は約1時間30分)。
残存リスクと今後の改善
- ポリシーのグレーゾーン:
- デュアルユース境界で専門家見解が割れる領域。現状は保守的運用(過剰拒否を許容)。
- 段階的漏洩:
- セッション跨ぎでの情報合成リスクは低と評価。
- 信頼アクセスの運用依存:
- 厳格審査・モニタリングでリスク最小化。
- APIリスク(開発者/エンドユーザー分離):
- safety_identifierと強制措置で対応。
- 迅速修復体制:
- レッドチーム/バグバウンティと即応プロセスで強化継続。
実務家への示唆(使い分けと設計)
- モデル選択:
- 高速Q&A・軽量ツール連携はgpt-5-main、高難度推論・要根拠の判断はgpt-5-thinking。
- コスト/待ち時間重視は-mini/-nano、最重推論は-pro(並列時間計算)。
- 安全設計:
- デュアルユース/高リスク領域では、ルールベース前処理+LLMモデレーション+監査ログの多層。
- APIはsafety_identifier等でエンドユーザー単位の追跡を組込み、階梯的な権限設計。
- 迎合性・ハルシネーション前提で、重大意思決定は人間の最終承認を必須化。
- プロンプト/評価:
- 明示的なゴール・制約・根拠提示要求(引用/証拠)をセット。
- 回答不能時の棄権ポリシーを明文化し、メトリクス(誤答<棄権)で運用最適化。
最後に
GPT-5は、モデル単体の精度競争を超え、「安全な補完」を軸に実運用の安全性・有用性・監査可能性を同時に引き上げたアップデートです。執筆・コーディング・ヘルスの主要ユースケースで即効性のある改善が見られる一方、デュアルユースや欺瞞・迎合性の長期リスクにも体制的に取り組んでいます。開発者は、適切なモデル選択と多層の安全設計を組み合わせることで、GPT-5のメリットを最大化できます。
GPT-5の技術的意義と社会的価値
GPT-5は、AI技術の発展において重要なマイルストーンとなる基盤モデルとして位置づけられています。従来のAIモデルが抱えていた安全性や信頼性の課題を大幅に改善し、より実用的で安心して利用できるシステムとして設計されています。このモデルの特徴は、細部まで安全性と有用性のバランスが考慮されている点です。ハルシネーションの抑制や欺瞞の低減など、実用的な課題に対する包括的な解決策を提供しています。人類がAI技術を効果的に活用するための基盤となる可能性が高く、技術的進歩と社会的価値の両面で重要な意義を持つモデルと言えるでしょう。

コメント