
【今回の主な内容】時系列データ解析と生成タスクの基礎
今回のテーマは、時系列データと自然言語処理(NLP)の基礎としての生成分野を学び、RNNを中心とした時系列モデルの役割を理解することです。
前編では時系列データ解析の基礎と生成分野、後編では自然言語処理モデル、音声認識における時系列モデル、Transformerモデルを使った時系列予測モデルについて学んでいきます。
トレンド、季節性、残差といった時系列データの特性を把握し、スライディングウィンドウや多変量データの準備といった基本手法を学びます。
また、RNN系モデルが生成タスクでどのように活用されるかに触れ、オートエンコーダや変分オートエンコーダー(VAE)が時系列データ解析や異常検知にどのように応用されるかを学びます。さらに、RNNの勾配消失問題と、それを克服するLSTMやGRUの仕組みも理解します。
実践では、Pythonを用いて時系列データの前処理や特徴量生成を行い、次回の自然言語処理を用いたtransformerモデル構築に備えます。これにより、時系列データ解析と生成タスクの応用力を高める基礎を築きます。
今回の学習目標
- 時系列データ解析の基礎を理解する
- トレンド、季節性、残差など、時系列データの基本構造を理解する。時系列データ解析におけるARIMAとSARIMAとは?
- 生成タスクの概要を理解する
- オートエンコーダや変分オートエンコーダー(VAE)の仕組みを理解し、データ拡張や異常検知への応用方法を学ぶ。
- スライディングウィンドウ、多変量データの準備、正規化や標準化など、時系列データ処理の基本的な前処理手法を習得する。
- 時系列データを活用した生成タスクの重要性を把握し、シミュレーションやデータ拡張の役割を理解する。
- リカレントニューラルネットワーク(RNN)の基礎を学ぶ
- 隠れ層(Hidden State)を活用して時系列データの依存関係をモデル化するRNNの動作原理を理解する。
- 勾配消失問題の影響を理解し、それを克服する必要性を把握する。
- RNNを改善したLSTMやGRUの動作原理を理解し、それぞれの利点や用途を学ぶ。
- 次回の応用に向けた準備
- 時系列解析や生成タスクで適切なモデルを選択する基準を学ぶ。
- LSTMやGRUを使った実装例やNLP・音声認識タスクに向けた基礎を固める。
ゴール
- 時系列データ解析の基礎を理解する
- トレンド、季節性、残差を正しく見分け、時系列データを適切に前処理できる。
- 生成タスクの概要を理解する
- オートエンコーダやVAEの仕組みと役割を説明し、生成タスクを時系列データに応用する方法を理解できる。
- RNNの基礎を理解する
- RNNの動作と隠れ状態の役割を説明し、勾配消失問題の原因を理解できる。
- LSTMとGRUの基礎を理解する
- LSTMとGRUの違いと利点を説明し、どちらのモデルを使うべきか判断できる。
時系列データとは?
時系列データとは、時間軸に沿って観測されたデータのことを指します。このデータは、過去の状態が現在や未来に影響を与えるため、データの依存性を考慮した解析が求められます。以下は、時系列データの主要な特性です。
時系列データの基本構造
| 構成要素 | 説明 |
|---|---|
| トレンド | 長期的な傾向や方向性を表し、データが全体的に増加または減少している様子を示します。 |
| 季節性 | 一定の周期で繰り返される変動を指し、例えば、季節ごとに変化する売上や需要などが挙げられます。 |
| 残差(ランダム成分) | トレンドや季節性に当てはまらないランダムな変動を表し、ノイズとも呼ばれます。 |
時系列データの応用例
| 分野 | 具体例 |
|---|---|
| 金融 | 株価や為替の予測、リスク評価 |
| 医療 | 心電図や脳波などの解析による異常検知や診断支援 |
| 音声認識 | 音声データを時系列として解析し、文字起こしや音声コマンド認識に活用 |
| 自然言語処理(NLP) | テキストデータを時系列的に解析し、文章生成や機械翻訳に応用 |
金融時系列データのイメージ(暗号通貨)
時系列データ解析の重要性
時系列データを適切に処理し、その特性であるトレンドや季節性を正確に把握することで、データから有益な洞察を得られます。これにより、予測精度や異常検知の精度を向上させる重要な基盤が築けます。
ARIMAモデル: 時系列データ解析の基礎
概要と特徴
ARIMA(AutoRegressive Integrated Moving Average)モデルは、過去の値や誤差項を用いて、時系列データの予測を行う統計的手法です。データの定常性を前提とし、トレンドやランダム変動を解析するために用いられます。
主な構成要素
| 要素 | 説明 |
|---|---|
| 自己回帰(AR) | 過去のデータ値を基に現在を予測。 |
| 差分(I) | 非定常なデータを定常化するための変換。 |
| 移動平均(MA) | 過去の誤差項を基に予測。 |
数式:
$$X_t = c + \sum_{i=1}^{p} \phi_i X_{t-i} + \sum_{j=1}^{q} \theta_j \epsilon_{t-j} + \epsilon_t$$
$X_t$:現在の値。$c$:定数項。$p$:自己回帰項の次数。$q$:移動平均項の次数。$ϕ_i$:自己回帰係数$θ_j$: 移動平均係数。$ϵ_t$:ホワイトノイズ(誤差項)。
目的と課題
- 目的
- 短期予測
- 将来の値を数時間から数週間単位で予測する。
- トレンド解析
- 時系列データの長期的な傾向を明らかにする。
- 異常検知
- 予測誤差が閾値を超える場合に異常を検知。
- 短期予測
- 課題
- 非線形性の限界
- データが線形であることを前提としており、複雑な非線形パターンは捉えられない。
- モデル選定の複雑さ
- 適切な$p$, $d$, $q$を選定する必要があり、自動化しても最適化が難しい場合がある。
- 大規模データへの適用性
- 計算効率の制約により、大規模データの処理には向かない。
- 非線形性の限界
メリットとデメリット
| メリット | デメリット |
|---|---|
| 解釈性:統計モデルとしての構造がシンプルで、結果が解釈しやすい。 | 定常性への依存:データが非定常の場合、適切な差分化が必須。 |
| 適用性:短期的なデータ予測や定常データの解析に優れる。 | 外部要因の考慮不足:外部変数や複雑な相関関係を直接組み込むのが難しい。 |
| 自動化可能:AIC(赤池情報量基準)などの指標を用いることで、パラメータ選定を自動化可能。 | 非線形パターンへの対応力不足:LSTMやGRUのような深層学習モデルと比較すると、非線形性の表現力が劣る。 |
適用例
| 適用例 | 具体例 |
|---|---|
| 株価や為替レートの予測 | 数日から数週間単位での短期的な動向予測。 |
| 経済指標のトレンド分析 | GDPやインフレ率など、季節性のあるデータの分析。 |
| 需要予測 | 電力消費量や商品需要の短期予測。 |
ARIMAモデルの実装例
ARIMAモデルを使用してウォークフォワード法でETH-USDの価格データを予測し、その予測精度を評価してみます。
必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import japanize_matplotlib
from statsmodels.tsa.arima.model import ARIMAウォークフォワード法を行う関数
def walk_forward_arima(data, arima_order=(5,1,0), train_size=0.8, step_size=30):
"""
data: pd.Series または pd.DataFrame (1列のCloseなど)
arima_order: ARIMA(p,d,q) のパラメータ
train_size: 学習データとして使用する割合
step_size: 1回のウォークフォワードで予測するステップ数
"""
# データをSeriesとして扱う
if isinstance(data, pd.DataFrame):
data_series = data.iloc[:, 0]
else:
data_series = data
n = len(data_series)
split_index = int(n * train_size)
# トレーニングデータとテストデータに分割
train_data = data_series[:split_index]
test_data = data_series[split_index:]
predictions = []
actuals = []
# 現在のトレーニングデータの終了点
current_end = split_index
while current_end < n:
# ARIMAモデルを学習
model = ARIMA(train_data, order=arima_order)
model_fit = model.fit()
# 次のstep_size分を予測
forecast_end = current_end + step_size
# テストデータの最終インデックスを超えないようにする
if forecast_end > n:
forecast_end = n
forecast_steps = forecast_end - current_end
forecast = model_fit.forecast(steps=forecast_steps)
# 実際のテストデータと比較する範囲を取得
actual = data_series[current_end:forecast_end]
predictions.extend(forecast.values)
actuals.extend(actual.values)
# ウォークフォワード: トレーニングデータを拡張
train_data = data_series[:forecast_end]
current_end = forecast_end
return np.array(predictions), np.array(actuals)メイン関数
def main():
# データの取得
ticker = 'ETH-USD'
df = yf.download(ticker, start='2016-01-01', end='2024-01-16')
close_data = df[['Close']] # Close列を取得
# ウォークフォワード法による検証
arima_order = (5, 1, 0) # ARIMA(p, d, q)
preds, acts = walk_forward_arima(close_data, arima_order=arima_order, train_size=0.8, step_size=30)
# 評価指標の計算
rmse = np.sqrt(mean_squared_error(acts, preds))
print(f'Walk-Forward Validation RMSE: {rmse:.4f}')
# 結果の可視化
plt.figure(figsize=(14, 7))
# テスト区間に対応するインデックスを作成
test_start = int(len(close_data) * 0.8)
test_index = close_data.index[test_start:]
# ウォークフォワードで取り出した実測値に合わせてインデックスを切り詰め
test_index = test_index[:len(acts)]
plt.plot(test_index, acts, label='Actual', color='blue')
plt.plot(test_index, preds, label='Forecast', color='red', linestyle='--')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Walk-Forward Validation with ARIMA')
plt.legend()
plt.show()
if __name__ == '__main__':
main()Walk-Forward Validation RMSE: 160.9284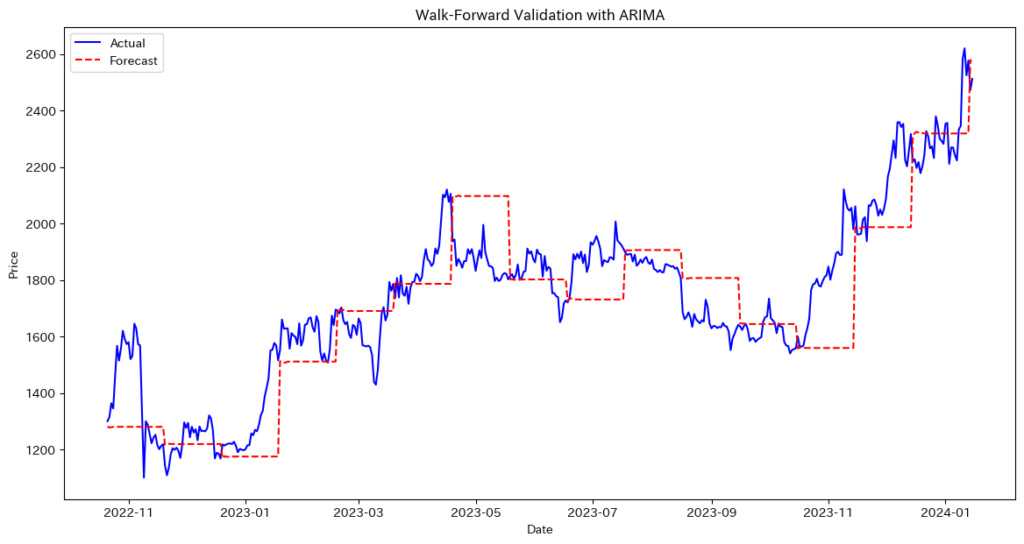
ウォークフォワード法を使用することで、時系列データの順序を保ちながらモデルを更新し、未来のデータに対して予測を行います。これにより、モデルの汎化性能を評価し、実際のデータに対する予測精度を確認することができます。評価指標としてRMSEを使用し、予測結果を実際のデータと比較して視覚的に確認します。
ARIMAモデルの性能を向上させるためには?
- パラメータの最適化
- ARIMAモデルの性能向上には、グリッドサーチや自動化手法を用いて最適なパラメータ(p, d, q)を選定することが重要です。
グリッドサーチ
from statsmodels.tsa.arima.model import ARIMA
import itertools
# パラメータの範囲を定義
p = range(0, 6)
d = range(0, 2)
q = range(0, 6)
# すべての組み合わせを生成
pdq = list(itertools.product(p, d, q))
best_aic = float("inf")
best_order = None
best_model = None
# グリッドサーチ
for order in pdq:
try:
model = ARIMA(data, order=order)
model_fit = model.fit()
if model_fit.aic < best_aic:
best_aic = model_fit.aic
best_order = order
best_model = model_fit
except:
continue
print(f'Best ARIMA order: {best_order} with AIC: {best_aic}')2. データの前処理
- データの前処理を改善することで、モデルの性能を向上させることができます。
データの正規化
データの正規化は、モデルの学習を効率化し、予測精度の向上につながります。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data.values.reshape(-1, 1))
data_scaled = pd.Series(data_scaled.flatten(), index=data.index)季節性の除去
データに季節性がある場合、それを除去することでモデルの予測精度を高めることができます。
data_diff = data.diff().dropna()3. モデルの拡張
- ARIMAモデルをSARIMA(季節性対応)やARIMAX(外部変数対応)に拡張することで、予測精度をさらに向上させることができます。
SARIMAモデル
from statsmodels.tsa.statespace.sarimax import SARIMAX
sarima_order = (5, 1, 0)
seasonal_order = (1, 1, 1, 12) # 季節性のパラメータ
sarima_model = SARIMAX(data, order=sarima_order, seasonal_order=seasonal_order)
sarima_model_fit = sarima_model.fit()Walk-Forward Validation RMSE: 159.2595ARIMAXモデル
# 外部変数を含むデータを用意
exog_data = pd.DataFrame({'exog_var': exog_var_values})
arimax_order = (5, 1, 0)
arimax_model = ARIMA(data, order=arimax_order, exog=exog_data)
arimax_model_fit = arimax_model.fit()Walk-Forward Validation RMSE: 160.97884. モデルの評価と選択
- 複数モデルを比較し、AICやBICなどの評価指標を用いて最適なモデルを選ぶことが重要です。モデルの値は小さい方が良いモデルとされています。
# ARIMAモデルの複数パラメータを比較し、AICやBICで最適なモデルを選択します。
import yfinance as yf
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# データの取得
ticker = 'ETH-USD'
df = yf.download(ticker, start='2019-01-01', end='2024-01-01')
data = df['Close'].dropna()
# テストするARIMAパラメータのリスト
candidate_orders = [(5,1,0), (5,1,1), (5,1,2), (2,1,2)]
best_aic = float('inf')
best_bic = float('inf')
best_order = None
best_model_fit = None
# モデルの評価
for order in candidate_orders:
try:
model = ARIMA(data, order=order)
model_fit = model.fit()
aic = model_fit.aic
bic = model_fit.bic
print(f'ARIMA{order} - AIC: {aic:.2f}, BIC: {bic:.2f}')
# AICが最小のモデルを更新
if aic < best_aic:
best_aic = aic
best_bic = bic
best_order = order
best_model_fit = model_fit
except Exception as e:
print(f'ARIMA{order} は適合できませんでした: {e}')
print('\n最適なモデル')
print(f'ARIMA{best_order} with AIC={best_aic:.2f} and BIC={best_bic:.2f}')ARIMA(5, 1, 0) - AIC: 21192.47, BIC: 21225.53
ARIMA(5, 1, 1) - AIC: 21187.48, BIC: 21226.04
ARIMA(5, 1, 2) - AIC: 21183.61, BIC: 21227.68
ARIMA(2, 1, 2) - AIC: 21202.54, BIC: 21230.09
最適なモデル
ARIMA(5, 1, 2) with AIC=21183.61 and BIC=21227.68最適なモデルはARIMA(5, 1, 2)であるという回答が返ってきました。
最適なモデルの学習結果
import yfinance as yf
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# データの取得
ticker = 'ETH-USD'
df = yf.download(ticker, start='2019-01-01', end='2024-01-01')
data = df['Close'].dropna()
# 最適なモデル (ARIMA(5, 1, 2)) を使って学習
model = ARIMA(data, order=(5, 1, 2))
model_fit = model.fit()
print(f"AIC: {model_fit.aic}")
print(f"BIC: {model_fit.bic}")
print(model_fit.summary())AIC: 21183.60508586214
BIC: 21227.67976799027
SARIMAX Results
==============================================================================
Dep. Variable: Close No. Observations: 1826
Model: ARIMA(5, 1, 2) Log Likelihood -10583.803
Date: Sat, 18 Jan 2025 AIC 21183.605
Time: 23:45:19 BIC 21227.680
Sample: 01-01-2019 HQIC 21199.863
- 12-31-2023
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.8186 0.104 -7.903 0.000 -1.022 -0.616
ar.L2 -0.5438 0.091 -6.005 0.000 -0.721 -0.366
ar.L3 0.0076 0.021 0.366 0.714 -0.033 0.049
ar.L4 0.0534 0.017 3.200 0.001 0.021 0.086
ar.L5 -0.0547 0.018 -3.093 0.002 -0.089 -0.020
ma.L1 0.7538 0.102 7.363 0.000 0.553 0.954
ma.L2 0.5127 0.079 6.468 0.000 0.357 0.668
sigma2 6408.5151 85.583 74.880 0.000 6240.775 6576.256
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 15824.82
Prob(Q): 0.97 Prob(JB): 0.00
...
===================================================================================表示された「SARIMAX Results」は、選択された「ARIMA(5, 1, 2)」モデルの学習結果を正しく反映しています。適合度やパラメータの有意性から現時点で最適なモデルと判断できますが、残差の正規性やパラメータの有意性を確認し、さらなる改善を検討することが重要です。
5. 交差検証としてのウォークフォワードテスト
- ウォークフォワード法や時系列クロスバリデーションを用いて、モデルの汎化性能を正確に評価します。
# ARIMAモデルの評価と選択、クロスバリデーションの実装
import yfinance as yf
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
import matplotlib.pyplot as plt
import japanize_matplotlib
# データの取得
ticker = 'ETH-USD'
df = yf.download(ticker, start='2019-01-01', end='2024-01-01')
data = df['Close'].dropna()
# モデルのパラメータ設定
candidate_orders = [(5, 1, 0), (5, 1, 1), (5, 1, 2), (2, 1, 2)]
best_aic = float('inf')
best_bic = float('inf')
best_order = None
best_model_fit = None
# モデルの評価
print("モデルの評価と選択")
for order in candidate_orders:
try:
model = ARIMA(data, order=order)
model_fit = model.fit()
aic = model_fit.aic
bic = model_fit.bic
print(f'ARIMA{order} - AIC: {aic:.2f}, BIC: {bic:.2f}')
# AICが最小のモデルを更新
if aic < best_aic:
best_aic = aic
best_bic = bic
best_order = order
best_model_fit = model_fit
except Exception as e:
print(f'ARIMA{order} は適合できませんでした: {e}')
print('\n最適なモデル')
print(f'ARIMA{best_order} with AIC={best_aic:.2f} and BIC={best_bic:.2f}')
# 最適なモデルを使用して予測とクロスバリデーション
print("\nクロスバリデーションの実行")
tscv = TimeSeriesSplit(n_splits=5)
rmse_scores = []
fold = 1
for train_index, test_index in tscv.split(data):
train_data, test_data = data.iloc[train_index], data.iloc[test_index]
try:
model = ARIMA(train_data, order=best_order)
model_fit = model.fit()
predictions = model_fit.forecast(steps=len(test_data))
rmse = np.sqrt(mean_squared_error(test_data, predictions))
rmse_scores.append(rmse)
print(f'Fold {fold} - RMSE: {rmse:.4f}')
except Exception as e:
print(f'Fold {fold} - モデルの適合中にエラーが発生しました: {e}')
fold += 1
# クロスバリデーションの結果
average_rmse = np.mean(rmse_scores)
std_rmse = np.std(rmse_scores)
print(f'\nクロスバリデーションの平均RMSE: {average_rmse:.4f}')
print(f'クロスバリデーションのRMSEの標準偏差: {std_rmse:.4f}')
# 全データを使ってモデルを再学習
print("\n全データを使って最適なモデルを再学習")
final_model = ARIMA(data, order=best_order)
final_model_fit = final_model.fit()
# 予測の可視化(全データに対するフィット)
plt.figure(figsize=(14, 7))
plt.plot(data.index, data, label='実際の値', color='blue')
plt.plot(data.index, final_model_fit.fittedvalues, label='フィット値', color='red', linestyle='--')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('ARIMAモデルのフィット結果')
plt.legend()
plt.show()最適なモデル
ARIMA(5, 1, 2) with AIC=21183.61 and BIC=21227.68
クロスバリデーションの平均RMSE: 882.5592
クロスバリデーションのRMSEの標準偏差: 575.4848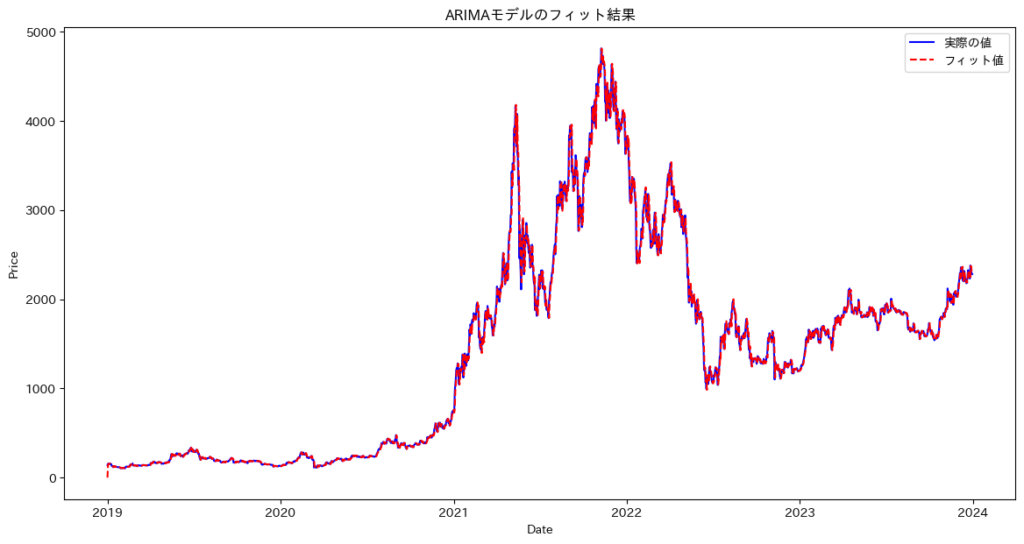
このコードは、AICとBICを基に最適なARIMAモデルを選び、時系列クロスバリデーションで汎化性能を評価します。その後、全データを使って最終モデルを再学習し、フィット結果を視覚化することで、モデルの適切性を総合的に確認します。
6. ハイブリッドモデルの使用
- ARIMAモデルとLSTMやGRUなどを組み合わせたハイブリッドモデルを用いると、予測精度をさらに向上させる可能性があります。
ARIMAモデルの予測精度を向上させるには、パラメータの最適化、データ前処理、モデル拡張、クロスバリデーション、評価と選択、ハイブリッドモデルの活用などを組み合わせて試すことが効果的です。
論文
論文1:『LSTM を用いた株価変動予測』

- 短期株価予測におけるLSTMの有効性
- LSTMモデルを用いてトヨタ自動車の1分ごとの利益率を予測しました。ノイズの多い金融データに対し、長期依存関係を効果的に学習し、訓練データで符号一致率87.0%を達成。短期予測モデルとしてのLSTMの実用性を示すとともに、高頻度取引や市場分析への応用可能性を明らかにしました。
- 過学習の課題と今後の改良の方向性
- LSTMを用いた短期株価予測モデルは訓練データで高精度を達成しましたが、テストデータでの性能低下が過学習の課題として浮上しました。本研究では、正則化手法(L1/L2正則化)やデータ拡張の導入が汎化性能向上に有効であることを示唆。これにより、LSTMモデルをより実用的な短期予測ツールとして改良し、金融分析への応用可能性を広げる方向性が提示されています。
論文2:『ARIMA-GA-SVRによる株価予測モデル』

- ハイブリッドモデルによる高精度な株価予測
- この研究は、ARIMAとSVRを組み合わせたハイブリッドモデルで株価予測精度を向上させました。ARIMAは線形トレンドを捉え、SVRは非線形特性を補完。さらに、遺伝的アルゴリズム(GA)でSVRのパラメータを最適化し、AppleやTeslaの株価データでMSEやMAEが従来モデルを上回る結果を達成しました。この手法は、線形性と非線形性を効果的に統合し、短期予測における実用性と精度向上を実証しています。
- GAを活用したSVR最適化の有効性
- SVRのパラメータ(罰則係数 $C$ とカーネルパラメータ $γ$)を遺伝的アルゴリズム(GA)で最適化する手法を導入しました。これにより、手動調整より効率的に最適値を特定し、非線形パターンの捕捉能力を向上。AppleやTeslaの株価データでは、MSEやMAEが大幅に改善され、高精度な予測を実現しました。GAの活用により、計算効率を維持しつつ、金融市場での実用的な応用可能性を示しました。
論文3:『ARIMAモデルによる需要予測』

- 適応的予測手法の確立
- 本論文は、ARIMAモデルを活用した需要予測手法を体系化し、非定常性を解消する差分処理を導入することで予測の精度を向上させています。特に、新たなデータに基づきモデルを更新する「適応的予測」を提案し、データの変化に迅速に対応可能な柔軟性を実現。モデル次数の推定からパラメータの効率的な算出まで、一貫した手順が設計され、実際のデータへの適用性が高められています。この手法は、多様なシナリオに対応できる汎用的な予測手段として有用です。
- パラメータ推定の効率化
- 本論文では、ARIMAモデルの効率的なパラメータ推定手法として、自己相関関数(ACF)と偏自己相関関数(PACF)を用いてモデル次数を合理的に推定する方法を提案しています。さらに、修正版Gauss-Newton法を活用したアルゴリズムを開発し、誤差二乗和を最小化することで、計算効率と予測精度を両立。この手法は、複雑なモデルや大規模データにも適応可能であり、実用的かつ柔軟なアプローチを提供しています。
生成分野の紹介
生成タスクとは?
生成タスクでは、入力データを基に次の値を予測するだけでなく、新たなデータパターンを構築することが求められます。例えば、時系列データの生成では、単に次の値を予測するのではなく、新しい時系列パターンを作り出すことを目指します。このような生成は、データの拡張やシミュレーションに役立ち、異常検知や予測精度の向上、モデルの安定性の強化につながります。
| 種類 | 説明 | 主な活用分野 |
|---|---|---|
| テキスト生成 | 与えられた文脈や単語の並びから次の単語や文章を生成します。次の単語を逐次的に予測して自然な文脈を維持する技術が重要です。 | 詩や小説の自動生成、チャットボットの応答生成、要約文の生成など |
| 画像生成 | 入力画像や特徴量を基に新しい画像を作成します。ノイズから高解像度画像を生成するGANやスタイル転写技術などが含まれます。 | アート制作、自動デザイン、医療画像の生成など |
| 音声合成 | テキストや他の音声データを基に、新しい音声を合成します。音声アシスタントの自然な話し方の生成、エンターテイメントコンテンツの作成、音楽の自動生成などが例です。 | 音声アシスタント、エンターテイメント、音楽生成など |
生成モデルの基礎
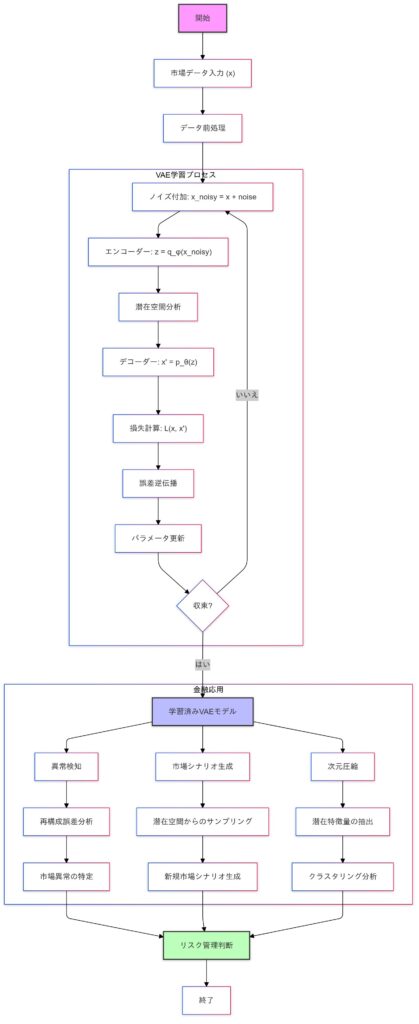
オートエンコーダや変分オートエンコーダ(VAE)は、データの潜在構造を学習し、新たなデータを生成する能力を持つため、生成モデルの基礎として広く用いられています。オートエンコーダは入力データを圧縮・復元する過程で特徴を抽出し、VAEは潜在変数に確率分布を導入することで、より滑らかで多様なデータ生成を可能にします。これらの特性により、未知のデータや新規サンプルの生成に適しています。
オートエンコーダ
オートエンコーダについては下記のブログを参考にしてみてください。

オートエンコーダーのイメージ
オートエンコーダの学習プロセス
金融時系列データの適用例
株価、為替レートなどの複雑なパターンを潜在空間に圧縮し、異常検知やノイズ除去、新しい視点の特徴抽出に活用されます。
特徴
- 非線形次元削減を実現(PCAの非線形版)。
- 潜在空間は時系列データの特徴を効率よく捉える。
PCAについては下記を参照して下さい。

データの形状と前処理
オートエンコーダを使用してデータを学習する前にデータの形状の確認と前処理を行う必要があります。
多変量化(マルチバリアント)
金融時系列データには、価格(始値、高値、安値、終値)、出来高、移動平均やボリンジャーバンドなどのテクニカル指標、さらには金利や他銘柄の価格といった外部要因が含まれます。オートエンコーダにこれらを入力する際は、過去N日分など一定期間のデータを同じ長さのベクトルやウィンドウにまとめることが重要です。
金融データの多変量化の実装例)
- 価格(始値、高値、安値、終値)、出来高、移動平均、ボリンジャーバンド、RSIなどのテクニカル指標を計算し、過去N日分のデータをシーケンスとしてまとめます。これによって金融時系列データを多変量化し、機械学習モデルに入力するための準備が整います。
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlib
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, start='2020-01-01', end='2023-12-31')
# テクニカル指標の計算
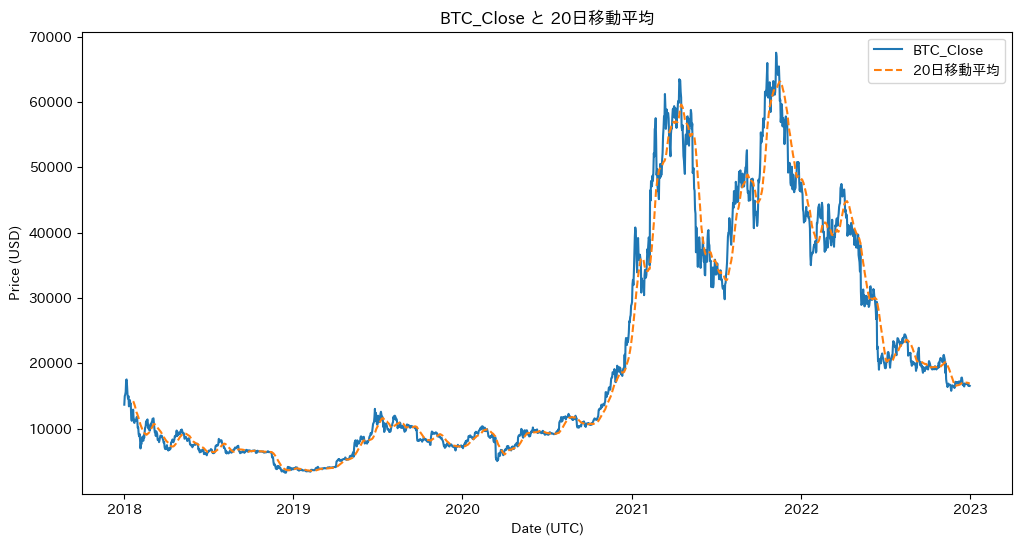
data['SMA_10'] = data['Close'].rolling(window=10).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
data['BB_upper'] = data['Close'].rolling(window=20).mean() + 2 * data['Close'].rolling(window=20).std()
data['BB_lower'] = data['Close'].rolling(window=20).mean() - 2 * data['Close'].rolling(window=20).std()
# RSIの計算関数
def compute_rsi(series, window=14):
delta = series.diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI_14'] = compute_rsi(data['Close'], window=14)
# 欠損値の除去
data.dropna(inplace=True)
# 特徴量の選択
features = ['Open', 'High', 'Low', 'Close', 'Volume', 'SMA_10', 'SMA_50', 'BB_upper', 'BB_lower', 'RSI_14']
data = data[features]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンスの作成
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length + 1):
x = data[i:i+seq_length]
xs.append(x)
return np.array(xs)
seq_length = 30
X = create_sequences(data_scaled, seq_length)
# データをテンソルに変換
X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
# データの形状を確認
print(f"Shape of X: {X.shape}") # (サンプル数, シーケンス長, 特徴量数)Using device: mps
[*********************100%***********************] 1 of 1 completed
Shape of X: (1382, 30, 10)スライディングウィンドウ(Rolling Window)
スライディングウィンドウは、時系列データを一定範囲で区切り、順次移動させて分析や特徴抽出を行う手法です。例えば、暗号通貨予測では過去5日間のデータを用いて1日ずつスライドさせ、モデルに入力します。局所的な特性を捉えたりノイズを軽減するのに効果的ですが、結果に影響を与えるウィンドウサイズの適切な設定が重要です。
- スライディングウィンドウの期間の選定
- スライディングウィンドウの期間は、分析目的やデータ特性に応じて選定します。短期(1〜7日)は暗号通貨の価格変動や短期トレンドを捉えるのに適し、中期(7〜30日)は月間トレンドやテクニカル指標、長期(30日以上)は市場全体の傾向や季節性の分析に用いられます。ウィンドウサイズの選定は、タスクや使用モデル(例:RNNやCNN)に依存し、交差検証や実験的アプローチによって最適化するのが一般的です。
# シーケンスの作成
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length + 1):
x = data[i:i+seq_length]
xs.append(x)
return np.array(xs)
seq_length = 30
X = create_sequences(data_scaled, seq_length)標準化・正規化
金融データは銘柄ごとにスケールやボラティリティが異なるため、平均0・分散1の標準化やMinMax正規化を行う必要があります。特に異常検知では、標準化により特徴量間のスケール不一致による誤検知を防ぐことが重要です。
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)主な応用シナリオ
異常検知
- 考え方
- オートエンコーダは、学習データに近いパターンを再構成し、異常なパターンは再構成誤差が大きくなる特性を利用します。これにより、金融時系列データでは、急落・急騰や異常な出来高変化などを検知することが可能です。
- 具体例
- オートエンコーダを株価や出来高の過去データに学習させ、特定の日付のパターンを再構成した際の再構成誤差を計算します。その誤差が閾値を超える場合、通常パターンからの逸脱と判断し、フラッシュクラッシュの検知などに活用します。
- メリット・注意点
- オートエンコーダは、非線形性を捉えられる点が強みであり、他のルールベース手法よりも柔軟な異常検知が可能です。ただし、学習データのバイアスや市場構造の変化(レジームチェンジ)により誤検知が発生することがあるため、モデルの結果をビジネス知見と併用して判断することが重要です。

RNN系Autoencoderを使った異常検知の実装)
多変量化した金融データをRNN系Autoencoderを使って異常検知を行うコード例を実装します。
- RNN系Autoencoderの定義
class RNNEncoder(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers):
super(RNNEncoder, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.rnn = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
out, _ = self.rnn(x, (h0, c0))
return out[:, -1, :]
class RNNDecoder(nn.Module):
def __init__(self, hidden_dim, output_dim, num_layers):
super(RNNDecoder, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.rnn = nn.LSTM(hidden_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x, seq_len):
x = x.unsqueeze(1).repeat(1, seq_len, 1)
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
out, _ = self.rnn(x, (h0, c0))
out = self.fc(out)
return out
class RNNAutoencoder(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers):
super(RNNAutoencoder, self).__init__()
self.encoder = RNNEncoder(input_dim, hidden_dim, num_layers)
self.decoder = RNNDecoder(hidden_dim, input_dim, num_layers)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded, x.size(1))
return decoded- 損失関数の定義
# 損失関数の定義
def loss_function(recon_x, x):
recon_loss = nn.MSELoss()(recon_x, x)
return recon_loss- モデルのインスタンス化とトレーニング
# モデルのインスタンス化
input_dim = X_tensor.shape[2]
hidden_dim = 64
num_layers = 2
model = RNNAutoencoder(input_dim, hidden_dim, num_layers).to(device)
# オプティマイザの定義
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# データローダーの作成
train_dataset = TensorDataset(X_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# トレーニング
num_epochs = 100
train_loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for batch_data in train_loader:
inputs = batch_data[0]
optimizer.zero_grad()
recon_outputs = model(inputs)
loss = loss_function(recon_outputs, inputs)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_epoch_loss = epoch_loss / len(train_loader)
train_loss_history.append(avg_epoch_loss)
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_epoch_loss:.4f}')
print("Autoencoder Training complete")
# トレーニング損失の可視化
plt.figure(figsize=(10, 5))
plt.plot(train_loss_history, label='Train Loss')
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()Epoch [80/100], Loss: 0.0013
Epoch [90/100], Loss: 0.0012
Epoch [100/100], Loss: 0.0014
Autoencoder Training complete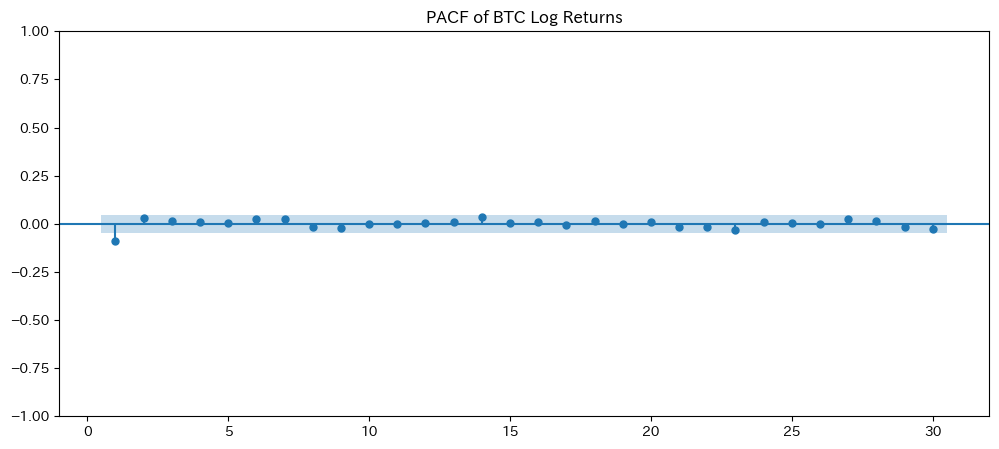
- 異常検知の実装
- モデルを評価モードで再構成誤差を計算し、95パーセンタイルを閾値として異常を判断し、その結果をプロットします。
# モデルを評価モードに設定
model.eval()
# 再構成誤差の計算
with torch.no_grad():
reconstructed = model(X_tensor)
loss = nn.MSELoss(reduction='none')(reconstructed, X_tensor)
reconstruction_errors = loss.mean(dim=(1, 2)).cpu().numpy()
# 閾値の設定
threshold = np.percentile(reconstruction_errors, 95)
print(f'Threshold for anomaly detection: {threshold}')
# 異常検知
anomalies = reconstruction_errors > threshold
print(f'Number of anomalies detected: {np.sum(anomalies)} out of {len(anomalies)}')Threshold for anomaly detection: 0.0025153413764201107
Number of anomalies detected: 70 out of 1382- 異常検知結果のプロット
# 異常検知結果のプロット(日本語化)
dates = data.index[seq_length-1:]
plt.figure(figsize=(14, 7))
plt.plot(dates, reconstruction_errors, label='再構成誤差')
plt.axhline(y=threshold, color='r', linestyle='--', label='閾値')
plt.scatter(dates[anomalies], reconstruction_errors[anomalies], color='red', label='異常')
plt.title('再構成誤差と異常検知')
plt.xlabel('日付')
plt.ylabel('再構成誤差')
plt.legend()
plt.show()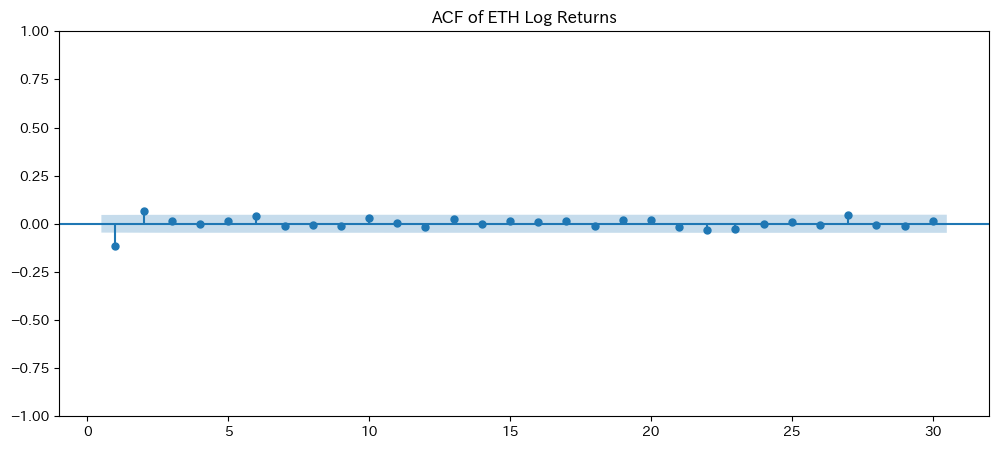
異常検知の正確性を評価するためには、再構成誤差のプロットやドメイン知識を活用して異常検知結果を確認することが重要です。
- 混同行列の作成と評価指標の計算
- 混同行列や評価指標を用いて異常検知の精度を定量的に評価することも有効で、これによりモデルの性能を客観的に評価し、必要に応じてモデルの改善を行うことができます。
# 実際の異常ラベル(例として異常が発生したインデックスを増やす)
actual_anomalies = np.zeros_like(reconstruction_errors)
actual_anomalies[[10, 50, 100, 200, 300, 400, 500]] = 1 # 異常インデックスの例を増やす
# 混同行列の作成
cm = confusion_matrix(actual_anomalies, anomalies)
print("Confusion Matrix:")
print(cm)
# 精度、再現率、F1スコアの計算
precision = precision_score(actual_anomalies, anomalies)
recall = recall_score(actual_anomalies, anomalies)
f1 = f1_score(actual_anomalies, anomalies)
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")Confusion Matrix:
[[1305 70]
[ 7 0]]
Precision: 0.0000
Recall: 0.0000
F1 Score: 0.0000混同行列の解釈
混同行列については下記のブログを参考にして下さい。

| 実際の正常 (0) | 実際の異常 (1) | |
|---|---|---|
| 予測が正常 (0) | 真陽性 (TP) | 偽陽性(FP) |
| 予測が異常 (1) | 偽陰性(FN) | 真陰性(TN) |
- TN (True Negative):1305
- モデルが正常と予測し、実際にも正常であった数。
- FP (False Positive):70
- モデルが異常と予測したが、実際には正常であった数。
- FN (False Negative):7
- モデルが正常と予測したが、実際には異常であった数。
- TP (True Positive):0
- モデルが異常と予測し、実際にも異常であった数。
異常検知の正確性を評価するための方法
| 段階 | チェックポイント |
|---|---|
| データの前処理と特徴量選択 | – 選択した特徴量(Open, High, Low, Close, Volume, SMA, BB, RSI)が適切かどうか。 – データの正規化が適切に行われているか。 |
| モデルのトレーニング | – モデルが十分にトレーニングされているか(エポック数、学習率など)。 – トレーニングデータが異常を含まない正常データであるか。 |
| 再構成誤差の閾値設定 | – 再構成誤差の閾値が適切に設定されているか(例えば、95パーセンタイル)。 – 閾値の設定方法がデータの特性に合っているか。 |
| 異常検知結果の評価 | – 検知された異常が実際に異常であるか(ドメイン知識を用いた評価)。 – 検知されなかった異常がないか(偽陰性の確認)。 |
モデル改善のための具体的なステップ
| カテゴリ | 詳細 |
|---|---|
| データの前処理の見直し | – 特徴量の選択を再評価し、異常検知に有効な特徴量を追加する。 – データの正規化方法を見直す。 |
| モデルのアーキテクチャの調整 | – RNNの層数やユニット数を増やして、モデルの表現力を高める。 – 他のモデル(例えば、GRUやTransformer)を試してみる。 |
| トレーニングデータの改善 | – トレーニングデータに異常データを含めるか、異常データを増やす。 – データ拡張技術を使用して、異常データを増やす。 |
| 閾値の設定の調整 | – 再構成誤差の閾値を適切に設定するために、異なる閾値を試してみる。 – ROC曲線やAUCを使用して、最適な閾値を見つける。 |
ノイズ除去(Denoising)
デノイジングオートエンコーダ(DAE)は市場の乱高下やノイズを緩和し、潜在的なトレンドを抽出しやすくするために、スパイクや外れ値をなめらかに再構成する効果があります。
デノイジングオートエンコーダについては下記を参照して下さい。
- 考え方
- デノイジングオートエンコーダは、入力データを一部破壊してから復元する仕組みを利用し、乱高下やノイズの多い時系列データをなめらかに再構成します。これにより、大きなスパイクや急激な外れ値を緩和しつつ、潜在的なトレンドを抽出しやすくする効果が期待できます。
- 応用例
- 高頻度取引データでは、秒単位やミリ秒単位での大きな変動が多く見られます。デノイジングオートエンコーダを活用すると、細かいノイズを平滑化した再構成データを取得でき、これをテクニカル分析やアルゴリズムトレードの入力データとして活用することが可能です。
デノイジングオートエンコーダの学習プロセス
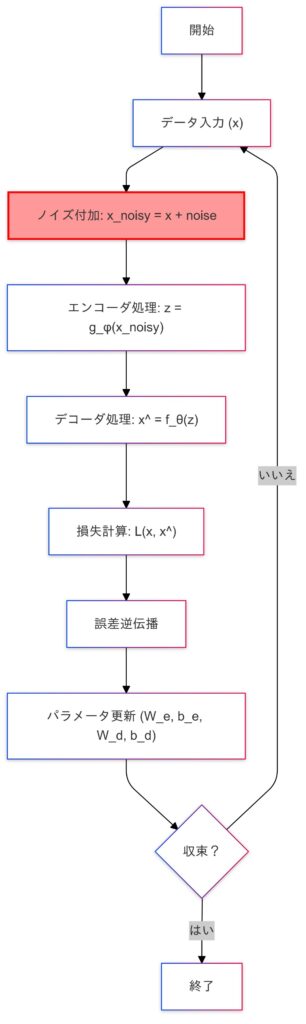
ノイズ処理の実装)
高頻度取引データ(秒単位またはミリ秒単位)を対象にデノイジングオートエンコーダを用いてノイズを平滑化した再構成データを取得し、テクニカル分析やアルゴリズムトレードに活用するためのコードを作成します。
詳しくはデータの前処理、デノイジングオートエンコーダモデルの構築と学習、再構成データの生成と可視化を含む実装です。
ライブラリをインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as pltデータの取得
# データの取得
ticker = 'ETH-USD'
# 高頻度データの取得期間を有効な値に設定(例: 過去5日間)
data = yf.download(ticker, period='5d', interval='1m') # 1分足データyfinanceで1分足などの高頻度データを取得する際は、期間を適切な値(例: ‘5d’や’1mo’)に設定する必要があります。取得後は、データが空でないか確認することを忘れないようにしましょう。長期間のデータが必要な場合は、インターバルを少し広げて(例: ‘5m’や’15m’)設定することで対応できる場合があります。それでも足りない場合は、Binance APIやCryptoCompare APIといった他のデータソースを検討すると良いでしょう。ただし、これらのサービスではAPIキーや利用料金が必要なこともあるため、事前の確認が大切です。
特徴量の選択と標準化
# 特徴量の選択(Open, High, Low, Close, Volume)
features = ['Open', 'High', 'Low', 'Close', 'Volume']
data = data[features]
# データの標準化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)ノイズの追加
# ノイズの追加関数
def add_noise(data, noise_factor=0.2): # ノイズファクターを調整
noisy_data = data + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=data.shape)
return np.clip(noisy_data, -3, 3) # 値の範囲を制限
# ノイズ付きデータの作成
data_noisy = add_noise(data_scaled)デノイジングオートエンコーダの入力としてノイズを追加します。
シーケンスの作成
# シーケンスの作成(スライディングウィンドウ)
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length):
x = data[i:(i + seq_length)]
xs.append(x)
return np.array(xs)
seq_length = 30 # シーケンス長を調整
X_clean = create_sequences(data_scaled, seq_length)
X_noisy = create_sequences(data_noisy, seq_length)スライディングウィンドウを用いてシーケンスデータを作成します。
テンソルへの変換
# テンソルへの変換
X_clean_tensor = torch.tensor(X_clean, dtype=torch.float32)
X_noisy_tensor = torch.tensor(X_noisy, dtype=torch.float32)データローダーの作成
# データローダーの作成
dataset = TensorDataset(X_noisy_tensor, X_clean_tensor)
train_loader = DataLoader(dataset, batch_size=128, shuffle=True)入力とターゲットのテンソルをまとめたデータセットを作成します。
デノイジングオートエンコーダモデルの定義
# デノイジングオートエンコーダモデルの定義(LSTMを使用)
class DenoisingAutoencoder(nn.Module):
def __init__(self, input_dim, encoding_dim):
super(DenoisingAutoencoder, self).__init__()
self.encoder = nn.LSTM(input_dim, encoding_dim, batch_first=True)
self.decoder = nn.LSTM(encoding_dim, input_dim, batch_first=True)
def forward(self, x):
encoded, _ = self.encoder(x)
decoded, _ = self.decoder(encoded)
return decodedモデルのインスタンス化とデバイス設定
# モデルのインスタンス化
input_dim = X_clean_tensor.shape[2]
encoding_dim = 32 # 隠れ層の次元数を調整
model = DenoisingAutoencoder(input_dim, encoding_dim)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)損失関数とオプティマイザの定義
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)学習ループ
# 学習ループ
num_epochs = 30 # エポック数を調整
for epoch in range(num_epochs):
for data in train_loader:
noisy_inputs, clean_inputs = data
noisy_inputs = noisy_inputs.to(device)
clean_inputs = clean_inputs.to(device)
optimizer.zero_grad()
outputs = model(noisy_inputs)
loss = criterion(outputs, clean_inputs)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')再構成データの生成
# 再構成データの生成
model.eval()
with torch.no_grad():
reconstructed = model(X_noisy_tensor.to(device)).cpu().numpy()model.eval()により、モデルを評価モードに設定し、ドロップアウトやバッチ正規化などの訓練特有の動作が無効になります。torch.no_grad()によりこのブロック内では勾配計算が無効になります。評価時には勾配計算が不要なため、メモリ使用量と計算コストを削減できます。- ノイズ付き入力データをモデルに通して再構成データを生成し、NumPy配列に変換します。
データの逆標準化
# データの逆標準化
reconstructed_data = scaler.inverse_transform(reconstructed.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)
original_data = scaler.inverse_transform(X_clean.reshape(-1, input_dim)).reshape(-1, seq_length, input_dim)可視化
# 可視化(Close価格の比較)
plt.figure(figsize=(14, 7))
plt.plot(original_data[:, -1, 3], label='Original Close') # 最後のシーケンスのClose価格をプロット
plt.plot(reconstructed_data[:, -1, 3], label='Reconstructed Close') # 最後のシーケンスのClose価格をプロット
plt.title('Original vs Reconstructed Close Prices')
plt.xlabel('Time Steps')
plt.ylabel('Close Price')
plt.legend()
plt.show()
print("処理が完了しました")Epoch [28/30], Loss: 0.6958
Epoch [29/30], Loss: 0.6223
Epoch [30/30], Loss: 0.6306
モデル性能改善案
ノイズ除去の精度向上の方法としてトランスフォーマーベースのデノイジングオートエンコーダなどを使う方法があります。その他には双方向LSTMの使用、ドロップアウトの追加、ハイパーパラメータの調整などが有効と言えます。その後再構成データを用いて、テクニカル分析やアルゴリズムトレードに活用することが可能です。
次元圧縮と特徴抽出
- 考え方
- 金融時系列データや出来高、テクニカル指標など数十〜数百の特徴量をオートエンコーダを用いてボトルネックで圧縮し、潜在空間ベクトル(例: 数次元)に変換することで、データの本質的な特徴を抽出できます。この方法は、PCAのような線形次元削減手法に比べ、非線形な構造を捉える能力に優れ、複雑なパターンの解析に適しています。
- 実務応用
- 数十銘柄以上のマルチアセットデータをオートエンコーダで学習し、潜在空間上の各銘柄をデータ点として分布を可視化・クラスタリングすることで、似た時系列パターンを持つ銘柄をグルーピングできます。この手法は、ポートフォリオ構築やリスク解析の際に有効な判断材料として活用できます。
特徴空間とは?
特徴空間とは、元の高次元データをオートエンコーダなどで次元削減し、データの重要なパターンを保持した低次元の空間です。その可視化は、データの分布やクラスタリング結果を視覚的に確認する目的で行われます。これにより、データ内のパターンや特定のグループ間の類似性を把握しやすくなり、分析結果の解釈や次の処理に役立てることができます。
- 特徴空間と潜在空間の関係(文脈の差異)
- 特徴空間は元の高次元データが存在する空間。
- 潜在空間は特徴空間から次元削減された低次元の空間。
特徴空間の可視化の実装)
# Autoencoderモデルの定義
class Autoencoder(nn.Module):
def __init__(self, input_dim, latent_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, latent_dim)
)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, input_dim)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
# モデルのインスタンス化
input_dim = data_scaled.shape[1]
latent_dim = 3 # 潜在空間の次元数
model = Autoencoder(input_dim, latent_dim)
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
# データのテンソル化
data_tensor = torch.tensor(data_scaled, dtype=torch.float32).to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習ループ
num_epochs = 100
batch_size = 32
for epoch in range(num_epochs):
for i in range(0, len(data_tensor), batch_size):
batch = data_tensor[i:i+batch_size]
optimizer.zero_grad()
encoded, decoded = model(batch)
loss = criterion(decoded, batch)
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 潜在空間への変換
model.eval()
with torch.no_grad():
latent_space, _ = model(data_tensor)
latent_space = latent_space.cpu().numpy()
# K-meansクラスタリング
kmeans = KMeans(n_clusters=3, random_state=0).fit(latent_space)
labels = kmeans.labels_
# 2次元散布図のプロット
plt.figure(figsize=(10, 7))
plt.scatter(latent_space[:, 0], latent_space[:, 1], c=labels, cmap='viridis')
plt.title('2D Latent Space')
plt.xlabel('Latent Dimension 1')
plt.ylabel('Latent Dimension 2')
plt.colorbar()
plt.show()
2次元の潜在空間の解釈:
- 2次元の潜在空間は、金融時系列データなどの高次元データを圧縮し、重要なパターンや構造を保持したまま2次元で可視化します。この空間では、時系列の順序に関係なく、類似したパターンを持つデータ点が近接してプロットされ、価格の動きやボラティリティの似た期間を直感的に分類することができます。
# 3次元散布図のプロット
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(latent_space[:, 0], latent_space[:, 1], latent_space[:, 2], c=labels, cmap='viridis')
plt.title('3D Latent Space')
ax.set_xlabel('Latent Dimension 1')
ax.set_ylabel('Latent Dimension 2')
ax.set_zlabel('Latent Dimension 3')
plt.colorbar(sc)
plt.show()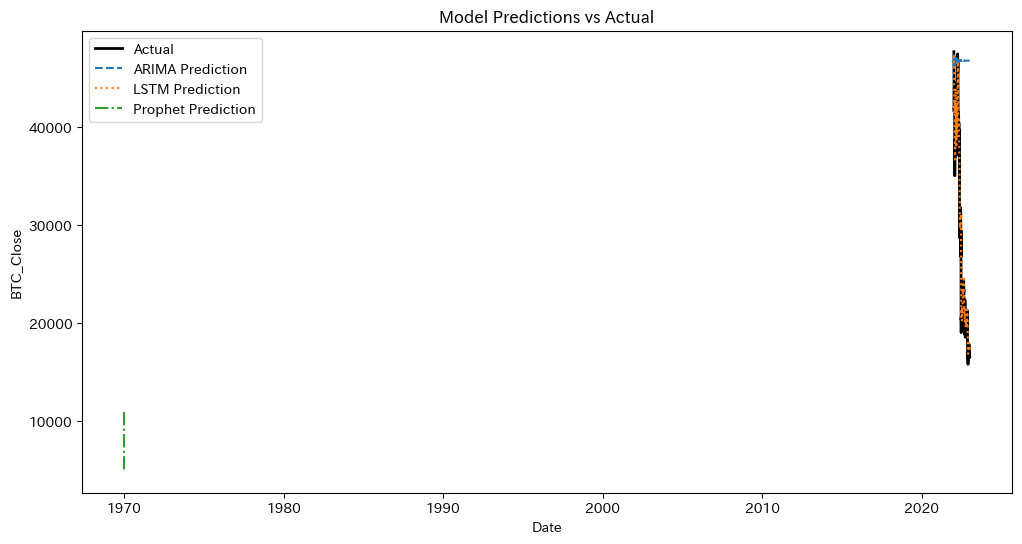
3次元の潜在空間の解釈:
- 3次元の潜在空間は、高次元データを圧縮し、データのパターンや構造を具体的に表現します。データ点の位置が詳細に示されるため、クラスタリング結果やパターンの類似性をより正確に確認可能です。特に、近接するデータ点は元の時系列データで類似した動きを持つことを示し、2次元よりも精度の高い分類が期待できます。
# クラスタリング結果のデータフレーム作成
clustered_data = pd.DataFrame(latent_space, columns=['Latent1', 'Latent2', 'Latent3'])
clustered_data['Cluster'] = labels
# クラスタごとのデータを表示
print(clustered_data.groupby('Cluster').mean())
# クラスタごとのデータをCSVに保存
clustered_data.to_csv('clustered_data.csv', index=False) Latent1 Latent2 Latent3
Cluster
0 -2.002071 0.292169 -2.889833
1 0.275859 -0.138511 2.956495
2 1.765697 -1.416945 0.213461- データのパターンの例:
- トレンド:長期的な価格の上昇や下降の傾向。
- サイクル:季節性や周期的な変動。
- ボラティリティ:価格変動の激しさ。
- 異常値:突発的な価格変動や異常な取引量。
金融時系列データの可視化は、データのパターンや構造を直感的に理解し、類似性の高いデータを特定するのに役立ちます。この結果は、ポートフォリオ構築やリスク解析において重要な材料となり、迅速で正確な意思決定を支えます。Pythonやデータ分析ツールを活用することで、可視化の効果や応用方法をより深く理解することができます。
ポートフォリオ構築とリスク解析について
- ポートフォリオ構築
| 手法 | 説明 |
|---|---|
| 分散投資 | 類似性の低い銘柄を選定することで、リスクを分散させることができます。クラスタリング結果を基に、異なるクラスタから銘柄を選定することで、ポートフォリオのリスクを低減できます。 |
| リバランス | クラスタリング結果を基に、ポートフォリオのリバランスを行うことで、リスクとリターンのバランスを最適化できます。 |
- リスク管理
| 手法 | 説明 |
|---|---|
| リスク要因の特定 | クラスタリング結果を基に、特定のクラスタに属する銘柄が共通して持つリスク要因を特定できます。これにより、リスク管理が容易になります。 |
| ストレステスト | 異なる市場条件下でのポートフォリオのパフォーマンスを評価するために、クラスタリング結果を活用できます。 |
| 直感的な理解 | 可視化により、データのパターンや構造を直感的に理解できるため、迅速かつ正確な意思決定が可能になります。 |
| リスク管理 | リスク要因を視覚的に確認することで、リスク管理が容易になります。異常値やボラティリティの変動を早期に発見し、適切な対応が可能になります。 |
| パフォーマンス評価 | ポートフォリオのパフォーマンスを視覚的に評価することで、リバランスや戦略の見直しが容易になります。 |
モデルの事前学習・教師なし特徴表現
- 考え方
- オートエンコーダを用いると、膨大なラベルなしデータから潜在空間上で意味のある特徴を抽出できます。このエンコーダ部分の重みを転用し、株価の上昇や下降予測といったラベルありタスクに初期化として利用することで、「事前学習 → 転移学習」の流れを実現できます。
- 事例
- 時系列分類タスクでは、例えば「特定の経済イベント発生前後の変動パターン」を予測する際に、オートエンコーダで学習したエンコーダの重みを初期化として利用することで、モデルの精度を向上させる手法があります。
事前学習(オートエンコーダ) → 転移学習
先ほどのオートエンコーダを事前学習として転移学習を行うことで転移学習を行わないモデルに比べて精度がどれぐらい違うのかを検証してみると事前学習にオートエンコーダモデルを用いることで少しだけ、性能が上がったと言えます。
転移学習ありモデル評価:
precision recall f1-score support
0 0.70 0.02 0.03 418
1 0.50 0.99 0.67 415
accuracy 0.50 833
macro avg 0.60 0.50 0.35 833
weighted avg 0.60 0.50 0.35 833
転移学習なしモデル評価:
precision recall f1-score support
0 0.53 0.02 0.04 418
1 0.50 0.98 0.66 415
accuracy 0.50 833
macro avg 0.52 0.50 0.35 833
weighted avg 0.52 0.50 0.35 833実装上のポイントと考慮事項
- RNN型AutoencoderやConv1D型Autoencoderの利用
- 金融時系列データはシーケンスデータであるため、単純な全結合ネットワークよりもRNN系(LSTMやGRU)や1次元Convを用いたオートエンコーダが有効です。特に、長期的な依存関係を捉える必要がある場合には、LSTM Encoder-Decoder構造の活用を検討すると良いでしょう。
- データ期間・レジームチェンジの影響
- 金融市場は時期によってボラティリティや相関構造が変化するため(レジームチェンジ)、長期間の古いデータを学習に含めると再構成誤差が高くなるリスクや、過去の異常パターンを「通常」と誤認するリスクがあります。このため、学習データを定期的に更新したり、複数のレジーム別にオートエンコーダを訓練する工夫が必要です。
- 評価指標の選択
- 異常検知では、「再構成誤差が一定閾値を超えたら異常」とする単純な基準や、ラベル付き異常データを用いたF1スコアで評価する方法があります。一方、ノイズ除去ではMSEやMAEに加え、予測タスクでのパフォーマンス向上度合いを総合的に判断することが重要です。
- 解釈性
- オートエンコーダなどの深層学習モデルは「なぜその再構成をしたのか」の解釈が難しいため、金融ではトレーダーや監査部門への説明責任を果たす必要があります。そのため、SHAPやLIMEといった解釈手法を併用することが有効です。
オートエンコーダに関する論文
論文1:『複数時間軸情報を用いたオートエンコーダーによる行動経済学的特性の抽出』

- マルチタイムスケール分析による異常検知
- 本研究では、自己符号化器(Autoencoder)を使って、金融データをさまざまな時間スケールで分析し、短期と長期それぞれの異常パターンを特定する手法を提案しています。異常の強さや正規化されたリターンを活用することで、より高精度な異常検知が可能になりました。
- 実践的応用可能性
- 本研究は、S&P500データを使った実験により、リスク管理や資産価格モデルへの応用の可能性を示しています。異常検知を活用して行動経済学的な要因を明らかにすることで、投資戦略や市場分析に役立つ実務的な成果を提供しています。
論文2:『拡散モデルを用いた条件付き金融時系列データ生成』

- 条件付き拡散モデル「CoFinDiff」の提案
- 「CoFinDiff」は、金融時系列データを生成するための革新的な条件付き拡散モデルです。このモデルでは、トレンドと実現ボラティリティを条件として指定し、それに基づいてデータを生成します。Haarウェーブレット変換を使って時系列データを画像形式に変換し、視覚的な特徴を活用することで、従来の数値ベース手法を超える精度と柔軟性を実現。さらに、クロスアテンション機構を導入し、条件の影響をモデル全体に効率的に反映。これにより、極端な市場状況や複雑な依存関係を再現可能なデータ生成が実現しました。
- 極端事象を再現可能なデータ生成能力
- CoFinDiffは、従来の金融データ生成モデルが苦手としていた極端な事象、例えばファットテールやボラティリティクラスタリングの再現に成功しました。このモデルを使えば、極端な市場環境を再現したデータを生成でき、取引アルゴリズムのリスク評価や極端事象への対応策を検討するのに役立ちます。
- アップサンプリングによる生成精度の向上
- CoFinDiffは、学習データ内の極端事象を強調するためにアップサンプリング手法を採用しました。このアプローチにより、トレンドやボラティリティといった極端な条件下でも一貫性のあるデータ生成が可能に。結果として、学習効率が向上し、より高精度な合成データの生成を実現しています。
論文3:『拡散モデルの金融時系列生成への応用』

- 金融時系列データ生成の革新的アプローチ
- 金融時系列データ生成に革新をもたらす新手法を提案しました。この研究では、拡散モデル(DDPMs)とウェーブレット変換を組み合わせ、時系列データを画像形式に変換して学習・生成を行います。このアプローチにより、トレンドやボラティリティの再現性が向上し、従来のGANやVAEでは難しかったファットテール性やボラティリティクラスタリングなど、金融市場特有の特徴を忠実に再現することに成功しました。
- 実データに近い多次元時系列生成の実現
- 提案モデルは、株価、価格スプレッド、取引量などの多次元時系列データを同時に生成できる手法です。実験結果では、生成データが実データの分布や日中の変動パターンと一致し、高い再現性を示しました。この技術は、取引アルゴリズムのリスク評価やシナリオ分析など、金融分野での幅広い応用可能性を提供します。
VAE(変分オートエンコーダ)
VAEは、確率分布を活用した生成と解析を統合した強力なツールです。金融時系列データにおいては、異常検知、データ生成、クラスタリングといった幅広い課題に対応可能です。
VAEの概要と目的
VAEは、入力データ $x$ を低次元の潜在変数 $z$ にマッピングすることで、データの圧縮と再構成を行う生成モデルです。さらに、潜在変数 $z$ を事前に定義した確率分布(通常は標準正規分布)に近づけるように学習し、新しいデータを生成する能力を持っています。
- エンコーダ
- 入力データ $x$ を潜在空間の分布$q_{\phi}(z \mid x)$にマッピング。
- デコーダ
- 潜在変数 $z$ から元データ $x$ を再構成するための確率分布$p_{\theta}(x \mid z)$。
数式による理論的背景
- ELBO(Evidence Lower Bound)の導出
- VAEの学習目標は、観測データ $x$ の対数尤度 $\log p_\theta(x)$ を最大化することです。ただし、この計算は潜在変数 $z$ の積分を含むため、直接計算が困難です。
$$\log p_{\theta}(x) = \log \int p_{\theta}(x, z) \, dz$$
代わりに、変分推論を用いて下界(ELBO)を最大化します。
$$\log p_{\theta}(x) \geq \mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)] – D_{\mathrm{KL}}(q_{\phi}(z|x) \| p(z))$$
項の説明
- 再構成誤差
$$\mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)]$$
デコーダによる観測データ $x$ の再構成誤差を表します。
$p_{\theta}(x \mid z)$はデコーダが生成したデータの分布(通常はガウス分布)で、実際の $x$ と比較されます。
- KLダイバージェンス
$$D_{KL}(q_{\phi}(z|x) \| p(z))$$
エンコーダが生成する潜在変数の分布$q_{\phi}(z \mid x)$を、事前分布$p(z)$(通常は標準正規分布)に近づけるよう正則化します。これにより、潜在空間の分布が滑らかになり、生成データの多様性が確保されます。
ELBOを具体化する
- 再構成誤差
- 通常、観測データ $x$ は多次元ガウス分布に従うと仮定します。そのため、再構成誤差は次のように計算されます。
$$\log p_{\theta}(x|z) \sim -\frac{1}{2} \|x – f_{\theta}(z)\|^2$$
ここで、$f_\theta(z)$ はデコーダの出力です。
- KLダイバージェンス
- エンコーダが生成する潜在変数の分布$q_{\phi}(z \mid x)$は、平均 $\mu$ と分散 $\sigma^2$ を持つ正規分布と仮定します。
$$q_{\phi}(z|x) = \mathcal{N}(z; \mu(x), \operatorname{diag}(\sigma^2(x)))$$
KLダイバージェンスは次のように計算されます。
$$D_{\text{KL}}(q_{\phi}(z|x) \| p(z)) = -\frac{1}{2} \sum_{i=1}^{d} \left( 1 + \log \sigma_i^2 – \mu_i^2 – \sigma_i^2 \right)$$
学習と最適化
VAEは以下の損失関数を最小化することで学習します。
$$\mathcal{L}(\theta, \phi; x) = \text{再構成誤差} + \text{KLダイバージェンス}$$
これをまとめると次の式になります。
$$\mathcal{L}(\theta, \phi; x) = \|x – f_\theta(z)\|^2 + \frac{1}{2} \sum_{i=1}^d \left( 1 + \log \sigma_i^2 – \mu_i^2 – \sigma_i^2 \right)$$
- 再パラメータ化トリック
- エンコーダから潜在変数 $z$ を直接サンプリングすると、勾配計算が不可能になります。そこで、再パラメータ化トリックを使い、サンプリングを次のように分解します。
$$z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})$$
これにより、損失関数を勾配降下法で最適化可能にします。
VAEモデルの動作イメージと具体的な適用例
今回は金融市場データを用いてVAEモデルの代表的な使い方である異常検知と市場シナリオ生成、次元圧縮について説明を行います。ノイズ除去に関してはデノイジングオートエンコーダを参照してください。
潜在空間の確率分布を活用するメリット
- サンプリングに基づく多様なシナリオ生成
- VAEは、潜在変数を確率分布(平均 μ と分散 σ²)として学習する点で従来のオートエンコーダと異なります。金融時系列データに応用すると、潜在空間からサンプリングしたベクトルを基に新たなデータを合成可能です。これにより、極端なボラティリティや未観測のパターンを含むシナリオを模擬生成でき、シナリオ分析やストレステストに役立ちます。
- 学習する確率分布を制約する利点
- 金融市場の「レジームチェンジ」や「非定常性」に対応するため、VAEではKLダイバージェンスを用いて潜在空間を標準正規分布に近づけます。これにより、過学習を防ぎつつ分布の滑らかさを維持し、未知の市場状態を生成する際も極端に偏ったシナリオを抑制できます。この特性は、安定したシナリオ分析やストレステストに有用です。
異常検知の仕組みと実装上のポイント
- 再構成誤差に基づく異常スコア
- VAEに市場データを入力すると、デコーダが再構成データを生成します。その際の再構成誤差(実際のデータと再構成データの差)が大きい場合、当該日のパターンは「学習済みの正常データ」から逸脱している可能性が高いと判断できます。
- 閾値設定の方法
- 異常検知では、統計的閾値(例: 平均+α倍の標準偏差)を利用する方法と、再構成誤差を基にロジスティック回帰やSVMで「異常/正常」を学習させる方法があります。特に、ラベル付き異常データを用意できる場合、再構成誤差を用いた二次分類器を学習することで、精度向上が期待できます。
- 長期依存とレジームチェンジへの対処
- VAEはサンプル単位で学習するため、過去数日〜数十日のウィンドウを1サンプルとして扱います。しかし、金融市場で長期トレンドの変化を異常として検知したい場合、短期間の特徴に偏る可能性があります。この課題を克服するため、RNN型VAE(LSTMやGRUを使用)や、定期的なモデル更新、レジームごとに異なるVAEを採用する工夫が有効です。
VAEを使った異常検知の実装例)
異常検知の考え方はオートエンコーダで説明しているので確認してみてください。今回の実装では改良されたVAEで時系列データを処理するために設計された変分オートエンコーダの一種『ImprovedVAE』を使ってみます。

必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlibデータの取得と前処理
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, start='2020-01-01', end='2023-12-31')
# テクニカル指標の計算
data['SMA_10'] = data['Close'].rolling(window=10).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
data['BB_upper'] = data['Close'].rolling(window=20).mean() + 2 * data['Close'].rolling(window=20).std()
data['BB_lower'] = data['Close'].rolling(window=20).mean() - 2 * data['Close'].rolling(window=20).std()
# RSIの計算関数
def compute_rsi(series, window=14):
delta = series.diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI_14'] = compute_rsi(data['Close'], window=14)
# 欠損値の除去
data.dropna(inplace=True)
# 特徴量の選択
features = ['Open', 'High', 'Low', 'Close', 'Volume', 'SMA_10', 'SMA_50', 'BB_upper', 'BB_lower', 'RSI_14']
data = data[features]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンスの作成
def create_sequences(data, seq_length):
xs = []
for i in range(len(data) - seq_length + 1):
x = data[i:i+seq_length]
xs.append(x)
return np.array(xs)
seq_length = 30
X = create_sequences(data_scaled, seq_length)
# データをテンソルに変換
X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
# データの形状を確認
print(f"Shape of X: {X.shape}") # (サンプル数, シーケンス長, 特徴量数)
# データをトレーニングセットと検証セットに分割
X_train, X_val = train_test_split(X_tensor, test_size=0.2, random_state=42)改良されたVAEモデルの定義
# 改良されたVAEモデルの定義(GRUを使用、層数を削減)
class ImprovedVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim, seq_length):
super(ImprovedVAE, self).__init__()
self.seq_length = seq_length
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
# エンコーダー
self.encoder_gru = nn.GRU(input_dim, hidden_dim, num_layers=1, batch_first=True, bidirectional=True)
self.fc_mu = nn.Linear(hidden_dim * 2, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim * 2, latent_dim)
# デコーダー
self.decoder_fc = nn.Linear(latent_dim, hidden_dim * 2)
self.decoder_gru = nn.GRU(hidden_dim * 2, hidden_dim, num_layers=1, batch_first=True)
self.output_layer = nn.Linear(hidden_dim, input_dim)
self.sigmoid = nn.Sigmoid()
def encode(self, x):
_, h = self.encoder_gru(x)
h = torch.cat((h[-2], h[-1]), dim=1)
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
hidden = self.decoder_fc(z)
hidden = hidden.unsqueeze(0).repeat(self.seq_length, 1, 1).permute(1, 0, 2)
decoded, _ = self.decoder_gru(hidden)
decoded = self.output_layer(decoded)
decoded = self.sigmoid(decoded)
return decoded
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
recon_x = self.decode(z)
return recon_x, mu, logvar損失関数の定義
# 損失関数の定義(再構成誤差の重みを大きくする)
def loss_function(recon_x, x, mu, logvar):
recon_loss = nn.MSELoss()(recon_x, x)
kl_loss = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return 2 * recon_loss + kl_loss # 再構成誤差の重みを2倍にする潜在次元の最適化
hidden_dim = 64
# 潜在次元の候補
latent_dims = [2, 3, 5, 10, 20, 30]
best_val_loss = float('inf')
best_latent_dim = None
best_model_state = None
for latent_dim in latent_dims:
model = ImprovedVAE(X_tensor.shape[2], hidden_dim, latent_dim, seq_length).to(device)
optimizer = optim.Adam(model.parameters(), lr=5e-4)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5, factor=0.5, verbose=True)
train_dataset = TensorDataset(X_train)
val_dataset = TensorDataset(X_val)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
num_epochs = 50
train_loss_history = []
val_loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_train_loss = 0
for batch_data in train_loader:
inputs = batch_data[0]
optimizer.zero_grad()
recon_outputs, mu, logvar = model(inputs)
loss = loss_function(recon_outputs, inputs, mu, logvar)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
avg_train_loss = epoch_train_loss / len(train_loader)
train_loss_history.append(avg_train_loss)
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for batch_data in val_loader:
inputs = batch_data[0]
recon_outputs, mu, logvar = model(inputs)
loss = loss_function(recon_outputs, inputs, mu, logvar)
epoch_val_loss += loss.item()
avg_val_loss = epoch_val_loss / len(val_loader)
val_loss_history.append(avg_val_loss)
scheduler.step(avg_val_loss)
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
best_latent_dim = latent_dim
best_model_state = model.state_dict()
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f'Latent Dim {latent_dim}, Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}')
# 最良モデルのロード
model = ImprovedVAE(X_tensor.shape[2], hidden_dim, best_latent_dim, seq_length).to(device)
model.load_state_dict(best_model_state)Latent Dim 2, Epoch [50/50], Train Loss: 0.0988, Val Loss: 0.1085
Latent Dim 3, Epoch [50/50], Train Loss: 0.1014, Val Loss: 0.1086
Latent Dim 5, Epoch [50/50], Train Loss: 0.0985, Val Loss: 0.1085
Latent Dim 10, Epoch [50/50], Train Loss: 0.0889, Val Loss: 0.1011
Latent Dim 20, Epoch [1/50], Train Loss: 0.1422, Val Loss: 0.1281
Latent Dim 30, Epoch [50/50], Train Loss: 0.0590, Val Loss: 0.0643学習と検証の損失をプロット
# 学習と検証の損失をプロット
plt.figure(figsize=(10, 5))
plt.plot(train_loss_history, label='Train Loss')
plt.plot(val_loss_history, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()再構成誤差の計算と異常検知
# モデルを評価モードに設定
model.eval()
# 再構成誤差の計算
with torch.no_grad():
reconstructed = model(X_tensor)[0]
loss = nn.MSELoss(reduction='none')(reconstructed, X_tensor)
reconstruction_errors = loss.mean(dim=(1, 2)).cpu().numpy()
# 閾値の設定
threshold = np.percentile(reconstruction_errors, 95)
print(f'Threshold for anomaly detection: {threshold}')
# 異常検知
anomalies = reconstruction_errors > threshold
print(f'Number of anomalies detected: {np.sum(anomalies)} out of {len(anomalies)}')
# 異常検知結果のプロット(日本語化)
dates = data.index[seq_length-1:]
plt.figure(figsize=(14, 7))
plt.plot(dates, reconstruction_errors, label='再構成誤差')
plt.axhline(y=threshold, color='r', linestyle='--', label='閾値')
plt.scatter(dates[anomalies], reconstruction_errors[anomalies], color='red', label='異常')
plt.title('再構成誤差と異常検知')
plt.xlabel('日付')
plt.ylabel('再構成誤差')
plt.legend()
plt.show()Threshold for anomaly detection: 0.041419203951954864
Number of anomalies detected: 70 out of 1382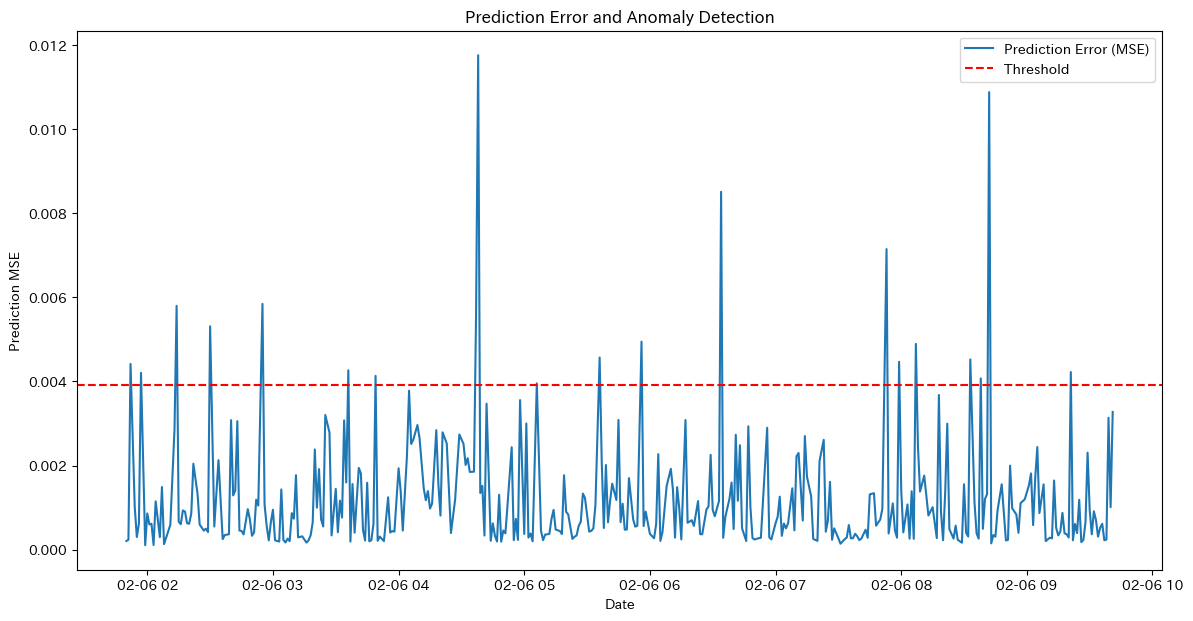
混合行列と評価指標の計算
# 実際の異常ラベル(例として異常が発生したインデックスを増やす)
actual_anomalies = np.zeros_like(reconstruction_errors)
actual_anomalies[[10, 50, 100, 200, 300, 400, 500]] = 1 # 異常インデックスの例を増やす
# 混同行列の作成
cm = confusion_matrix(actual_anomalies, anomalies)
print("Confusion Matrix:")
print(cm)
# 精度、再現率、F1スコアの計算
precision = precision_score(actual_anomalies, anomalies)
recall = recall_score(actual_anomalies, anomalies)
f1 = f1_score(actual_anomalies, anomalies)
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")Confusion Matrix:
[[1305 70]
[ 7 0]]
Precision: 0.0000
Recall: 0.0000
F1 Score: 0.0000このモデルの異常検知の結果は良いとは言えませんが、まだ、改善の余地があるということを示していると言えます。
市場シナリオ分析と新規データ生成
市場シナリオの生成
- VAEは「市場の特徴」を潜在空間という低次元な空間に圧縮します。
- この潜在空間を利用して、過去のデータに基づいた「新しい市場シナリオ」を合成できます。
- 例:過去にはなかったけれど「起こりそうな市場の動き」を仮定する。
ストレステスト・シミュレーション
- VAEでは、潜在空間内のデータを意図的に「平均から外れた」位置に変更して、新しいシナリオを生成することができます。
- 例:極端な市場下落やボラティリティ急上昇のシナリオを想定し、ポートフォリオへの影響を分析できます。
現実性の検証
- 生成されたシナリオが「現実的かどうか」を確認する必要があります。
- トレーダーやリスク管理者の知識を使い、「市場の規則や原理に基づいているか」を検証します。
- 例:現実離れしたシナリオは実務では役に立たないため、生成結果をフィルタリングします。
課題:
この手法は生成データが実データの分布や日中の変動パターンと一致し、高い再現性を示す必要があり、現状VAEではあまり良い結果が出ませんでしたので実装はやめておこうと思います。
オートエンコーダの論文で紹介した、『拡散モデルの金融時系列生成への応用』などの手法を用いることで取引アルゴリズムのリスク評価やシナリオ分析など、金融分野での幅広い応用可能性を探ることが可能です。
マルチアセット解析とクラスタリング
- VAEを用いることで、多銘柄・多市場のデータを学習し、非線形な相関やグループ化を把握することが可能です。潜在空間上でクラスタリングを行い、ポートフォリオの分散投資やリスク管理に役立てる具体例が挙げられます。また、PCAのような線形手法と比較することで、VAEの非線形次元削減の強みを直感的に理解することができます。
VAEによる潜在空間の可視化とPCAによる線形手法との比較の実装例)
必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCAデータの取得と前処理
tickers = ["ETH-USD", "BTC-USD", "XRP-USD"]
start_date = "2022-01-01"
end_date = "2023-01-01"
dfs = []
for t in tickers:
df_tmp = yf.download(t, start=start_date, end=end_date)[["Open","High","Low","Close","Volume"]].dropna()
df_tmp["Asset"] = t # 後で区別しやすいように銘柄名を追加
dfs.append(df_tmp)
df_all = pd.concat(dfs, axis=0)
df_all.sort_values(by=['Asset','Date'], inplace=True)
# スケーリング
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df_all[["Open","High","Low","Close","Volume"]])
# スライディングウィンドウ
seq_length = 30
def create_sequences(data, assets, seq_len):
seqs = []
labels = []
unique_assets = assets.unique()
# assetごとに時系列サンプル生成
for asset in unique_assets:
idx = (assets == asset).values
subset = data[idx]
for i in range(len(subset) - seq_len):
seq = subset[i : i + seq_len]
seqs.append(seq)
labels.append(asset)
return np.array(seqs), np.array(labels, dtype=object)
X, asset_labels = create_sequences(scaled_data, df_all["Asset"], seq_length)
X_tensor = torch.tensor(X, dtype=torch.float32)VAEモデルの構築 (GRUエンコーダ/デコーダ、潜在次元=2)
class GRUVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
# Encoder
self.gru_enc = nn.GRU(input_dim, hidden_dim, batch_first=True)
self.mu_layer = nn.Linear(hidden_dim, latent_dim)
self.logvar_layer = nn.Linear(hidden_dim, latent_dim)
# Decoder
self.latent_to_hidden = nn.Linear(latent_dim, hidden_dim)
self.gru_dec = nn.GRU(hidden_dim, hidden_dim, batch_first=True)
self.output_layer = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
_, h = self.gru_enc(x)
h = h[-1]
mu = self.mu_layer(h)
logvar = self.logvar_layer(h)
return mu, logvar
def reparam(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z, seq_len=30):
hidden = self.latent_to_hidden(z).unsqueeze(0)
dec_input = torch.zeros((z.size(0), seq_len, self.hidden_dim), device=z.device)
dec_output, _ = self.gru_dec(dec_input, hidden)
return self.output_layer(dec_output)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparam(mu, logvar)
recon = self.decode(z, x.size(1))
return recon, mu, logvar
input_dim = X_tensor.shape[2]
hidden_dim = 64学習と交差検証
# 潜在次元の候補
latent_dims = [2, 3, 5, 10]
best_val_loss = float('inf')
best_latent_dim = None
best_model_state = None
for latent_dim in latent_dims:
model = GRUVAE(input_dim, hidden_dim, latent_dim).float()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.MSELoss()
def vae_loss(recon, x, mu, logvar):
recon_loss = criterion(recon, x)
kl = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl
# 3. 学習と交差検証
batch_size = 32
epochs = 10
train_dataset = torch.utils.data.TensorDataset(X_train)
val_dataset = torch.utils.data.TensorDataset(X_val)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
train_losses = []
val_losses = []
model.train()
for ep in range(epochs):
total_train_loss = 0
total_val_loss = 0
# トレーニング
model.train()
for batch_data in train_loader:
batch_data = batch_data[0]
optimizer.zero_grad()
recon, mu, logvar = model(batch_data)
loss = vae_loss(recon, batch_data, mu, logvar)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
avg_train_loss = total_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 検証
model.eval()
with torch.no_grad():
for batch_data in val_loader:
batch_data = batch_data[0]
recon, mu, logvar = model(batch_data)
loss = vae_loss(recon, batch_data, mu, logvar)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_loader)
val_losses.append(avg_val_loss)
# 最良モデルの保存
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
best_latent_dim = latent_dim
best_model_state = model.state_dict()
print(f"Latent Dim {latent_dim}, Epoch {ep+1}/{epochs}, Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}")
# 最良モデルのロード
model = GRUVAE(input_dim, hidden_dim, best_latent_dim).float()
model.load_state_dict(best_model_state)
# 学習と検証の損失をプロット
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()潜在空間への埋め込み
model.eval()
with torch.no_grad():
_, mu_all, _ = model(X_tensor)
latent_data = mu_all.numpy()クラスタリングと可視化
# K-meansクラスタリング
kmeans = KMeans(n_clusters=3, random_state=42).fit(latent_data)
labels_km = kmeans.labels_
# クラスタごとの銘柄比率を簡単に表示
df_latent = pd.DataFrame({"Asset": asset_labels, "Cluster": labels_km})
print(df_latent.groupby(["Cluster","Asset"]).size())
# 結果の可視化 (2D)
plt.figure(figsize=(8,6))
for cluster in np.unique(labels_km):
idx = labels_km == cluster
plt.scatter(latent_data[idx, 0], latent_data[idx, 1], label=f"Cluster {cluster}")
plt.title("Latent Space (VAE) with K-means Clusters")
plt.xlabel("Z1")
plt.ylabel("Z2")
plt.legend()
plt.show()
# PCAと比較
pca = PCA(n_components=2)
pca_data = pca.fit_transform(X_tensor.view(-1, input_dim).numpy())
labels_pca = KMeans(n_clusters=3, random_state=42).fit_predict(pca_data)
plt.figure(figsize=(8,6))
for cluster in np.unique(labels_pca):
idx = labels_pca == cluster
plt.scatter(pca_data[idx, 0], pca_data[idx, 1], label=f"Cluster {cluster}")
plt.title("PCA Space with K-means Clusters")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.legend()
plt.show()Latent Dim 2, Epoch 10/10, Train Loss: 1.0106, Val Loss: 0.9116
Latent Dim 3, Epoch 10/10, Train Loss: 0.5067, Val Loss: 0.4491
Latent Dim 5, Epoch 5/10, Train Loss: 1.0048, Val Loss: 0.8415
Latent Dim 10, Epoch 10/10, Train Loss: 0.3105, Val Loss: 0.3096
Cluster Asset
0 ETH-USD 335
XRP-USD 335
1 BTC-USD 201
2 BTC-USD 134
dtype: int64
3D可視化
# 6. 3D可視化が必要な場合 (例)
# latent_dim=3 でVAEを定義後、下記のように描画可
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
for cluster in np.unique(labels_km_3d):
idx = labels_km_3d == cluster
ax.scatter(latent_data_3d[idx, 0], latent_data_3d[idx, 1], latent_data_3d[idx, 2], label=f"Cluster {cluster}")
ax.set_title("Latent Space (VAE) with K-means Clusters (3D)")
ax.set_xlabel("Z1")
ax.set_ylabel("Z2")
ax.set_zlabel("Z3")
ax.legend()
plt.show()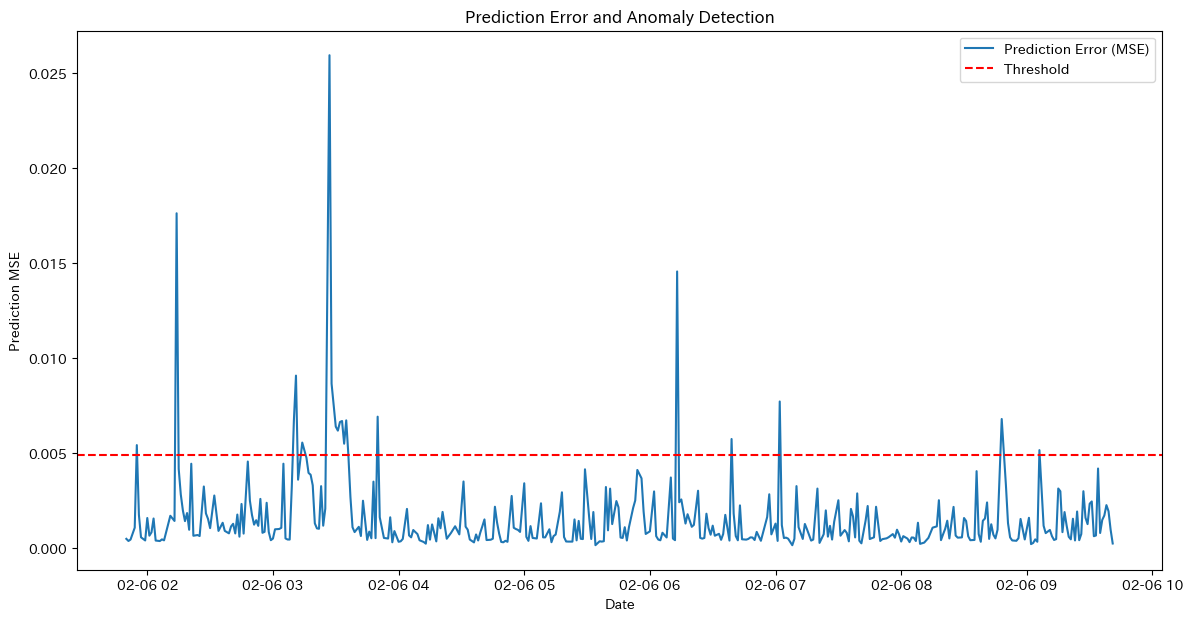
潜在空間とPCAのプロットの特徴量
- 潜在空間のプロット
- VAEが学習した潜在変数は、元の高次元データ(Open、High、Low、Close、Volume)の重要な特徴を圧縮して表現したものです。
- PCAのプロット
- PCAは、元の高次元データを分散が最大となる主成分方向に線形変換し、低次元空間に射影する手法です。
潜在空間とPCAのプロットの用途
- 潜在空間でのクラスタリングは、市場構造の理解、異なるアセット間の関係性把握、リスク分散を考慮したポートフォリオ最適化、さらに異常なアセットの検出(異常検知)に役立ちます。
VAEに関する論文
論文1:『TimeVAE: A Variational Auto-Encoder for Multivariate Time Series Generation』

- 高精度と効率性の両立
- TimeVAEは、少ないデータでも時系列データの特徴を正確に再現できるモデルです。ノイズを減らしながら、予測タスクでも高い精度を発揮し、さらに短時間で効率的に学習を完了できます。
- 解釈可能な生成モデル
- Interpretable TimeVAEは、トレンドや季節性といった時間的パターンを組み込める特別なデコーダー設計を採用しています。これにより、生成されたデータが分かりやすく、ドメイン知識を活用しやすいモデルとなっています。
論文2:『Time-Causal VAE: Robust Financial Time Series Generator』

- 因果性制約による分布整合性の向上
- TC-VAEは、生成データと実際の市場データの整合性を保証するため、因果的ワッサースタイン距離を損失関数に採用しています。この工夫により、価格設定やヘッジングといった動的な最適化問題で、より信頼性の高い結果を得られるようになっています。
- RealNVP統合による潜在空間の改善
- TC-VAEはRealNVPを組み込むことで、潜在空間の分布を実データに近づけ、生成データの質を向上させています。これにより、ボラティリティクラスタリングなどの金融市場の特徴を正確に再現し、価格設定やリスク管理といった実際の応用での有用性が高まります。
- 実データと生成データの多角的評価
- TC-VAEは、生成データの質を切片ワッサースタイン距離やMMDなどの統計指標で評価し、実データとの比較を行いました。その結果、生成データはボラティリティクラスタリングなどの市場特性を再現しながら、市場データセットに多様性を加えることができると確認されました。
VAE実装時のポイント
VAE実装時のポイントとして、データは標準化や対数変換でスケールを揃えることが重要です。潜在次元は交差検証で最適化し、少なすぎると情報損失、多すぎると過学習のリスクがあります。また、MLP型だけでなく、長期依存を考慮したLSTMやGRUを用いたRNN型VAEも有効です。
VAEは、金融市場の複雑性を潜在空間に効率よく反映する手法として、異常検知、データ生成、特徴抽出など多彩な応用可能性を持っています。この手法を実際に運用する際には、事前処理やハイパーパラメータの調整を十分に検討する必要があります。
生成分野におけるRNNモデルの必要性と組み合わせの利点
RNNモデルの必要性
- 時間的依存関係の学習
- 時系列データや連続したデータのパターンを捉える。
- データの生成能力
- シーケンスデータの次のステップや新しいパターンを生成。
モデル選定のポイント
| モデル | 特徴 | 適用分野 | メリット | デメリット |
|---|---|---|---|---|
| RNN | 基本的なリカレント構造で、短期的依存関係を学習。 | 短い時系列、基本的生成タスク | シンプルで軽量。設計と実装が容易。 | 勾配消失問題により長期依存関係を学習困難。 |
| LSTM | 長期的依存関係を学習するためのセル状態とゲート機構を持つ。 | 長期依存が重要な生成タスク | 長期的な依存関係を効果的にモデル化。 | パラメータが多く計算コストが高い。 |
| GRU | LSTMの簡略版。更新ゲートとリセットゲートを持つ。 | 長期依存が中程度の生成タスク | パラメータ数が少なく、計算効率が高い。 | 非線形な複雑データへの適応性がやや低い。 |
RNNとオートエンコーダ/VAEの組み合わせ
生成分野では、RNNモデルをオートエンコーダやVAEと組み合わせることで、以下のような性能向上が期待できます。
| 組み合わせ | 特徴・利点 | 適用例 |
|---|---|---|
| RNN + Autoencoder | データの圧縮と再構成を行いつつ、シーケンス全体のパターンを学習可能。 | 時系列の異常検知、ノイズ除去 |
| LSTM + Autoencoder | 長期依存を考慮したデータ圧縮。 | 音声やテキストの特徴抽出、データ再構成 |
| GRU + Autoencoder | 効率的な特徴抽出と短中期的なシーケンス依存の生成。 | リアルタイムシーケンスデータの再構成と生成 |
| RNN + VAE | 確率分布の学習を加え、生成データの多様性を向上。 | 金融時系列のシナリオ生成、自然言語生成 |
| LSTM + VAE | 長期的依存関係を学習した上で、新規データを生成。 | 時系列の異常検知、ストレステストシミュレーション |
| GRU + VAE | 効率的に分布を学習しつつ、短中期の依存関係を捉えた生成を実現。 | 高頻度データの生成、ノイズ除去 |
リカレントニューラルネットワーク(RNN)の基礎
RNNの概要と特徴
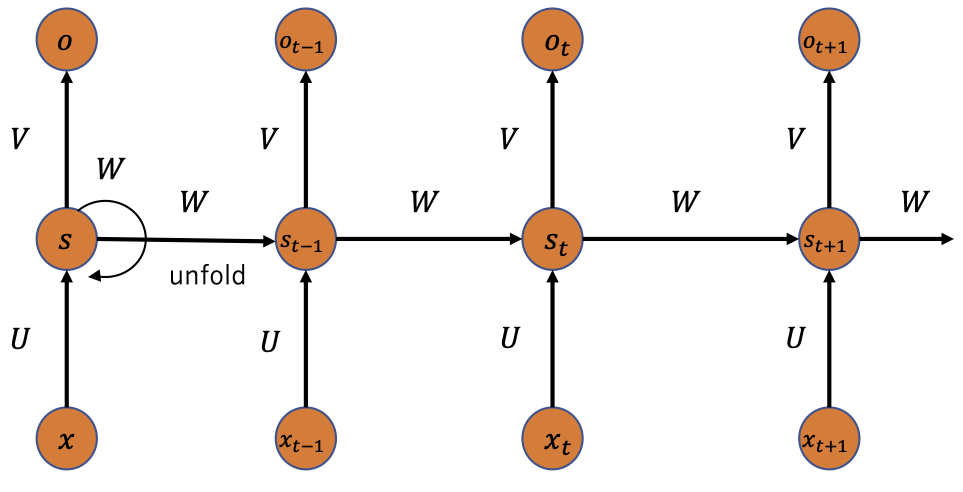
- RNNは、時系列データやシーケンスデータを処理するために設計されたニューラルネットワークの一種です。その主な特徴は、隠れ状態(Hidden State)を用いることで、現在の入力だけでなく過去の情報も考慮して次の出力を計算できる点にあります。
構造の特徴
- RNNは従来のニューラルネットワークと異なり、時間的依存関係をモデル化します。これにより、過去の情報を利用して現在の出力を決定できます。
主な適用例
- テキスト生成、音声認識、時系列予測、自然言語処理(NLP)など、多くの時間依存データに対応します。
動作の仕組み
- 各時刻 $t$ で隠れ状態 $h_t$ を更新し、出力 $y_t$ を生成します。隠れ状態は過去の情報を保持し、次の時刻に引き継がれるため、連続データのパターンを学習できます。
RNNの数式
- 隠れ状態の更新式
$$s_t = f(W s_{t-1} + U x_t)$$
$s_t$:時刻 $t$ の隠れ状態。$s_t−1$:前時刻の隠れ状態。$x_t$: 時刻 $t$ の入力。$W$:隠れ状態の重み行列。$U$:入力から隠れ状態への重み行列。$f$:活性化関数(通常はtanhやReLU)。
- 出力の計算式
$$o_t = g(V s_t)$$
$o_t$:時刻 $t$ の出力。$V$:隠れ状態から出力への重み行列。$g$:出力層の活性化関数(タスクによる)。
RNNのメリットとデメリット
| メリット | デメリット |
|---|---|
| 時間的依存関係を明示的にモデリング可能。 | 勾配消失や勾配爆発問題により長期的依存関係を学習しにくい。 |
| テキスト、音声、時系列などのシーケンスデータに対して適用可能。 | 並列処理が難しく、トレーニング時間が長い。 |
| シンプルな構造で実装が容易。 | パラメータ数が多い場合、過学習のリスクがある。 |
| 入力データの順序に敏感であり、自然な流れを保持した処理が可能。 | 大規模なデータセットでは計算資源の消費が高い。 |
RNNの適用例
| 応用分野 | 具体例 |
|---|---|
| 時系列予測 | 株価、気象データ、センサーデータなどの将来値を予測。 |
| 自然言語処理 | テキスト生成、機械翻訳、文章の感情分析。 |
| 音声認識 | 音声からテキストへの変換。 |
| 異常検知 | 時系列データの異常パターンを検出。 |
RNNの実装例)
- この例では、ETH-USDの価格データを使用して、次の日の価格を予測するためのRNNモデルを構築します。
必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlibデータの取得と前処理
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, start='2020-01-01', end='2024-1-16')
# 特徴量の選択
data = data[['Close']]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンスの作成
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 30
X, y = create_sequences(data_scaled, seq_length)
# データをテンソルに変換
X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
y_tensor = torch.tensor(y, dtype=torch.float32).to(device)
# データをトレーニングセットと検証セットに分割
X_train, X_val, y_train, y_val = train_test_split(X_tensor, y_tensor, test_size=0.2, random_state=42)Using device: mps
[*********************100%***********************] 1 of 1 completedSimpleRNNモデルの定義
class SimpleRNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super(SimpleRNN, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.rnn = nn.RNN(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(device)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return outモデルの学習
# モデルのインスタンス化
input_dim = X_tensor.shape[2]
hidden_dim = 64
output_dim = 1
num_layers = 1
model = SimpleRNN(input_dim, hidden_dim, output_dim, num_layers).to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# データローダーの作成
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# トレーニング
num_epochs = 100
train_loss_history = []
val_loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_train_loss = 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
avg_train_loss = epoch_train_loss / len(train_loader)
train_loss_history.append(avg_train_loss)
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
epoch_val_loss += loss.item()
avg_val_loss = epoch_val_loss / len(val_loader)
val_loss_history.append(avg_val_loss)
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}')
print("Training complete")Epoch [80/100], Train Loss: 0.0005, Val Loss: 0.0006
Epoch [90/100], Train Loss: 0.0004, Val Loss: 0.0005
Epoch [100/100], Train Loss: 0.0004, Val Loss: 0.0005
Training complete学習と検証の損失をプロット
plt.figure(figsize=(10, 5))
plt.plot(train_loss_history, label='Train Loss')
plt.plot(val_loss_history, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
モデルの評価
model.eval()
with torch.no_grad():
train_predictions = model(X_train).cpu().numpy()
val_predictions = model(X_val).cpu().numpy()
# 逆正規化
train_predictions = scaler.inverse_transform(train_predictions)
val_predictions = scaler.inverse_transform(val_predictions)
y_train_actual = scaler.inverse_transform(y_train.cpu().numpy().reshape(-1, 1))
y_val_actual = scaler.inverse_transform(y_val.cpu().numpy().reshape(-1, 1))
# 評価指標の計算
train_rmse = np.sqrt(mean_squared_error(y_train_actual, train_predictions))
val_rmse = np.sqrt(mean_squared_error(y_val_actual, val_predictions))
print(f'Train RMSE: {train_rmse:.4f}')
print(f'Validation RMSE: {val_rmse:.4f}')Train RMSE: 96.0457
Validation RMSE: 105.3713予測結果のプロット
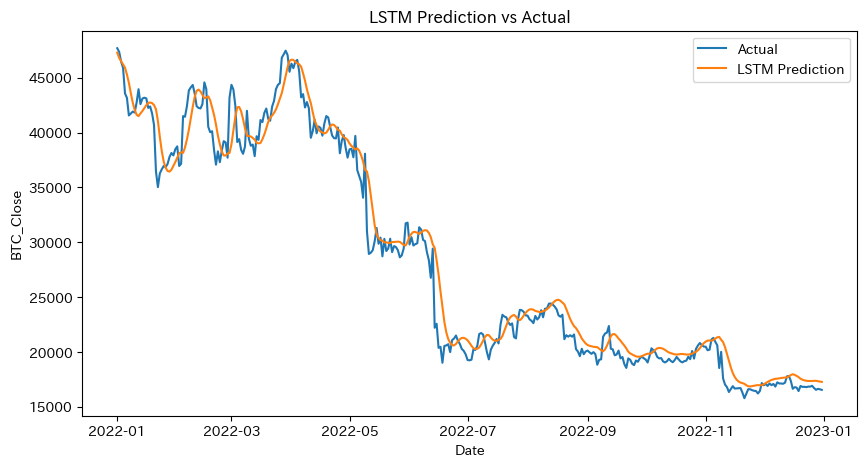
plt.figure(figsize=(14, 7))
plt.plot(y_val_actual, label='Actual')
plt.plot(val_predictions, label='Predicted')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.title('Actual vs Predicted Prices')
plt.show()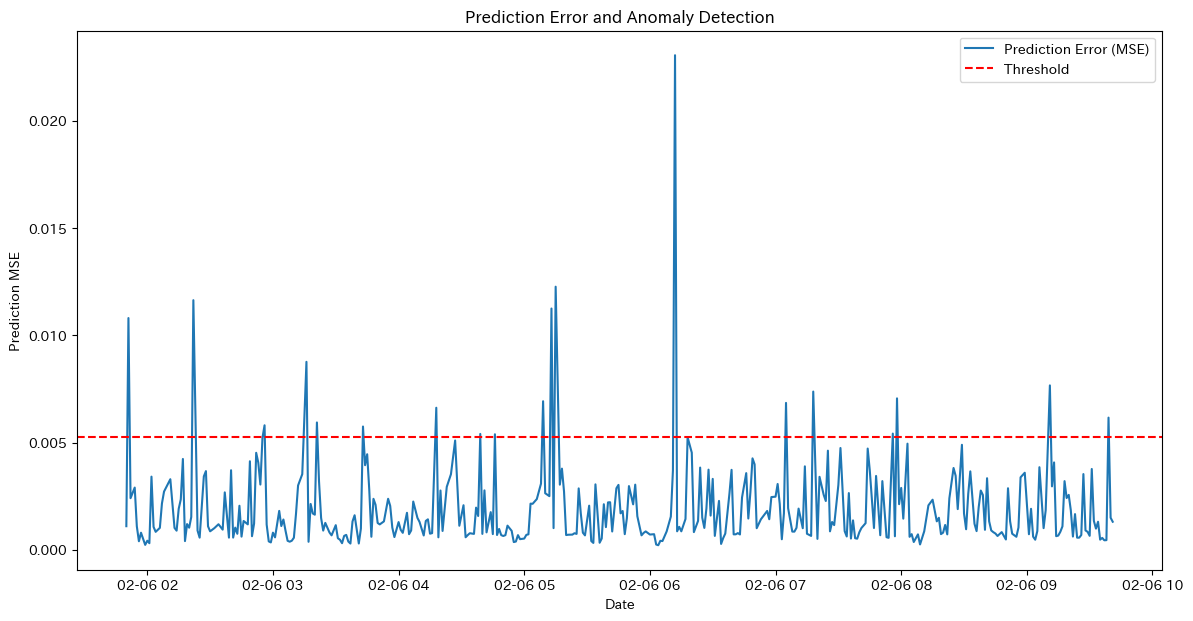
RNNは短期の分析データを用いる場合に有効な手段です。あまり使う機会は多くありませんが、短期データを扱う分にはLSTMを使うよりもモデルの検証精度は良い結果が出ることもありました。
LSTMとGRU:RNNの課題を克服するモデル
RNNの課題
RNNは、長期的な依存関係を学習しにくい勾配消失、学習の不安定さを引き起こす勾配爆発、処理の遅さにつながる高い計算コストといった課題を抱えています。
LSTM
LSTM(Long Short-Term Memory)は、リカレントニューラルネットワーク(RNN)の一種で、特に長期的な依存関係を持つ時系列データの学習に適しています。RNNが抱える勾配消失問題を克服するために設計され、自然言語処理や音声認識など、多くの分野で広く利用されています。
概要と特徴
LSTMは、情報の保持と忘却を制御する3つのゲート(忘却ゲート、入力ゲート、出力ゲート)とセル状態(Cell State)を持ち、重要な情報を長期間保持し、不要な情報を適切に忘れることができます。これにより、長期的な依存関係を持つデータの学習が可能となります。
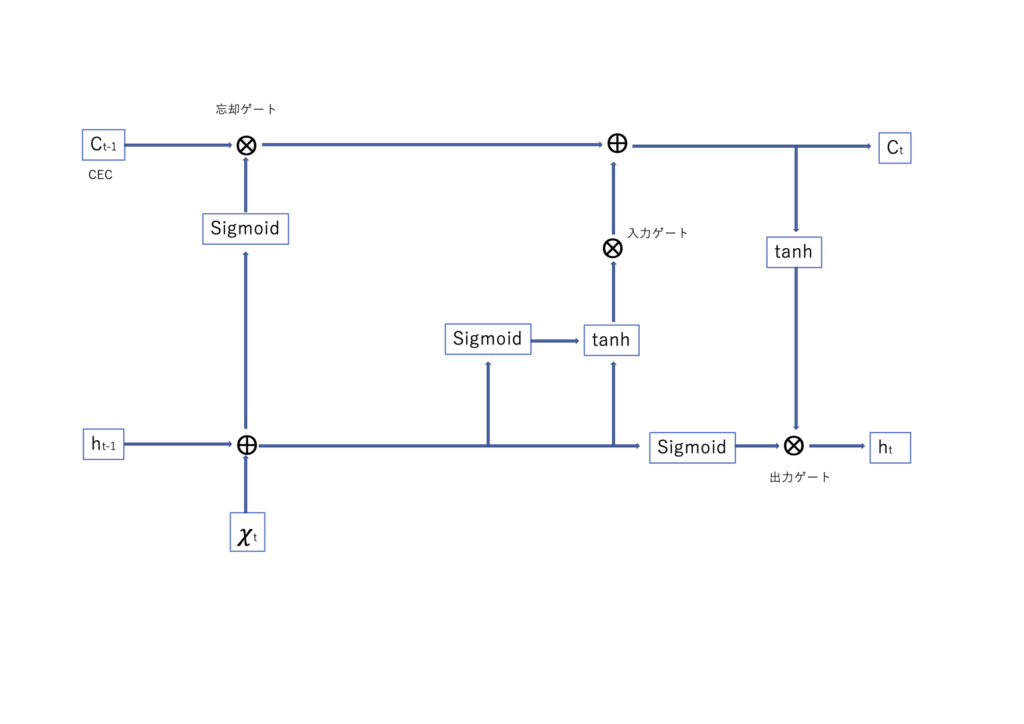
数式
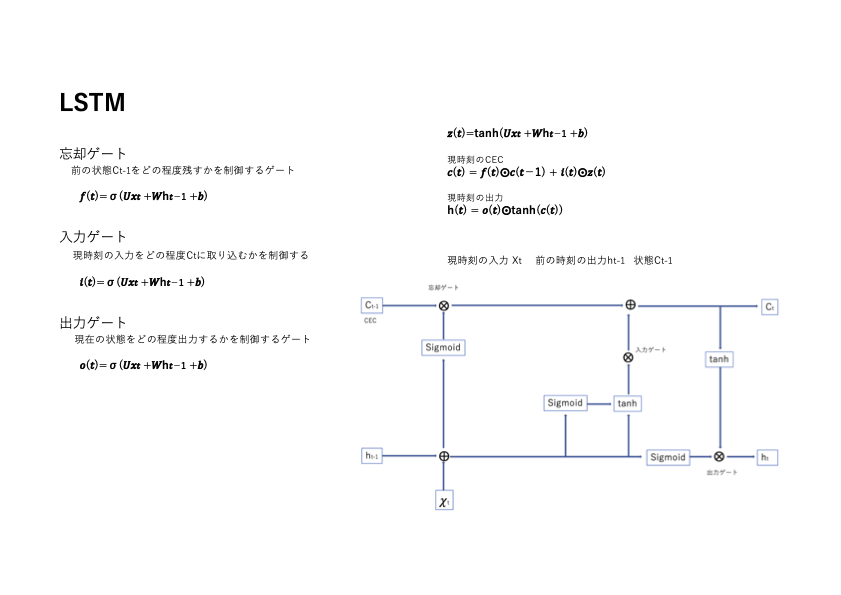
$\sigma$はシグモイド関数、$\tanh$は双曲線正接関数、$W$と$b$は学習可能な重みとバイアス、$h_t$は時刻tttの隠れ状態、$x_t$は入力、$C_t$はセル状態を表します。
目的と課題
- 目的
- 長期的な依存関係を持つ時系列データの学習や予測を行うこと。例えば、文章生成や音声認識など、前後の文脈を考慮する必要があるタスクに適しています。
- 課題
- モデルの複雑さから計算コストが高く、学習時間が長くなることがあります。また、適切なハイパーパラメータの設定や大量のデータが必要となる場合があります。
メリットとデメリット
| メリット | デメリット |
|---|---|
| 長期的な依存関係を効果的に学習可能。 | 計算コストが高く、学習時間が長い。 |
| 勾配消失問題を軽減し、安定した学習が可能。 | モデルの複雑さから過学習のリスクがある。 |
| 多様な時系列データに適用可能。 | 大量のデータと適切なハイパーパラメータの設定が必要。 |
適用例
- 自然言語処理(NLP):文の生成や機械翻訳。
- 音声認識:音声からテキストへの変換。
- 時系列予測:株価や気象データの予測。
LSTMの実装例
ETH-USDの価格データを使用して、CV法を用いた交差検証を行い、LSTMモデルを使用して時系列予測を行ってみます。CV法とはk分割交差検証と通常は呼ばれるものです。
CV法とは?
k分割交差検証は、データを複数のフォールドに分割し、各フォールドごとにトレーニングとテストを行う手法です。一般的には、データをシャッフルして分割しますが、時系列データの場合はシャッフルせずに分割することもあります。

- データのシャッフル
- 時系列データの交差検証では、データの順序を保った分割が必要です。
- 時系列データの交差検証では、データの時間的依存性を尊重し、順序を保つ分割が必要です。これにより、過去が未来に影響を与える因果関係を再現し、データ漏洩を防ぎます。また、モデルが未知の未来データにどれだけ適応できるかを正確に評価することで、現実的で信頼性の高い予測が可能となります。
- 時系列データの交差検証では、データの順序を保った分割が必要です。
- トレーニングデータとテストデータの分割
- 各フォールドでトレーニングデータとテストデータを一定の割合で分割します。
- 交差検証では、データセットを複数のトレーニングセットとテストセットに分割し、各データ点が一度はテストデータとして使用されるようにします。一定の割合で分割することで、モデルの汎化性能を公平かつ一貫性のある方法で評価でき、未知のデータへの適応力を確認できます。特に時系列データでは、順序を保った分割が必要で、現実の予測シナリオに近い評価が可能です。
- 各フォールドでトレーニングデータとテストデータを一定の割合で分割します。
- 汎化性能の評価
- 各フォールドの結果を平均してモデルの汎化性能を評価します。
- 交差検証では、各フォールドでの評価結果を平均し、モデルが未知のデータにどれだけ適応できるかを測定します。この手法により、データの偏りを排除し、モデルの汎化性能を公平かつ信頼性の高い方法で評価できます。未知データへの適応力を定量的に把握するため、実用性を確認する重要なプロセスとなります。
必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlibデバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')データの取得と前処理
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, start='2015-01-01', end='2024-01-16') # 長期間のデータを取得
# 特徴量の選択
data = data[['Close']]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンスの作成
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 60 # 長期間の依存関係を捉えるためにシーケンス長を長く設定
X, y = create_sequences(data_scaled, seq_length)
# データをテンソルに変換
X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
y_tensor = torch.tensor(y, dtype=torch.float32).to(device)LSTMモデルの定義
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out交差検証の設定とモデルのトレーニング
# 交差検証の設定
tscv = TimeSeriesSplit(n_splits=5)
fold = 1
for train_index, val_index in tscv.split(X_tensor):
print(f'Fold {fold}')
X_train, X_val = X_tensor[train_index], X_tensor[val_index]
y_train, y_val = y_tensor[train_index], y_tensor[val_index]
# モデルのインスタンス化
input_dim = X_tensor.shape[2]
hidden_dim = 64
output_dim = 1
num_layers = 1
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers).to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# データローダーの作成
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# トレーニング
num_epochs = 100
train_loss_history = []
val_loss_history = []
for epoch in range(num_epochs):
model.train()
epoch_train_loss = 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
avg_train_loss = epoch_train_loss / len(train_loader)
train_loss_history.append(avg_train_loss)
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
epoch_val_loss += loss.item()
avg_val_loss = epoch_val_loss / len(val_loader)
val_loss_history.append(avg_val_loss)
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}')
print("Training complete for this fold")
# 学習と検証の損失をプロット
plt.figure(figsize=(10, 5))
plt.plot(train_loss_history, label='Train Loss')
plt.plot(val_loss_history, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title(f'Training and Validation Loss for Fold {fold}')
plt.show()
# モデルを評価モードに設定
model.eval()
with torch.no_grad():
train_predictions = model(X_train).cpu().numpy()
val_predictions = model(X_val).cpu().numpy()
# 逆正規化
train_predictions = scaler.inverse_transform(train_predictions)
val_predictions = scaler.inverse_transform(val_predictions)
y_train_actual = scaler.inverse_transform(y_train.cpu().numpy().reshape(-1, 1))
y_val_actual = scaler.inverse_transform(y_val.cpu().numpy().reshape(-1, 1))
# 評価指標の計算
train_rmse = np.sqrt(mean_squared_error(y_train_actual, train_predictions))
val_rmse = np.sqrt(mean_squared_error(y_val_actual, val_predictions))
print(f'Train RMSE for Fold {fold}: {train_rmse:.4f}')
print(f'Validation RMSE for Fold {fold}: {val_rmse:.4f}')
# 予測結果のプロット
plt.figure(figsize=(14, 7))
plt.plot(data.index[train_index[-1]+1:train_index[-1]+1+len(val_index)], y_val_actual, label='Actual')
plt.plot(data.index[train_index[-1]+1:train_index[-1]+1+len(val_index)], val_predictions, label='Predicted')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.title(f'Actual vs Predicted Prices for Fold {fold}')
plt.show()
fold += 1Fold 1
Train RMSE for Fold 1: 50.2462
Validation RMSE for Fold 1: 16.5660
Fold 2
Train RMSE for Fold 2: 39.6357
Validation RMSE for Fold 2: 44.6975
Fold 3
Train RMSE for Fold 3: 29.7197
Validation RMSE for Fold 3: 277.7834
Fold 4
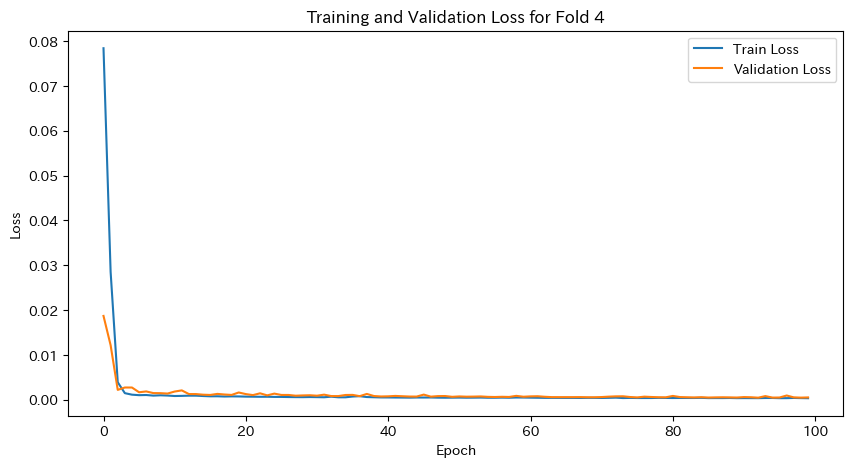
Train RMSE for Fold 4: 87.0200
Validation RMSE for Fold 4: 111.1821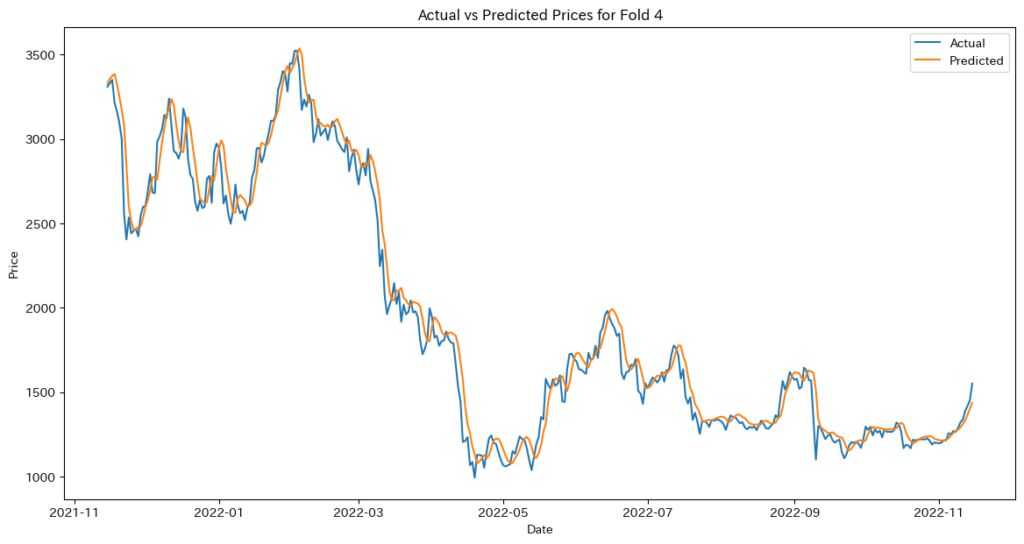
Fold 5
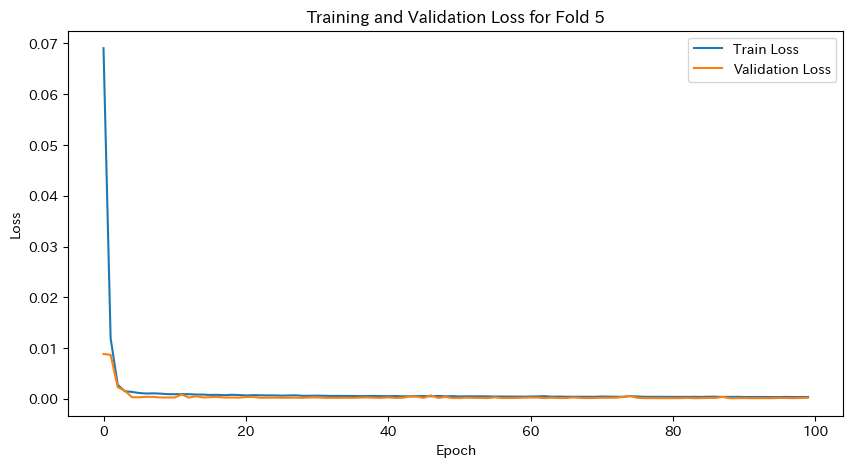
Train RMSE for Fold 5: 96.2908
Validation RMSE for Fold 5: 68.3427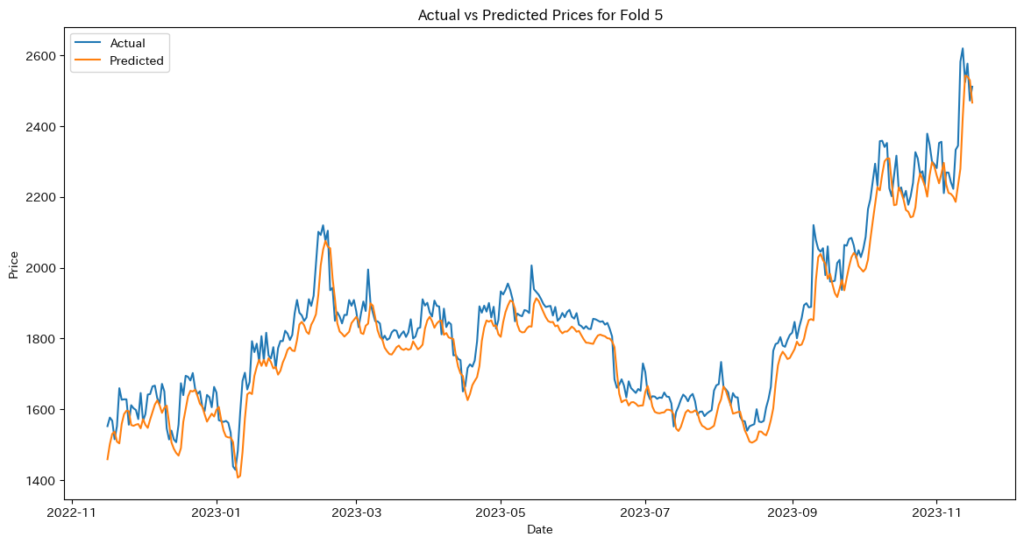
このコードは、交差検証を取り入れてLSTMモデルの性能を評価し、予測データとオリジナルデータをプロットするものです。交差検証を使用することで、モデルの汎化性能を評価し、過学習を防ぐことができます。
LSTMモデルの精度を向上させるための改善手法は下記の通りです。また、これらのモデルを組み合わせることによって個々のモデルの弱点を補完し、精度を向上させることができます。
- 隠れ層の次元数や層の数を増やす
- 特徴量の追加
- ドロップアウトの使用
- L1/L2正則化
- ドロップコネクト
- 学習率スケジューラの使用
- データ拡張
- バッチ正規化
- レイヤー正規化
- ノイズ正則化
- アンサンブル学習
- ウェイトクリッピング
- 早期停止
具体的な改善方法は、データセットやタスクに依存するため、実験を通じて最適な方法を見つけることが重要です。
論文
論文1:『金融時系列データ予測におけるLSTMの有効性』

- 金融時系列データ予測におけるLSTMの有効性
- この研究では、LSTMがTOPIX Core30の株式リターンを予測する際、他のモデル(GBTやSVMなど)を上回る優れた性能を発揮しました。LSTMは、長期的な依存関係を効果的に捉える能力があり、ノイズの多い金融データの処理に適しています。その結果、予測精度が向上し、実現リターンの改善にもつながりました。
- 分位ポートフォリオによる実務的応用可能性の提示
- この研究では、予測モデルを使って銘柄を分位ポートフォリオに分類し、ロング/ショート戦略を設計しました。特にLSTMを活用した戦略は、安定した高リターンを達成しています。これにより、金融市場でのリスク管理や投資意思決定へのLSTMの実務的応用可能性が明確に示されました。
論文2:『LSTM を用いた株価変動予測』
- LSTMによる短期株価予測モデルの提案
- 本研究では、LSTMを使用して1分ごとの株価リターンを予測する手法を提案しました。トヨタ自動車の株式データを対象に、LSTMの長期依存性を捉える能力を活用し、符号一致率87.0%という高精度を達成しました。この成果は、短期株価予測におけるニューラルネットワークの有効性を示すものです。
- 実データに基づく課題と展望の提示
- 本研究では、トレーニングデータで高い精度を達成したものの、テストデータでは過学習が課題として確認されました。これを解決するために、正則化手法(先ほどのモデル改善のための方法論)やモデル改良が必要であることが示唆されています。この結果は、LSTMの金融データ分析への適用をさらに発展させるための重要な方向性を示しています。
論文3:『LSTM-RNNを用いたイベント考慮後の株価時系列予測』

- イベント情報を統合した株価予測モデルの提案
- この研究は、LSTM-RNNに企業イベント情報やマクロ経済指標を統合する新手法を提案しています。業績発表や政策発表などのイベント情報を活用することで、株価予測の一致率が向上。LSTMの長期依存関係を捉える能力を活かし、イベントや経済指標が市場変動に与える影響を効果的にモデル化しました。このアプローチは、投資戦略やリスク管理の精度向上にも寄与する可能性があります。
- 短期予測における実用性の証明
- ツガミの株価データを対象に、LSTMモデルに企業イベント情報を組み込む手法を検証。業績発表や政策発表といった重要イベントを入力に加えることで、予測精度が向上し、RMSEが最小化されました。特定期間における実験で、高精度な短期予測を実現し、金融業界での実用性が示されています。
GRU
GRU(Gated Recurrent Unit)は、LSTM から派生したモデルで、シンプルな構造を持ちながらも、長短期依存関係を学習できるRNNの一種です。LSTMと同様に、勾配消失問題を克服し、時間的依存関係を捉えることができますが、ゲート構造が簡略化されているため、より計算効率が高い点が特徴です。
GRUの概要と特徴
- GRUは、LSTMにある3つのゲート(忘却ゲート、入力ゲート、出力ゲート)を2つ(更新ゲート、リセットゲート)に統合したモデルです。
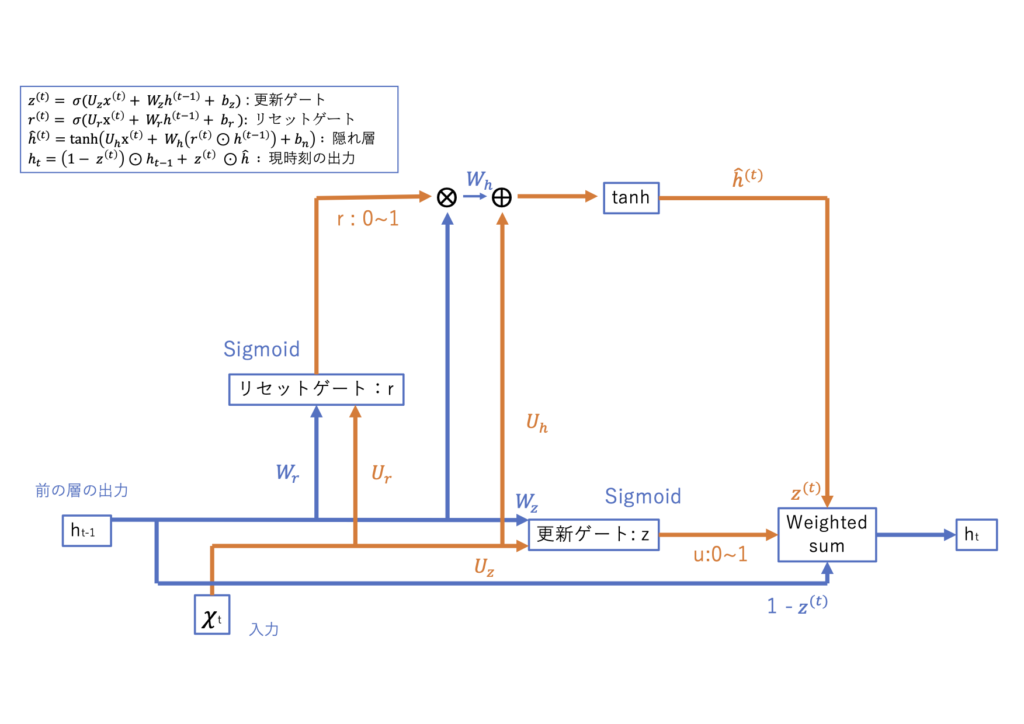
LSTMと比較した特徴
- 計算コストを抑えて学習時間を短縮できる反面、長期的な依存関係の学習にはやや弱い場合があります。

$z_t$:更新ゲート。隠れ状態をどの程度更新するかを決定。$h_t−1$:前時刻の隠れ状態。$x_t$:現在の入力。$W_z,b_z$: 重み行列とバイアス。$σ$:シグモイド関数。
目的と課題
- 目的
- シーケンシャルデータの短期・長期依存関係を効率的に学習し、処理を高速化する仕組みを持ち、勾配消失問題も克服します。
- 課題
- LSTMに比べて長期依存関係の学習や柔軟性がやや劣るため、特定タスクで精度が低下する場合があります。
メリットとデメリット
| メリット | デメリット |
|---|---|
| シンプルな構造により計算効率が高い(パラメータ数が少ない)。 | 長期依存関係を学習する際、LSTMほどの性能を発揮しない場合がある。 |
| LSTMとほぼ同等の精度を維持しつつ学習時間が短縮される。 | 構造がシンプルであるため、柔軟性が求められるタスクでは精度が劣ることがある。 |
| メモリ消費量が少なく、大規模なデータセットでも適用可能。 | 非線形で非常に複雑な依存関係を捉えるのが困難。 |
適用例:
- 自然言語処理(NLP):文の生成や機械翻訳。
- 音声認識:音声からテキストへの変換。
- 時系列予測:株価や気象データの予測。
- 異常検知:センサーデータや金融取引データの異常値検出。
GRUの実装
ETH-USDの価格データを使用して、ウォークフォワード法を用いた交差検証を行い、GRUモデルを使用して時系列予測を行ってみます。
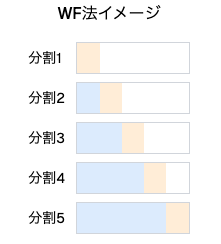
ウォークフォワード法とは?
ウォークフォワード法は、特に時系列データに対して適用される交差検証の一種です。この手法は、データの順序を保ちながら、トレーニングデータとテストデータを分割します。
- 時系列データの順序を保つ
- 時系列データでは、順序を保ったデータ分割を行い、未来のデータで過去を予測する誤りを防ぎます。
- ウォークフォワード法では、過去のデータのみでモデルをトレーニングし、未来のデータで検証することで、時系列の順序を尊重し現実的な予測シナリオを再現します。この手法により、未来のデータを誤って利用するデータ漏洩を防ぎ、モデルの汎化性能(異なる期間への適応力)を適切に評価できます。ランダムなデータ分割では得られない信頼性の高い検証結果を提供します。
- 時系列データでは、順序を保ったデータ分割を行い、未来のデータで過去を予測する誤りを防ぎます。
- トレーニングデータの増加
- ウォークフォワード法では、各フォールドでトレーニングデータを順次拡大し、新しいデータを追加してモデルを学習させます。
- ウォークフォワード法での「トレーニングデータの増加」とは、各フォールドごとに新しいデータを追加しながらトレーニングを行う手法です。これにより、モデルは多くの過去情報を利用し、将来の予測精度を向上させます。また、現実的な運用環境を模倣しつつ、データ量の増加によるモデルの安定性や汎化性能を段階的に評価することが可能です。
- ウォークフォワード法では、各フォールドでトレーニングデータを順次拡大し、新しいデータを追加してモデルを学習させます。
- 検証データの一貫性
- 各フォールドの検証データは一貫しており、モデルの汎化性能を評価するのに適しています。
- ウォークフォワード法で「検証データが一貫している」とは、順序を保った未来のデータで構成されることを意味します。この方法により、モデルが未知のデータにどれだけ適応できるかを適切に評価し、現実的な予測シナリオを再現できます。また、一貫性のある検証データを使用することで評価の偏りを防ぎ、信頼性の高い結果を得られる点が特徴です。
- 各フォールドの検証データは一貫しており、モデルの汎化性能を評価するのに適しています。
必要なライブラリのインポート
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import japanize_matplotlibデバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')データの取得と前処理
# データの取得
ticker = 'ETH-USD'
data = yf.download(ticker, start='2016-01-01', end='2024-01-16') # 指定された期間のデータを取得
# 特徴量の選択
data = data[['Close']]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# シーケンスの作成
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 60 # シーケンス長
X, y = create_sequences(data_scaled, seq_length)
# データをテンソルに変換
X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
y_tensor = torch.tensor(y, dtype=torch.float32).to(device)GRUモデルの定義
class GRUModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers, dropout_prob):
super(GRUModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.gru = nn.GRU(input_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout_prob)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(device)
out, _ = self.gru(x, h0)
out = self.fc(out[:, -1, :])
return outウォークフォワード法の設定とモデルのトレーニング
# ウォークフォワード法の設定
tscv = TimeSeriesSplit(n_splits=5)
fold = 1
for train_index, val_index in tscv.split(X_tensor):
print(f'Fold {fold}')
X_train, X_val = X_tensor[train_index], X_tensor[val_index]
y_train, y_val = y_tensor[train_index], y_tensor[val_index]
# モデルのインスタンス化
input_dim = X_tensor.shape[2]
hidden_dim = 128
output_dim = 1
num_layers = 2
dropout_prob = 0.5
model = GRUModel(input_dim, hidden_dim, output_dim, num_layers, dropout_prob).to(device)
# 損失関数とオプティマイザの定義
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5, factor=0.5, verbose=True)
# データローダーの作成
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# トレーニング
num_epochs = 100
train_loss_history = []
val_loss_history = []
early_stopping_patience = 10
best_val_loss = float('inf')
patience_counter = 0
for epoch in range(num_epochs):
model.train()
epoch_train_loss = 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
avg_train_loss = epoch_train_loss / len(train_loader)
train_loss_history.append(avg_train_loss)
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
epoch_val_loss += loss.item()
avg_val_loss = epoch_val_loss / len(val_loader)
val_loss_history.append(avg_val_loss)
scheduler.step(avg_val_loss)
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
best_model_state = model.state_dict()
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= early_stopping_patience:
print("Early stopping")
break
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}')
print("Training complete for this fold")
# 最良モデルのロード
model.load_state_dict(best_model_state)
# 学習と検証の損失をプロット
plt.figure(figsize=(10, 5))
plt.plot(train_loss_history, label='Train Loss')
plt.plot(val_loss_history, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title(f'Training and Validation Loss for Fold {fold}')
plt.show()
# モデルを評価モードに設定
model.eval()
with torch.no_grad():
train_predictions = model(X_train).cpu().numpy()
val_predictions = model(X_val).cpu().numpy()
# 逆正規化
train_predictions = scaler.inverse_transform(train_predictions)
val_predictions = scaler.inverse_transform(val_predictions)
y_train_actual = scaler.inverse_transform(y_train.cpu().numpy().reshape(-1, 1))
y_val_actual = scaler.inverse_transform(y_val.cpu().numpy().reshape(-1, 1))
# 評価指標の計算
train_rmse = np.sqrt(mean_squared_error(y_train_actual, train_predictions))
val_rmse = np.sqrt(mean_squared_error(y_val_actual, val_predictions))
print(f'Train RMSE for Fold {fold}: {train_rmse:.4f}')
print(f'Validation RMSE for Fold {fold}: {val_rmse:.4f}')
# 予測結果のプロット
plt.figure(figsize=(14, 7))
plt.plot(data.index[train_index[-1]+1:train_index[-1]+1+len(val_index)], y_val_actual, label='Actual')
plt.plot(data.index[train_index[-1]+1:train_index[-1]+1+len(val_index)], val_predictions, label='Predicted')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.title(f'Actual vs Predicted Prices for Fold {fold}')
plt.show()
fold += 1Fold 1
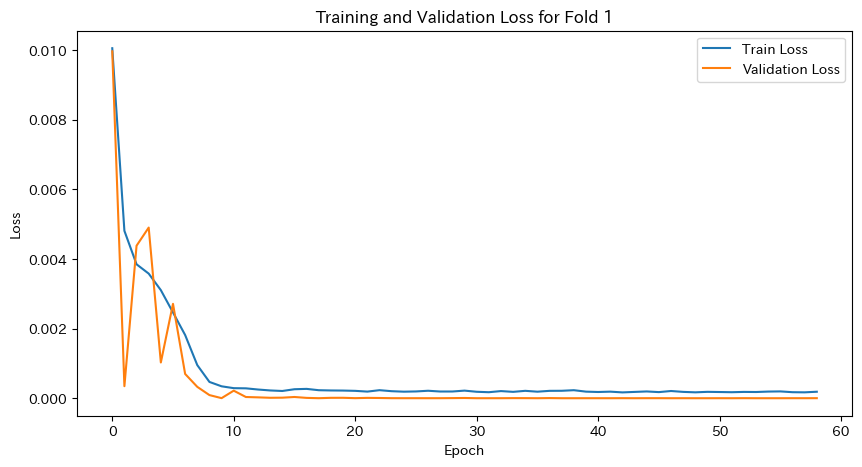
Train RMSE for Fold 1: 54.9688
Validation RMSE for Fold 1: 14.2020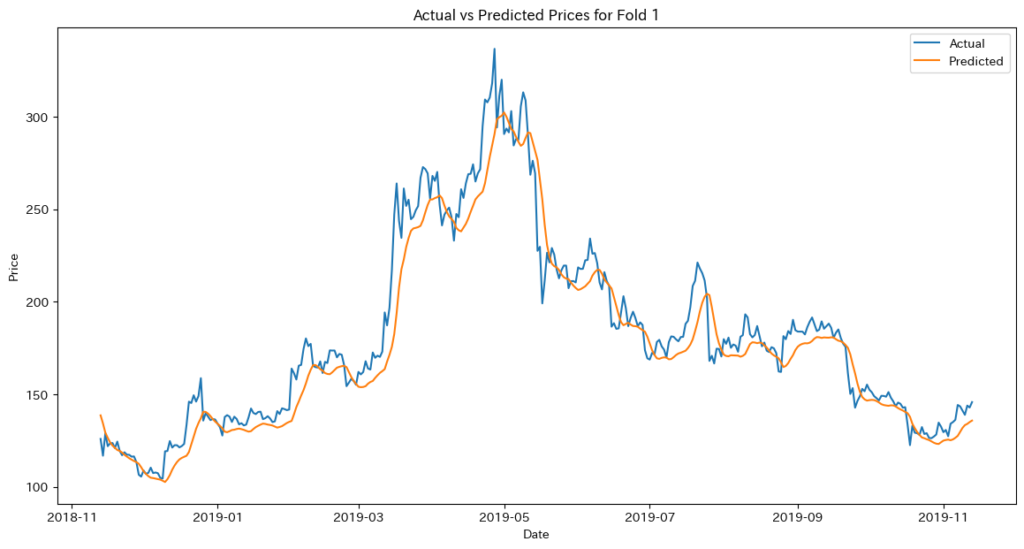
Fold 2
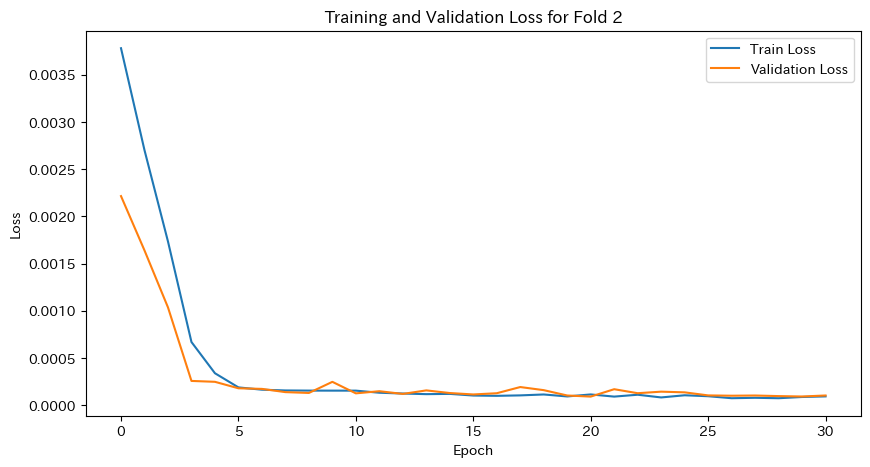
Train RMSE for Fold 2: 36.0598
Validation RMSE for Fold 2: 43.0738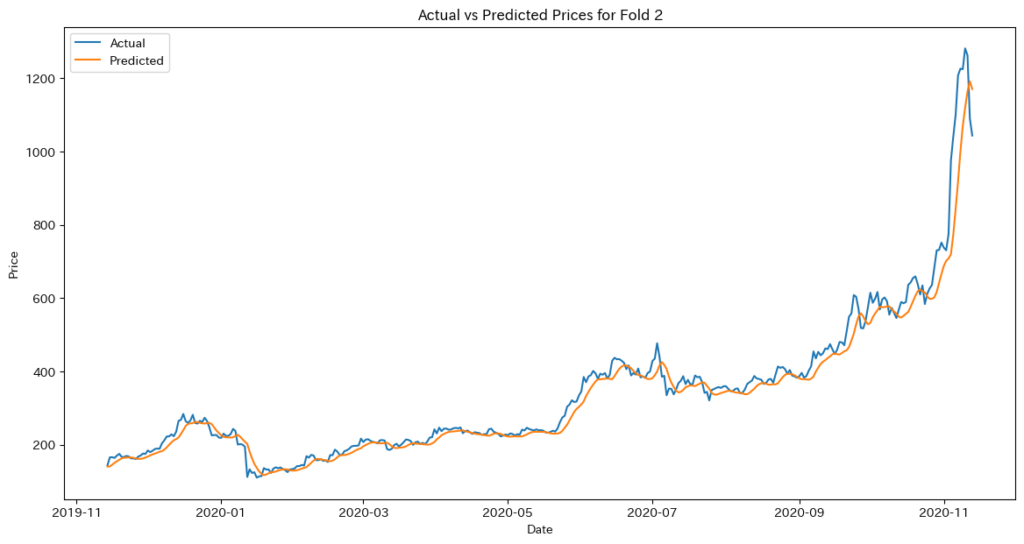
Fold 3
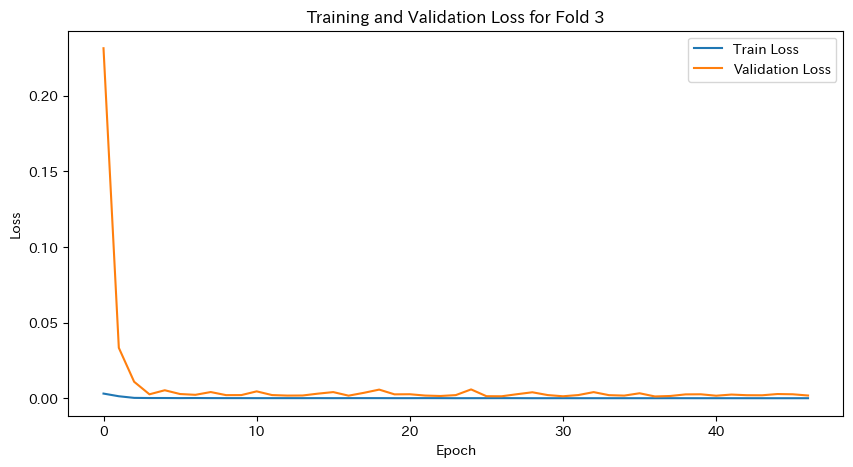
Train RMSE for Fold 3: 32.7122
Validation RMSE for Fold 3: 201.4362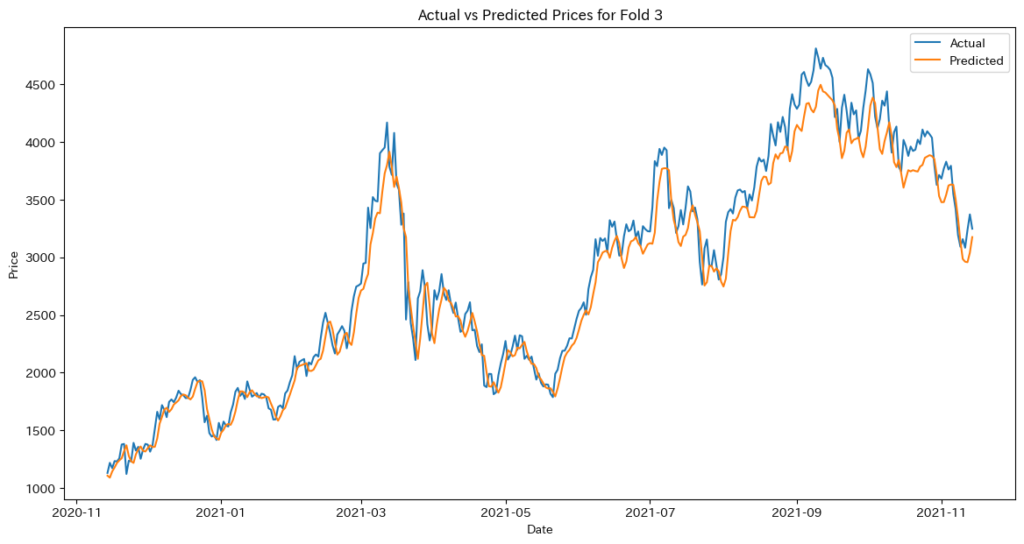
Fold 4
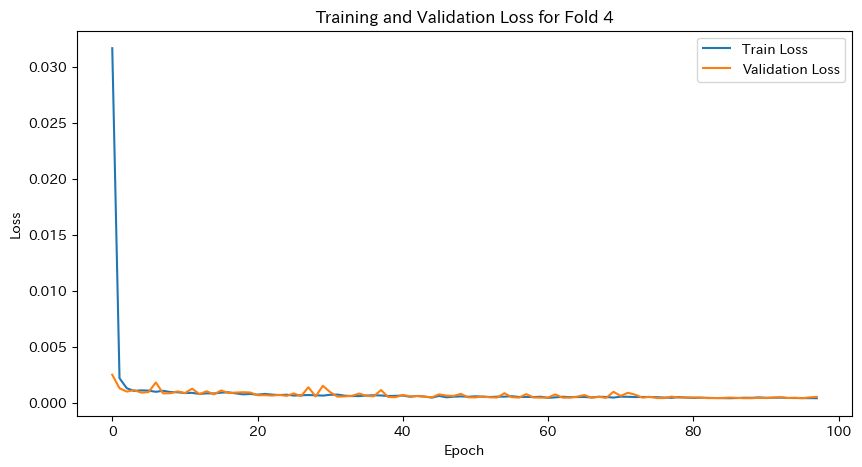
Train RMSE for Fold 4: 85.4003
Validation RMSE for Fold 4: 112.3236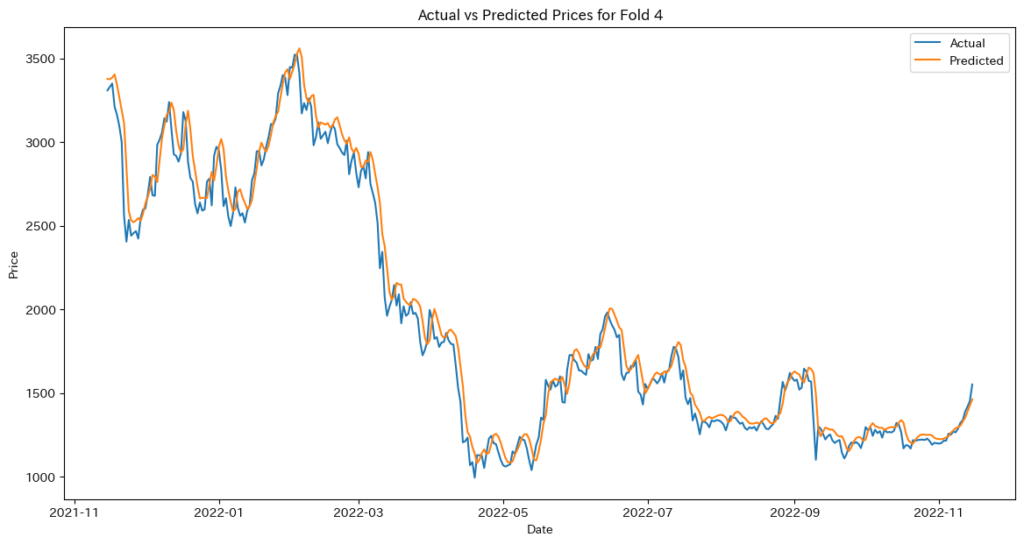
Fold 5
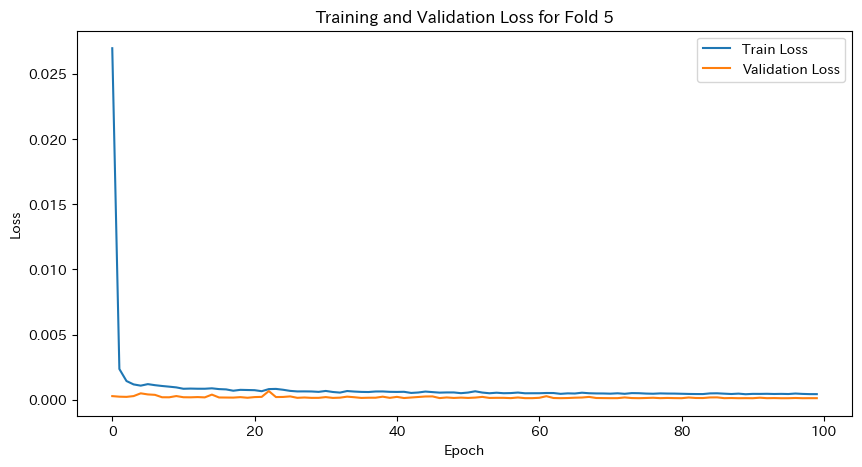
Train RMSE for Fold 5: 85.2406
Validation RMSE for Fold 5: 50.3445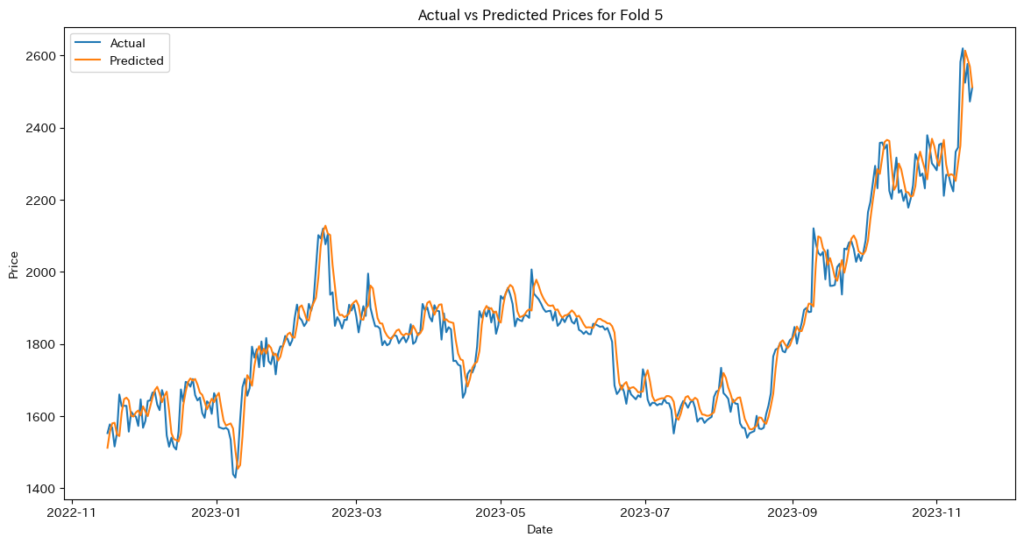
ウォークフォワード法は、時系列データの順序を保ちながら、トレーニングデータと検証データを分割するため、時系列データの予測に適しています。
ウォークフォワード法とCV法の違い
| 比較項目 | ウォークフォワード法 | CV法(一般的な交差検証) |
|---|---|---|
| データの順序 | 時系列データの順序を保ちながら分割します。 | データをシャッフルして分割することが一般的ですが、時系列データの場合は順序を保つこともあります。 |
| トレーニングデータの増加 | 各フォールドごとにトレーニングデータの範囲が広がります。 | 各フォールドのトレーニングデータの範囲は一定です。 |
| 適用対象 | 特に時系列データに適しています。 | 時系列データ以外のデータにも適用できます。 |
論文
論文1:『Combining Deep Learning and GARCH Models for Financial Volatility and Risk Forecasting』

- ハイブリッドモデルによるボラティリティ予測の精度向上
- GARCHモデルとGRUニューラルネットワークを組み合わせたハイブリッドモデルを提案。GARCHで基礎的なボラティリティを予測し、その出力をGRUで補正することで、非線形性や長期依存性を効果的に学習。S&P500やビットコインなどでMSEやMAEの精度向上を実証し、高ボラティリティ資産の予測でも優れた性能を発揮しました。このモデルは、金融市場でのリスク管理や予測の精度向上に寄与します。
- リスク評価への応用と課題の提示
- 提案されたハイブリッドモデルは、ボラティリティ予測精度の向上に成功しましたが、リスク評価指標であるValue at Risk(VaR)やExpected Shortfall(ES)の予測においては、従来の手法を一貫して上回る成果が得られませんでした。これは、モデルが高精度でボラティリティを予測できるものの、極端な市場状況や尾部リスクを十分に捉えきれていない可能性を示唆しています。研究では、これらの課題に対処するために、極値理論(EVT)や分位回帰モデルなどの補完的な手法の統合が提案されています。この結果は、金融リスク評価における複雑な要素を理解し、モデル設計を最適化する必要性を明確に示しました。
論文2:『A Gated Recurrent Unit Approach to Bitcoin Price Prediction』

- GRUモデルによる高精度なビットコイン価格予測
- GRUモデルを活用したビットコイン価格予測では、リカレントドロップアウトを導入し、非線形性や高ボラティリティに対応する高い精度を実現しました。特に、SARIMAやLSTMを上回る性能を示し、テストデータではRMSEが0.017と最小値を記録。短期的な価格変動を効果的に予測でき、投資やリスク管理に役立つ実用性が実証されました。この研究は、ディープラーニングを金融市場分析に応用する新たな可能性を示しています。
- モデルを活用した収益性の高い投資戦略の提案
- GRUモデルを活用した価格予測に基づき、収益性の高い投資戦略を提案しました。ロング/ショート戦略では相場の上下で利益を狙い、バイ/セル戦略では取引コストを抑えつつ安定した収益を実現。特にバイ/セル戦略が高いパフォーマンスを示し、ビットコイン市場のような高ボラティリティな環境での実務応用可能性が明確に示されました。このアプローチは、投資意思決定やリスク管理の強力なツールとして活用が期待されます。
論文3:『Comparative Study of Bitcoin Price Prediction』

- GRUモデルの優位性を示すビットコイン価格予測の成功
- GRUモデルは、ビットコイン価格予測においてLSTMを上回る性能を示しました。具体的には、MSEが4.67とLSTMの6.25を下回り、精度と計算効率で優位性を発揮。さらに、5-foldクロスバリデーションを活用し、過学習を抑えながら汎化性能を向上させました。この結果、GRUは非線形性やボラティリティの高いビットコイン市場の分析において、高い実用性を持つモデルであることが示されました。
- 正則化とデータ前処理の効果的な組み合わせ
- 本研究では、L2正則化と5-foldクロスバリデーションを組み合わせることで、モデルの過学習を抑えつつ安定性と汎化性能を向上させました。また、高値、安値、終値、出来高など多次元特徴量を取り入れるデータ前処理により、ビットコイン市場の複雑な動きを正確に捉えることを実現。特に、高ボラティリティ環境での予測精度向上に寄与し、モデルの実用性を強化しています。
学習の振り返りと次回予告
今回の学習では、時系列データ解析の基礎と生成分野の関連性を学びました。トレンド、季節性、残差の分解やスライディングウィンドウ、正規化など前処理の基本を理解し、オートエンコーダやVAEによる生成タスクの応用例も確認しました。また、RNNの動作原理や勾配消失問題を学び、それを克服するLSTMとGRUの仕組みや用途についても理解を深めました。
次回は、Transformerモデルの基本構造をわかりやすく紐解きながら、自然言語処理(NLP)のさまざまな応用例を探っていきます。Self-AttentionやEncoder-Decoderアーキテクチャがどのようにデータを処理するのか、その仕組みを丁寧に解説。また、時系列データ解析や音声認識における具体的な活用シナリオもご紹介します。コードの詳細な説明に加え、実際の応用方法がしっかり理解できるような内容で取り組む予定です。


コメント