
第4回の目標
今回は機械学習の歴史を振り返り、3つの主要な学習方法(教師あり学習、教師なし学習、強化学習)についての基本的な理解を深め、それぞれの手法の違いや適用方法を把握します。
機械学習の歴史
機械学習とディープラーニングの歴史は、多くの科学者たちの発見と技術の進歩によって支えられています。以下に、その重要な歴史的な出来事を振り返ってみましょう。
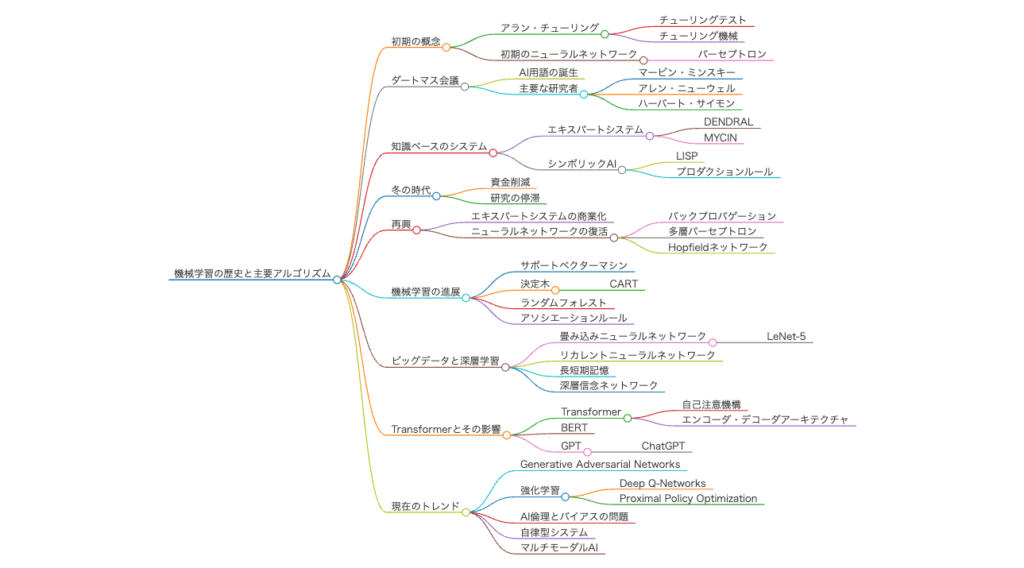
初期の人工知能の発展(1950年代 – 1970年代)
- 1950年: アラン・チューリングが「コンピュータ機械と知性」をテーマに「チューリングテスト」を提案し、人工知能(AI)に関する初期の概念が生まれました。
- 1956年:ダートマス会議で「人工知能(AI)」という言葉が初めて使われ、機械に知性を持たせる研究が正式にスタートしました。
- 1960年代:パーセプトロンという初期のニューラルネットワークが開発され、機械がデータから学ぶという基本的な考えが形づくられました。
機械学習の確立(1980年代)
- 1980年代: パーセプトロンの限界が指摘されたことを受け、複数の層を持つ「多層パーセプトロン(MLP)」が登場し、バックプロパゲーションアルゴリズムが開発されました。この技術により、ニューラルネットワークは複雑なパターンを学習できるようになりました。
- サポートベクターマシン(SVM): この頃、サポートベクターマシンが開発され、教師あり学習の分野で大きな成果を上げました。SVMは、クラス間の最適な境界を見つけるための強力な手法です。
データマイニングとビッグデータ(1990年代 – 2000年代)
- 1990年代:この時代は「データマイニング」の興隆期であり、データから情報を引き出すための様々なアルゴリズムが開発されました。また、この時期に「決定木」や「K-平均法」などの教師あり学習および教師なし学習のアルゴリズムも広く普及しました。
- 2000年代: インターネットの発展により、巨大なデータ(ビッグデータ)が生成され始め、それに応じてデータを効率的に処理するためのアルゴリズムと計算技術の必要性が高まりました。
ディープラーニングの夜明け(2010年代)
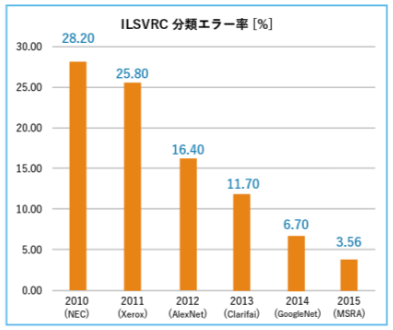
- 2012年: ジェフリー・ヒントンとそのチームがImageNetコンペティションで大規模なニューラルネットワークを使ったモデルを発表し、大きな成功を収めました。この出来事により、ディープラーニングは広く認知されるようになり、コンピュータビジョン分野での新たな可能性を示しました。
- 畳み込みニューラルネットワーク(CNN): 画像認識での成果に大きく貢献した技術で、画像中の特徴を捉えることに長けたモデルです。
- リカレントニューラルネットワーク(RNN): 自然言語処理(NLP)や音声認識など、時系列データの扱いに特化したモデルが普及しました。その後、RNNの改良版である「LSTM(Long Short-Term Memory)」や「GRU(Gated Recurrent Unit)」も開発され、精度が向上しました。
現代の機械学習とAIの進化(2020年代以降)
- トランスフォーマーモデルの進化: 2017年に発表された「Attention is All You Need」によってトランスフォーマーアーキテクチャが登場し、自然言語処理や画像処理において革新的な成果をもたらしました。トランスフォーマーモデルは、それ以前のRNNやCNNに比べて、並列計算が可能であり、長距離依存関係を効率的に処理することができるため、非常に効率的で多用途なアーキテクチャです。この技術はGPT-3やBERTなど、多くのモデルに応用されています。2020年代に入り、GPT-3.5やGPT-4など、より高度なトランスフォーマーモデルが登場し、AIの性能は飛躍的に向上しました。
- 自己教師あり学習の進展: 自己教師あり学習(Self-Supervised Learning)は、ラベルのないデータから特徴を学び取る新たなアプローチとして注目を集めています。これにより、大規模なデータセットを効果的に利用することが可能となり、様々なAI分野におけるモデルの性能が向上しました。
- 強化学習の実世界応用: 強化学習は、ゲーム分野での成功に続き、自動運転や産業ロボットの分野でも応用が進んでいます。たとえば、AlphaStarがリアルタイム戦略ゲーム「StarCraft II」でプロプレイヤーに勝利したことは、その実力を証明しました。
- 生成系AIの発展(2020年代):生成AI(Generative AI)の分野では、DALL-E、Midjourneyなどのモデルが登場し、画像生成やコンテンツクリエーションの自動化が急速に進みました。また、ChatGPTをはじめとする対話型AIは、様々な業界でのカスタマーサポートやクリエイティブライティングに広く利用されています。
機械学習の3つの種類
◾️scikit-learnライブラリ(Pythonプログラミング入門)
- 教師あり学習
- 教師なし学習

教師あり学習(Supervised Learning)
教師あり学習は、Kaggleコンペティションの多くで使われる手法です。ラベル付きデータを使ってモデルを訓練し、未知のデータに対して予測を行います。たとえば、価格予測、分類問題、または画像認識などが主な応用例です。さらに、ビジネスの実例として、顧客の離脱予測(カスタマーチャーン)や詐欺検出(フロードディテクション)などがあります。これらは企業が顧客満足度を向上させたり、損失を防ぐために広く活用されています。
Kaggleでの重要性
教師あり学習は、特に回帰問題や分類問題のコンペで大きな成果を上げやすいです。多くのKaggleコンペティションでは、正解データが与えられるため、教師あり学習を重点的に学んでおくことは非常に有効です。
代表的なアルゴリズム
- 線形回帰
- ロジスティック回帰
- サポートベクターマシン(SVM)
- 決定木、ランダムフォレスト
- 勾配ブースティング(Gradient Boosting)
- XGBoost
- ライトGBM(LightGBM)
- ニューラルネットワーク(深層学習モデルを含む)
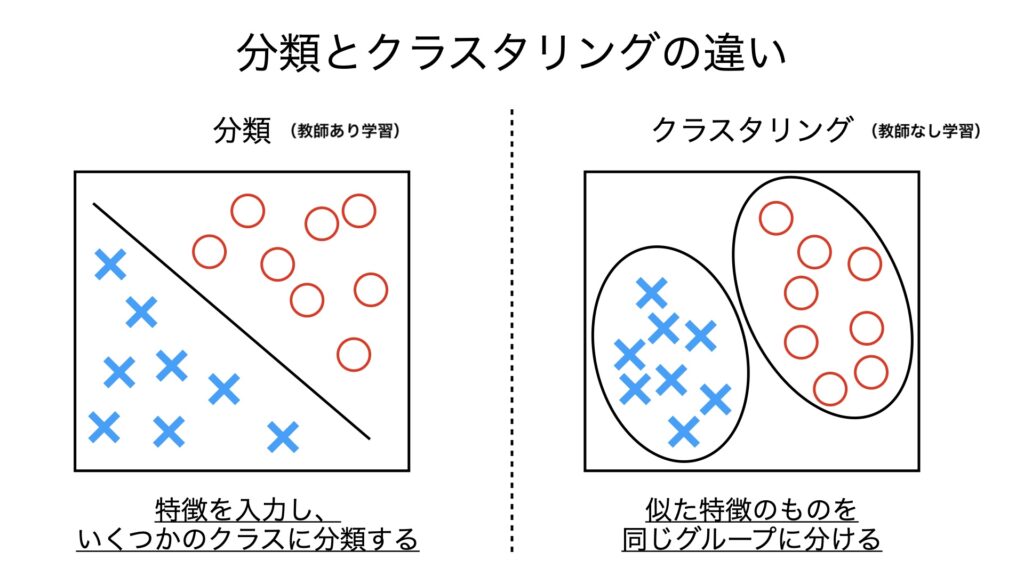
教師なし学習(Unsupervised Learning)
教師なし学習は、データにラベルがついていない場合に使います。データのパターンや構造を見つけ出すために用いられ、Kaggleではデータの前処理や特徴量のエンジニアリングに役立ちます。たとえば、クラスタリング手法を使って似たようなデータをグループ化することができます。しかし、教師なし学習にはモデルの出力の質を評価するのが難しいという課題もあります。これは、ラベルがないため、結果がどれほど正確かを測定する基準が存在しないからです。
Kaggleでの重要性
データ探索や前処理で非常に有用です。特に大量のデータから有益な情報を引き出す際、教師なし学習を活用することがあります。例えば、Kaggleのマーケティングコンペティションで、顧客セグメントを自動的にグループ化するのに使われます。
代表的なアルゴリズム
- K-平均法(K-means clustering)
- 主成分分析(PCA)
- 異常検知
- 階層型クラスタリング(Hierarchical Clustering)
- 確率的潜在意味解析(Latent Dirichlet Allocation, LDA)
- t-SNE(t-Distributed Stochastic Neighbor Embedding)
- オートエンコーダ(Autoencoder)
強化学習(Reinforcement Learning)
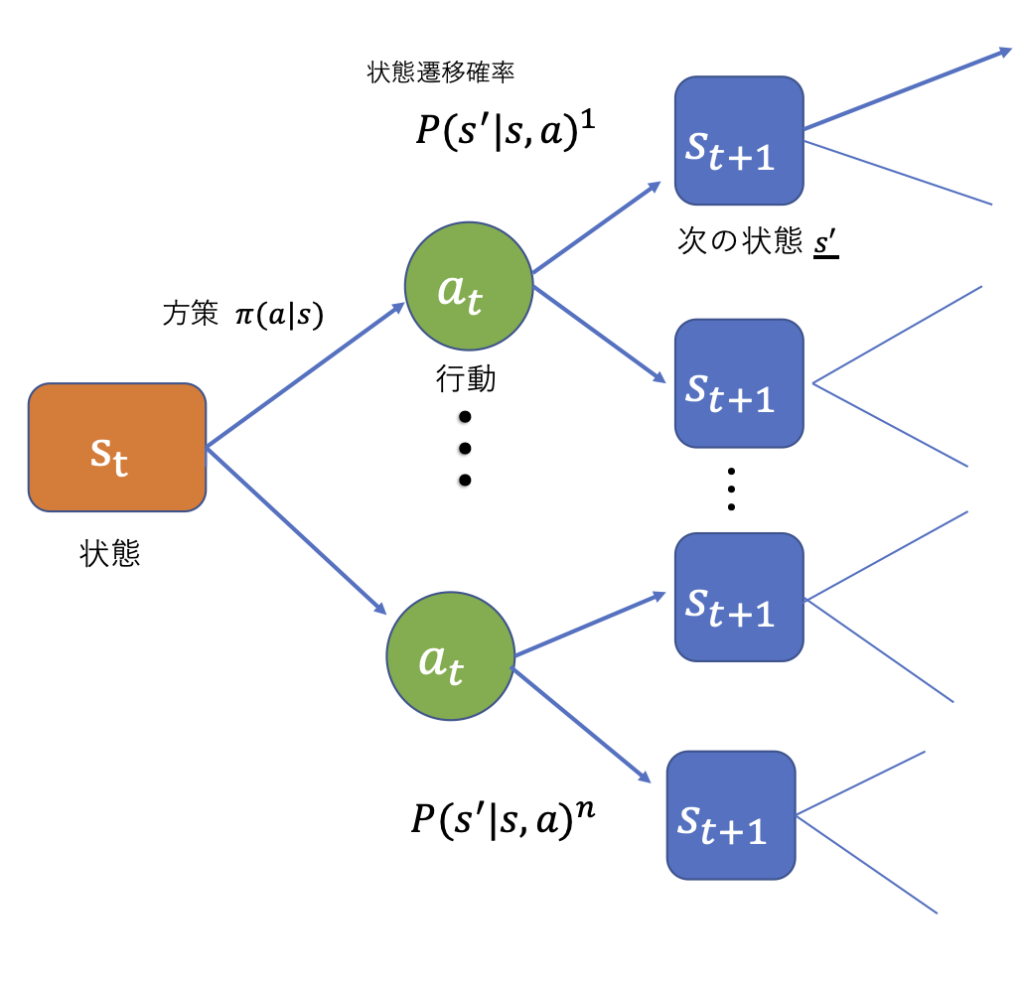
強化学習は、エージェントが環境との相互作用を通じて学習する手法です。特定の報酬を最大化するために試行錯誤を繰り返します。Kaggleで出題されることは少ないものの、ゲームやロボティクスの分野で注目されています。例えば、強化学習を使ってAIがゲームをプレイすることを学ぶケースがあります。エージェントが何度もゲームをプレイし、成功(報酬)と失敗(ペナルティ)から学ぶことで、最終的には効率的な戦略を見つけ出します。こうした技術は、チェスや囲碁、さらにはコンピュータゲームのような複雑なタスクにも応用されています。
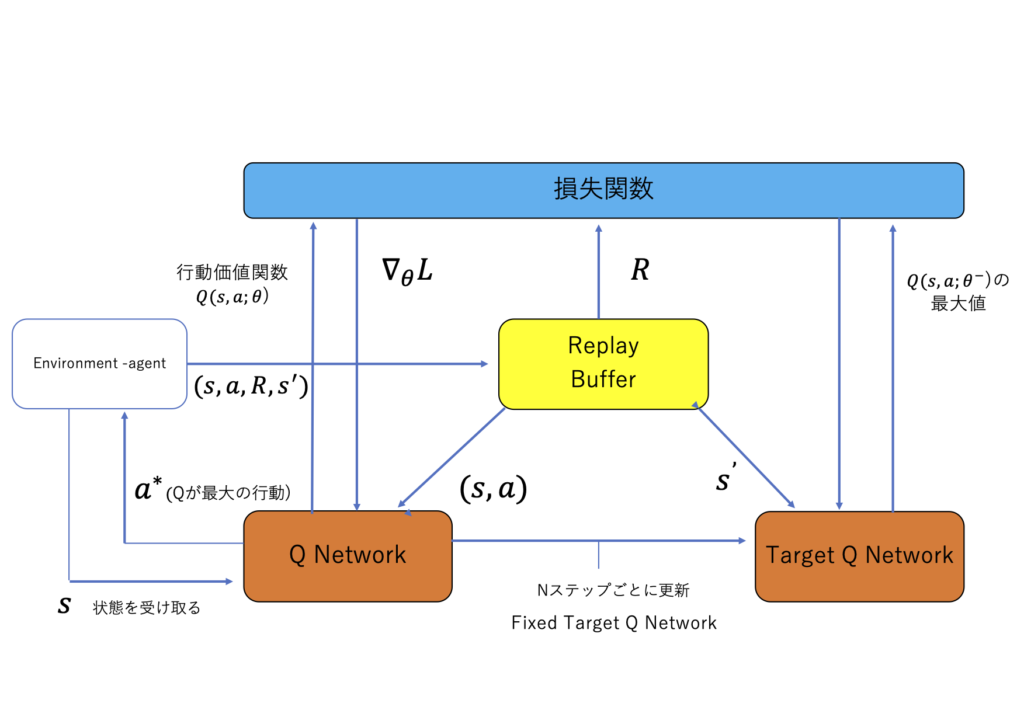
Kaggleでの重要性
Kaggleのコンペティションでは強化学習を直接使うことは少ないですが、AIの応用を学ぶ上で重要な分野です。
代表的なアルゴリズム
- Q学習(Q-Learning)
- サポート学習(SARSA)
- Deep Q-Network(DQN)
- 方策勾配法(Policy Gradient)
- アクタークリティック法(Actor-Critic Methods)
- Proximal Policy Optimization(PPO)
- A3C(Asynchronous Advantage Actor-Critic)
代表的な応用例
- ゲームAI(チェスや囲碁)
- 自動運転車
- ロボットの動作計画
機械学習のプロセス
Kaggleコンペティションの流れ
Kaggleで成果を上げるには、以下のプロセスを正しく実行することが求められます。
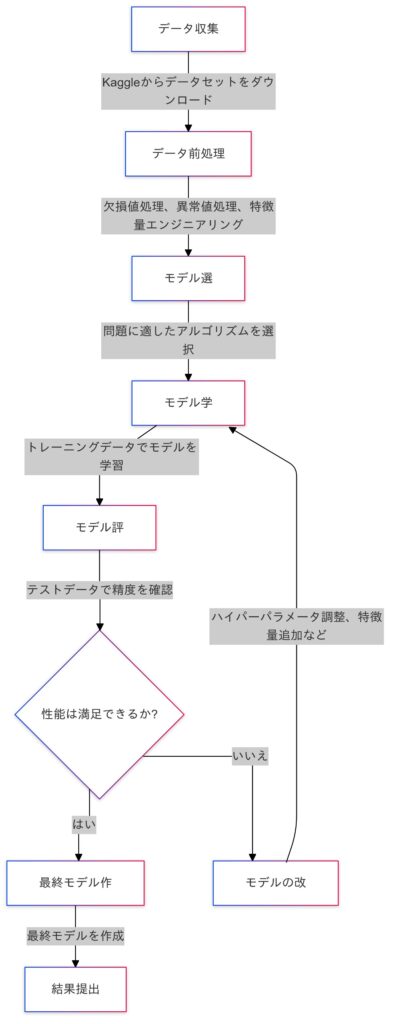
- データ収集:まず、使用するデータを理解し、分析の準備をします。Kaggleではデータセットが提供されるので、それを適切に取り扱うことが重要です。
- データ前処理:欠損値や異常値を処理し、データをモデルに適した形に変換します。これがモデルの性能に直結します。
- モデル選択:Kaggleの問題に応じた適切なアルゴリズムを選びます。回帰問題や分類問題に応じたモデルを選ぶことがカギです。
- モデル学習:トレーニングデータを使ってモデルを学習させます。
- モデル評価:学習したモデルをテストデータで評価し、精度を確認します。
- モデルの改善:必要に応じてハイパーパラメータの調整やモデルの改善を行い、最終的な提出用のモデルを作ります。
機械学習全体のプロセス
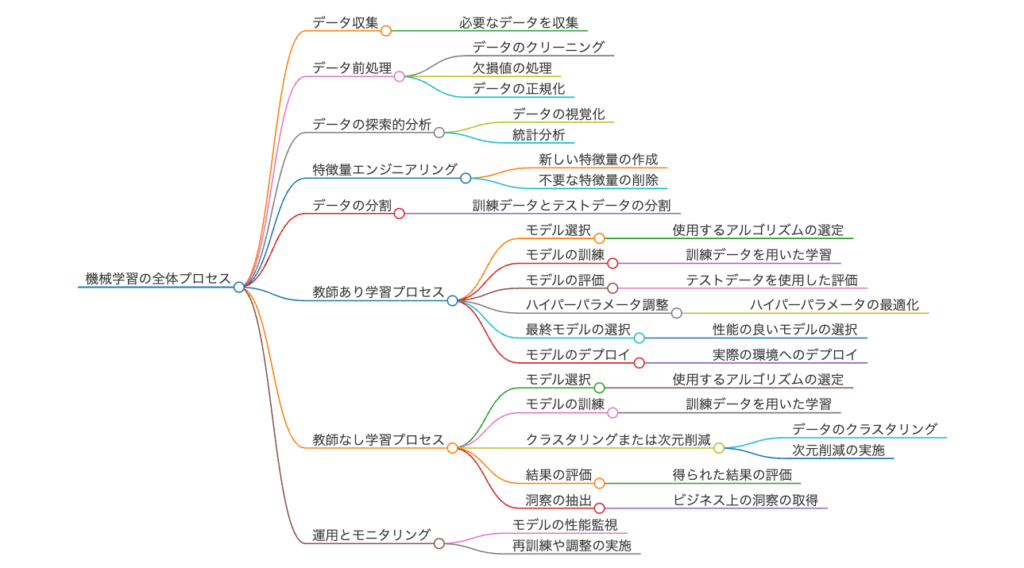
Kaggleでの機械学習の選択戦略
Kaggleでメダルを取るためには、自分が取り組むコンペティションの問題に応じた最適な手法を選ぶ必要があります。
分類問題
ロジスティック回帰、サポートベクターマシン、ランダムフォレスト、XGBoost、ライトGBM、ニューラルネットワークなどが強力です。
回帰問題
線形回帰、決定木、ランダムフォレスト、XGBoost、ライトGBMが有効です。
クラスタリングや次元削減
データの前処理や探索で、教師なし学習が効果的です。
これらの手法をバランスよく学ぶことで、コンペティションごとに最適な戦略を立てられるようになります。
実世界での機械学習の応用
機械学習の技術は、医療、金融、マーケティング、製造業など多くの分野で活用されています。たとえば、金融ではクレジットスコアリングに、医療では病気の予測に、マーケティングでは顧客セグメントの特定に活用されます。
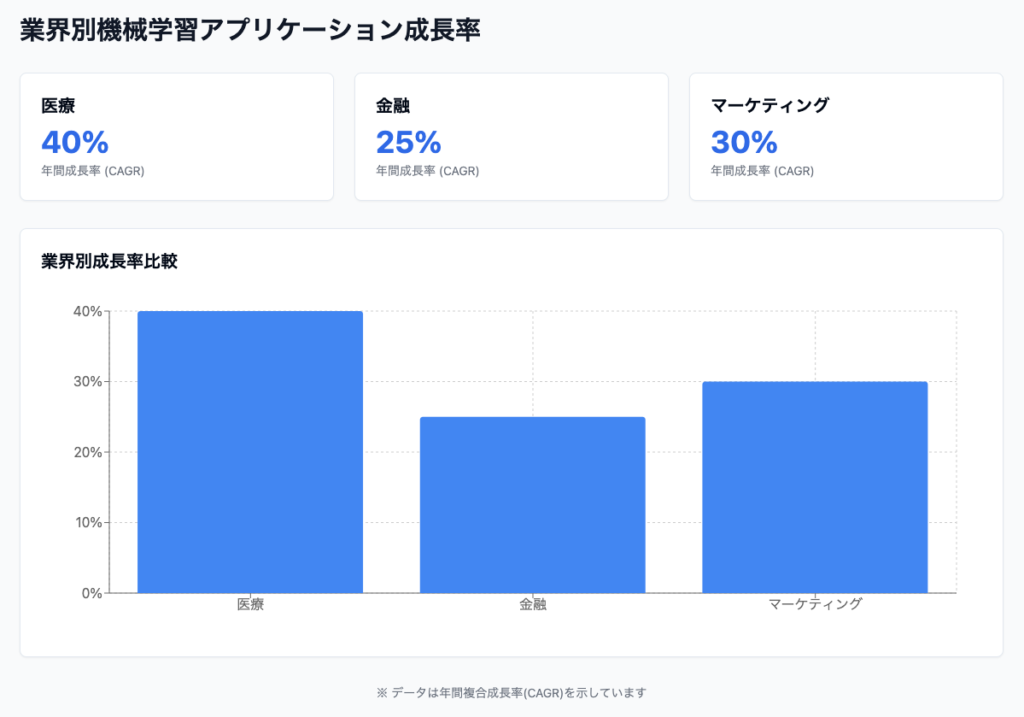
機械学習は、医療、金融、マーケティングなどの異なる業界で急速に成長しており、その影響は実世界で顕著に現れています。以下に、各業界における機械学習アプリケーションの成長を示す要素を詳述します。
医療業界
医療分野では、機械学習が診断支援、患者モニタリング、個別化医療などに利用されています。例えば、画像診断においては、機械学習アルゴリズムがX線やMRI画像を解析し、疾患の早期発見を助けています。これにより、診断精度が向上し、治療の迅速化が実現しています。
- 成長率:医療用AI市場は2023年から2028年までに約40%の年平均成長率(CAGR)を見込んでいます。
金融業界
金融業界では、機械学習がリスク管理、不正検出、顧客サービスの向上に寄与しています。特に、不正取引の検出では、リアルタイムでトランザクションデータを分析し、不審な活動を即座に特定することが可能です。
- 成長率:金融テクノロジー(FinTech)市場は2023年から2027年までに約25%のCAGRで成長すると予測されています。
マーケティング業界
マーケティング分野では、機械学習が顧客データ分析やターゲティング広告に活用されています。消費者行動を予測し、パーソナライズされた広告を提供することで、企業はより高いROI(投資対効果)を実現しています。
- 成長率:マーケティングAI市場は2023年から2028年までに約30%のCAGRで成長すると見込まれています。
実世界への影響
これらの成長は、各業界の効率性向上やコスト削減だけでなく、新たなビジネスモデルの創出にも寄与しています。例えば、医療分野では患者の健康管理がより効率的になり、金融分野では顧客体験が向上し、マーケティング分野では消費者との関係構築が強化されています。
例えば、医療分野では、機械学習を使って病気の予測や診断が行われています。具体的には、患者の電子カルテデータを基にして糖尿病や心疾患のリスクを予測するモデルを構築することで、早期の治療が可能になります。これにより、医療従事者はリソースを効果的に配分し、患者の健康状態をより適切に管理することができます。特にディープラーニングを活用した画像診断では、X線やMRI画像からがんを検出する精度が向上しており、医師のサポートとして重要な役割を果たしています。
次回予告
次回は、「第5回:モデル評価と最適化」に進みます。モデルの性能を評価し、ハイパーパラメータのチューニングを行うことで、モデルのパフォーマンスを向上させる方法を学びます。これらの手法は、データ分析でより良い成果を上げるための重要な技術ですので、楽しみにしてください!


コメント