
Soraとは?
Soraは、OpenAIによって2024年2月にリリースされたテキストからビデオを生成するAIモデルです。

Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots,
プロンプト: 暖かく光るネオンとアニメーションの看板で埋め尽くされた東京の通りを、スタイリッシュな女性が歩いている。彼女は黒いレザージャケットを羽織り、赤いロングドレスを着て、黒いブーツを履いている、
Prompt: The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from
プロンプト: 山の急斜面にある松の木に囲まれた急勾配の未舗装道路を疾走する、黒いルーフラックの付いた白いヴィンテージSUVの後ろをカメラが追う。
論文について
論文の構成
- 導入
- 背景
- 技術
- 応用
- 議論
- 結論
- 関連作品
『Sora: A Review on Background, Technology, Limitations, and
Opportunities of Large Vision Models』

1. 導入
論文の導入部では、AI技術が日常生活や産業における相互作用をどのように変革しているか、そしてその中でOpenAIによって開発されたテキスト・トゥ・ビデオ生成モデル「Sora」の重要性が強調されています。
Soraは、テキストプロンプトから最大1分間の高品質ビデオを生成する能力を持ち、これまでのビデオ生成モデルを大きく進化させた点が特徴です。
このモデルは、動的で文脈豊かなシミュレーションを通じて実世界の問題を解決するために、複雑なユーザー指示を解釈し実行する能力を示しています。また、Soraは複数のキャラクターが複雑な背景の中で特定の行動を行う詳細なシーンを生成できること、そして、視覚的に一貫した長さのビデオを提供することで、AI駆動のクリエイティブツールとしての新たな可能性を開いています。
2. 背景
歴史的背景
ディープラーニング革命以前、コンピュータビジョン(CV)の伝統的な画像生成技術は、手作業による特徴に基づくテクスチャ合成やテクスチャマッピングなどの方法に依存していました。しかし、これらの方法は複雑で鮮やかな画像を生成する能力に限界がありました。GAN(Generative Adversarial Networks)やVAE(Variational Autoencoders)の導入は、画像生成の詳細と品質を向上させる重要な転換点となりました。トランスフォーマーアーキテクチャやCLIPのような多モーダルモデルの成功は、言語と視覚のモデルが人間の指示を解釈する能力を中心に、AIの焦点が移行したことを示しています。
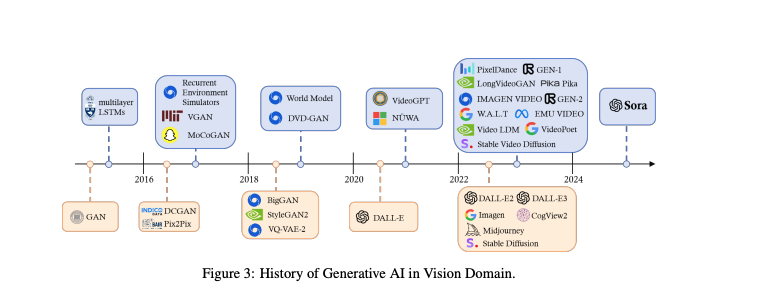
先進的概念
視覚モデルのスケーリング法則に関する最近の研究は、十分なトレーニングデータを持つViTモデルのパフォーマンスが(飽和する)べき乗則に従うことを示しています。このようなスケーリング原則に従うSoraは、テキストからビデオへの生成において複数の新しい能力を明らかにしました。Soraは、LLM(Large Language Models)のようなモデルと同様に、開発者によって明示的にプログラムされていない洗練された振る舞いや機能を示す「出現する能力」を持つ最初の視覚モデルです。これらの能力は、モデルがさまざまなデータセットで広範なトレーニングを受け、広大なパラメータ数を持つことから生じるもので、単なるパターン認識や暗記を超えた接続と推論を形成する能力を持ちます。
3-1. 技術:基礎技術について
Soraの概要
Soraは、柔軟なサンプリング次元を持つ拡散トランスフォーマーモデルです。ビデオを潜在空間にマッピングし、トークン化された潜在表現を処理して、最終的にピクセル空間にマッピングします。
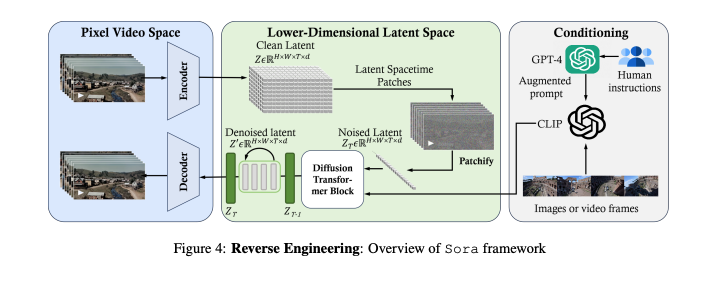
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
データ前処理
可変期間、解像度、アスペクト比
Soraは様々な形式のビデオと画像をそのネイティブサイズで処理します。
統一された視覚表現
ビデオを低次元の潜在空間に圧縮し、時空間パッチに分解します。
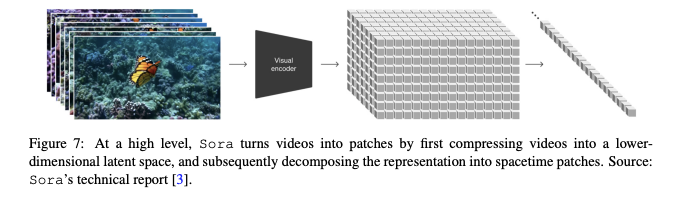
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
ビデオ圧縮ネットワーク
入力データの次元削減を目的としています。
時空間潜在パッチ
潜在空間の次元の変動を処理するための技術について議論します。
拡散トランスフォーマー
視覚ノイズから始まり、テキストプロンプトに従って具体的な詳細を段階的に導入するプロセスを通じて、生成されたビデオが現れます。
モデリング
Soraのビデオ生成プロセスは、拡散モデルのフレームワークを使用して、テキストプロンプトに基づいて具体的なビジュアルディテールを段階的に導入することで、ビデオを生成します。
言語指示のフォロー
Soraは、テキストプロンプトを理解し、それに基づいてビデオを生成する能力を持ちます。
DALL·Eの研究で得た成果、特にDALL·E 3からのキャプション再生成技術を応用し、非常に説明的なキャプションモデルをトレーニングし、次にそれを使用してトレーニングセット内のすべての動画のテキストキャプションを生成します。
プロンプトエンジニアリング
ユーザーが特定の出力を達成するためにAIシステムに与える入力の設計と改善を指します。テキスト、画像、ビデオプロンプトを使用して、ユーザーの意図に沿ったコンテンツを生成するプロセスを含みます。
3-2 技術:拡散トランスフォーマーモデルの3つの主要ステップ
- 時空間圧縮器が元のビデオを潜在空間にマッピングします。
- ViT(Vision Transformer)がトークン化された潜在表現を処理し、デノイズされた潜在表現を出力します。
- CLIPのような条件付けメカニズムが、LLM(大規模言語モデル)拡張ユーザー指示と、場合によっては視覚プロンプトを受け取り、拡散モデルを誘導してスタイルまたはテーマに沿ったビデオを生成します。
事前訓練された拡散変換器
ビデオの細部を精密に生成するプロセスを管理
拡散変換器は、Soraの核心技術であり、多くの自然言語処理タスクにおいてスケーラブルかつ効果的であることが証明されています。GPT-4のような大規模言語モデルに類似しており、テキストを解析し、複雑なユーザー指示を理解する能力を持っています。ビデオ生成プロセスでは、視覚的ノイズで満たされたフレームから始まり、モデルが反復的に画像のノイズを除去し、提供されたテキストプロンプトに従って特定の詳細を導入することで、望まれるコンテンツと品質に一致するビデオを生成します。
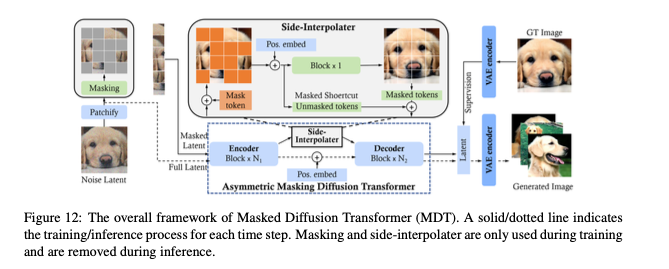
画像拡散トランス
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
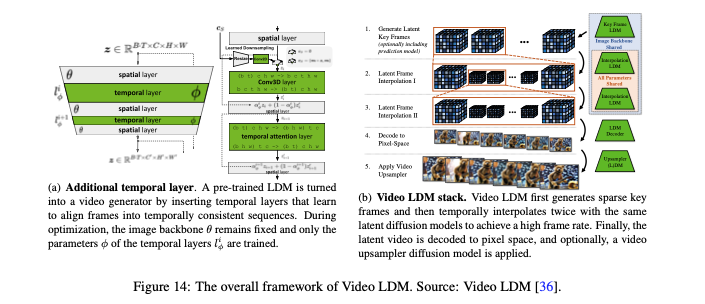
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
拡散変換機とは?
拡散変換機は、トランスフォーマーアーキテクチャを組み込んだ拡散モデルであり、伝統的な畳み込みベースのU-Netに代わる新しいアプローチを提供します。この技術は、視覚トランスフォーマーを用いて潜在拡散モデルに適用され、マルチヘッドアテンションとバッチレイヤーノーマライゼーションを活用して学習プロセスを安定化させます。拡散変換機は、画像やテキストから画像への生成で高い性能を発揮し、動的なデノイジング行動のモデリングなど、従来の拡散モデルが直面していた課題を克服しています。

論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
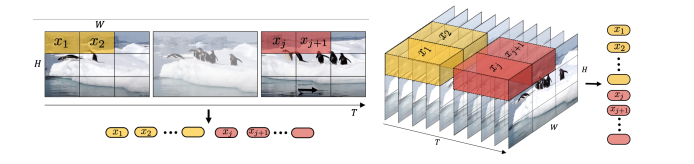
時空間潜在パッチ
ビデオの動きと視覚的詳細を捉えるための効率的な方法を提供
Soraはビデオ生成を計算効率よく行うため、時空間潜在パッチを基本構成要素として使用します。具体的には、Soraは原始の入力ビデオを潜在時空間表現に圧縮し、その圧縮されたビデオから時空間パッチのシーケンスを抽出して、短い間隔で視覚的外観と動きのダイナミクスを包括します。これらのパッチは、言語モデルの単語トークンに類似しており、ビデオを構築するための詳細な視覚フレーズを提供します。
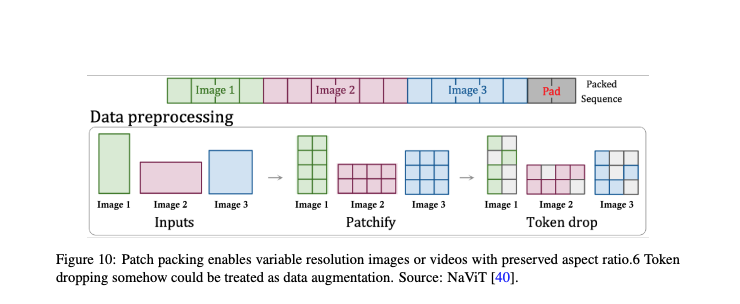
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
Soraはビデオの潜在空間の次元の変動性をどのように処理するか?
PNPという方法がこの問題の解決策として提案されており、異なるビデオからのパッチを単一のシーケンスにパッケージングすることで、可変長の入力に対して効率的なトレーニングを実現します。トークンをどのように効率的にパックし、不要なトークンをどのように選択してドロップするかについての課題が議論されています。また、3D一貫性を維持しつつ、すべてのトークンを超長いコンテキストウィンドウにパックするOpenAIのアプローチが、計算コストは高いものの、この問題に対する可能性のある解決策として提案されています。
論文:『Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models』より抜粋
4. 応用:Soraの主な特徴と応用
シミュレーション能力の向上
Soraは、3Dモデリングを明示的に行わなくても、動的なカメラモーションや長距離の一貫性を含む3Dの一貫性を示し、簡単な相互作用を世界でシミュレートすることができます。また、Minecraftのようなデジタル環境も、基本的なポリシーを維持しながら視覚的忠実度を保持するようにシミュレートします。
創造性の促進
テキストを介して概念をアウトラインし、数秒以内にリアルまたは高度にスタイリッシュなビデオをレンダリングすることが可能になります。これにより、アーティスト、映画製作者、デザイナーはアイデアの探求と洗練を迅速化し、創造性を大幅に向上させることができます。
教育革新の推進
Soraを使用して、教育者はクラスプランをテキストからビデオに簡単に変換し、学生の注意を引きつけ、学習効率を向上させることができます。科学シミュレーションから歴史的な演出まで、可能性は無限に広がっています。
アクセシビリティの向上
テキストの説明を視覚コンテンツに変換することで、Soraはすべての人々、特に視覚障害を持つ人々がコンテンツ作成と他者とのより効果的なやり取りに積極的に参加することを可能にします。これにより、誰もがビデオを通じて自分のアイデアを表現する機会を持つ、より包括的な環境が実現します。
新たな応用の促進
Soraの応用は非常に広範囲に及びます。例えば、マーケターは特定の観客の説明に合わせてダイナミックな広告を作成するためにSoraを使用することができます。また、ゲーム開発者は、プレイヤーの物語からカスタマイズされた視覚効果やキャラクターのアクションを生成するためにSoraを使用することができます。
5. 議論:Soraの制約と改善の機会について
制約
物理的リアリズムの課題
Soraは、複雑なシナリオを正確に描写する際に物理原則の一貫性を欠くことがあります。例えば、クッキーを一口食べたとしても対応する噛み跡が残らない場合があり、物理的な妥当性からの逸脱を示しています。また、オブジェクトの不自然な変形や椅子のような剛体構造の誤ったシミュレーションなど、リアリスティックな物理モデリングに挑戦する動きを生成することがあります。
空間的および時間的複雑さ
Soraは、オブジェクトやキャラクターの配置に関連する指示を時々誤解し、方向についての混乱(例えば、左と右を混同する)を引き起こします。また、指定されたカメラムーブメントやシーケンスに沿ったイベントの時間的正確性を維持することに挑戦します。
人間とコンピュータの相互作用(HCI)における制限
ビデオ生成の分野において潜在的な可能性を示しているものの、SoraはHCIにおける重要な制限に直面しています。これは、生成されたコンテンツに対する詳細な修正や最適化を行う際の一貫性や効率性において主に顕著です。
使用上の制限
OpenAIはまだSoraの公開アクセスに関して具体的なリリース日を設定しておらず、広範囲にわたる展開前の安全性と準備に慎重なアプローチを強調しています。また、現在のところ、Soraは最大で1分間のビデオしか生成できません。
改善の機会
学術界
Soraの導入は、AIコミュニティにテキストからビデオへのモデルの探求を深めるよう奨励し、コンテンツ作成、ストーリーテリング、情報共有の可能性を革新するという戦略的なシフトを示しています。
産業界
Soraの現在の能力は、ビデオシミュレーション技術の進歩に向けた有望な道を示し、テキスト記述から高度にリアルな環境を作成する可能性を秘めています。これはコンテンツ作成とゲーム開発を革命的に変える未来を提供します。
社会
Soraと類似のプラットフォームは、社会メディア上でのコンテンツ作成に変革的な可能性を持ち、高品質なビデオ制作を誰もがアクセスできるものにします。これは、クリエイティブなコンテンツクリエイターをエンパワーメントし、新たな創造性とエンゲージメントの時代をもたらします。
まとめ
2024年2月にOpenAIがリリースしたSoraは、テキストの指示からリアルまたは想像上のシーンをビデオとして生成するAIモデルです。この革新的なモデルは、物理世界をシミュレートする能力を持ち、テキストからビデオへの変換に新たな地平を開きました。技術報告書とリバースエンジニアリングに基づいて、この論文はSoraの開発背景、鍵となる技術、幅広い産業での応用、そして直面する挑戦について詳細に解説しています。
始めに、Soraがどのようにして「世界シミュレーター」として構築されたか、その基礎となる技術について掘り下げています。次に、映画制作、教育、マーケティングなど、さまざまな分野でのSoraの利用方法とその影響力について具体的に説明しています。また、AIによるビデオ生成が直面する主な課題や、安全かつ公平な利用を確保するための必要性についても触れています。そして、ビデオ生成技術の未来に目を向け、Soraや類似のモデルがどのように進化し、人間とAIの間でより創造的で生産的な相互作用を生み出すかについて考察しています。
この論文は、Soraを中心に、テキストからビデオへの生成技術の現状と将来の展望を網羅的に紹介し、それによりAIがビデオ制作の領域でいかに大きな可能性を秘めているかを明らかにしています。
参考文献
『Sora: A Review on Background, Technology, Limitations, and
Opportunities of Large Vision Models』


コメント