 実装詳細
実装詳細 大規模言語モデル【Transformer:実装詳細B-1】
Embedding層と入出力形状の追跡:BPEからベクトル化までブログA(基礎理論)では、Transformerの全体構造を学びました。ここからは、各コンポーネントの実装詳細を深掘りしていきます。まずは、テキストをモデルが処理できる形式に変...
実装詳細  基礎理論
基礎理論  基礎理論
基礎理論 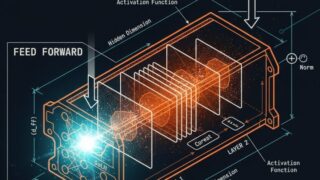 基礎理論
基礎理論  基礎理論
基礎理論  基礎理論
基礎理論  基礎理論
基礎理論  LLM
LLM  GPT
GPT  LLM
LLM