
The Pileと多様性の発見
2020年、EleutherAIが公開したThe Pileは、LLMデータセット設計の見方を少し変えました。単に量を増やすのではなく、どんな種類のテキストをどう混ぜるかが重要だと示したデータセットです。
1. The Pileの戦略:「量から多様性へ」
1.1 従来のアプローチとの違い
The Pileが出てきた背景には、「大きいデータを集めれば十分」という考え方への見直しがあります。ここでは、その違いをはっきりさせておきます。
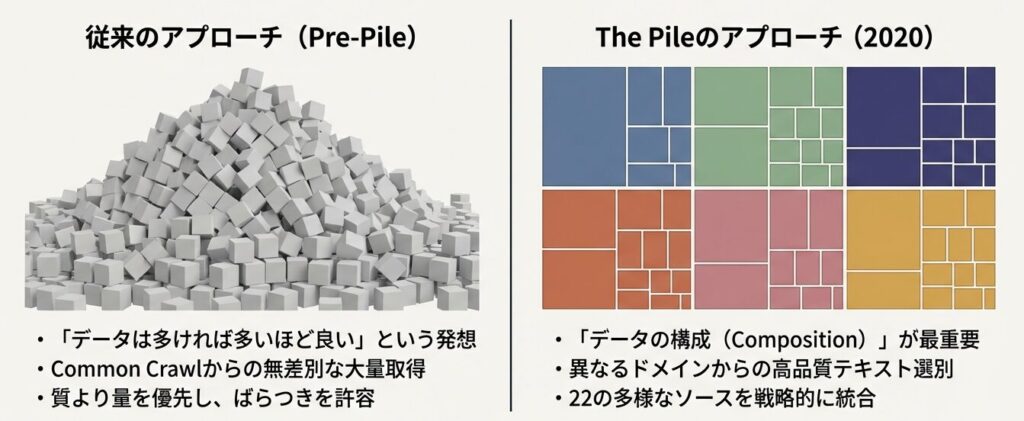
従来のアプローチ
- 「データは多ければ多いほど良い」という発想
- Common Crawlから可能な限り大量に取得する
- 質にばらつきがあっても、量でカバーする
The Pileのアプローチ
- 「データの構成(composition)が重要」という発想
- 異なるドメインから高品質なテキストを選別する
- 22の多様なソースを戦略的に統合する
単なるスケーリングの限界を打破し、「何をどう混ぜるか」というパラダイムへ移行。
1.2 22の多様なソース構成
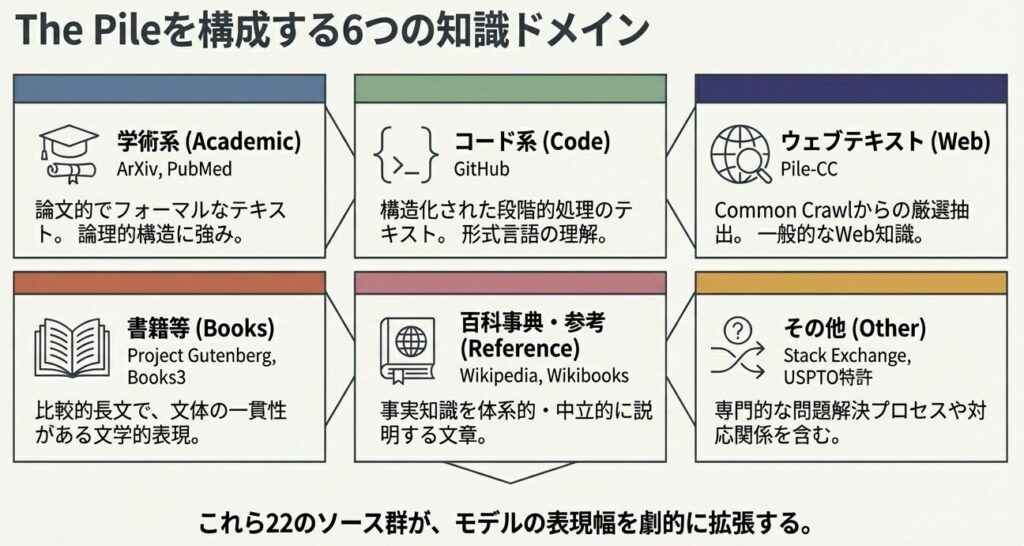
The Pile の構成
-
学術系
- ArXiv(物理、CS等の論文)
- PubMed(生物医学論文)
- 特徴: 論文的でフォーマルなテキストが多い
-
ウェブテキスト
- Pile-CC(Common Crawlから厳選)
- 特徴: 一般的なWebテキストを広く含む
-
書籍等
- Project Gutenberg(古典文学)
- Books3(出版済書籍)
- 特徴: 比較的長文で、文体の一貫性がある
-
コード系
- GitHub(プログラミングコード)
- 特徴: 構造化されたテキストを学べる
-
百科事典・参考
- Wikipedia
- Wikibooks
- 特徴: 知識を体系的に説明する文章が多い
-
その他
- Stack Exchange(Q&A)
- USPTO(特許)
- 特徴: 問題解決や専門的な表現を含む
2. The Pileの規模と特性
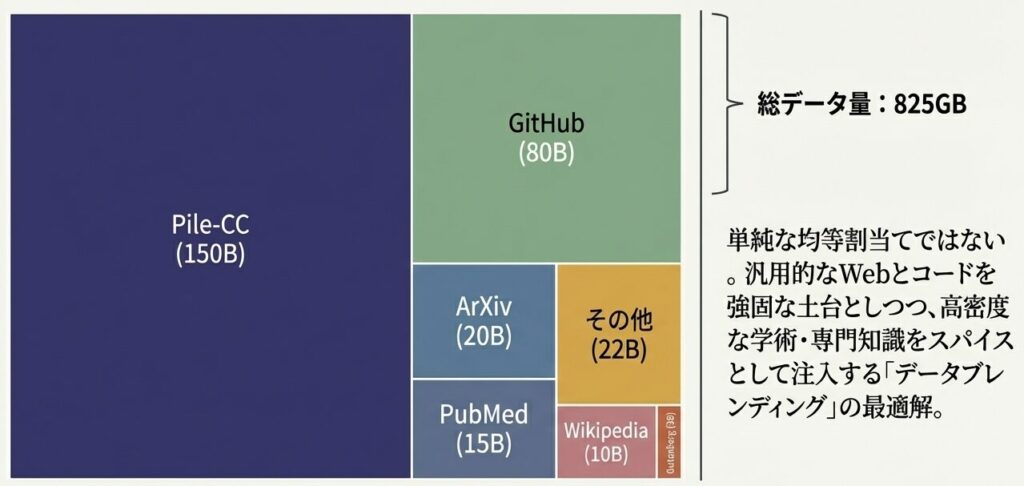
2.1 トークン数の内訳
The Pileの総規模は、圧縮後で825GB、トークン数ではおよそ300Bです。内訳を見ると、どのソースがどれだけ学習に寄与しているかが分かります。
内訳(トークン数)
- Pile-CC: 150B
- GitHub: 80B
- ArXiv: 20B
- PubMed: 15B
- Wikipedia: 10B
- Gutenberg: 3B
- その他: 22B
2.2 データセット規模比較

戦略的な配合比率:300Bトークンの内訳
3. 多様性がもたらした性能向上
3.1 重要な発見
The Pileの価値は、単にソース数が多いことではありません。異なる種類の文章を混ぜることで、モデルが学習できる表現の幅そのものを広げた点にあります。
実験結果
- 比較実験から見えてきたのは、「データの量よりも構成が重要」という点でした
- 例として、Common Crawl 250Bトークンの単一ソース構成では基準スコアが70%でした
- 一方、The Pile 300Bトークンの22ソース構成では77%となり、性能は+7%改善しました
- この結果から、単なるスケーリングだけではなく、質的な設計が重要だという認識が広がりました
3.2 クロスドメイン性能の向上
The Pileの強みは、特定のタスクだけでなく、複数のドメインでそろって性能が上がりやすいことにもあります。以下は、傾向が見えやすいように主要な比較を抜き出したものです。
| タスク | Common Crawl | The Pile | 差分 |
|---|---|---|---|
| 学術論文理解 | 65% | 75% | +10% |
| コード生成 | 62% | 72% | +10% |
| 百科事典問答 | 70% | 78% | +8% |
| 質問応答 | 68% | 76% | +8% |
この結果は、The Pileが「ある分野だけに強いデータセット」ではなく、複数ドメインでバランスよく学習を支える設計になっていることを示しています。
4. 多様性の効果のメカニズム
4.1 なぜ多様性が効くのか
多様性が効く理由は、感覚論だけではありません。同じ概念を違う文脈で何度も見せることで、モデルが表面的なパターンに引っ張られにくくなるからです。
理由を3つに分けると、次のように整理できます。
- 表現の汎化
- 異なるドメインで同じ概念を、別々の言い回しで学習できる
- たとえば「推論」は、数学論文、プログラミング、法律文書で少しずつ違う形で現れる
- その結果、より堅牢な概念理解につながる
- 知識の転移
- あるドメインで学んだ知識を、別のドメインで活用しやすくなる
- たとえば、科学論文の論理構造が法律文書の読み取りに役立つことがある
- 過学習の防止
- 単一ソースだけだと、特定の文体やパターンに過適合しやすい
- 多様なソースを混ぜることで、自然な正則化の効果が得られる
この3点が重なることで、The Pileは「広く読めるモデル」を育てやすい構成になっています。
4.2 ソース別の貢献
多角的な学習プロセスの可視化
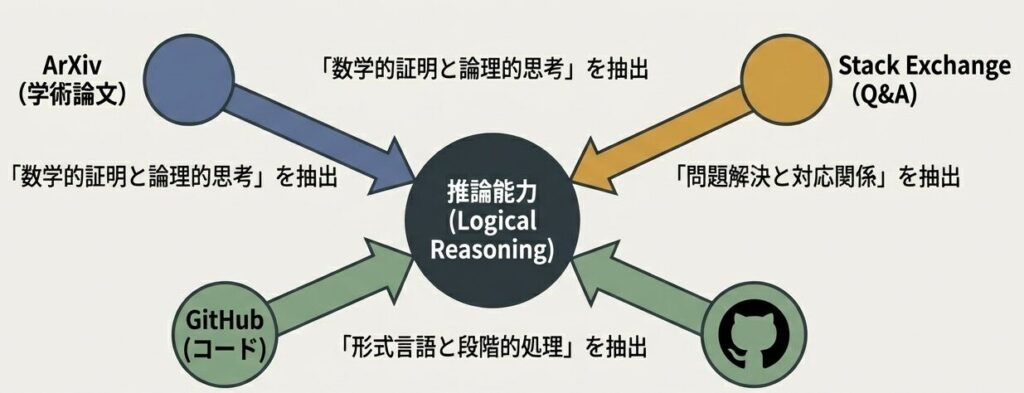
各ソースの役割
-
ArXiv(論文)
- 論理的思考や数学的表現を学べる
- 長文の構造化された議論に強い
-
GitHub(コード)
- 形式言語の理解に向いている
- 段階的な処理の表現を学べる
-
Wikipedia(百科事典)
- 事実知識や定義の学習に向いている
- 中立的で体系的な説明が多い
-
Stack Exchange(Q&A)
- 問題解決パターンを学べる
- 質問と回答の対応関係が明確
-
Books(書籍)
- 長文の一貫性を学びやすい
- 文学的表現やストーリー構造も含まれる
1つの概念を異なる文脈(コンテキスト)で何度も照射することで、モデルは表面的なパターンではなく、背後にある普遍的な「構造」を獲得する。
5. The Pileの影響と後続研究
5.1 パラダイムシフト
The Pileの登場で、データセット設計の話は「どうやって大量に集めるか」から「どういう構成で学ばせるか」へ少しずつ移っていきました。

The Pile以前
- 「データ量」が最重要だった
- 巨大なCommon Crawlを使えば性能が上がると考えられていた
The Pile以後
- 「データ構成」が決定的だと認識されるようになった
- 戦略的なソース選択と配合が必要になった
- この考え方が後続のDolmaやFineWebにも影響した
データセット設計は、もはや単なる前処理ではなく、LLM開発における最もクリエイティブで決定的な「アーキテクチャ設計」となった。
5.2 研究コミュニティへの貢献
オープンソースの意義
- The Pileはデータセット自体を公開している
- 構築パイプラインも公開されている
- 研究の再現性を確保しやすい
- その結果、多くの後続研究が参照し、データセット設計の標準化にも貢献した
- 商用LLMの設計にも影響を与えた
6. 実務での活用指針
6.1 The Pile利用のケース
適している場面
- 汎用LLMのプロトタイピング
- 学術研究・実験
- 中規模モデル(1〜10B)の訓練
利点
- バランスの取れた多様性がある
- 研究での実績がある
- 適度なサイズ(825GB)で扱いやすい
- オープンソースとして参照しやすい
制約
- 最新のデータセットより規模が小さい
- 一部のソースにライセンス問題がある(Books3など)
6.2 推奨される使用シナリオ
研究・実験段階
- 推奨度: ⭐⭐⭐⭐⭐
- 理由: 多様性とサイズのバランスが最適
商用開発初期
- 推奨度: ⭐⭐⭐⭐
- 理由: 品質が確保されており、実績もある
大規模商用モデル
- 推奨度: ⭐⭐
- 理由: FineWebなど、より大規模なデータセットを優先したい
📖 参考文献
主要論文
-
Gao, L., et al. (2020): “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, arXiv
-
Touvron, H., et al. (2023): “LLaMA: Open and Efficient Foundation Language Models”, arXiv
-
Xie, S. M., et al. (2023): “Doremi: Optimizing Data Mixture for Language Model Pre-Training”, arXiv
📚 シリーズ案内
ブログC:データセット戦略編では、LLM訓練データの選択と前処理戦略を解説しています。
このシリーズの他の記事:
- Common Crawlとスケール戦略
- The Pileと多様性の発見(この記事)
- Dolmaと前処理の体系化
- FineWebと学習効率の最前線
- データセット前処理戦略の比較分析
- データセット選択ガイダンス
- 特化データセット戦略とドメイン最適化
- データブレンディングと将来の自動化戦略
関連シリーズ:
- ブログA:基礎理論編 – 基礎的導入
- ブログB:実装詳細編 – 言語対応処理
前の記事: Common Crawlとスケール戦略 次の記事: Dolmaと前処理の体系化

コメント