
Gemmaモデルとは?


Gemmaの概要
Gemmaは、Googleの「Gemini」モデルに用いられた技術を基に開発された、軽量で最先端のオープン言語モデルファミリーです。
このモデルは大規模テキストコーパスを用いて自己教師ありの方法で事前トレーニングされ、ドメイン特有のデータで微調整されることで、センチメント分析などの様々なNLPタスクに対応します。
Gemmaモデルは、その比較的小さなサイズにより、リソースが限られた環境でも使用可能で、質問応答、要約、推論などのテキスト生成タスクに適しています。
Gemmaの特徴
リソースの効率性
Gemmaモデルは比較的小さいサイズであり、ラップトップやデスクトップ、独自のクラウドインフラストラクチャなど、リソースが限られた環境でもデプロイ可能です。
アクセスの民主化
最先端のAIモデルへのアクセスを拡大し、幅広いユーザーがイノベーションを進めることを可能にします。
安全性と信頼性
トレーニングデータからの個人情報除外、ヒューマンフィードバックによる微調整、リスクプロファイルの評価など、安全かつ信頼性の高いモデル作成のための厳格な措置が講じられています。
責任あるAI
モデルの命令調整、レッドチーム化、敵対的テスト、危険な活動に対するモデルの挙動評価など、責任ある行動を促すための広範な微調整と強化学習が用いられています。
透明性
モデルカードには、これらの評価の概要が記載されており、ユーザーがGemmaモデルのリスクプロファイルを理解しやすくなっています。
Model Card

Gemmaモデル
2Bと7Bの違い
Gemma には 2 つのサイズがあります。消費者向けサイズの GPU および TPU での効率的な導入と開発のための 7B パラメータと、CPU およびオンデバイス アプリケーション用の 2B バージョンです。どちらも、基本バージョンと命令調整バージョンがあります。
7B : GPU および TPU用
2B:CPU およびオンデバイス アプリケーション用
4つのモデル
Gemma は、Gemini をベースとした Google の 4 つの新しい LLM モデルのファミリーです。2B パラメーターと 7B パラメーターの 2 つのサイズがあり、それぞれにベース (事前トレーニング) バージョンと命令調整バージョンがあります。すべてのバリアントは、量子化なしでもさまざまなタイプのコンシューマ ハードウェアで実行でき、コンテキスト長は 8K トークンです。
- gemma-7b : ベース 7B モデル。
- gemma-7b-it : 基本 7B モデルの命令を微調整したバージョン。
- gemma-2b : ベース 2B モデル。
- gemma-2b-it : 基本 2B モデルの命令を微調整したバージョン。
モデルダウンロード

Chat

Gemmaモデルを使ってみる
いつも通りGoogleColabを使って説明します。今回はCPUのみでも動作できるgemma-2b-itを使ってみようと思います。7Bモデルを使用する場合はColabのランタイムを「T4 GPU」に変更してください。
Huggingfaceのアクセストークン取得
まずはHuggingFaceのトークンの取得を行うためにHuggingfaceにサインアップし、必要項目を入力しHuggingFaceの登録を進めていきます。

登録が完了すると下の画面が表示されます。
次にアクセストークンの取得を行うために右上のプロフィール画面から「setting」を選び、「Access Tokens」をクリックします。

「New token」をクリックしトークンを発行します。

これでHuggingfaceの「アクセストークン」を取得することができました。
モデルのライセンス取得
まずはモデルのライセンスを取得するためにHuggingfaceにログインをします。
モデルのライセンスを取得するためにgemma-2b-itのページにアクセスし、下の「Access Gemma on HuggingFace」からGoogleのライセンスを取得するために規約事項に同意します。

ライセンスの取得ができると「Gated model:You have been granted access to this model」と表示されます。

実行環境の準備
Colab上でまずHuggingfaceのアクセストークンを読み込みます。
# HuggingFaceのログイン
!huggingface-cli login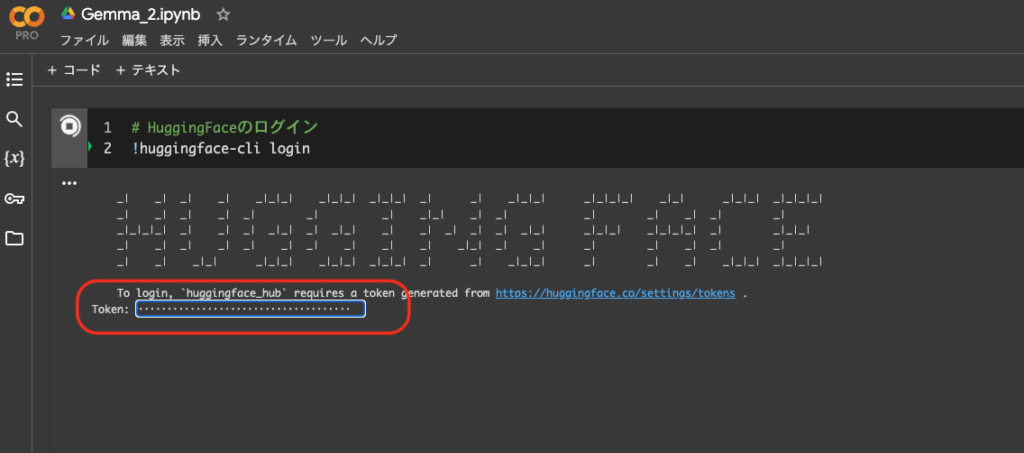
Colabでは読み込み方は上記の他にHuggingfaceのアクセストークンを予め読み込む方法があります。
Colab上の鍵マークをクリックし、シークレットの追加を行うことで上記のHuggingFaceへのログインを省略することが可能です。
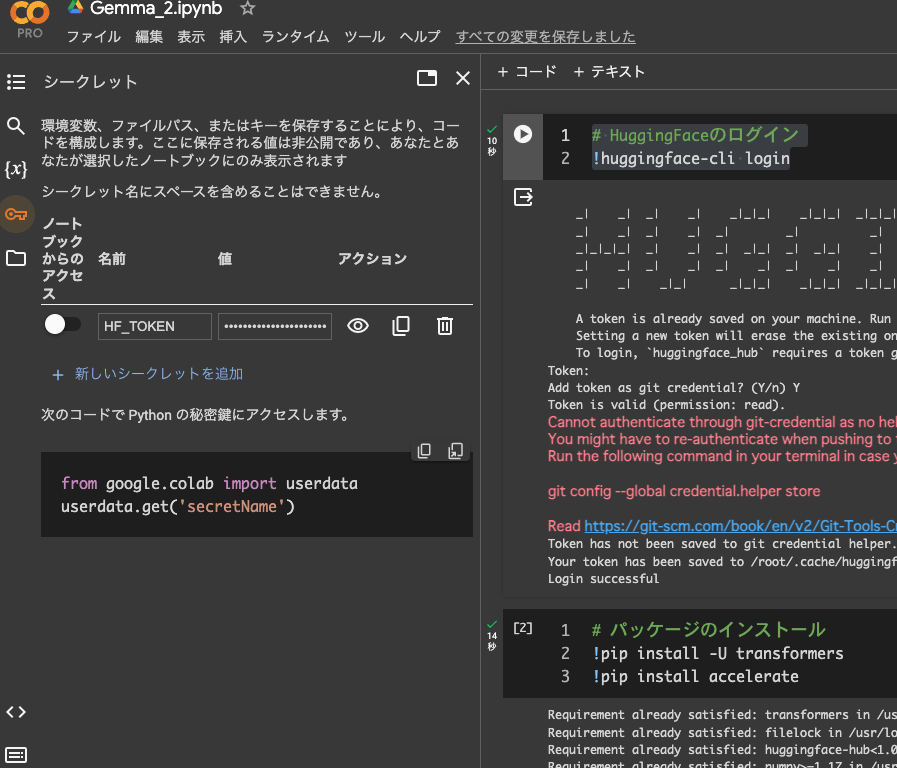
パッケージのインストール
次にパッケージのインストールを行います。
# パッケージのインストール
!pip install -U transformers
!pip install accelerateトークナイザーとモデルの準備
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-2b-it"
)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
torch_dtype=torch.float16
)推論の実行
2Bモデルの場合はmodelをFlote型に変更する必要があります。7Bモデルの場合は不要です。
# プロンプトの準備
chat = [
{ "role": "user", "content": "シンギュラリティとは何を意味するのでしょうか?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
model = model.float() # モデルをFloat型に変更
outputs = model.generate(
**input_ids,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.7,
repetition_penalty=1.1,
)
print(tokenizer.decode(outputs[0]))
gemma-2b-itの返答が無事返ってきました。「シンギュラリティ」という言葉を推論しているのがわかります。
まとめ
今回はCPUを使って2Bモデルを動かしましたが、7Bモデルを使って動作させることでGemmaの本当のポテンシャルを実感できるようなところがありましたので、ColabのGPU容量が余っている人は7Bモデルを是非試してみてください。


コメント