
スケール則の証拠と信頼性:主要研究の検証
スケール則は、きれいな理論式だけで成立している話ではありません。LLM 開発の現場で信頼されてきた理由は、異なる組織が、異なる条件で、似た傾向を何度も観測してきたからです。
ただし、ここで大事なのは「大規模化すれば必ず勝てる」という単純な話ではないことです。証拠が示しているのは、性能がどの要素にどう反応するか、かなり高い精度で見積もれるという点です。
この記事では、OpenAI の 2020 年研究と DeepMind の Chinchilla 研究を軸に、スケール則がなぜ信頼されるのか、どこまで使えるのかを整理します。
この記事で学べること
- OpenAI の Scaling Laws 論文が何を示したのか?
- DeepMind の Chinchilla 研究が何を変えたのか?
- スケール則が信頼される理由
- どこまで使えて、どこから注意が必要なのか?
1. OpenAI の研究は何を示したのか?
2020 年、OpenAI は「Scaling Laws for Neural Language Models」で、言語モデルの性能がパラメータ数、データ量、計算量に対して、予測可能な形で変化することを示しました。
この研究の重要点は、性能が単純な偶然ではなく、べき乗則に近い形で変化することを実証した点です。
具体的には、損失 $L$ はパラメータ数 $N$ に対して、おおむね次のような形で下がります。
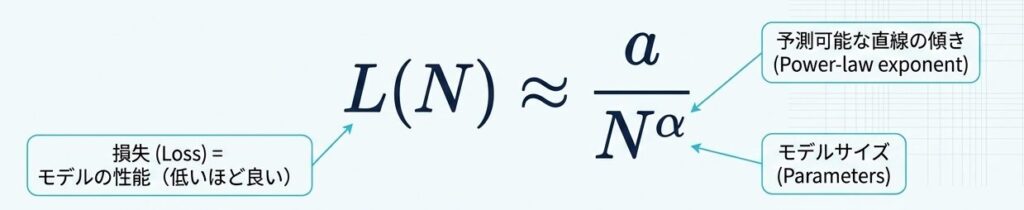
ここでの意味はシンプルです。モデルを大きくすると性能は上がりますが、その上がり方は気まぐれではなく、ある程度外挿できるということです。
たとえば何がうれしいのか?
たとえば、100M パラメータ程度の実験結果しかなくても、そこから 1B パラメータ級での傾向をある程度見積もれるようになります。
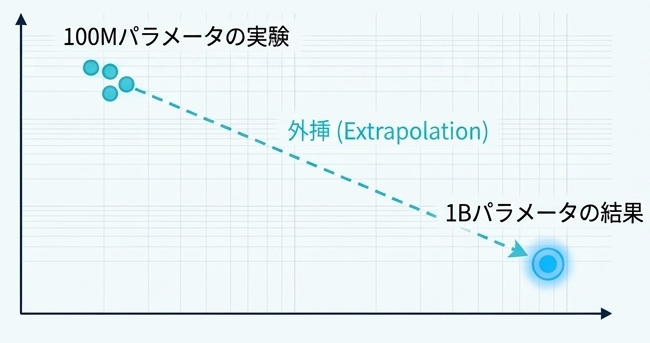
これは研究開発では大きいです。なぜなら、いきなり巨大な学習を走らせなくても、投資に見合う見込みがあるかを先に判断しやすくなるからです。
2. DeepMind の Chinchilla は何を変えたのか?
2022 年、DeepMind は「Training Compute-Optimal Large Language Models」で、計算量が限られているときに、どのようにパラメータ数と学習データ量を配分すべきかを示しました。ここで登場したのが Chinchilla です。
何が新しかったのか?
それ以前は、モデルを大きくすることが強く重視されがちでした。たとえば GPT-3 は 175B パラメータに対して、学習トークン数は約 300B です。
Chinchilla の研究が示したのは、計算量を固定するなら、パラメータ数だけを増やしても最適にはならないという点です。むしろ、十分なデータで学習させることとのバランスが重要でした。
Chinchilla が示した配分の違い
| 項目 | Gopher(従来型) | Chinchilla(最適型) | 改善度 |
|---|---|---|---|
| パラメータ数 | 280B | 70B | 1/4 |
| 学習トークン数 | 300B | 1.4T | 4.6倍 |
| D/N比 | 1.1 | 20.0 | 18倍 |
| 性能 | Baseline | 大幅に向上 | – |
パラメータを1/4に削り、データを4.6倍に増やす。D/N比が18倍に変わることで、はるかに小さなモデルが巨大モデル(Gopher)の性能を凌駕した。
この比較で見えてくるのは、サイズを小さくしても、学習データを増やせば性能が上がる場面があるということです。つまり、「大きいモデルが常に最良」ではありません。
十分なデータで学習させることとのバランスこそが最重要である。 同じ計算予算なら、「サイズを小さくして、学習データを増やす」 ことで性能が逆転する場面が存在する。
3. なぜ信頼できると言えるのか?
信頼性の根拠は、単一の研究の成功ではありません。異なる研究機関が、異なる時期に、異なる規模で、似た傾向を確認してきたことです。
実務で重要なのは、次の 3 点です。
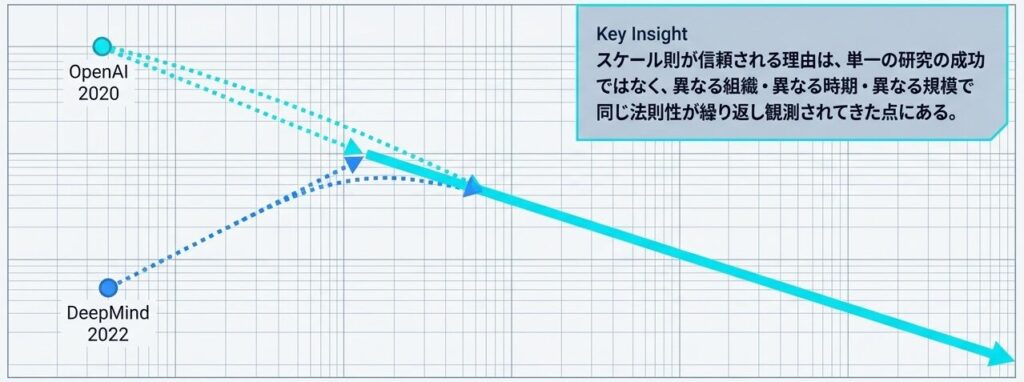
- 両対数グラフで見ると、きれいな直線に近い傾向が出る
- パラメータ数、データ量、計算量の関係を分けて考えられる
- 小規模実験から大規模実験の傾向を見積もりやすい
言い換えると、スケール則は「未来を完全に言い当てる魔法」ではなく、「投資判断の精度を上げる地図」に近い存在です。
4. どこまで信頼してよいのか?
スケール則は強力ですが、万能ではありません。信頼できるからこそ、限界もはっきり見ておく必要があります。
使いやすい領域
- 事前学習のような、Next Token Prediction を中心にしたタスク
- パラメータ数、データ量、計算量が十分に大きい領域
- 標準的な Transformer 系の構成
注意が必要な領域
- 創発能力のように、急に見え方が変わる現象
モデルサイズが大きくなると、推理やコード生成で予測しきれない改善が出ることがあります。これは、単純な直線的予測だけでは説明しにくい領域です。
- タスクごとの違い
すべてのタスクが同じように伸びるわけではありません。推理、コード生成、要約では、伸び方や最適な配分が違う可能性があります。
- データ汚染の問題
学習データと評価データが混ざっていれば、見かけの性能は簡単に良く見えてしまいます。この場合、スケール則そのものではなく、評価設計のほうが怪しくなります。
よくある誤解
「スケール則があるなら、ただ大きくすればいい」と考えるのは早計です。Chinchilla が示したのは、同じ計算予算でも、配分を変えれば結果が変わるということでした。
逆に言えば、証拠が強いからこそ、雑に使うと外しやすいとも言えます。
5. 実務ではどう使うのか?
スケール則は、研究者だけの話ではありません。実務では、次の判断に役立ちます。
たとえば、あるチームが「モデルを 2 倍にすれば精度も 2 倍上がるはずだ」と考えているとします。この見立ては、かなり危ういです。実際には、データが足りなければ伸びは鈍りますし、計算予算に対して配分を誤れば、無駄に重いだけのモデルになります。
ここで役立つのが、OpenAI の 2020 年研究と Chinchilla の考え方です。どちらも、「大きさ」ではなく「関係性」を見るべきだと教えてくれます。
スケール則は「大きさ」ではなく、「要素間の関係性」を見るためのツールであり、「何を増やすか」の前に、「何がボトルネックか」を特定するための羅針盤であると言えます。
6. まとめ
スケール則が信頼されるのは、単なる流行語だからではありません。異なる研究が、似た法則性を繰り返し確認し、さらにその法則を使ってモデル設計の改善まで実現してきたからです。
要点を整理すると、次の 3 つです。
- OpenAI は、性能がパラメータ数・データ量・計算量に対して予測可能に変化することを示した
- DeepMind は、計算予算が限られるときはモデルサイズだけでなくデータ量との配分が重要だと示した
- ただし、創発能力やタスク依存性、データ汚染のような限界は残る
スケール則は、万能な答えではありません。それでも、投資判断と実験設計の精度を上げるという意味では、今でも非常に強い道具です。
7. 今回のブログの考察
今回の記事で見えてくるのは、スケール則の価値は「大きいモデルが強い」という単純な話ではなく、性能の変化をどう見積もるかを教えてくれる点にある、ということです。OpenAI の研究は、性能がパラメータ数、データ量、計算量に対して規則的に変わることを示し、DeepMind の Chinchilla は、その規則を使うなら配分の考え方まで含めて見なければいけないと教えてくれました。
実務でこの話が重要なのは、モデルの拡大そのものよりも、限られた予算の中で何を優先するかを判断しやすくなるからです。パラメータだけを増やして安心するのではなく、データが足りているのか、計算資源の使い方が妥当なのかを一緒に見る。そうした見方ができると、開発は一気に感覚論から離れます。
ただし、スケール則を知ったからといって、すぐに正解が分かるわけではありません。今回扱った内容はあくまで経験則であり、データ品質や評価設計が悪ければ、きれいな法則も簡単に崩れます。だからこそ大事なのは、スケール則を「答え」ではなく、「判断の順番を整えるための道具」として使うことです。何を増やすべきかを考える前に、何がボトルネックなのかを見極める。その姿勢があるかどうかで、同じ理論を読んでも実務での成果はかなり変わります。
参考文献
- Kaplan, J. et al. (2020). “Scaling Laws for Neural Language Models.” arXiv:2001.08361
- Hoffmann, J. et al. (2022). “Training Compute-Optimal Large Language Models.” arXiv:2203.15556
- Rae, J. et al. (2021). “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.” arXiv:2112.11446


コメント